
۱. مقدمه
محصولات هوش مصنوعی مولد نسبتاً جدید هستند و رفتارهای یک برنامه میتواند بیش از اشکال اولیه نرمافزار متفاوت باشد. این امر بررسی مدلهای یادگیری ماشینی مورد استفاده، بررسی نمونههایی از رفتار مدل و بررسی شگفتیها را مهم میکند.
ابزار تفسیرپذیری یادگیری (LIT؛ وبسایت ، گیتهاب ) بستری برای اشکالزدایی و تحلیل مدلهای یادگیری ماشین است تا دلیل و چگونگی رفتار آنها را درک کنیم.
در این آزمایشگاه کد، یاد خواهید گرفت که چگونه از LIT برای بهرهبرداری بیشتر از مدل Gemma گوگل استفاده کنید. این آزمایشگاه کد نحوه استفاده از برجستگی توالی، یک تکنیک تفسیرپذیری، را برای تجزیه و تحلیل رویکردهای مختلف مهندسی سریع نشان میدهد.
اهداف یادگیری:
- درک برجستگی توالی و کاربردهای آن در تحلیل مدل
- راهاندازی LIT برای Gemma جهت محاسبه خروجیهای سریع و برجستگی توالی.
- استفاده از برجستگی توالی از طریق ماژول برجستگی LM برای درک تأثیر طرحهای سریع بر خروجیهای مدل.
- آزمایش فرضیهها، بهبودهای سریع در LIT را تسریع میکند و تأثیر آنها را مشاهده میکند.
توجه: این آزمایشگاه کد از پیادهسازی KerasNLP در Gemma و TensorFlow نسخه ۲ برای backend استفاده میکند. اکیداً توصیه میشود برای ادامه از یک هسته GPU استفاده کنید.

۲. برجستگی توالی و کاربردهای آن در تحلیل مدل
مدلهای مولد متن به متن، مانند Gemma، یک توالی ورودی را به شکل متن توکنشده دریافت میکنند و توکنهای جدیدی تولید میکنند که معمولاً دنبالهها یا تکمیلکنندههای آن ورودی هستند. این تولید توکن در هر زمان اتفاق میافتد و هر توکن جدید تولید شده (در یک حلقه) به ورودی به علاوه هر نسل قبلی اضافه میشود تا زمانی که مدل به یک شرط توقف برسد. مثالها شامل زمانی است که مدل یک توکن پایان توالی (EOS) تولید میکند یا به حداکثر طول از پیش تعریف شده میرسد.
روشهای برجستگی، دستهای از تکنیکهای هوش مصنوعی قابل توضیح (XAI) هستند که میتوانند به شما بگویند کدام بخشهای یک ورودی برای بخشهای مختلف خروجی مدل مهم هستند. LIT از روشهای برجستگی برای انواع وظایف طبقهبندی پشتیبانی میکند که تأثیر توالی توکنهای ورودی را بر برچسب پیشبینیشده توضیح میدهد. برجستگی توالی، این روشها را به مدلهای مولد متن به متن تعمیم میدهد و تأثیر توکنهای قبلی را بر توکنهای تولید شده توضیح میدهد.
شما در اینجا از روش Grad L2 Norm برای برجستگی توالی استفاده خواهید کرد، که گرادیانهای مدل را تجزیه و تحلیل میکند و میزان تأثیر هر نشانه قبلی بر خروجی را ارائه میدهد. این روش ساده و کارآمد است و نشان داده شده است که در طبقهبندی و سایر تنظیمات عملکرد خوبی دارد. هرچه امتیاز برجستگی بزرگتر باشد، تأثیر بیشتر است. این روش در LIT استفاده میشود زیرا به خوبی درک شده و به طور گسترده در جامعه تحقیقاتی تفسیرپذیری مورد استفاده قرار میگیرد.
