
1. परिचय
जनरेटिव एआई वाले प्रॉडक्ट, अपेक्षाकृत नए हैं. साथ ही, किसी ऐप्लिकेशन के काम करने का तरीका, सॉफ़्टवेयर के पुराने वर्शन की तुलना में ज़्यादा अलग हो सकता है. इसलिए, यह ज़रूरी है कि इस्तेमाल किए जा रहे मशीन लर्निंग मॉडल की जांच की जाए, मॉडल के व्यवहार के उदाहरणों की जांच की जाए, और अचानक मिले नतीजों की जांच की जाए.
Learning Interpretability Tool (LIT; वेबसाइट, GitHub) एक ऐसा प्लैटफ़ॉर्म है जिसका इस्तेमाल, एमएल मॉडल को डीबग करने और उनका विश्लेषण करने के लिए किया जाता है. इससे यह समझने में मदद मिलती है कि एमएल मॉडल, किसी खास तरीके से क्यों और कैसे काम करते हैं.
इस कोडलैब में, आपको LIT का इस्तेमाल करने का तरीका बताया जाएगा. इससे आपको Google के Gemma मॉडल का ज़्यादा से ज़्यादा फ़ायदा मिल पाएगा. इस कोडलैब में, अलग-अलग प्रॉम्प्ट इंजीनियरिंग के तरीकों का विश्लेषण करने के लिए, सीक्वेंस सैलिएंस का इस्तेमाल करने का तरीका बताया गया है. यह एक ऐसी तकनीक है जिससे मॉडल के फ़ैसलों को समझा जा सकता है.
सीखने के लक्ष्य:
- सीक्वेंस की अहमियत और मॉडल के विश्लेषण में इसके इस्तेमाल के बारे में जानकारी.
- Gemma के लिए LIT को सेट अप करना, ताकि वह प्रॉम्प्ट के आउटपुट और सीक्वेंस की अहमियत का हिसाब लगा सके.
- एलएम सैलिएंस मॉड्यूल का इस्तेमाल करके, सीक्वेंस सैलिएंस का इस्तेमाल करना. इससे मॉडल के आउटपुट पर प्रॉम्प्ट डिज़ाइन के असर को समझा जा सकता है.
- एलआईटी में, प्रॉम्प्ट को बेहतर बनाने के लिए हाइपोथीसिस की टेस्टिंग करना और उनके असर को देखना.
ध्यान दें: इस कोडलैब में, Gemma के KerasNLP को लागू करने और बैकएंड के लिए TensorFlow v2 का इस्तेमाल किया गया है. हमारा सुझाव है कि आप जीपीयू कर्नल का इस्तेमाल करें.
2. मॉडल के विश्लेषण में, सीक्वेंस की अहमियत और उसके इस्तेमाल
टेक्स्ट-टू-टेक्स्ट जनरेटिव मॉडल, जैसे कि Gemma, टोकनाइज़ किए गए टेक्स्ट के तौर पर इनपुट सीक्वेंस लेते हैं. इसके बाद, ऐसे नए टोकन जनरेट करते हैं जो उस इनपुट के हिसाब से फ़ॉलो-अप या पूरे किए गए टेक्स्ट होते हैं. यह जनरेशन, एक बार में एक टोकन के हिसाब से होता है. इसमें, हर नए जनरेट किए गए टोकन को इनपुट के साथ-साथ पिछले जनरेशन में शामिल किया जाता है. ऐसा तब तक होता है, जब तक मॉडल किसी स्टॉपिंग कंडीशन तक नहीं पहुंच जाता. उदाहरण के लिए, जब मॉडल एंड-ऑफ़-सीक्वेंस (ईओएस) टोकन जनरेट करता है या पहले से तय की गई ज़्यादा से ज़्यादा लंबाई तक पहुंच जाता है.
सैलियंस के तरीके, एक्सप्लनेबल एआई (एक्सएआई) की तकनीकों का एक क्लास है. इससे आपको यह पता चल सकता है कि इनपुट के कौनसे हिस्से, मॉडल के आउटपुट के अलग-अलग हिस्सों के लिए अहम हैं. LIT, क्लासिफ़िकेशन से जुड़े कई कामों के लिए, अहम जानकारी निकालने के तरीके इस्तेमाल करता है. इनसे यह पता चलता है कि इनपुट टोकन के क्रम का, अनुमानित लेबल पर क्या असर पड़ता है. सीक्वेंस सैलियंस, इन तरीकों को टेक्स्ट-टू-टेक्स्ट जनरेटिव मॉडल के लिए सामान्य बनाता है. साथ ही, जनरेट किए गए टोकन पर पिछले टोकन के असर के बारे में बताता है.
