
1. Pengantar
Produk AI generatif relatif baru dan perilaku aplikasi dapat lebih bervariasi daripada bentuk software sebelumnya. Oleh karena itu, penting untuk menyelidiki model machine learning yang digunakan, memeriksa contoh perilaku model, dan menyelidiki hal-hal yang tidak terduga.
Learning Interpretability Tool (LIT; situs, GitHub) adalah platform untuk men-debug dan menganalisis model ML guna memahami alasan dan cara kerjanya.
Dalam codelab ini, Anda akan mempelajari cara menggunakan LIT untuk mendapatkan hasil maksimal dari model Gemma Google. Codelab ini menunjukkan cara menggunakan keunggulan urutan, sebuah teknik interpretasi, untuk menganalisis berbagai pendekatan rekayasa perintah.
Tujuan pembelajaran:
- Memahami keunggulan urutan dan penggunaannya dalam analisis model.
- Menyiapkan LIT untuk Gemma guna menghitung output perintah dan keunggulan urutan.
- Menggunakan keunggulan urutan melalui modul LM Salience untuk memahami dampak desain perintah pada output model.
- Menguji peningkatan perintah yang dihipotesiskan dalam LIT dan melihat dampaknya.
Perhatikan: bahwa codelab ini menggunakan implementasi KerasNLP Gemma, dan TensorFlow v2 untuk backend. Sangat disarankan untuk menggunakan kernel GPU untuk mengikuti langkah-langkahnya.
2. Keunggulan Urutan dan Penggunaannya dalam Analisis Model
Model generatif teks-ke-teks, seperti Gemma, menerima urutan input dalam bentuk teks yang ditokenisasi dan menghasilkan token baru yang biasanya merupakan lanjutan atau penyelesaian dari input tersebut. Pembuatan ini terjadi satu token dalam satu waktu, dengan menambahkan (dalam loop) setiap token yang baru dibuat ke input ditambah pembuatan sebelumnya hingga model mencapai kondisi penghentian. Contohnya termasuk saat model menghasilkan token akhir urutan (EOS) atau mencapai panjang maksimum yang telah ditentukan sebelumnya.
Metode keunggulan adalah kelas teknik AI yang dapat dijelaskan (XAI) yang dapat memberi tahu Anda bagian input mana yang penting bagi model untuk berbagai bagian outputnya. LIT mendukung metode keunggulan untuk berbagai tugas klasifikasi, yang menjelaskan dampak urutan token input pada label yang diprediksi. Keunggulan urutan menggeneralisasi metode ini ke model generatif teks-ke-teks dan menjelaskan dampak token sebelumnya pada token yang dihasilkan.
Anda akan menggunakan metode Grad L2 Norm di sini untuk keunggulan urutan, yang menganalisis gradien model dan memberikan besarnya pengaruh setiap token sebelumnya pada output. Metode ini sederhana dan efisien, serta telah terbukti berperforma baik dalam klasifikasi dan setelan lainnya. Makin besar skor keunggulan, makin tinggi pengaruhnya. Metode ini digunakan dalam LIT karena dipahami dengan baik dan digunakan secara luas di seluruh komunitas riset interpretasi.
Metode salience berbasis gradien yang lebih canggih mencakup Grad ⋅ Input dan integrated gradients. Ada juga metode berbasis penghapusan yang tersedia, seperti LIME dan SHAP, yang bisa lebih andal, tetapi secara signifikan lebih mahal untuk dihitung. Baca artikel ini untuk mengetahui perbandingan mendetail berbagai metode keunggulan.
Anda dapat mempelajari lebih lanjut metode ilmu keunggulan dalam penjelasan interaktif pengantar tentang keunggulan ini.
3. Impor, Lingkungan, dan Kode Penyiapan Lainnya
Sebaiknya ikuti codelab ini di Colab baru. Sebaiknya gunakan runtime akselerator, karena Anda akan memuat model ke dalam memori, tetapi perlu diketahui bahwa opsi akselerator bervariasi dari waktu ke waktu dan tunduk pada batasan. Colab menawarkan langganan berbayar jika Anda ingin mengakses akselerator yang lebih canggih. Atau, Anda dapat menggunakan runtime lokal jika komputer Anda memiliki GPU yang sesuai.
