
1. 概览
本实验详细介绍了如何在 Google Cloud Platform (GCP) 上部署 LIT 应用服务器,以与 Vertex AI Gemini 基础模型和自托管的第三方大语言模型 (LLM) 进行交互。此外,还包含有关如何使用 LIT 界面进行提示调试和模型解读的指南。
完成本实验后,用户将了解如何:
- 在 GCP 上配置 LIT 服务器。
- 将 LIT 服务器连接到 Vertex AI Gemini 模型或其他自托管 LLM。
- 利用 LIT 界面分析、调试和解读提示,以获得更好的模型性能和洞见。
什么是 LIT?
LIT 是一款直观的交互式模型理解工具,支持文本、图片和表格数据。它可以作为独立服务器运行,也可以在笔记本环境中运行,例如 Google Colab、Jupyter 和 Google Cloud Vertex AI。您可以从 PyPI 和 GitHub 获取 LIT。
最初,LLM Playground 旨在了解分类模型和回归模型,但最近的更新添加了用于调试 LLM 提示的工具,让您可以探索用户、模型和系统内容如何影响生成行为。
什么是 Vertex AI 和 Model Garden?
Vertex AI 是一个机器学习 (ML) 平台,可用于训练和部署机器学习模型和 AI 应用,还可自定义 LLM 以在依托 AI 技术的应用中使用。Vertex AI 结合了数据工程、数据科学和机器学习工程工作流,使您的团队能够使用统一的工具集进行协作,并利用 Google Cloud 的优势扩展您的应用。
Vertex Model Garden 是一个机器学习模型库,可帮助您发现、测试、自定义和部署 Google 专有的以及部分第三方模型和资产。
您将执行的操作
您将使用 Google Cloud Shell 和 Cloud Run 从 LIT 的预构建映像部署 Docker 容器。
Cloud Run 是一个托管式计算平台,可让您直接在 Google 可伸缩的基础架构之上运行容器,包括在 GPU 上运行。
数据集
默认情况下,此演示使用 LIT 提示调试示例数据集,您也可以通过界面加载自己的数据集。
准备工作
在本参考指南中,您需要一个 Google Cloud 项目。您可以创建新项目,也可以选择已创建的项目。
2. 启动 Google Cloud 控制台和 Cloud Shell
在此步骤中,您将启动 Google Cloud 控制台并使用 Google Cloud Shell。
2-a:启动 Google Cloud 控制台
启动浏览器并前往 Google Cloud 控制台。
Google Cloud 控制台是一个功能强大且安全的 Web 管理界面,可让您快速管理 Google Cloud 资源。这是一款可随时随地使用的 DevOps 工具。
2-b:启动 Google Cloud Shell
Cloud Shell 是一个在线开发和运营环境,您可通过浏览器随时随地访问。您可以利用其预加载了实用程序(如 gcloud 命令行工具、kubectl 等)的在线终端管理资源,您还可以使用在线 Cloud Shell 编辑器开发、构建、调试和部署云端应用。Cloud Shell 提供了一个可供开发者使用的在线环境,其中预安装了常用的工具集,并提供 5GB 的永久性存储空间。您将在后续步骤中使用命令提示符。
使用菜单栏右上角的图标启动 Google Cloud Shell,如下图所示,该图标以蓝色圆圈标记。

