
1. מבוא
מוצרי AI גנרטיבי הם חדשים יחסית, וההתנהגויות של אפליקציה יכולות להיות מגוונות יותר מאשר בגרסאות קודמות של תוכנות. לכן חשוב לבדוק את המודלים של למידת מכונה שבהם נעשה שימוש, לבחון דוגמאות להתנהגות המודל ולחקור הפתעות.
הכלי Learning Interpretability Tool (LIT; אתר, GitHub) הוא פלטפורמה לניפוי באגים ולניתוח של מודלים של למידת מכונה, כדי להבין למה ואיך הם מתנהגים כמו שהם מתנהגים.
ב-codelab הזה תלמדו איך להשתמש ב-LIT כדי להפיק יותר מהמודל Gemma של Google. Codelab זה מדגים איך להשתמש בטכניקת ההסבר של רצף חשיבות (salience) כדי לנתח גישות שונות להנדסת הנחיות.
יעדי למידה:
- הסבר על חשיבות הרצף והשימושים שלו בניתוח מודלים.
- הגדרת LIT לחישוב פלט הנחיות ומידת החשיבות של רצפים ב-Gemma.
- שימוש בבולטות של רצף באמצעות המודול LM Salience כדי להבין את ההשפעה של עיצוב הנחיות על פלט המודל.
- בדיקת שיפורים היפותטיים בהנחיות ב-LIT ובחינת ההשפעה שלהם.
הערה: ב-codelab הזה נעשה שימוש בהטמעה של Gemma ב-KerasNLP וב-TensorFlow v2 עבור ה-backend. מומלץ מאוד להשתמש בגרעין GPU כדי לעקוב אחרי ההנחיות.

2. הדגשת רצפים והשימושים שלה בניתוח מודלים
מודלים גנרטיביים של יצירת טקסט על סמך טקסט, כמו Gemma, מקבלים רצף קלט בצורה של טקסט עם טוקניזציה ויוצרים טוקנים חדשים שהם בדרך כלל המשכים או השלמות של הקלט הזה. היצירה הזו מתבצעת טוקן אחד בכל פעם, וכל טוקן חדש שנוצר מתווסף (בלולאה) לקלט ולכל היצירות הקודמות, עד שהמודל מגיע לתנאי עצירה. לדוגמה, כשהמודל יוצר אסימון לסיום הרצף (EOS) או מגיע לאורך המקסימלי המוגדר מראש.
שיטות בולטות הן סוג של טכניקות AI שניתנות להסבר (XAI) שיכולות להראות לכם אילו חלקים בקלט חשובים למודל עבור חלקים שונים בפלט שלו. LIT תומך בשיטות בולטות למגוון משימות סיווג, שמסבירות את ההשפעה של רצף של טוקנים של קלט על התווית החזויה. השיטה Sequence salience מכלילה את השיטות האלה למודלים גנרטיביים של יצירת טקסט על סמך טקסט, ומסבירה את ההשפעה של הטוקנים הקודמים על הטוקנים שנוצרו.
כאן תשתמשו בשיטה Grad L2 Norm כדי לזהות את החלקים החשובים ברצף. השיטה הזו מנתחת את הגרדיאנטים של המודל ומספקת את עוצמת ההשפעה של כל טוקן קודם על הפלט. השיטה הזו פשוטה ויעילה, והוכח שהיא פועלת היטב בסיווג ובהגדרות אחרות. ככל שציון הבולטות גבוה יותר, כך ההשפעה גדולה יותר. השיטה הזו נמצאת בשימוש ב-LIT כי היא מובנת היטב ונעשה בה שימוש נרחב בקהילת המחקר בתחום הפרשנות.
שיטות מתקדמות יותר לזיהוי אזורים חשובים שמבוססות על צבעים מדורגים כוללות את Grad ⋅ Input וצבעים מדורגים משולבים. יש גם שיטות שמבוססות על אבלציה, כמו LIME ו-SHAP, שיכולות להיות חזקות יותר אבל יקרות משמעותית לחישוב. במאמר הזה מופיעה השוואה מפורטת בין שיטות שונות לחישוב רמת החשיבות.
במדריך האינטראקטיבי הזה בנושא שיטות להדגשת תוכן אפשר לקבל מידע נוסף על המדע שמאחורי השיטות האלה.
