
1. 簡介
生成式 AI 產品相對較新,應用程式的行為可能比舊版軟體更多變。因此,請務必探查所用的機器學習模型、檢查模型行為的範例,並調查意外情況。
學習技術可解釋性工具 (Learning Interpretability Tool,LIT;網站、GitHub) 是一個平台,可供偵錯及分析機器學習模型,瞭解模型行為的原因和方式。
在本程式碼研究室中,您將瞭解如何使用 LIT,充分發揮 Google Gemma 模型的效用。本程式碼研究室將示範如何使用序列顯著性 (一種可解讀性技術),分析不同的提示工程方法。
學習目標:
- 瞭解序列顯著性,以及這項指標在模型分析中的用途。
- 為 Gemma 設定 LIT,計算提示詞輸出內容和序列顯著性。
- 透過 LM Salience 模組使用序列顯著性,瞭解提示設計對模型輸出內容的影響。
- 在 LIT 中測試假設的提示改善項目,並查看其影響。
注意:本程式碼研究室使用 KerasNLP 實作Gemma,並以 TensorFlow v2 做為後端。強烈建議使用 GPU 核心來進行後續操作。

2. 序列顯著性及其在模型分析中的用途
Gemma 等文字生成模型會接收以權杖化文字形式輸入的序列,並生成新的權杖,這些權杖通常是該輸入內容的後續或完成內容。這項生成作業一次會生成一個權杖,並將每個新生成的權杖附加至輸入內容和先前生成的內容 (以迴圈形式),直到模型達到停止條件為止。例如,模型生成序列結尾 (EOS) 符記,或達到預先定義的長度上限。
顯著性方法是一類可解釋的 AI (XAI) 技術,可告訴您輸入內容的哪些部分對模型輸出內容的不同部分很重要。LIT 支援各種分類工作的顯著性方法,可說明輸入權杖序列對預測標籤的影響。序列顯著性會將這些方法歸納為文字到文字的生成模型,並說明先前權杖對生成權杖的影響。
您將在此使用「Grad L2 Norm」方法,分析模型的梯度,並提供每個前一個權杖對輸出內容的影響程度。這個方法簡單有效率,且已證實在分類和其他設定中表現良好。顯著性分數越高,影響力就越大。LIT 使用這種方法,是因為可解釋性研究社群普遍瞭解並廣泛採用。
更進階的梯度式顯著性方法包括 Grad ⋅ Input 和積分梯度。此外,還有基於消融的方法,例如 LIME 和 SHAP,這些方法可能更穩健,但運算成本也高出許多。如要詳細比較不同的顯著性方法,請參閱這篇文章。
如要進一步瞭解顯著性方法背後的科學原理,請參閱這份顯著性簡介互動式可探索文件。
3. 匯入、環境和其他設定程式碼
建議您使用新版 Colab 進行本程式碼研究室。建議使用加速器執行階段,因為您會將模型載入記憶體,但請注意,加速器選項會隨時間而異,且受限。如要使用更強大的加速器,可以訂閱 Colab 的付費方案。如果您的電腦有適當的 GPU,也可以使用本機執行階段。
注意:您可能會看到一些表單警告
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
您可以放心忽略這些訊息。
安裝 LIT 和 Keras NLP
在本程式碼研究室中,您需要最新版的 keras (3) keras-nlp (0.14.) 和 lit-nlp (1.2),以及 Kaggle 帳戶才能下載基礎模型。
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
Kaggle 存取權
如要透過 Kaggle 進行驗證,請採取下列任一做法:
- 將憑證儲存在檔案中,例如
~/.kaggle/kaggle.json; - 使用
KAGGLE_USERNAME和KAGGLE_KEY環境變數;或 - 在互動式 Python 環境 (例如 Google Colab) 中執行下列程式碼。
import kagglehub
kagglehub.login()
詳情請參閱 kagglehub說明文件,並務必接受 Gemma 授權協議。
設定 Keras
Keras 3 支援多個深度學習後端,包括 TensorFlow (預設)、PyTorch 和 JAX。後端是使用 KERAS_BACKEND 環境變數設定,且必須在匯入 Keras 程式庫前設定。下列程式碼片段說明如何在互動式 Python 環境中設定這個變數。
