
1. مقدمة
منتجات الذكاء الاصطناعي التوليدي جديدة نسبيًا، ويمكن أن تختلف سلوكيات التطبيق أكثر من أشكال البرامج السابقة. لهذا السبب، من المهم اختبار نماذج تعلُّم الآلة المستخدَمة، وفحص أمثلة على سلوك النموذج، والتحقيق في النتائج غير المتوقّعة.
Learning Interpretability Tool (LIT) (الموقع الإلكتروني، GitHub) هي منصة لتصحيح أخطاء نماذج تعلُّم الآلة وتحليلها من أجل فهم سبب سلوكها وطريقة عملها.
في هذا الدرس التطبيقي حول الترميز، ستتعرّف على كيفية استخدام LIT للاستفادة بشكل أكبر من نموذج Gemma من Google. يوضّح هذا الدرس التطبيقي حول الترميز كيفية استخدام أهمية التسلسل، وهي إحدى تقنيات القابلية للتفسير، لتحليل طرق مختلفة لهندسة الطلبات.
أهداف التعلُّم:
- فهم أهمية التسلسل واستخداماته في تحليل النماذج
- إعداد LIT لكي تحسب Gemma نواتج الطلبات وأهمية التسلسل
- استخدام أهمية التسلسل من خلال وحدة أهمية النموذج اللغوي لفهم تأثير تصاميم الطلبات على نتائج النموذج
- اختبار التحسينات المفترَضة على الطلبات في LIT والاطّلاع على تأثيرها
ملاحظة: يستخدم هذا الدرس التطبيقي حول الترميز تنفيذ KerasNLP لنموذج Gemma، وTensorFlow الإصدار 2 للواجهة الخلفية. يُنصح بشدة باستخدام نواة وحدة معالجة الرسومات للمتابعة.
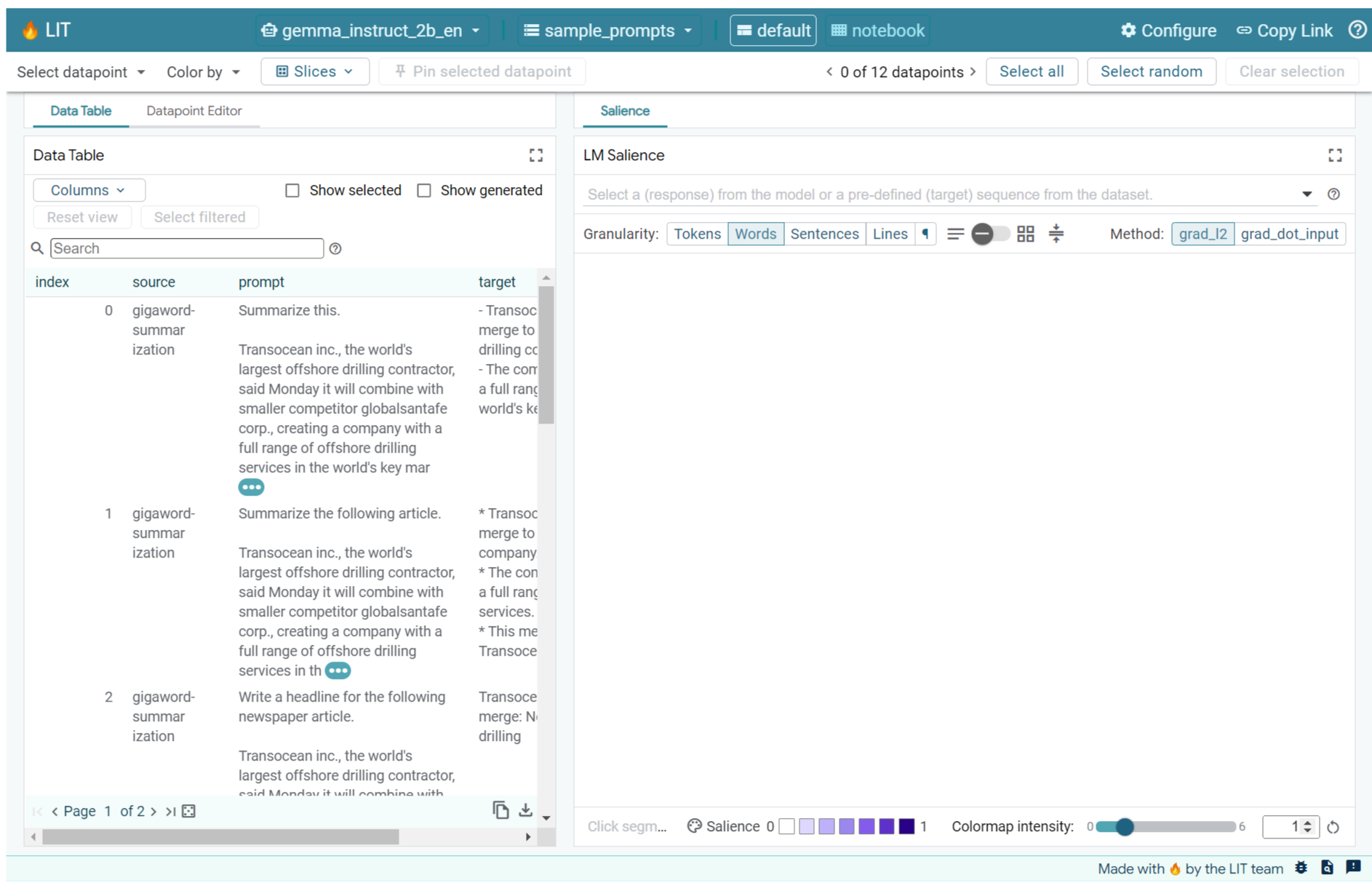
2. أهمية التسلسل واستخداماته في تحليل النماذج