3. ייבוא, סביבה וקוד הגדרה אחר
מומלץ לעבוד עם ה-codelab הזה ב-Colab חדש. מומלץ להשתמש בזמן ריצה של מאיץ, כי אתם תטענו מודל לזיכרון. עם זאת, חשוב לדעת שאפשרויות המאיץ משתנות עם הזמן וכפופות למגבלות. אם רוצים גישה למאיצים חזקים יותר, אפשר להירשם למינויים בתשלום ל-Colab. אפשרות אחרת היא להשתמש בסביבת זמן ריצה מקומית אם במחשב שלכם יש GPU מתאים.
הערה: יכול להיות שיוצגו אזהרות מסוימות לגבי הטופס
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
אפשר להתעלם מהן.
התקנה של LIT ו-Keras NLP
כדי להשתמש ב-codelab הזה, תצטרכו גרסה עדכנית של keras (3) keras-nlp (0.14.) ושל lit-nlp (1.2), וחשבון Kaggle כדי להוריד את מודל הבסיס.
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
גישה ל-Kaggle
כדי להיכנס ל-Kaggle, אפשר:
- שומרים את פרטי הכניסה בקובץ, כמו
~/.kaggle/kaggle.json. - משתמשים במשתני הסביבה
KAGGLE_USERNAMEו-KAGGLE_KEY. - מריצים את הפקודה הבאה בסביבת Python אינטראקטיבית, כמו Google Colab.
import kagglehub
kagglehub.login()
פרטים נוספים זמינים במסמכי התיעוד של kagglehub. חשוב לאשר את הסכם הרישיון של Gemma.
הגדרת Keras
Keras 3 תומך במספר רב של backends ללמידה עמוקה, כולל TensorFlow (ברירת מחדל), PyTorch ו-JAX. הבק-אנד מוגדר באמצעות משתנה הסביבה KERAS_BACKEND, שצריך להגדיר אותו לפני ייבוא ספריית Keras. בקטע הקוד הבא אפשר לראות איך מגדירים את המשתנה הזה בסביבת Python אינטראקטיבית.
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
4. הגדרת LIT
אפשר להשתמש ב-LIT ב-Python Notebooks או דרך שרת אינטרנט. ה-Codelab הזה מתמקד בתרחיש השימוש של Notebook, ואנחנו ממליצים לעקוב אחרי ההוראות ב-Google Colab.
ב-Codelab הזה תטענו את Gemma v2 2B IT באמצעות הגדרות קבועות מראש של KerasNLP. בקטע הקוד הבא מתבצעת אתחול של Gemma וטעינה של מערך נתונים לדוגמה בווידג'ט LIT Notebook.
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
אפשר להגדיר את הווידג'ט על ידי שינוי הערכים שמועברים לשני הארגומנטים המיקומיים הנדרשים:
-
datasets_config: רשימה של מחרוזות שמכילות את שמות קבוצות הנתונים והנתיבים לטעינה, בתבנית dataset:path, כאשר הנתיב יכול להיות כתובת URL או נתיב לקובץ מקומי. בדוגמה שלמטה נעשה שימוש בערך המיוחד,sample_prompts, כדי לטעון את ההנחיות לדוגמה שמופיעות בהפצה של LIT. -
models_config: רשימה של מחרוזות שמכילות את שמות המודלים והנתיבים לטעינה מהם, בתבנית model:path, כאשר path יכול להיות כתובת URL, נתיב לקובץ מקומי או שם של הגדרה קבועה מראש למסגרת הלמידה העמוקה שהוגדרה.
אחרי שמגדירים את LIT לשימוש במודל שמעניין אתכם, מריצים את קטע הקוד הבא כדי להציג את הווידג'ט ב-Notebook.
lit_widget.render(open_in_new_tab=True)
שימוש בנתונים שלכם
כמודל גנרטיבי של יצירת טקסט על סמך טקסט, Gemma מקבל טקסט כקלט ומפיק טקסט כפלט. LIT משתמש בopinionated API כדי להעביר למודלים את המבנה של מערכי הנתונים שנטענו. מודלים גדולים של שפה (LLM) ב-LIT מיועדים לעבודה עם מערכי נתונים שמספקים שני שדות:
-
prompt: הקלט למודל שממנו ייווצר הטקסט. -
target: רצף יעד אופציונלי, כמו תגובה של 'אמת בסיסית' שניתנה על ידי בודקים אנושיים או תגובה שנוצרה מראש על ידי מודל אחר.
