
1. Descripción general
En este lab, se proporciona una guía detallada para implementar un servidor de aplicaciones de LIT en Google Cloud Platform (GCP) para interactuar con los modelos básicos de Gemini de Vertex AI y los modelos de lenguaje grandes (LLM) de terceros alojados por el usuario. También incluye orientación sobre cómo usar la IU de LIT para depurar instrucciones y realizar la interpretación de modelos.
Si sigues este lab, aprenderás a hacer lo siguiente:
- Configura un servidor LIT en GCP.
- Conecta el servidor de LIT a los modelos de Gemini de Vertex AI o a otros LLM alojados por tu cuenta.
- Utiliza la IU de LIT para analizar, depurar e interpretar instrucciones y, así, obtener un mejor rendimiento y estadísticas del modelo.
¿Qué es LIT?
LIT es una herramienta visual interactiva para entender modelos que admite datos tabulares, de texto y en imágenes. Se puede ejecutar como servidor independiente o dentro de entornos de notebook, como Google Colab, Jupyter y Google Cloud Vertex AI. LIT está disponible en PyPI y GitHub.
Originalmente creada para comprender los modelos de clasificación y regresión, las actualizaciones recientes agregaron herramientas para depurar instrucciones de LLM, lo que te permite explorar cómo el contenido del usuario, del modelo y del sistema influye en el comportamiento de la generación.
¿Qué son Vertex AI y Model Garden?
Vertex AI es una plataforma de aprendizaje automático (AA) que te permite entrenar y, también, implementar modelos de AA y aplicaciones de IA, y personalizar LLM para usarlos en tus aplicaciones impulsadas por IA. Vertex AI combina la ingeniería de datos, la ciencia de datos y los flujos de trabajo de ingeniería de AA, lo que permite que tus equipos colaboren con un conjunto de herramientas común y escalen tus aplicaciones con los beneficios de Google Cloud.
Vertex Model Garden es una biblioteca de modelos de AA que te ayuda a descubrir, probar, personalizar e implementar modelos y recursos de terceros y de propiedad de Google.
Qué harás
Usarás Cloud Shell y Cloud Run de Google Cloud para implementar un contenedor de Docker desde la imagen compilada previamente de LIT.
Cloud Run es una plataforma de procesamiento administrada que te permite ejecutar contenedores directamente sobre la infraestructura escalable de Google, incluidas las GPUs.
Conjunto de datos
De forma predeterminada, la demostración usa el conjunto de datos de muestra de depuración de instrucciones de LIT, pero puedes cargar el tuyo a través de la IU.
Antes de comenzar
Para esta guía de referencia, necesitas un proyecto de Google Cloud. Puedes crear uno nuevo o seleccionar un proyecto que ya hayas creado.
2. Inicia la consola de Google Cloud y Cloud Shell
En este paso, iniciarás una consola de Google Cloud y usarás Google Cloud Shell.
2a: Inicia una consola de Google Cloud
Inicia un navegador y ve a Google Cloud Console.
La consola de Google Cloud es una interfaz de administrador web potente y segura que te permite administrar tus recursos de Google Cloud rápidamente. Es una herramienta de DevOps estés donde estés.
2b: Inicia Google Cloud Shell
Cloud Shell es un entorno de desarrollo y operaciones en línea al que puedes acceder desde cualquier lugar con tu navegador. Puedes administrar tus recursos con su terminal en línea que ya cuenta con utilidades, como la herramienta de línea de comandos de gcloud y kubectl, entre otras. También puedes desarrollar, compilar, depurar e implementar tus APPs basadas en la nube con el editor de Cloud Shell en línea. Cloud Shell proporciona un entorno en línea listo para desarrolladores con un conjunto de herramientas favoritas preinstaladas y 5 GB de espacio de almacenamiento persistente. Usarás el símbolo del sistema en los próximos pasos.
Inicia Google Cloud Shell con el ícono que se encuentra en la parte superior derecha de la barra de menú, que se muestra en un círculo azul en la siguiente captura de pantalla.

Deberías ver una terminal con un shell de Bash en la parte inferior de la página.

2c: Configura el proyecto de Google Cloud
Debes configurar el ID del proyecto y la región del proyecto con el comando gcloud.
# Set your GCP Project ID.
gcloud config set project your-project-id
# Set your GCP Project Region.
gcloud config set run/region your-project-region
3. Implementa la imagen de Docker del servidor de la app de LIT con Cloud Run
3a: Implementa la app de LIT en Cloud Run
Primero, debes establecer la versión más reciente de LIT-App como la versión que se implementará.
# Set latest version as your LIT_SERVICE_TAG.
export LIT_SERVICE_TAG=latest
# List all the public LIT GCP App server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app
Después de configurar la etiqueta de versión, debes asignarle un nombre al servicio.
# Set your lit service name. While 'lit-app-service' is provided as a placeholder, you can customize the service name based on your preferences.
export LIT_SERVICE_NAME=lit-app-service
Después, puedes ejecutar el siguiente comando para implementar el contenedor en Cloud Run.
# Use below cmd to deploy the LIT App to Cloud Run.
gcloud run deploy $LIT_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app:$LIT_SERVICE_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--no-allow-unauthenticated
LIT también te permite agregar el conjunto de datos cuando inicias el servidor. Para ello, configura la variable DATASETS para que incluya los datos que deseas cargar con el formato name:path, por ejemplo, data_foo:/bar/data_2024.jsonl. El formato del conjunto de datos debe ser .jsonl, en el que cada registro contiene prompt y los campos opcionales target y source. Para cargar varios conjuntos de datos, sepáralos con una coma. Si no se configura, se cargará el conjunto de datos de muestra de depuración de instrucciones de LIT.
# Set the dataset.
export DATASETS=[DATASETS]
Si configuras MAX_EXAMPLES, puedes establecer la cantidad máxima de ejemplos que se cargarán desde cada conjunto de evaluación.
# Set the max examples.
export MAX_EXAMPLES=[MAX_EXAMPLES]
Luego, en el comando de implementación, puedes agregar
--set-env-vars "DATASETS=$DATASETS" \
--set-env-vars "MAX_EXAMPLES=$MAX_EXAMPLES" \
3b: Visualiza el servicio de la app de LIT
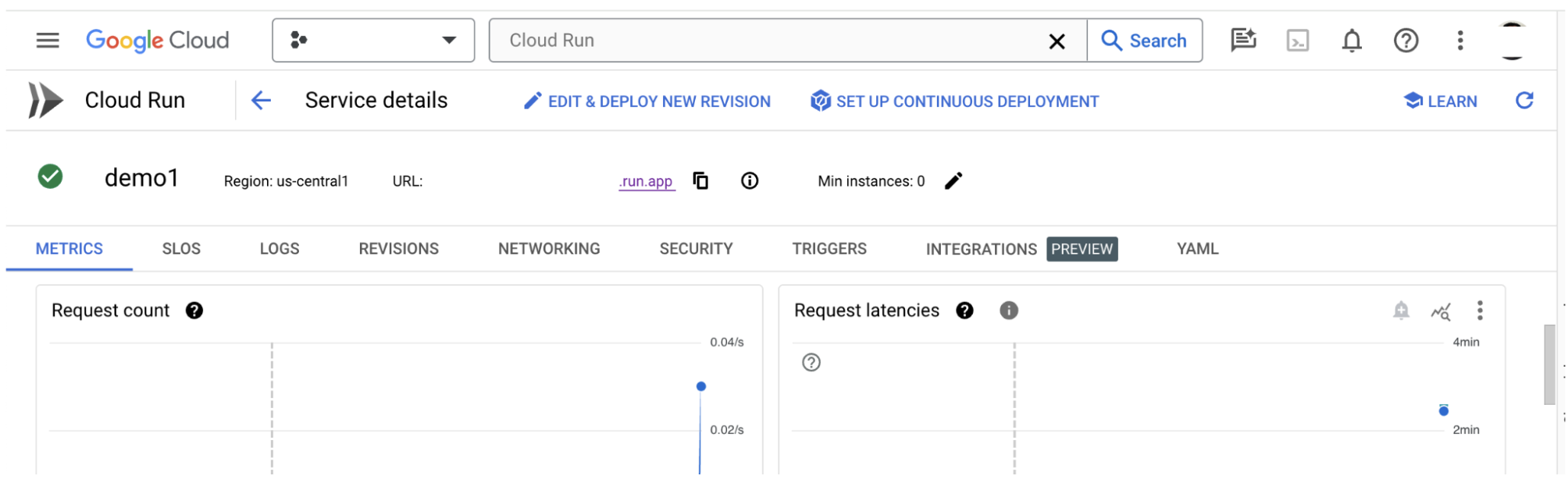
Después de crear el servidor de la app de LIT, puedes encontrar el servicio en la sección Cloud Run de Cloud Console.
Selecciona el servicio de la app de LIT que acabas de crear. Asegúrate de que el nombre del servicio sea el mismo que LIT_SERVICE_NAME.
