
1. Wprowadzenie
Usługi generatywnej AI są stosunkowo nowe, a zachowania aplikacji mogą się różnić bardziej niż w przypadku wcześniejszych form oprogramowania. Dlatego ważne jest, aby sprawdzać używane modele uczenia maszynowego, analizować przykłady ich działania i badać niespodziewane wyniki.
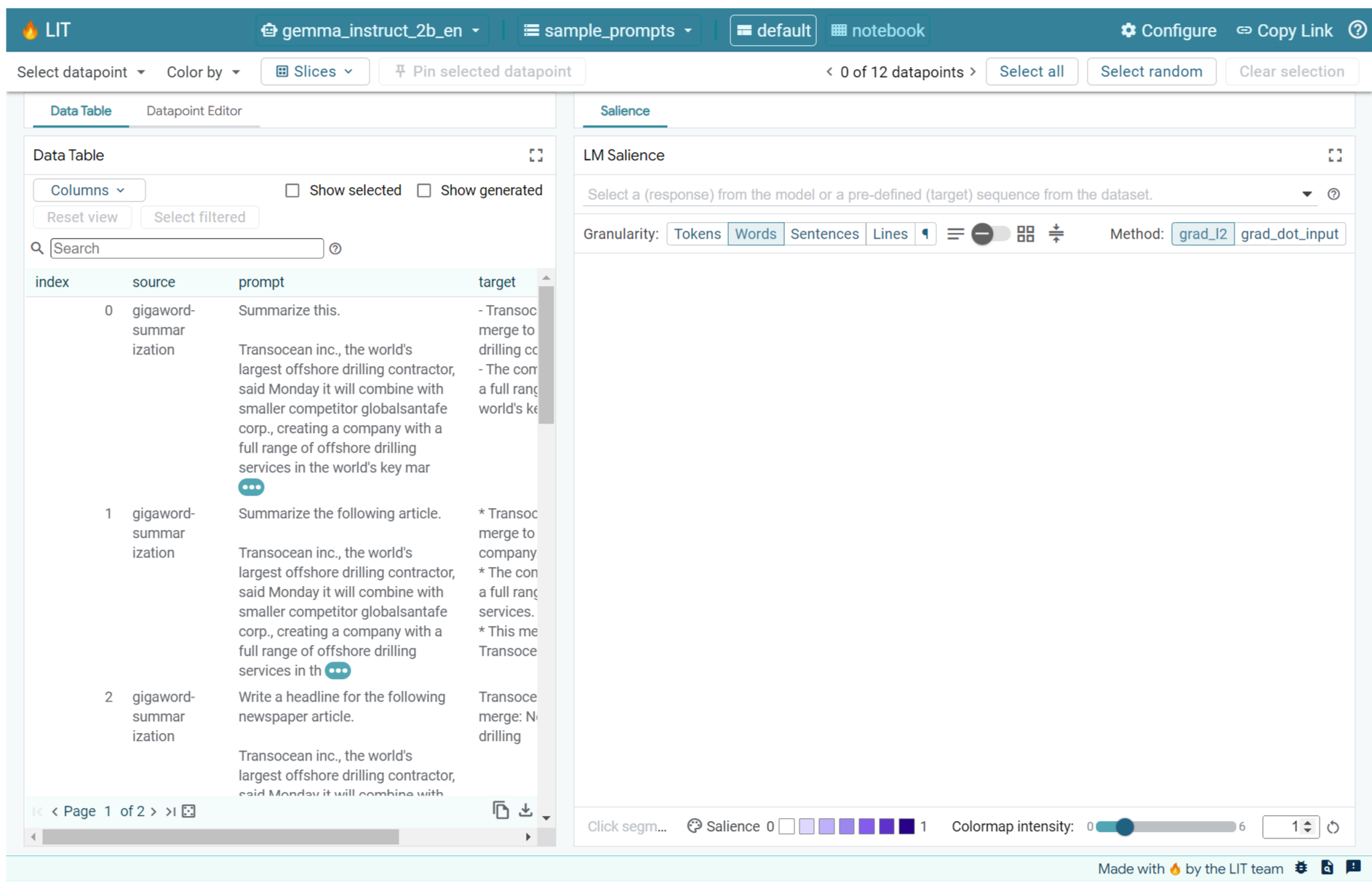
Narzędzie do analizowania interpretowalności (LIT; strona internetowa, GitHub) to platforma do debugowania i analizowania modeli uczenia maszynowego, która pomaga zrozumieć, dlaczego i jak działają one w określony sposób.
