
1. Введение
Продукты на основе генеративного искусственного интеллекта относительно новы, и поведение приложений может варьироваться гораздо сильнее, чем у более ранних форм программного обеспечения. Это делает важным изучение используемых моделей машинного обучения, анализ примеров поведения моделей и исследование неожиданных результатов.
Инструмент интерпретируемости обучения (LIT; веб-сайт , GitHub ) — это платформа для отладки и анализа моделей машинного обучения, позволяющая понять, почему и как они ведут себя именно так.
В этом практическом занятии вы узнаете, как использовать LIT, чтобы получить больше пользы от модели Gemma от Google. В этом занятии демонстрируется, как использовать значимость последовательности, метод интерпретируемости, для анализа различных подходов к разработке подсказок.
Цели обучения:
- Понимание значимости последовательности и ее применения в анализе моделей.
- Настройка LIT для Gemma с целью вычисления выходных данных подсказок и значимости последовательности.
- Использование функции определения значимости последовательности с помощью модуля LM Salience для понимания влияния дизайна подсказок на результаты работы модели.
- Проверка гипотезы о скорейшем улучшении показателей LIT и оценка их влияния.
Примечание: в этом практическом задании используется реализация Gemma на KerasNLP и TensorFlow v2 в качестве бэкенда. Настоятельно рекомендуется использовать ядро для графического процессора (GPU) для выполнения задания.

2. Значимость последовательности и ее использование в анализе моделей.
Генеративные модели преобразования текста в текст, такие как Gemma, принимают на вход последовательность в виде токенизированного текста и генерируют новые токены, которые обычно являются продолжением или завершением этой последовательности. Генерация происходит по одному токену за раз, добавляя (в цикле) каждый вновь сгенерированный токен к входным данным плюс любые предыдущие генерации, пока модель не достигнет условия остановки. Примерами таких условий являются генерация токена конца последовательности (EOS) или достижение предопределенной максимальной длины.
Методы определения значимости — это класс методов объяснимого искусственного интеллекта (XAI), которые позволяют определить, какие части входных данных важны для модели при формировании различных частей её выходных данных. LIT поддерживает методы определения значимости для различных задач классификации , объясняя влияние последовательности входных токенов на прогнозируемую метку. Метод определения значимости последовательности обобщает эти методы на модели генерации текста и объясняет влияние предшествующих токенов на сгенерированные токены.
Здесь для анализа значимости последовательности будет использоваться метод Grad L2 Norm , который анализирует градиенты модели и определяет величину влияния каждого предшествующего токена на выходные данные. Этот метод прост и эффективен, и, как было показано , хорошо зарекомендовал себя в задачах классификации и других контекстах. Чем выше показатель значимости, тем сильнее влияние. Этот метод используется в рамках LIT, поскольку он хорошо изучен и широко применяется в исследовательском сообществе, занимающемся вопросами интерпретируемости.
К более продвинутым методам выделения значимости на основе градиентов относятся Grad ⋅ Input и интегрированные градиенты . Также существуют методы, основанные на абляции, такие как LIME и SHAP , которые могут быть более надежными, но значительно более затратными в вычислительном отношении. Подробное сравнение различных методов выделения значимости приведено в этой статье .
Вы можете узнать больше о научных методах определения значимости в этом вводном интерактивном руководстве по определению значимости .
3. Импорт, окружение и другой код настройки
Лучше всего выполнять это практическое задание в новой версии Colab . Мы рекомендуем использовать среду выполнения с ускорителем , поскольку вы будете загружать модель в память, однако имейте в виду, что параметры ускорителя со временем меняются и могут иметь ограничения . Colab предлагает платные подписки, если вам нужен доступ к более мощным ускорителям. В качестве альтернативы вы можете использовать локальную среду выполнения , если ваш компьютер оснащен подходящим графическим процессором.
Примечание: вы можете увидеть несколько предупреждений следующего вида.
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
Их можно смело игнорировать.
Установите LIT и Keras NLP.
Для выполнения этого практического задания вам потребуется последняя версия keras (3), keras-nlp (0.14.) и lit-nlp (1.2), а также учетная запись Kaggle для загрузки базовой модели.
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
Доступ к Kaggle
Для аутентификации на Kaggle вы можете сделать одно из следующих действий:
- Сохраните свои учетные данные в файле, например,
~/.kaggle/kaggle.json; - Используйте переменные среды
KAGGLE_USERNAMEиKAGGLE_KEY; или - Выполните следующие действия в интерактивной среде Python, например, в Google Colab.
import kagglehub
kagglehub.login()
Более подробную информацию см. в документации kagglehub и обязательно примите лицензионное соглашение Gemma .
