
1. はじめに
生成 AI プロダクトは比較的新しく、アプリケーションの動作は以前の形式のソフトウェアよりも大きく異なる可能性があります。そのため、使用されている ML モデルを調査し、モデルの動作の例を調べ、予期しない結果を調査することが重要になります。
Learning Interpretability Tool(LIT、ウェブサイト、GitHub)は、ML モデルをデバッグして分析し、モデルがどのように動作するのかを理解するためのプラットフォームです。
この Codelab では、LIT を使用して Google の Gemma モデルを最大限に活用する方法を学びます。この Codelab では、解釈可能性の手法であるシーケンスの顕著性を使用して、さまざまなプロンプト エンジニアリング アプローチを分析する方法について説明します。
学習目標:
- シーケンスの顕著性と、モデル分析でのその使用について理解する。
- Gemma 用に LIT を設定して、プロンプト出力とシーケンスの顕著性を計算します。
- LM Salience モジュールを使用してシーケンスの顕著性を利用し、プロンプト設計がモデル出力に与える影響を把握します。
- LIT で仮説に基づくプロンプトの改善をテストし、その影響を確認します。
注: この Codelab では、Gemma の KerasNLP 実装と、バックエンドに TensorFlow v2 を使用します。GPU カーネルを使用して、この手順を進めることを強くおすすめします。
2. シーケンスの顕著性とモデル分析での使用
Gemma などの Text-to-Text 生成モデルは、トークン化されたテキストの形式で入力シーケンスを受け取り、その入力の典型的なフォローアップまたは補完となる新しいトークンを生成します。この生成は一度に 1 つのトークンで行われ、モデルが停止条件に達するまで、新しく生成された各トークンが入力と以前の生成に追加されます(ループ内)。たとえば、モデルがシーケンス終了(EOS)トークンを生成した場合や、事前定義された最大長に達した場合などです。
顕著性メソッドは、Explainable AI(XAI)手法の一種で、出力のさまざまな部分について、入力のどの部分がモデルにとって重要であるかを判断できます。LIT は、さまざまな分類タスクの顕著性メソッドをサポートしています。このメソッドは、入力トークンのシーケンスが予測ラベルに与える影響を説明します。シーケンスの顕著性は、これらの方法を Text-to-Text 生成モデルに一般化し、先行するトークンが生成されたトークンに与える影響を説明します。
ここでは、シーケンスの顕著性に対して Grad L2 Norm メソッドを使用します。このメソッドは、モデルのグラデーションを分析し、先行する各トークンが出力に与える影響の大きさを提供します。この方法はシンプルで効率的であり、分類などの設定で優れたパフォーマンスを発揮することが示されています。顕著性スコアが大きいほど、影響力が高くなります。このメソッドは、解釈可能性の研究コミュニティで広く理解され、利用されているため、LIT 内で使用されます。