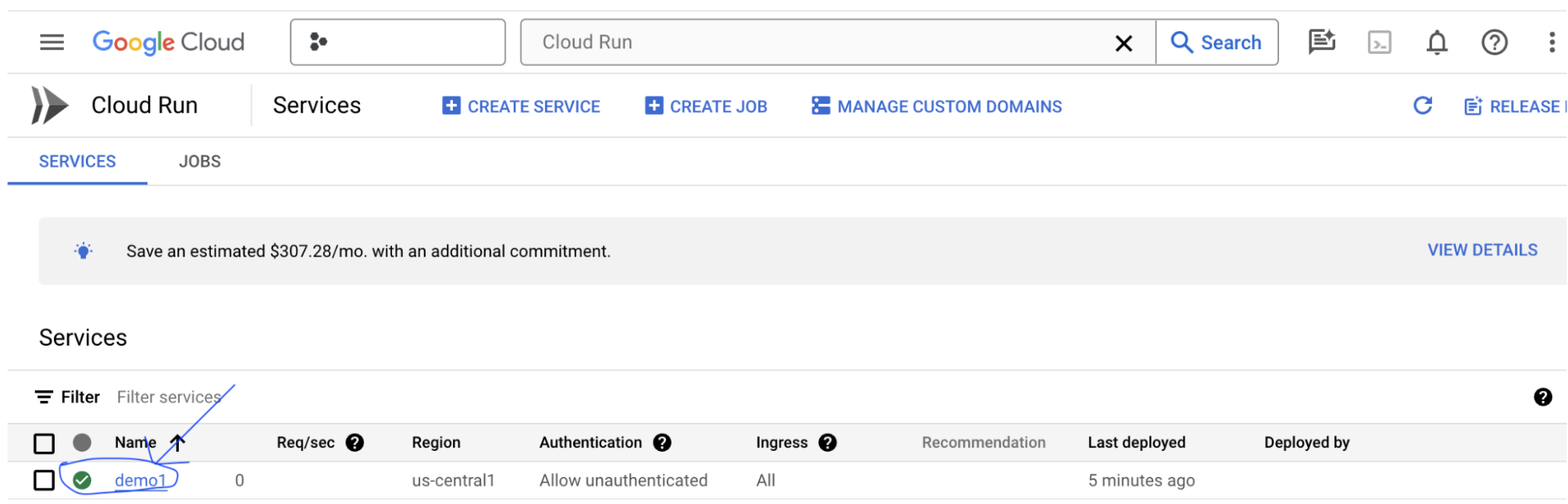
Para encontrar la URL del servicio, haz clic en el servicio que acabas de implementar.
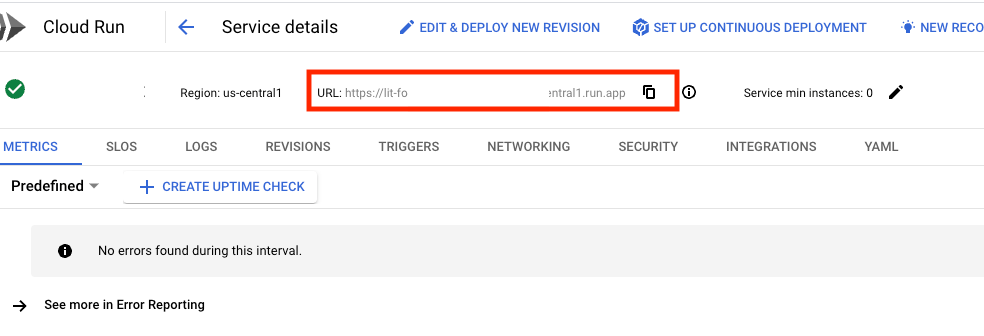
Luego, deberías poder ver la IU de LIT. Si encuentras un error, consulta la sección Solución de problemas.
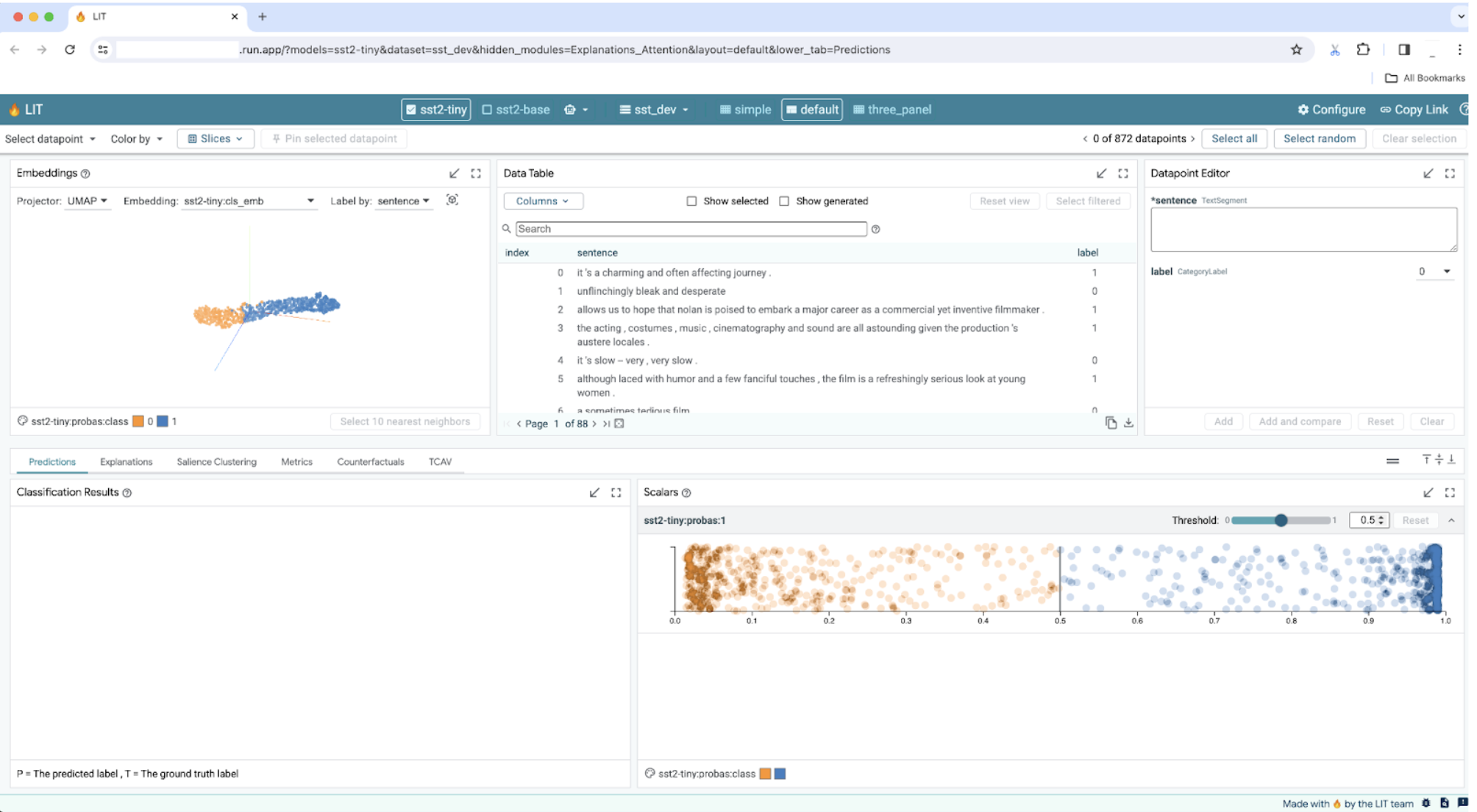
Puedes consultar la sección REGISTROS para supervisar la actividad, ver los mensajes de error y hacer un seguimiento del progreso de la implementación.
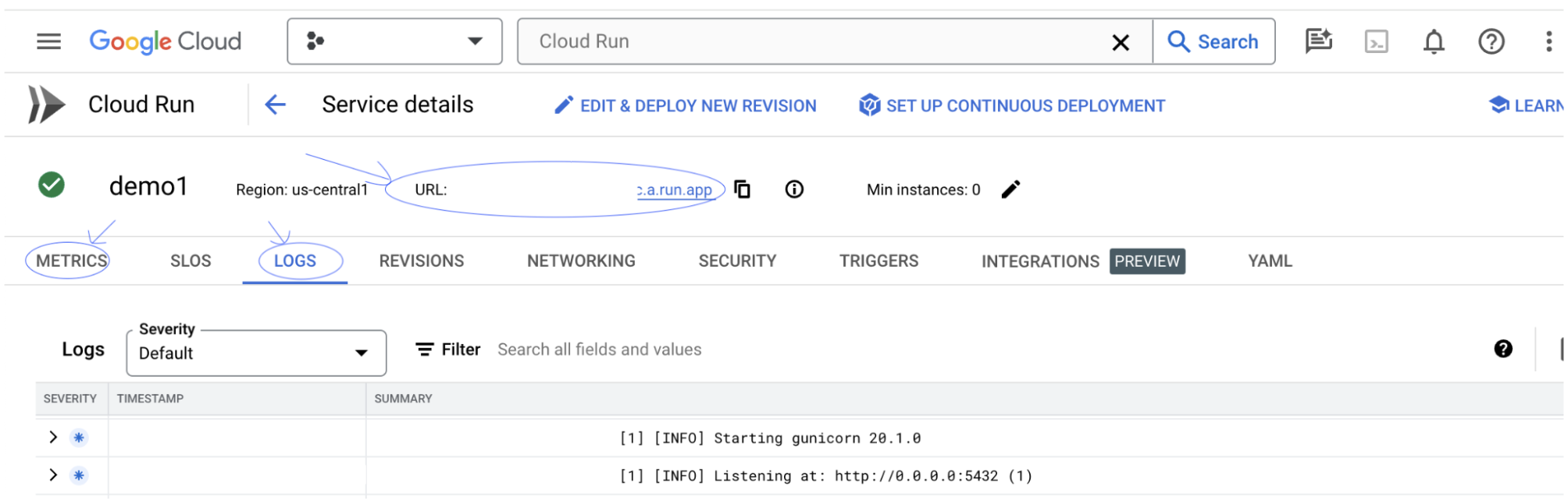
Puedes consultar la sección MÉTRICAS para ver las métricas del servicio.