यहां क्रम के हिसाब से शब्दों के महत्व का पता लगाने के लिए, Grad L2 Norm तरीके का इस्तेमाल किया जाएगा. यह मॉडल के ग्रेडिएंट का विश्लेषण करता है. साथ ही, यह बताता है कि हर पिछले टोकन का आउटपुट पर कितना असर पड़ता है. यह तरीका आसान और असरदार है. साथ ही, यह दिखाया गया है कि यह क्लासिफ़िकेशन और अन्य सेटिंग में अच्छा परफ़ॉर्म करता है. सैलियंस स्कोर जितना ज़्यादा होगा, असर उतना ही ज़्यादा होगा. इस तरीके का इस्तेमाल LIT में किया जाता है, क्योंकि इसे अच्छी तरह से समझा जाता है. साथ ही, व्याख्या करने से जुड़ी रिसर्च कम्यूनिटी में इसका इस्तेमाल बड़े पैमाने पर किया जाता है.
ग्रेडिएंट पर आधारित, ज़्यादा बेहतर सैलिएंस के तरीकों में Grad ⋅ Input और इंटिग्रेटेड ग्रेडिएंट शामिल हैं. इसके अलावा, LIME और SHAP जैसे एब्लेशन-आधारित तरीके भी उपलब्ध हैं. ये ज़्यादा भरोसेमंद हो सकते हैं, लेकिन इनकी गणना करना काफ़ी महंगा होता है. सैलियंस के अलग-अलग तरीकों की तुलना करने के बारे में ज़्यादा जानने के लिए, यह लेख पढ़ें.
सैलियंस के बारे में जानकारी देने वाले इस इंटरैक्टिव एक्सप्लोरेबल में, सैलियंस के तरीकों के विज्ञान के बारे में ज़्यादा जानें.
3. इंपोर्ट, एनवायरमेंट, और अन्य सेटअप कोड
इस कोडलैब को नए Colab में इस्तेमाल करना सबसे अच्छा है. हम ऐक्सलरेटर रनटाइम का इस्तेमाल करने का सुझाव देते हैं, क्योंकि आपको मॉडल को मेमोरी में लोड करना होगा. हालांकि, ध्यान रखें कि ऐक्सलरेटर के विकल्प समय के साथ बदलते रहते हैं और इन पर कुछ पाबंदियां लागू होती हैं. अगर आपको ज़्यादा दमदार ऐक्सलरेटर का ऐक्सेस चाहिए, तो Colab की पैसे चुकाकर ली जाने वाली सदस्यताएं लें. इसके अलावा, अगर आपकी मशीन में सही जीपीयू है, तो लोकल रनटाइम का इस्तेमाल किया जा सकता है.
ध्यान दें: आपको फ़ॉर्म की कुछ चेतावनियां दिख सकती हैं
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
इन्हें अनदेखा किया जा सकता है.
LIT और Keras NLP इंस्टॉल करना
इस कोडलैब के लिए, आपको keras (3) keras-nlp (0.14.) और lit-nlp (1.2) के नए वर्शन की ज़रूरत होगी. साथ ही, बेस मॉडल डाउनलोड करने के लिए, Kaggle खाते की ज़रूरत होगी.
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
Kaggle का ऐक्सेस
Kaggle खाते से पुष्टि करने के लिए, इनमें से कोई एक तरीका अपनाएं:
- अपने क्रेडेंशियल को किसी फ़ाइल में सेव करें, जैसे कि
~/.kaggle/kaggle.json; KAGGLE_USERNAMEऔरKAGGLE_KEYएनवायरमेंट वैरिएबल का इस्तेमाल करें; या- इसे Google Colab जैसे इंटरैक्टिव Python एनवायरमेंट में चलाएं.
import kagglehub
kagglehub.login()
ज़्यादा जानकारी के लिए, kagglehub दस्तावेज़ देखें. साथ ही, Gemma के लाइसेंस समझौते को स्वीकार करना न भूलें.
Keras को कॉन्फ़िगर करना
Keras 3, डीप लर्निंग के कई बैकएंड के साथ काम करता है. इनमें TensorFlow (डिफ़ॉल्ट), PyTorch, और JAX शामिल हैं. बैकएंड को KERAS_BACKEND एनवायरमेंट वैरिएबल का इस्तेमाल करके कॉन्फ़िगर किया जाता है. Keras लाइब्रेरी को इंपोर्ट करने से पहले इसे सेट करना ज़रूरी है. नीचे दिए गए कोड स्निपेट में बताया गया है कि इंटरैक्टिव Python एनवायरमेंट में इस वैरिएबल को कैसे सेट किया जाता है.
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
4. LIT सेट अप करना
LIT का इस्तेमाल Python Notebooks में या वेब सर्वर के ज़रिए किया जा सकता है. यह Codelab, नोटबुक के इस्तेमाल के उदाहरण पर आधारित है. हमारा सुझाव है कि आप Google Colab में इसका इस्तेमाल करें.
इस कोडलैब में, KerasNLP प्रीसेट का इस्तेमाल करके, Gemma v2 2B IT को लोड किया जाएगा. यहां दिए गए स्निपेट में, Gemma को शुरू किया गया है. साथ ही, LIT Notebook विजेट में डेटासेट का एक उदाहरण लोड किया गया है.
