
1. Introdução
Os produtos de IA generativa são relativamente novos, e os comportamentos de um aplicativo podem variar mais do que as formas anteriores de software. Por isso, é importante testar os modelos de machine learning usados, examinar exemplos do comportamento deles e investigar surpresas.
A ferramenta de aprendizado de interpretabilidade (LIT, site, GitHub) é uma plataforma para depurar e analisar modelos de ML e entender por que e como eles se comportam da maneira que fazem.
Neste codelab, você vai aprender a usar o LIT para aproveitar ao máximo o modelo Gemma do Google. Este codelab demonstra como usar a saliência de sequência, uma técnica de interpretabilidade, para analisar diferentes abordagens de engenharia de comandos.
Objetivos de aprendizado:
- Entender a saliência da sequência e seus usos na análise de modelos.
- Configurar o LIT para a Gemma calcular saídas de comandos e saliência de sequência.
- Usar a saliência de sequência pelo módulo LM Salience para entender o impacto dos designs de comandos nas saídas do modelo.
- Testar melhorias hipotéticas de comandos no LIT e conferir o impacto delas.
Observação: este codelab usa a implementação do KerasNLP do Gemma e o TensorFlow v2 para o back-end. É altamente recomendável usar um kernel de GPU para acompanhar.
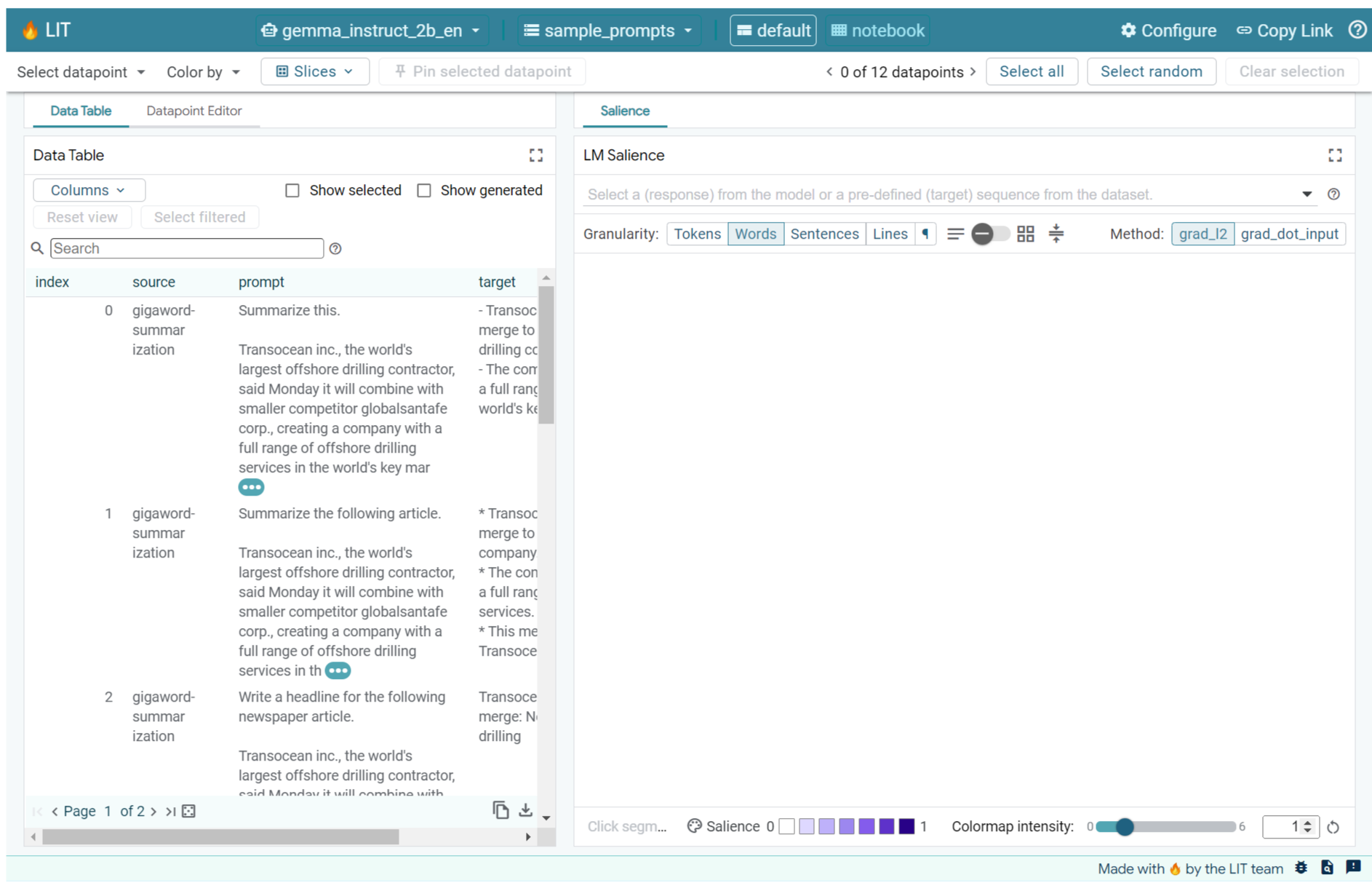
2. Saliência de sequência e usos na análise de modelos
Os modelos generativos de texto para texto, como o Gemma, usam uma sequência de entrada na forma de texto tokenizado e geram novos tokens que são complementos típicos dessa entrada. Essa geração acontece um token por vez, adicionando ao final (em um loop) cada token recém-gerado à entrada mais qualquer geração anterior até que o modelo atinja uma condição de parada. Por exemplo, quando o modelo gera um token de fim de sequência (EOS) ou atinge o comprimento máximo predefinido.