より高度な勾配ベースの顕著性手法には、Grad ⋅ Input や統合勾配などがあります。LIME や SHAP などのアブレーション ベースの方法もあります。これらはより堅牢ですが、計算コストが大幅に高くなります。さまざまな顕著性メソッドの詳細な比較については、こちらの記事をご覧ください。
顕著性メソッドの科学について詳しくは、顕著性に関するこちらのインタラクティブな入門記事をご覧ください。
3. インポート、環境、その他の設定コード
この Codelab は、新しい Colab で進めることをおすすめします。モデルをメモリに読み込むため、アクセラレータ ランタイムを使用することをおすすめします。ただし、アクセラレータ オプションは時間の経過とともに変化し、制限を受けることに注意してください。より強力なアクセラレータをご希望の場合は、Colab の有料サブスクリプションをご利用ください。また、マシンに適切な GPU が搭載されている場合は、ローカル ランタイムを使用することもできます。
注: 次のような形式の警告が表示されることがあります。
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
これらは無視しても問題ありません。
LIT と Keras NLP をインストールする
この Codelab では、最新バージョンの keras(3)、keras-nlp(0.14)、lit-nlp(1.2)と、ベースモデルをダウンロードするための Kaggle アカウントが必要です。
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
Kaggle Access
Kaggle で認証するには、次のいずれかを行います。
- 認証情報を
~/.kaggle/kaggle.jsonなどのファイルに保存します。 KAGGLE_USERNAMEとKAGGLE_KEYの環境変数を使用する。- Google Colab などのインタラクティブな Python 環境で、次のコードを実行します。
import kagglehub
kagglehub.login()
詳細については、kagglehub のドキュメントをご覧ください。また、Gemma ライセンス契約に同意してください。
Keras の構成
Keras 3 は、Tensorflow(デフォルト)、PyTorch、JAX など、複数のディープ ラーニング バックエンドをサポートしています。バックエンドは KERAS_BACKEND 環境変数を使用して構成されます。この変数は、Keras ライブラリをインポートする前に設定する必要があります。次のコード スニペットは、インタラクティブな Python 環境でこの変数を設定する方法を示しています。
