
1. Einführung
Produkte mit generativer KI sind relativ neu und das Verhalten einer Anwendung kann stärker variieren als bei früheren Softwareformen. Daher ist es wichtig, die verwendeten Modelle für maschinelles Lernen zu untersuchen, Beispiele für das Verhalten des Modells zu analysieren und Überraschungen zu untersuchen.
Das Learning Interpretability Tool (LIT; Website, GitHub) ist eine Plattform zum Debuggen und Analysieren von ML-Modellen, um zu verstehen, warum und wie sie sich so verhalten, wie sie es tun.
In diesem Codelab erfahren Sie, wie Sie LIT verwenden, um mehr aus dem Gemma-Modell von Google herauszuholen. In diesem Codelab wird gezeigt, wie Sie mit der Sequenz-Salienz, einer Interpretierbarkeitstechnik, verschiedene Prompt-Engineering-Ansätze analysieren können.
Lernziele:
- Die Bedeutung von Sequenzen und ihre Verwendung bei der Modellanalyse.
- LIT für Gemma einrichten, um Prompteingaben und die Salienz von Sequenzen zu berechnen.
- Mit der Sequenzauffälligkeit über das Modul LM Salience können Sie die Auswirkungen von Prompt-Designs auf die Modellausgaben nachvollziehen.
- Hypothetische Prompt-Verbesserungen in LIT testen und ihre Auswirkungen beobachten.
Hinweis: In diesem Codelab wird die KerasNLP-Implementierung von Gemma und TensorFlow v2 für das Backend verwendet. Wir empfehlen dringend, einen GPU-Kernel zu verwenden.
2. Sequenzrelevanz und ihre Verwendung bei der Modellanalyse
Generative Text-zu-Text-Modelle wie Gemma erhalten eine Eingabesequenz in Form von tokenisiertem Text und generieren neue Tokens, die typische Fortsetzungen oder Vervollständigungen dieser Eingabe sind. Die Generierung erfolgt Token für Token. Dabei wird jedes neu generierte Token in einer Schleife an die Eingabe und alle vorherigen Generationen angehängt, bis das Modell eine Stoppbedingung erreicht. Das kann beispielsweise der Fall sein, wenn das Modell ein End-of-Sequence-Token (EOS) generiert oder die vordefinierte maximale Länge erreicht.
Salienzmethoden sind eine Klasse von Explainable AI-Techniken (XAI), mit denen Sie ermitteln können, welche Teile einer Eingabe für das Modell für verschiedene Teile seiner Ausgabe wichtig sind. LIT unterstützt Methoden zur Ermittlung der Salienz für eine Vielzahl von Klassifizierungsaufgaben, mit denen die Auswirkungen einer Sequenz von Eingabetokens auf das vorhergesagte Label erklärt werden. Die Sequenzauffälligkeit verallgemeinert diese Methoden auf generative Text-zu-Text-Modelle und erklärt die Auswirkungen der vorhergehenden Tokens auf die generierten Tokens.
Hier verwenden Sie die Methode Grad L2 Norm für die Sequenzauffälligkeit. Dabei werden die Gradienten des Modells analysiert und eine Größenordnung des Einflusses angegeben, den jedes vorherige Token auf die Ausgabe hat. Diese Methode ist einfach und effizient und hat sich in der Praxis bei der Klassifizierung und in anderen Situationen bewährt. Je höher der Salience-Wert, desto größer der Einfluss. Diese Methode wird in LIT verwendet, da sie in der Forschungsgemeinschaft für Interpretierbarkeit gut verstanden und weit verbreitet ist.
Zu den erweiterten gradientenbasierten Salienzmethoden gehören Grad ⋅ Eingabe und integrierte Gradienten. Es sind auch auf Ablation basierende Methoden wie LIME und SHAP verfügbar, die robuster, aber deutlich rechenintensiver sein können. Einen detaillierten Vergleich der verschiedenen Methoden zur Berechnung der Salienz finden Sie in diesem Artikel.
Weitere Informationen zu den Methoden für die Berechnung der Salienz
3. Importe, Umgebung und anderer Einrichtungscode
Am besten folgen Sie diesem Codelab im neuen Colab. Wir empfehlen die Verwendung einer Accelerator-Laufzeit, da Sie ein Modell in den Arbeitsspeicher laden. Die Accelerator-Optionen variieren jedoch im Laufe der Zeit und unterliegen Einschränkungen. Wenn Sie Zugriff auf leistungsstärkere Beschleuniger benötigen, können Sie kostenpflichtige Colab-Abos abschließen. Alternativ können Sie eine lokale Laufzeit verwenden, wenn Ihr Computer eine geeignete GPU hat.