Настройка Keras
Keras 3 поддерживает несколько бэкендов для глубокого обучения , включая Tensorflow (по умолчанию), PyTorch и JAX. Бэкенд настраивается с помощью переменной среды KERAS_BACKEND , которую необходимо установить перед импортом библиотеки Keras. Следующий фрагмент кода показывает, как установить эту переменную в интерактивной среде Python.
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
4. Настройка LIT
LIT можно использовать в блокнотах Python или через веб-сервер. Данный практический пример посвящен использованию блокнотов Python, поэтому мы рекомендуем выполнять его в Google Colab .
В этом практическом занятии вы загрузите Gemma v2 2B IT, используя предустановку KerasNLP . Следующий фрагмент кода инициализирует Gemma и загружает пример набора данных в виджет LIT Notebook.
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
Вы можете настроить виджет, изменив значения, передаваемые двум обязательным позиционным аргументам:
-
datasets_config: Список строк, содержащих имена и пути к наборам данных для загрузки, в формате "dataset:path", где path может быть URL-адресом или путем к локальному файлу. В приведенном ниже примере используется специальное значениеsample_promptsдля загрузки примеров подсказок, предоставленных в дистрибутиве LIT. -
models_config: Список строк, содержащих имена и пути моделей для загрузки, в формате "model:path", где path может быть URL-адресом, путем к локальному файлу или именем предустановки для настроенной среды глубокого обучения.
После того, как вы настроите LIT для использования интересующей вас модели, запустите следующий фрагмент кода, чтобы отобразить виджет в вашем блокноте.
lit_widget.render(open_in_new_tab=True)
Использование собственных данных
Gemma, как генеративная модель преобразования текста в текст, принимает текстовый ввод и генерирует текстовый вывод. LIT использует API с заданными параметрами для передачи структуры загруженных наборов данных моделям. Модели LLM в LIT разработаны для работы с наборами данных, содержащими два поля:
-
prompt: Входные данные для модели, на основе которых будет генерироваться текст; и -
target: Необязательная последовательность целевых значений, например, «эталонный» ответ от экспертов или предварительно сгенерированный ответ от другой модели.
LIT включает небольшой набор примеров sample_prompts из следующих источников, которые поддерживают этот Codelab и расширенное руководство по отладке подсказок от LIT.
- GSM8K : Решение задач по математике для начальной школы с помощью примеров с небольшим количеством заданий.
- Gigaword Benchmark : Генерация заголовков для сборника коротких статей.
- Конституционное стимулирование : генерация новых идей о том, как использовать объекты с установленными правилами/границами.
Вы также можете легко загрузить собственные данные, либо в виде файла .jsonl , содержащего записи с полями prompt и, при необходимости, target ( пример ), либо из любого другого формата, используя API наборов данных LIT.
Запустите ячейку ниже, чтобы загрузить примеры подсказок.
5. Анализ нескольких подсказок для Джеммы в LIT.
Сегодня создание подсказок — это в равной степени искусство и наука, и LIT может помочь вам эмпирически улучшить подсказки для больших языковых моделей, таких как Gemma. Далее вы увидите пример того, как LIT можно использовать для изучения поведения Gemma, прогнозирования потенциальных проблем и повышения ее безопасности.
Выявляйте ошибки в сложных запросах.
Два наиболее важных метода подсказок для создания высококачественных прототипов и приложений на основе LLM — это подсказки с небольшим количеством примеров (включая примеры желаемого поведения в подсказке) и цепочка рассуждений (включая объяснение или обоснование перед окончательным результатом работы LLM). Однако создание эффективной подсказки часто остается сложной задачей.
Рассмотрим пример того, как помочь человеку оценить, понравится ли ему еда, исходя из его вкусовых предпочтений. Первоначальный прототип шаблона для построения логической цепочки рассуждений может выглядеть следующим образом:
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
Вы заметили проблемы в этом задании? LIT поможет вам проанализировать задание с помощью модуля LM Salience .
6. Используйте значимость последовательности для отладки.
Значимость вычисляется на самом низком возможном уровне (т.е. для каждого входного токена), но LIT может объединять значимость токенов в более интерпретируемые большие фрагменты, такие как строки, предложения или слова. Узнайте больше о значимости и о том, как использовать ее для выявления непреднамеренных искажений, в нашем разделе «Исследование значимости» .