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
4. LIT の設定
LIT は、Python ノートブックまたはウェブサーバー経由で使用できます。この Codelab では、ノートブックのユースケースに焦点を当てています。Google Colab で手順に沿って操作することをおすすめします。
この Codelab では、KerasNLP プリセットを使用して Gemma v2 2B IT を読み込みます。次のスニペットは、Gemma を初期化し、LIT Notebook ウィジェットにサンプル データセットを読み込みます。
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
ウィジェットを構成するには、2 つの必須位置引数に渡される値を変更します。
datasets_config: ロードするデータセットの名前とパスを含む文字列のリスト(「dataset:path」形式)。path は URL またはローカル ファイルパスにできます。次の例では、特別な値sample_promptsを使用して、LIT ディストリビューションで提供されているプロンプトの例を読み込みます。models_config: ロードするモデル名とパスを含む文字列のリスト(「model:path」形式)。path は、URL、ローカル ファイルパス、構成されたディープ ラーニング フレームワークのプリセット名にできます。
目的のモデルを使用するように LIT を構成したら、次のコード スニペットを実行して、ノートブックにウィジェットをレンダリングします。
lit_widget.render(open_in_new_tab=True)
独自のデータを使用する
Text-to-Text 生成モデルである Gemma は、テキスト入力を受け取り、テキスト出力を生成します。LIT は、独自の API を使用して、読み込まれたデータセットの構造をモデルに伝えます。LIT の LLM は、次の 2 つのフィールドを提供するデータセットで動作するように設計されています。
prompt: テキストが生成されるモデルへの入力。target: 省略可能なターゲット シーケンス。たとえば、人間の評価者による「グラウンド トゥルース」レスポンスや、別のモデルから事前に生成されたレスポンスなどです。
LIT には、この Codelab と LIT の拡張プロンプト デバッグ チュートリアルをサポートする次のソースの例を含む、少数の sample_prompts が含まれています。
- GSM8K: 少数ショットの例を使用して小学校の数学の問題を解きます。
- Gigaword Benchmark: 短い記事のコレクションの広告見出しを生成します。
- 憲法プロンプト: ガイドラインや境界線に沿ってオブジェクトを使用する方法に関する新しいアイデアを生成します。