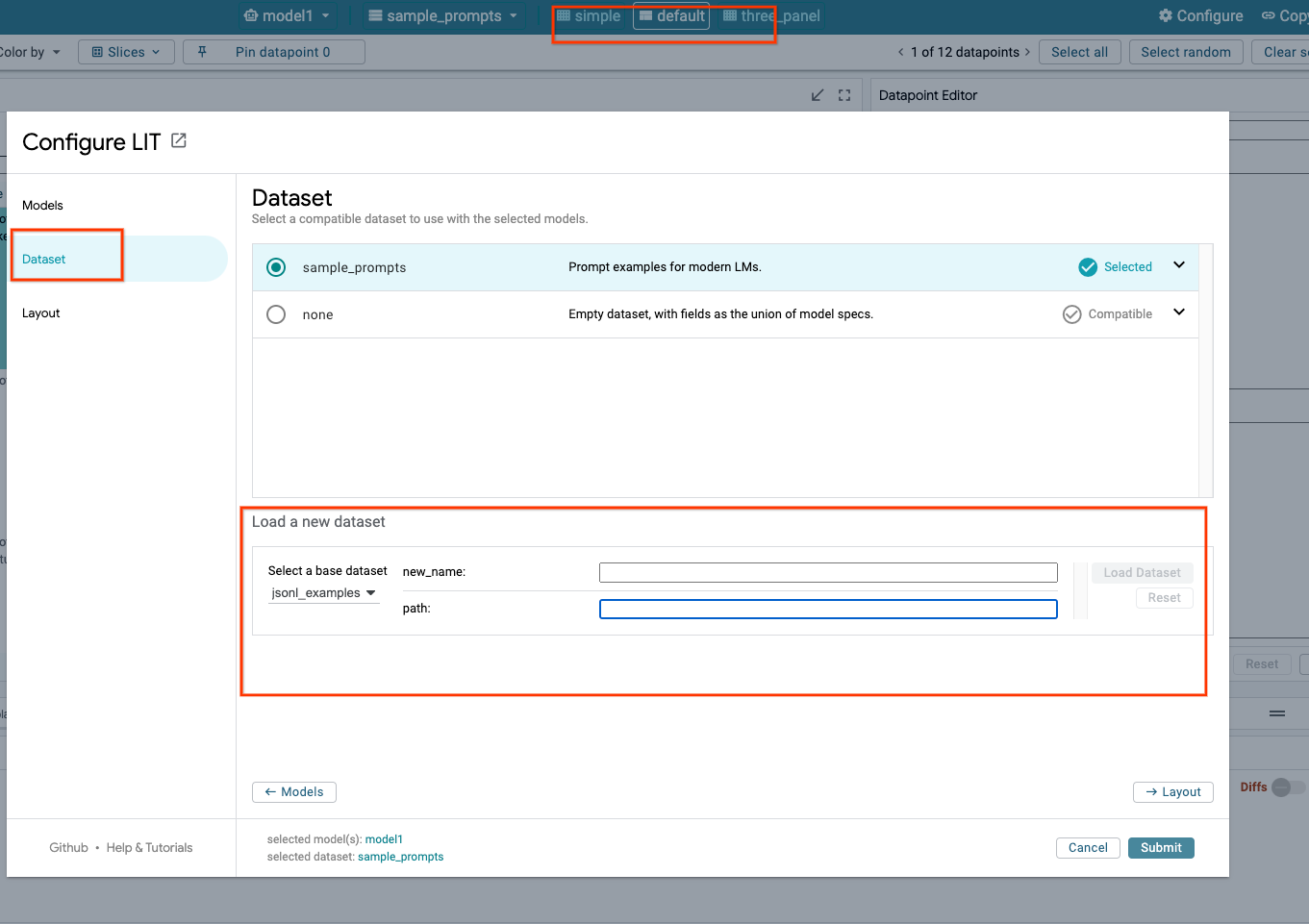
3c: Carga conjuntos de datos
Haz clic en la opción Configure en la IU de LIT y selecciona Dataset. Carga el conjunto de datos especificando un nombre y proporcionando la URL del conjunto de datos. El formato del conjunto de datos debe ser .jsonl, en el que cada registro contiene prompt y los campos opcionales target y source.
4. Prepara modelos de Gemini en Model Garden de Vertex AI
Los modelos de base de Gemini de Google están disponibles en la API de Vertex AI. LIT proporciona el wrapper del modelo VertexAIModelGarden para usar estos modelos en la generación. Simplemente especifica la versión deseada (p.ej., "gemini-1.5-pro-001") a través del parámetro del nombre del modelo. Una ventaja clave de usar estos modelos es que no requieren ningún esfuerzo adicional para la implementación. De forma predeterminada, tienes acceso inmediato a modelos como Gemini 1.0 Pro y Gemini 1.5 Pro en GCP, lo que elimina la necesidad de realizar pasos de configuración adicionales.
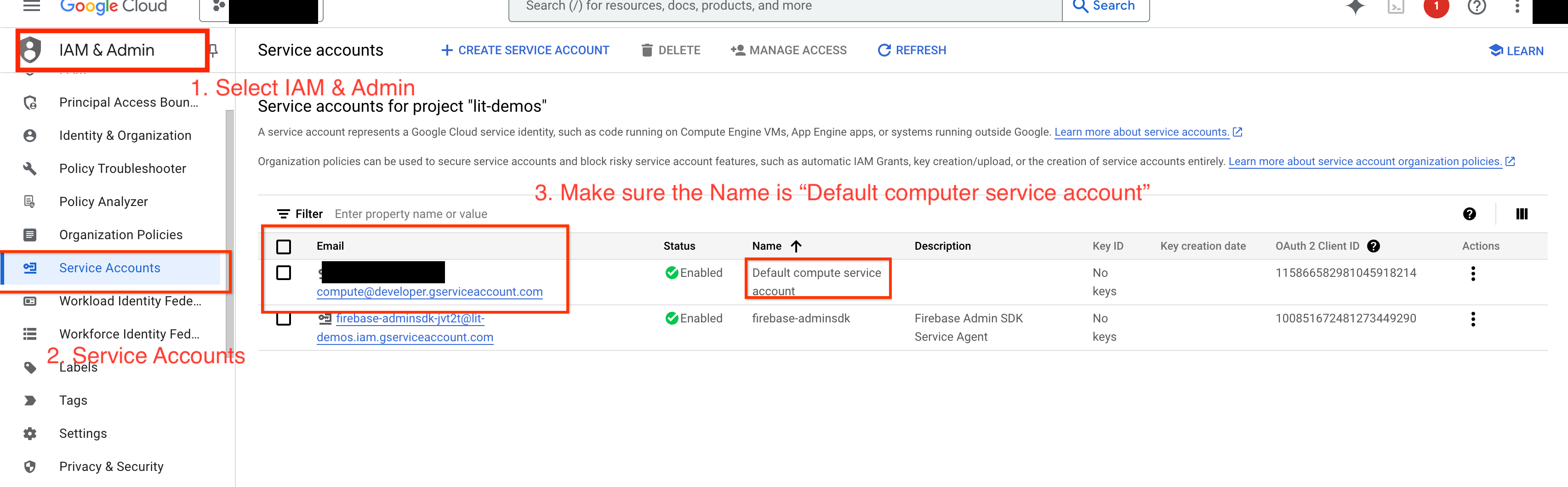
4a: Otorga permisos de Vertex AI
Para consultar Gemini en GCP, debes otorgar permisos de Vertex AI a la cuenta de servicio. Asegúrate de que el nombre de la cuenta de servicio sea Default compute service account. Copia el correo electrónico de la cuenta de servicio.
