
1. ভূমিকা
জেনারেটিভ এআই পণ্যগুলি তুলনামূলকভাবে নতুন এবং একটি অ্যাপ্লিকেশনের আচরণ পূর্ববর্তী সফ্টওয়্যারের তুলনায় অনেক বেশি পরিবর্তিত হতে পারে। এর ফলে ব্যবহৃত মেশিন লার্নিং মডেলগুলি অনুসন্ধান করা, মডেলের আচরণের উদাহরণগুলি পরীক্ষা করা এবং আশ্চর্যজনক ঘটনাগুলি তদন্ত করা গুরুত্বপূর্ণ হয়ে ওঠে।
লার্নিং ইন্টারপ্রেটেবিলিটি টুল (LIT; ওয়েবসাইট , GitHub ) হল ML মডেলগুলি কেন এবং কীভাবে আচরণ করে তা বোঝার জন্য ডিবাগিং এবং বিশ্লেষণ করার একটি প্ল্যাটফর্ম।
এই কোডল্যাবে, আপনি শিখবেন কিভাবে LIT ব্যবহার করে Google এর Gemma মডেল থেকে আরও বেশি কিছু পেতে হয়। এই কোডল্যাবটি বিভিন্ন প্রম্পট ইঞ্জিনিয়ারিং পদ্ধতি বিশ্লেষণ করার জন্য সিকোয়েন্স স্যালিয়েন্স, একটি ব্যাখ্যাযোগ্যতা কৌশল, কীভাবে ব্যবহার করতে হয় তা প্রদর্শন করে।
শেখার উদ্দেশ্য:
- মডেল বিশ্লেষণে সিকোয়েন্স স্যালিয়েন্স এবং এর ব্যবহার বোঝা।
- প্রম্পট আউটপুট এবং সিকোয়েন্স স্যালিয়েন্স গণনা করার জন্য জেমার জন্য LIT সেট আপ করা হচ্ছে।
- মডেল আউটপুটগুলিতে প্রম্পট ডিজাইনের প্রভাব বোঝার জন্য LM স্যালিয়েন্স মডিউলের মাধ্যমে সিকোয়েন্স স্যালিয়েন্স ব্যবহার করা।
- LIT-তে অনুমানকৃত তাৎক্ষণিক উন্নতি পরীক্ষা করা এবং তাদের প্রভাব দেখা।
দ্রষ্টব্য: এই কোডল্যাবটি Gemma-এর KerasNLP বাস্তবায়ন এবং ব্যাকএন্ডের জন্য TensorFlow v2 ব্যবহার করে। এটি অনুসরণ করার জন্য একটি GPU কার্নেল ব্যবহার করার জন্য অত্যন্ত সুপারিশ করা হয়।
2. মডেল বিশ্লেষণে সিকোয়েন্স স্যালিয়েন্স এবং এর ব্যবহার
টেক্সট-টু-টেক্সট জেনারেটিভ মডেল, যেমন জেম্মা, টোকেনাইজড টেক্সট আকারে একটি ইনপুট সিকোয়েন্স নেয় এবং নতুন টোকেন তৈরি করে যা সেই ইনপুটের সাধারণ ফলো-অন বা সম্পূর্ণতা। এই জেনারেশনটি একবারে একটি টোকেন তৈরি করে, প্রতিটি নতুন জেনারেটেড টোকেনকে ইনপুটে (একটি লুপে) যুক্ত করে এবং পূর্ববর্তী যেকোনো প্রজন্মকে মডেলটি স্টপিং অবস্থায় পৌঁছানো পর্যন্ত। উদাহরণগুলির মধ্যে রয়েছে যখন মডেলটি একটি এন্ড-অফ-সিকোয়েন্স (EOS) টোকেন তৈরি করে বা পূর্বনির্ধারিত সর্বোচ্চ দৈর্ঘ্যে পৌঁছায়।
স্যালিয়েন্স পদ্ধতি হল ব্যাখ্যাযোগ্য AI (XAI) কৌশলের একটি শ্রেণী যা আপনাকে বলতে পারে যে একটি ইনপুটের কোন অংশগুলি মডেলের জন্য তার আউটপুটের বিভিন্ন অংশের জন্য গুরুত্বপূর্ণ। LIT বিভিন্ন শ্রেণীবদ্ধকরণ কাজের জন্য স্যালিয়েন্স পদ্ধতি সমর্থন করে, যা পূর্বাভাসিত লেবেলে ইনপুট টোকেনের একটি ক্রম প্রভাব ব্যাখ্যা করে। সিকোয়েন্স স্যালিয়েন্স এই পদ্ধতিগুলিকে টেক্সট-টু-টেক্সট জেনারেটিভ মডেলগুলিতে সাধারণীকরণ করে এবং জেনারেটেড টোকেনের উপর পূর্ববর্তী টোকেনের প্রভাব ব্যাখ্যা করে।
সিকোয়েন্স স্যালিয়েন্সের জন্য আপনি এখানে গ্র্যাড L2 নর্ম পদ্ধতি ব্যবহার করবেন, যা মডেলের গ্রেডিয়েন্ট বিশ্লেষণ করে এবং আউটপুটের উপর পূর্ববর্তী প্রতিটি টোকেনের প্রভাবের পরিমাণ প্রদান করে। এই পদ্ধতিটি সহজ এবং দক্ষ, এবং শ্রেণীবিভাগ এবং অন্যান্য সেটিংসে এটি ভালোভাবে কাজ করে বলে প্রমাণিত হয়েছে। স্যালিয়েন্স স্কোর যত বেশি হবে, প্রভাব তত বেশি হবে। এই পদ্ধতিটি LIT-এর মধ্যে ব্যবহৃত হয় কারণ এটি ব্যাখ্যাযোগ্যতা গবেষণা সম্প্রদায় জুড়ে সুপরিচিত এবং ব্যাপকভাবে ব্যবহৃত হয়।