Os métodos de saliência são uma classe de técnicas de IA explicável (XAI, na sigla em inglês) que informam quais partes de uma entrada são importantes para o modelo em diferentes partes da saída. A LIT oferece suporte a métodos de saliência para várias tarefas de classificação, que explicam o impacto de uma sequência de tokens de entrada no rótulo previsto. A saliência de sequência generaliza esses métodos para modelos generativos de texto a texto e explica o impacto dos tokens anteriores nos tokens gerados.
Aqui, você vai usar o método Grad L2 Norm para saliência de sequência, que analisa os gradientes do modelo e fornece uma magnitude da influência que cada token anterior tem na saída. Esse método é simples e eficiente e demonstrou ter um bom desempenho na classificação e em outras configurações. Quanto maior a pontuação de saliência, maior a influência. Esse método é usado na LIT porque é bem compreendido e amplamente utilizado na comunidade de pesquisa de interpretabilidade.
Métodos de saliência mais avançados baseados em gradiente incluem Grad ⋅ Input e gradientes integrados. Também há métodos baseados em remoção disponíveis, como LIME e SHAP, que podem ser mais robustos, mas significativamente mais caros de calcular. Consulte este artigo para uma comparação detalhada de diferentes métodos de saliência.
Saiba mais sobre a ciência dos métodos de saliência nesta explicação interativa introdutória.
3. Importações, ambiente e outros códigos de configuração
É melhor acompanhar este codelab no novo Colab. Recomendamos usar um tempo de execução de acelerador, já que você vai carregar um modelo na memória. No entanto, as opções de acelerador variam com o tempo e estão sujeitas a limitações. O Colab oferece assinaturas pagas se você quiser ter acesso a aceleradores mais potentes. Como alternativa, use um tempo de execução local se a máquina tiver uma GPU adequada.
Observação: talvez você veja alguns avisos do tipo
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
É possível ignorá-las com segurança.
Instalar o LIT e o Keras NLP
Para este codelab, você vai precisar de uma versão recente do keras (3), keras-nlp (0.14) e lit-nlp (1.2), além de uma conta do Kaggle para fazer o download do modelo de base.
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
Acesso ao Kaggle
Para fazer a autenticação com o Kaggle, você pode:
- Armazene suas credenciais em um arquivo, como
~/.kaggle/kaggle.json. - Use as variáveis de ambiente
KAGGLE_USERNAMEeKAGGLE_KEY; ou - Execute o seguinte em um ambiente Python interativo, como o Google Colab.
import kagglehub
kagglehub.login()
Consulte a documentação do kagglehub para mais detalhes e aceite o contrato de licença do Gemma.
Como configurar o Keras
O Keras 3 oferece suporte a vários back-ends de aprendizado profundo, incluindo TensorFlow (padrão), PyTorch e JAX. O back-end é configurado usando a variável de ambiente KERAS_BACKEND, que precisa ser definida antes da importação da biblioteca Keras. O snippet de código a seguir mostra como definir essa variável em um ambiente Python interativo.
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
4. Configurar o LIT
O LIT pode ser usado em notebooks Python ou por um servidor da Web. Este codelab se concentra no caso de uso do notebook. Recomendamos que você acompanhe no Google Colab.