Z tego przewodnika dowiesz się, jak korzystać z LIT, aby w pełni wykorzystać możliwości modelu Gemma od Google. W ramach tych ćwiczeń z programowania dowiesz się, jak używać istotności sekwencji, czyli techniki interpretacji, do analizowania różnych podejść do inżynierii promptów.
Cele szkolenia:
- Poznaj istotność sekwencji i jej zastosowania w analizie modelu.
- Konfigurowanie LIT dla Gemy w celu obliczania danych wyjściowych promptów i istotności sekwencji.
- Korzystanie z istotności sekwencji w module Istotność modelu językowego, aby zrozumieć wpływ projektów promptów na dane wyjściowe modelu.
- Testowanie w LIT hipotetycznych ulepszeń promptów i sprawdzanie ich wpływu.
Uwaga: w tych ćwiczeniach z programowania używamy implementacji KerasNLP modelu Gemma i TensorFlow w wersji 2 jako backendu. Zdecydowanie zalecamy użycie jądra GPU.
2. Znaczenie sekwencji i jego zastosowania w analizie modelu
Modele generatywne typu tekst na podstawie tekstu, takie jak Gemma, przyjmują sekwencję wejściową w postaci tokenizowanego tekstu i generują nowe tokeny, które zwykle są kontynuacją lub uzupełnieniem tych danych wejściowych. Generowanie odbywa się po jednym tokenie naraz. Każdy nowo wygenerowany token jest dołączany (w pętli) do danych wejściowych i wszystkich poprzednich wygenerowanych tokenów, dopóki model nie osiągnie warunku zatrzymania. Na przykład gdy model wygeneruje token końca sekwencji (EOS) lub osiągnie zdefiniowaną maksymalną długość.
Metody istotności to klasa technik wyjaśnialnej AI (XAI), które mogą wskazywać, które części danych wejściowych są ważne dla modelu w przypadku różnych części jego danych wyjściowych. LIT obsługuje metody istotności w przypadku różnych zadań klasyfikacji, które wyjaśniają wpływ sekwencji tokenów wejściowych na prognozowaną etykietę. Istotność sekwencji uogólnia te metody na generatywne modele tekst na podstawie tekstu i wyjaśnia wpływ poprzednich tokenów na wygenerowane tokeny.
W tym przypadku do określania istotności sekwencji użyjesz metody Grad L2 Norm, która analizuje gradienty modelu i określa, jak duże jest znaczenie każdego poprzedniego tokena dla wyniku. Ta metoda jest prosta i wydajna, a wykazano, że sprawdza się w klasyfikacji i innych ustawieniach. Im większy wynik istotności, tym większy wpływ. Ta metoda jest używana w LIT, ponieważ jest dobrze znana i powszechnie stosowana w środowisku badaczy zajmujących się interpretowalnością.
Bardziej zaawansowane metody istotności oparte na gradientach to Grad ⋅ Input i gradienty zintegrowane. Dostępne są też metody oparte na usuwaniu, takie jak LIME i SHAP, które mogą być bardziej niezawodne, ale ich obliczenie jest znacznie droższe. Szczegółowe porównanie różnych metod określania istotności znajdziesz w tym artykule.
Więcej informacji o metodach opartych na wyrazistości znajdziesz w tym interaktywnym wprowadzeniu do wyrazistości.
3. Importy, środowisko i inny kod konfiguracji
Najlepiej jest korzystać z tego samouczka w nowej wersji Colab. Zalecamy używanie środowiska wykonawczego akceleratora, ponieważ będziesz wczytywać model do pamięci. Pamiętaj jednak, że opcje akceleratora zmieniają się z czasem i podlegają ograniczeniom. Jeśli chcesz mieć dostęp do wydajniejszych akceleratorów, możesz skorzystać z płatnych subskrypcji Colab. Możesz też użyć lokalnego środowiska wykonawczego, jeśli Twój komputer ma odpowiedni procesor graficzny.
