
1. Introduction
Les produits d'IA générative sont relativement nouveaux et le comportement d'une application peut varier plus que les formes de logiciels précédentes. Il est donc important d'examiner les modèles de machine learning utilisés, d'analyser des exemples de leur comportement et d'étudier les surprises.
Learning Interpretability Tool (LIT ; site Web, GitHub) est une plate-forme permettant de déboguer et d'analyser les modèles de ML pour comprendre pourquoi et comment ils se comportent de telle ou telle manière.
Dans cet atelier de programmation, vous allez apprendre à utiliser LIT pour exploiter tout le potentiel du modèle Gemma de Google. Cet atelier de programmation montre comment utiliser la saillance de séquence, une technique d'interprétabilité, pour analyser différentes approches d'ingénierie des requêtes.
Objectifs de la formation :
- Comprendre la saillance des séquences et ses utilisations dans l'analyse des modèles.
- Configurer LIT pour que Gemma calcule les sorties d'invite et la saillance de séquence.
- Utiliser la saillance de séquence via le module LM Salience pour comprendre l'impact des conceptions de requêtes sur les résultats du modèle.
- Tester les améliorations hypothétiques des requêtes dans LIT et observer leur impact.
Remarque : Cet atelier de programmation utilise l'implémentation KerasNLP de Gemma et TensorFlow v2 pour le backend. Nous vous recommandons vivement d'utiliser un noyau de GPU pour suivre ce tutoriel.
2. Importance de la séquence et ses utilisations dans l'analyse des modèles
Les modèles génératifs texte-vers-texte, tels que Gemma, prennent une séquence d'entrée sous la forme de texte tokenisé et génèrent de nouveaux jetons qui sont des suites ou des complétions typiques de cette entrée. Cette génération se fait jeton par jeton, en ajoutant (dans une boucle) chaque jeton nouvellement généré à l'entrée, ainsi qu'à toutes les générations précédentes, jusqu'à ce que le modèle atteigne une condition d'arrêt. Par exemple, lorsque le modèle génère un jeton de fin de séquence (EOS) ou atteint la longueur maximale prédéfinie.
Les méthodes de saillance sont une classe de techniques d'IA explicable (XAI) qui peuvent vous indiquer quelles parties d'une entrée sont importantes pour le modèle pour différentes parties de sa sortie. LIT est compatible avec les méthodes de saillance pour diverses tâches de classification, qui expliquent l'impact d'une séquence de jetons d'entrée sur le libellé prédit. La saillance de séquence généralise ces méthodes aux modèles génératifs texte-vers-texte et explique l'impact des jetons précédents sur les jetons générés.
Ici, vous utiliserez la méthode Grad L2 Norm pour la saillance de séquence, qui analyse les gradients du modèle et fournit une magnitude de l'influence de chaque jeton précédent sur la sortie. Cette méthode est simple et efficace, et il a été démontré qu'elle fonctionnait bien dans les paramètres de classification et autres. Plus le score de saillance est élevé, plus l'influence est importante. Cette méthode est utilisée dans LIT, car elle est bien comprise et largement utilisée dans la communauté de recherche sur l'interprétabilité.
Les méthodes de saillance basées sur les gradients plus avancées incluent Grad ⋅ Input et les gradients intégrés. Il existe également des méthodes basées sur l'ablation, telles que LIME et SHAP, qui peuvent être plus robustes, mais dont le calcul est beaucoup plus coûteux. Pour une comparaison détaillée des différentes méthodes de saillance, consultez cet article.
Pour en savoir plus sur les méthodes de saillance, consultez cette présentation interactive de la saillance.
3. Code d'importation, d'environnement et d'autres configurations
Il est préférable de suivre cet atelier de programmation dans new Colab. Nous vous recommandons d'utiliser un environnement d'exécution d'accélérateur, car vous allez charger un modèle en mémoire. Toutefois, sachez que les options d'accélérateur varient au fil du temps et sont soumises à des limites. Colab propose des abonnements payants si vous souhaitez accéder à des accélérateurs plus puissants. Vous pouvez également utiliser un environnement d'exécution local si votre machine dispose d'un GPU approprié.
Remarque : Vous pouvez voir des avertissements du type suivant :
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
Vous pouvez les ignorer.
Installer LIT et Keras NLP
Pour cet atelier de programmation, vous aurez besoin d'une version récente de keras (3) keras-nlp (0.14.) et lit-nlp (1.2), ainsi que d'un compte Kaggle pour télécharger le modèle de base.