تتلقّى النماذج التوليدية التي تحوّل النص إلى نص، مثل Gemma، تسلسلاً من الرموز المميزة كمدخل، ثم تنشئ رموزًا مميزة جديدة تكون عادةً عبارة عن متابعات أو عمليات إكمال لهذا المدخل. تحدث عملية الإنشاء هذه بمعدل رمز مميز واحد في كل مرة، حيث تتم إضافة كل رمز مميز تم إنشاؤه حديثًا إلى الإدخال بالإضافة إلى أي عمليات إنشاء سابقة (في حلقة) إلى أن يصل النموذج إلى شرط الإيقاف. وتشمل الأمثلة الحالات التي ينشئ فيها النموذج رمز نهاية التسلسل (EOS) أو يصل إلى الحد الأقصى المحدّد مسبقًا للطول.
طُرق تحديد الأهمية هي فئة من تقنيات الذكاء الاصطناعي القابل للتفسير (XAI) التي يمكن أن تخبرك بالأجزاء المهمة من الإدخال بالنسبة إلى النموذج في ما يتعلّق بأجزاء مختلفة من الناتج. تتيح أداة LIT طرق تحديد مدى أهمية الكلمات لمهام التصنيف المختلفة، ما يوضّح تأثير تسلسل الرموز المميزة للإدخال على التصنيف المتوقّع. تعمّم ميزة "أهمية التسلسل" هذه الطرق على النماذج التوليدية التي تتلقى طلبات وردود نصية، وتوضّح تأثير الرموز المميزة السابقة على الرموز المميزة التي تم إنشاؤها.
ستستخدم هنا طريقة Grad L2 Norm لتحديد مدى أهمية التسلسل، وهي تحلّل تدرّجات النموذج وتقدّم مقدار التأثير الذي يحدثه كل رمز مميّز سابق في الناتج. هذه الطريقة بسيطة وفعّالة، وقد ثبت أنّها تؤدي أداءً جيدًا في التصنيف والإعدادات الأخرى. وكلما زادت درجة بروز الكيان، زاد تأثيره. يتم استخدام هذه الطريقة ضمن LIT لأنّها مفهومة جيدًا ويتم استخدامها على نطاق واسع في أوساط الباحثين في مجال قابلية التفسير.