また、独自のデータを簡単に読み込むこともできます。データは、フィールド prompt とオプションの target を含むレコードを含む .jsonl ファイル(例)として読み込むことも、LIT の Dataset API を使用して任意の形式で読み込むこともできます。
次のセルを実行して、サンプル プロンプトを読み込みます。
5. LIT で Gemma の少数ショット プロンプトを分析する
現在、プロンプトは科学であると同時に芸術でもあります。LIT を使用すると、Gemma などの大規模言語モデルのプロンプトを経験的に改善できます。以降では、LIT を使用して Gemma の動作を調べ、潜在的な問題を予測し、安全性を向上させる方法の例を示します。
複雑なプロンプトのエラーを特定する
高品質の LLM ベースのプロトタイプとアプリケーションに最も重要なプロンプト手法は、少数ショット プロンプト(プロンプトに目的の動作の例を含める)と思考の連鎖(LLM の最終出力の前に説明や推論の形式を含める)の 2 つです。しかし、効果的なプロンプトを作成することは、依然として難しい場合があります。
たとえば、ユーザーの好みに基づいて、そのユーザーが食べ物を気に入るかどうかを判断する例を考えてみましょう。初期プロトタイプの Chain-of-Thought プロンプト テンプレートは次のようになります。
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
このプロンプトの問題点に気づきましたか?LIT は、LM Salience モジュールを使用してプロンプトを調べるのに役立ちます。
6. デバッグにシーケンスの顕著性を使用する
顕著性は可能な限り最小のレベル(つまり、入力トークンごと)で計算されますが、LIT はトークンの顕著性を行、文、単語などの解釈しやすい大きなスパンに集約できます。顕著性とその使用方法について詳しくは、顕著性 Explorable をご覧ください。
まず、プロンプト テンプレート変数に新しい入力例をプロンプトに指定します。
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
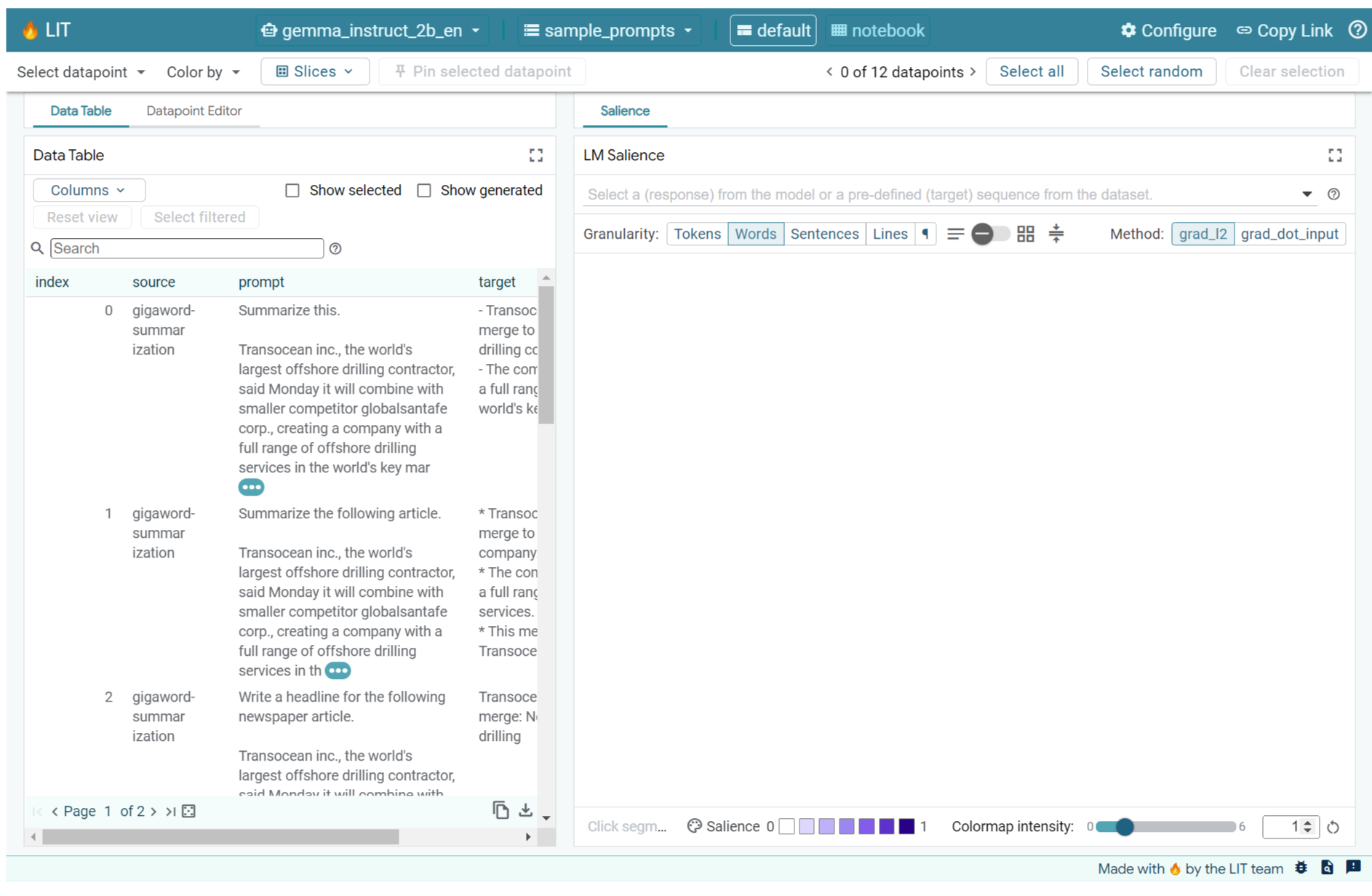
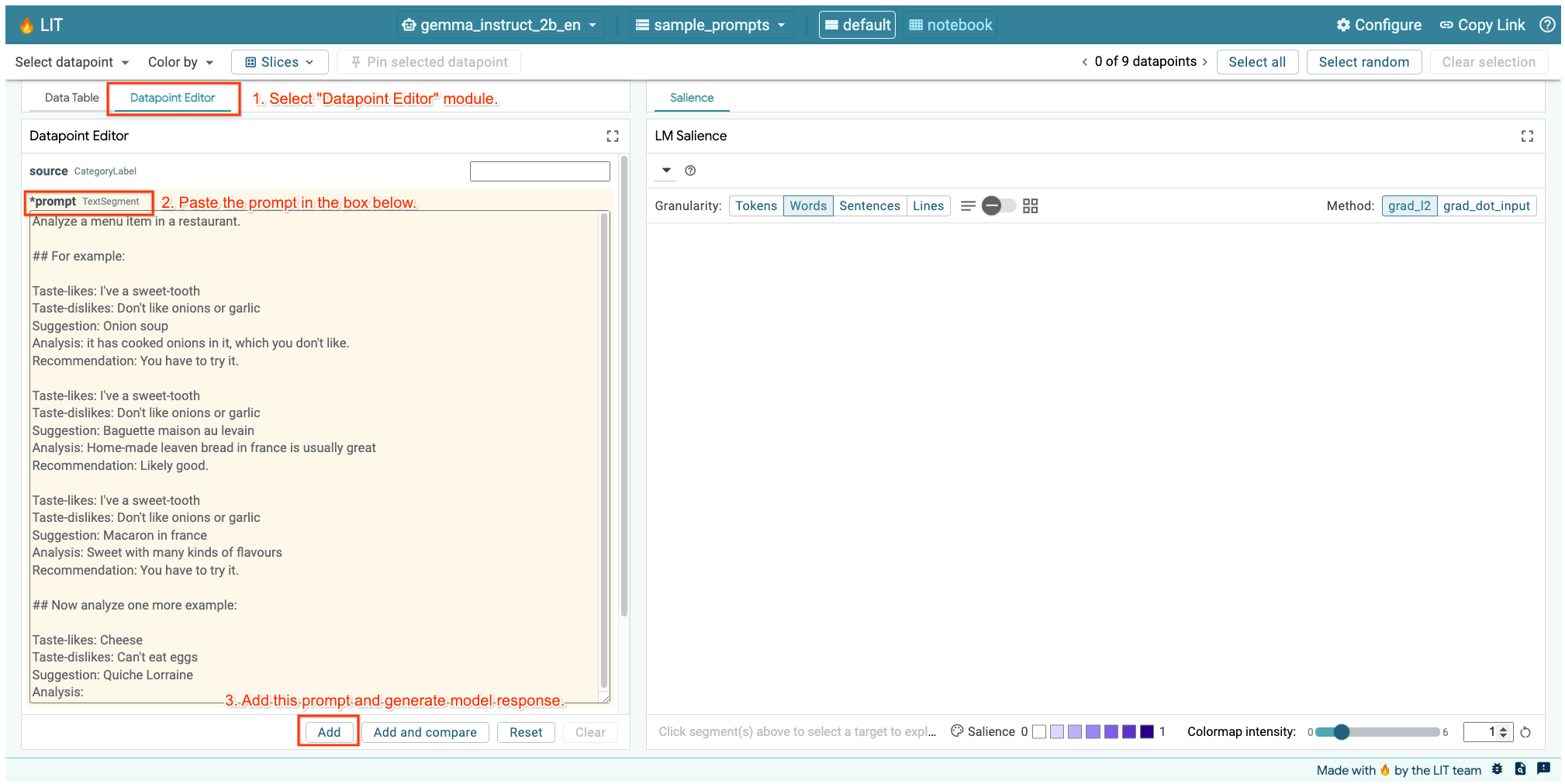
上記のセルまたは別のタブで LIT UI を開いている場合は、LIT のデータポイント エディタを使用して、このプロンプトを追加できます。
別の方法として、目的のプロンプトを使用してウィジェットを直接再レンダリングすることもできます。
lit_widget.render(data=[fewshot_mistake_example])
モデルの予期しない補完に注意してください。
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
明らかに食べられないと言ったものを、モデルが食べるように提案するのはなぜですか?