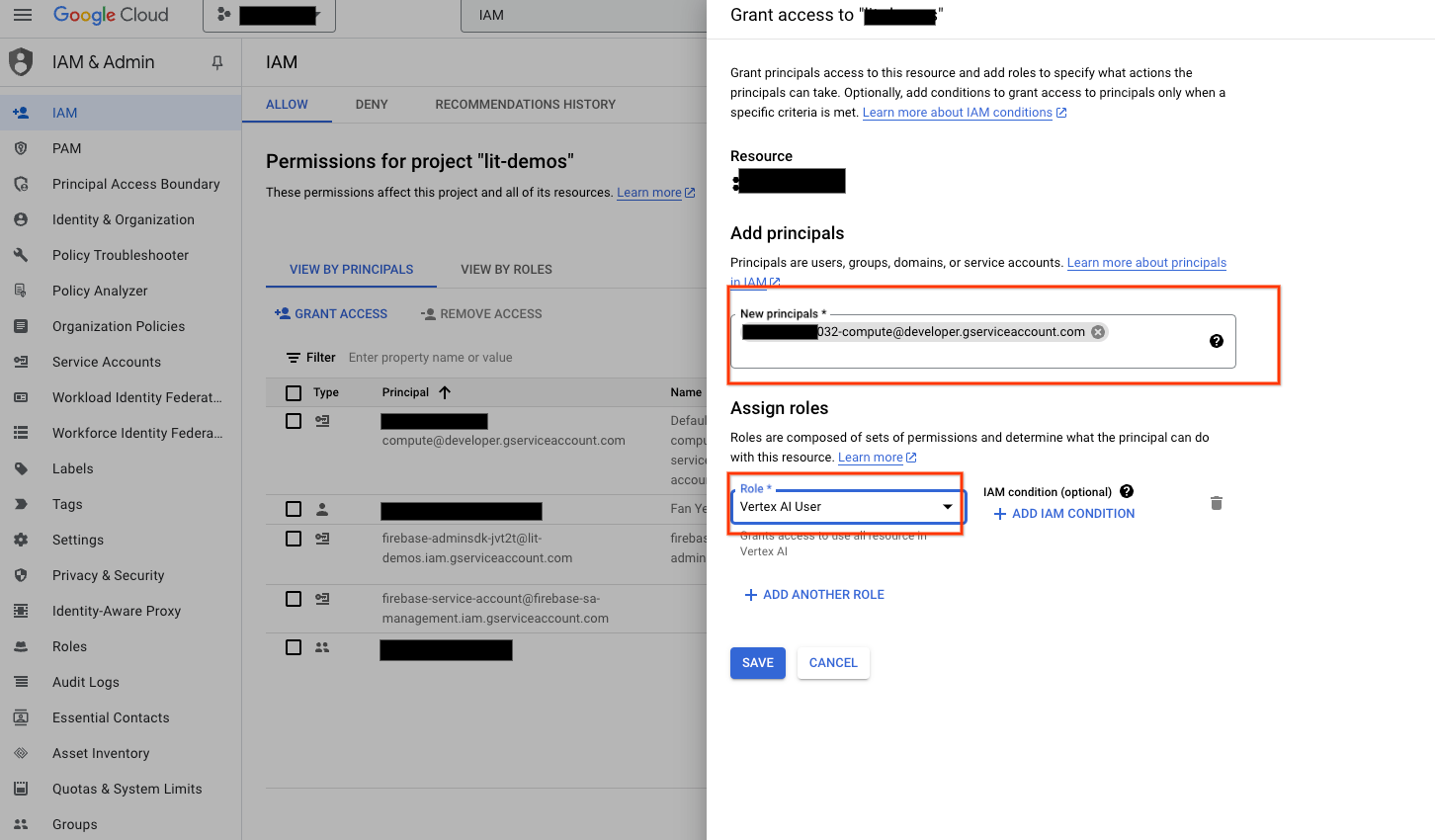
Agrega el correo electrónico de la cuenta de servicio como principal con el rol de Vertex AI User en tu lista de entidades permitidas de IAM.
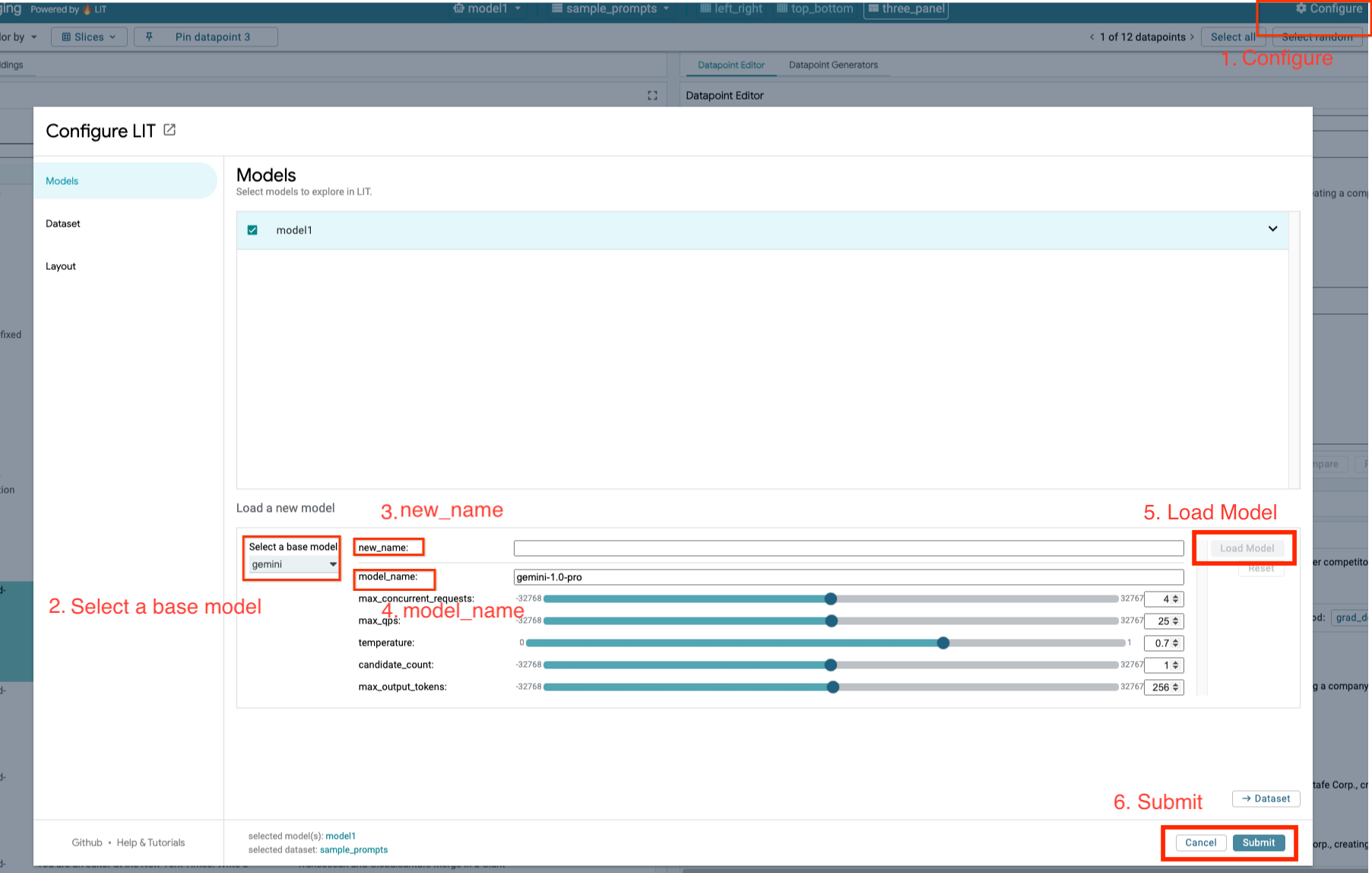
4b: Carga los modelos de Gemini
Cargarás los modelos de Gemini y ajustarás sus parámetros siguiendo los pasos que se indican a continuación.
- Haz clic en la opción
Configureen la IU de LIT.
- Haz clic en la opción
- Selecciona la opción
geminien la opciónSelect a base model.
- Selecciona la opción
- Debes nombrar el modelo en
new_name.
- Debes nombrar el modelo en
- Ingresa los modelos de Gemini seleccionados como
model_name.
- Ingresa los modelos de Gemini seleccionados como
- Haz clic en
Load Model.
- Haz clic en
- Haz clic en
Submit.
- Haz clic en
5. Implementa el servidor de modelos de LLM autoalojados en GCP
El autoalojamiento de LLM con la imagen de Docker del servidor de modelos de LIT te permite usar las funciones de prominencia y tokenización de LIT para obtener estadísticas más detalladas sobre el comportamiento del modelo. La imagen del servidor de modelos funciona con los modelos de KerasNLP o Hugging Face Transformers, incluidos los pesos proporcionados por la biblioteca y los alojados por el usuario, p.ej., en Google Cloud Storage.
5a: Configura modelos
Cada contenedor carga un modelo, que se configura con variables de entorno.
Debes especificar los modelos que se cargarán configurando MODEL_CONFIG. El formato debe ser name:path, por ejemplo, model_foo:model_foo_path. La ruta de acceso puede ser una URL, una ruta de acceso a un archivo local o el nombre de un parámetro de configuración predeterminado para el framework de aprendizaje profundo configurado (consulta la siguiente tabla para obtener más información). Este servidor se probó con Gemma, GPT2, Llama y Mistral en todos los valores de DL_FRAMEWORK admitidos. Otros modelos deberían funcionar, pero es posible que se necesiten ajustes.
# Set models you want to load. While 'gemma2b is given as a placeholder, you can load your preferred model by following the instructions above.
export MODEL_CONFIG=gemma2b:gemma_2b_en
Además, el servidor de modelos de LIT permite configurar varias variables de entorno con el siguiente comando. Consulta la tabla para obtener más detalles. Ten en cuenta que cada variable debe establecerse de forma individual.