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
Accès à Kaggle
Pour vous authentifier auprès de Kaggle, vous pouvez :
- Stockez vos identifiants dans un fichier, tel que
~/.kaggle/kaggle.json. - Utilisez les variables d'environnement
KAGGLE_USERNAMEetKAGGLE_KEY. - Exécutez ce qui suit dans un environnement Python interactif, tel que Google Colab.
import kagglehub
kagglehub.login()
Pour en savoir plus, consultez la documentation kagglehub et veillez à accepter le contrat de licence Gemma.
Configurer Keras
Keras 3 est compatible avec plusieurs backends de deep learning, y compris TensorFlow (par défaut), PyTorch et JAX. Le backend est configuré à l'aide de la variable d'environnement KERAS_BACKEND, qui doit être définie avant d'importer la bibliothèque Keras. L'extrait de code suivant vous montre comment définir cette variable dans un environnement Python interactif.
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
4. Configurer LIT
LIT peut être utilisé dans des notebooks Python ou via un serveur Web. Cet atelier de programmation se concentre sur le cas d'utilisation des notebooks. Nous vous recommandons de le suivre dans Google Colab.
Dans cet atelier de programmation, vous allez charger Gemma v2 2B IT à l'aide du préréglage KerasNLP. L'extrait suivant initialise Gemma et charge un exemple d'ensemble de données dans un widget LIT Notebook.
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
Vous pouvez configurer le widget en modifiant les valeurs transmises aux deux arguments positionnels requis :
datasets_config: liste de chaînes contenant les noms et les chemins d'accès des ensembles de données à charger, au format "dataset:path", où le chemin d'accès peut être une URL ou un chemin d'accès à un fichier local. L'exemple ci-dessous utilise la valeur spécialesample_promptspour charger les exemples d'invites fournis dans la distribution LIT.models_config: liste de chaînes contenant les noms et les chemins d'accès des modèles à charger, au format "modèle:chemin d'accès", où le chemin d'accès peut être une URL, un chemin d'accès à un fichier local ou le nom d'un préréglage pour le framework de deep learning configuré.
Une fois que vous avez configuré LIT pour utiliser le modèle qui vous intéresse, exécutez l'extrait de code suivant pour afficher le widget dans votre notebook.
lit_widget.render(open_in_new_tab=True)
Utiliser vos propres données
Gemma est un modèle génératif texte-vers-texte qui prend du texte en entrée et génère du texte en sortie. LIT utilise une API orientée pour communiquer la structure des ensembles de données chargés aux modèles. Les LLM de LIT sont conçus pour fonctionner avec des ensembles de données qui fournissent deux champs :
prompt: entrée du modèle à partir de laquelle le texte sera généré.target: séquence cible facultative, telle qu'une réponse de "vérité terrain" provenant d'évaluateurs humains ou une réponse pré-générée provenant d'un autre modèle.
LIT inclut un petit ensemble de sample_prompts avec des exemples provenant des sources suivantes qui prennent en charge cet atelier de programmation et le tutoriel de débogage d'invites étendu de LIT.
- GSM8K : résoudre des problèmes de mathématiques de l'école primaire avec des exemples few-shot.
- Gigaword Benchmark : génération de titres pour une collection d'articles courts.
- Constitutional Prompting : générer de nouvelles idées sur la façon d'utiliser des objets avec des consignes/limites.
Vous pouvez également charger facilement vos propres données, soit sous la forme d'un fichier .jsonl contenant des enregistrements avec les champs prompt et éventuellement target (exemple), soit à partir de n'importe quel format en utilisant l'API Dataset de LIT.
Exécutez la cellule ci-dessous pour charger les exemples de requêtes.
5. Analyser les requêtes few-shot pour Gemma dans LIT
Aujourd'hui, le prompting est à la fois un art et une science. LIT peut vous aider à améliorer empiriquement les requêtes pour les grands modèles de langage, tels que Gemma. Vous trouverez ci-dessous un exemple d'utilisation de LIT pour explorer les comportements de Gemma, anticiper les problèmes potentiels et améliorer sa sécurité.
Identifier les erreurs dans les requêtes complexes
Deux des techniques de prompting les plus importantes pour les prototypes et applications basés sur des LLM de haute qualité sont le prompting few-shot (qui inclut des exemples du comportement souhaité dans la requête) et la chaîne de pensée (qui inclut une forme d'explication ou de raisonnement avant la sortie finale du LLM). Mais créer une requête efficace reste souvent difficile.
