
1. खास जानकारी
इस लैब में, Google Cloud Platform (GCP) पर LIT ऐप्लिकेशन सर्वर को डिप्लॉय करने के बारे में पूरी जानकारी दी गई है. इससे Vertex AI Gemini फ़ाउंडेशन मॉडल और खुद होस्ट किए गए तीसरे पक्ष के लार्ज लैंग्वेज मॉडल (एलएलएम) के साथ इंटरैक्ट किया जा सकता है. इसमें, प्रॉम्प्ट डीबग करने और मॉडल इंटरप्रेट करने के लिए, LIT यूज़र इंटरफ़ेस (यूआई) का इस्तेमाल करने के बारे में भी दिशा-निर्देश दिए गए हैं.
इस लैब को पूरा करने के बाद, उपयोगकर्ता इन कामों को करने का तरीका जान पाएंगे:
- GCP पर LIT सर्वर कॉन्फ़िगर करें.
- LIT सर्वर को Vertex AI Gemini मॉडल या खुद होस्ट किए गए अन्य एलएलएम से कनेक्ट करें.
- मॉडल की परफ़ॉर्मेंस और अहम जानकारी को बेहतर बनाने के लिए, LIT यूज़र इंटरफ़ेस (यूआई) का इस्तेमाल करके प्रॉम्प्ट का विश्लेषण करें, उन्हें डीबग करें, और उनकी व्याख्या करें.
एलआईटी क्या है?
LIT, मॉडल को समझने में मदद करने वाला एक विज़ुअल और इंटरैक्टिव टूल है. यह टेक्स्ट, इमेज, और टेबल के रूप में दिए गए डेटा के साथ काम करता है. इसे स्टैंडअलोन सर्वर के तौर पर चलाया जा सकता है. इसके अलावा, इसे Google Colab, Jupyter, और Google Cloud Vertex AI जैसे नोटबुक एनवायरमेंट में भी चलाया जा सकता है. LIT, PyPI और GitHub पर उपलब्ध है.
इसे मूल रूप से क्लासिफ़िकेशन और रिग्रेशन मॉडल को समझने के लिए बनाया गया था. हाल ही के अपडेट में, एलएलएम प्रॉम्प्ट को डीबग करने के लिए टूल जोड़े गए हैं. इससे यह पता लगाया जा सकता है कि उपयोगकर्ता, मॉडल, और सिस्टम के कॉन्टेंट से जनरेशन के व्यवहार पर कैसे असर पड़ता है.
Vertex AI और Model Garden क्या है?
Vertex AI एक मशीन लर्निंग (एमएल) प्लैटफ़ॉर्म है. इसकी मदद से, एमएल मॉडल और एआई ऐप्लिकेशन को ट्रेन और डिप्लॉय किया जा सकता है. साथ ही, एआई की मदद से काम करने वाले ऐप्लिकेशन में इस्तेमाल करने के लिए, एलएलएम को पसंद के मुताबिक बनाया जा सकता है. Vertex AI में डेटा इंजीनियरिंग, डेटा साइंस, और एमएल इंजीनियरिंग के वर्कफ़्लो शामिल होते हैं. इससे आपकी टीमें, टूल के एक सामान्य सेट का इस्तेमाल करके एक साथ काम कर सकती हैं. साथ ही, Google Cloud के फ़ायदों का इस्तेमाल करके अपने ऐप्लिकेशन को स्केल कर सकती हैं.