LIT כולל קבוצה קטנה של sample_prompts עם דוגמאות מהמקורות הבאים, שתומכות ב-Codelab הזה ובמדריך המורחב לניפוי באגים בהנחיות של LIT.
- GSM8K: פתרון בעיות מתמטיות של בית ספר יסודי עם כמה דוגמאות.
- Gigaword Benchmark: יצירת כותרות לאוסף של מאמרים קצרים.
- הנחיות חוקתיות: יצירת רעיונות חדשים לשימוש באובייקטים עם הנחיות או גבולות.
אפשר גם לטעון בקלות נתונים משלכם, או כקובץ .jsonl שמכיל רשומות עם שדות prompt ואופציונלית target (דוגמה), או מכל פורמט באמצעות Dataset API של LIT.
מריצים את התא שלמטה כדי לטעון את ההנחיות לדוגמה.
5. ניתוח הנחיות עם דוגמאות בודדות ל-Gemma ב-LIT
כיום, יצירת הנחיות היא גם אומנות וגם מדע, ו-LIT יכול לעזור לכם לשפר באופן אמפירי את ההנחיות למודלים גדולים של שפה, כמו Gemma. בהמשך תראו דוגמה לאופן השימוש ב-LIT כדי לבחון את ההתנהגויות של Gemma, לחזות בעיות פוטנציאליות ולשפר את הבטיחות שלו.
זיהוי שגיאות בהנחיות מורכבות
שתי טכניקות חשובות במיוחד ליצירת אבות-טיפוס ויישומים איכותיים שמבוססים על מודלים גדולים של שפה (LLM) הן הנחיה עם כמה דוגמאות (כולל דוגמאות להתנהגות הרצויה בהנחיה) ושרשרת חשיבה (כולל הסבר או נימוק לפני הפלט הסופי של ה-LLM). אבל עדיין מאתגר ליצור הנחיה אפקטיבית.
לדוגמה, אפשר לעזור למישהו להעריך אם הוא יאהב אוכל מסוים על סמך הטעם שלו. תבנית הנחיה ראשונית בטכניקת שרשרת חשיבה עשויה להיראות כך:
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
האם זיהית את הבעיות בהנחיה הזו? LIT יעזור לכם לבחון את ההנחיה באמצעות מודול בולטות של LM.
6. שימוש במידת החשיבות של רצף לניפוי באגים
הערך של הבולטות מחושב ברמה הקטנה ביותר האפשרית (כלומר, לכל טוקן קלט), אבל LIT יכול לצבור את ערכי הבולטות של הטוקנים לטווחים גדולים יותר שקל יותר לפרש, כמו שורות, משפטים או מילים. בכלי לזיהוי אזורים בולטים אפשר לקרוא מידע נוסף על בולטות ועל האופן שבו אפשר להשתמש בה כדי לזהות הטיה לא מכוונת.
נתחיל בכך שנספק להנחיה דוגמה חדשה של קלט למשתני תבנית ההנחיה:
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
אם ממשק המשתמש של LIT פתוח בתא שמעל או בכרטיסייה נפרדת, אפשר להשתמש בכלי לעריכת נקודות נתונים של LIT כדי להוסיף את ההנחיה הזו:

דרך נוספת היא לעבד מחדש את הווידג'ט ישירות עם ההנחיה הרלוונטית:
lit_widget.render(data=[fewshot_mistake_example])
שימו לב להשלמה המפתיעה של המודל:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
למה המודל מציע לך לאכול משהו שאמרת בבירור שאתה לא יכול לאכול?
ההדגשה של רצף יכולה לעזור להבליט את שורש הבעיה, שמופיע בדוגמאות שלנו עם מעט נתונים. בדוגמה הראשונה, הנימוק של שרשרת המחשבות בקטע הניתוח it has cooked onions in it, which you don't like לא תואם להמלצה הסופית You have to try it.