تشمل طرق تحديد الأهمية المستندة إلى التدرّج الأكثر تقدّمًا Grad ⋅ Input والتدرّجات المتكاملة. تتوفّر أيضًا طرق تستند إلى الاستئصال، مثل LIME وSHAP، والتي يمكن أن تكون أكثر فعالية ولكنّها تتطلّب تكلفة أعلى بكثير من حيث الحساب. يمكنك الرجوع إلى هذه المقالة للاطّلاع على مقارنة تفصيلية بين طرق تحديد درجة الأهمية المختلفة.
يمكنك الاطّلاع على مزيد من المعلومات حول علم طرق التميّز في هذا الشرح التفاعلي التمهيدي حول التميّز.
3- عمليات الاستيراد والبيئة ورمز الإعداد الآخر
من الأفضل اتّباع الخطوات الواردة في هذا الدرس التطبيقي حول الترميز باستخدام Colab الجديد. ننصحك باستخدام وقت تشغيل مسرِّع، لأنّك ستحمّل نموذجًا في الذاكرة، ولكن يجب الانتباه إلى أنّ خيارات المسرِّع تتغيّر بمرور الوقت وتخضع لقيود. يوفّر Colab اشتراكات مدفوعة إذا أردت الوصول إلى مسرّعات أكثر فعالية. بدلاً من ذلك، يمكنك استخدام بيئة تشغيل محلية إذا كان جهازك يتضمّن وحدة معالجة رسومات مناسبة.
ملاحظة: قد تظهر لك بعض التحذيرات من النموذج
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
يمكنك تجاهل هذه الرسائل.
تثبيت LIT وKeras NLP
في هذا الدرس التطبيقي حول الترميز، ستحتاج إلى إصدار حديث من keras (3) وkeras-nlp (0.14.) وlit-nlp (1.2)، بالإضافة إلى حساب على Kaggle لتنزيل النموذج الأساسي.
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
الوصول إلى Kaggle
للمصادقة باستخدام Kaggle، يمكنك إجراء أحد الإجراءَين التاليَين:
- تخزين بيانات الاعتماد في ملف، مثل
~/.kaggle/kaggle.json - استخدِم متغيرَي البيئة
KAGGLE_USERNAMEوKAGGLE_KEY. - نفِّذ ما يلي في بيئة Python تفاعلية، مثل Google Colab.
import kagglehub
kagglehub.login()
لمزيد من التفاصيل، يُرجى الاطّلاع على مستندات kagglehub، ويُرجى التأكّد من قبول اتفاقية ترخيص Gemma.
إعداد Keras
يتوافق الإصدار 3 من Keras مع العديد من الخلفيات للتعليم المعمّق، بما في ذلك TensorFlow (الإعداد التلقائي) وPyTorch وJAX. يتم ضبط الخلفية باستخدام متغيّر البيئة KERAS_BACKEND، الذي يجب ضبطه قبل استيراد مكتبة Keras. يوضّح مقتطف الرمز التالي كيفية ضبط هذا المتغيّر في بيئة Python تفاعلية.
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
4. إعداد LIT
يمكن استخدام LIT في دفاتر ملاحظات Python أو من خلال خادم ويب. يركّز هذا الدرس التطبيقي حول الترميز على حالة الاستخدام "المفكرة"، ويمكننا أن ننصحك بتجربة الخطوات في Google Colab.
في هذا الدرس التطبيقي حول الترميز، سيتم تحميل Gemma v2 2B IT باستخدام الإعداد المُسبَق KerasNLP. تعمل المقتطفة التالية على تهيئة Gemma وتحميل مجموعة بيانات نموذجية في أداة LIT Notebook.
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
يمكنك ضبط الأداة عن طريق تغيير القيم التي يتم تمريرها إلى وسيطتَي الموضع المطلوبتَين:
-
datasets_config: قائمة سلاسل تحتوي على أسماء مجموعات البيانات ومسارات التحميل منها، مثل "مجموعة البيانات:المسار"، حيث يمكن أن يكون المسار عنوان URL أو مسار ملف محلي. يستخدم المثال أدناه القيمة الخاصةsample_promptsلتحميل أمثلة الطلبات المقدَّمة في حزمة LIT. models_config: قائمة سلاسل تحتوي على أسماء النماذج ومسارات التحميل منها، مثل "model:path"، حيث يمكن أن يكون المسار عنوان URL أو مسار ملف محلي أو اسم إعداد مُسبَق لإطار التعلّم العميق الذي تم إعداده.