Vertex Model Garden, एमएल मॉडल की एक लाइब्रेरी है. इसकी मदद से, Google के मालिकाना हक वाले और तीसरे पक्ष के चुने गए मॉडल और ऐसेट को खोजा, टेस्ट किया, पसंद के मुताबिक बनाया, और डिप्लॉय किया जा सकता है.
आपको क्या करना होगा
LIT की पहले से बनी इमेज से Docker कंटेनर को डिप्लॉय करने के लिए, Google Cloud Shell और Cloud Run का इस्तेमाल किया जाएगा.
Cloud Run, मैनेज किया जाने वाला कंप्यूट प्लैटफ़ॉर्म है. इसकी मदद से, कंटेनर को सीधे तौर पर Google के स्केलेबल इंफ़्रास्ट्रक्चर पर चलाया जा सकता है. इसमें GPU भी शामिल हैं.
डेटासेट
डिफ़ॉल्ट रूप से, डेमो में LIT के प्रॉम्प्ट डिबग करने वाले सैंपल डेटासेट का इस्तेमाल किया जाता है. हालांकि, यूज़र इंटरफ़ेस (यूआई) के ज़रिए अपना डेटा भी लोड किया जा सकता है.
शुरू करने से पहले
इस रेफ़रंस गाइड के लिए, आपको Google Cloud प्रोजेक्ट की ज़रूरत होगी. आपके पास नया प्रोजेक्ट बनाने या पहले से बनाए गए किसी प्रोजेक्ट को चुनने का विकल्प होता है.
2. Google Cloud Console और Cloud Shell लॉन्च करना
इस चरण में, Google Cloud Console लॉन्च करें और Google Cloud Shell का इस्तेमाल करें.
2-a: Google Cloud Console लॉन्च करना
कोई ब्राउज़र लॉन्च करें और Google Cloud Console पर जाएं.
Google Cloud Console एक सुरक्षित और वेब एडमिन इंटरफ़ेस है. इसकी मदद से, Google Cloud के संसाधनों को आसानी से मैनेज किया जा सकता है. यह एक DevOps टूल है, जो कभी भी इस्तेमाल किया जा सकता है.
2-b: Google Cloud Shell लॉन्च करना
Cloud Shell एक ऑनलाइन डेवलपमेंट और ऑपरेशंस एनवायरमेंट है. इसे अपने ब्राउज़र से कहीं भी ऐक्सेस किया जा सकता है. इसकी मदद से, अपने संसाधनों को मैनेज किया जा सकता है. इसमें gcloud कमांड-लाइन टूल, kubectl वगैरह जैसे टूल पहले से लोड होते हैं. ऑनलाइन Cloud Shell Editor का इस्तेमाल करके, क्लाउड पर आधारित अपने ऐप्लिकेशन डेवलप, बिल्ड, डीबग, और डिप्लॉय किए जा सकते हैं. Cloud Shell, डेवलपर के लिए तैयार एक ऑनलाइन एनवायरमेंट उपलब्ध कराता है. इसमें पहले से इंस्टॉल किए गए टूल का पसंदीदा सेट और 5 जीबी का परसिस्टेंट स्टोरेज स्पेस होता है. अगले चरणों में, कमांड प्रॉम्प्ट का इस्तेमाल किया जाएगा.
मेन्यू बार में सबसे ऊपर दाईं ओर मौजूद आइकॉन का इस्तेमाल करके, Google Cloud Shell लॉन्च करें. इस आइकॉन को यहां दिए गए स्क्रीनशॉट में नीले रंग के गोले में दिखाया गया है.