Hinweis: Möglicherweise werden Warnungen der folgenden Art angezeigt:
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
Diese können ignoriert werden.
LIT und Keras NLP installieren
Für dieses Codelab benötigen Sie eine aktuelle Version von keras (3) keras-nlp (0.14.) und lit-nlp (1.2) sowie ein Kaggle-Konto zum Herunterladen des Basismodells.
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
Kaggle-Zugriff
Sie haben zwei Möglichkeiten, sich bei Kaggle zu authentifizieren:
- Speichern Sie Ihre Anmeldedaten in einer Datei, z. B.
~/.kaggle/kaggle.json. - Verwenden Sie die Umgebungsvariablen
KAGGLE_USERNAMEundKAGGLE_KEY. - Führen Sie den folgenden Code in einer interaktiven Python-Umgebung wie Google Colab aus.
import kagglehub
kagglehub.login()
Weitere Informationen finden Sie in der kagglehub-Dokumentation. Achten Sie darauf, die Gemma-Lizenzvereinbarung zu akzeptieren.
Keras konfigurieren
Keras 3 unterstützt mehrere Deep-Learning-Back-Ends, darunter TensorFlow (Standard), PyTorch und JAX. Das Backend wird mit der Umgebungsvariable KERAS_BACKEND konfiguriert, die vor dem Importieren der Keras-Bibliothek festgelegt werden muss. Das folgende Code-Snippet zeigt, wie Sie diese Variable in einer interaktiven Python-Umgebung festlegen.
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
4. LIT einrichten
LIT kann in Python-Notebooks oder über einen Webserver verwendet werden. In diesem Codelab geht es um den Anwendungsfall „Notebook“. Wir empfehlen, die Schritte in Google Colab nachzuvollziehen.
In diesem Codelab laden Sie Gemma v2 2B IT mit dem KerasNLP-Preset. Im folgenden Snippet wird Gemma initialisiert und ein Beispiel-Dataset in ein LIT Notebook-Widget geladen.
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
Sie können das Widget konfigurieren, indem Sie die Werte ändern, die an die beiden erforderlichen Positionsargumente übergeben werden:
datasets_config: Eine Liste von Strings mit den Dataset-Namen und Pfaden, aus denen geladen werden soll, im Format „dataset:path“. Der Pfad kann eine URL oder ein lokaler Dateipfad sein. Im folgenden Beispiel wird der Sonderwertsample_promptsverwendet, um die in der LIT-Distribution enthaltenen Beispielprompts zu laden.models_config: Eine Liste von Strings mit den Modellnamen und Pfaden, die geladen werden sollen, im Format „model:path“. Der Pfad kann eine URL, ein lokaler Dateipfad oder der Name einer Voreinstellung für das konfigurierte Deep-Learning-Framework sein.
Nachdem Sie LIT so konfiguriert haben, dass das gewünschte Modell verwendet wird, führen Sie das folgende Code-Snippet aus, um das Widget in Ihrem Notebook zu rendern.
lit_widget.render(open_in_new_tab=True)
Eigene Daten verwenden
Als generatives Text-zu-Text-Modell nimmt Gemma Texteingaben entgegen und generiert Textausgaben. LIT verwendet eine Meinungs-API, um die Struktur der geladenen Datasets an Modelle zu kommunizieren. LLMs in LIT sind für die Verwendung mit Datasets konzipiert, die zwei Felder enthalten:
prompt: Die Eingabe für das Modell, aus der Text generiert wird.target: Eine optionale Zielsequenz, z. B. eine „Ground Truth“-Antwort von menschlichen Ratern oder eine vorab generierte Antwort von einem anderen Modell.
LIT enthält eine kleine Gruppe von sample_prompts mit Beispielen aus den folgenden Quellen, die dieses Codelab und das erweiterte LIT-Tutorial zum Debuggen von Prompts unterstützen.
- GSM8K: Lösen von mathematischen Aufgaben für die Grundschule mit wenigen Beispielen.
- Gigaword Benchmark: Generierung von Überschriften für eine Sammlung kurzer Artikel.
- Constitutional Prompting: Generieren neuer Ideen für die Verwendung von Objekten mit Richtlinien/Grenzen.