بعد إعداد LIT لاستخدام النموذج الذي يهمّك، شغِّل مقتطف الرمز التالي لعرض الأداة في دفترك.
lit_widget.render(open_in_new_tab=True)
استخدام بياناتك
بما أنّ Gemma هو نموذج توليدي من نص إلى نص، فهو يتلقّى نصًا كمدخل وينشئ نصًا كمخرج. تستخدم أداة LIT واجهة برمجة تطبيقات ذات آراء مسبقة لتوضيح بنية مجموعات البيانات المحمَّلة للنماذج. تم تصميم النماذج اللغوية الكبيرة في LIT للعمل مع مجموعات البيانات التي توفّر حقلَين:
prompt: هو الإدخال إلى النموذج الذي سيتم إنشاء النص منه.-
target: تسلسل مستهدف اختياري، مثل ردّ "صحيح" من مقيّمين بشريين أو ردّ تم إنشاؤه مسبقًا من نموذج آخر.
تتضمّن أداة LIT مجموعة صغيرة من sample_prompts مع أمثلة من المصادر التالية التي تتوافق مع هذا الدرس التطبيقي حول الترميز والبرنامج التعليمي الموسّع لتصحيح أخطاء الطلبات في أداة LIT.
- GSM8K: حلّ المسائل الرياضية في المرحلة الابتدائية باستخدام أمثلة قليلة.
- مجموعة بيانات Gigaword Benchmark: إنشاء عناوين لمجموعة من المقالات القصيرة
- الطلبات الدستورية: إنشاء أفكار جديدة حول كيفية استخدام الكائنات مع إرشادات أو حدود
يمكنك أيضًا تحميل بياناتك بسهولة، إما كملف .jsonl يحتوي على سجلات تتضمّن الحقلين prompt وtarget اختياريًا (مثال)، أو من أي تنسيق باستخدام واجهة برمجة التطبيقات لمجموعة البيانات من LIT.
نفِّذ الخلية أدناه لتحميل الطلبات النموذجية.
5- تحليل الطلبات القليلة اللقطات في Gemma ضمن LIT
في الوقت الحالي، يُعدّ التلقين فنًا وعلمًا في الوقت نفسه، ويمكن أن تساعدك أداة LIT في تحسين الطلبات بشكل تجريبي للنماذج اللغوية الكبيرة، مثل Gemma. في ما يلي مثال على كيفية استخدام أداة LIT لاستكشاف سلوكيات Gemma وتوقّع المشاكل المحتملة وتحسين مستوى أمانها.
تحديد الأخطاء في الطلبات المعقّدة
من أهم تقنيات التلقين التي تؤدي إلى إنشاء نماذج أولية وتطبيقات عالية الجودة تستند إلى نماذج لغوية كبيرة، نذكر التلقين ببضعة أمثلة (بما في ذلك أمثلة على السلوك المطلوب في الطلب) وسلسلة الأفكار (بما في ذلك شكل من أشكال التفسير أو الاستدلال قبل الناتج النهائي لنموذج اللغة الكبير). ومع ذلك، لا يزال من الصعب في كثير من الأحيان إنشاء طلب فعّال.
لنفترض أنّك تريد مساعدة شخص ما في تقييم ما إذا كان سيحب طعامًا معيّنًا استنادًا إلى ذوقه. قد يبدو نموذج طلب أولي لسلسلة أفكار على النحو التالي:
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
هل رصدت المشاكل في هذا الطلب؟ ستساعدك أداة LIT في فحص الطلب باستخدام وحدة LM Salience.
6. استخدام أهمية التسلسل لتصحيح الأخطاء
يتم احتساب درجة الأهمية على أصغر مستوى ممكن (أي لكل رمز مميز للإدخال)، ولكن يمكن لأداة LIT تجميع درجة أهمية الرموز المميزة في نطاقات أكبر وأكثر قابلية للتفسير، مثل الأسطر أو الجمل أو الكلمات. يمكنك الاطّلاع على مزيد من المعلومات حول مدى الأهمية وكيفية استخدامه لتحديد التحيزات غير المقصودة في Saliency Explorable.