Uwaga: możesz zobaczyć ostrzeżenia w formie
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
Możesz je zignorować.
Instalowanie LIT i Keras NLP
Na potrzeby tego laboratorium potrzebujesz najnowszej wersji keras (3) keras-nlp (0.14.) i lit-nlp (1.2) oraz konta Kaggle, aby pobrać model podstawowy.
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
Dostęp do Kaggle
Aby uwierzytelnić się w usłudze Kaggle, możesz:
- Zapisz dane logowania w pliku, np.
~/.kaggle/kaggle.json; - użyj zmiennych środowiskowych
KAGGLE_USERNAMEiKAGGLE_KEY; - Uruchom poniższe polecenia w interaktywnym środowisku Pythona, np. Google Colab.
import kagglehub
kagglehub.login()
Więcej informacji znajdziesz w kagglehubdokumentacji. Pamiętaj, aby zaakceptować umowę licencyjną Gemma.
Konfigurowanie Keras
Keras 3 obsługuje wiele backendów deep learningu, w tym TensorFlow (domyślny), PyTorch i JAX. Backend jest konfigurowany za pomocą zmiennej środowiskowej KERAS_BACKEND, którą należy ustawić przed zaimportowaniem biblioteki Keras. Poniższy fragment kodu pokazuje, jak ustawić tę zmienną w interaktywnym środowisku Pythona.
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
4. Konfigurowanie LIT
LIT można używać w notatnikach Pythona lub za pomocą serwera WWW. Ten Codelab skupia się na przypadku użycia notatnika. Zalecamy korzystanie z Google Colab.
W tym module dowiesz się, jak wczytać model Gemma v2 w wersji 2B IT za pomocą ustawień wstępnych KerasNLP. Poniższy fragment kodu inicjuje model Gemma i wczytuje przykładowy zbiór danych w widżecie LIT Notebook.
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
Widżet możesz skonfigurować, zmieniając wartości przekazywane do 2 wymaganych argumentów pozycyjnych:
datasets_config: lista ciągów tekstowych zawierających nazwy zbiorów danych i ścieżki do nich w formacie „zbiór danych:ścieżka”, gdzie ścieżka może być adresem URL lub ścieżką do pliku lokalnego. W przykładzie poniżej użyto wartości specjalnejsample_prompts, aby wczytać przykładowe prompty podane w dystrybucji LIT.models_config: lista ciągów znaków zawierających nazwy modeli i ścieżki do wczytania w formacie „model:path”, gdzie ścieżka może być adresem URL, lokalną ścieżką do pliku lub nazwą gotowego ustawienia dla skonfigurowanej platformy uczenia głębokiego.
Gdy skonfigurujesz LIT tak, aby używać interesującego Cię modelu, uruchom ten fragment kodu, aby wyrenderować widżet w notatniku.
lit_widget.render(open_in_new_tab=True)
Korzystanie z własnych danych
Gemma to generatywny model tekstowy, który przyjmuje tekstowe dane wejściowe i generuje tekstowe dane wyjściowe. LIT używa opartego na opiniach interfejsu API do przekazywania struktury wczytanych zbiorów danych do modeli. Modele LLM w LIT są przeznaczone do pracy ze zbiorami danych, które zawierają 2 pola:
prompt: dane wejściowe dla modelu, na podstawie których będzie generowany tekst;target: opcjonalna sekwencja docelowa, np. „prawdziwa” odpowiedź od oceniających lub wstępnie wygenerowana odpowiedź z innego modelu.
LIT zawiera mały zestaw sample_prompts z przykładami z tych źródeł, które obsługują ten przewodnik Codelab i rozszerzony samouczek debugowania promptów LIT.
- GSM8K: rozwiązywanie zadań matematycznych z klasy podstawowej na podstawie kilku przykładów.
- Gigaword Benchmark: generowanie nagłówków dla kolekcji krótkich artykułów.
- Constitutional Prompting: generowanie nowych pomysłów na wykorzystanie obiektów zgodnie z wytycznymi lub ograniczeniami.
Możesz też łatwo wczytać własne dane w postaci .jsonlpliku zawierającego rekordy z polami prompt i opcjonalnie target (przykład) lub w dowolnym formacie za pomocą interfejsu Dataset API LIT.