Catatan: Anda mungkin melihat beberapa peringatan dalam bentuk
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
Peringatan ini aman untuk diabaikan.
Menginstal LIT dan Keras NLP
Untuk codelab ini, Anda memerlukan keras (3) keras-nlp (0.14.) dan lit-nlp (1.2) versi terbaru, serta akun Kaggle untuk mendownload model dasar.
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
Akses Kaggle
Untuk melakukan autentikasi dengan Kaggle, Anda dapat:
- Simpan kredensial Anda dalam file, seperti
~/.kaggle/kaggle.json; - Gunakan variabel lingkungan
KAGGLE_USERNAMEdanKAGGLE_KEY; atau - Jalankan kode berikut di lingkungan Python interaktif, seperti Google Colab.
import kagglehub
kagglehub.login()
Lihat dokumentasi kagglehub untuk mengetahui detail selengkapnya, dan pastikan untuk menyetujui perjanjian lisensi Gemma.
Mengonfigurasi Keras
Keras 3 mendukung beberapa backend deep learning, termasuk Tensorflow (default), PyTorch, dan JAX. Backend dikonfigurasi menggunakan variabel lingkungan KERAS_BACKEND, yang harus disetel sebelum mengimpor library Keras. Cuplikan kode berikut menunjukkan cara menyetel variabel ini di lingkungan Python interaktif.
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
4. Menyiapkan LIT
LIT dapat digunakan di Notebook Python atau melalui server web. Codelab ini berfokus pada kasus penggunaan Notebook, sebaiknya ikuti langkah-langkahnya di Google Colab.
Dalam Codelab ini, Anda akan memuat Gemma v2 2B IT menggunakan preset KerasNLP. Cuplikan berikut menginisialisasi Gemma dan memuat contoh set data di widget Notebook LIT.
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
Anda dapat mengonfigurasi widget dengan mengubah nilai yang diteruskan ke dua argumen posisi yang diperlukan:
datasets_config: Daftar string yang berisi nama set data dan jalur yang akan dimuat, sebagai "dataset:path", dengan jalur dapat berupa URL atau jalur file lokal. Contoh di bawah menggunakan nilai khusus,sample_prompts, untuk memuat contoh perintah yang disediakan dalam distribusi LIT.models_config: Daftar string yang berisi nama model dan jalur untuk dimuat, sebagai "model:path", dengan jalur dapat berupa URL, jalur file lokal, atau nama preset untuk framework deep learning yang dikonfigurasi.
Setelah Anda mengonfigurasi LIT untuk menggunakan model yang Anda minati, jalankan cuplikan kode berikut untuk merender widget di Notebook Anda.
lit_widget.render(open_in_new_tab=True)
Menggunakan Data Anda Sendiri
Sebagai model generatif teks-ke-teks, Gemma menerima input teks dan menghasilkan output teks. LIT menggunakan API yang memiliki opini untuk mengomunikasikan struktur set data yang dimuat ke model. LLM di LIT dirancang untuk bekerja dengan set data yang menyediakan dua kolom:
prompt: Input ke model yang akan digunakan untuk membuat teks; dantarget: Urutan target opsional, seperti respons "kebenaran dasar" dari pemberi rating manusia atau respons yang telah dibuat sebelumnya dari model lain.
LIT menyertakan sekumpulan kecil sample_prompts dengan contoh dari sumber berikut yang mendukung Codelab ini dan tutorial penelusuran kesalahan perintah yang diperluas di LIT.
- GSM8K: Menyelesaikan soal matematika sekolah dasar dengan contoh sedikit-shot.
- Tolok Ukur Gigaword: Pembuatan judul untuk kumpulan artikel singkat.
- Perintah Konstitusional (Constitutional Prompting): Menghasilkan ide baru tentang cara menggunakan objek dengan pedoman/batasan.
Anda juga dapat memuat data Anda sendiri dengan mudah, baik sebagai file .jsonl yang berisi rekaman dengan kolom prompt dan opsional target (contoh), atau dari format apa pun dengan menggunakan Dataset API LIT.
Jalankan sel di bawah untuk memuat contoh perintah.