لنبدأ بإدخال مثال جديد لمتغيّرات نموذج الطلب:
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
إذا كانت واجهة مستخدم LIT مفتوحة في الخلية أعلاه أو في علامة تبويب منفصلة، يمكنك استخدام محرّر نقاط البيانات في LIT لإضافة هذا الطلب:
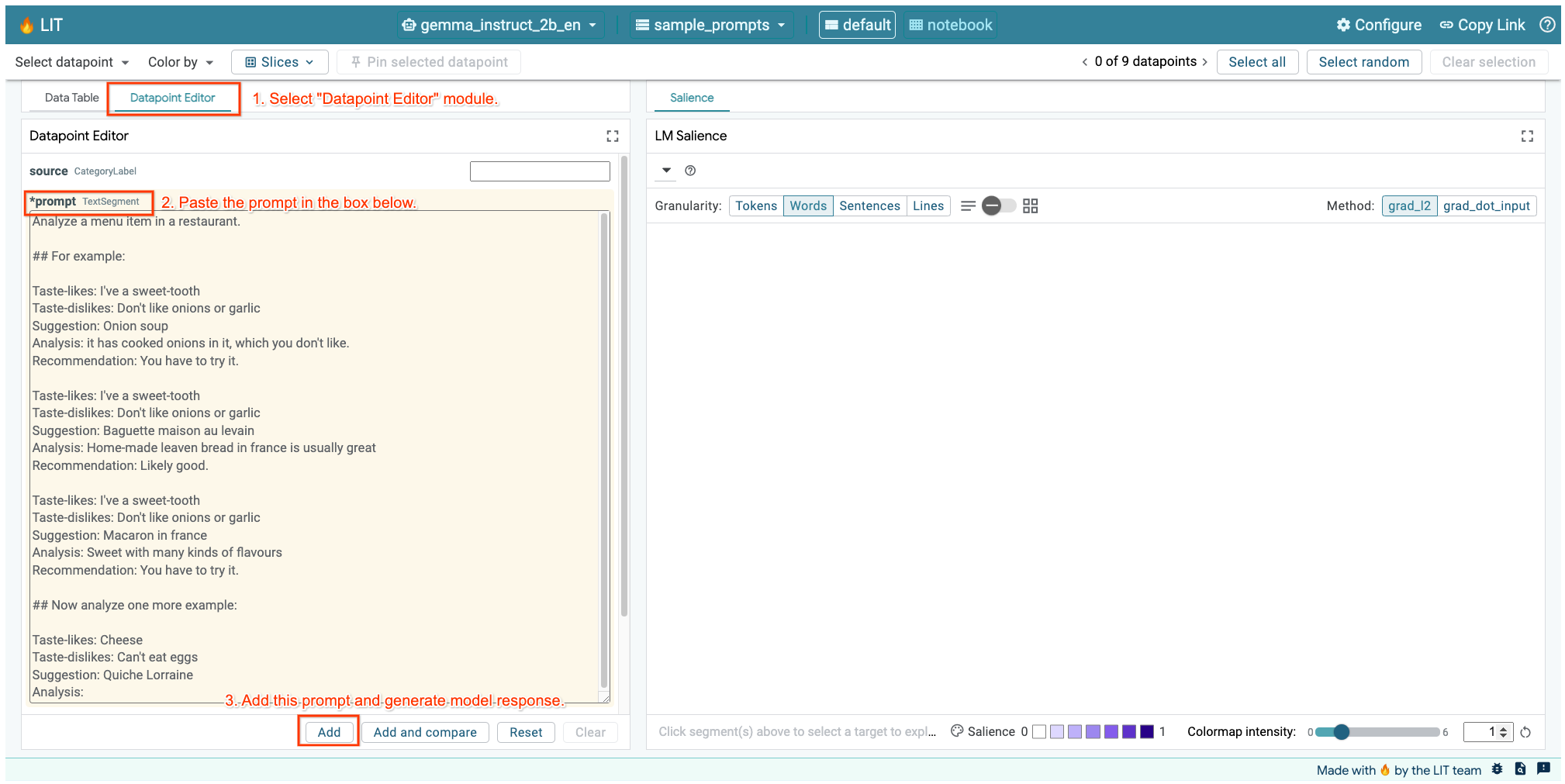
هناك طريقة أخرى وهي إعادة عرض التطبيق المصغّر مباشرةً باستخدام الطلب الذي يهمّك:
lit_widget.render(data=[fewshot_mistake_example])
لاحظ إكمال النموذج المفاجئ:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
لماذا يقترح عليك النموذج تناول طعام قلت بوضوح إنّك لا تستطيع تناوله؟
يمكن أن تساعد أهمية التسلسل في تسليط الضوء على المشكلة الأساسية، وهي موجودة في أمثلة التعلّم من عدد قليل من اللقطات. في المثال الأول، لا يتطابق الاستنتاج المستند إلى سلسلة الأفكار في قسم التحليل it has cooked onions in it, which you don't like مع التوصية النهائية You have to try it.