আরও উন্নত গ্রেডিয়েন্ট-ভিত্তিক স্যালিয়েন্স পদ্ধতির মধ্যে রয়েছে গ্র্যাড ⋅ ইনপুট এবং ইন্টিগ্রেটেড গ্রেডিয়েন্ট । এছাড়াও অ্যাবলেশন-ভিত্তিক পদ্ধতি উপলব্ধ রয়েছে, যেমন LIME এবং SHAP , যা আরও শক্তিশালী হতে পারে কিন্তু গণনা করা উল্লেখযোগ্যভাবে বেশি ব্যয়বহুল। বিভিন্ন স্যালিয়েন্স পদ্ধতির বিস্তারিত তুলনার জন্য এই নিবন্ধটি পড়ুন।
স্যালিয়েন্স পদ্ধতির বিজ্ঞান সম্পর্কে আপনি এই ভূমিকামূলক ইন্টারেক্টিভ এক্সপ্লোরেবল টু স্যালিয়েন্সে আরও জানতে পারবেন।
৩. আমদানি, পরিবেশ এবং অন্যান্য সেটআপ কোড
নতুন Colab- এ এই কোডল্যাবটি অনুসরণ করাই ভালো। আমরা একটি অ্যাক্সিলারেটর রানটাইম ব্যবহার করার পরামর্শ দিচ্ছি, যেহেতু আপনি মেমোরিতে একটি মডেল লোড করবেন, তবে মনে রাখবেন যে অ্যাক্সিলারেটরের বিকল্পগুলি সময়ের সাথে সাথে পরিবর্তিত হয় এবং সীমাবদ্ধতার সাপেক্ষে । আপনি যদি আরও শক্তিশালী অ্যাক্সিলারেটর অ্যাক্সেস করতে চান তবে Colab পেইড সাবস্ক্রিপশন অফার করে। বিকল্পভাবে, যদি আপনার মেশিনে উপযুক্ত GPU থাকে তবে আপনি একটি স্থানীয় রানটাইম ব্যবহার করতে পারেন।
দ্রষ্টব্য: আপনি ফর্মের কিছু সতর্কতা দেখতে পারেন
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
এগুলো উপেক্ষা করা নিরাপদ।
LIT এবং Keras NLP ইনস্টল করুন
এই কোডল্যাবের জন্য, আপনার keras (3) keras-nlp (0.14.) এবং lit-nlp (1.2) এর একটি সাম্প্রতিক সংস্করণ এবং বেস মডেলটি ডাউনলোড করার জন্য একটি Kaggle অ্যাকাউন্টের প্রয়োজন হবে।
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
কাগল অ্যাক্সেস
Kaggle দিয়ে প্রমাণীকরণ করতে, আপনি যে কোনও একটি করতে পারেন:
- আপনার শংসাপত্রগুলি একটি ফাইলে সংরক্ষণ করুন, যেমন
~/.kaggle/kaggle.json; -
KAGGLE_USERNAMEএবংKAGGLE_KEYপরিবেশ ভেরিয়েবল ব্যবহার করুন; অথবা - গুগল কোল্যাবের মতো একটি ইন্টারেক্টিভ পাইথন পরিবেশে নিম্নলিখিতটি চালান।
import kagglehub
kagglehub.login()
আরও বিস্তারিত জানার জন্য kagglehub ডকুমেন্টেশন দেখুন, এবং Gemma লাইসেন্স চুক্তি গ্রহণ করতে ভুলবেন না।
কেরাস কনফিগার করা হচ্ছে
Keras 3 একাধিক ডিপ লার্নিং ব্যাকএন্ড সমর্থন করে, যার মধ্যে রয়েছে Tensorflow (ডিফল্ট), PyTorch, এবং JAX। ব্যাকএন্ডটি KERAS_BACKEND এনভায়রনমেন্ট ভেরিয়েবল ব্যবহার করে কনফিগার করা হয়েছে, যা Keras লাইব্রেরি আমদানি করার আগে সেট করতে হবে। নিম্নলিখিত কোড স্নিপেটটি আপনাকে দেখায় কিভাবে একটি ইন্টারেক্টিভ পাইথন পরিবেশে এই ভেরিয়েবল সেট করতে হয়।
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
৪. এলআইটি স্থাপন করা
LIT পাইথন নোটবুকগুলিতে অথবা ওয়েব সার্ভারের মাধ্যমে ব্যবহার করা যেতে পারে। এই কোডল্যাবটি নোটবুক ব্যবহারের ক্ষেত্রে ফোকাস করে, আমরা কি গুগল কোলাবে অনুসরণ করার পরামর্শ দিতে পারি?