您应该会在页面底部看到一个带有 Bash shell 的终端。

2-c:设置 Google Cloud 项目
您必须使用 gcloud 命令设置项目 ID 和项目区域。
# Set your GCP Project ID.
gcloud config set project your-project-id
# Set your GCP Project Region.
gcloud config set run/region your-project-region
3. 使用 Cloud Run 部署 LIT 应用服务器 Docker 映像
3-a:将 LIT 应用部署到 Cloud Run
您首先需要将最新版本的 LIT-App 设置为要部署的版本。
# Set latest version as your LIT_SERVICE_TAG.
export LIT_SERVICE_TAG=latest
# List all the public LIT GCP App server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app
设置版本标记后,您需要为服务命名。
# Set your lit service name. While 'lit-app-service' is provided as a placeholder, you can customize the service name based on your preferences.
export LIT_SERVICE_NAME=lit-app-service
之后,您可以运行以下命令将容器部署到 Cloud Run。
# Use below cmd to deploy the LIT App to Cloud Run.
gcloud run deploy $LIT_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app:$LIT_SERVICE_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--no-allow-unauthenticated
LIT 还允许您在启动服务器时添加数据集。为此,请使用 name:path 格式(例如 data_foo:/bar/data_2024.jsonl)设置 DATASETS 变量,以包含要加载的数据。数据集格式应为 .jsonl,其中每条记录包含 prompt 字段以及可选的 target 和 source 字段。如需加载多个数据集,请用英文逗号分隔。如果未设置,系统将加载 LIT 提示调试示例数据集。
# Set the dataset.
export DATASETS=[DATASETS]
通过设置 MAX_EXAMPLES,您可以设置从每个评估集中加载的最大示例数量。
# Set the max examples.
export MAX_EXAMPLES=[MAX_EXAMPLES]
然后,在部署命令中,您可以添加
--set-env-vars "DATASETS=$DATASETS" \
--set-env-vars "MAX_EXAMPLES=$MAX_EXAMPLES" \
3-b:查看 LIT 应用服务
创建 LIT 应用服务器后,您可以在 Cloud Console 的 Cloud Run 部分中找到该服务。
选择您刚刚创建的 LIT 应用服务。确保服务名称与 LIT_SERVICE_NAME 相同。
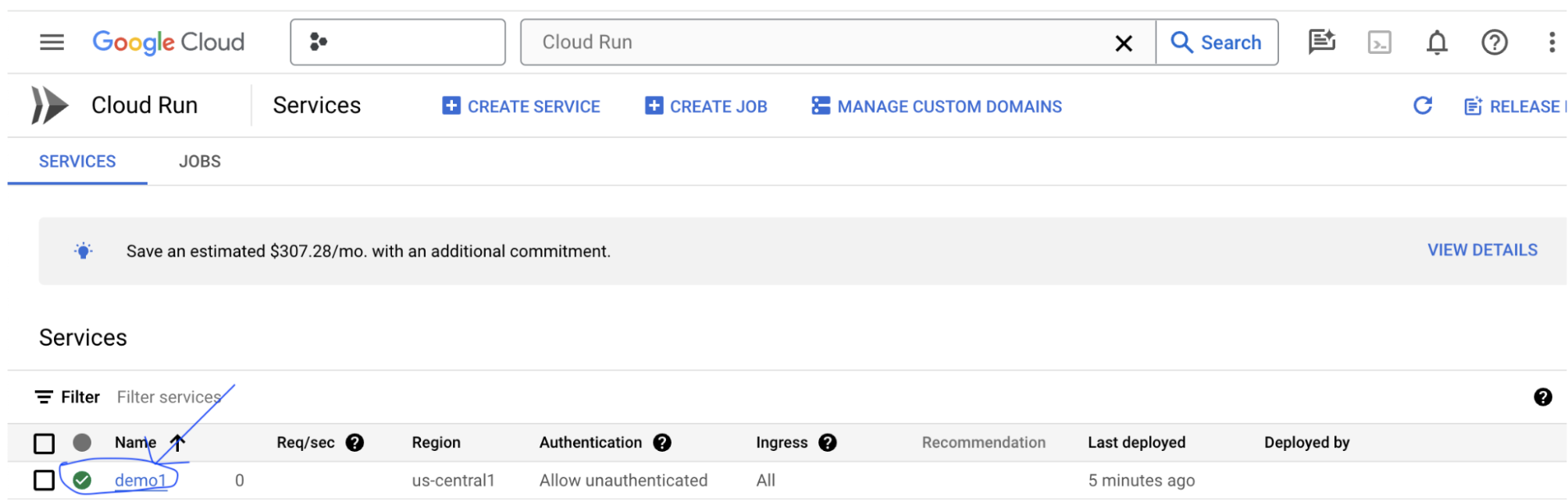
您可以点击刚刚部署的服务,找到该服务的网址。