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
विजेट को कॉन्फ़िगर करने के लिए, दो ज़रूरी पोज़ीशनल आर्ग्युमेंट को पास की गई वैल्यू में बदलाव करें:
datasets_config: स्ट्रिंग की एक सूची, जिसमें डेटासेट के नाम और लोड करने के लिए पाथ शामिल होते हैं. इन्हें "dataset:path" के तौर पर दिखाया जाता है. यहां पाथ, यूआरएल या स्थानीय फ़ाइल का पाथ हो सकता है. नीचे दिए गए उदाहरण में, LIT डिस्ट्रिब्यूशन में दिए गए उदाहरण के तौर पर दिए गए प्रॉम्प्ट लोड करने के लिए, खास वैल्यूsample_promptsका इस्तेमाल किया गया है.models_config: स्ट्रिंग की एक सूची, जिसमें मॉडल के नाम और लोड करने के पाथ शामिल होते हैं. इन्हें "model:path" के तौर पर दिखाया जाता है. इसमें पाथ, यूआरएल, स्थानीय फ़ाइल का पाथ या कॉन्फ़िगर किए गए डीप लर्निंग फ़्रेमवर्क के लिए प्रीसेट का नाम हो सकता है.
जब LIT को आपकी पसंद के मॉडल का इस्तेमाल करने के लिए कॉन्फ़िगर कर दिया जाए, तब अपने नोटबुक में विजेट को रेंडर करने के लिए, यहां दिए गए कोड स्निपेट को चलाएं.
lit_widget.render(open_in_new_tab=True)
अपने डेटा का इस्तेमाल करना
टेक्स्ट से टेक्स्ट जनरेट करने वाले मॉडल के तौर पर, Gemma टेक्स्ट इनपुट लेता है और टेक्स्ट आउटपुट जनरेट करता है. LIT, opinionated API का इस्तेमाल करता है, ताकि लोड किए गए डेटासेट के स्ट्रक्चर के बारे में मॉडल को बताया जा सके. LIT में मौजूद एलएलएम, ऐसे डेटासेट के साथ काम करने के लिए डिज़ाइन किए गए हैं जिनमें दो फ़ील्ड होते हैं:
prompt: मॉडल को दिया गया इनपुट, जिससे टेक्स्ट जनरेट किया जाएगा; औरtarget: यह एक वैकल्पिक टारगेट सीक्वेंस है. जैसे, इंसानों की ओर से की गई रेटिंग के आधार पर "ग्राउंड ट्रुथ" जवाब या किसी दूसरे मॉडल से पहले से जनरेट किया गया जवाब.
LIT में sample_prompts का एक छोटा सेट शामिल है. इसमें ऐसे सोर्स के उदाहरण दिए गए हैं जो इस कोडलैब और LIT के प्रॉम्प्ट डीबग करने से जुड़े ट्यूटोरियल के साथ काम करते हैं.
- GSM8K: इसमें, कुछ उदाहरणों की मदद से ग्रेड स्कूल के गणित के सवालों को हल किया जाता है.
- Gigaword Benchmark: छोटे लेखों के कलेक्शन के लिए हेडलाइन जनरेट करना.
- संविधान के मुताबिक प्रॉम्प्ट देना: दिशा-निर्देशों/सीमाओं के साथ ऑब्जेक्ट का इस्तेमाल करने के नए आइडिया जनरेट करना.
अपने डेटा को आसानी से लोड किया जा सकता है. इसके लिए, .jsonl फ़ील्ड वाले रिकॉर्ड वाली फ़ाइल prompt और वैकल्पिक तौर पर target (उदाहरण) का इस्तेमाल किया जा सकता है. इसके अलावा, LIT के डेटासेट एपीआई का इस्तेमाल करके, किसी भी फ़ॉर्मैट से डेटा लोड किया जा सकता है.
सैंपल प्रॉम्प्ट लोड करने के लिए, नीचे दी गई सेल चलाएँ.
5. LIT में Gemma के लिए कुछ प्रॉम्प्ट का विश्लेषण करना
आज के समय में, प्रॉम्प्ट देना एक कला के साथ-साथ विज्ञान भी है. LIT, Gemma जैसे लार्ज लैंग्वेज मॉडल के लिए प्रॉम्प्ट को बेहतर बनाने में आपकी मदद कर सकता है. यहां, LIT का इस्तेमाल करके Gemma के व्यवहारों को समझने, संभावित समस्याओं का अनुमान लगाने, और इसकी सुरक्षा को बेहतर बनाने का एक उदाहरण दिया गया है.