במודול LM Salience, בוחרים באפשרות 'משפטים' ואז בוחרים את שורת ההמלצה. ממשק המשתמש אמור להיראות עכשיו כך:
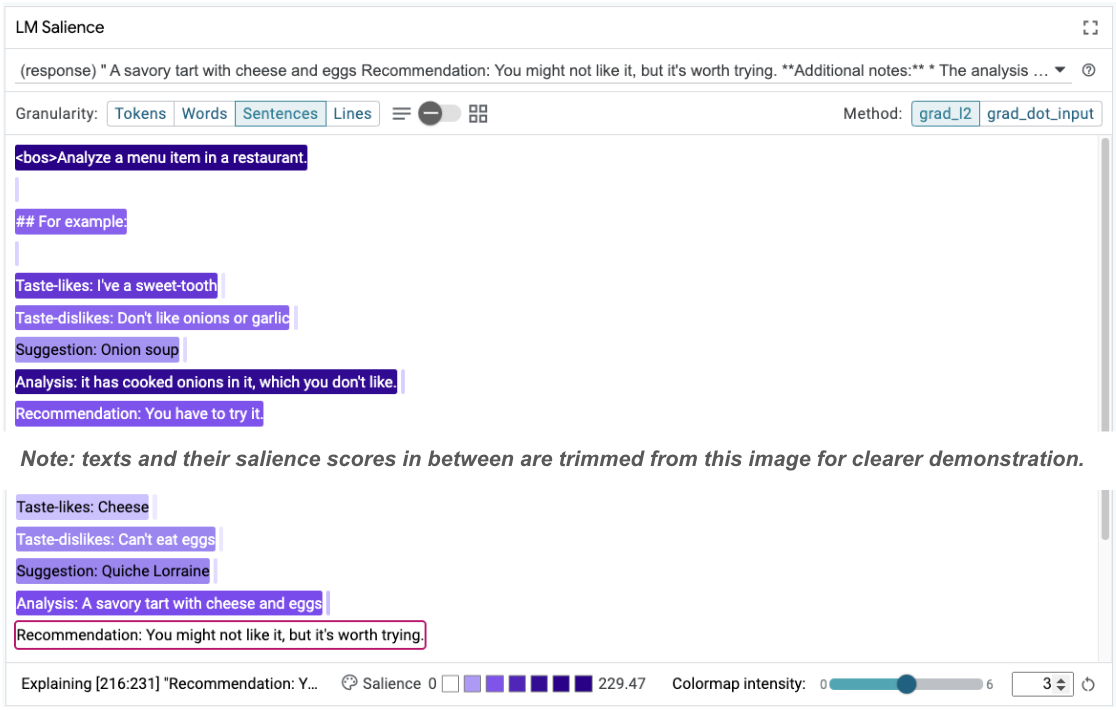
השגיאה הזו היא טעות אנוש: העתקה והדבקה של חלק ההמלצה בטעות, בלי לעדכן אותו.
עכשיו נתקן את ההמלצה בדוגמה הראשונה ל-Avoid וננסה שוב. הדוגמה הזו כבר נטענה מראש בהנחיות לדוגמה של LIT, כך שאפשר להשתמש בפונקציה הבסיסית הקטנה הזו כדי לאחזר אותה:
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
עכשיו השלמת המודל היא:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
הלקח החשוב שצריך להסיק מכאן הוא: אב טיפוס מוקדם עוזר לחשוף סיכונים שאולי לא חשבתם עליהם מראש, והנטייה של מודלים של שפה לטעות מחייבת לתכנן מראש את הטיפול בשגיאות. דיון נוסף בנושא הזה מופיע במדריך שלנו בנושא אנשים + AI לתכנון באמצעות AI.
ההנחיה המתוקנת עם כמה דוגמאות טובה יותר, אבל היא עדיין לא מדויקת: היא אומרת למשתמש להימנע מביצים, אבל החשיבה הרציונלית לא נכונה. היא אומרת שהיא לא אוהבת ביצים, אבל למעשה המשתמש אמר שהוא לא יכול לאכול ביצים. בקטע הבא מוסבר איך לשפר את הביצועים.