Sie können auch ganz einfach Ihre eigenen Daten laden, entweder als .jsonl-Datei mit Datensätzen mit den Feldern prompt und optional target (Beispiel) oder in einem beliebigen Format über die Dataset API von LIT.
Führen Sie die Zelle unten aus, um die Beispiel-Prompts zu laden.
5. Few-Shot-Prompts für Gemma in LIT analysieren
Das Erstellen von Prompts ist heute sowohl Kunst als auch Wissenschaft. Mit LIT können Sie Prompts für Large Language Models wie Gemma empirisch verbessern. Im Folgenden sehen Sie ein Beispiel dafür, wie LIT verwendet werden kann, um das Verhalten von Gemma zu untersuchen, potenzielle Probleme zu antizipieren und die Sicherheit zu verbessern.
Fehler in komplexen Prompts erkennen
Zwei der wichtigsten Prompting-Techniken für hochwertige LLM-basierte Prototypen und Anwendungen sind Few-Shot-Prompting (mit Beispielen für das gewünschte Verhalten im Prompt) und Chain-of-Thought (mit einer Art Erklärung oder Begründung vor der endgültigen Ausgabe des LLM). Einen effektiven Prompt zu erstellen, ist jedoch oft immer noch eine Herausforderung.
Stellen Sie sich vor, Sie helfen jemandem, anhand seines Geschmacks zu beurteilen, ob ihm ein bestimmtes Gericht schmecken wird. Eine erste Vorlage für einen Chain-of-Thought-Prompt könnte so aussehen:
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
Haben Sie die Probleme mit diesem Prompt erkannt? Mit LIT können Sie den Prompt mit dem LM Salience-Modul untersuchen.
6. Sequenzauffälligkeit für die Fehlerbehebung verwenden