Начнём с того, что добавим в подсказку новый пример входных данных для переменных шаблона подсказки:
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
Если у вас открыт пользовательский интерфейс LIT в ячейке выше или в отдельной вкладке, вы можете использовать редактор точек данных LIT, чтобы добавить этот запрос:
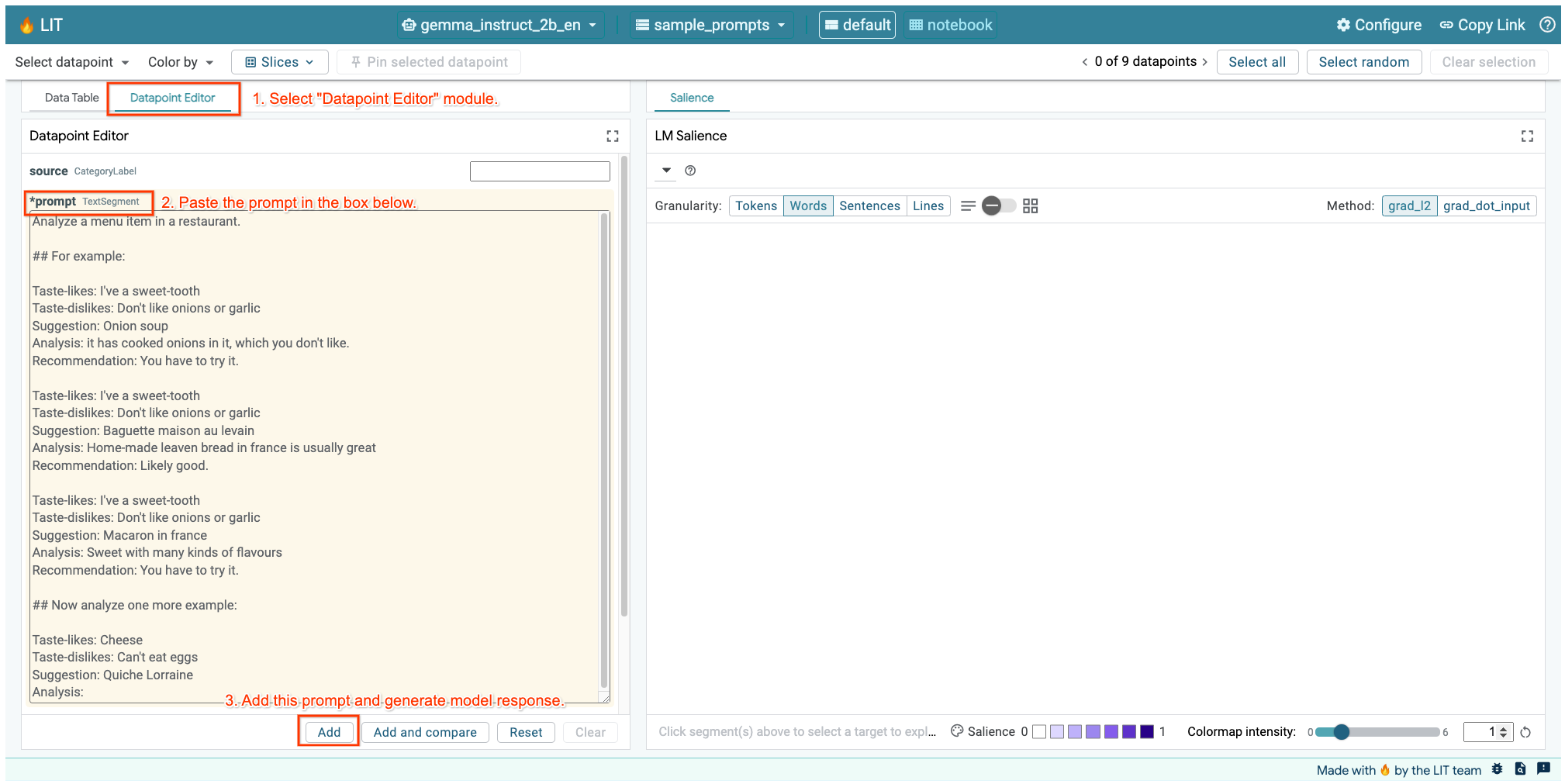
Другой способ — перерисовать виджет непосредственно с интересующим вас запросом:
lit_widget.render(data=[fewshot_mistake_example])
Обратите внимание на неожиданно высокий уровень завершенности модели:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
Почему модель предлагает вам съесть то, что вы ясно дали понять, что не можете есть?
Выявление значимости последовательности событий может помочь выделить основную проблему, которая присутствует в наших примерах с небольшим количеством примеров. В первом примере логическая цепочка рассуждений в разделе анализа it has cooked onions in it, which you don't like не соответствует окончательной рекомендации ( You have to try it .