जटिल प्रॉम्प्ट में मौजूद गड़बड़ियों की पहचान करना
एलएलएम पर आधारित प्रोटोटाइप और ऐप्लिकेशन से बेहतर नतीजे पाने के लिए, प्रॉम्प्ट देने की दो तकनीकें सबसे अहम हैं. पहली, फ़्यू-शॉट प्रॉम्प्टिंग. इसमें प्रॉम्प्ट में, एलएलएम से मिलने वाले जवाब के उदाहरण शामिल किए जाते हैं. दूसरी, चेन-ऑफ़-थॉट. इसमें एलएलएम से मिलने वाले फ़ाइनल आउटपुट से पहले, जवाब के बारे में जानकारी या तर्क शामिल किया जाता है. हालांकि, असरदार प्रॉम्प्ट बनाना अब भी मुश्किल है.
उदाहरण के लिए, किसी व्यक्ति को यह तय करने में मदद करना कि उसे अपने स्वाद के हिसाब से खाना पसंद आएगा या नहीं. शुरुआती प्रोटोटाइप के लिए, सिलसिलेवार तरीके से जवाब देने वाले प्रॉम्प्ट का टेंप्लेट कुछ ऐसा दिख सकता है:
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
क्या आपको इस प्रॉम्प्ट में मौजूद समस्याएं मिलीं? LIT, एलएम सैलिएंस मॉड्यूल की मदद से प्रॉम्प्ट की जांच करने में आपकी मदद करेगा.
6. डीबग करने के लिए, क्रम के हिसाब से अहमियत का इस्तेमाल करना
