
1. Introducción
Los productos de IA generativa son relativamente nuevos, y el comportamiento de una aplicación puede variar más que en las formas anteriores de software. Por lo tanto, es importante sondear los modelos de aprendizaje automático que se utilizan, examinar ejemplos del comportamiento del modelo y analizar las sorpresas.
La herramienta de interpretabilidad de aprendizaje (LIT; sitio web, GitHub) es una plataforma para depurar y analizar modelos de AA con el objetivo de comprender por qué y cómo se comportan de la manera en que lo hacen.
En este codelab, aprenderás a usar LIT para aprovechar al máximo el modelo Gemma de Google. En este codelab, se muestra cómo usar la prominencia de secuencia, una técnica de interpretabilidad, para analizar diferentes enfoques de ingeniería de instrucciones.
Objetivos de aprendizaje:
- Comprender la prominencia de la secuencia y sus usos en el análisis de modelos
- Configuración de LIT para que Gemma calcule los resultados de las instrucciones y la relevancia de la secuencia.
- Usar la relevancia de la secuencia a través del módulo LM Salience para comprender el impacto de los diseños de instrucciones en los resultados del modelo
- Probar las mejoras hipotéticas en las instrucciones en LIT y observar su impacto
Nota: Este codelab usa la implementación de KerasNLP de Gemma y TensorFlow v2 para el backend. Se recomienda usar un kernel de GPU para seguir el ejemplo.
2. Importancia de la secuencia y sus usos en el análisis de modelos
Los modelos generativos de texto a texto, como Gemma, toman una secuencia de entrada en forma de texto tokenizado y generan tokens nuevos que suelen ser continuaciones o complementos típicos de esa entrada. Esta generación se realiza un token a la vez, y se agrega (en un bucle) cada token generado recientemente a la entrada, además de las generaciones anteriores, hasta que el modelo alcanza una condición de detención. Por ejemplo, cuando el modelo genera un token de fin de secuencia (EOS) o alcanza la longitud máxima predefinida.
Los métodos de prominencia son una clase de técnicas de IA explicable (XAI) que pueden indicarte qué partes de una entrada son importantes para el modelo en diferentes partes de su salida. La LIT admite métodos de prominencia para una variedad de tareas de clasificación, que explican el impacto de una secuencia de tokens de entrada en la etiqueta predicha. La relevancia de la secuencia generaliza estos métodos para los modelos generativos de texto a texto y explica el impacto de los tokens precedentes en los tokens generados.
Aquí usarás el método Grad L2 Norm para la relevancia de la secuencia, que analiza los gradientes del modelo y proporciona una magnitud de la influencia que cada token anterior tiene en el resultado. Este método es simple y eficiente, y se demostró que funciona bien en la clasificación y otros parámetros de configuración. Cuanto mayor sea la puntuación de importancia, mayor será la influencia. Este método se usa en LIT porque se comprende bien y se utiliza ampliamente en la comunidad de investigación de interpretabilidad.
Entre los métodos de relevancia basados en gradientes más avanzados, se incluyen Grad ⋅ Input y los gradientes integrados. También hay métodos basados en la ablación disponibles, como LIME y SHAP, que pueden ser más sólidos, pero mucho más costosos de calcular. Consulta este artículo para obtener una comparación detallada de los diferentes métodos de prominencia.
Puedes obtener más información sobre la ciencia de los métodos de prominencia en esta explicación interactiva introductoria sobre la prominencia.
3. Importaciones, entorno y otro código de configuración
Lo mejor es seguir este codelab en Colab nuevo. Te recomendamos que uses un tiempo de ejecución del acelerador, ya que cargarás un modelo en la memoria, pero ten en cuenta que las opciones del acelerador varían con el tiempo y están sujetas a limitaciones. Colab ofrece suscripciones pagadas si quieres acceder a aceleradores más potentes. Como alternativa, puedes usar un tiempo de ejecución local si tu máquina tiene una GPU adecuada.