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
4. 設定 LIT
LIT 可在 Python 筆記本中使用,也可以透過網頁伺服器使用。本程式碼研究室著重於筆記本用途,建議您在 Google Colab 中操作。
在本程式碼研究室中,您將使用 KerasNLP 預設值載入 Gemma v2 2B IT。下列程式碼片段會初始化 Gemma,並在 LIT 筆記本小工具中載入範例資料集。
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
您可以變更傳遞至兩個必要位置引數的值,藉此設定小工具:
datasets_config:字串清單,包含要載入的資料集名稱和路徑,格式為「資料集:路徑」,其中路徑可以是網址或本機檔案路徑。以下範例使用特殊值sample_prompts,載入 LIT 發布內容中提供的範例提示。models_config:字串清單,包含要載入的模型名稱和路徑,格式為「model:path」,其中路徑可以是網址、本機檔案路徑,或是已設定深度學習架構的預設名稱。
設定 LIT 以使用您感興趣的模型後,請執行下列程式碼片段,在 Notebook 中算繪小工具。
lit_widget.render(open_in_new_tab=True)
使用自有資料
Gemma 是文字轉文字生成模型,可接收文字輸入並生成文字輸出。LIT 使用武斷的 API,將已載入資料集的結構傳達給模型。LIT 中的 LLM 適用於提供下列兩個欄位的資料集:
prompt:模型輸入內容,系統會根據這項內容生成文字;以及target:選用的目標序列,例如人工評估人員的「實際資料」回應,或是其他模型預先生成的回應。
LIT 包含一小組 sample_prompts,其中有來自下列來源的範例,支援本程式碼研究室和 LIT 的擴充提示偵錯教學課程。
- GSM8K:透過少量樣本解答小學程度的數學問題。
- Gigaword 基準:為一系列短文生成標題。
- 憲法提示:根據規範/界線,產生如何使用物件的新點子。
您也可以輕鬆載入自己的資料,方法是使用包含欄位 prompt 和選用 target 的記錄 (範例) 的 .jsonl 檔案,或使用 LIT 的 Dataset API 載入任何格式的資料。
執行下列儲存格,載入範例提示。
5. 在 LIT 中分析 Gemma 的 Few Shot 提示
如今,提示工程既是科學也是藝術,而 LIT 可協助您根據經驗改善大型語言模型 (例如 Gemma) 的提示。接下來,您會看到如何使用 LIT 探索 Gemma 的行為、預測潛在問題,以及提升安全性。
找出複雜提示中的錯誤
如要製作高品質的 LLM 基礎原型和應用程式,最重要的提示技術有兩種:少量樣本提示 (在提示中加入所需行為的範例) 和思維鏈 (在 LLM 的最終輸出內容前加入說明或推理形式)。但建立有效的提示通常仍有難度。
舉例來說,你可以根據某人的口味,協助他們判斷是否會喜歡某種食物。初步的思維鏈提示範本可能如下所示:
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
你發現這個提示有什麼問題嗎?LIT 會透過 LM Salience 模組檢查提示。
6. 使用序列顯著性進行偵錯
顯著性是在最小可能層級 (即每個輸入權杖) 計算,但 LIT 可將權杖顯著性匯總為更易於解讀的較大範圍,例如行、句子或字詞。如要進一步瞭解顯著性,以及如何使用這項功能找出無意間產生的偏誤,請參閱 Saliency Explorable。
首先,請為提示範本變數提供新的提示範例輸入內容:
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
如果已在上方儲存格或另一個分頁中開啟 LIT UI,可以使用 LIT 的「資料點編輯器」新增這個提示:

另一種方法是使用感興趣的提示直接重新算繪小工具:
lit_widget.render(data=[fewshot_mistake_example])