सैलियंस की गिनती सबसे छोटे लेवल पर की जाती है. इसका मतलब है कि हर इनपुट टोकन के लिए, सैलियंस की गिनती की जाती है. हालांकि, LIT टोकन-सैलियंस को ज़्यादा आसानी से समझने लायक बड़े स्पैन में एग्रीगेट कर सकता है. जैसे, लाइनें, वाक्य या शब्द. Saliency Explorable में, अहम जानकारी और इसका इस्तेमाल करके अनचाहे पूर्वाग्रहों की पहचान करने के तरीके के बारे में ज़्यादा जानें.
आइए, प्रॉम्प्ट-टेंप्लेट वैरिएबल के लिए, प्रॉम्प्ट को नया उदाहरण इनपुट देकर शुरुआत करते हैं:
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
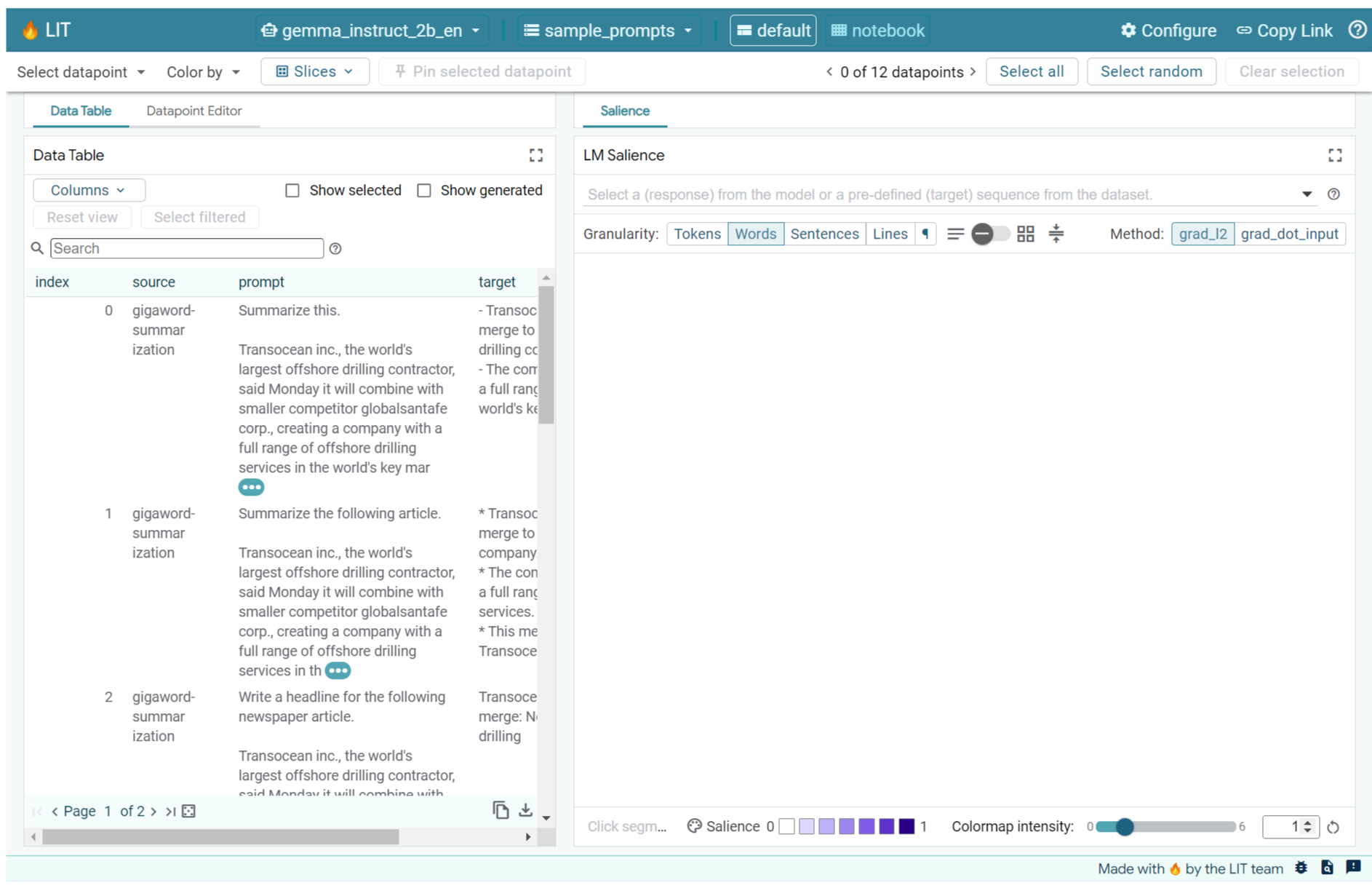
अगर आपने ऊपर वाली सेल या किसी दूसरे टैब में LIT यूज़र इंटरफ़ेस (यूआई) खोला है, तो इस प्रॉम्प्ट को जोड़ने के लिए, LIT के डेटापॉइंट एडिटर का इस्तेमाल करें:
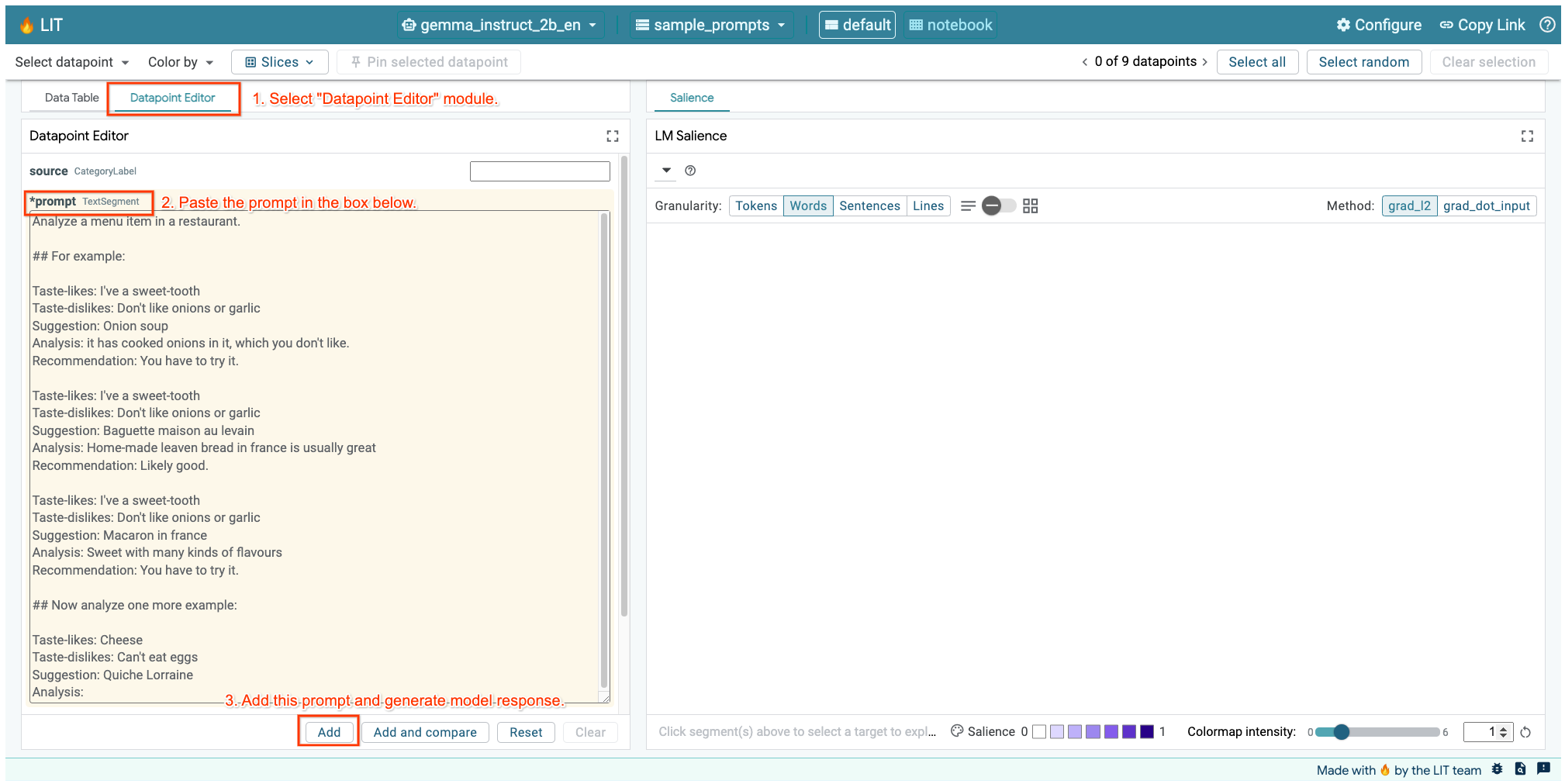
इसके अलावा, सीधे तौर पर विजेट को फिर से रेंडर किया जा सकता है. इसके लिए, आपको अपनी पसंद का प्रॉम्प्ट इस्तेमाल करना होगा:
lit_widget.render(data=[fewshot_mistake_example])
मॉडल के जवाब में मिली हैरान करने वाली जानकारी पर ध्यान दें:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
मॉडल, आपको ऐसा खाना खाने का सुझाव क्यों दे रहा है जिसे आपने साफ़ तौर पर खाने से मना किया है?