Uruchom komórkę poniżej, aby wczytać przykładowe prompty.
5. Analizowanie promptów Few Shot dla modelu Gemma w LIT
Obecnie tworzenie promptów to w równym stopniu sztuka, co nauka. LIT może pomóc Ci empirycznie ulepszać prompty dla dużych modeli językowych, takich jak Gemma. Poniżej znajdziesz przykład użycia LIT do zbadania zachowań Gemy, przewidzenia potencjalnych problemów i zwiększenia jej bezpieczeństwa.
Wykrywanie błędów w złożonych promptach
Dwie najważniejsze techniki tworzenia promptów w przypadku wysokiej jakości prototypów i aplikacji opartych na LLM to tworzenie promptów few-shot (uwzględniające w prompcie przykłady pożądanego zachowania) i łańcuch myśli (uwzględniające formę wyjaśnienia lub rozumowania przed ostatecznym wynikiem LLM). Jednak stworzenie skutecznego promptu często nadal jest trudne.
Rozważmy przykład pomocy w ocenie, czy komuś będzie smakować jedzenie na podstawie jego preferencji. Wstępny szablon promptu z ciągiem myślowym może wyglądać tak:
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
Czy udało Ci się dostrzec problemy z tym promptem? LIT pomoże Ci zbadać prompt za pomocą modułu LM Salience.
6. Używanie istotności sekwencji do debugowania
Istotność jest obliczana na najmniejszym możliwym poziomie (czyli dla każdego tokena wejściowego), ale LIT może agregować istotność tokenów w bardziej zrozumiałe większe zakresy, takie jak wiersze, zdania lub słowa. Więcej informacji o istotności i o tym, jak jej używać do identyfikowania niezamierzonych odchyleń, znajdziesz w tym artykule.
