
1. 소개
생성형 AI 제품은 비교적 새로운 기술이며 애플리케이션의 동작은 이전 형태의 소프트웨어보다 더 다양할 수 있습니다. 따라서 사용 중인 머신러닝 모델을 조사하고, 모델의 행동 사례를 검토하고, 예상치 못한 결과를 조사하는 것이 중요합니다.
Learning Interpretability Tool (LIT; 웹사이트, GitHub)은 ML 모델을 디버깅하고 분석하여 모델이 특정 방식으로 작동하는 이유와 방법을 이해하는 플랫폼입니다.
이 Codelab에서는 LIT를 사용하여 Google의 Gemma 모델을 최대한 활용하는 방법을 알아봅니다. 이 Codelab에서는 해석 가능성 기법인 시퀀스 현저성을 사용하여 다양한 프롬프트 엔지니어링 접근 방식을 분석하는 방법을 보여줍니다.
학습 목표:
- 시퀀스 현저성과 모델 분석에서의 사용 이해
- 프롬프트 출력과 시퀀스 현저성을 계산하기 위해 Gemma용 LIT 설정
- LM Salience 모듈을 통해 시퀀스 현저성을 사용하여 프롬프트 설계가 모델 출력에 미치는 영향을 파악합니다.
- LIT에서 가설로 설정된 프롬프트 개선사항을 테스트하고 그 영향을 확인합니다.
참고: 이 Codelab에서는 Gemma의 KerasNLP 구현과 백엔드로 TensorFlow v2를 사용합니다. GPU 커널을 사용하여 따라 하는 것이 좋습니다.
2. 시퀀스 현저성과 모델 분석에서의 사용
Gemma와 같은 텍스트 간 변환 생성 모델은 토큰화된 텍스트 형태의 입력 시퀀스를 가져와 해당 입력에 대한 일반적인 후속 또는 완성인 새 토큰을 생성합니다. 이 생성은 한 번에 하나의 토큰으로 이루어지며, 모델이 중지 조건에 도달할 때까지 새로 생성된 각 토큰을 입력과 이전 생성에 추가합니다 (루프에서). 예를 들어 모델이 시퀀스 종료 (EOS) 토큰을 생성하거나 사전 정의된 최대 길이에 도달하는 경우입니다.
Salience 메서드는 입력의 어떤 부분이 출력의 여러 부분에 대해 모델에 중요한지 알려주는 설명 가능한 AI (XAI) 기법의 한 종류입니다. LIT는 다양한 분류 작업의 현저성 메서드를 지원하여 입력 토큰 시퀀스가 예측 라벨에 미치는 영향을 설명합니다. 시퀀스 현저성은 이러한 방법을 텍스트 간 생성 모델로 일반화하고 생성된 토큰에 대한 이전 토큰의 영향을 설명합니다.
여기서는 시퀀스 현저성에 Grad L2 Norm 메서드를 사용합니다. 이 메서드는 모델의 그라데이션을 분석하고 각 이전 토큰이 출력에 미치는 영향의 크기를 제공합니다. 이 방법은 간단하고 효율적이며 분류 및 기타 설정에서 성능이 우수한 것으로 입증되었습니다. 관련성 점수가 클수록 영향력이 높습니다. 이 메서드는 해석 가능성 연구 커뮤니티에서 잘 이해되고 널리 활용되므로 LIT 내에서 사용됩니다.
더 고급 경사 기반 현저성 기법에는 Grad ⋅ Input 및 통합 경사가 있습니다. LIME 및 SHAP와 같은 제거 기반 방법도 사용할 수 있으며, 이는 더 강력하지만 계산 비용이 훨씬 더 많이 듭니다. 다양한 중요도 방법의 자세한 비교는 이 도움말을 참고하세요.
이 대화형 탐색형 돌출성 소개에서 돌출성 방법의 과학에 대해 자세히 알아볼 수 있습니다.
3. 가져오기, 환경, 기타 설정 코드
새 Colab에서 이 Codelab을 따라 하는 것이 좋습니다. 메모리에 모델을 로드하므로 액셀러레이터 런타임을 사용하는 것이 좋습니다. 하지만 액셀러레이터 옵션은 시간이 지남에 따라 달라지며 제한이 적용됩니다. 더 강력한 가속기에 액세스하려면 Colab에서 유료 구독을 이용하세요. 또는 머신에 적절한 GPU가 있는 경우 로컬 런타임을 사용할 수 있습니다.
