
1. Giriş
Üretken yapay zeka ürünleri nispeten yenidir ve bir uygulamanın davranışları, önceki yazılım biçimlerine kıyasla daha fazla değişiklik gösterebilir. Bu nedenle, kullanılan makine öğrenimi modellerini incelemek, modelin davranış örneklerini incelemek ve beklenmedik sonuçları araştırmak önemlidir.
Learning Interpretability Tool (LIT; web sitesi, GitHub), makine öğrenimi modellerini hata ayıklama ve analiz etme platformudur. Bu platform, modellerin neden ve nasıl bu şekilde davrandığını anlamanıza yardımcı olur.
Bu codelab'de, Google'ın Gemma modelinden daha fazla yararlanmak için LIT'yi nasıl kullanacağınızı öğreneceksiniz. Bu codelab'de, farklı istem mühendisliği yaklaşımlarını analiz etmek için yorumlanabilirlik tekniği olan sıra öneminin nasıl kullanılacağı gösterilmektedir.
Öğrenme hedefleri:
- Sıra önemini ve model analizindeki kullanım alanlarını anlama
- Gemma'nın istem çıkışlarını hesaplaması ve önem sırasını belirlemesi için LIT'yi ayarlama.
- İstem tasarımlarının model çıktıları üzerindeki etkisini anlamak için LM Salience modülü aracılığıyla sıra önemini kullanma.
- LIT'de varsayılan istem iyileştirmelerini test edin ve etkilerini görün.
Bu codelab'de, arka uç için Gemma'nın KerasNLP uygulamasının ve TensorFlow v2'nin kullanıldığını unutmayın. Takip etmek için GPU çekirdeği kullanmanız önemle tavsiye edilir.
2. Sıra Önem Derecesi ve Model Analizindeki Kullanım Alanları
Gemma gibi metinden metne üretken modeller, jetonlaştırılmış metin biçiminde bir giriş dizisi alır ve bu girişi takip eden veya tamamlayan yeni jetonlar oluşturur. Bu oluşturma işlemi, model bir durdurma koşuluna ulaşana kadar her yeni oluşturulan jetonun girişe ve önceki oluşturmalara (bir döngü içinde) eklenmesiyle, her seferinde bir jeton olacak şekilde gerçekleşir. Örneğin, model dizinin sonu (EOS) jetonu oluşturduğunda veya önceden tanımlanmış maksimum uzunluğa ulaştığında.
Önem yöntemleri, bir girişin hangi bölümlerinin çıkışının farklı bölümleri için model açısından önemli olduğunu söyleyebilen bir açıklanabilir yapay zeka (XAI) tekniği sınıfıdır. LIT, çeşitli sınıflandırma görevleri için belirginlik yöntemlerini destekler. Bu yöntemler, giriş jetonları dizisinin tahmin edilen etiket üzerindeki etkisini açıklar. Sıra belirginliği, bu yöntemleri metinden metne üretken modellere genelleştirir ve önceki jetonların oluşturulan jetonlar üzerindeki etkisini açıklar.
Burada, sıra önemini belirlemek için Grad L2 Norm yöntemini kullanacaksınız. Bu yöntem, modelin gradyanlarını analiz eder ve her bir önceki jetonun çıktı üzerindeki etki büyüklüğünü sağlar. Bu yöntem basit ve verimlidir. Ayrıca sınıflandırma ve diğer ayarlarda iyi performans gösterdiği kanıtlanmıştır. Önem puanı ne kadar yüksekse etki de o kadar yüksek olur. Bu yöntem, iyi anlaşılması ve yorumlanabilirlik araştırması topluluğunda yaygın olarak kullanılması nedeniyle LIT'de kullanılır.
Daha gelişmiş gradyan tabanlı dikkat çekiciliği yöntemleri arasında Grad ⋅ Input ve entegre gradyanlar yer alır. Ayrıca, LIME ve SHAP gibi ablasyona dayalı yöntemler de mevcuttur. Bu yöntemler daha sağlam olabilir ancak hesaplanması önemli ölçüde daha maliyetlidir. Farklı dikkat çekicilik yöntemlerinin ayrıntılı karşılaştırması için bu makaleyi inceleyin.