請注意模型完成的內容出乎意料:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
你明明說過不能吃某種食物,為什麼模型還建議你吃?
序列顯著性有助於凸顯根本問題,這在少量樣本範例中很常見。在第一個範例中,分析部分 it has cooked onions in it, which you don't like 的連鎖思維推理與最終建議 You have to try it 不符。
在 LM Salience 模組中選取「句子」,然後選取建議行。UI 現在應如下所示:
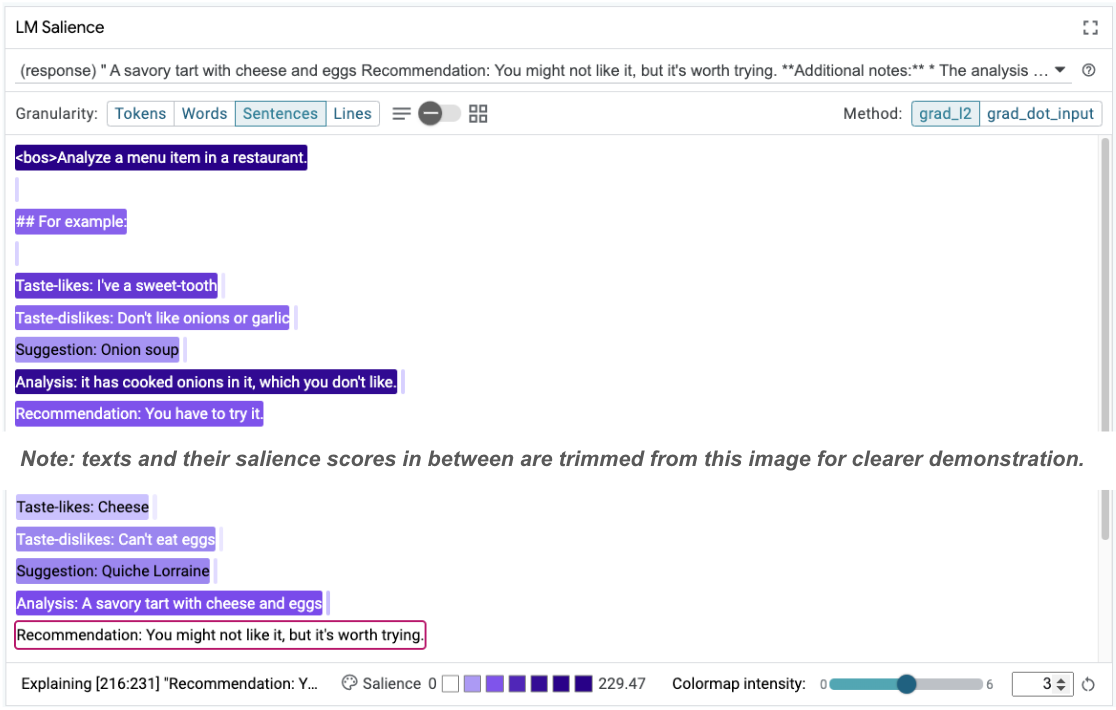
這凸顯了人為錯誤:不小心複製並貼上建議部分,但未更新!
現在,請將第一個範例中的「Recommendation」修正為 Avoid,然後再試一次。LIT 已在範例提示中預先載入這個範例,因此您可以使用這個小實用函式來擷取:
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
現在模型完成的內容如下:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
從中可學到重要的一課:早期原型設計有助於揭露您可能未事先想到的風險,且語言模型容易出錯,因此必須主動設計錯誤處理機制。如要進一步瞭解這項主題,請參閱「People + AI Guidebook」的 AI 設計指南。
雖然修正後的少樣本提示較好,但仍不完全正確:提示正確告知使用者避免食用雞蛋,但理由不對,提示說使用者不喜歡雞蛋,但事實上使用者表示自己不能吃雞蛋。下一節將說明如何改善。
7. 測試假設,改善模型行為
您可以在同一個介面中,使用 LIT 測試提示的變更。在本例中,您將測試新增憲法,改善模型行為。憲法是指以原則為基礎的設計提示,可引導模型生成內容。近期的做法甚至能互動推導憲法原則。
讓我們運用這個想法,進一步改善提示。在提示開頭新增生成原則,現在提示開頭如下:
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
更新後,您可以重新執行範例,並觀察輸出內容的差異:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
接著可以重新檢查提示詞顯著性,瞭解發生這項變更的原因:

請注意,建議的安全性較高。此外,「不適合你」的結果是根據清楚說明適合度的原則 (根據飲食限制) 以及分析 (即所謂的思維鏈) 而定。這有助於進一步確認輸出內容是基於正當理由。
8. 讓非技術團隊參與模型探查和探索
可解讀性應由團隊共同努力,涵蓋 XAI、政策、法律等專業知識。
傳統上,在早期開發階段與模型互動需要大量技術專業知識,因此部分協作者較難存取及探究模型。過去沒有相關工具,因此這些團隊無法參與早期原型設計階段。
我們希望透過 LIT 改變這種情況。如本程式碼研究室所示,LIT 的視覺化媒介和互動式功能可檢查顯著性及探索範例,有助於不同利害關係人分享及傳達發現。這有助於您納入更多不同背景的隊友,一起探索、探查及偵錯模型。讓他們接觸這些技術方法,有助於瞭解模型的運作方式。此外,在早期模型測試中,如果能有更多不同領域的專家參與,也有助於找出可改善的不良結果。
9. 重點回顧
重點回顧:
- LIT UI 提供互動式模型執行介面,可讓使用者直接生成輸出內容,並測試「假設」情境。這項功能特別適合用來測試不同的提示變化版本。
- LM Salience 模組會以視覺化方式呈現顯著性,並提供可控的資料精細度,讓您能以人為中心的建構體 (例如句子和字詞) 進行溝通,而非以模型為中心的建構體 (例如權杖)。
在模型評估中發現有問題的範例時,請將這些範例匯入 LIT 進行偵錯。首先,請分析您能想到的最大合理內容單元,這些單元在邏輯上與模型工作相關,然後使用視覺化內容,查看模型正確或錯誤地關注提示內容的位置,接著深入分析較小的內容單元,進一步說明您看到的錯誤行為,找出可能的修正方式。
最後:Lit 持續進步!如要進一步瞭解我們的功能並分享建議,請按這裡。