Nota: Es posible que veas algunas advertencias con el siguiente formato
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
Puedes ignorarlos sin problemas.
Instala LIT y Keras NLP
Para este codelab, necesitarás una versión reciente de keras (3) keras-nlp (0.14) y lit-nlp (1.2), y una cuenta de Kaggle para descargar el modelo base.
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
Acceso a Kaggle
Para autenticarte con Kaggle, puedes hacer lo siguiente:
- Almacena tus credenciales en un archivo, como
~/.kaggle/kaggle.json. - Usa las variables de entorno
KAGGLE_USERNAMEyKAGGLE_KEY. - Ejecuta lo siguiente en un entorno interactivo de Python, como Google Colab.
import kagglehub
kagglehub.login()
Consulta la documentación de kagglehub para obtener más detalles y asegúrate de aceptar el acuerdo de licencia de Gemma.
Configuración de Keras
Keras 3 admite varios backends de aprendizaje profundo, incluidos TensorFlow (predeterminado), PyTorch y JAX. El backend se configura con la variable de entorno KERAS_BACKEND, que se debe establecer antes de importar la biblioteca de Keras. En el siguiente fragmento de código, se muestra cómo configurar esta variable en un entorno interactivo de Python.
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
4. Cómo configurar el LIT
LIT se puede usar en notebooks de Python o a través de un servidor web. Este codelab se enfoca en el caso de uso de Notebook, por lo que recomendamos seguirlo en Google Colab.
En este codelab, cargarás Gemma v2 2B IT con el ajuste predeterminado de KerasNLP. En el siguiente fragmento, se inicializa Gemma y se carga un conjunto de datos de ejemplo en un widget de notebook de LIT.
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
Puedes configurar el widget cambiando los valores que se pasan a los dos argumentos posicionales obligatorios:
datasets_config: Es una lista de cadenas que contiene los nombres de los conjuntos de datos y las rutas de acceso desde las que se cargarán, como "dataset:path", donde la ruta de acceso puede ser una URL o una ruta de acceso a un archivo local. En el siguiente ejemplo, se usa el valor especialsample_promptspara cargar las instrucciones de ejemplo que se proporcionan en la distribución de LIT.models_config: Es una lista de cadenas que contiene los nombres de los modelos y las rutas de acceso desde las que se cargarán, como "modelo:ruta de acceso", en la que la ruta de acceso puede ser una URL, una ruta de acceso a un archivo local o el nombre de un parámetro predeterminado para el framework de aprendizaje profundo configurado.
Una vez que hayas configurado LIT para usar el modelo que te interesa, ejecuta el siguiente fragmento de código para renderizar el widget en tu notebook.
lit_widget.render(open_in_new_tab=True)
Usa tus propios datos
Como modelo generativo de texto a texto, Gemma toma texto como entrada y genera texto como salida. LIT usa una API con opiniones para comunicar la estructura de los conjuntos de datos cargados a los modelos. Los LLM en LIT están diseñados para trabajar con conjuntos de datos que proporcionan dos campos:
prompt: Es la entrada del modelo a partir de la cual se generará el texto.target: Es una secuencia objetivo opcional, como una respuesta de "verdad fundamental" de evaluadores humanos o una respuesta generada previamente por otro modelo.
LIT incluye un pequeño conjunto de sample_prompts con ejemplos de las siguientes fuentes que admiten este codelab y el instructivo de depuración de instrucciones extendidas de LIT.
- GSM8K: Resolución de problemas matemáticos de primaria con ejemplos de aprendizaje con pocos ejemplos.
- Gigaword Benchmark: Generación de títulos para una colección de artículos breves.
- Sugerencias constitucionales: Generar ideas nuevas sobre cómo usar objetos con lineamientos o límites
También puedes cargar fácilmente tus propios datos, ya sea como un archivo .jsonl que contenga registros con campos prompt y, opcionalmente, target (ejemplo), o desde cualquier formato con la API de Dataset de LIT.
Ejecuta la siguiente celda para cargar las instrucciones de ejemplo.