आपको पेज के सबसे नीचे, बैश शेल वाला टर्मिनल दिखेगा.

2-c: Google Cloud प्रोजेक्ट सेट करना
आपको gcloud कमांड का इस्तेमाल करके, प्रोजेक्ट आईडी और प्रोजेक्ट क्षेत्र सेट करना होगा.
# Set your GCP Project ID.
gcloud config set project your-project-id
# Set your GCP Project Region.
gcloud config set run/region your-project-region
3. Cloud Run की मदद से, LIT ऐप्लिकेशन सर्वर की Docker इमेज डिप्लॉय करना
3-a: LIT ऐप्लिकेशन को Cloud Run पर डिप्लॉय करना
सबसे पहले, आपको LIT-App के नए वर्शन को डिप्लॉय किए जाने वाले वर्शन के तौर पर सेट करना होगा.
# Set latest version as your LIT_SERVICE_TAG.
export LIT_SERVICE_TAG=latest
# List all the public LIT GCP App server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app
वर्शन टैग सेट करने के बाद, आपको सेवा का नाम देना होगा.
# Set your lit service name. While 'lit-app-service' is provided as a placeholder, you can customize the service name based on your preferences.
export LIT_SERVICE_NAME=lit-app-service
इसके बाद, कंटेनर को Cloud Run पर डिप्लॉय करने के लिए, यहां दिया गया निर्देश चलाएं.
# Use below cmd to deploy the LIT App to Cloud Run.
gcloud run deploy $LIT_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app:$LIT_SERVICE_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--no-allow-unauthenticated
LIT, सर्वर शुरू करते समय डेटासेट जोड़ने की सुविधा भी देता है. इसके लिए, DATASETS वैरिएबल को सेट करें, ताकि वह डेटा शामिल किया जा सके जिसे आपको लोड करना है. इसके लिए, name:path फ़ॉर्मैट का इस्तेमाल करें. उदाहरण के लिए, data_foo:/bar/data_2024.jsonl. डेटासेट का फ़ॉर्मैट .jsonl होना चाहिए. इसमें हर रिकॉर्ड में prompt और वैकल्पिक तौर पर target और source फ़ील्ड शामिल होने चाहिए. एक से ज़्यादा डेटासेट लोड करने के लिए, उन्हें कॉमा लगाकर अलग करें. अगर इसे सेट नहीं किया जाता है, तो LIT प्रॉम्प्ट डीबग करने के लिए डेटासेट का सैंपल लोड किया जाएगा.
# Set the dataset.
export DATASETS=[DATASETS]
MAX_EXAMPLES सेट करके, हर आकलन सेट से लोड किए जाने वाले उदाहरणों की ज़्यादा से ज़्यादा संख्या सेट की जा सकती है.
# Set the max examples.
export MAX_EXAMPLES=[MAX_EXAMPLES]
इसके बाद, डिप्लॉय कमांड में
--set-env-vars "DATASETS=$DATASETS" \
--set-env-vars "MAX_EXAMPLES=$MAX_EXAMPLES" \
3-b: LIT App Service देखना
LIT ऐप्लिकेशन सर्वर बनाने के बाद, आपको यह सेवा Cloud Console के Cloud Run सेक्शन में दिखेगी.
आपने अभी-अभी जो LIT ऐप्लिकेशन सेवा बनाई है उसे चुनें. पक्का करें कि सेवा का नाम LIT_SERVICE_NAME के जैसा हो.

अभी-अभी डिप्लॉय की गई सेवा पर क्लिक करके, सेवा का यूआरएल देखा जा सकता है.

इसके बाद, आपको LIT UI दिखेगा. अगर आपको कोई गड़बड़ी मिलती है, तो समस्या हल करने से जुड़ा सेक्शन देखें.

गतिविधि को मॉनिटर करने, गड़बड़ी के मैसेज देखने, और डिप्लॉयमेंट की प्रोग्रेस को ट्रैक करने के लिए, LOGS सेक्शन देखा जा सकता है.
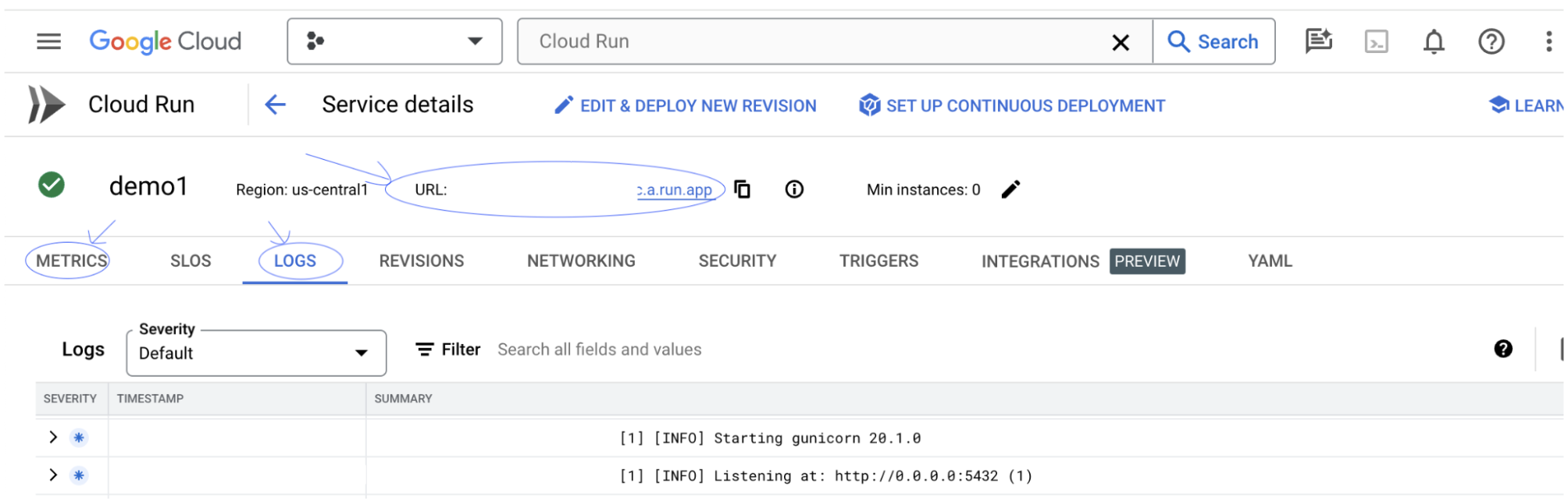
सेवा की मेट्रिक देखने के लिए, METRICS सेक्शन पर जाएं.