Neste codelab, você vai carregar o Gemma v2 2B IT usando o preset do KerasNLP. O snippet a seguir inicializa a Gemma e carrega um conjunto de dados de exemplo em um widget do notebook LIT.
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
É possível configurar o widget mudando os valores transmitidos aos dois argumentos posicionais obrigatórios:
datasets_config: uma lista de strings que contém os nomes e caminhos dos conjuntos de dados a serem carregados, como "dataset:path", em que "path" pode ser um URL ou um caminho de arquivo local. O exemplo abaixo usa o valor especialsample_promptspara carregar os comandos de exemplo fornecidos na distribuição do LIT.models_config: uma lista de strings que contém os nomes dos modelos e os caminhos para carregar, como "model:path", em que "path" pode ser um URL, um caminho de arquivo local ou o nome de uma predefinição para o framework de aprendizado profundo configurado.
Depois de configurar o LIT para usar o modelo de seu interesse, execute o snippet de código a seguir para renderizar o widget no seu notebook.
lit_widget.render(open_in_new_tab=True)
Como usar seus próprios dados
Como um modelo generativo de texto para texto, a Gemma recebe texto como entrada e gera texto como saída. O LIT usa uma API opinativa para comunicar a estrutura dos conjuntos de dados carregados aos modelos. Os LLMs no LIT foram projetados para trabalhar com conjuntos de dados que fornecem dois campos:
prompt: a entrada do modelo de que o texto será gerado; etarget: uma sequência de destino opcional, como uma resposta "com base em informações empíricas" de rotuladores humanos ou uma resposta pré-gerada de outro modelo.
O LIT inclui um pequeno conjunto de sample_prompts com exemplos das seguintes fontes que oferecem suporte a este codelab e ao tutorial estendido de depuração de comandos do LIT.
- GSM8K: resolução de problemas matemáticos do ensino fundamental com exemplos de poucos disparos.
- Gigaword Benchmark: geração de títulos para uma coleção de artigos curtos.
- Comandos constitucionais: geração de novas ideias sobre como usar objetos com diretrizes/limites.
Você também pode carregar seus próprios dados, seja como um arquivo .jsonl contendo registros com campos prompt e, opcionalmente, target (exemplo), ou de qualquer formato usando a API Dataset do LIT.
Execute a célula abaixo para carregar os comandos de amostra.
5. Analisando comandos de poucos disparos para Gemma no LIT
Hoje, a criação de comandos é uma arte e uma ciência, e o LIT pode ajudar você a melhorar empiricamente os comandos para modelos de linguagem grandes, como o Gemma. A seguir, você vai ver um exemplo de como a LIT pode ser usada para analisar os comportamentos da Gemma, antecipar possíveis problemas e melhorar a segurança dela.
Identificar erros em comandos complexos
Duas das técnicas de comando mais importantes para protótipos e aplicativos de alta qualidade baseados em LLMs são o comando com poucos exemplos (incluindo exemplos do comportamento desejado no comando) e a linha de raciocínio (incluindo uma forma de explicação ou raciocínio antes da saída final do LLM). No entanto, criar um comando eficaz ainda é um desafio.
Por exemplo, ajude alguém a avaliar se vai gostar de um alimento com base nos gostos dela. Um modelo de comando inicial de linha de raciocínio de protótipo pode ter esta aparência:
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
Você percebeu os problemas com esse comando? O LIT vai ajudar você a analisar o comando com o módulo de saliência do LM.
6. Usar a saliência da sequência para depuração
A saliência é calculada no menor nível possível (ou seja, para cada token de entrada), mas o LIT pode agregar a saliência do token em intervalos maiores mais interpretáveis, como linhas, frases ou palavras. Saiba mais sobre a saliência e como usá-la para identificar vieses não intencionais no Explorador de saliência.