Öne çıkma yöntemlerinin bilimi hakkında daha fazla bilgiyi Öne çıkma yöntemlerine giriş niteliğindeki bu etkileşimli keşif aracında bulabilirsiniz.
3. İçe Aktarmalar, Ortam ve Diğer Kurulum Kodu
Bu codelab'i yeni Colab'de takip etmeniz önerilir. Bir modeli belleğe yükleyeceğiniz için hızlandırıcı çalışma zamanı kullanmanızı öneririz. Ancak hızlandırıcı seçeneklerinin zaman içinde değiştiğini ve sınırlamalara tabi olduğunu unutmayın. Daha güçlü hızlandırıcılara erişmek istiyorsanız Colab'in ücretli aboneliklerinden yararlanabilirsiniz. Alternatif olarak, makinenizde uygun bir GPU varsa yerel çalışma zamanı da kullanabilirsiniz.
Not: Aşağıdaki biçimde bazı uyarılar görebilirsiniz:
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
Bu uyarıları yoksayabilirsiniz.
LIT ve Keras NLP'yi yükleme
Bu codelab için keras (3) keras-nlp (0.14.) ve lit-nlp (1.2) sürümlerinin güncel bir sürümüne ve temel modeli indirmek için bir Kaggle hesabına ihtiyacınız olacak.
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
Kaggle Erişimi
Kaggle ile kimlik doğrulamak için:
- Kimlik bilgilerinizi
~/.kaggle/kaggle.jsongibi bir dosyada saklayın. KAGGLE_USERNAMEveKAGGLE_KEYortam değişkenlerini kullanın veya- Aşağıdaki kodu Google Colab gibi etkileşimli bir Python ortamında çalıştırın.
import kagglehub
kagglehub.login()
Daha fazla bilgi için kagglehub dokümanlarını inceleyin ve Gemma lisans sözleşmesini kabul ettiğinizden emin olun.
Keras'ı yapılandırma
Keras 3, Tensorflow (varsayılan), PyTorch ve JAX dahil olmak üzere birden fazla derin öğrenme arka ucunu destekler. Arka uç, Keras kitaplığı içe aktarılmadan önce ayarlanması gereken KERAS_BACKEND ortam değişkeni kullanılarak yapılandırılır. Aşağıdaki kod snippet'inde, bu değişkenin etkileşimli bir Python ortamında nasıl ayarlanacağı gösterilmektedir.
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
4. LIT'yi ayarlama
LIT, Python not defterlerinde veya web sunucusu üzerinden kullanılabilir. Bu Codelab, not defteri kullanım alanına odaklanmaktadır. Google Colab'de takip etmenizi öneririz.
Bu Codelab'de, KerasNLP hazır ayarını kullanarak Gemma v2 2B IT'yi yükleyeceksiniz. Aşağıdaki snippet, Gemma'yı başlatır ve bir LIT Notebook widget'ına örnek bir veri kümesi yükler.
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
Gerekli iki konumsal bağımsız değişkene iletilen değerleri değiştirerek widget'ı yapılandırabilirsiniz:
datasets_config: "dataset:path" biçiminde, yüklenecek veri kümesi adlarını ve yollarını içeren bir dizeler listesi. Burada yol, bir URL veya yerel bir dosya yolu olabilir. Aşağıdaki örnekte, LIT dağıtımında sağlanan örnek istemleri yüklemek içinsample_promptsözel değeri kullanılmaktadır.models_config: "model:path" biçiminde, yüklenecek model adlarını ve yollarını içeren bir dizeler listesi. Burada yol, bir URL, yerel dosya yolu veya yapılandırılmış derin öğrenme çerçevesi için bir hazır ayarın adı olabilir.