3-ग: डेटासेट लोड करना
LIT UI में, Configure विकल्प पर क्लिक करें. इसके बाद, Dataset चुनें. डेटासेट का नाम और यूआरएल देकर, डेटासेट लोड करें. डेटासेट का फ़ॉर्मैट .jsonl होना चाहिए. इसमें हर रिकॉर्ड में prompt और वैकल्पिक तौर पर target और source फ़ील्ड शामिल होने चाहिए.

4. Vertex AI Model Garden में Gemini मॉडल तैयार करना
Google के Gemini फ़ाउंडेशन मॉडल, Vertex AI API से उपलब्ध हैं. LIT, जनरेटिव एआई मॉडल के लिए VertexAIModelGarden मॉडल रैपर उपलब्ध कराता है. मॉडल के नाम वाले पैरामीटर के ज़रिए, ज़रूरत के मुताबिक वर्शन (जैसे, "gemini-1.5-pro-001") के बारे में बताएं. इन मॉडल का इस्तेमाल करने का मुख्य फ़ायदा यह है कि इन्हें लागू करने के लिए, किसी अतिरिक्त प्रयास की ज़रूरत नहीं होती. डिफ़ॉल्ट रूप से, आपको GCP पर Gemini 1.0 Pro और Gemini 1.5 Pro जैसे मॉडल का तुरंत ऐक्सेस मिल जाता है. इससे आपको कॉन्फ़िगरेशन के अतिरिक्त चरणों को पूरा करने की ज़रूरत नहीं पड़ती.
4-a: Vertex AI को अनुमतियां देना
GCP में Gemini से क्वेरी करने के लिए, आपको सेवा खाते को Vertex AI की अनुमतियां देनी होंगी. पक्का करें कि सेवा खाते का नाम Default compute service account हो. खाते के सेवा खाते का ईमेल पता कॉपी करें.

अपने IAM की अनुमति वाली सूची में, सेवा खाते के ईमेल को Vertex AI User भूमिका वाले प्रिंसिपल के तौर पर जोड़ें.

4-b: Gemini के मॉडल लोड करना
यहां दिए गए तरीके का इस्तेमाल करके, Gemini मॉडल लोड किए जा सकते हैं और उनके पैरामीटर में बदलाव किया जा सकता है.
- LIT UI में मौजूद
Configureविकल्प पर क्लिक करें.
- LIT UI में मौजूद
Select a base modelविकल्प में जाकर,geminiविकल्प चुनें.
- आपको
new_nameमें मॉडल का नाम डालना होगा.
- आपको
- चुने गए Gemini मॉडल को
model_nameके तौर पर डालें.
- चुने गए Gemini मॉडल को
Load Modelपर क्लिक करें.
Submitपर क्लिक करें.