# Customize the variable value as needed.
export [VARIABLE]=[VALUE]
Variable | Valores | Descripción |
DL_FRAMEWORK |
| Es la biblioteca de modelado que se usa para cargar los pesos del modelo en el tiempo de ejecución especificado. La configuración predeterminada es |
DL_RUNTIME |
| Es el framework de backend de aprendizaje profundo en el que se ejecuta el modelo. Todos los modelos que cargue este servidor usarán el mismo backend, y las incompatibilidades generarán errores. La configuración predeterminada es |
PRECISIÓN |
| Es la precisión de punto flotante para los modelos de LLM. La configuración predeterminada es |
BATCH_SIZE | Números enteros positivos | Es la cantidad de ejemplos que se procesarán por lote. La configuración predeterminada es |
SEQUENCE_LENGTH | Números enteros positivos | Es la longitud máxima de la secuencia de la instrucción de entrada más el texto generado. La configuración predeterminada es |
5b: Implementa el servidor de modelos en Cloud Run
Primero debes establecer la versión más reciente de Model Server como la versión que se implementará.
# Set latest as MODEL_VERSION_TAG.
export MODEL_VERSION_TAG=latest
# List all the public LIT GCP model server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server
Después de establecer la etiqueta de versión, debes asignarle un nombre a tu servidor de modelos.
# Set your Service name.
export MODEL_SERVICE_NAME='gemma2b-model-server'
Después, puedes ejecutar el siguiente comando para implementar el contenedor en Cloud Run. Si no configuras las variables de entorno, se aplicarán los valores predeterminados. Como la mayoría de los LLM requieren recursos de procesamiento costosos, se recomienda usar la GPU. Si prefieres ejecutar solo en la CPU (lo que funciona bien para modelos pequeños como GPT2), puedes quitar los argumentos relacionados --gpu 1 --gpu-type nvidia-l4 --max-instances 7.
# Deploy the model service container.
gcloud beta run deploy $MODEL_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server:$MODEL_VERSION_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 7 \
--set-env-vars "MODEL_CONFIG=$MODEL_CONFIG" \
--no-allow-unauthenticated
Además, puedes personalizar las variables de entorno agregando los siguientes comandos. Incluye solo las variables de entorno que sean necesarias para tus necesidades específicas.
--set-env-vars "DL_FRAMEWORK=$DL_FRAMEWORK" \
--set-env-vars "DL_RUNTIME=$DL_RUNTIME" \
--set-env-vars "PRECISION=$PRECISION" \
--set-env-vars "BATCH_SIZE=$BATCH_SIZE" \
--set-env-vars "SEQUENCE_LENGTH=$SEQUENCE_LENGTH" \
Es posible que se necesiten variables de entorno adicionales para acceder a ciertos modelos. Consulta las instrucciones de Kaggle Hub (que se usa para los modelos de KerasNLP) y Hugging Face Hub según corresponda.
5c: Accede al servidor de modelos
Después de crear el servidor del modelo, el servicio iniciado se puede encontrar en la sección Cloud Run de tu proyecto de GCP.
Selecciona el servidor del modelo que acabas de crear. Asegúrate de que el nombre del servicio sea el mismo que MODEL_SERVICE_NAME.
Para encontrar la URL del servicio, haz clic en el servicio del modelo que acabas de implementar.
Puedes consultar la sección REGISTROS para supervisar la actividad, ver los mensajes de error y hacer un seguimiento del progreso de la implementación.
Puedes consultar la sección MÉTRICAS para ver las métricas del servicio.
5-d: Carga modelos alojados por tu cuenta
Si envías tu servidor de LIT a través de un proxy en el paso 3 (consulta la sección Solución de problemas), deberás obtener tu token de identidad de GCP ejecutando el siguiente comando.
# Find your GCP identity token.
gcloud auth print-identity-token
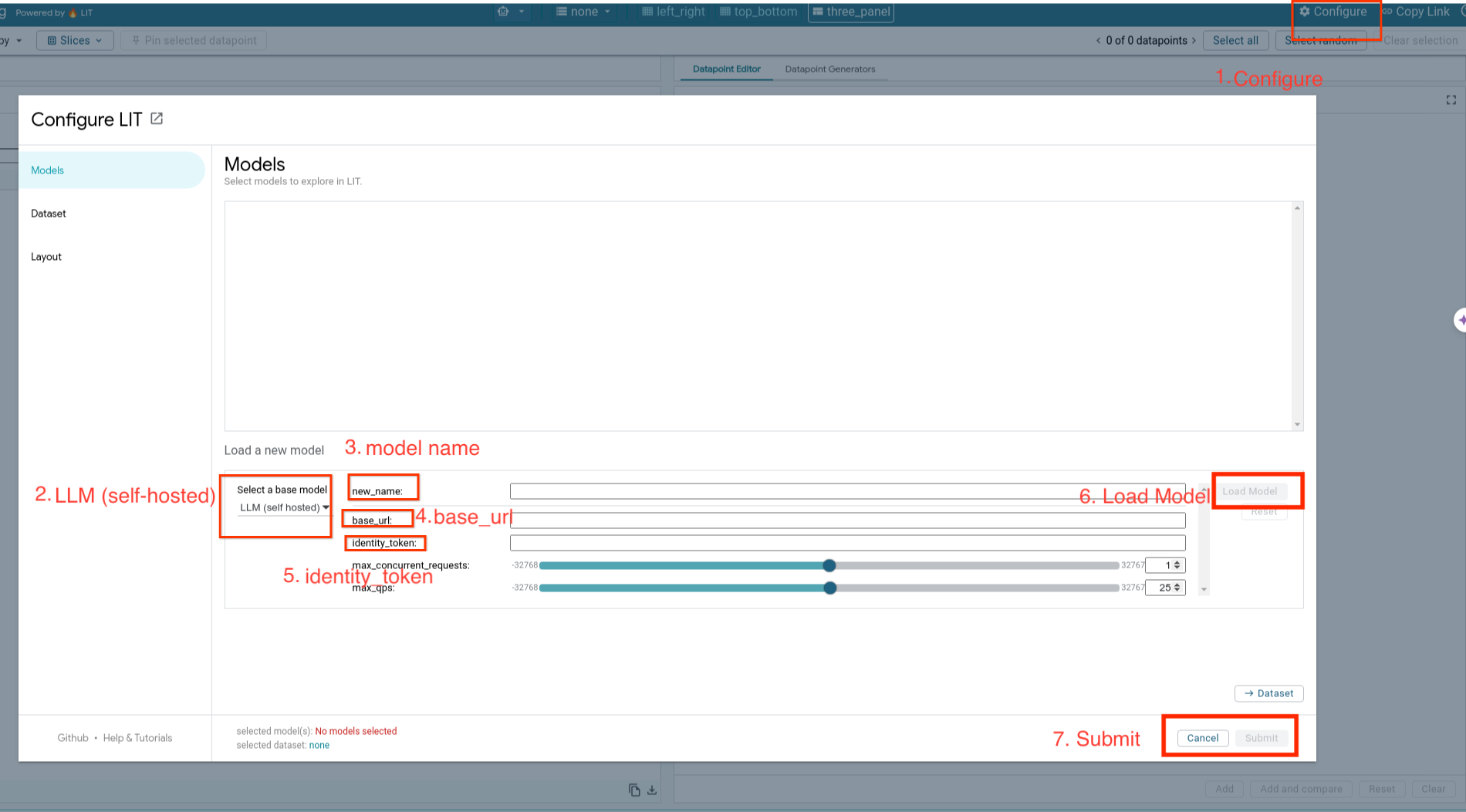
Cargarás modelos autoalojados y ajustarás sus parámetros siguiendo los pasos que se indican a continuación.
- Haz clic en la opción
Configureen la IU de LIT. - Selecciona la opción
LLM (self hosted)en la opciónSelect a base model. - Debes nombrar el modelo en
new_name. - Ingresa la URL de tu servidor de modelos como
base_url. - Ingresa el token de identidad obtenido en
identity_tokensi envías el servidor de la app de LIT a través de un proxy (consulta los pasos 3 y 7). De lo contrario, déjalo vacío. - Haz clic en
Load Model. - Haz clic en
Submit.