روشهای پیشرفتهترِ تعیین برجستگی مبتنی بر گرادیان شامل Grad ⋅ Input و گرادیانهای یکپارچه هستند. همچنین روشهای مبتنی بر حذف مانند LIME و SHAP نیز موجود هستند که میتوانند قویتر باشند اما محاسبه آنها به طور قابل توجهی گرانتر است. برای مقایسه دقیق روشهای مختلف تعیین برجستگی، به این مقاله مراجعه کنید.
شما میتوانید در این کتاب تعاملی مقدماتی و قابل کاوش در مورد برجستگی، اطلاعات بیشتری در مورد علم روشهای برجستگی کسب کنید.
۳. کدهای ایمپورت، محیط و سایر تنظیمات
بهتر است این کدلب را در Colab جدید دنبال کنید. ما استفاده از یک زمان اجرای شتابدهنده را توصیه میکنیم، زیرا قرار است یک مدل را در حافظه بارگذاری کنید، هرچند توجه داشته باشید که گزینههای شتابدهنده با گذشت زمان تغییر میکنند و محدودیتهایی دارند. اگر میخواهید به شتابدهندههای قدرتمندتری دسترسی داشته باشید، Colab اشتراکهای پولی ارائه میدهد. همچنین، اگر دستگاه شما GPU مناسبی دارد، میتوانید از یک زمان اجرای محلی استفاده کنید.
توجه: ممکن است برخی از هشدارهای فرم را مشاهده کنید
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
نادیده گرفتن این موارد بیخطر است.
نصب LIT و Keras NLP
برای این آزمایشگاه کد، به نسخه جدیدی از keras (3) keras-nlp (0.14.) و lit-nlp (1.2) و یک حساب کاگل برای دانلود مدل پایه نیاز دارید.
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
دسترسی کاگل
برای احراز هویت با Kaggle ، میتوانید یکی از روشهای زیر را انجام دهید:
- اعتبارنامههای خود را در یک فایل، مانند
~/.kaggle/kaggle.jsonذخیره کنید. - از متغیرهای محیطی
KAGGLE_USERNAMEوKAGGLE_KEYاستفاده کنید؛ یا - دستور زیر را در یک محیط تعاملی پایتون، مانند Google Colab، اجرا کنید.
import kagglehub
kagglehub.login()
برای جزئیات بیشتر به مستندات kagglehub مراجعه کنید و حتماً توافقنامه مجوز Gemma را بپذیرید.
پیکربندی کِرَس
Keras 3 از چندین backend یادگیری عمیق ، از جمله Tensorflow (پیشفرض)، PyTorch و JAX، پشتیبانی میکند. backend با استفاده از متغیر محیطی KERAS_BACKEND پیکربندی شده است که باید قبل از وارد کردن کتابخانه Keras تنظیم شود. قطعه کد زیر نحوه تنظیم این متغیر را در یک محیط تعاملی پایتون نشان میدهد.
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
۴. راهاندازی LIT
LIT را میتوان در دفترچههای پایتون یا از طریق یک وب سرور استفاده کرد. این Codelab بر روی مورد استفاده دفترچه یادداشت تمرکز دارد، آیا توصیه میکنیم در Google Colab آن را دنبال کنید؟
در این Codelab، شما Gemma نسخه ۲ ۲B IT را با استفاده از پیشتنظیمات KerasNLP بارگذاری خواهید کرد. قطعه کد زیر Gemma را مقداردهی اولیه کرده و یک مجموعه داده نمونه را در یک ویجت LIT Notebook بارگذاری میکند.
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
شما میتوانید ویجت را با دو تغییر در مقادیر ارسالی به دو آرگومان موقعیتی مورد نیاز پیکربندی کنید:
-
datasets_config: فهرستی از رشتهها شامل نام مجموعه دادهها و مسیرهایی که باید از آنها بارگذاری شوند، به صورت "dataset:path"، که در آن path میتواند یک URL یا مسیر فایل محلی باشد. مثال زیر از مقدار ویژهsample_promptsبرای بارگذاری نمونههای ارائه شده در توزیع LIT استفاده میکند. -
models_config: فهرستی از رشتهها شامل نام مدلها و مسیرهایی که باید از آنها بارگذاری شوند، به صورت "model:path" که در آن path میتواند یک URL، مسیر فایل محلی یا نام یک پیشتنظیم برای چارچوب یادگیری عمیق پیکربندیشده باشد.