참고: 다음과 같은 경고가 표시될 수 있습니다.
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
이러한 오류는 무시해도 됩니다.
LIT 및 Keras NLP 설치
이 Codelab에서는 최신 버전의 keras (3), keras-nlp (0.14), lit-nlp (1.2)이 필요하며 기본 모델을 다운로드할 Kaggle 계정이 필요합니다.
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
Kaggle 액세스
Kaggle로 인증하려면 다음 중 하나를 수행하세요.
~/.kaggle/kaggle.json과 같은 파일에 사용자 인증 정보를 저장합니다.KAGGLE_USERNAME및KAGGLE_KEY환경 변수를 사용합니다.- Google Colab과 같은 대화형 Python 환경에서 다음을 실행합니다.
import kagglehub
kagglehub.login()
자세한 내용은 kagglehub 문서를 참고하고 Gemma 라이선스 계약에 동의하세요.
Keras 구성
Keras 3는 TensorFlow (기본값), PyTorch, JAX를 비롯한 여러 딥 러닝 백엔드를 지원합니다. 백엔드는 KERAS_BACKEND 환경 변수를 사용하여 구성되며, 이 변수는 Keras 라이브러리를 가져오기 전에 설정해야 합니다. 다음 코드 스니펫은 대화형 Python 환경에서 이 변수를 설정하는 방법을 보여줍니다.
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
4. LIT 설정
LIT는 Python 노트북에서 또는 웹 서버를 통해 사용할 수 있습니다. 이 Codelab은 노트북 사용 사례에 중점을 두므로 Google Colab에서 따라 하는 것이 좋습니다.
이 Codelab에서는 KerasNLP 사전 설정을 사용하여 Gemma v2 2B IT를 로드합니다. 다음 스니펫은 Gemma를 초기화하고 LIT Notebook 위젯에 예시 데이터 세트를 로드합니다.
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
필수 위치 인수 두 개에 전달되는 값을 변경하여 위젯을 구성할 수 있습니다.
datasets_config: 로드할 데이터 세트 이름과 경로가 포함된 문자열 목록입니다. 'dataset:path' 형식이며, 여기서 경로는 URL 또는 로컬 파일 경로일 수 있습니다. 아래 예에서는 특수 값sample_prompts을 사용하여 LIT 배포에 제공된 예시 프롬프트를 로드합니다.models_config: 모델 이름과 로드할 경로가 포함된 문자열 목록입니다. 'model:path' 형식이며, 여기서 경로는 URL, 로컬 파일 경로 또는 구성된 딥 러닝 프레임워크의 사전 설정 이름일 수 있습니다.
관심 있는 모델을 사용하도록 LIT를 구성한 후 다음 코드 스니펫을 실행하여 노트북에서 위젯을 렌더링합니다.
lit_widget.render(open_in_new_tab=True)
자체 데이터 사용
텍스트 간 변환 생성형 모델인 Gemma는 텍스트 입력을 받아 텍스트 출력을 생성합니다. LIT는 의견이 있는 API를 사용하여 로드된 데이터 세트의 구조를 모델에 전달합니다. LIT의 LLM은 다음 두 필드를 제공하는 데이터 세트와 함께 작동하도록 설계되었습니다.
prompt: 텍스트가 생성될 모델의 입력target: 인간 평가자의 '정답' 응답이나 다른 모델의 사전 생성된 응답과 같은 선택적 타겟 시퀀스입니다.
LIT에는 이 Codelab과 LIT의 확장된 프롬프트 디버깅 튜토리얼을 지원하는 다음 소스의 예가 포함된 작은 sample_prompts 세트가 포함되어 있습니다.
- GSM8K: 몇 가지 예시를 통해 초등학교 수학 문제 풀기
- Gigaword Benchmark: 짧은 기사 모음의 헤드라인 생성
- 헌법적 프롬프트: 가이드라인/경계를 사용하여 객체를 사용하는 방법에 관한 새로운 아이디어를 생성합니다.
필드 prompt 및 선택적으로 target (예)이 포함된 레코드가 있는 .jsonl 파일로 또는 LIT의 Dataset API를 사용하여 모든 형식에서 자체 데이터를 쉽게 로드할 수도 있습니다.