Zacznijmy od podania nowego przykładu danych wejściowych prompta dla zmiennych szablonu prompta:
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
Jeśli masz otwarty interfejs LIT w komórce powyżej lub w osobnej karcie, możesz użyć Edytora punktów danych w LIT, aby dodać ten prompt:
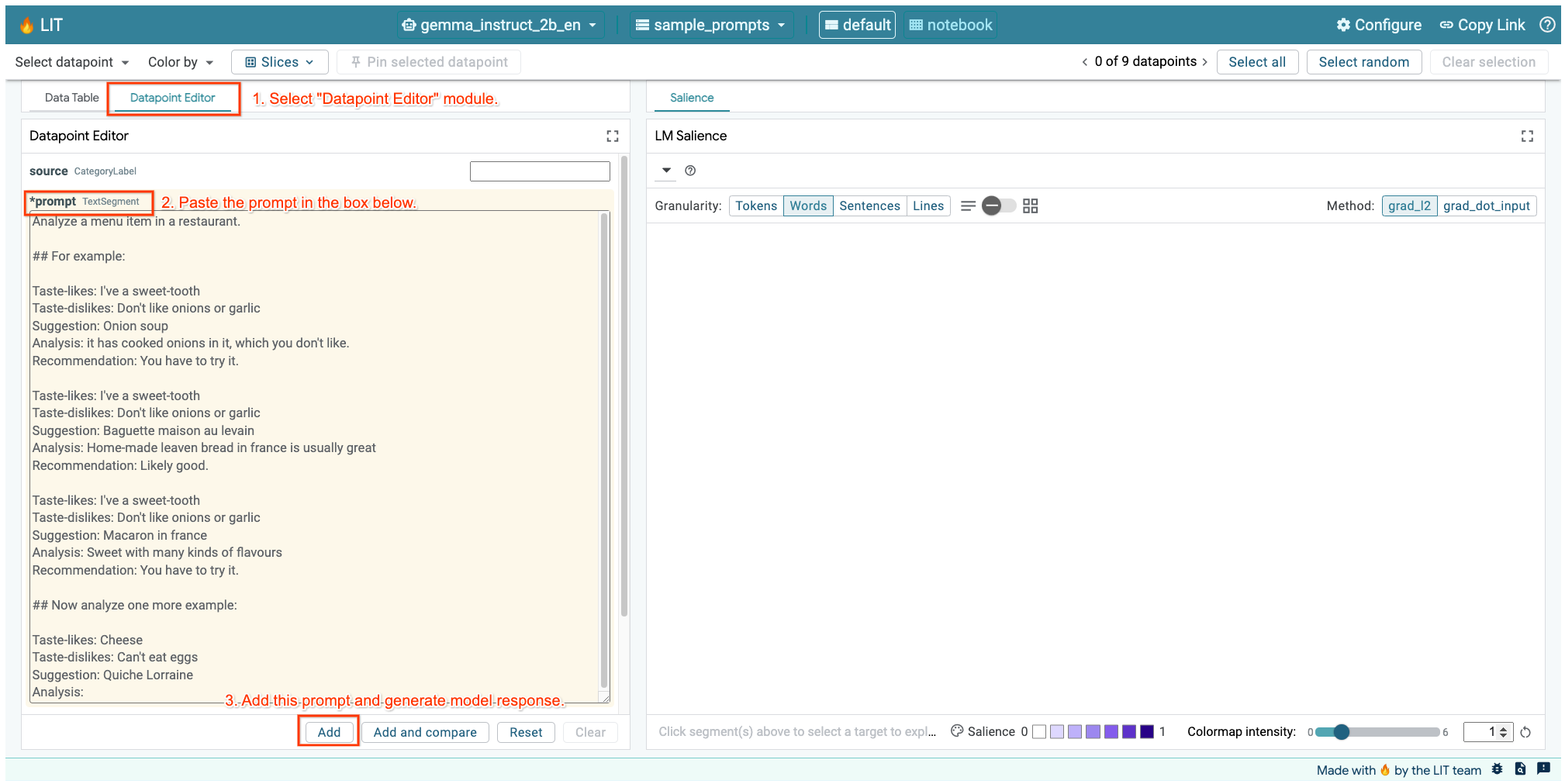
Innym sposobem jest bezpośrednie ponowne renderowanie widżetu za pomocą interesującego Cię promptu:
lit_widget.render(data=[fewshot_mistake_example])
Zwróć uwagę na zaskakujące dokończenie modelu:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
Dlaczego model sugeruje Ci zjedzenie czegoś, czego wyraźnie nie możesz jeść?
Istotność sekwencji może pomóc w wykryciu głównego problemu, który występuje w przykładach z kilkoma próbkami. W pierwszym przykładzie rozumowanie w sekcji analizy it has cooked onions in it, which you don't like nie pasuje do ostatecznej rekomendacji You have to try it.
W module LM Salience (Istotność LM) wybierz „Sentences” (Zdania), a następnie wiersz rekomendacji. Interfejs powinien teraz wyglądać tak:
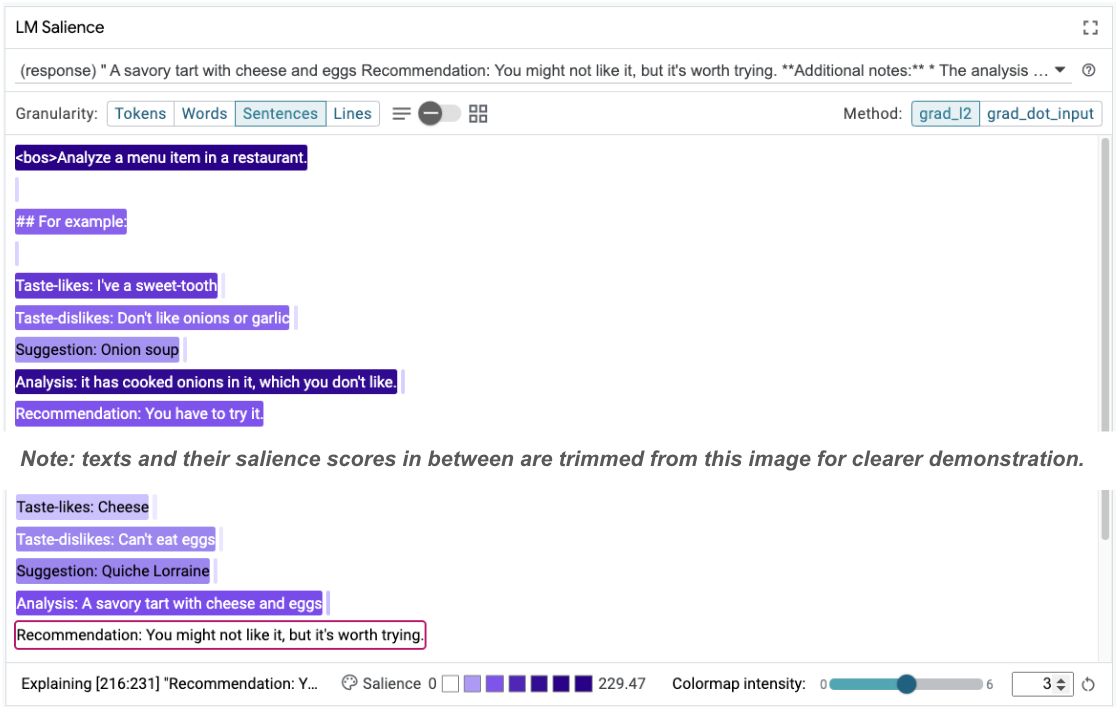
Wskazuje to na błąd ludzki: przypadkowe skopiowanie i wklejenie części rekomendacji oraz brak jej aktualizacji.