5. Menganalisis Perintah Few Shot untuk Gemma di LIT
Saat ini, penulisan perintah adalah seni sekaligus sains, dan LIT dapat membantu Anda meningkatkan perintah secara empiris untuk model bahasa besar, seperti Gemma. Selanjutnya, Anda akan melihat contoh cara penggunaan LIT untuk mempelajari perilaku Gemma, mengantisipasi potensi masalah, dan meningkatkan keamanannya.
Mengidentifikasi kesalahan dalam perintah yang kompleks
Dua teknik perintah yang paling penting untuk prototipe dan aplikasi berbasis LLM berkualitas tinggi adalah perintah beberapa contoh (termasuk contoh perilaku yang diinginkan dalam perintah) dan rantai pemikiran (termasuk bentuk penjelasan atau penalaran sebelum output akhir LLM). Namun, membuat perintah yang efektif sering kali masih sulit.
Pertimbangkan contoh membantu seseorang menilai apakah mereka akan menyukai makanan berdasarkan selera mereka. Template prompt chain-of-thought prototipe awal mungkin terlihat seperti ini:
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
Apakah Anda melihat masalah pada perintah ini? LIT akan membantu Anda memeriksa perintah dengan modul Keunggulan LM.
6. Menggunakan keunggulan urutan untuk proses debug
Keutamaan dihitung pada tingkat terkecil yang memungkinkan (yaitu, untuk setiap token input), tetapi LIT dapat menggabungkan keutamaan token ke dalam rentang yang lebih besar dan lebih mudah ditafsirkan, seperti baris, kalimat, atau kata. Pelajari lebih lanjut keunggulan dan cara menggunakannya untuk mengidentifikasi bias yang tidak disengaja di Saliency Explorable kami.
Mari kita mulai dengan memberikan contoh input baru untuk variabel template perintah:
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
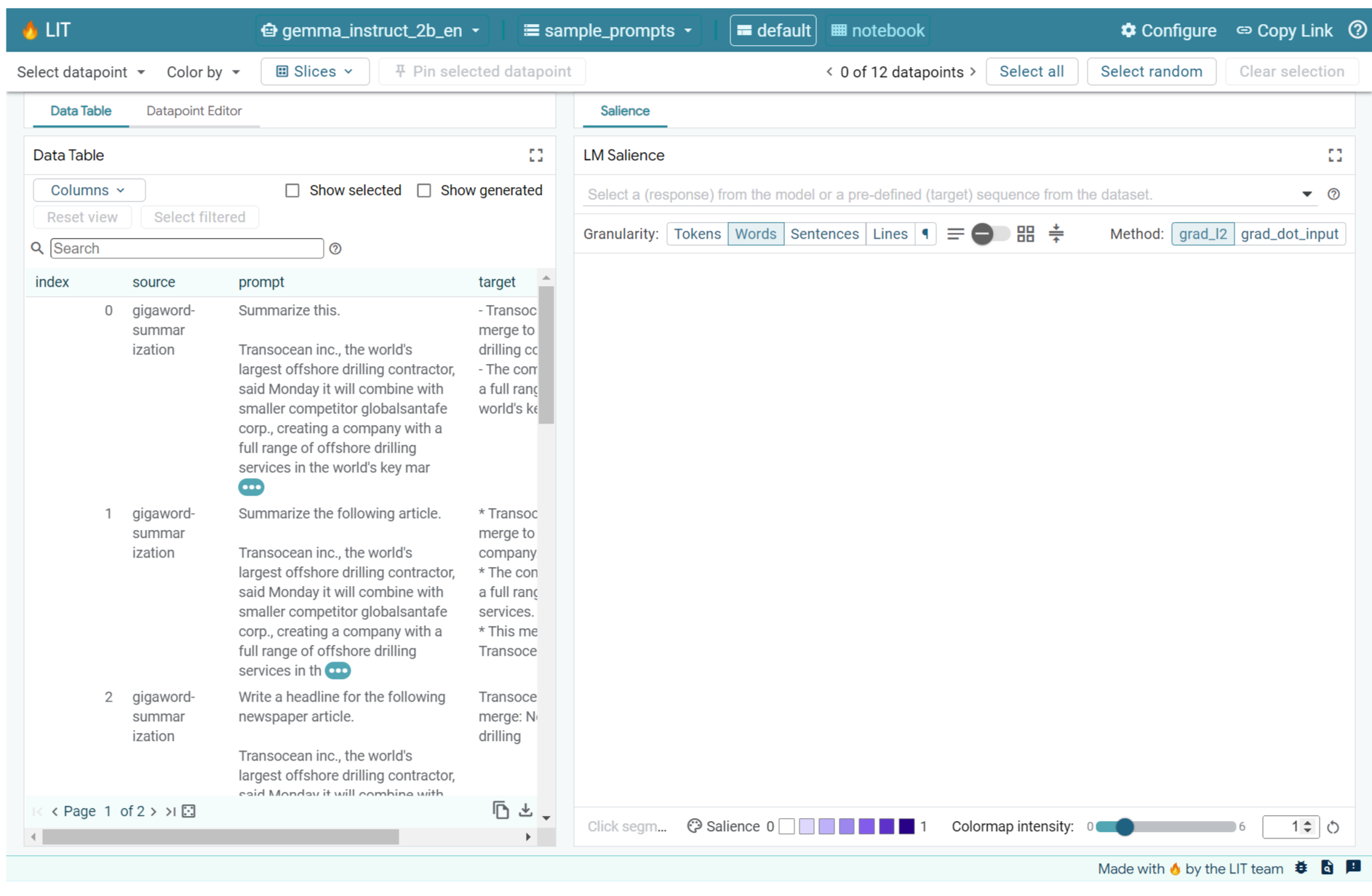
Jika Anda membuka UI LIT di sel di atas atau di tab terpisah, Anda dapat menggunakan Datapoint Editor LIT untuk menambahkan perintah ini:
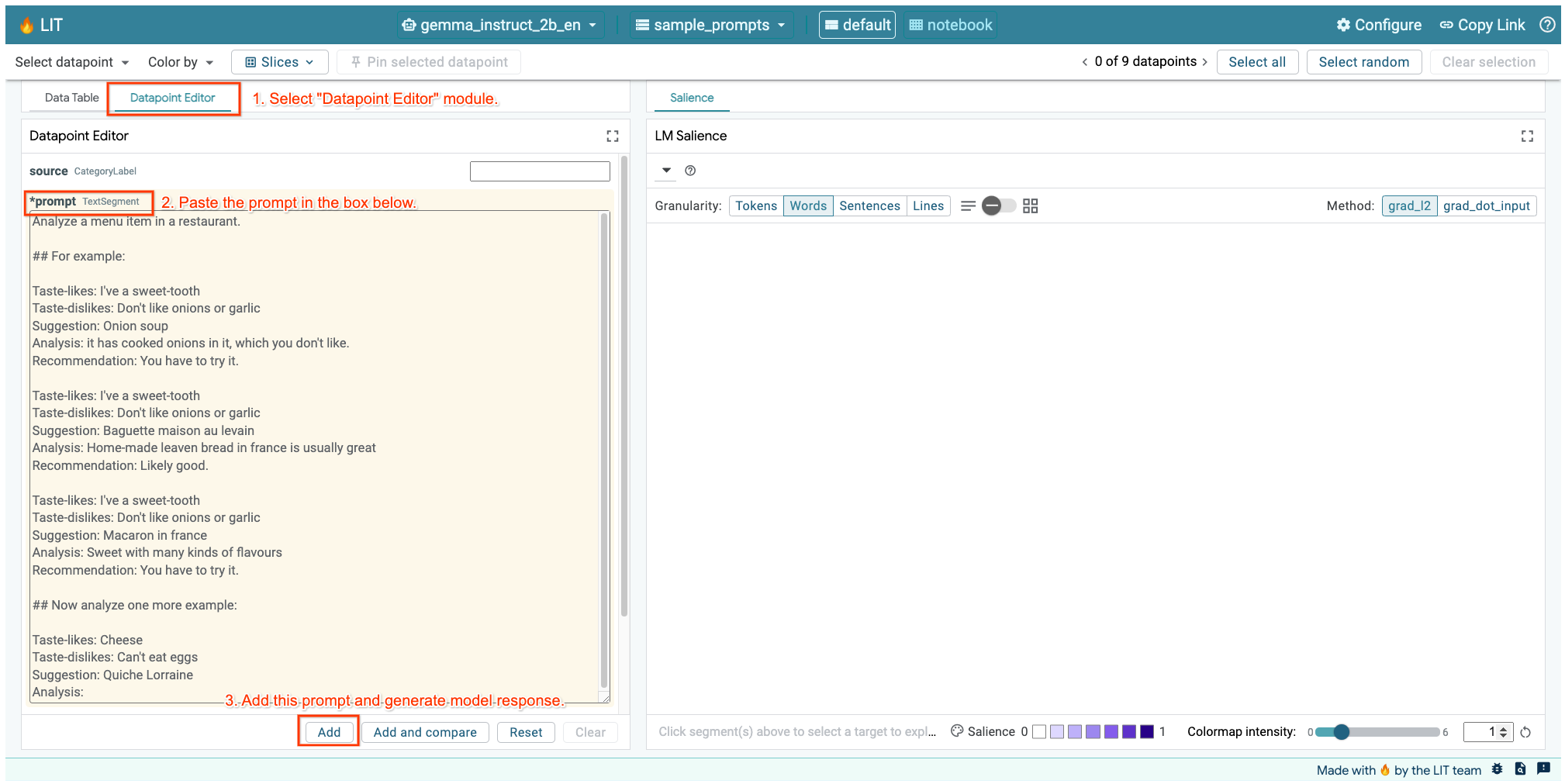
Cara lainnya adalah merender ulang widget secara langsung dengan perintah yang diinginkan:
lit_widget.render(data=[fewshot_mistake_example])
Perhatikan penyelesaian model yang mengejutkan:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
Mengapa model menyarankan Anda makan sesuatu yang jelas-jelas Anda katakan tidak bisa Anda makan?
Keunggulan urutan dapat membantu menyoroti masalah utama, yang ada dalam contoh sedikit data kami. Dalam contoh pertama, penalaran rantai pikiran di bagian analisis it has cooked onions in it, which you don't like tidak sesuai dengan rekomendasi akhir You have to try it.
Di modul LM Salience, pilih "Sentences", lalu pilih garis rekomendasi. UI sekarang akan terlihat seperti berikut:
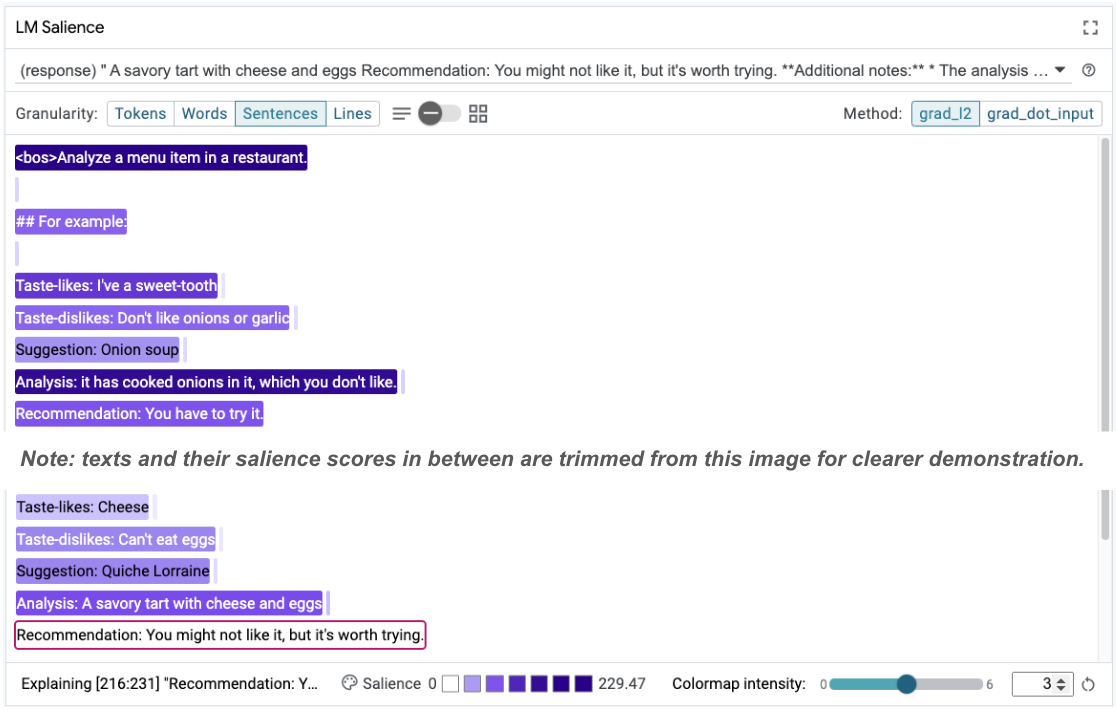
Hal ini menunjukkan kesalahan manusia: penyalinan dan penempelan bagian rekomendasi secara tidak sengaja dan tidak memperbaruinya.