아래 셀을 실행하여 샘플 프롬프트를 로드합니다.
5. LIT에서 Gemma의 퓨샷 프롬프트 분석
오늘날 프롬프트는 과학만큼이나 예술에 가깝습니다. LIT는 Gemma와 같은 대규모 언어 모델의 프롬프트를 경험적으로 개선하는 데 도움이 됩니다. 아래에서 LIT를 사용하여 Gemma의 동작을 탐색하고, 잠재적인 문제를 예측하고, 안전성을 개선하는 방법을 보여주는 예를 확인할 수 있습니다.
복잡한 프롬프트의 오류 식별
고품질 LLM 기반 프로토타입 및 애플리케이션을 위한 가장 중요한 프롬프트 기법 두 가지는 퓨샷 프롬프트 (프롬프트에 원하는 동작의 예 포함)와 연쇄적 사고 (LLM의 최종 출력 전에 설명 또는 추론 형태 포함)입니다. 하지만 효과적인 프롬프트를 만드는 것은 여전히 어려운 경우가 많습니다.
예를 들어 사용자의 취향에 따라 음식을 좋아할지 평가하는 데 도움을 주는 경우를 생각해 보세요. 초기 프로토타입 연쇄적 사고 프롬프트 템플릿은 다음과 같을 수 있습니다.
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
이 프롬프트의 문제를 발견하셨나요? LIT를 사용하면 LM Salience module을 사용하여 프롬프트를 검사할 수 있습니다.
6. 디버깅을 위해 시퀀스 중요도 사용
중요도는 가능한 가장 작은 수준(즉, 각 입력 토큰)에서 계산되지만 LIT는 토큰 중요도를 더 해석하기 쉬운 더 큰 범위(예: 줄, 문장 또는 단어)로 집계할 수 있습니다. Saliency Explorable에서 중요도와 이를 사용하여 의도하지 않은 편향을 식별하는 방법을 자세히 알아보세요.