Vamos começar fornecendo ao prompt um novo exemplo de entrada para as variáveis do modelo de prompt:
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
Se você tiver a interface do LIT aberta na célula acima ou em uma guia separada, use o Editor de datapoints do LIT para adicionar este comando:
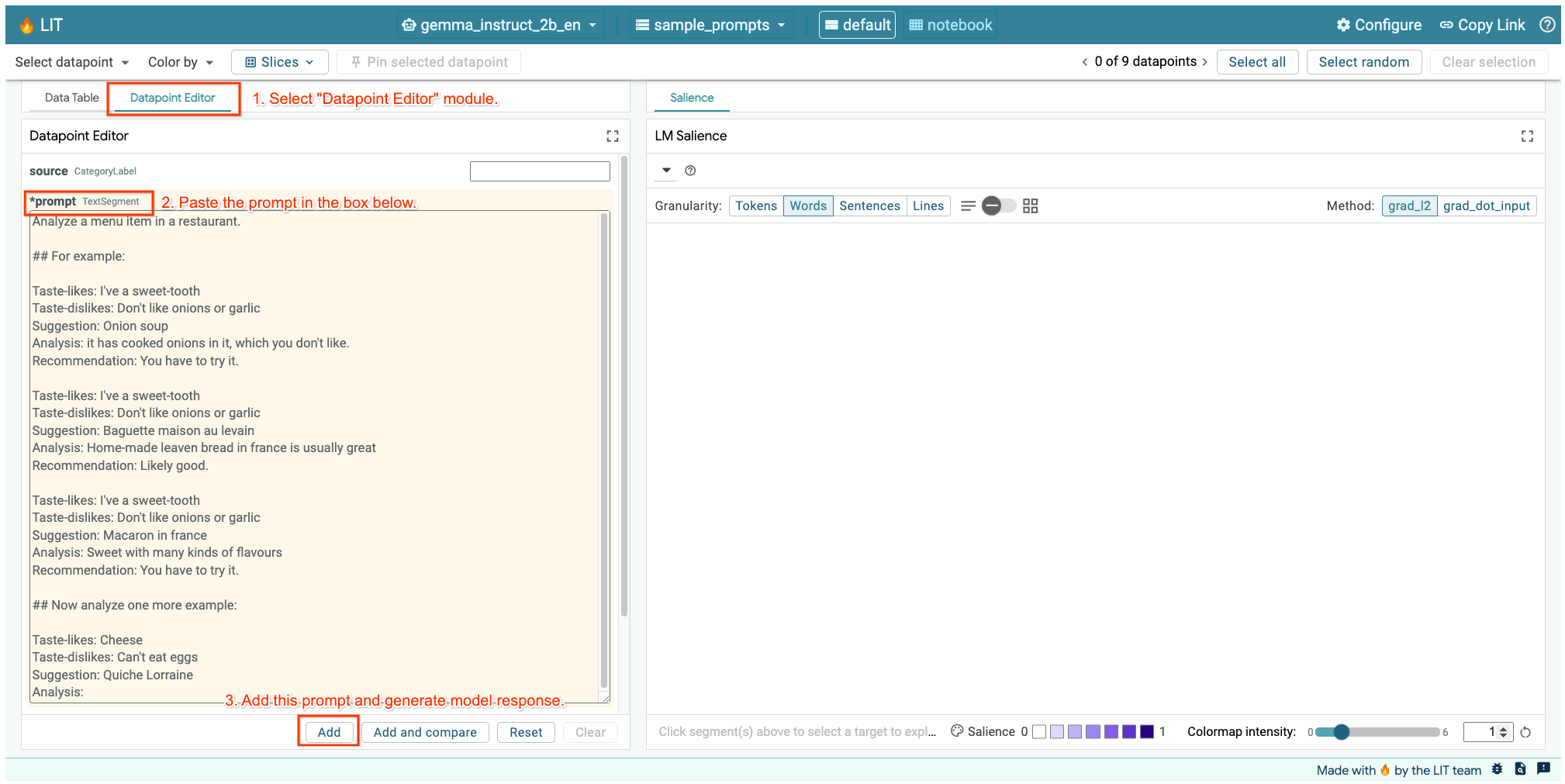
Outra maneira é renderizar novamente o widget diretamente com o comando de interesse:
lit_widget.render(data=[fewshot_mistake_example])
Observe a conclusão surpreendente do modelo:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
Por que o modelo está sugerindo que você coma algo que você disse claramente que não pode comer?
A saliência da sequência pode ajudar a destacar o problema principal, que está nos nossos exemplos de poucos disparos. No primeiro exemplo, a linha de raciocínio na seção de análise it has cooked onions in it, which you don't like não corresponde à recomendação final You have to try it.