Sekarang, mari kita koreksi "Rekomendasi" dalam contoh pertama menjadi Avoid, lalu coba lagi. LIT telah memuat contoh ini sebelumnya dalam perintah contoh, sehingga Anda dapat menggunakan fungsi utilitas kecil ini untuk mengambilnya:
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
Sekarang penyelesaian model menjadi:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
Pelajaran penting yang dapat diambil dari hal ini adalah: prototipe awal membantu mengungkap risiko yang mungkin tidak Anda pikirkan sebelumnya, dan sifat model bahasa yang rentan terhadap kesalahan berarti seseorang harus secara proaktif mendesain untuk mengatasi kesalahan. Pembahasan lebih lanjut tentang hal ini dapat ditemukan dalam Buku Panduan People + AI kami untuk mendesain dengan AI.
Meskipun perintah beberapa contoh yang telah dikoreksi lebih baik, perintah tersebut masih belum tepat: perintah tersebut dengan benar memberi tahu pengguna untuk menghindari telur, tetapi alasannya tidak tepat, perintah tersebut mengatakan bahwa pengguna tidak menyukai telur, padahal pengguna telah menyatakan bahwa mereka tidak dapat makan telur. Di bagian berikut, Anda akan melihat cara meningkatkan kualitas.
7. Menguji hipotesis untuk meningkatkan kualitas perilaku model
LIT memungkinkan Anda menguji perubahan pada perintah dalam antarmuka yang sama. Dalam contoh ini, Anda akan menguji penambahan konstitusi untuk meningkatkan perilaku model. Konstitusi merujuk pada perintah desain dengan prinsip-prinsip untuk membantu memandu pembuatan model. Metode terbaru bahkan memungkinkan derivasi interaktif prinsip konstitusional.
Mari kita gunakan ide ini untuk membantu meningkatkan kualitas perintah lebih lanjut. Tambahkan bagian dengan prinsip-prinsip untuk generasi di bagian atas perintah kita, yang sekarang dimulai sebagai berikut:
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
Dengan update ini, contoh dapat dijalankan ulang dan menghasilkan output yang sangat berbeda:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
Kemudian, keunggulan perintah dapat diperiksa ulang untuk membantu memahami alasan perubahan ini terjadi:
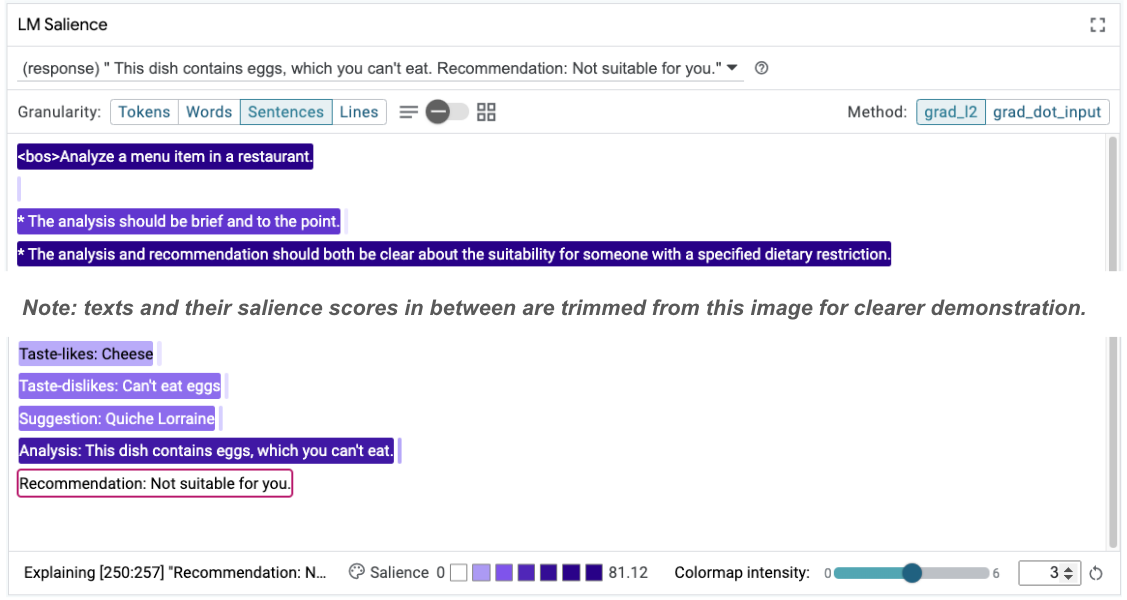
Perhatikan bahwa rekomendasi ini jauh lebih aman. Selain itu, "Tidak cocok untuk Anda" dipengaruhi oleh prinsip menyatakan kesesuaian dengan jelas sesuai dengan batasan diet, beserta analisisnya (yang disebut rantai pemikiran). Hal ini membantu memberikan keyakinan tambahan bahwa output terjadi karena alasan yang tepat.