6. Interactúa con LIT en GCP
La LIT ofrece un amplio conjunto de funciones para ayudarte a depurar y comprender los comportamientos del modelo. Puedes hacer algo tan simple como consultar el modelo escribiendo texto en un cuadro y viendo las predicciones del modelo, o bien inspeccionar los modelos en profundidad con el conjunto de funciones potentes de LIT, que incluyen las siguientes:
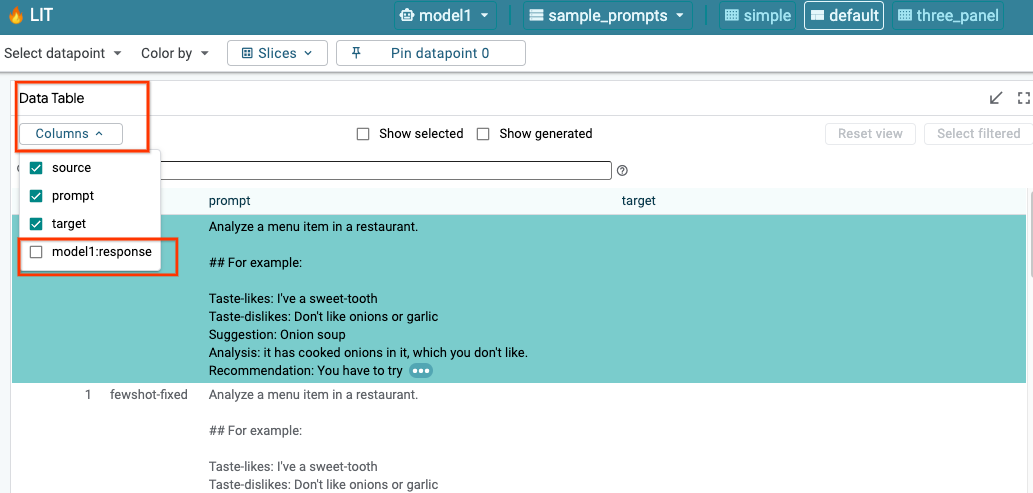
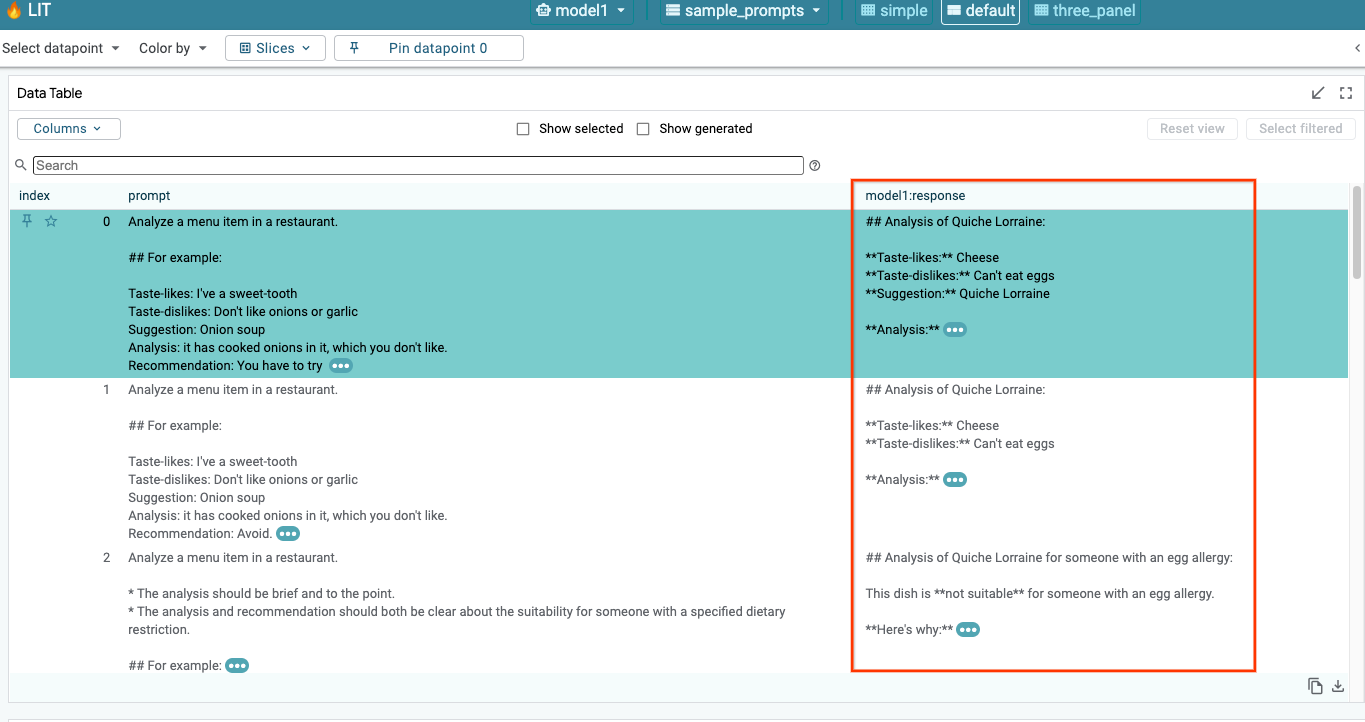
6a: Consulta el modelo a través de LIT
LIT consulta automáticamente el conjunto de datos después de cargar el modelo y el conjunto de datos. Para ver la respuesta de cada modelo, selecciona la respuesta en las columnas.
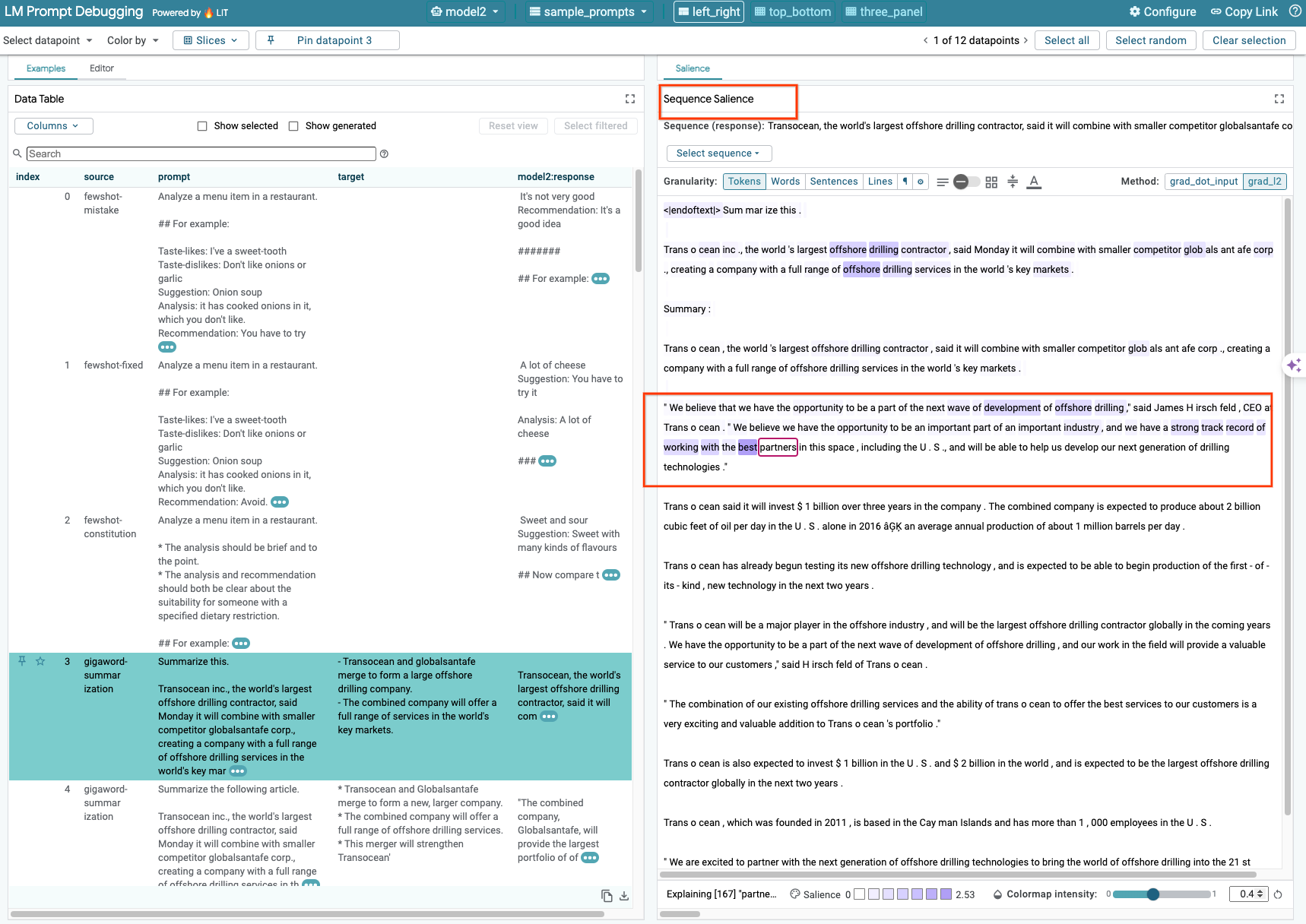
6-b: Usa la técnica de prominencia de secuencia
Actualmente, la técnica de prominencia de secuencia en LIT solo admite modelos alojados por el usuario.
La relevancia de la secuencia es una herramienta visual que ayuda a depurar las instrucciones de los LLM destacando qué partes de una instrucción son más importantes para un resultado determinado. Para obtener más información sobre la relevancia de la secuencia, consulta el instructivo completo sobre cómo usar esta función.
Para acceder a los resultados de relevancia, haz clic en cualquier entrada o salida de la instrucción o la respuesta, y se mostrarán los resultados de relevancia.