Prenons l'exemple d'une personne qui a besoin d'aide pour savoir si elle va aimer un plat en fonction de ses goûts. Un modèle de requête par chaîne de pensée pour un prototype initial peut se présenter comme suit :
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
Avez-vous identifié les problèmes liés à cette requête ? LIT vous aidera à examiner la requête avec le module de saillance du LM.
6. Utiliser la saillance de séquence pour le débogage
La saillance est calculée au niveau le plus petit possible (c'est-à-dire pour chaque jeton d'entrée), mais LIT peut agréger la saillance des jetons en des étendues plus grandes et plus interprétables, telles que des lignes, des phrases ou des mots. Pour en savoir plus sur la saillance et sur la façon de l'utiliser pour identifier les biais involontaires, consultez notre explorable sur la saillance.
Commençons par fournir un nouvel exemple d'entrée pour les variables du modèle de requête :
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
Si l'UI LIT est ouverte dans la cellule ci-dessus ou dans un onglet distinct, vous pouvez utiliser l'éditeur de points de données de LIT pour ajouter cette invite :

Une autre méthode consiste à afficher à nouveau le widget directement avec la requête qui vous intéresse :
lit_widget.render(data=[fewshot_mistake_example])
Notez la complétion surprenante du modèle :
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
Pourquoi le modèle vous suggère-t-il de manger quelque chose que vous avez clairement indiqué ne pas pouvoir manger ?
La saillance de séquence peut aider à mettre en évidence le problème racine, qui se trouve dans nos exemples few-shot. Dans le premier exemple, le raisonnement de type "chaîne de pensée" dans la section d'analyse it has cooked onions in it, which you don't like ne correspond pas à la recommandation finale You have to try it.
Dans le module "LM Salience", sélectionnez "Sentences" (Phrases), puis la ligne de recommandation. L'UI devrait maintenant se présenter comme suit :
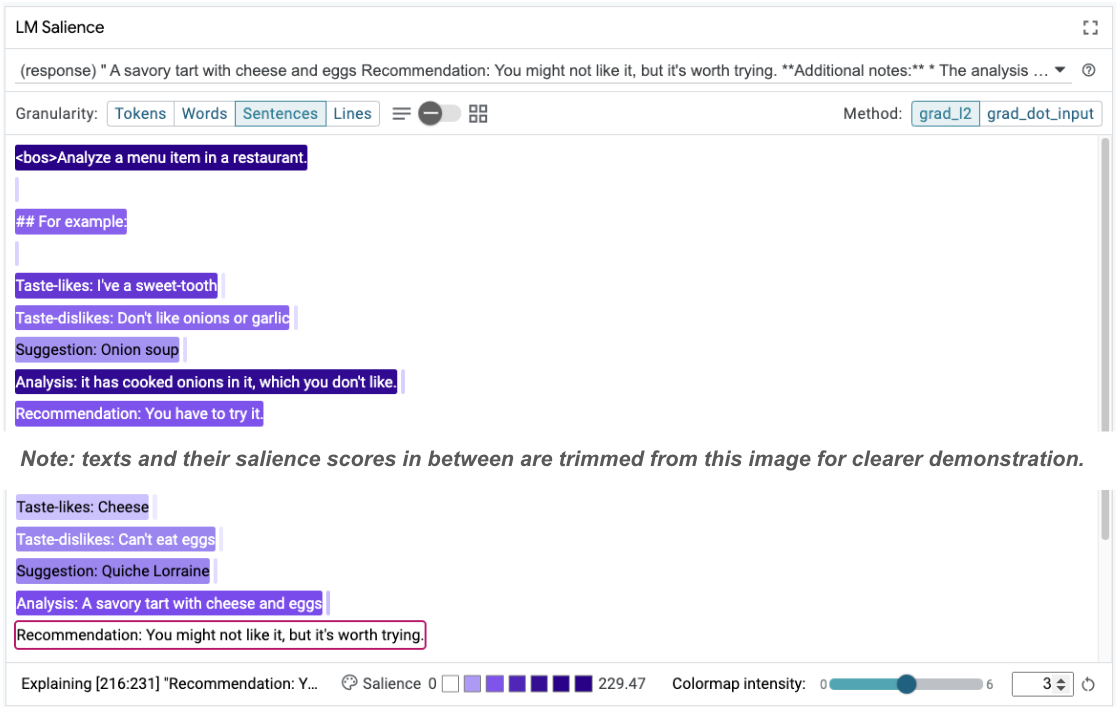
Cela met en évidence une erreur humaine : la partie de la recommandation a été copiée et collée par erreur, et n'a pas été mise à jour.