এই কোডল্যাবে, আপনি KerasNLP প্রিসেট ব্যবহার করে Gemma v2 2B IT লোড করবেন। নিম্নলিখিত স্নিপেটটি Gemma কে আরম্ভ করে এবং একটি LIT নোটবুক উইজেটে একটি উদাহরণ ডেটাসেট লোড করে।
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
দুটি প্রয়োজনীয় অবস্থানগত আর্গুমেন্টে পাস করা মান দুটি পরিবর্তন করে আপনি উইজেটটি কনফিগার করতে পারেন:
-
datasets_config: "dataset:path" হিসেবে লোড করার জন্য ডেটাসেটের নাম এবং পাথ ধারণকারী স্ট্রিংগুলির একটি তালিকা, যেখানে পাথ একটি URL অথবা একটি স্থানীয় ফাইল পাথ হতে পারে। নীচের উদাহরণটি LIT বিতরণে প্রদত্ত উদাহরণ প্রম্পটগুলি লোড করার জন্য বিশেষ মান,sample_promptsব্যবহার করে। -
models_config: লোড করার জন্য মডেলের নাম এবং পাথ সম্বলিত স্ট্রিংগুলির একটি তালিকা, "model:path" হিসাবে, যেখানে পাথ একটি URL, একটি স্থানীয় ফাইল পাথ, অথবা কনফিগার করা গভীর শিক্ষা কাঠামোর জন্য একটি প্রিসেটের নাম হতে পারে।
আপনার আগ্রহের মডেলটি ব্যবহার করার জন্য LIT কনফিগার করার পরে, আপনার নোটবুকে উইজেটটি রেন্ডার করতে নিম্নলিখিত কোড স্নিপেটটি চালান।
lit_widget.render(open_in_new_tab=True)
আপনার নিজস্ব ডেটা ব্যবহার করা
টেক্সট-টু-টেক্সট জেনারেটিভ মডেল হিসেবে, জেমা টেক্সট ইনপুট নেয় এবং টেক্সট আউটপুট তৈরি করে। লোড করা ডেটাসেটের কাঠামো মডেল মডেলগুলিতে যোগাযোগ করার জন্য LIT একটি মতামতযুক্ত API ব্যবহার করে। LIT-তে LLM গুলি দুটি ক্ষেত্র প্রদানকারী ডেটাসেটের সাথে কাজ করার জন্য ডিজাইন করা হয়েছে:
-
prompt: যে মডেল থেকে টেক্সট তৈরি করা হবে তার ইনপুট; এবং -