シーケンスの顕著性は、根本的な問題をハイライトするのに役立ちます。これは、少数のショットの例で確認できます。最初の例では、分析セクションの連鎖的思考の推論 it has cooked onions in it, which you don't like が最終的な推奨事項 You have to try it と一致していません。
[LM Salience] モジュールで、[Sentences] を選択し、推奨事項の行を選択します。UI は次のようになります。
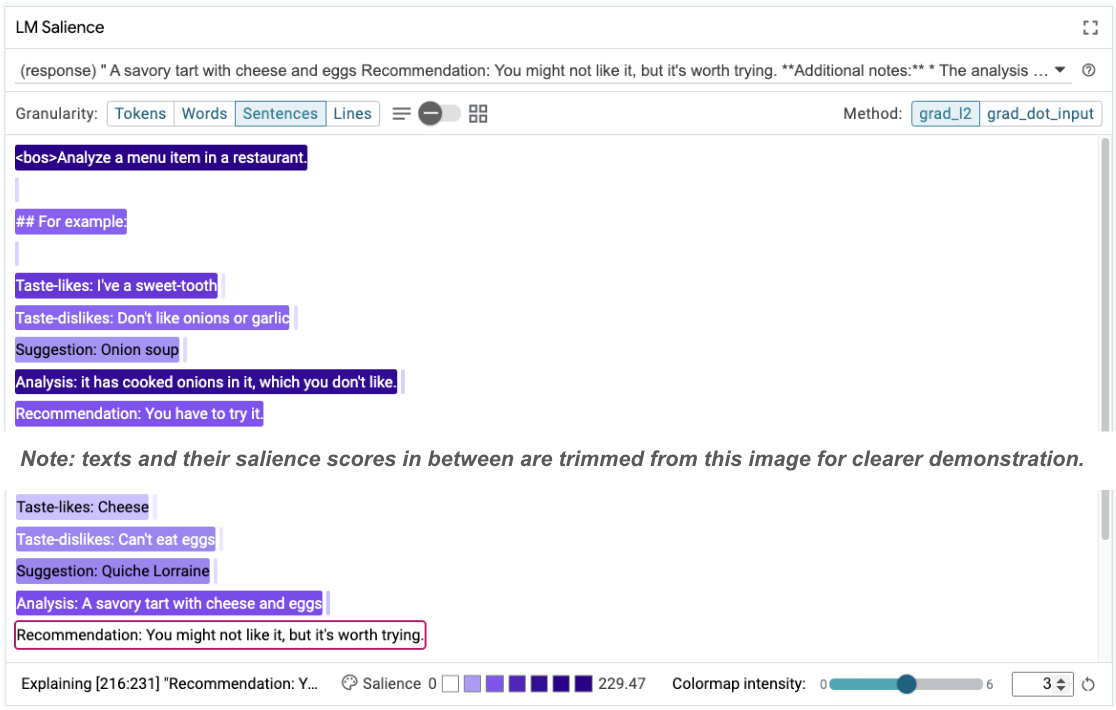
これは、推奨事項の一部を誤ってコピーして貼り付け、更新しなかったという人為的なミスをハイライト表示しています。
最初の例の「Recommendation」を Avoid に修正して、もう一度試してみましょう。LIT にはこの例がサンプル プロンプトにプリロードされているため、この小さなユーティリティ関数を使用して取得できます。
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
モデルの補完は次のようになります。
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
このことから得られる重要な教訓は、早期のプロトタイピングは、事前に想定していなかったリスクを明らかにするのに役立つということです。また、言語モデルはエラーが発生しやすい性質があるため、エラーを想定した設計を積極的に行う必要があります。詳細については、AI を使用した設計に関する People + AI Guidebook をご覧ください。
修正された数ショット プロンプトは改善されていますが、まだ完全ではありません。ユーザーに卵を避けるよう正しく伝えていますが、その理由が正しくありません。実際にはユーザーは卵を食べられないと述べているのに、卵が好きではないと述べています。次のセクションでは、この問題を解決する方法について説明します。
7. 仮説をテストしてモデルの動作を改善する
LIT を使用すると、同じインターフェース内でプロンプトの変更をテストできます。このインスタンスでは、モデルの動作を改善するために constitution を追加するテストを行います。憲法とは、モデルの生成をガイドする原則を含む設計プロンプトを指します。最近の方法では、憲法原則のインタラクティブな導出も可能になっています。
このアイデアを参考に、プロンプトをさらに改善してみましょう。プロンプトの先頭に生成の原則のセクションを追加します。プロンプトは次のようになります。
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
この更新により、例を再実行して、まったく異なる出力を確認できます。