सीक्वेंस की अहमियत से, मुख्य समस्या को हाइलाइट करने में मदद मिल सकती है. यह समस्या, हमारे कुछ उदाहरणों में मौजूद है. पहले उदाहरण में, विश्लेषण सेक्शन it has cooked onions in it, which you don't like में दी गई चेन-ऑफ़-थॉट रीज़निंग, फ़ाइनल सुझाव You have to try it से मेल नहीं खाती.
एलएम सैलिएंस मॉड्यूल में, "वाक्य" चुनें. इसके बाद, सुझाव वाली लाइन चुनें. अब यूज़र इंटरफ़ेस (यूआई) ऐसा दिखेगा:
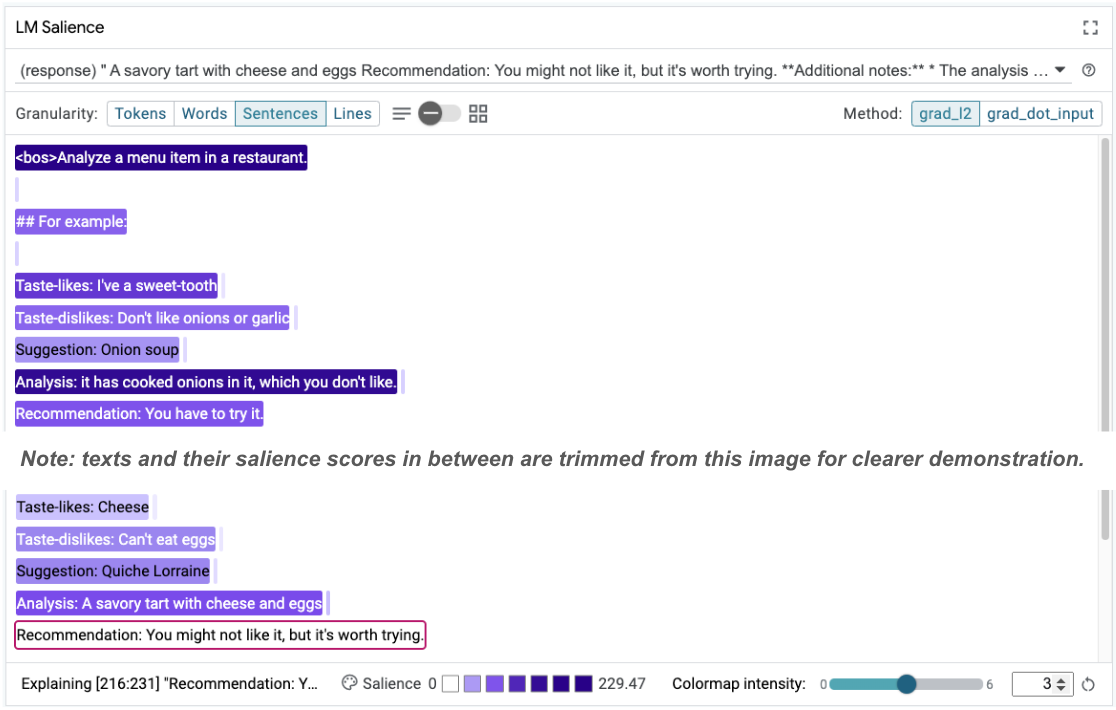
इससे पता चलता है कि किसी व्यक्ति से गलती हुई है: गलती से सुझाव वाले हिस्से को कॉपी करके चिपका दिया गया है और उसे अपडेट नहीं किया गया है!