target: একটি ঐচ্ছিক লক্ষ্য ক্রম, যেমন মানব রেটারদের কাছ থেকে "স্থল সত্য" প্রতিক্রিয়া অথবা অন্য মডেল থেকে পূর্ব-উত্পন্ন প্রতিক্রিয়া।
LIT-তে sample_prompts এর একটি ছোট সেট রয়েছে, যার উদাহরণ নিম্নলিখিত উৎস থেকে পাওয়া যায় যা এই কোডল্যাব এবং LIT-এর বর্ধিত প্রম্পট ডিবাগিং টিউটোরিয়ালকে সমর্থন করে।
- GSM8K : কয়েকটি শট উদাহরণ দিয়ে গ্রেড স্কুলের গণিত সমস্যা সমাধান করা।
- গিগাওয়ার্ড বেঞ্চমার্ক : ছোট নিবন্ধের সংগ্রহের জন্য শিরোনাম তৈরি।
- সাংবিধানিক প্রণোদনা : নির্দেশিকা/সীমানা সহ বস্তুগুলি কীভাবে ব্যবহার করতে হয় সে সম্পর্কে নতুন ধারণা তৈরি করা।
আপনি সহজেই আপনার নিজস্ব ডেটা লোড করতে পারেন, হয় .jsonl ফাইল হিসেবে যাতে ফিল্ড prompt এবং ঐচ্ছিকভাবে target ( উদাহরণস্বরূপ ) সহ রেকর্ড থাকে, অথবা LIT এর ডেটাসেট API ব্যবহার করে যেকোনো ফর্ম্যাট থেকে।
নমুনা প্রম্পট লোড করতে নিচের সেলটি চালান।
৫. LIT-তে জেমার জন্য কয়েকটি শট প্রম্পট বিশ্লেষণ করা
আজ, প্রম্পটিং যতটা বিজ্ঞান, ততটাই শিল্প, এবং LIT আপনাকে জেমার মতো বৃহৎ ভাষা মডেলের জন্য প্রম্পট উন্নত করতে অভিজ্ঞতাগতভাবে সাহায্য করতে পারে। সামনে, আপনি জেমার আচরণ অন্বেষণ করতে, সম্ভাব্য সমস্যাগুলি পূর্বাভাস দিতে এবং এর নিরাপত্তা উন্নত করতে LIT কীভাবে ব্যবহার করা যেতে পারে তার একটি উদাহরণ দেখতে পাবেন।
জটিল প্রম্পটে ত্রুটি চিহ্নিত করুন
উচ্চমানের LLM-ভিত্তিক প্রোটোটাইপ এবং অ্যাপ্লিকেশনের জন্য দুটি গুরুত্বপূর্ণ প্রম্পটিং কৌশল হল কয়েক-শট প্রম্পটিং (প্রম্পটে পছন্দসই আচরণের উদাহরণ সহ) এবং চেইন-অফ-থট (LLM-এর চূড়ান্ত আউটপুটের আগে ব্যাখ্যা বা যুক্তির একটি ফর্ম সহ)। কিন্তু একটি কার্যকর প্রম্পট তৈরি করা প্রায়শই এখনও চ্যালেঞ্জিং।