5. GCP पर, खुद होस्ट किए गए LLM मॉडल सर्वर को डिप्लॉय करना
LIT के मॉडल सर्वर की डॉकर इमेज के साथ LLM को खुद होस्ट करने से, आपको मॉडल के व्यवहार के बारे में ज़्यादा जानकारी मिलती है. इसके लिए, LIT के सैलियंस और टोकनाइज़ फ़ंक्शन का इस्तेमाल किया जा सकता है. मॉडल सर्वर इमेज, KerasNLP या Hugging Face Transformers मॉडल के साथ काम करती है.इसमें लाइब्रेरी से मिले और खुद होस्ट किए गए वेट शामिल हैं. जैसे, Google Cloud Storage पर.
5-a: मॉडल कॉन्फ़िगर करना
हर कंटेनर एक मॉडल लोड करता है. इसे एनवायरमेंट वैरिएबल का इस्तेमाल करके कॉन्फ़िगर किया जाता है.
आपको MODEL_CONFIG सेट करके, लोड किए जाने वाले मॉडल तय करने चाहिए. फ़ॉर्मैट name:path होना चाहिए. उदाहरण के लिए, model_foo:model_foo_path. पाथ, यूआरएल, लोकल फ़ाइल पाथ या कॉन्फ़िगर किए गए डीप लर्निंग फ़्रेमवर्क के लिए प्रीसेट का नाम हो सकता है. ज़्यादा जानकारी के लिए, यहां दी गई टेबल देखें. इस सर्वर को Gemma, GPT2, Llama, और Mistral के साथ टेस्ट किया गया है. साथ ही, इसे सभी DL_FRAMEWORK वैल्यू के साथ भी टेस्ट किया गया है. अन्य मॉडल काम कर सकते हैं. हालांकि, उनमें बदलाव करने की ज़रूरत पड़ सकती है.
# Set models you want to load. While 'gemma2b is given as a placeholder, you can load your preferred model by following the instructions above.
export MODEL_CONFIG=gemma2b:gemma_2b_en
इसके अलावा, LIT मॉडल सर्वर, नीचे दिए गए कमांड का इस्तेमाल करके अलग-अलग एनवायरमेंट वैरिएबल को कॉन्फ़िगर करने की अनुमति देता है. ज़्यादा जानकारी के लिए, कृपया टेबल देखें. ध्यान दें कि हर वैरिएबल को अलग-अलग सेट करना होगा.
# Customize the variable value as needed.
export [VARIABLE]=[VALUE]
वैरिएबल | वैल्यू | ब्यौरा |
DL_FRAMEWORK |
| मॉडलिंग लाइब्रेरी का इस्तेमाल, मॉडल के वेट को तय किए गए रनटाइम पर लोड करने के लिए किया जाता है. यह डिफ़ॉल्ट रूप से |
DL_RUNTIME |
| डीप लर्निंग बैकएंड फ़्रेमवर्क, जिस पर मॉडल काम करता है. इस सर्वर से लोड किए गए सभी मॉडल, एक ही बैकएंड का इस्तेमाल करेंगे. अगर ऐसा नहीं होता है, तो गड़बड़ियां होंगी. यह डिफ़ॉल्ट रूप से |
PRECISION |
| एलएलएम मॉडल के लिए फ़्लोटिंग पॉइंट प्रेसिज़न. यह डिफ़ॉल्ट रूप से |
BATCH_SIZE | पॉज़िटिव पूर्णांक | हर बैच में प्रोसेस किए जाने वाले उदाहरणों की संख्या. यह डिफ़ॉल्ट रूप से |
SEQUENCE_LENGTH | पॉज़िटिव पूर्णांक | इनपुट प्रॉम्प्ट और जनरेट किए गए टेक्स्ट की ज़्यादा से ज़्यादा सीक्वेंस लेंथ. यह डिफ़ॉल्ट रूप से |
5-ख: मॉडल सर्वर को Cloud Run पर डिप्लॉय करना
सबसे पहले, आपको मॉडल सर्वर के सबसे नए वर्शन को डिप्लॉय किए जाने वाले वर्शन के तौर पर सेट करना होगा.
# Set latest as MODEL_VERSION_TAG.
export MODEL_VERSION_TAG=latest
# List all the public LIT GCP model server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server
वर्शन टैग सेट करने के बाद, आपको अपने मॉडल-सर्वर का नाम देना होगा.
# Set your Service name.
export MODEL_SERVICE_NAME='gemma2b-model-server'