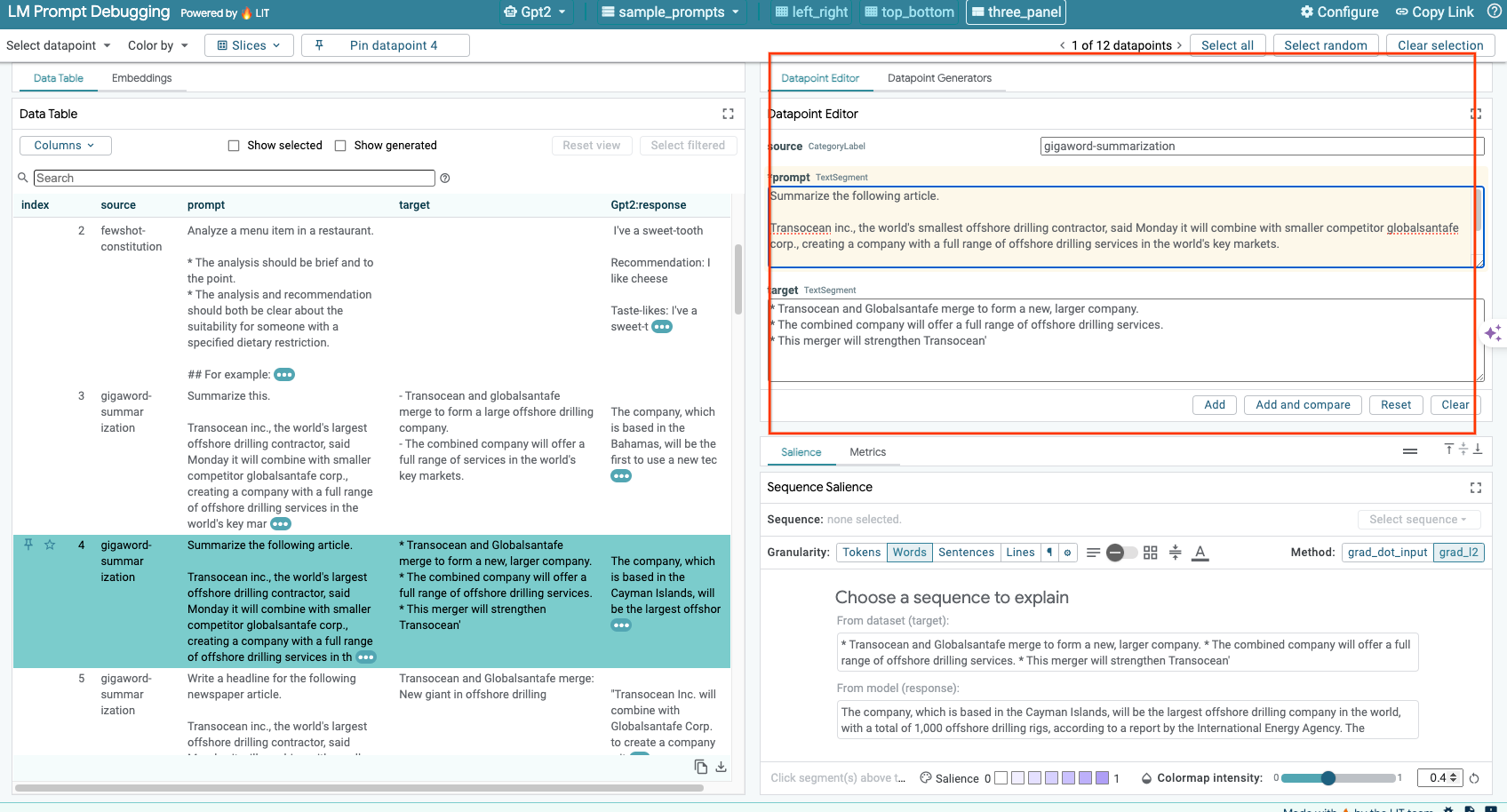
6-c: Edita manualmente la instrucción y el destino
LIT te permite editar manualmente cualquier prompt y target para un punto de datos existente. Si haces clic en Add, la nueva entrada se agregará al conjunto de datos.
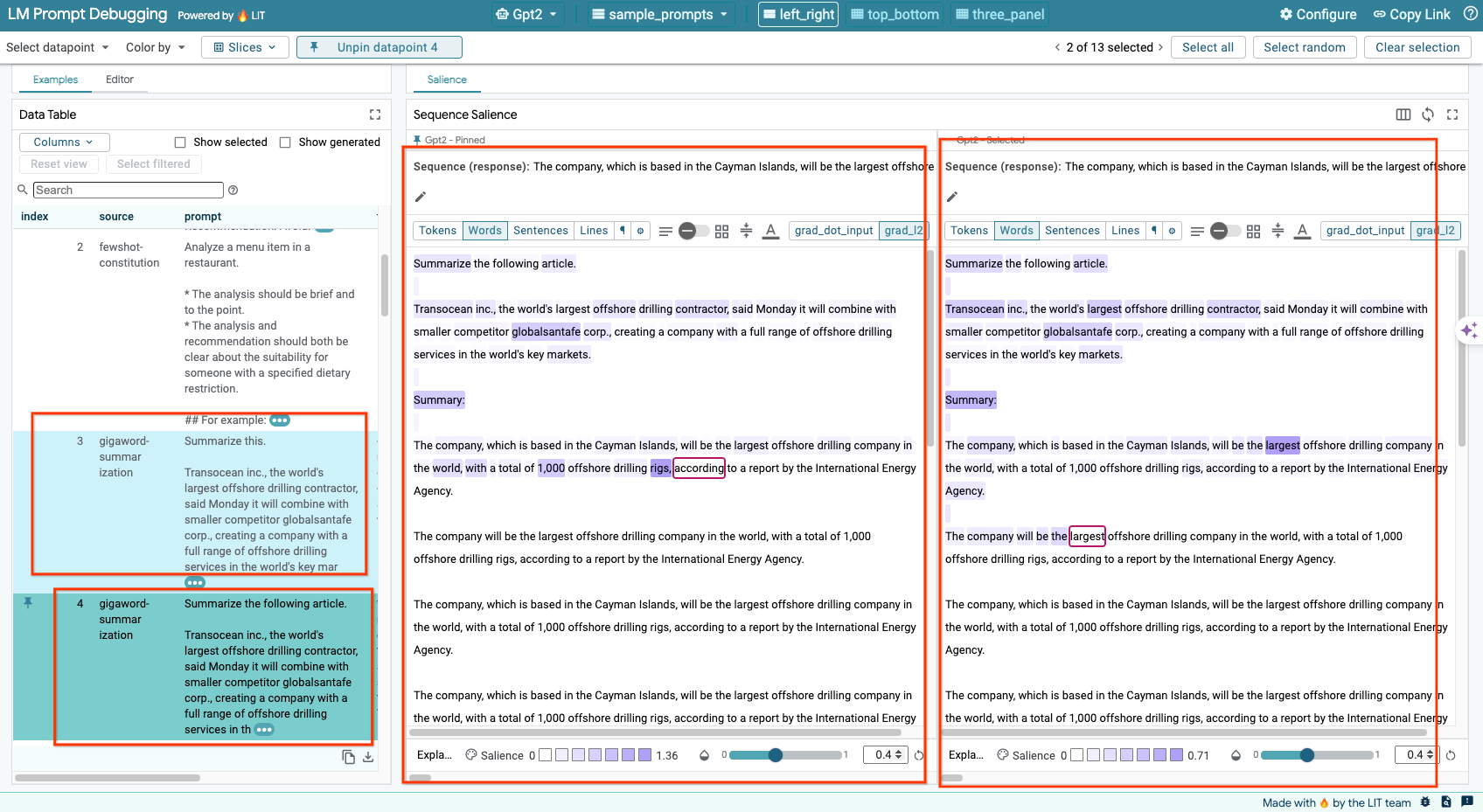
6-d: Comparar instrucciones en paralelo
LIT te permite comparar instrucciones en paralelo en ejemplos originales y editados. Puedes editar manualmente un ejemplo y ver el resultado de la predicción y el análisis de la relevancia de la secuencia para las versiones original y editada de forma simultánea. Puedes modificar la instrucción para cada punto de datos, y LIT generará la respuesta correspondiente consultando el modelo.