কারো রুচির উপর ভিত্তি করে খাবার পছন্দ হবে কিনা তা নির্ধারণে সাহায্য করার একটি উদাহরণ বিবেচনা করুন। একটি প্রাথমিক প্রোটোটাইপ চেইন-অফ-থট প্রম্পট-টেমপ্লেট এইরকম দেখতে হতে পারে:
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
এই প্রম্পটের সমস্যাগুলো কি আপনি লক্ষ্য করেছেন? LIT আপনাকে LM Salience মডিউলের সাহায্যে প্রম্পটটি পরীক্ষা করতে সাহায্য করবে।
৬. ডিবাগিংয়ের জন্য সিকোয়েন্স স্যালিয়েন্স ব্যবহার করুন
স্যালিয়েন্স সম্ভাব্য ক্ষুদ্রতম স্তরে (অর্থাৎ, প্রতিটি ইনপুট টোকেনের জন্য) গণনা করা হয়, কিন্তু LIT টোকেন-স্যালিয়েন্সিকে আরও ব্যাখ্যাযোগ্য বৃহত্তর স্প্যানে একত্রিত করতে পারে, যেমন লাইন, বাক্য বা শব্দ। স্যালিয়েন্সি সম্পর্কে আরও জানুন এবং আমাদের স্যালিয়েন্সি এক্সপ্লোরেবলে অনিচ্ছাকৃত পক্ষপাত সনাক্ত করতে এটি কীভাবে ব্যবহার করবেন তা জানুন।
প্রম্পট-টেমপ্লেট ভেরিয়েবলের জন্য প্রম্পটকে একটি নতুন উদাহরণ ইনপুট দিয়ে শুরু করা যাক:
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
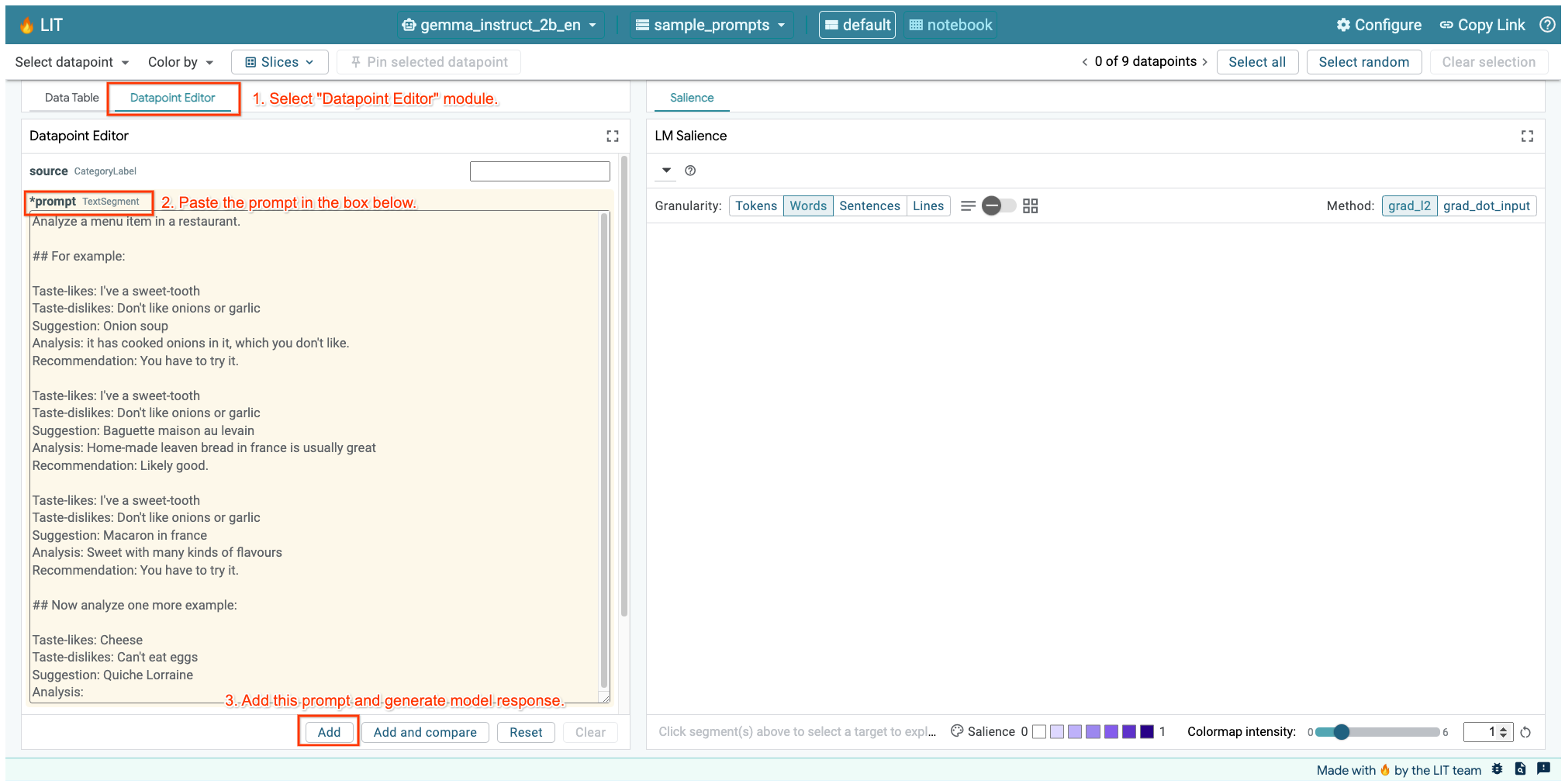
যদি আপনার LIT UI উপরের সেলে অথবা আলাদা ট্যাবে খোলা থাকে, তাহলে আপনি LIT এর Datapoint Editor ব্যবহার করে এই প্রম্পটটি যোগ করতে পারেন:
আরেকটি উপায় হল আগ্রহের প্রম্পট দিয়ে সরাসরি উইজেটটি পুনরায় রেন্ডার করা:
lit_widget.render(data=[fewshot_mistake_example])
মডেলটির আশ্চর্যজনক সমাপ্তি লক্ষ্য করুন:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
মডেল কেন তোমাকে এমন কিছু খেতে বলছে যা তুমি স্পষ্টভাবে বলেছিলে যে তুমি খেতে পারবে না?