في وحدة "بروز اللغة"، اختَر "الجُمل" ثم اختَر سطر الاقتراح. من المفترض أن تبدو واجهة المستخدم الآن على النحو التالي:
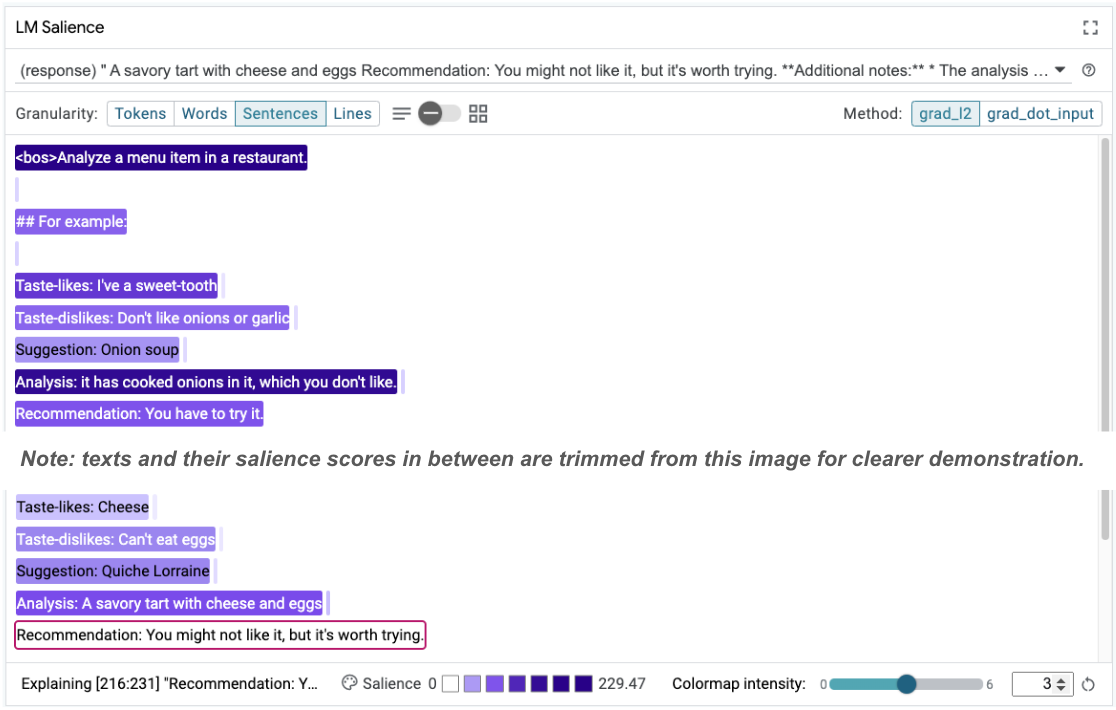
يشير ذلك إلى خطأ بشري، وهو نسخ جزء من التوصية ولصقه عن طريق الخطأ وعدم تعديله.