프롬프트 템플릿 변수에 대한 새 예시 입력을 프롬프트에 제공하여 시작해 보겠습니다.
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
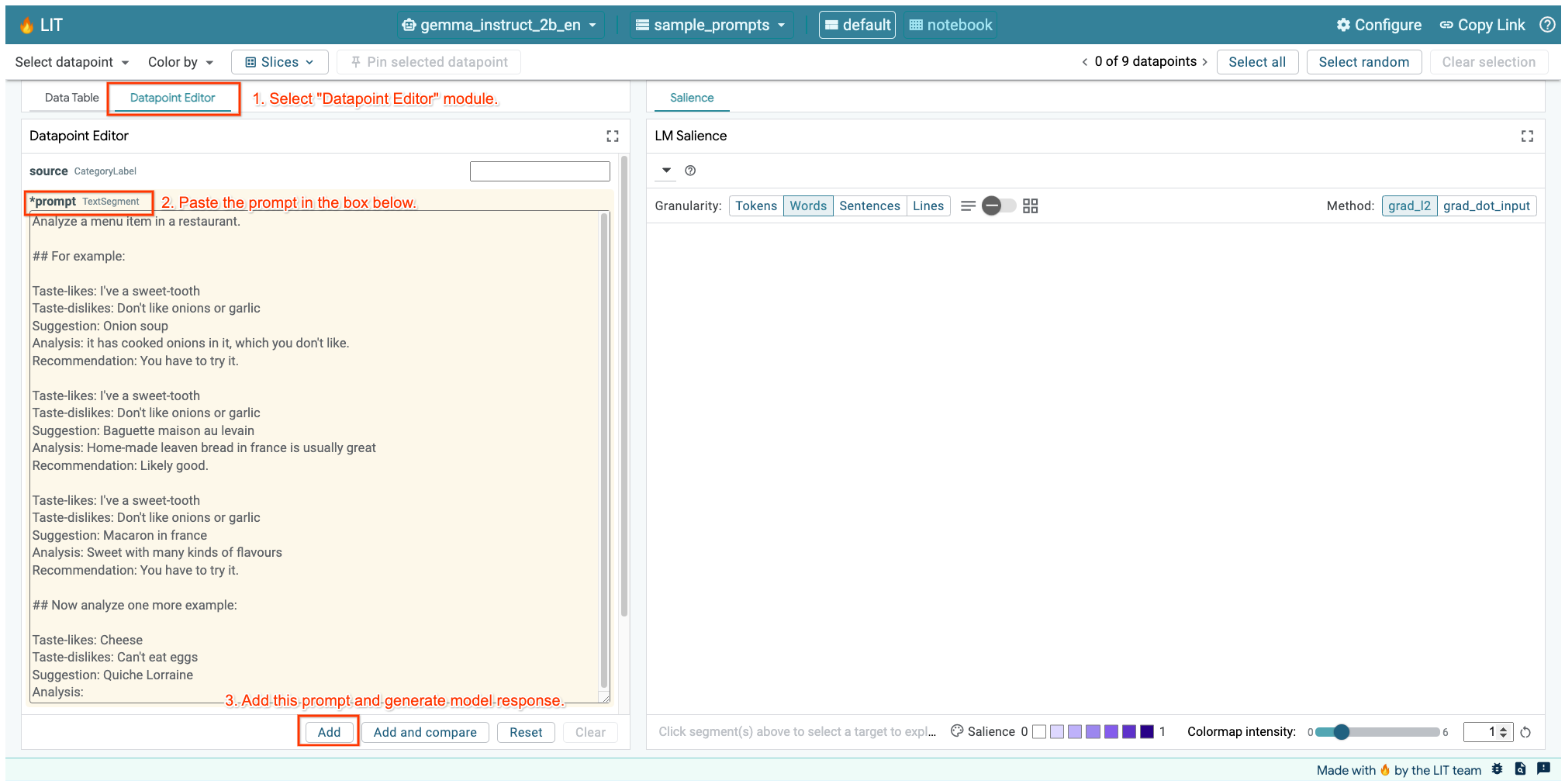
위의 셀이나 별도의 탭에 LIT UI가 열려 있는 경우 LIT의 데이터 포인트 편집기를 사용하여 다음 프롬프트를 추가할 수 있습니다.
또 다른 방법은 관심 있는 프롬프트로 위젯을 직접 다시 렌더링하는 것입니다.
lit_widget.render(data=[fewshot_mistake_example])
놀라운 모델 완성에 주목하세요.
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
모델이 명확하게 먹을 수 없다고 말한 음식을 추천하는 이유는 무엇인가요?
시퀀스 현저성은 퓨샷 예시에 있는 근본 문제를 강조하는 데 도움이 될 수 있습니다. 첫 번째 예에서 분석 섹션의 사고의 흐름 추론 it has cooked onions in it, which you don't like이 최종 추천 You have to try it과 일치하지 않습니다.
LM Salience 모듈에서 'Sentences'를 선택한 다음 추천 라인을 선택합니다. 이제 UI가 다음과 같이 표시됩니다.
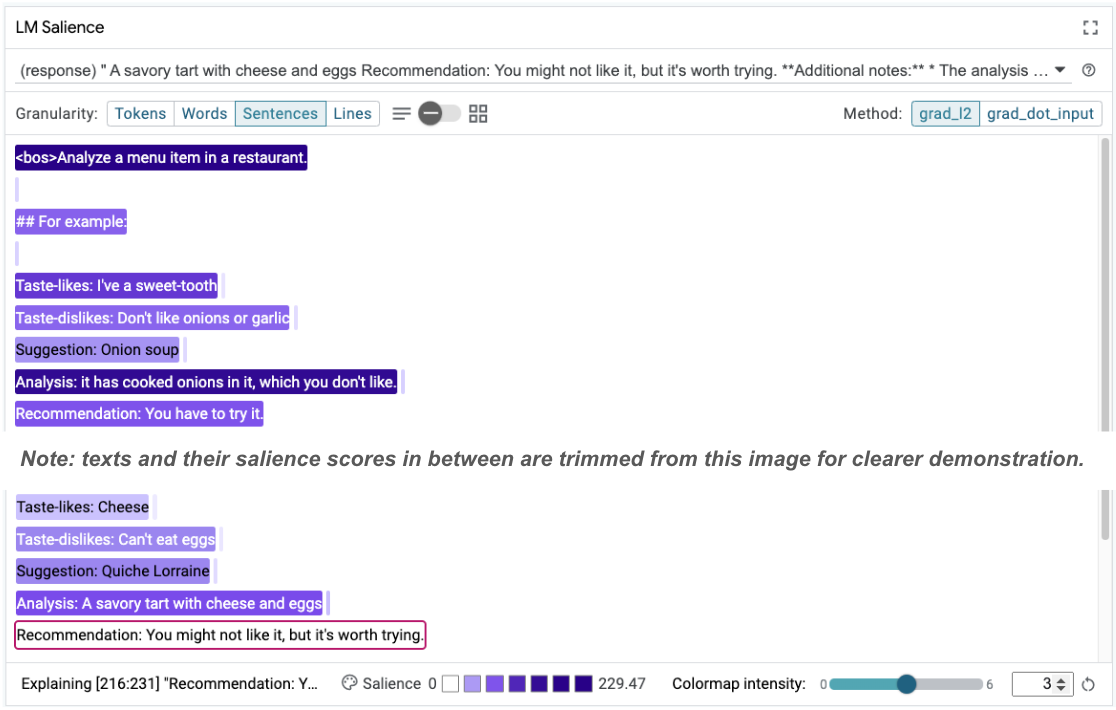
이는 추천 부분을 실수로 복사하여 붙여넣고 업데이트하지 않은 인적 오류를 강조합니다.