Teraz poprawmy „Rekomendację” w pierwszym przykładzie na Avoid i spróbujmy jeszcze raz. LIT ma ten przykład wstępnie załadowany w przykładowych promptach, więc możesz użyć tej małej funkcji użytkowej, aby go pobrać:
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
Teraz dokończenie modelu wygląda tak:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
Ważna lekcja, jaką można wyciągnąć z tego przykładu, to: wczesne prototypowanie pomaga wykryć ryzyko, o którym wcześniej nie pomyślisz, a podatność modeli językowych na błędy oznacza, że trzeba aktywnie projektować pod kątem błędów. Więcej informacji na ten temat znajdziesz w naszym przewodniku Ludzie + AI dotyczącym projektowania z wykorzystaniem AI.
Poprawiony prompt z kilkoma przykładami jest lepszy, ale nadal nie do końca prawidłowy: poprawnie informuje użytkownika, aby unikał jajek, ale uzasadnienie jest nieprawidłowe – mówi, że nie lubi jajek, podczas gdy użytkownik stwierdził, że nie może ich jeść. W następnej sekcji dowiesz się, jak to zrobić lepiej.
7. Testowanie hipotez w celu poprawy działania modelu
LIT umożliwia testowanie zmian w promptach w ramach tego samego interfejsu. W tym przypadku przetestujesz dodanie konstytucji, aby poprawić działanie modelu. Konstytucje to prompty projektowe zawierające zasady, które pomagają kierować generowaniem modelu. Nowsze metody umożliwiają nawet interaktywne wyprowadzanie zasad konstytucyjnych.
Wykorzystajmy ten pomysł, aby jeszcze bardziej ulepszyć prompt. Dodaj na początku promptu sekcję z zasadami generowania. Prompt będzie teraz zaczynać się tak:
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
Po tej aktualizacji przykład można uruchomić ponownie i zaobserwować zupełnie inne dane wyjściowe:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
Możesz ponownie sprawdzić istotność prompta, aby dowiedzieć się, dlaczego ta zmiana nastąpiła:
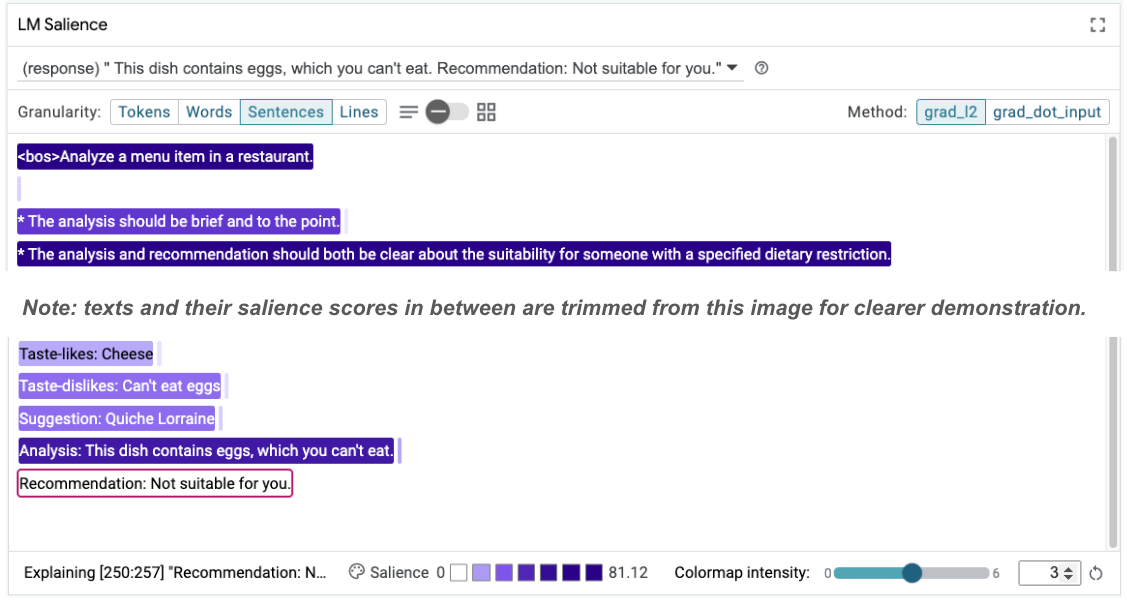
Zwróć uwagę, że rekomendacja jest znacznie bezpieczniejsza. Poza tym na komunikat „Nieodpowiednie dla Ciebie” wpływa zasada jasnego określania przydatności zgodnie z ograniczeniami dietetycznymi oraz analiza (tzw. ciąg myślowy). Daje to dodatkową pewność, że wynik jest osiągany z właściwego powodu.