5. Cómo analizar instrucciones con pocos ejemplos para Gemma en LIT
Actualmente, la generación de instrucciones es tanto un arte como una ciencia, y LIT puede ayudarte a mejorar de forma empírica las instrucciones para los modelos de lenguaje grandes, como Gemma. A continuación, verás un ejemplo de cómo se puede usar LIT para explorar los comportamientos de Gemma, anticipar posibles problemas y mejorar su seguridad.
Identifica errores en instrucciones complejas
Dos de las técnicas de instrucción más importantes para los prototipos y las aplicaciones basadas en LLM de alta calidad son la instrucción con pocos ejemplos (que incluye ejemplos del comportamiento deseado en la instrucción) y la cadena de pensamientos (que incluye una forma de explicación o razonamiento antes del resultado final del LLM). Sin embargo, crear una instrucción eficaz suele ser un desafío.
Considera un ejemplo de cómo ayudar a alguien a evaluar si le gustará la comida según sus gustos. Una plantilla de instrucciones inicial de cadena de pensamiento para un prototipo podría verse de la siguiente manera:
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
¿Detectaste los problemas con esta instrucción? LIT te ayudará a examinar la instrucción con el módulo de prominencia del LM.
6. Usa la prominencia de la secuencia para la depuración
La prominencia se calcula en el nivel más pequeño posible (es decir, para cada token de entrada), pero LIT puede agregar la prominencia de los tokens en tramos más grandes y más interpretables, como líneas, oraciones o palabras. Obtén más información sobre la importancia y cómo usarla para identificar sesgos no intencionales en nuestro Explorador de importancia.
Comencemos por darle a la instrucción un nuevo ejemplo de entrada para las variables de la plantilla de instrucción:
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
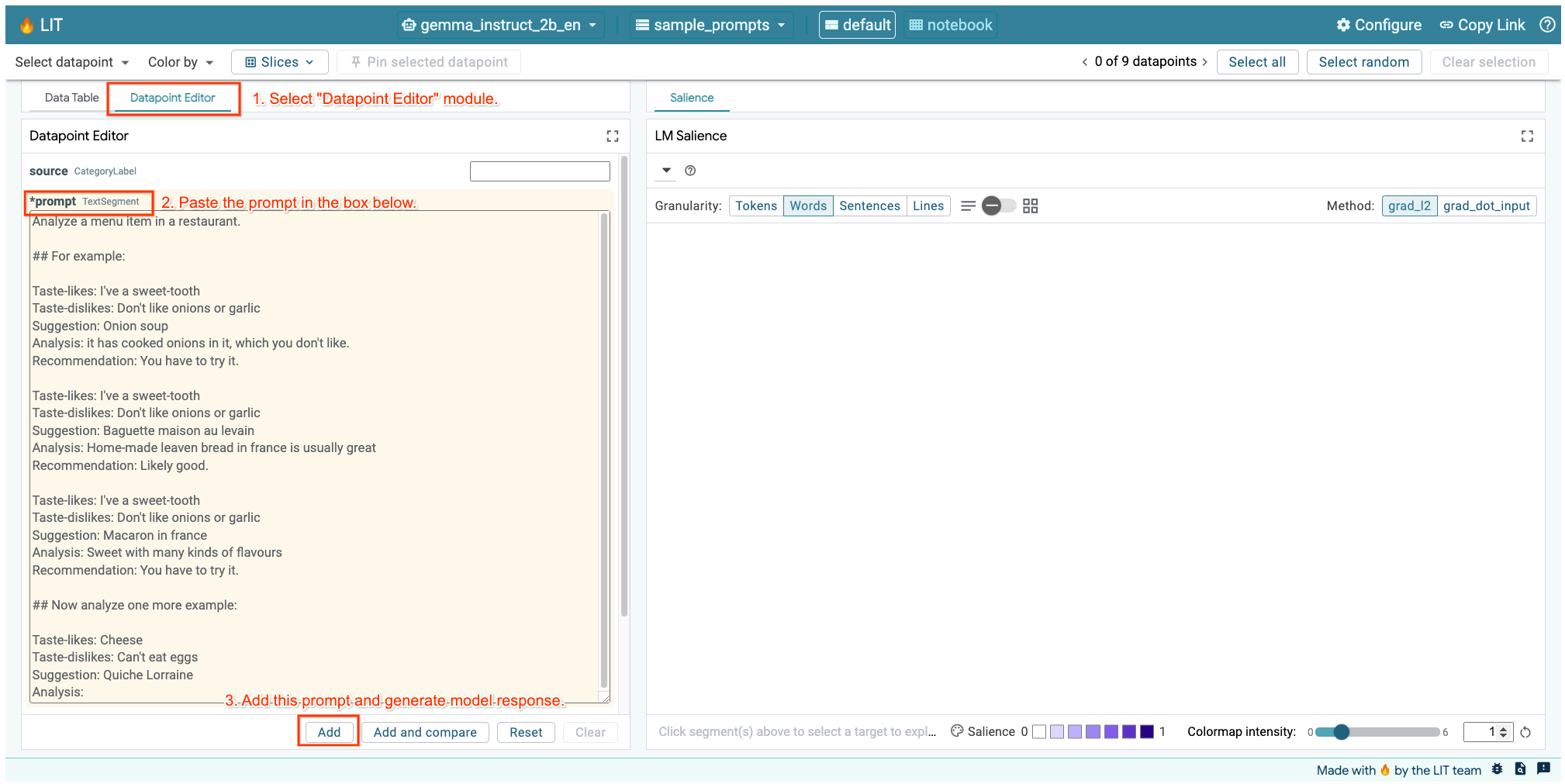