پس از پیکربندی LIT برای استفاده از مدل مورد نظر خود، قطعه کد زیر را اجرا کنید تا ویجت در نوتبوک شما رندر شود.
lit_widget.render(open_in_new_tab=True)
استفاده از دادههای خودتان
به عنوان یک مدل مولد متن به متن، Gemma ورودی متن را دریافت کرده و خروجی متن تولید میکند. LIT از یک API نظرمحور برای ارتباط ساختار مجموعه دادههای بارگذاری شده با مدلهای مدل استفاده میکند. LLMها در LIT برای کار با مجموعه دادههایی طراحی شدهاند که دو فیلد ارائه میدهند:
-
prompt: ورودی مدل که متن از آن تولید خواهد شد؛ و -
target: یک توالی هدف اختیاری، مانند پاسخ «حقیقت زمینهای» از ارزیابهای انسانی یا پاسخی از پیش تولید شده از مدل دیگر.
LIT شامل مجموعه کوچکی از sample_prompts به همراه مثالهایی از منابع زیر است که از این آموزش اشکالزدایی پیشرفته Codelab و LIT پشتیبانی میکنند.
- GSM8K : حل مسائل ریاضی دبستان با مثالهای کوتاه.
- معیار گیگا ورد : تولید تیتر برای مجموعهای از مقالات کوتاه.
- راهنمایی مبتنی بر قانون اساسی : خلق ایدههای جدید در مورد چگونگی استفاده از اشیاء با دستورالعملها/مرزها.
شما همچنین میتوانید به راحتی دادههای خود را بارگذاری کنید، چه به صورت یک فایل .jsonl حاوی رکوردهایی با فیلدهای prompt و target (به صورت اختیاری) ( مثال )، و چه از هر فرمتی با استفاده از API مجموعه دادههای LIT.
برای بارگذاری دستورات نمونه، سلول زیر را اجرا کنید.
۵. تحلیل چند صحنهی آماده برای جما در LIT
امروزه، راهنمایی به همان اندازه که علم است، هنر نیز هست، و LIT میتواند به شما کمک کند تا به صورت تجربی راهنماییها را برای مدلهای زبانی بزرگ، مانند Gemma، بهبود بخشید. در ادامه، مثالی از نحوه استفاده از LIT برای بررسی رفتارهای Gemma، پیشبینی مشکلات بالقوه و بهبود ایمنی آن را مشاهده خواهید کرد.
شناسایی خطاها در دستورات پیچیده
دو مورد از مهمترین تکنیکهای ایجاد انگیزه برای نمونههای اولیه و کاربردهای مبتنی بر LLM با کیفیت بالا ، ایجاد انگیزه در چند مرحله (شامل نمونههایی از رفتار مطلوب در انگیزه) و زنجیره فکری (شامل نوعی توضیح یا استدلال قبل از خروجی نهایی LLM) است. اما ایجاد یک انگیزه مؤثر اغلب هنوز چالش برانگیز است.
مثالی را در نظر بگیرید که در آن به کسی کمک میکنید تا ارزیابی کند که آیا بر اساس ذائقهاش غذا را دوست خواهد داشت یا خیر. یک الگوی اولیه از زنجیره فکری میتواند چیزی شبیه به این باشد:
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
آیا متوجه مشکلات این سوال شدید؟ LIT به شما کمک میکند تا سوال را با ماژول LM Salience بررسی کنید.