Die Auffälligkeit wird auf der kleinstmöglichen Ebene berechnet, d. h. für jedes Eingabetoken. LIT kann die Token-Auffälligkeit jedoch in interpretierbarere größere Spannen wie Zeilen, Sätze oder Wörter zusammenfassen. Weitere Informationen zu Saliency und zur Verwendung von Saliency Explorable
Geben wir zuerst eine neue Beispiel-Eingabe für die Variablen der Prompt-Vorlage an:
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
Wenn Sie die LIT-Benutzeroberfläche in der Zelle oben oder auf einem separaten Tab geöffnet haben, können Sie den Datapoint Editor von LIT verwenden, um diesen Prompt hinzuzufügen:
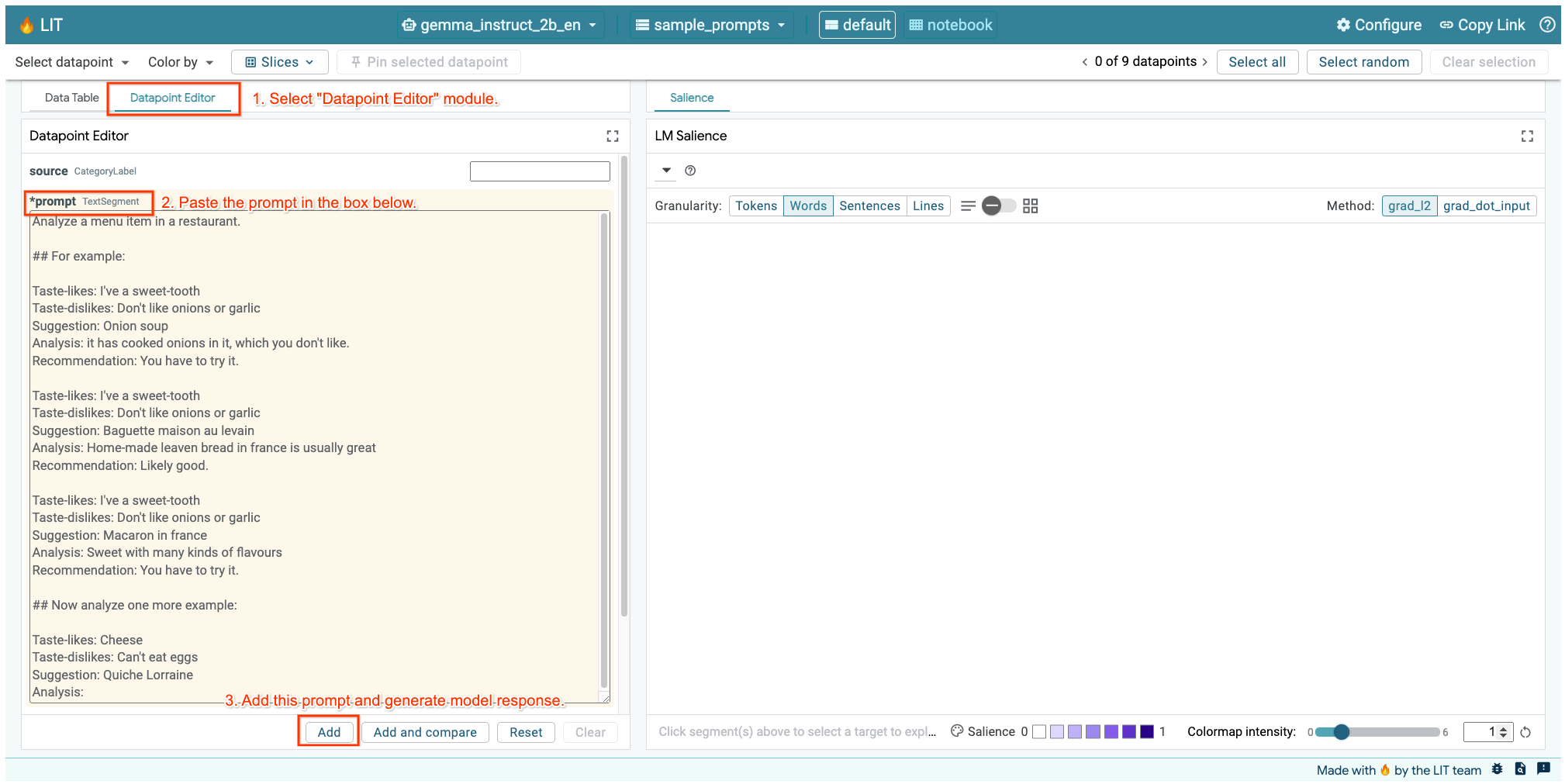
Eine weitere Möglichkeit besteht darin, das Widget direkt mit dem gewünschten Prompt neu zu rendern:
lit_widget.render(data=[fewshot_mistake_example])
Beachten Sie die überraschende Vervollständigung des Modells:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
Warum schlägt das Modell vor, dass Sie etwas essen, das Sie ganz klar nicht essen können?
Die Sequenzauffälligkeit kann helfen, das zugrunde liegende Problem hervorzuheben, das in unseren Few-Shot-Beispielen liegt. Im ersten Beispiel stimmt die Chain-of-Thought-Argumentation im Analyseabschnitt it has cooked onions in it, which you don't like nicht mit der endgültigen Empfehlung You have to try it überein.
Wählen Sie im Modul „LM Salience“ (LM-Auffälligkeit) die Option „Sentences“ (Sätze) und dann die Empfehlungszeile aus. Die Benutzeroberfläche sollte jetzt so aussehen:
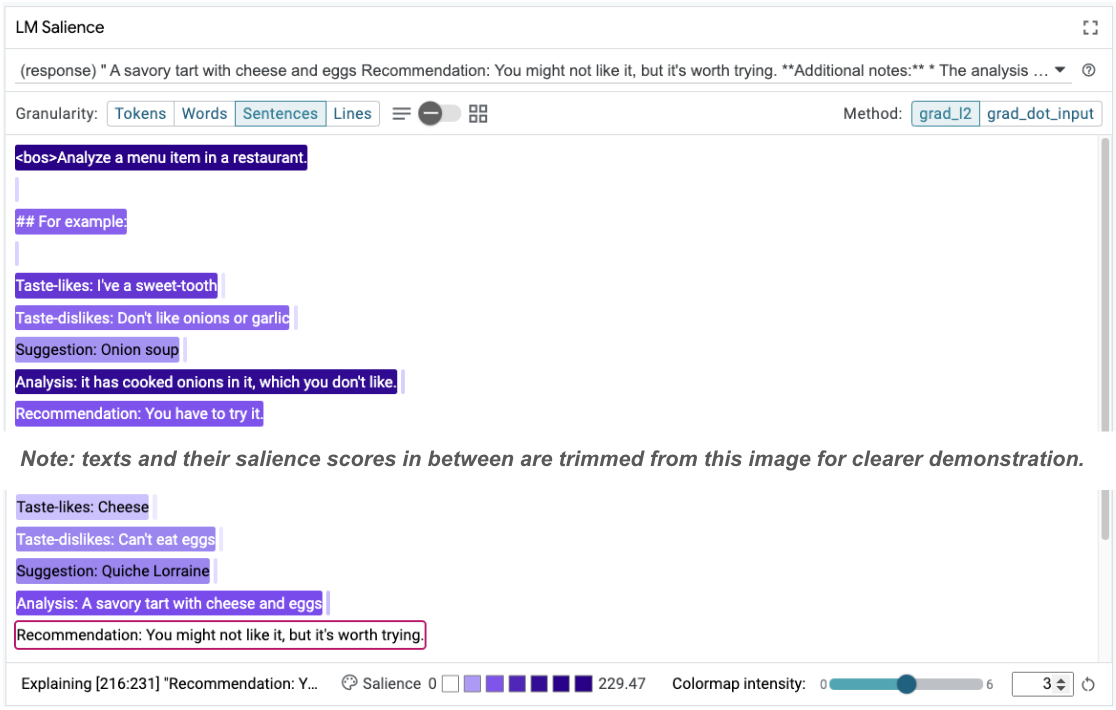
Das ist ein menschlicher Fehler: Der Empfehlungsteil wurde versehentlich kopiert und eingefügt und nicht aktualisiert.