لنصحّح الآن "الاقتراح" في المثال الأول إلى Avoid، ثم نعيد المحاولة. يتم تحميل هذا المثال مسبقًا في طلبات العيّنات في LIT، لذا يمكنك استخدام وظيفة الأداة المساعدة الصغيرة هذه للحصول عليه:
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
أصبح إكمال النموذج الآن كما يلي:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
من الدروس المهمة التي يمكن استخلاصها من ذلك ما يلي: يساعد إنشاء النماذج الأولية في وقت مبكر في الكشف عن المخاطر التي قد لا تفكر فيها مسبقًا، كما أنّ طبيعة نماذج اللغة المعرضة للأخطاء تعني أنّه يجب تصميمها بشكل استباقي لتجنُّب الأخطاء. يمكنك الاطّلاع على مزيد من المناقشات حول هذا الموضوع في دليل "الأشخاص + الذكاء الاصطناعي" لتصميم المنتجات باستخدام الذكاء الاصطناعي.
على الرغم من أنّ الطلب المعدّل الذي يتضمّن أمثلة قليلة أفضل، إلا أنّه لا يزال غير دقيق تمامًا: فهو يطلب من المستخدم بشكل صحيح تجنُّب البيض، ولكن السبب غير صحيح، إذ يقول إنّه لا يحب البيض، بينما ذكر المستخدم أنّه لا يستطيع تناول البيض. في القسم التالي، ستتعرّف على كيفية تحسين أدائك.
7. اختبار الفرضيات لتحسين سلوك النموذج
تتيح لك هذه الأداة اختبار التغييرات على الطلبات ضمن الواجهة نفسها. في هذه الحالة، ستختبر إضافة دستور لتحسين سلوك النموذج. تشير الدساتير إلى طلبات التصميم التي تتضمّن مبادئ للمساعدة في توجيه عملية إنشاء النموذج. تتيح الطرق الحديثة حتى الاشتقاق التفاعلي للمبادئ الدستورية.
لنستخدِم هذه الفكرة للمساعدة في تحسين الطلب بشكلٍ أكبر. أضِف قسمًا يتضمّن مبادئ الإنشاء في أعلى الطلب، والذي يبدأ الآن على النحو التالي:
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
بعد هذا التحديث، يمكن إعادة تشغيل المثال وملاحظة ناتج مختلف تمامًا:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
يمكن بعد ذلك إعادة فحص أهمية الطلب للمساعدة في فهم سبب حدوث هذا التغيير:
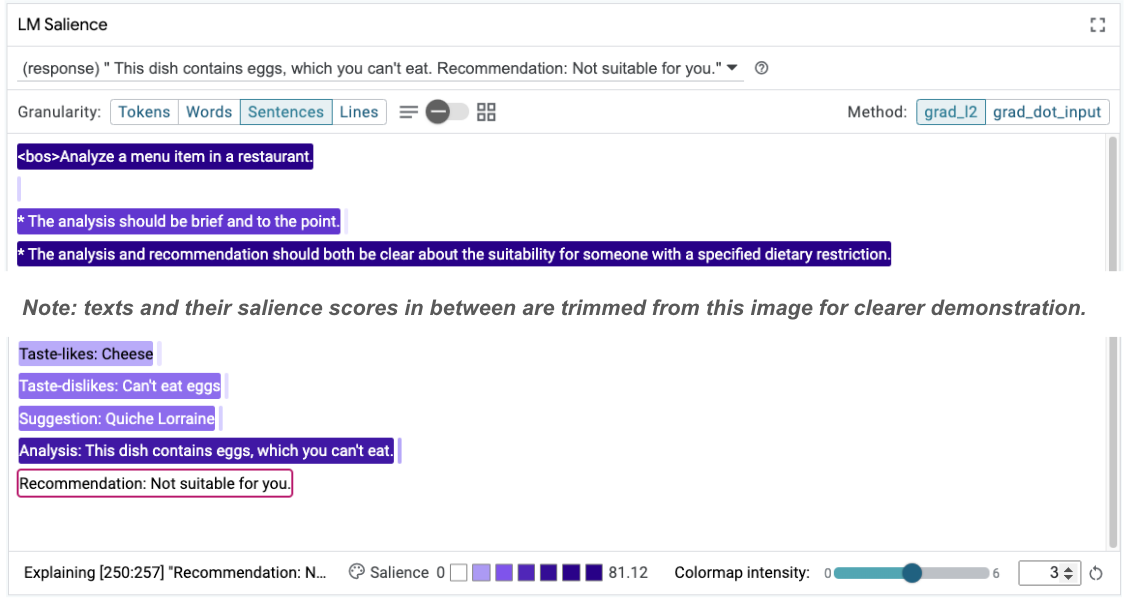
لاحظ أنّ الاقتراح أكثر أمانًا. بالإضافة إلى ذلك، يتأثّر الردّ "غير مناسب لك" بمبدأ توضيح مدى ملاءمة المنتج وفقًا للقيود الغذائية، بالإضافة إلى التحليل (ما يُعرف بسلسلة الأفكار). يساعد ذلك في تعزيز الثقة في أنّ النتائج تظهر للسبب الصحيح.