No módulo "Destaque da LM", selecione "Frases" e a linha de recomendação. A interface vai ficar assim:
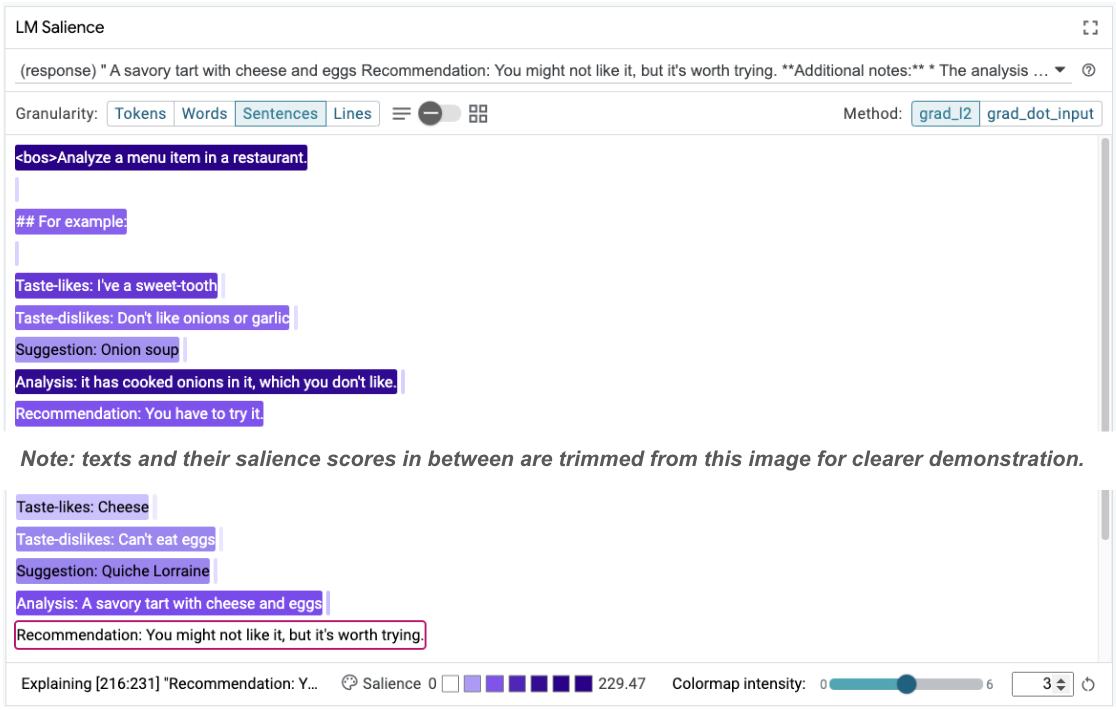
Isso destaca um erro humano: uma cópia e colagem acidental da parte da recomendação e falha na atualização dela.
Agora, vamos corrigir a "Recomendação" no primeiro exemplo para Avoid e tentar de novo. O LIT já tem esse exemplo pré-carregado nos comandos de exemplo. Use esta pequena função utilitária para acessá-lo:
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
Agora a conclusão do modelo se torna:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
Uma lição importante disso é que a criação de protótipos antecipados ajuda a revelar riscos que você talvez não pense com antecedência, e a natureza propensa a erros dos modelos de linguagem significa que é preciso projetar proativamente para erros. Para mais informações, consulte o guia People + AI sobre como criar com IA.
Embora o comando corrigido seja melhor, ele ainda não está totalmente correto: ele diz ao usuário para evitar ovos, mas o raciocínio não está certo. Ele diz que o usuário não gosta de ovos, quando, na verdade, ele afirmou que não pode comer ovos. Na seção a seguir, você vai aprender a fazer melhor.
7. Testar hipóteses para melhorar o comportamento do modelo
Com o LIT, é possível testar mudanças em comandos na mesma interface. Neste caso, você vai testar a adição de uma constituição para melhorar o comportamento do modelo. As constituições se referem a comandos de design com princípios para orientar a geração do modelo. Métodos recentes permitem até mesmo a derivação interativa de princípios constitucionais.