۶. از برجستگی توالی برای اشکالزدایی استفاده کنید
برجستگی در کوچکترین سطح ممکن محاسبه میشود (یعنی برای هر نشانه ورودی)، اما LIT میتواند برجستگی نشانه را در محدودههای بزرگتر و قابل تفسیرتر، مانند خطوط، جملات یا کلمات، تجمیع کند. برای کسب اطلاعات بیشتر در مورد برجستگی و نحوه استفاده از آن برای شناسایی سوگیریهای ناخواسته، به بخش برجستگی قابل کاوش ما مراجعه کنید.
بیایید با دادن یک ورودی نمونه جدید برای متغیرهای prompt-template شروع کنیم:
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
اگر رابط کاربری LIT را در سلول بالا یا در یک تب جداگانه باز کردهاید، میتوانید از ویرایشگر Datapoint LIT برای اضافه کردن این اعلان استفاده کنید:
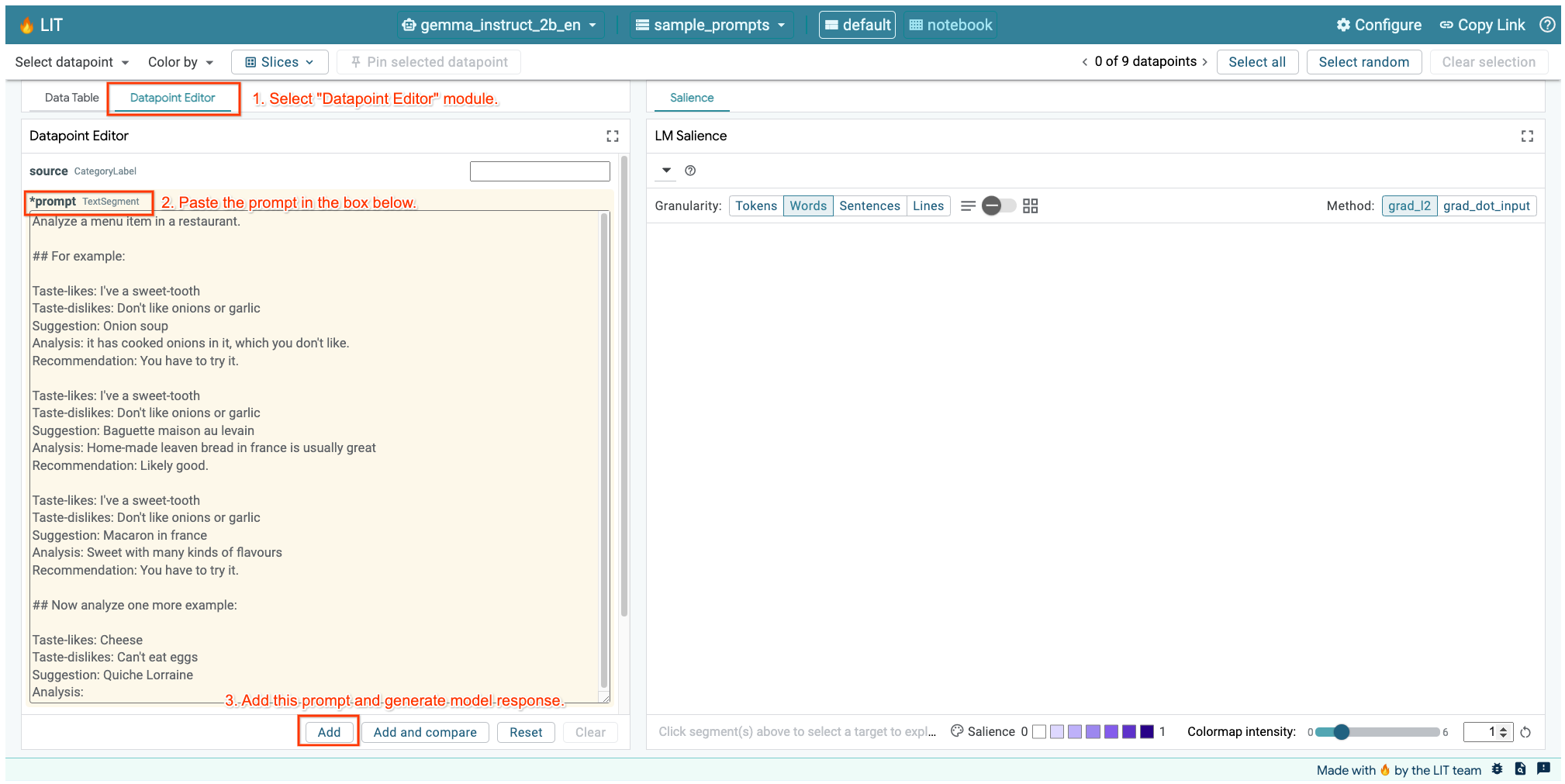
راه دیگر این است که ویجت را مستقیماً با اعلان مورد نظر، مجدداً رندر کنید:
lit_widget.render(data=[fewshot_mistake_example])
به تکمیل شگفتانگیز مدل توجه کنید:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
چرا مدل به شما پیشنهاد میدهد چیزی را بخورید که به وضوح گفتهاید نمیتوانید بخورید؟
برجستگی توالی میتواند به برجسته کردن مشکل ریشهای، که در مثالهای معدود ما وجود دارد، کمک کند. در مثال اول، استدلال زنجیره فکری در بخش تحلیل it has cooked onions in it, which you don't like با توصیه نهایی You have to try it ، مطابقت ندارد.
در ماژول LM Salience، گزینه "Sentences" و سپس خط توصیه را انتخاب کنید. رابط کاربری اکنون باید به شکل زیر باشد:

این یک خطای انسانی را برجسته میکند: کپی و پیست تصادفی بخش توصیه و عدم بهروزرسانی آن!