LIT'yi ilgilendiğiniz modeli kullanacak şekilde yapılandırdıktan sonra, widget'ı not defterinizde oluşturmak için aşağıdaki kod snippet'ini çalıştırın.
lit_widget.render(open_in_new_tab=True)
Kendi verilerinizi kullanma
Gemma, metinden metne üretken bir model olarak metin girişini alır ve metin çıkışı oluşturur. LIT, yüklenen veri kümelerinin yapısını modellere iletmek için opinionated API'yi kullanır. LIT'deki LLM'ler, iki alan sağlayan veri kümeleriyle çalışmak üzere tasarlanmıştır:
prompt: Metnin oluşturulacağı modelin girişi vetarget: İsteğe bağlı bir hedef dizidir. Örneğin, değerlendiriciler tarafından verilen bir "kesin referans" yanıtı veya başka bir modelden önceden oluşturulmuş bir yanıt.
LIT, bu codelab'i ve LIT'in genişletilmiş istem hata ayıklama eğitimini destekleyen aşağıdaki kaynaklardan alınan örneklerle birlikte küçük bir sample_prompts kümesi içerir.
- GSM8K: İlkokul düzeyindeki matematik problemlerini az sayıda örnekle çözme.
- Gigaword Karşılaştırması: Kısa makalelerden oluşan bir koleksiyon için başlık oluşturma.
- Anayasal istem: Nesneleri yönergeler/sınırlar dahilinde kullanma konusunda yeni fikirler üretme.
Kendi verilerinizi de kolayca yükleyebilirsiniz. Verilerinizi .jsonl alanlar içeren kayıtlar prompt ve isteğe bağlı olarak target (örnek) içeren bir dosya olarak veya LIT'nin Dataset API'sini kullanarak herhangi bir biçimde yükleyebilirsiniz.
Örnek istemleri yüklemek için aşağıdaki hücreyi çalıştırın.
5. LIT'de Gemma için az görevli istemleri analiz etme
Günümüzde istem oluşturma, bilim kadar sanat da içerir. LIT, Gemma gibi büyük dil modelleri için istemleri deneysel olarak iyileştirmenize yardımcı olabilir. Aşağıda, LIT'nin Gemma'nın davranışlarını keşfetmek, olası sorunları öngörmek ve güvenliğini artırmak için nasıl kullanılabileceğine dair bir örnek göreceksiniz.
Karmaşık istemlerdeki hataları belirleme
Yüksek kaliteli LLM tabanlı prototipler ve uygulamalar için en önemli istem tekniklerinden ikisi az görevli istem (istemde istenen davranış örneklerini içerir) ve düşünce zinciri'dir (LLM'nin nihai çıktısından önce bir açıklama veya muhakeme biçimi içerir). Ancak etkili bir istem oluşturmak genellikle hâlâ zorlu bir süreçtir.
Bir kullanıcının, zevklerine göre yemeği beğenip beğenmeyeceğini değerlendirmesine yardımcı olma örneğini ele alalım. İlk prototip zincirleme düşünce istem şablonu şu şekilde görünebilir:
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
Bu istemle ilgili sorunları fark ettiniz mi? LIT, LM Salience modülü ile istemi incelemenize yardımcı olur.
6. Hata ayıklama için sıra belirginliğini kullanma
Öne çıkma, mümkün olan en küçük düzeyde (yani her giriş jetonu için) hesaplanır ancak LIT, jetonun öne çıkma durumunu satırlar, cümleler veya kelimeler gibi daha büyük ve yorumlanabilir aralıklar halinde toplayabilir. Öne çıkma ve bunu kullanarak istenmeyen önyargıları nasıl belirleyeceğiniz hakkında daha fazla bilgiyi Saliency Explorable (Öne Çıkma Keşif Aracı) sayfamızda bulabilirsiniz.