अब पहले उदाहरण में "सुझाव" को Avoid में बदलते हैं और फिर से कोशिश करते हैं. LIT में, इस उदाहरण को सैंपल प्रॉम्प्ट में पहले से लोड किया गया है. इसलिए, इसे पाने के लिए इस छोटे से यूटिलिटी फ़ंक्शन का इस्तेमाल किया जा सकता है:
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
अब मॉडल पूरा होने की प्रोसेस यह हो जाती है:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
इससे हमें यह अहम सबक मिलता है कि प्रोटोटाइप बनाने से, उन जोखिमों के बारे में पता चलता है जिनके बारे में आपने पहले नहीं सोचा होता. साथ ही, भाषा मॉडल में गड़बड़ियां होने की वजह से, हमें पहले से ही गड़बड़ियों को ठीक करने के लिए डिज़ाइन तैयार करना होता है. इस बारे में ज़्यादा जानकारी, एआई की मदद से डिज़ाइन करने के लिए बनी हमारी People + AI Guidebook में दी गई है.
कुछ उदाहरणों के साथ दिए गए सुधारे गए प्रॉम्प्ट का जवाब बेहतर है, लेकिन यह अब भी पूरी तरह से सही नहीं है: इसमें उपयोगकर्ता को अंडे न खाने की सलाह दी गई है, लेकिन इसकी वजह सही नहीं है. इसमें कहा गया है कि उपयोगकर्ता को अंडे पसंद नहीं हैं, जबकि उपयोगकर्ता ने बताया है कि वह अंडे नहीं खा सकता. यहां दिए गए सेक्शन में, आपको बेहतर तरीके से काम करने के बारे में जानकारी मिलेगी.
7. मॉडल के व्यवहार को बेहतर बनाने के लिए हाइपोथेसिस टेस्ट करना
एलआईटी की मदद से, एक ही इंटरफ़ेस में प्रॉम्प्ट में किए गए बदलावों को टेस्ट किया जा सकता है. इस उदाहरण में, मॉडल के व्यवहार को बेहतर बनाने के लिए, संविधान को जोड़ा जाएगा. संविधान का मतलब, सिद्धांतों के साथ डिज़ाइन किए गए प्रॉम्प्ट से है. ये सिद्धांत, मॉडल को जनरेट करने में मदद करते हैं. हाल ही के तरीकों से, संवैधानिक सिद्धांतों के इंटरैक्टिव तरीके से जवाब पाने की सुविधा भी मिलती है.
इस आइडिया का इस्तेमाल करके, प्रॉम्प्ट को और बेहतर बनाते हैं. हमारे प्रॉम्प्ट में सबसे ऊपर, जनरेशन के सिद्धांतों वाला एक सेक्शन जोड़ो. अब यह इस तरह से शुरू होता है:
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
इस अपडेट के बाद, उदाहरण को फिर से चलाया जा सकता है और एक अलग आउटपुट देखा जा सकता है:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
इसके बाद, प्रॉम्प्ट की अहमियत की फिर से जांच की जा सकती है, ताकि यह पता चल सके कि यह बदलाव क्यों हो रहा है:
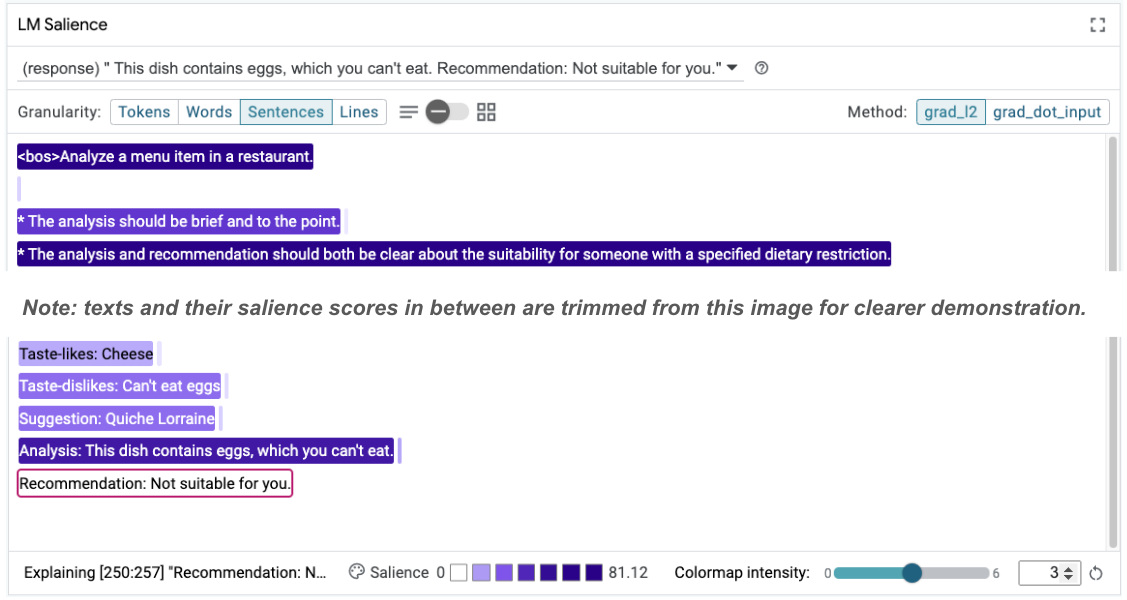
ध्यान दें कि यह सुझाव ज़्यादा सुरक्षित है. इसके अलावा, "आपके लिए सही नहीं है" जवाब, इस सिद्धांत पर आधारित होता है कि आहार से जुड़ी पाबंदी के हिसाब से, साफ़ तौर पर बताया जाए कि कोई व्यंजन आपके लिए सही है या नहीं. साथ ही, इसमें विश्लेषण (जिसे चेन ऑफ़ थॉट कहा जाता है) भी शामिल होता है. इससे यह भरोसा बढ़ता है कि जवाब सही वजह से दिया गया है.