इसके बाद, कंटेनर को Cloud Run पर डिप्लॉय करने के लिए, यहां दिया गया निर्देश चलाएं. अगर एनवायरमेंट वैरिएबल सेट नहीं किए जाते हैं, तो डिफ़ॉल्ट वैल्यू लागू होंगी. ज़्यादातर एलएलएम को महंगे कंप्यूटिंग संसाधनों की ज़रूरत होती है. इसलिए, हमारा सुझाव है कि आप GPU का इस्तेमाल करें. अगर आपको सिर्फ़ सीपीयू पर मॉडल चलाना है (यह GPT2 जैसे छोटे मॉडल के लिए ठीक काम करता है), तो इससे जुड़े आर्ग्युमेंट --gpu 1 --gpu-type nvidia-l4 --max-instances 7 हटाए जा सकते हैं.
# Deploy the model service container.
gcloud beta run deploy $MODEL_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server:$MODEL_VERSION_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 7 \
--set-env-vars "MODEL_CONFIG=$MODEL_CONFIG" \
--no-allow-unauthenticated
इसके अलावा, यहां दी गई कमांड जोड़कर एनवायरमेंट वैरिएबल को पसंद के मुताबिक बनाया जा सकता है. सिर्फ़ उन एनवायरमेंट वैरिएबल को शामिल करें जो आपकी खास ज़रूरतों के लिए ज़रूरी हैं.
--set-env-vars "DL_FRAMEWORK=$DL_FRAMEWORK" \
--set-env-vars "DL_RUNTIME=$DL_RUNTIME" \
--set-env-vars "PRECISION=$PRECISION" \
--set-env-vars "BATCH_SIZE=$BATCH_SIZE" \
--set-env-vars "SEQUENCE_LENGTH=$SEQUENCE_LENGTH" \
कुछ मॉडल को ऐक्सेस करने के लिए, अतिरिक्त एनवायरमेंट वैरिएबल की ज़रूरत पड़ सकती है. ज़रूरत के मुताबिक, Kaggle Hub (KerasNLP मॉडल के लिए इस्तेमाल किया जाता है) और Hugging Face Hub से जुड़े निर्देश देखें.
5-c: ऐक्सेस मॉडल सर्वर
मॉडल सर्वर बनाने के बाद, शुरू की गई सेवा को अपने GCP प्रोजेक्ट के Cloud Run सेक्शन में देखा जा सकता है.
आपने जो मॉडल सर्वर अभी बनाया है उसे चुनें. पक्का करें कि सेवा का नाम MODEL_SERVICE_NAME के जैसा हो.
आपने अभी-अभी जिस मॉडल सेवा को डिप्लॉय किया है उस पर क्लिक करके, सेवा का यूआरएल देखा जा सकता है.
गतिविधि को मॉनिटर करने, गड़बड़ी के मैसेज देखने, और डिप्लॉयमेंट की प्रोग्रेस को ट्रैक करने के लिए, LOGS सेक्शन देखा जा सकता है.
सेवा की मेट्रिक देखने के लिए, METRICS सेक्शन पर जाएं.
5-d: Load Self-Hosted Models
अगर आपने तीसरे चरण में अपने LIT सर्वर को प्रॉक्सी किया है (समस्या हल करने से जुड़ा सेक्शन देखें), तो आपको यह कमांड चलाकर अपना GCP आइडेंटिटी टोकन पाना होगा.
# Find your GCP identity token.
gcloud auth print-identity-token
आपको यहां दिए गए चरणों का पालन करके, खुद के होस्ट किए गए मॉडल लोड करने होंगे और उनके पैरामीटर में बदलाव करना होगा.
- LIT UI में मौजूद
Configureविकल्प पर क्लिक करें. Select a base modelविकल्प में जाकर,LLM (self hosted)विकल्प चुनें.- आपको
new_nameमें मॉडल का नाम डालना होगा. - अपने मॉडल सर्वर का यूआरएल,
base_urlके तौर पर डालें. - अगर आपने LIT ऐप्लिकेशन सर्वर को प्रॉक्सी किया है, तो
identity_tokenमें मिला आइडेंटिटी टोकन डालें. इसके लिए, तीसरा और सातवां चरण देखें. अगर ऐसा नहीं है, तो इसे खाली छोड़ दें. Load Modelपर क्लिक करें.Submitपर क्लिक करें.