이제 첫 번째 예의 '추천'을 Avoid로 수정하고 다시 시도해 보겠습니다. LIT에는 이 예시가 샘플 프롬프트에 미리 로드되어 있으므로 이 작은 유틸리티 함수를 사용하여 가져올 수 있습니다.
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
이제 모델 완성은 다음과 같이 됩니다.
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
여기서 얻을 수 있는 중요한 교훈은 초기 프로토타입 제작을 통해 사전에 생각하지 못했던 위험을 파악할 수 있다는 것입니다. 언어 모델의 오류 발생 가능성을 고려하여 오류를 사전에 방지하는 설계를 해야 합니다. 자세한 내용은 AI를 활용한 설계를 위한 People + AI 가이드북을 참고하세요.
수정된 몇 가지 예시 프롬프트가 더 나은 것은 사실이지만, 여전히 완전히 올바르지는 않습니다. 사용자에게 달걀을 피하라고 올바르게 말하지만, 그 이유가 올바르지 않습니다. 실제로 사용자는 달걀을 먹을 수 없다고 말했는데, 달걀을 좋아하지 않는다고 말합니다. 다음 섹션에서는 더 나은 방법을 알아봅니다.
7. 가설을 테스트하여 모델 동작 개선
LIT를 사용하면 동일한 인터페이스 내에서 프롬프트의 변경사항을 테스트할 수 있습니다. 이 인스턴스에서는 헌법을 추가하여 모델의 동작을 개선하는 것을 테스트합니다. 컨스티튜션은 모델의 생성을 안내하는 데 도움이 되는 원칙이 포함된 디자인 프롬프트를 의미합니다. 최근 방법은 헌법 원칙의 대화형 파생도 지원합니다.
이 아이디어를 사용하여 프롬프트를 더욱 개선해 보겠습니다. 이제 다음과 같이 시작하는 프롬프트의 상단에 생성 원칙이 포함된 섹션을 추가합니다.
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
이 업데이트를 통해 예시를 다시 실행하고 매우 다른 출력을 확인할 수 있습니다.
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
그런 다음 프롬프트의 두드러짐을 다시 검토하여 이러한 변화가 발생하는 이유를 파악할 수 있습니다.