সিকোয়েন্স স্যালিয়েন্স মূল সমস্যাটি তুলে ধরতে সাহায্য করতে পারে, যা আমাদের কয়েকটি-শট উদাহরণে রয়েছে। প্রথম উদাহরণে, বিশ্লেষণ বিভাগে চিন্তাভাবনার শৃঙ্খল যুক্তিতে it has cooked onions in it, which you don't like চূড়ান্ত সুপারিশের সাথে মেলে না। You have to try it ।
LM Salience মডিউলে, "Sentences" নির্বাচন করুন এবং তারপর সুপারিশ লাইনটি নির্বাচন করুন। UI এখন নিম্নরূপ দেখাবে:
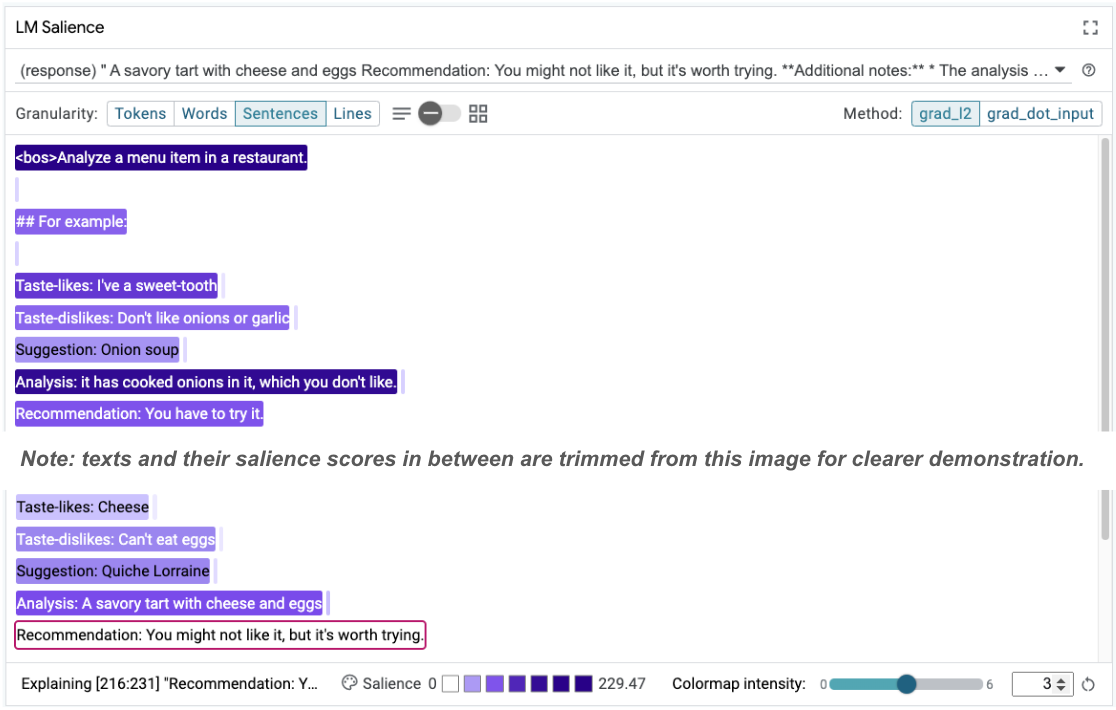
এটি একটি মানবিক ত্রুটি তুলে ধরে: সুপারিশ অংশটির একটি দুর্ঘটনাক্রমে কপি এবং পেস্ট এবং এটি আপডেট করতে ব্যর্থতা!
এবার প্রথম উদাহরণে "Recommendation" সংশোধন করে Avoid , এবং আবার চেষ্টা করুন। LIT-এর নমুনা প্রম্পটে এই উদাহরণটি আগে থেকে লোড করা আছে, তাই আপনি এটি পেতে এই ছোট ইউটিলিটি ফাংশনটি ব্যবহার করতে পারেন:
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
এখন মডেলের সমাপ্তি হল:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
এ থেকে একটি গুরুত্বপূর্ণ শিক্ষা হল: প্রাথমিক প্রোটোটাইপিং এমন ঝুঁকিগুলি প্রকাশ করতে সাহায্য করে যা আপনি আগে থেকে ভাবতেও পারবেন না , এবং ভাষা মডেলগুলির ত্রুটি-প্রবণ প্রকৃতির অর্থ হল ত্রুটির জন্য সক্রিয়ভাবে ডিজাইন করতে হবে। এআই দিয়ে ডিজাইন করার জন্য আমাদের পিপল + এআই গাইডবুক- এ এই বিষয়ে আরও আলোচনা পাওয়া যাবে।
যদিও সংশোধিত কিছু শট প্রম্পটটি আরও ভালো, তবুও এটি পুরোপুরি সঠিক নয়: এটি ব্যবহারকারীকে সঠিকভাবে ডিম এড়াতে বলে, কিন্তু যুক্তিটি সঠিক নয়, এটি বলে যে তারা ডিম পছন্দ করে না, যখন আসলে ব্যবহারকারী বলেছেন যে তারা ডিম খেতে পারবেন না। পরবর্তী বিভাগে, আপনি কীভাবে আরও ভালো করতে পারেন তা দেখতে পাবেন।
৭. মডেল আচরণ উন্নত করার জন্য অনুমান পরীক্ষা করুন