В модуле LM Salience выберите «Предложения», а затем выберите строку рекомендаций. Теперь пользовательский интерфейс должен выглядеть следующим образом:

Это указывает на человеческую ошибку: случайное копирование и вставка части с рекомендациями и отсутствие ее обновления!
Теперь давайте исправим "Рекомендацию" в первом примере на " Avoid " и попробуем снова. В LIT этот пример уже загружен в примерах подсказок, так что вы можете использовать эту небольшую вспомогательную функцию, чтобы его получить:
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
Теперь процесс завершения модели выглядит следующим образом:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
Важный урок, который следует извлечь из этого: раннее прототипирование помогает выявить риски, о которых вы могли не подумать заранее , а подверженность языковых моделей ошибкам означает, что необходимо заблаговременно проектировать с учетом возможных ошибок. Более подробное обсуждение этого вопроса можно найти в нашем руководстве «Люди + ИИ» по проектированию с использованием ИИ.
Хотя исправленная версия подсказки с несколькими кадрами лучше, она все еще не совсем верна: она правильно сообщает пользователю о необходимости избегать яиц, но обоснование неверно: в ней говорится, что пользователь не любит яйца, тогда как на самом деле он заявил, что не может их есть. В следующем разделе вы узнаете, как можно исправить ситуацию.
7. Проверка гипотез для улучшения работы модели.
LIT позволяет тестировать изменения в подсказках в рамках одного и того же интерфейса. В данном случае вы будете тестировать добавление конституции для улучшения поведения модели. Конституции — это подсказки для проектирования, содержащие принципы, помогающие в создании модели. Современные методы даже позволяют интерактивно выводить конституционные принципы.
Давайте воспользуемся этой идеей, чтобы еще больше улучшить задание. Добавим раздел с принципами генерации в начало нашего задания, которое теперь начинается следующим образом:
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
После этого обновления пример можно запустить повторно, и вы увидите совершенно другой результат:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
Затем можно повторно проанализировать значимость предварительного ответа, чтобы понять, почему происходят эти изменения:

Обратите внимание, что эта рекомендация гораздо безопаснее. Кроме того, формулировка «Не подходит вам» основана на принципе четкого указания на пригодность продукта с учетом диетических ограничений, а также на анализе (так называемая логическая цепочка рассуждений). Это помогает повысить уверенность в том, что решение принимается по правильным причинам.
8. Привлекайте нетехнические команды к исследованию и анализу моделей.
Интерпретируемость должна быть результатом командной работы, охватывающей экспертные знания в области искусственного интеллекта, политики, права и многого другого.
Взаимодействие с моделями на ранних этапах разработки традиционно требовало значительных технических знаний, что затрудняло доступ к ним и их исследование для некоторых участников. Исторически сложилось так, что инструменты, позволяющие этим командам участвовать в ранних этапах прототипирования, отсутствовали.
С помощью LIT мы надеемся изменить эту парадигму. Как вы убедились в ходе этого практического занятия, визуальная среда LIT и интерактивные возможности для анализа значимости и изучения примеров могут помочь различным заинтересованным сторонам обмениваться результатами и сообщать о них. Это позволит привлечь более широкий круг коллег для исследования, анализа и отладки моделей. Ознакомление их с этими техническими методами может улучшить их понимание того, как работают модели. Кроме того, более разнообразный набор экспертов на ранних этапах тестирования моделей также может помочь выявить нежелательные результаты, которые можно улучшить.
9. Подведение итогов
Подведем итог:
- Пользовательский интерфейс LIT предоставляет возможность интерактивного выполнения модели, позволяя пользователям напрямую генерировать выходные данные и тестировать сценарии типа «что если». Это особенно полезно для тестирования различных вариантов подсказок.
- Модуль LM Salience обеспечивает визуальное представление значимости и позволяет контролировать детализацию данных, что дает возможность общаться о человекоцентричных конструкциях (например, предложениях и словах), а не о конструкциях, ориентированных на модель (например, токенах).
Когда вы обнаруживаете проблемные примеры в результатах оценки вашей модели, перенесите их в LIT для отладки. Начните с анализа самой крупной разумной единицы контента, которая логически связана с задачей моделирования, используйте визуализации, чтобы увидеть, где модель правильно или неправильно реагирует на контент подсказки, а затем углубитесь в более мелкие единицы контента, чтобы более подробно описать наблюдаемое некорректное поведение и определить возможные способы исправления.
И наконец: Lit постоянно совершенствуется! Узнайте больше о наших функциях и поделитесь своими предложениями здесь .