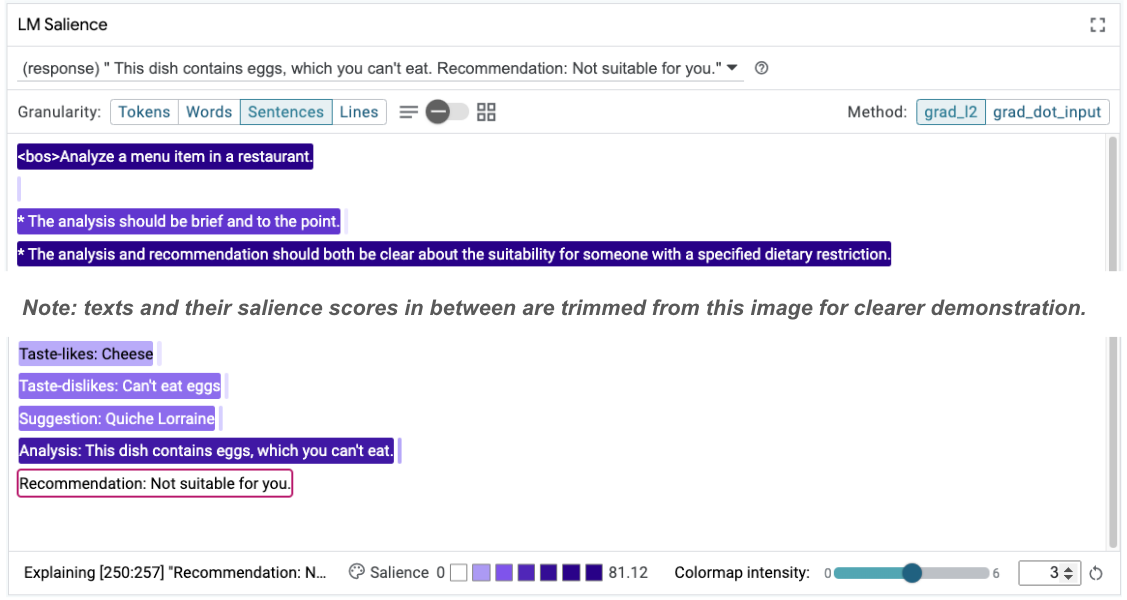
훨씬 안전한 추천을 확인하세요. 또한 '나에게 적합하지 않음'은 분석 (소위 사고의 연쇄)과 함께 식이 제한에 따라 적합성을 명확하게 명시하는 원칙의 영향을 받습니다. 이렇게 하면 출력이 올바른 이유로 발생한다는 확신을 더할 수 있습니다.
8. 모델 프로빙 및 탐색에 비기술팀 포함
해석 가능성은 XAI, 정책, 법률 등 다양한 분야의 전문 지식을 아우르는 팀의 노력으로 이루어집니다.
초기 개발 단계에서 모델과 상호작용하려면 일반적으로 상당한 기술 전문 지식이 필요했기 때문에 일부 공동작업자가 모델에 액세스하고 조사하기가 더 어려웠습니다. 이러한 팀이 초기 프로토타입 제작 단계에 참여할 수 있는 도구가 과거에는 없었습니다.
LIT를 통해 이러한 패러다임을 바꿀 수 있기를 바랍니다. 이 Codelab을 통해 살펴본 것처럼 LIT의 시각적 매체와 두드러짐을 검사하고 예시를 탐색하는 대화형 기능을 사용하면 다양한 이해관계자가 결과를 공유하고 소통할 수 있습니다. 이를 통해 모델 탐색, 프로빙, 디버깅을 위해 더 다양한 팀원을 참여시킬 수 있습니다. 이러한 기술적 방법을 접하게 되면 모델의 작동 방식을 더 잘 이해할 수 있습니다. 또한 초기 모델 테스트에서 더 다양한 전문성을 갖추면 개선할 수 있는 바람직하지 않은 결과를 발견하는 데 도움이 될 수 있습니다.
9. 요약
요약하면 다음과 같습니다.
- LIT UI는 대화형 모델 실행을 위한 인터페이스를 제공하여 사용자가 직접 출력을 생성하고 '만약' 시나리오를 테스트할 수 있습니다. 이는 다양한 프롬프트 변형을 테스트하는 데 특히 유용합니다.
- LM Salience 모듈은 중요도를 시각적으로 표현하고 제어 가능한 데이터 세분성을 제공하므로 모델 중심 구조 (예: 토큰) 대신 인간 중심 구조 (예: 문장 및 단어)에 관해 소통할 수 있습니다.
모델 평가에서 문제가 있는 예시를 찾으면 디버깅을 위해 LIT로 가져옵니다. 모델링 작업과 논리적으로 관련된 가장 큰 콘텐츠 단위를 분석하고, 시각화를 사용하여 모델이 프롬프트 콘텐츠에 올바르게 또는 잘못 집중하는 위치를 확인한 다음, 더 작은 콘텐츠 단위로 드릴다운하여 표시되는 잘못된 동작을 추가로 설명하여 가능한 수정사항을 파악합니다.
마지막으로 Lit은 지속적으로 개선되고 있습니다. 여기에서 기능을 자세히 알아보고 의견을 공유하세요.