7. בדיקת השערות כדי לשפר את התנהגות המודל
הכלי LIT מאפשר לכם לבדוק שינויים בהנחיות באותו ממשק. בדוגמה הזו, אתם תבדקו הוספה של חוקה כדי לשפר את התנהגות המודל. חוקות הן הנחיות עיצוב עם עקרונות שמנחים את יצירת התוכן על ידי המודל. שיטות עדכניות אפילו מאפשרות הסקה אינטראקטיבית של עקרונות חוקתיים.
נשתמש ברעיון הזה כדי לשפר עוד יותר את ההנחיה. להוסיף קטע עם העקרונות ליצירה בחלק העליון של ההנחיה, שמתחילה עכשיו כך:
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
בעקבות העדכון הזה, אפשר להריץ מחדש את הדוגמה ולראות פלט שונה מאוד:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
אפשר לבדוק מחדש את מידת ההבלטה של ההנחיה כדי להבין למה השינוי הזה קורה:

שימו לב שההמלצה בטוחה הרבה יותר. בנוסף, ההמלצה 'לא מתאים לך' מושפעת מהעיקרון של ציון ההתאמה בצורה ברורה בהתאם להגבלות התזונתיות, וגם מהניתוח (מה שנקרא שרשרת מחשבות). כך אפשר להיות בטוחים שהתוצאה מתקבלת מהסיבה הנכונה.
8. הכללת צוותים לא טכניים בבדיקה ובניתוח של המודלים
הפרשנות צריכה להיות מאמץ משותף של הצוות, שכולל מומחיות בתחומים כמו XAI, מדיניות, משפטים ועוד.
בעבר, כדי ליצור אינטראקציה עם מודלים בשלבי הפיתוח הראשוניים היה צורך במומחיות טכנית משמעותית, ולכן היה קשה יותר לחלק מהמשתמשים לנסות אותם. בעבר לא היו כלים שאיפשרו לצוותים האלה להשתתף בשלבי האב-טיפוס המוקדמים.
אנחנו מקווים שבאמצעות LIT נוכל לשנות את הפרדיגמה הזו. כפי שראיתם ב-Codelab הזה, המדיום הוויזואלי של LIT והיכולת האינטראקטיבית שלו לבחון את חשיבות (salience) ולעיין בדוגמאות יכולים לעזור לבעלי עניין שונים לשתף את הממצאים ולתקשר אותם. כך תוכלו לצרף מגוון רחב יותר של חברי צוות לתהליך של חקר מודלים, בדיקה וניפוי באגים. החשיפה לשיטות הטכניות האלה יכולה לשפר את ההבנה שלהם לגבי אופן הפעולה של המודלים. בנוסף, מגוון רחב יותר של מומחיות בבדיקות מוקדמות של מודלים יכול לעזור לגלות תוצאות לא רצויות שאפשר לשפר.
9. Recap
לסיכום:
- ממשק המשתמש של LIT מספק ממשק להרצת מודלים אינטראקטיביים, שמאפשר למשתמשים ליצור פלט באופן ישיר ולבדוק תרחישים של 'מה יקרה אם'. האפשרות הזו שימושית במיוחד לבדיקת וריאציות שונות של הנחיות.
- מודול הבולטות של LM מספק ייצוג חזותי של בולטות, וגם מאפשר לשלוט בגרנולריות של הנתונים כדי שתוכלו לתקשר לגבי מבנים שממוקדים באדם (למשל, משפטים ומילים) במקום מבנים שממוקדים במודל (למשל, טוקנים).
כשמוצאים דוגמאות בעייתיות בהערכות של המודל, אפשר להשתמש ב-LIT כדי לנפות באגים. מתחילים בניתוח של יחידת התוכן הגדולה ביותר שאפשר לחשוב עליה שקשורה באופן הגיוני למשימת המידול, משתמשים בהדמיות כדי לראות איפה המודל מתייחס לתוכן ההנחיה בצורה נכונה או לא נכונה, ואז מתעמקים בנתונים ביחידות תוכן קטנות יותר כדי לתאר בצורה מפורטת יותר את ההתנהגות הלא נכונה שרואים, במטרה לזהות פתרונות אפשריים.
לבסוף: אנחנו כל הזמן משפרים את Lit! כאן אפשר לקבל מידע נוסף על התכונות שלנו ולשתף הצעות.