LIT আপনাকে একই ইন্টারফেসের মধ্যে প্রম্পটে পরিবর্তন পরীক্ষা করতে সক্ষম করে। এই ক্ষেত্রে, আপনি মডেলের আচরণ উন্নত করার জন্য একটি সংবিধান যোগ করার পরীক্ষা করতে যাচ্ছেন। সংবিধান বলতে মডেলের প্রজন্মকে পরিচালনা করতে সাহায্য করার জন্য নীতিমালা সহ নকশা প্রম্পটগুলিকে বোঝায়। সাম্প্রতিক পদ্ধতিগুলি এমনকি সাংবিধানিক নীতিগুলির ইন্টারেক্টিভ ডেরিভেশন সক্ষম করে।
প্রম্পটটিকে আরও উন্নত করতে এই ধারণাটি ব্যবহার করা যাক। আমাদের প্রম্পটের উপরে জেনারেশনের নীতিগুলি সহ একটি বিভাগ যুক্ত করুন, যা এখন নিম্নরূপ শুরু হয়:
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
এই আপডেটের মাধ্যমে, উদাহরণটি পুনরায় চালানো যেতে পারে এবং একটি খুব ভিন্ন আউটপুট পর্যবেক্ষণ করা যেতে পারে:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
এই পরিবর্তন কেন ঘটছে তা বোঝার জন্য প্রম্পট স্যালিয়েন্সটি পুনরায় পরীক্ষা করা যেতে পারে:
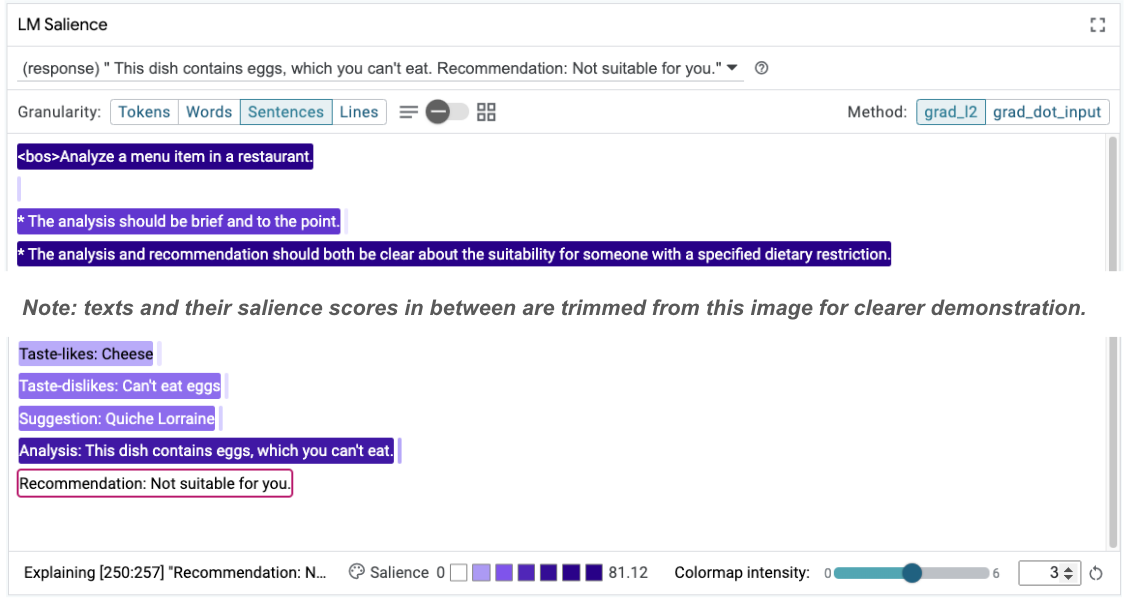
লক্ষ্য করুন যে সুপারিশটি অনেক বেশি নিরাপদ। তদুপরি, "আপনার জন্য উপযুক্ত নয়" নীতিটি খাদ্যতালিকাগত সীমাবদ্ধতা অনুসারে উপযুক্ততা স্পষ্টভাবে উল্লেখ করার নীতি দ্বারা প্রভাবিত হয়, সেই সাথে বিশ্লেষণ (তথাকথিত চিন্তার শৃঙ্খল)। এটি অতিরিক্ত আত্মবিশ্বাস তৈরি করতে সাহায্য করে যে ফলাফল সঠিক কারণেই ঘটছে।
৮. মডেল অনুসন্ধান এবং অনুসন্ধানে অ-প্রযুক্তিগত দলগুলিকে অন্তর্ভুক্ত করুন
ব্যাখ্যাযোগ্যতা বলতে বোঝায় একটি দলগত প্রচেষ্টা, যা XAI, নীতি, আইনি এবং আরও অনেক কিছুতে দক্ষতা বিস্তৃত করে।
প্রাথমিক উন্নয়ন পর্যায়ে মডেলগুলির সাথে মিথস্ক্রিয়া করার জন্য ঐতিহ্যগতভাবে উল্লেখযোগ্য প্রযুক্তিগত দক্ষতার প্রয়োজন ছিল, যা কিছু সহযোগীদের জন্য সেগুলি অ্যাক্সেস করা এবং অনুসন্ধান করা আরও কঠিন করে তুলেছিল। ঐতিহাসিকভাবে এই দলগুলিকে প্রাথমিক প্রোটোটাইপিং পর্যায়ে অংশগ্রহণ করতে সক্ষম করার জন্য টুলিং বিদ্যমান ছিল না।