Si tienes abierta la IU de LIT en la celda anterior o en una pestaña separada, puedes usar el Editor de puntos de datos de LIT para agregar esta instrucción:
Otra forma es volver a renderizar el widget directamente con la instrucción de interés:
lit_widget.render(data=[fewshot_mistake_example])
Observa la sorprendente finalización del modelo:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
¿Por qué el modelo te sugiere que comas algo que claramente dijiste que no puedes comer?
La prominencia de la secuencia puede ayudar a destacar el problema raíz, que se encuentra en nuestros ejemplos de pocos disparos. En el primer ejemplo, el razonamiento de cadena de pensamiento en la sección de análisis it has cooked onions in it, which you don't like no coincide con la recomendación final You have to try it.
En el módulo de prominencia de LM, selecciona "Oraciones" y, luego, la línea de recomendación. Ahora, la IU debería verse de la siguiente manera:
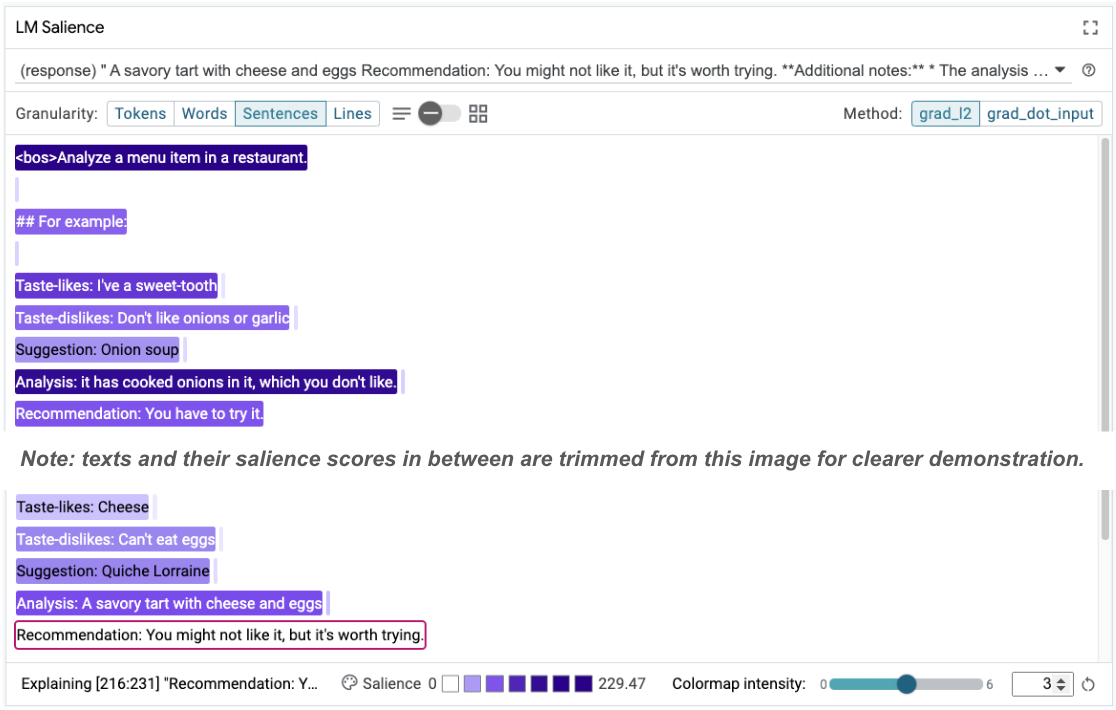
Esto destaca un error humano: se copió y pegó accidentalmente la parte de la recomendación y no se actualizó.
Ahora, corrijamos la "Recomendación" en el primer ejemplo a Avoid y volvamos a intentarlo. LIT tiene este ejemplo precargado en las instrucciones de ejemplo, por lo que puedes usar esta pequeña función de utilidad para obtenerlo:
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
Ahora, la finalización del modelo será la siguiente:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
Una lección importante que debes tener en cuenta es que la creación de prototipos anticipada ayuda a revelar riesgos que tal vez no consideres con anticipación, y la naturaleza propensa a errores de los modelos de lenguaje significa que se deben diseñar de forma proactiva para los errores. Puedes encontrar más información sobre este tema en nuestra guía sobre personas y la IA para diseñar con IA.