8. إشراك فِرق غير تقنية في استكشاف النماذج واختبارها
يجب أن يكون التفسير جهدًا جماعيًا يشمل خبرات في مجالات الذكاء الاصطناعي القابل للتفسير والسياسات والقانون وغيرها.
كان التفاعل مع النماذج في مراحل التطوير المبكرة يتطلب عادةً خبرة فنية كبيرة، ما صعّب على بعض المتعاونين الوصول إليها واستكشافها. لم تكن الأدوات متاحة في السابق لتمكين هذه الفِرق من المشاركة في مراحل تصميم النماذج الأولية.
من خلال LIT، نأمل أن يتغيّر هذا النموذج. كما رأيت في هذا الدرس التطبيقي حول الترميز، يمكن أن تساعد الوسيط المرئي الذي توفّره أداة LIT وإمكانية فحص أهمية الكلمات واستكشاف الأمثلة بشكل تفاعلي مختلف الجهات المعنيّة في مشاركة النتائج والتواصل بشأنها. ويمكن أن يتيح لك ذلك الاستعانة بفريق متنوع من الزملاء لاستكشاف النماذج وفحصها وتصحيح أخطائها. ويمكن أن يؤدي تعريفهم بهذه الأساليب الفنية إلى تعزيز فهمهم لطريقة عمل النماذج. بالإضافة إلى ذلك، يمكن أن تساعد مجموعة أكثر تنوعًا من الخبرات في اختبار النماذج المبكر على الكشف عن النتائج غير المرغوب فيها التي يمكن تحسينها.
9- ملخّص
باختصار:
- توفّر واجهة مستخدم LIT واجهة لتنفيذ النماذج التفاعلية، ما يتيح للمستخدمين إنشاء نتائج مباشرةً واختبار سيناريوهات "ماذا لو". ويفيد ذلك على وجه الخصوص في اختبار صيغ مختلفة من الطلبات.
- يوفّر وحدة قياس بروز نموذج اللغة تمثيلاً مرئيًا للبروز، كما يوفّر دقة بيانات قابلة للتحكّم حتى تتمكّن من التواصل بشأن البُنى التي تركّز على الإنسان (مثل الجُمل والكلمات) بدلاً من البُنى التي تركّز على النموذج (مثل الرموز المميزة).
عند العثور على أمثلة تتضمّن مشاكل في تقييمات النموذج، يمكنك إضافتها إلى "أداة التفسير" لتصحيح الأخطاء. ابدأ بتحليل أكبر وحدة معقولة من المحتوى يمكنك التفكير فيها والتي ترتبط منطقيًا بمهمة النمذجة، واستخدِم الرسومات البيانية لمعرفة المواضع التي يركّز فيها النموذج بشكل صحيح أو غير صحيح على محتوى الطلب، ثم انتقِل إلى وحدات أصغر من المحتوى لوصف السلوك غير الصحيح الذي تلاحظه بشكل أكبر من أجل تحديد الحلول الممكنة.
أخيرًا، نعمل باستمرار على تحسين Lit. يمكنك الاطّلاع على مزيد من المعلومات حول ميزاتنا ومشاركة اقتراحاتك هنا.