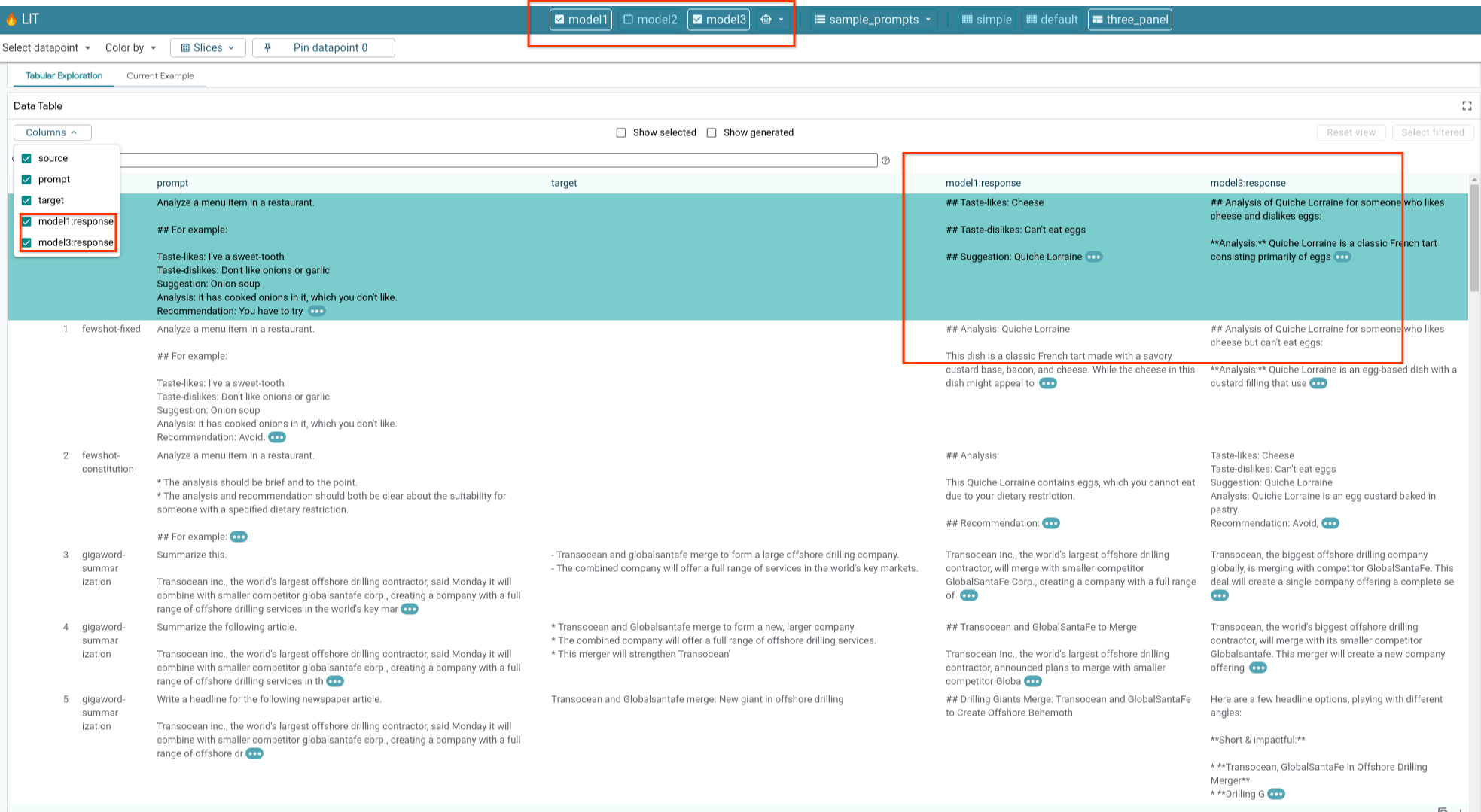
6e: Compara varios modelos en paralelo
LIT permite comparar modelos de forma paralela en ejemplos individuales de generación y puntuación de texto, así como en ejemplos agregados para métricas específicas. Si consultas varios modelos cargados, puedes comparar fácilmente las diferencias en sus respuestas.
6-f: Automatic Counterfactual Generators
Puedes usar generadores de contrafácticos automáticos para crear entradas alternativas y ver cómo se comporta tu modelo con ellas de inmediato.
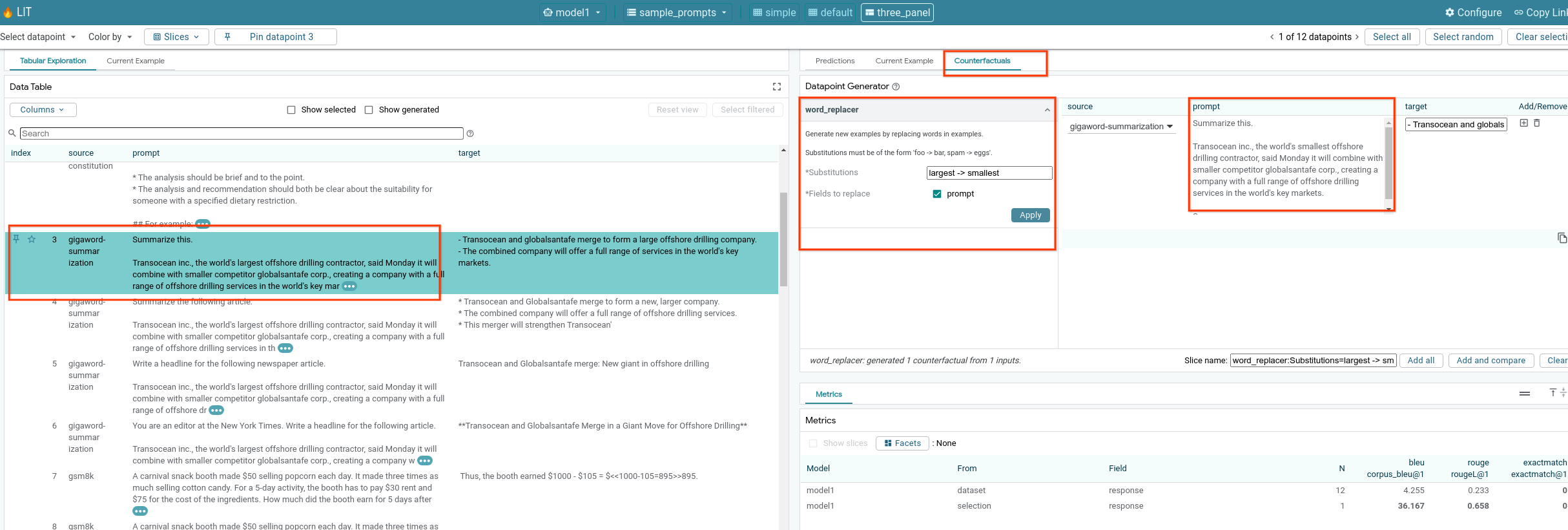
6-g: Evalúa el rendimiento del modelo
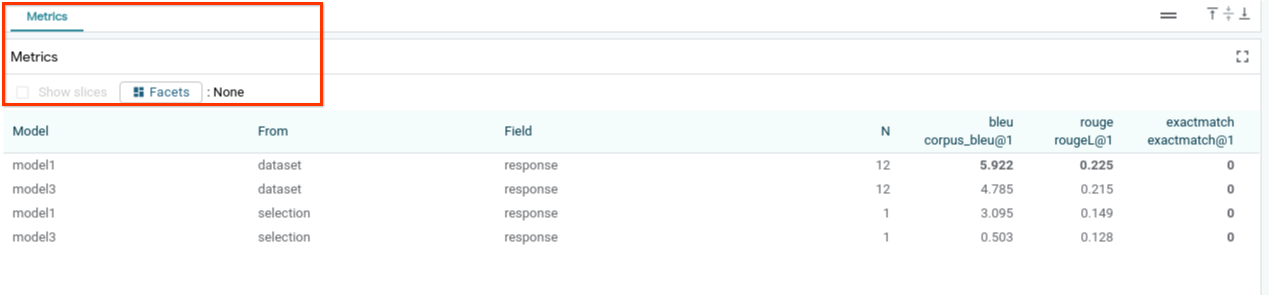
Puedes evaluar el rendimiento del modelo con métricas (actualmente, se admiten las puntuaciones BLEU y ROUGE para la generación de texto) en todo el conjunto de datos o en cualquier subconjunto de ejemplos filtrados o seleccionados.
7. Solución de problemas
7-a: Posibles problemas de acceso y soluciones
Como se aplica --no-allow-unauthenticated cuando se realiza la implementación en Cloud Run, es posible que encuentres errores prohibidos, como se muestra a continuación.

Existen dos enfoques para acceder al servicio de la app de LIT.
1. Proxy para el servicio local
Puedes enviar un proxy del servicio al host local con el siguiente comando.
# Proxy the service to local host.
gcloud run services proxy $LIT_SERVICE_NAME
Luego, deberías poder acceder al servidor de LIT haciendo clic en el vínculo del servicio proxy.
2. Autentica usuarios directamente
Puedes seguir este vínculo para autenticar a los usuarios y permitir el acceso directo al servicio de la app de LIT. Este enfoque también puede permitir que un grupo de usuarios acceda al servicio. Para el desarrollo que implica la colaboración con varias personas, esta es una opción más eficaz.
7-b: Verificaciones para garantizar que el servidor del modelo se haya iniciado correctamente
Para asegurarte de que el servidor de modelos se haya iniciado correctamente, puedes consultarlo directamente enviando una solicitud. El servidor de modelos proporciona tres extremos: predict, tokenize y salience. Asegúrate de proporcionar los campos prompt y target en tu solicitud.
# Query the model server predict endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/predict -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server tokenize endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/tokenize -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server salience endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/salience -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
Si tienes problemas de acceso, consulta la sección 7-a anterior.
8. Felicitaciones
¡Felicitaciones por completar el codelab! ¡Es hora de relajarse!
Limpia
Para limpiar el lab, borra todos los servicios de Google Cloud que se crearon para el lab. Usa Google Cloud Shell para ejecutar los siguientes comandos.
Si se pierde la conexión de Google Cloud debido a la inactividad, restablece las variables siguiendo los pasos anteriores.
# Delete the LIT App Service.
gcloud run services delete $LIT_SERVICE_NAME
Si iniciaste el servidor de modelos, también debes borrarlo.
# Delete the Model Service.
gcloud run services delete $MODEL_SERVICE_NAME
Lecturas adicionales
Sigue aprendiendo sobre las funciones de la herramienta LIT con los siguientes materiales:
- Gemma: Vínculo
- Base de código fuente abierto de LIT: Repositorio de Git
- Artículo sobre LIT: ArXiv
- Documento de depuración de instrucciones de LIT: ArXiv
- Video de demostración de la función LIT: YouTube
- Demostración de depuración de instrucciones LIT: YouTube
- Kit de herramientas de IA generativa responsable: Vínculo
Contacto
Si tienes preguntas o problemas con este codelab, comunícate con nosotros en GitHub.
Licencia
Esta obra se ofrece bajo la licencia Atribución 4.0 Genérica de Creative Commons.