Si bien la instrucción corregida de pocos ejemplos es mejor, aún no es del todo correcta: le indica al usuario que evite los huevos, pero el razonamiento no es correcto, ya que dice que no le gustan los huevos, cuando, de hecho, el usuario indicó que no puede comerlos. En la siguiente sección, verás cómo puedes mejorar tu respuesta.
7. Prueba hipótesis para mejorar el comportamiento del modelo
LIT te permite probar cambios en las instrucciones dentro de la misma interfaz. En este caso, probarás agregar una constitución para mejorar el comportamiento del modelo. Las constituciones son instrucciones de diseño con principios que ayudan a guiar la generación del modelo. Los métodos recientes incluso permiten la derivación interactiva de principios constitucionales.
Usemos esta idea para mejorar aún más la instrucción. Agrega una sección con los principios de la generación en la parte superior de nuestra instrucción, que ahora comienza de la siguiente manera:
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
Con esta actualización, el ejemplo se puede volver a ejecutar y observar un resultado muy diferente:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
Luego, se puede volver a examinar la prominencia de la instrucción para comprender por qué se produce este cambio:
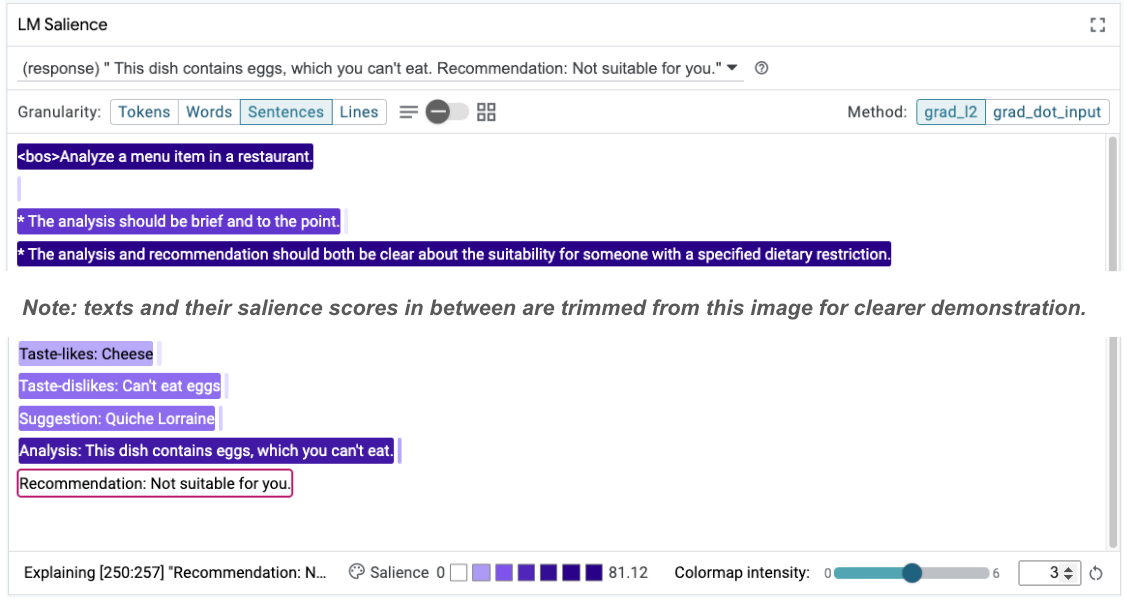
Observa que la recomendación es mucho más segura. Además, la opción "No apto para ti" se ve influenciada por el principio de indicar claramente la idoneidad según la restricción dietética, junto con el análisis (la llamada cadena de pensamiento). Esto ayuda a tener más confianza en que el resultado se produce por el motivo correcto.
8. Incluye a los equipos no técnicos en la exploración y el sondeo de modelos
La interpretabilidad debe ser un esfuerzo en equipo que abarque la experiencia en XAI, políticas, asuntos legales y mucho más.
Tradicionalmente, interactuar con modelos en las primeras etapas de desarrollo requería una gran experiencia técnica, lo que dificultaba que algunos colaboradores accedieran a ellos y los probaran. Históricamente, no existían herramientas que permitieran a estos equipos participar en las primeras fases de creación de prototipos.