Corrigeons maintenant la "Recommandation" du premier exemple en la remplaçant par Avoid, puis réessayons. LIT a préchargé cet exemple dans les exemples d'invites. Vous pouvez donc utiliser cette petite fonction utilitaire pour le récupérer :
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
La réponse du modèle devient :
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
Une leçon importante à retenir est la suivante : le prototypage précoce permet de révéler des risques auxquels vous n'auriez peut-être pas pensé à l'avance. De plus, la nature sujette aux erreurs des modèles de langage signifie qu'il faut concevoir les systèmes de manière proactive pour gérer les erreurs. Pour en savoir plus, consultez notre guide "People + AI" sur la conception avec l'IA.
Bien que la correction de l'invite few-shot soit meilleure, elle n'est toujours pas tout à fait correcte : elle indique correctement à l'utilisateur d'éviter les œufs, mais le raisonnement n'est pas bon. Elle indique que l'utilisateur n'aime pas les œufs, alors qu'il a en fait déclaré qu'il ne pouvait pas en manger. Dans la section suivante, vous verrez comment faire mieux.
7. Tester des hypothèses pour améliorer le comportement du modèle
LIT vous permet de tester les modifications apportées aux requêtes dans la même interface. Dans ce cas, vous allez tester l'ajout d'une constitution pour améliorer le comportement du modèle. Les constitutions font référence à des requêtes de conception avec des principes pour guider la génération du modèle. Des méthodes récentes permettent même de dériver de manière interactive les principes constitutionnels.
Utilisons cette idée pour améliorer encore le prompt. Ajoutez une section avec les principes de génération en haut de notre requête, qui commence désormais comme suit :
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
Avec cette mise à jour, l'exemple peut être réexécuté et un résultat très différent peut être observé :
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
La saillance du prompt peut ensuite être réexaminée pour comprendre pourquoi ce changement se produit :

Notez que la recommandation est beaucoup plus sûre. De plus, la mention "Ne vous convient pas" est influencée par le principe d'indiquer clairement l'adéquation en fonction de la restriction alimentaire, ainsi que par l'analyse (la chaîne de pensée). Cela permet de s'assurer que le résultat est généré pour la bonne raison.
8. Inclure les équipes non techniques dans l'exploration et l'analyse des modèles
L'interprétabilité est un travail d'équipe qui nécessite l'expertise de plusieurs domaines, comme l'IA explicable, les règles, le droit, etc.
Traditionnellement, l'interaction avec les modèles lors des premières étapes de développement nécessitait une expertise technique importante, ce qui rendait l'accès et l'exploration plus difficiles pour certains collaborateurs. Historiquement, il n'existait pas d'outils permettant à ces équipes de participer aux premières phases de prototypage.
L'objectif de LIT est de changer ce paradigme. Comme vous l'avez vu dans cet atelier de programmation, le support visuel et la capacité interactive de LIT à examiner la saillance et à explorer des exemples peuvent aider différentes parties prenantes à partager et à communiquer des résultats. Cela peut vous permettre d'intégrer une plus grande diversité de coéquipiers pour l'exploration, l'analyse et le débogage des modèles. Les exposer à ces méthodes techniques peut les aider à mieux comprendre le fonctionnement des modèles. De plus, un ensemble d'expertises plus diversifié lors des premiers tests du modèle peut également aider à identifier les résultats indésirables qui peuvent être améliorés.
9. Récapitulatif
En résumé :
- L'UI LIT fournit une interface pour l'exécution interactive des modèles, permettant aux utilisateurs de générer directement des sorties et de tester des scénarios "et si". Cela est particulièrement utile pour tester différentes variantes de requêtes.
- Le module de saillance LM fournit une représentation visuelle de la saillance et une granularité des données contrôlable. Vous pouvez ainsi communiquer sur des constructions centrées sur l'humain (par exemple, des phrases et des mots) au lieu de constructions centrées sur le modèle (par exemple, des jetons).
Lorsque vous trouvez des exemples problématiques dans les évaluations de votre modèle, importez-les dans LIT pour les déboguer. Commencez par analyser la plus grande unité de contenu pertinente à laquelle vous pouvez penser et qui est logiquement liée à la tâche de modélisation. Utilisez les visualisations pour voir où le modèle prête attention au contenu de la requête de manière correcte ou incorrecte. Ensuite, examinez des unités de contenu plus petites pour décrire plus précisément le comportement incorrect que vous observez afin d'identifier les solutions possibles.
Enfin, Lit s'améliore constamment ! Pour en savoir plus sur nos fonctionnalités et nous faire part de vos suggestions, cliquez ici.