6. GCP पर LIT के साथ इंटरैक्ट करना
LIT में कई सुविधाएं उपलब्ध हैं. इनकी मदद से, मॉडल के व्यवहार को डीबग किया जा सकता है और उसे समझा जा सकता है. मॉडल से क्वेरी करना बहुत आसान है. इसके लिए, बॉक्स में टेक्स्ट टाइप करें और मॉडल के अनुमान देखें. इसके अलावा, LIT की सुविधाओं का इस्तेमाल करके, मॉडल की बारीकी से जांच करें. इनमें ये सुविधाएं शामिल हैं:
6-a: LIT के ज़रिए मॉडल से क्वेरी करना
मॉडल और डेटासेट लोड होने के बाद, LIT अपने-आप डेटासेट के लिए क्वेरी करता है. कॉलम में मौजूद जवाब को चुनकर, हर मॉडल का जवाब देखा जा सकता है.


6-b: सीक्वेंस सैलिएंस तकनीक का इस्तेमाल करना
फ़िलहाल, LIT पर Sequence Salience की तकनीक सिर्फ़ ऐसे मॉडल के साथ काम करती है जिन्हें खुद होस्ट किया गया हो.
सीक्वेंस सैलियंस, एक विज़ुअल टूल है. यह एलएलएम प्रॉम्प्ट को डीबग करने में मदद करता है. इसके लिए, यह हाइलाइट करता है कि किसी आउटपुट के लिए, प्रॉम्प्ट के कौनसे हिस्से सबसे ज़्यादा ज़रूरी हैं. सीक्वेंस सैलिएंस के बारे में ज़्यादा जानने के लिए, इस सुविधा को इस्तेमाल करने के तरीके के बारे में ज़्यादा जानने के लिए, पूरा ट्यूटोरियल देखें.
सैलियंस के नतीजों को ऐक्सेस करने के लिए, प्रॉम्प्ट या जवाब में मौजूद किसी भी इनपुट या आउटपुट पर क्लिक करें. इसके बाद, सैलियंस के नतीजे दिखेंगे.

6-c: Manullay Edit Prompt and Target
एलआईटी की मदद से, मौजूदा डेटापॉइंट के लिए किसी भी prompt और target में मैन्युअल तरीके से बदलाव किया जा सकता है. Add पर क्लिक करने से, नया इनपुट डेटासेट में जुड़ जाएगा.

6-d: प्रॉम्प्ट की अगल-बगल में तुलना करें
LIT की मदद से, ओरिजनल और बदले गए उदाहरणों में प्रॉम्प्ट की तुलना की जा सकती है. उदाहरण में मैन्युअल तरीके से बदलाव किया जा सकता है. साथ ही, ओरिजनल और बदले गए, दोनों वर्शन के लिए अनुमान के नतीजे और क्रम के महत्व का विश्लेषण एक साथ देखा जा सकता है. हर डेटापॉइंट के लिए प्रॉम्प्ट में बदलाव किया जा सकता है. इसके बाद, LIT मॉडल से क्वेरी करके जवाब जनरेट करेगा.

6-e: एक साथ कई मॉडल की तुलना करना
LIT की मदद से, टेक्स्ट जनरेट करने और स्कोरिंग के अलग-अलग उदाहरणों के साथ-साथ, खास मेट्रिक के लिए एग्रीगेट किए गए उदाहरणों के आधार पर, मॉडल की तुलना एक साथ की जा सकती है. लोड किए गए अलग-अलग मॉडल से क्वेरी करके, उनके जवाबों के बीच के अंतर की आसानी से तुलना की जा सकती है.

6-f: Automatic Counterfactual Generators
वैकल्पिक इनपुट बनाने के लिए, अपने-आप काम करने वाले काउंटरफ़ैक्चुअल जनरेटर का इस्तेमाल किया जा सकता है. साथ ही, यह देखा जा सकता है कि आपका मॉडल उन पर कैसा व्यवहार करता है.

6-g: मॉडल की परफ़ॉर्मेंस का आकलन करना
पूरे डेटासेट या फ़िल्टर किए गए या चुने गए उदाहरणों के किसी भी सबसेट में, मेट्रिक का इस्तेमाल करके मॉडल की परफ़ॉर्मेंस का आकलन किया जा सकता है. फ़िलहाल, टेक्स्ट जनरेशन के लिए BLEU और ROUGE स्कोर काम करते हैं.