Korrigieren wir nun die „Empfehlung“ im ersten Beispiel zu Avoid und versuchen es noch einmal. LIT hat dieses Beispiel in den Beispiel-Prompts vorab geladen. Sie können diese kleine Hilfsfunktion verwenden, um es abzurufen:
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
Die Modellvervollständigung sieht jetzt so aus:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
Eine wichtige Erkenntnis daraus ist: Frühe Prototypen helfen, Risiken aufzudecken, an die Sie möglicherweise nicht im Voraus denken. Die fehleranfällige Natur von Sprachmodellen bedeutet, dass man proaktiv auf Fehler reagieren muss. Weitere Informationen dazu finden Sie in unserem People + AI Guidebook.
Der korrigierte Few-Shot-Prompt ist zwar besser, aber immer noch nicht ganz richtig: Er weist den Nutzer zwar korrekt darauf hin, Eier zu vermeiden, aber die Begründung ist falsch. Es wird gesagt, dass der Nutzer keine Eier mag, obwohl er angegeben hat, dass er keine Eier essen kann. Im nächsten Abschnitt erfahren Sie, wie Sie es besser machen können.
7. Hypothesen testen, um das Modellverhalten zu verbessern
Mit LIT können Sie Änderungen an Prompts in derselben Benutzeroberfläche testen. In diesem Fall fügen Sie eine Verfassung hinzu, um das Verhalten des Modells zu verbessern. „Constitutions“ sind Design-Prompts mit Prinzipien, die die Generierung des Modells steuern. Neuere Methoden ermöglichen sogar die interaktive Ableitung von verfassungsmäßigen Grundsätzen.
Wir nutzen diese Idee, um den Prompt weiter zu verbessern. Fügen Sie oben in den Prompt einen Abschnitt mit den Grundsätzen für die Generierung ein. Der Prompt beginnt jetzt so:
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
Nach dieser Aktualisierung kann das Beispiel noch einmal ausgeführt werden und es wird eine ganz andere Ausgabe angezeigt:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
Die Prompt-Salienz kann dann noch einmal untersucht werden, um herauszufinden, warum diese Änderung erfolgt:
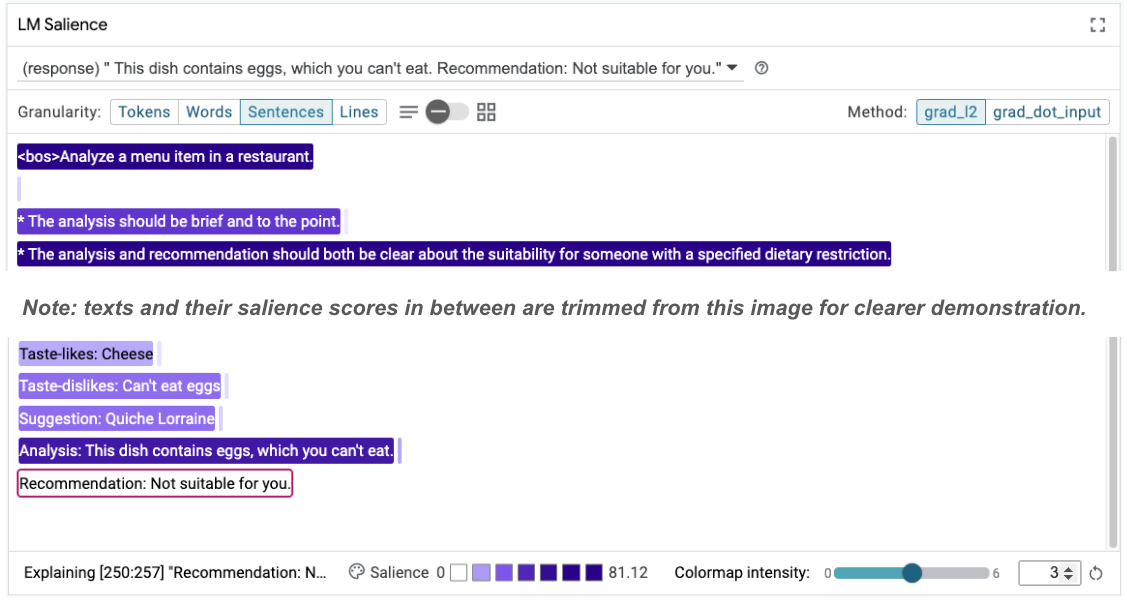
Die Empfehlung ist viel sicherer. Außerdem wird die Angabe „Nicht für dich geeignet“ durch den Grundsatz beeinflusst, die Eignung gemäß der Ernährungseinschränkung zusammen mit der Analyse (dem sogenannten Gedankengang) klar anzugeben. So wird die Wahrscheinlichkeit erhöht, dass die Ausgabe aus dem richtigen Grund erfolgt.