حالا بیایید «توصیه» را در مثال اول به Avoid اصلاح کنیم و دوباره امتحان کنیم. LIT این مثال را از قبل در نمونه سوالات بارگذاری کرده است، بنابراین میتوانید از این تابع کاربردی کوچک برای دریافت آن استفاده کنید:
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
اکنون تکمیل مدل به صورت زیر میشود:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
درس مهمی که میتوان از این موضوع گرفت این است: نمونهسازی اولیه به آشکار شدن خطراتی که ممکن است از قبل به آنها فکر نکرده باشید، کمک میکند و ماهیت مستعد خطا بودن مدلهای زبانی به این معنی است که باید به طور پیشگیرانه برای خطاها طراحی کرد. بحث بیشتر در این مورد را میتوانید در کتاب راهنمای People + AI ما برای طراحی با هوش مصنوعی بیابید.
اگرچه دستور اصلاحشدهی چند شات بهتر است، اما هنوز کاملاً درست نیست: به درستی به کاربر میگوید که از تخممرغ پرهیز کند، اما استدلال درست نیست، میگوید که آنها تخممرغ دوست ندارند، در حالی که در واقع کاربر گفته است که نمیتواند تخممرغ بخورد. در بخش بعدی، خواهید دید که چگونه میتوانید بهتر عمل کنید.
۷. فرضیهها را برای بهبود رفتار مدل آزمایش کنید
LIT شما را قادر میسازد تا تغییرات در دستورالعملها را در همان رابط کاربری آزمایش کنید. در این مثال، شما قصد دارید اضافه کردن یک قانون اساسی را برای بهبود رفتار مدل آزمایش کنید. قوانین اساسی به دستورالعملهای طراحی با اصولی اشاره دارند که به هدایت تولید مدل کمک میکنند. روشهای اخیر حتی امکان استخراج تعاملی اصول قانون اساسی را فراهم میکنند.