İstem şablonu değişkenleri için isteme yeni bir örnek giriş vererek başlayalım:
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
LIT kullanıcı arayüzü yukarıdaki hücrede veya ayrı bir sekmede açıksa bu istemi eklemek için LIT'nin Veri Noktası Düzenleyicisi'ni kullanabilirsiniz:
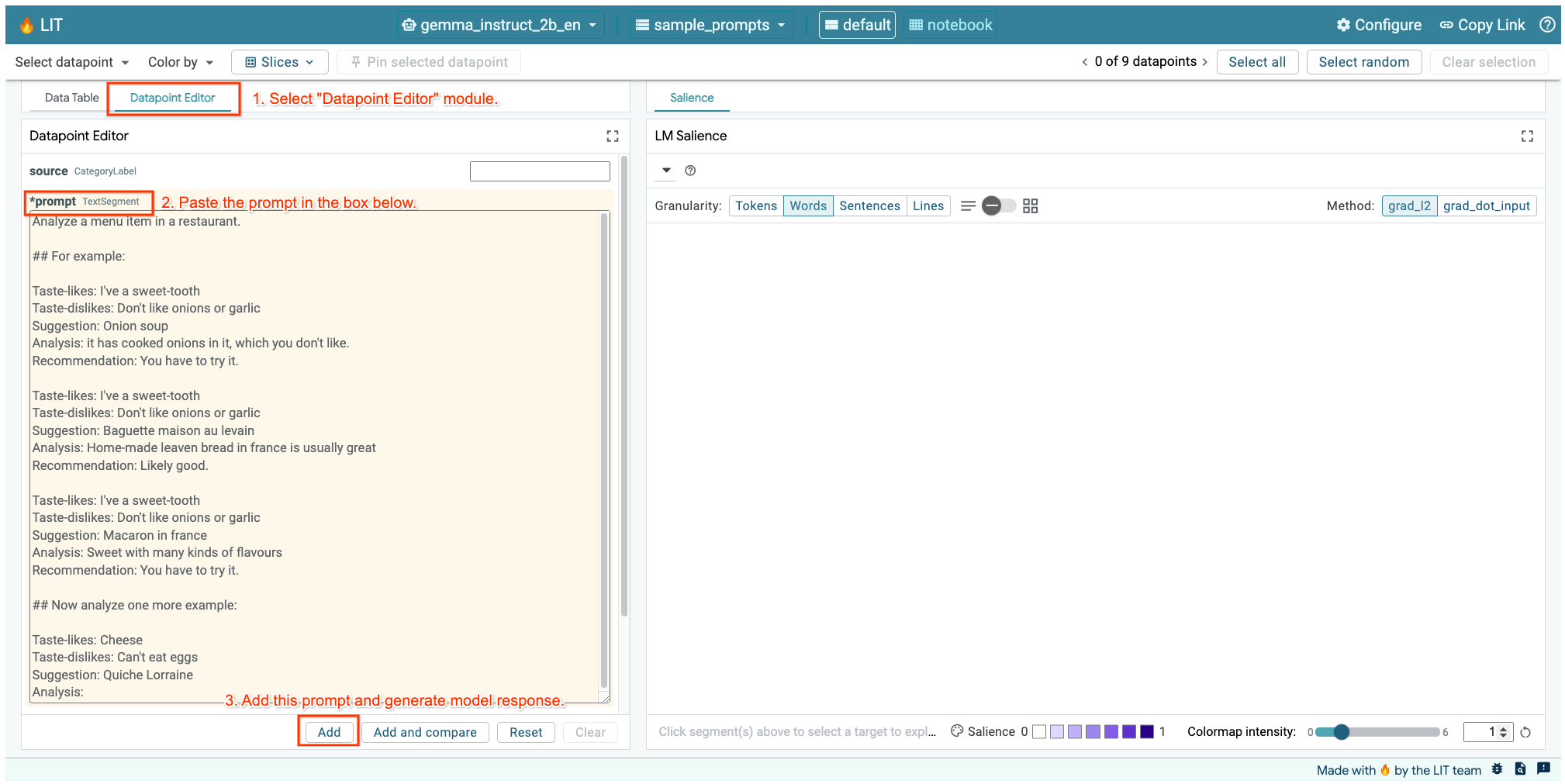
Başka bir yöntem de widget'ı doğrudan ilgilendiğiniz istemle yeniden oluşturmaktır:
lit_widget.render(data=[fewshot_mistake_example])
Şaşırtıcı model tamamlama:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
Model, açıkça yiyemeyeceğinizi söylediğiniz bir şeyi neden yemenizi öneriyor?