7. समस्या का हल
7-a: ऐक्सेस से जुड़ी संभावित समस्याएं और उनके समाधान
Cloud Run पर डिप्लॉय करते समय, --no-allow-unauthenticated लागू होता है. इसलिए, आपको यहां दिखाई गई गड़बड़ियां दिख सकती हैं.

LIT App की सेवा को ऐक्सेस करने के दो तरीके हैं.
1. लोकल सर्विस के लिए प्रॉक्सी
नीचे दिए गए निर्देश का इस्तेमाल करके, सेवा को लोकल होस्ट पर प्रॉक्सी किया जा सकता है.
# Proxy the service to local host.
gcloud run services proxy $LIT_SERVICE_NAME
इसके बाद, प्रॉक्सी की गई सेवा के लिंक पर क्लिक करके, LIT सर्वर को ऐक्सेस किया जा सकेगा.
2. उपयोगकर्ताओं की सीधे पुष्टि करना
उपयोगकर्ताओं की पुष्टि करने के लिए, इस लिंक पर जाएं. इससे उन्हें LIT App की सेवा को सीधे तौर पर ऐक्सेस करने की अनुमति मिल जाएगी. इस तरीके से, उपयोगकर्ताओं के किसी ग्रुप को भी सेवा ऐक्सेस करने की अनुमति दी जा सकती है. अगर आपको कई लोगों के साथ मिलकर डेवलपमेंट करना है, तो यह विकल्प ज़्यादा कारगर है.
7-b: यह जांच करता है कि मॉडल सर्वर लॉन्च हो गया है या नहीं
यह पक्का करने के लिए कि मॉडल सर्वर सही तरीके से लॉन्च हो गया है, अनुरोध भेजकर सीधे मॉडल सर्वर से क्वेरी की जा सकती है. मॉडल सर्वर तीन एंडपॉइंट उपलब्ध कराता है: predict, tokenize, और salience. पक्का करें कि आपने अपने अनुरोध में prompt और target, दोनों फ़ील्ड की जानकारी दी हो.
# Query the model server predict endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/predict -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server tokenize endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/tokenize -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server salience endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/salience -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
अगर आपको ऐक्सेस करने में कोई समस्या आ रही है, तो ऊपर दिया गया सेक्शन 7-a देखें.
8. बधाई हो
कोडलैब पूरा करने के लिए बधाई! अब आराम करने का समय है!
व्यवस्थित करें
लैब को क्लीन अप करने के लिए, लैब के लिए बनाई गई सभी Google Cloud सेवाएं मिटाएं. नीचे दिए गए निर्देशों को चलाने के लिए, Google Cloud Shell का इस्तेमाल करें.
अगर कुछ समय तक कोई गतिविधि न होने की वजह से Google Cloud Connection बंद हो जाता है, तो पिछले चरणों का पालन करके वैरिएबल रीसेट करें.
# Delete the LIT App Service.
gcloud run services delete $LIT_SERVICE_NAME
अगर आपने मॉडल सर्वर शुरू किया है, तो आपको मॉडल सर्वर भी मिटाना होगा.
# Delete the Model Service.
gcloud run services delete $MODEL_SERVICE_NAME
इस बारे में और पढ़ें
नीचे दिए गए संसाधनों की मदद से, LIT टूल की सुविधाओं के बारे में जानें:
- Gemma: Link
- LIT का ओपन सोर्स कोड बेस: Git repo
- साहित्यिक पेपर: ArXiv
- एलआईटी प्रॉम्प्ट डीबगिंग पेपर: ArXiv
- LIT सुविधा का वीडियो डेमो: YouTube
- LIT प्रॉम्प्ट डीबग करने का डेमो: Youtube
- ज़िम्मेदारी के साथ जेन एआई का इस्तेमाल करने के लिए टूलकिट: लिंक
संपर्क करना
अगर आपको इस कोडलैब से जुड़ा कोई सवाल पूछना है या कोई समस्या आ रही है, तो कृपया GitHub पर हमसे संपर्क करें.
लाइसेंस
इस काम के लिए, Creative Commons एट्रिब्यूशन 4.0 जेनेरिक लाइसेंस के तहत लाइसेंस मिला है.