LIT-এর মাধ্যমে, আশা করা যায় যে এই দৃষ্টান্তটি পরিবর্তন হতে পারে। আপনি যেমনটি এই কোডল্যাবের মাধ্যমে দেখেছেন, LIT-এর ভিজ্যুয়াল মাধ্যম এবং সালিসিটি পরীক্ষা করার এবং উদাহরণ অন্বেষণ করার ইন্টারেক্টিভ ক্ষমতা বিভিন্ন স্টেকহোল্ডারদের ফলাফল ভাগ করে নিতে এবং যোগাযোগ করতে সাহায্য করতে পারে। এটি আপনাকে মডেল অন্বেষণ, অনুসন্ধান এবং ডিবাগিংয়ের জন্য সতীর্থদের একটি বিস্তৃত বৈচিত্র্য আনতে সক্ষম করতে পারে। এই প্রযুক্তিগত পদ্ধতিগুলির সাথে তাদের পরিচিত করা মডেলগুলি কীভাবে কাজ করে সে সম্পর্কে তাদের বোধগম্যতা বৃদ্ধি করতে পারে। এছাড়াও, প্রাথমিক মডেল পরীক্ষায় আরও বৈচিত্র্যময় দক্ষতা অবাঞ্ছিত ফলাফলগুলি আবিষ্কার করতেও সহায়তা করতে পারে যা উন্নত করা যেতে পারে।
9. সংক্ষিপ্তসার
সংক্ষেপে বলতে গেলে:
- LIT UI ইন্টারেক্টিভ মডেল এক্সিকিউশনের জন্য একটি ইন্টারফেস প্রদান করে, যা ব্যবহারকারীদের সরাসরি আউটপুট তৈরি করতে এবং "কি হলে" পরিস্থিতি পরীক্ষা করতে সক্ষম করে। এটি বিভিন্ন প্রম্পট ভেরিয়েশন পরীক্ষা করার জন্য বিশেষভাবে কার্যকর।
- LM স্যালিয়েন্স মডিউল স্যালিয়েন্সের একটি ভিজ্যুয়াল উপস্থাপনা প্রদান করে এবং নিয়ন্ত্রণযোগ্য ডেটা গ্র্যানুলারিটি প্রদান করে যাতে আপনি মডেল-কেন্দ্রিক নির্মাণ (যেমন, টোকেন) এর পরিবর্তে মানব-কেন্দ্রিক নির্মাণ (যেমন, বাক্য এবং শব্দ) সম্পর্কে যোগাযোগ করতে পারেন।
যখন আপনি আপনার মডেল মূল্যায়নে সমস্যাযুক্ত উদাহরণ খুঁজে পান, তখন ডিবাগিংয়ের জন্য সেগুলিকে LIT-তে আনুন। মডেলিং টাস্কের সাথে যৌক্তিকভাবে সম্পর্কিত সবচেয়ে বড় সংবেদনশীল কন্টেন্ট ইউনিট বিশ্লেষণ করে শুরু করুন, ভিজ্যুয়ালাইজেশন ব্যবহার করে দেখুন যে মডেলটি প্রম্পট কন্টেন্টে সঠিকভাবে বা ভুলভাবে কোথায় মনোযোগ দিচ্ছে, এবং তারপরে সম্ভাব্য সমাধানগুলি সনাক্ত করার জন্য আপনি যে ভুল আচরণ দেখছেন তা আরও বর্ণনা করার জন্য কন্টেন্টের ছোট ইউনিটগুলিতে ড্রিল করুন।
পরিশেষে: লিট ক্রমাগত উন্নতি করছে! আমাদের বৈশিষ্ট্যগুলি সম্পর্কে আরও জানুন এবং আপনার পরামর্শ এখানে শেয়ার করুন।