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
プロンプトの顕著性を再確認すると、この変更が起こっている理由を把握できます。
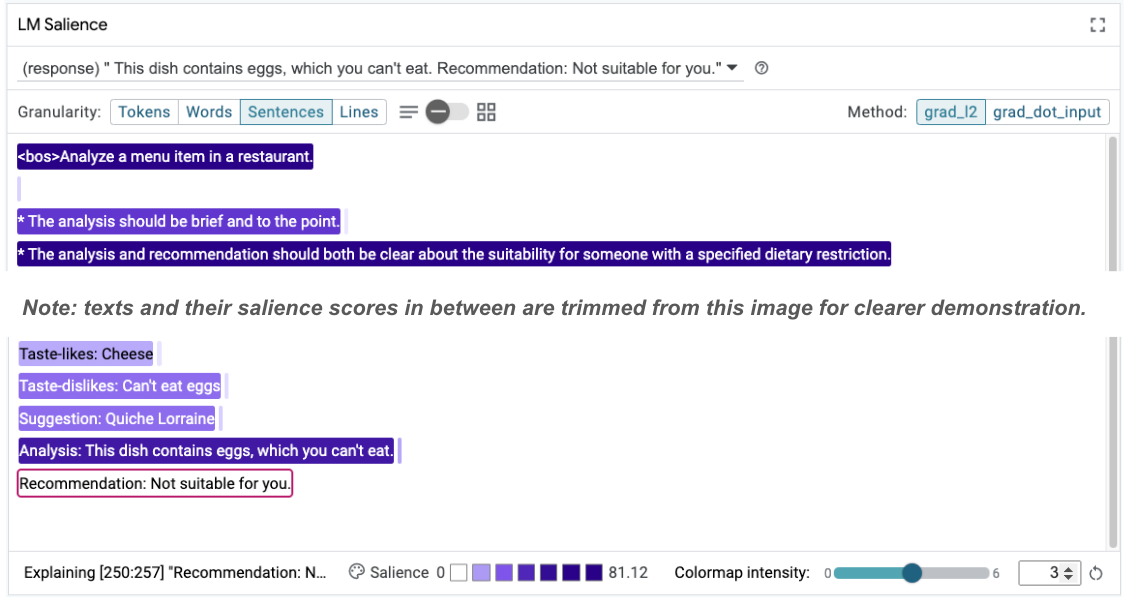
推奨事項ははるかに安全です。また、「Not suitable for you」は、食事制限に応じた適合性を明確に述べるという原則と、分析(いわゆる思考の連鎖)の影響を受けます。これにより、出力が正しい理由で発生しているという確信を深めることができます。
8. モデルのプロービングと探索に技術以外のチームを含める
解釈可能性は、XAI、ポリシー、法務などの専門知識を横断するチームの取り組みを意味します。
従来、開発の初期段階でモデルを操作するには高度な技術的専門知識が必要だったため、一部の共同作業者がモデルにアクセスして調査することが困難でした。これまで、これらのチームが初期のプロトタイピング フェーズに参加するためのツールは存在していませんでした。
LIT を通じて、このパラダイムを変えることが期待されています。この Codelab で説明したように、LIT の視覚的なメディアと、顕著性を調べたり例を探索したりするインタラクティブな機能は、さまざまな関係者が調査結果を共有し、コミュニケーションをとるのに役立ちます。これにより、モデルの探索、プロービング、デバッグに、より多様なチームメンバーを参加させることができます。これらの技術的な方法を理解することで、モデルの仕組みについての理解を深めることができます。また、初期のモデルテストで多様な専門知識を活用することで、改善可能な望ましくない結果を発見することもできます。
9. まとめ
まとめると次のようになります。
- LIT UI は、インタラクティブなモデル実行用のインターフェースを提供します。これにより、ユーザーは出力を直接生成し、仮説シナリオをテストできます。これは、さまざまなプロンプトのバリエーションをテストする場合に特に便利です。
- LM Salience モジュールは、顕著性の視覚的表現を提供し、制御可能なデータ粒度を提供します。これにより、モデル中心の構成要素(トークンなど)ではなく、人間中心の構成要素(文や単語など)について説明できます。
モデル評価で問題のある例が見つかった場合は、デバッグのために LIT に取り込みます。まず、モデリング タスクに論理的に関連する最大のコンテンツ単位を分析します。次に、可視化を使用して、モデルがプロンプト コンテンツを正しく認識しているか、間違って認識しているかを確認します。その後、コンテンツのより小さな単位にドリルダウンして、表示されている誤った動作をさらに詳しく説明し、可能な修正を特定します。
最後に、Lit は常に改善されています。機能の詳細やご提案については、こちらをご覧ください。