A través de LIT, se espera que este paradigma pueda cambiar. Como viste en este codelab, el medio visual y la capacidad interactiva de LIT para examinar la prominencia y explorar ejemplos pueden ayudar a los diferentes stakeholders a compartir y comunicar los hallazgos. Esto te permite incorporar una mayor diversidad de compañeros de equipo para la exploración, el sondeo y la depuración de modelos. Exponerlos a estos métodos técnicos puede mejorar su comprensión de cómo funcionan los modelos. Además, un conjunto más diverso de conocimientos especializados en las pruebas iniciales del modelo también puede ayudar a descubrir resultados no deseados que se pueden mejorar.
9. Resumen
En resumen:
- La IU de LIT proporciona una interfaz para la ejecución interactiva de modelos, lo que permite a los usuarios generar resultados directamente y probar situaciones hipotéticas. Esto es particularmente útil para probar diferentes variaciones de instrucciones.
- El módulo de prominencia del LM proporciona una representación visual de la prominencia y ofrece una granularidad de datos controlable para que puedas comunicarte sobre constructos centrados en el ser humano (p.ej., oraciones y palabras) en lugar de constructos centrados en el modelo (p.ej., tokens).
Cuando encuentres ejemplos problemáticos en las evaluaciones de tu modelo, incorpóralos a LIT para depurarlos. Comienza por analizar la unidad de contenido más grande y lógica que se te ocurra y que se relacione con la tarea de modelado. Luego, usa las visualizaciones para ver dónde el modelo presta atención de forma correcta o incorrecta al contenido del mensaje y, luego, profundiza en unidades de contenido más pequeñas para describir mejor el comportamiento incorrecto que observas y, así, identificar posibles soluciones.
Por último, Lit mejora constantemente. Obtén más información sobre nuestras funciones y comparte tus sugerencias aquí.