Sıra belirginliği, temel sorunu vurgulamaya yardımcı olabilir. Bu sorun, birkaç görevli örneklerimizde yer almaktadır. İlk örnekte, analiz bölümündeki it has cooked onions in it, which you don't like düşünce zinciri muhakemesi, nihai öneriyle You have to try it eşleşmiyor.
LM Salience (LM Önem Derecesi) modülünde "Sentences" (Cümleler) seçeneğini, ardından öneri satırını belirleyin. Kullanıcı arayüzü artık aşağıdaki gibi görünecektir:
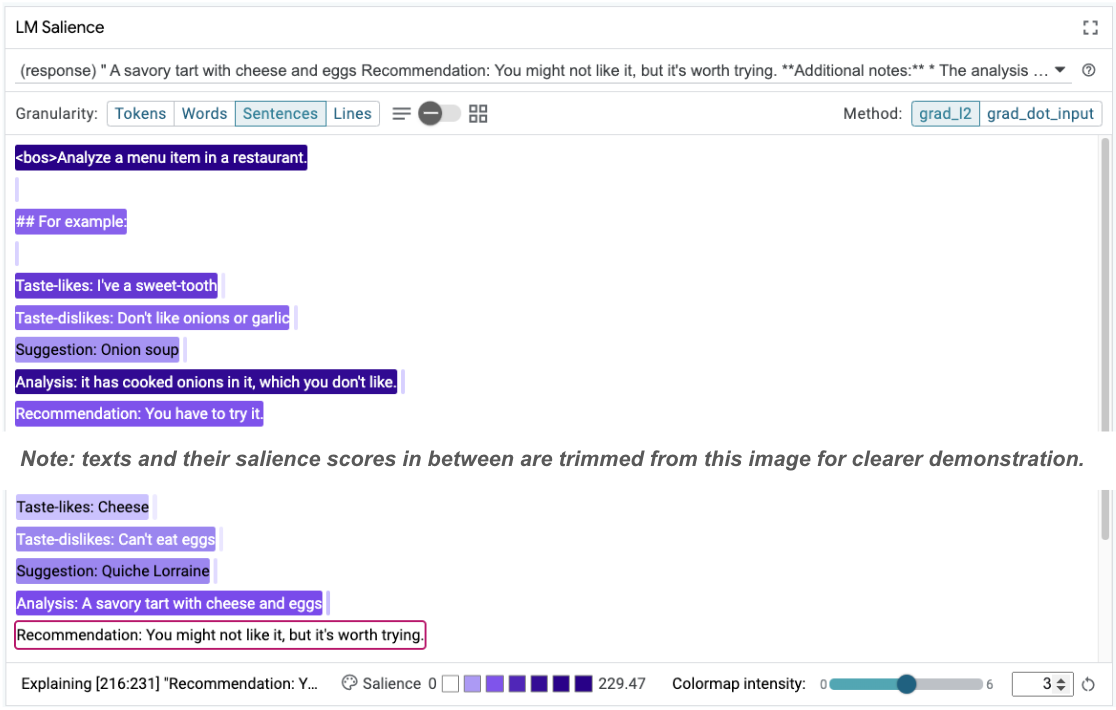
Bu, bir insan hatasını vurgular: Önerinin yanlışlıkla kopyalanıp yapıştırılması ve güncellenmemesi.