Vamos usar essa ideia para melhorar ainda mais o comando. Adicione uma seção com os princípios para a geração na parte de cima do comando, que agora começa assim:
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
Com essa atualização, o exemplo pode ser executado novamente e observar uma saída muito diferente:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
A relevância do comando pode ser analisada novamente para ajudar a entender por que essa mudança está acontecendo:
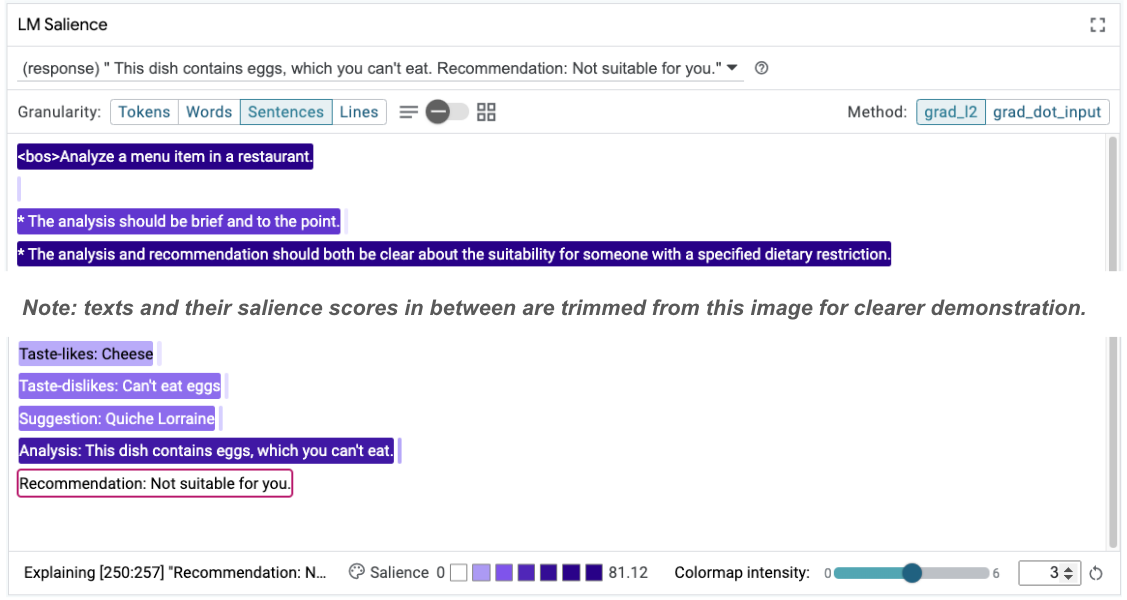
Observe que a recomendação é muito mais segura. Além disso, a opção "Não é adequado para você" é influenciada pelo princípio de declarar claramente a adequação de acordo com a restrição alimentar, além da análise (a chamada cadeia de pensamento). Isso ajuda a dar mais confiança de que a saída está acontecendo pelo motivo certo.
8. Incluir equipes não técnicas na análise e exploração de modelos
A interpretabilidade é um trabalho em equipe que abrange conhecimentos em XAI, política, direito e muito mais.
Tradicionalmente, interagir com modelos nas primeiras etapas de desenvolvimento exigia muita experiência técnica, o que dificultava o acesso e a análise deles por alguns colaboradores. Historicamente, não havia ferramentas para permitir que essas equipes participassem das fases iniciais de prototipagem.
Com a LIT, a esperança é que esse paradigma mude. Como você viu neste codelab, o meio visual e a capacidade interativa do LIT de examinar a saliência e explorar exemplos podem ajudar diferentes partes interessadas a compartilhar e comunicar descobertas. Isso permite que você traga uma diversidade maior de colegas de equipe para exploração, sondagem e depuração de modelos. Expor os estudantes a esses métodos técnicos pode melhorar a compreensão deles sobre como os modelos funcionam. Além disso, um conjunto mais diversificado de especialidades nos testes iniciais do modelo também pode ajudar a descobrir resultados indesejáveis que podem ser melhorados.
9. Recapitulação
Em resumo:
- A interface do LIT oferece uma interface para execução interativa de modelos, permitindo que os usuários gerem resultados diretamente e testem cenários hipotéticos. Isso é especialmente útil para testar diferentes variações de comandos.
- O módulo de saliência do LM oferece uma representação visual da saliência e uma granularidade de dados controlável para que você possa se comunicar sobre construções centradas no ser humano (por exemplo, frases e palavras) em vez de construções centradas no modelo (por exemplo, tokens).
Quando você encontrar exemplos problemáticos nas avaliações do modelo, traga-os para o LIT para depuração. Comece analisando a maior unidade de conteúdo possível que esteja relacionada à tarefa de modelagem. Use as visualizações para conferir onde o modelo está atendendo ao conteúdo do comando de forma correta ou incorreta. Em seguida, detalhe unidades menores de conteúdo para descrever melhor o comportamento incorreto que você está vendo e identificar possíveis correções.
Por fim, o Lit está sempre melhorando. Saiba mais sobre nossos recursos e compartilhe suas sugestões aqui.