8. Włączanie zespołów nietechnicznych do testowania i eksploracji modeli
Interpretacja powinna być wynikiem pracy zespołowej, obejmującej wiedzę z zakresu XAI, zasad, prawa i innych dziedzin.
Interakcja z modelami na wczesnych etapach rozwoju tradycyjnie wymagała znacznej wiedzy technicznej, co utrudniało niektórym współpracownikom dostęp do nich i ich testowanie. Do tej pory nie było narzędzi, które umożliwiałyby tym zespołom udział w początkowych fazach prototypowania.
Mamy nadzieję, że dzięki LIT ten paradygmat może się zmienić. Jak widać w tym samouczku, wizualny charakter LIT i interaktywna możliwość analizowania istotności oraz przeglądania przykładów mogą pomóc różnym zainteresowanym stronom w udostępnianiu i przekazywaniu wyników. Dzięki temu możesz zaprosić do eksplorowania, testowania i debugowania modelu bardziej zróżnicowane grono współpracowników. Zapoznanie ich z tymi metodami technicznymi może pomóc im lepiej zrozumieć, jak działają modele. Dodatkowo bardziej zróżnicowany zestaw umiejętności w zakresie testowania wczesnych modeli może pomóc w odkryciu niepożądanych wyników, które można ulepszyć.
9. Podsumowanie
Podsumowując:
- Interfejs LIT umożliwia interaktywne wykonywanie modelu, dzięki czemu użytkownicy mogą bezpośrednio generować dane wyjściowe oraz testować scenariusze „co by było, gdyby”. Jest to szczególnie przydatne do testowania różnych wariantów promptów.
- Moduł LM Salience zapewnia wizualną reprezentację istotności i umożliwia kontrolowanie szczegółowości danych, dzięki czemu możesz komunikować się za pomocą konstrukcji skoncentrowanych na człowieku (np. zdań i słów) zamiast konstrukcji skoncentrowanych na modelu (np. tokenów).
Gdy w ocenach modelu znajdziesz problematyczne przykłady, przenieś je do LIT, aby je debugować. Zacznij od analizy największej sensownej jednostki treści, która jest logicznie powiązana z zadaniem modelowania. Użyj wizualizacji, aby sprawdzić, gdzie model prawidłowo lub nieprawidłowo odnosi się do treści promptu, a następnie przejdź do mniejszych jednostek treści, aby dokładniej opisać nieprawidłowe zachowanie, które obserwujesz, i zidentyfikować możliwe rozwiązania.
Na koniec: Lit stale się rozwija. Więcej informacji o naszych funkcjach i swoje sugestie znajdziesz tutaj.