Şimdi ilk örnekteki "Öneri"yi Avoid olarak düzeltip tekrar deneyelim. LIT'de bu örnek, örnek istemlere önceden yüklenmiştir. Bu nedenle, bu küçük hizmet işlevini kullanarak örneği alabilirsiniz:
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
Modelin tamamlaması şu şekilde olur:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
Buradan çıkarılacak önemli ders şudur: Erken prototipleme, önceden düşünemeyeceğiniz riskleri ortaya çıkarmanıza yardımcı olur ve dil modellerinin hata yapmaya yatkın olması nedeniyle hatalara karşı proaktif bir şekilde tasarım yapılması gerekir. Bu konuyla ilgili daha fazla bilgiyi, yapay zeka ile tasarım yapma konulu İnsanlar + Yapay Zeka Rehberimizde bulabilirsiniz.
Düzeltilmiş birkaç görevli istem daha iyi olsa da hâlâ tam olarak doğru değil: Kullanıcıya yumurta yememesi gerektiğini doğru bir şekilde söylüyor ancak gerekçelendirme doğru değil. Kullanıcı yumurta yiyemediğini belirtmişken yumurtayı sevmediğini söylüyor. Aşağıdaki bölümde, daha iyi sonuçlar elde etmek için neler yapabileceğinizi öğreneceksiniz.
7. Model davranışını iyileştirmek için hipotezleri test etme
LIT, aynı arayüzde istemlerdeki değişiklikleri test etmenizi sağlar. Bu örnekte, modelin davranışını iyileştirmek için bir anayasa eklemeyi test edeceksiniz. Anayasalar, modelin oluşturma sürecine rehberlik etmeye yardımcı olacak ilkeler içeren tasarım istemlerini ifade eder. Son yöntemler, anayasal ilkelerin etkileşimli türetilmesine bile olanak tanır.
Bu fikri kullanarak istemi daha da iyileştirelim. İstemimizin en üstüne, oluşturma ilkelerini içeren bir bölüm ekleyin. İstemimiz artık şu şekilde başlıyor:
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
Bu güncelleme ile örnek yeniden çalıştırılabilir ve çok farklı bir çıkış gözlemlenebilir:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
Bu değişikliğin neden yapıldığını anlamak için istemin belirginliği yeniden incelenebilir:
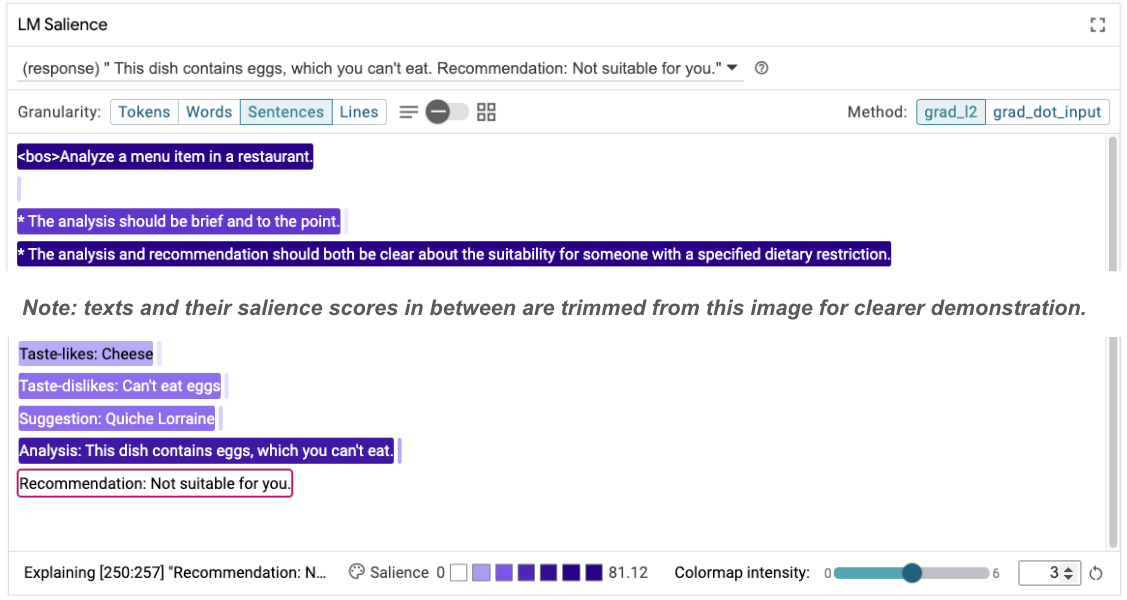
Önerinin çok daha güvenli olduğunu fark edeceksiniz. Ayrıca, "Size uygun değil" yanıtı, beslenme kısıtlamasına göre uygunluğun açıkça belirtilmesi ilkesinin yanı sıra analizden (sözde düşünce zinciri) etkilenir. Bu, çıktının doğru nedenle gerçekleştiğine dair ek güven sağlar.