8. Nicht-technische Teams in die Modellprüfung und ‑exploration einbeziehen
Die Interpretierbarkeit ist eine Teamleistung, die Fachwissen aus den Bereichen XAI, Richtlinien, Recht und mehr umfasst.
Für die Interaktion mit Modellen in den frühen Entwicklungsphasen waren bisher erhebliche technische Kenntnisse erforderlich, was den Zugriff und die Überprüfung für einige Mitarbeiter erschwert hat. Bisher gab es keine Tools, mit denen diese Teams an den frühen Prototyping-Phasen teilnehmen konnten.
Durch LIT soll sich dieses Paradigma ändern. Wie Sie in diesem Codelab gesehen haben, können verschiedene Stakeholder mithilfe der visuellen und interaktiven Funktionen von LIT, mit denen sich die Salienz untersuchen und Beispiele ansehen lassen, Ergebnisse teilen und kommunizieren. So können Sie eine größere Vielfalt an Teammitgliedern für die Modellanalyse, das Testen und das Debugging einbeziehen. Wenn sie mit diesen technischen Methoden vertraut sind, können sie besser nachvollziehen, wie Modelle funktionieren. Außerdem kann eine größere Vielfalt an Fachwissen bei frühen Modelltests dazu beitragen, unerwünschte Ergebnisse aufzudecken, die verbessert werden können.
9. Zusammenfassung
Zusammenfassung:
- Die LIT-Benutzeroberfläche bietet eine Schnittstelle für die interaktive Ausführung von Modellen, mit der Nutzer Ausgaben direkt generieren und „Was wäre wenn“-Szenarien testen können. Das ist besonders nützlich, wenn Sie verschiedene Prompt-Variationen testen möchten.
- Das Modul zur LM-Auffälligkeit bietet eine visuelle Darstellung der Auffälligkeit und eine steuerbare Datengranularität, sodass Sie über menschenzentrierte Konstrukte (z.B. Sätze und Wörter) anstelle von modellzentrierten Konstrukten (z.B. Tokens) kommunizieren können.
Wenn Sie in Ihren Modellbewertungen problematische Beispiele finden, können Sie sie zum Debuggen in LIT importieren. Beginnen Sie mit der Analyse der größten sinnvollen Inhaltseinheit, die logisch mit der Modellierungsaufgabe zusammenhängt. Verwenden Sie die Visualisierungen, um zu sehen, wo das Modell die Eingabeaufforderungsinhalte richtig oder falsch berücksichtigt. Gehen Sie dann zu kleineren Inhaltseinheiten über, um das falsche Verhalten, das Sie beobachten, genauer zu beschreiben und mögliche Korrekturen zu finden.
Zu guter Letzt: Lit wird ständig verbessert. Weitere Informationen zu unseren Funktionen