8. मॉडल की जांच और एक्सप्लोरेशन में, नॉन-टेक्निकल टीमों को शामिल करें
व्याख्या करने की क्षमता को टीम के साथ मिलकर बेहतर बनाया जा सकता है. इसके लिए, XAI, नीति, कानूनी, और अन्य क्षेत्रों के विशेषज्ञों की ज़रूरत होती है.
डेवलपमेंट के शुरुआती चरणों में मॉडल के साथ इंटरैक्ट करने के लिए, आम तौर पर तकनीकी विशेषज्ञता की ज़रूरत होती है. इस वजह से, कुछ सहयोगियों के लिए मॉडल को ऐक्सेस करना और उनकी जांच करना मुश्किल हो जाता है. पहले, इन टीमों के पास ऐसे टूल नहीं थे जिनकी मदद से वे प्रोटोटाइपिंग के शुरुआती चरणों में हिस्सा ले सकें.
LIT के ज़रिए, उम्मीद है कि इस पैराडाइम को बदला जा सकता है. इस कोडलैब में आपने देखा कि LIT के विज़ुअल मीडियम और इंटरैक्टिव सुविधाओं की मदद से, अलग-अलग स्टेकहोल्डर, अहम जानकारी को शेयर कर सकते हैं और उसके बारे में बता सकते हैं. साथ ही, उदाहरणों को एक्सप्लोर कर सकते हैं. इससे आपको मॉडल एक्सप्लोर करने, उसकी जांच करने, और उसे डीबग करने के लिए, अलग-अलग तरह के लोगों को अपनी टीम में शामिल करने में मदद मिल सकती है. उन्हें इन तकनीकी तरीकों के बारे में बताने से, उन्हें यह समझने में मदद मिल सकती है कि मॉडल कैसे काम करते हैं. इसके अलावा, मॉडल की शुरुआती टेस्टिंग में अलग-अलग तरह की विशेषज्ञता से, ऐसे अनचाहे नतीजों का पता लगाने में भी मदद मिल सकती है जिन्हें बेहतर बनाया जा सकता है.
9. रीकैप
ज़रूरी बातों पर फिर से एक नज़र:
- LIT यूज़र इंटरफ़ेस, इंटरैक्टिव मॉडल को लागू करने के लिए एक इंटरफ़ेस उपलब्ध कराता है. इससे उपयोगकर्ता सीधे तौर पर आउटपुट जनरेट कर सकते हैं. साथ ही, "क्या होगा अगर" वाले सवालों के जवाबों की जांच कर सकते हैं. यह सुविधा, प्रॉम्प्ट के अलग-अलग वर्शन की जांच करने के लिए खास तौर पर फ़ायदेमंद है.
- एलएम सैलिएंस मॉड्यूल, सैलिएंस को विज़ुअल तौर पर दिखाता है. साथ ही, यह डेटा ग्रैन्युलैरिटी को कंट्रोल करने की सुविधा देता है, ताकि मॉडल के हिसाब से बनाए गए कंस्ट्रक्ट (जैसे, टोकन) के बजाय, इंसानों के हिसाब से बनाए गए कंस्ट्रक्ट (जैसे, वाक्य और शब्द) के बारे में बताया जा सके.
जब आपको मॉडल के आकलन में समस्या वाले उदाहरण मिलते हैं, तो उन्हें डीबग करने के लिए LIT में ले जाएं. सबसे पहले, कॉन्टेंट की सबसे बड़ी ऐसी यूनिट का विश्लेषण करें जो मॉडलिंग टास्क से तार्किक रूप से जुड़ी हो. विज़ुअलाइज़ेशन का इस्तेमाल करके देखें कि मॉडल, प्रॉम्प्ट के कॉन्टेंट पर सही तरीके से ध्यान दे रहा है या नहीं. इसके बाद, कॉन्टेंट की छोटी यूनिट में जाकर, उस गलत व्यवहार के बारे में ज़्यादा जानकारी दें जो आपको दिख रहा है, ताकि संभावित समाधानों की पहचान की जा सके.
आखिर में: Lit को लगातार बेहतर बनाया जा रहा है! हमारी सुविधाओं के बारे में ज़्यादा जानें और अपने सुझाव देने के लिए यहां क्लिक करें.