8. Teknik olmayan ekipleri model sorgulama ve keşif sürecine dahil etme
Yorumlanabilirlik, XAI, politika ve hukuk gibi alanlardaki uzmanlığı kapsayan bir ekip çalışması olarak tasarlanmıştır.
Geliştirme sürecinin ilk aşamalarında modellerle etkileşim kurmak geleneksel olarak önemli ölçüde teknik uzmanlık gerektiriyordu. Bu durum, bazı iş ortaklarının modellere erişmesini ve bunları incelemesini zorlaştırıyordu. Geçmişte, bu ekiplerin ilk prototip oluşturma aşamalarına katılmasına olanak tanıyan araçlar yoktu.
LIT ile bu paradigmanın değişmesi hedefleniyor. Bu codelab'de gördüğünüz gibi, LIT'nin görsel ortamı ve öne çıkma durumunu inceleme ve örnekleri keşfetme konusundaki etkileşimli özelliği, farklı paydaşların bulgularını paylaşmasına ve iletmesine yardımcı olabilir. Bu sayede, model keşfi, inceleme ve hata ayıklama için daha çeşitli ekip arkadaşları getirebilirsiniz. Bu teknik yöntemleri kullanarak modellerin nasıl çalıştığını daha iyi anlamalarını sağlayabilirsiniz. Ayrıca, erken model testlerinde daha çeşitli bir uzmanlık seti, iyileştirilebilecek istenmeyen sonuçların ortaya çıkarılmasına da yardımcı olabilir.
9. Özet
Özetle:
- LIT kullanıcı arayüzü, etkileşimli model yürütme için bir arayüz sağlar. Bu arayüz, kullanıcıların doğrudan çıkış oluşturmasına ve "ne olurdu" senaryolarını test etmesine olanak tanır. Bu özellik, özellikle farklı istem varyasyonlarını test etmek için yararlıdır.
- LM Salience modülü, belirginliğin görsel bir temsilini sunar ve kontrol edilebilir veri ayrıntı düzeyi sağlar. Böylece, modele odaklı yapılar (ör. jetonlar) yerine insana odaklı yapılar (ör. cümleler ve kelimeler) hakkında iletişim kurabilirsiniz.
Model değerlendirmelerinizde sorunlu örnekler bulduğunuzda bunları hata ayıklama için LIT'ye aktarın. Modelleme göreviyle mantıksal olarak ilişkili olduğunu düşündüğünüz en büyük anlamlı içerik birimini analiz ederek başlayın. Modelin istem içeriğine doğru veya yanlış şekilde nerede dikkat ettiğini görmek için görselleştirmeleri kullanın. Ardından, olası düzeltmeleri belirlemek için gördüğünüz yanlış davranışı daha ayrıntılı bir şekilde açıklamak üzere daha küçük içerik birimlerine inin.
Son olarak: Lit sürekli olarak geliştirilmektedir. Özelliklerimiz hakkında daha fazla bilgi edinin ve önerilerinizi buradan paylaşın.