بیایید از این ایده برای بهبود بیشتر دستورالعمل استفاده کنیم. بخشی را با اصول مربوط به تولید در بالای دستورالعمل خود اضافه کنید که اکنون به شرح زیر شروع میشود:
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
با این بهروزرسانی، میتوان مثال را دوباره اجرا کرد و خروجی بسیار متفاوتی را مشاهده کرد:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
سپس میتوان اهمیت فوری را دوباره بررسی کرد تا به درک دلیل وقوع این تغییر کمک کند:

توجه داشته باشید که این توصیه بسیار ایمنتر است. علاوه بر این، عبارت «برای شما مناسب نیست» تحت تأثیر اصل بیان واضح مناسب بودن با توجه به محدودیت غذایی، همراه با تجزیه و تحلیل (به اصطلاح زنجیره فکری) قرار دارد. این امر به اطمینان بیشتر در مورد اینکه خروجی به دلیل درستی اتفاق میافتد، کمک میکند.
۸. تیمهای غیرفنی را در بررسی و اکتشاف مدل دخیل کنید
قابلیت تفسیر به معنای یک تلاش تیمی است که تخصص را در حوزههای XAI، سیاست، قانون و موارد دیگر در بر میگیرد.
تعامل با مدلها در مراحل اولیه توسعه، به طور سنتی نیازمند تخصص فنی قابل توجهی بوده است، که دسترسی و بررسی آنها را برای برخی از همکاران دشوارتر میکرد. از نظر تاریخی، ابزارهایی وجود نداشته است که این تیمها را قادر به شرکت در مراحل اولیه نمونهسازی کند.
امید است که از طریق LIT این الگو تغییر کند. همانطور که در این آزمایشگاه کد مشاهده کردید، محیط بصری و توانایی تعاملی LIT برای بررسی برجستگی و کاوش مثالها میتواند به ذینفعان مختلف کمک کند تا یافتهها را به اشتراک گذاشته و با یکدیگر در میان بگذارند. این امر میتواند شما را قادر سازد تا طیف وسیعتری از همتیمیها را برای کاوش، بررسی و اشکالزدایی مدل گرد هم آورید. قرار دادن آنها در معرض این روشهای فنی میتواند درک آنها از نحوه عملکرد مدلها را افزایش دهد. علاوه بر این، مجموعهای متنوعتر از تخصصها در آزمایش اولیه مدل نیز میتواند به کشف نتایج نامطلوبی که میتوانند بهبود یابند، کمک کند.
۹. خلاصه
برای خلاصه کردن:
- رابط کاربری LIT رابطی برای اجرای مدل تعاملی فراهم میکند و کاربران را قادر میسازد تا مستقیماً خروجیها را تولید کرده و سناریوهای «چه میشود اگر» را آزمایش کنند. این امر به ویژه برای آزمایش انواع مختلف اعلان مفید است.
- ماژول LM Salience نمایش بصری از برجستگی را ارائه میدهد و جزئیات دادههای قابل کنترلی را فراهم میکند تا بتوانید به جای ساختارهای مدلمحور (مثلاً توکنها)، در مورد ساختارهای انسانمحور (مثلاً جملات و کلمات) ارتباط برقرار کنید.
وقتی در ارزیابیهای مدل خود نمونههای مشکلدار پیدا کردید، آنها را برای اشکالزدایی به LIT بیاورید. با تجزیه و تحلیل بزرگترین واحد معقول محتوایی که میتوانید به آن فکر کنید و منطقاً به وظیفه مدلسازی مربوط میشود، شروع کنید، از تجسمها استفاده کنید تا ببینید مدل در کجا به درستی یا نادرستی به محتوای درخواستی توجه میکند، و سپس به واحدهای کوچکتر محتوا بروید تا رفتار نادرستی را که میبینید بیشتر توصیف کنید تا بتوانید راهحلهای ممکن را شناسایی کنید.
در آخر: لیت دائماً در حال بهبود است! درباره ویژگیهای ما بیشتر بدانید و پیشنهادات خود را اینجا به اشتراک بگذارید.