8. Sertakan tim non-teknis dalam penyelidikan dan eksplorasi model
Interpretasi dimaksudkan sebagai upaya tim, yang mencakup keahlian di bidang XAI, kebijakan, hukum, dan lainnya.
Berinteraksi dengan model pada tahap awal pengembangan secara tradisional memerlukan keahlian teknis yang signifikan, sehingga menyulitkan beberapa kolaborator untuk mengakses dan menyelidikinya. Secara historis, tidak ada alat yang memungkinkan tim ini berpartisipasi dalam fase pembuatan prototipe awal.
Melalui LIT, diharapkan paradigma ini dapat berubah. Seperti yang telah Anda lihat melalui codelab ini, media visual dan kemampuan interaktif LIT untuk memeriksa keunggulan dan menjelajahi contoh dapat membantu berbagai pemangku kepentingan membagikan dan mengomunikasikan temuan. Hal ini memungkinkan Anda melibatkan lebih banyak rekan tim dengan latar belakang yang beragam untuk eksplorasi, penyelidikan, dan proses debug model. Mengekspos mereka ke metode teknis ini dapat meningkatkan pemahaman mereka tentang cara kerja model. Selain itu, serangkaian keahlian yang lebih beragam dalam pengujian model awal juga dapat membantu mengungkap hasil yang tidak diinginkan yang dapat ditingkatkan.
9. Rangkuman
Ringkasnya:
- UI LIT menyediakan antarmuka untuk eksekusi model interaktif, sehingga memungkinkan pengguna menghasilkan output secara langsung dan menguji skenario "bagaimana jika". Hal ini sangat berguna untuk menguji berbagai variasi perintah.
- Modul Kebermaknaan LM memberikan representasi visual kebermaknaan, dan memberikan perincian data yang dapat dikontrol sehingga Anda dapat berkomunikasi tentang konstruksi yang berpusat pada manusia (misalnya, kalimat dan kata) alih-alih konstruksi yang berpusat pada model (misalnya, token).
Saat Anda menemukan contoh bermasalah dalam evaluasi model, masukkan contoh tersebut ke LIT untuk di-debug. Mulailah dengan menganalisis unit konten terbesar yang masuk akal yang dapat Anda pikirkan dan secara logis terkait dengan tugas pemodelan, gunakan visualisasi untuk melihat di mana model secara benar atau salah memperhatikan konten perintah, lalu lihat lebih dalam unit konten yang lebih kecil untuk lebih menjelaskan perilaku salah yang Anda lihat guna mengidentifikasi kemungkinan perbaikan.
Terakhir: Lit terus ditingkatkan! Pelajari lebih lanjut fitur kami dan sampaikan saran Anda di sini.