然后,您应该能够查看 LIT 界面。如果您遇到错误,请查看“问题排查”部分。

您可以查看“日志”部分,以监控活动、查看错误消息并跟踪部署进度。
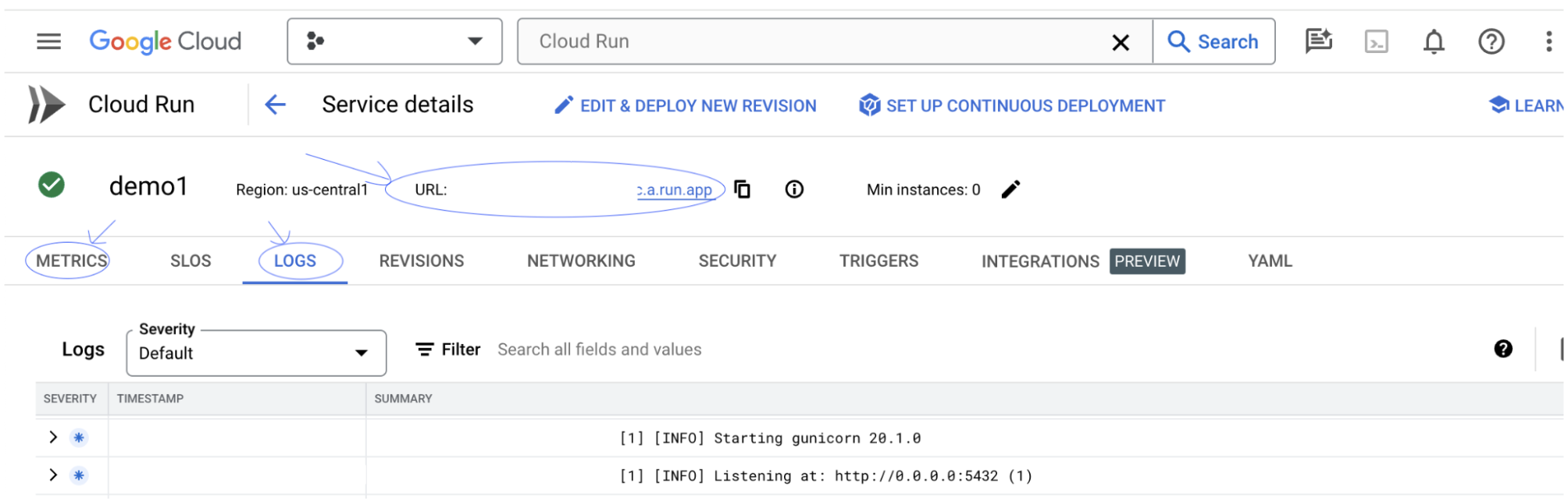
您可以查看“指标”部分,了解服务的指标。

3-c:加载数据集
在 LIT 界面中点击 Configure 选项,然后选择 Dataset。通过指定名称并提供数据集网址来加载数据集。数据集格式应为 .jsonl,其中每条记录包含 prompt 字段以及可选的 target 和 source 字段。

4. 在 Vertex AI Model Garden 中准备 Gemini 模型
Google 的 Gemini 基础模型可通过 Vertex AI API 使用。LIT 提供 VertexAIModelGarden 模型封装容器,以便使用这些模型进行生成。只需通过模型名称参数指定所需版本(例如“gemini-1.5-pro-001”)。使用这些模型的一大优势是,无需额外费力即可进行部署。默认情况下,您可以在 GCP 上立即访问 Gemini 1.0 Pro 和 Gemini 1.5 Pro 等模型,无需执行额外的配置步骤。
4-a:授予 Vertex AI 权限
如需在 GCP 中查询 Gemini,您需要向服务账号授予 Vertex AI 权限。确保服务账号名称为 Default compute service account。复制相应账号的服务账号电子邮件地址。

将服务账号电子邮件地址添加为 IAM 许可名单中具有 Vertex AI User 角色的主账号。

4-b:加载 Gemini 模型
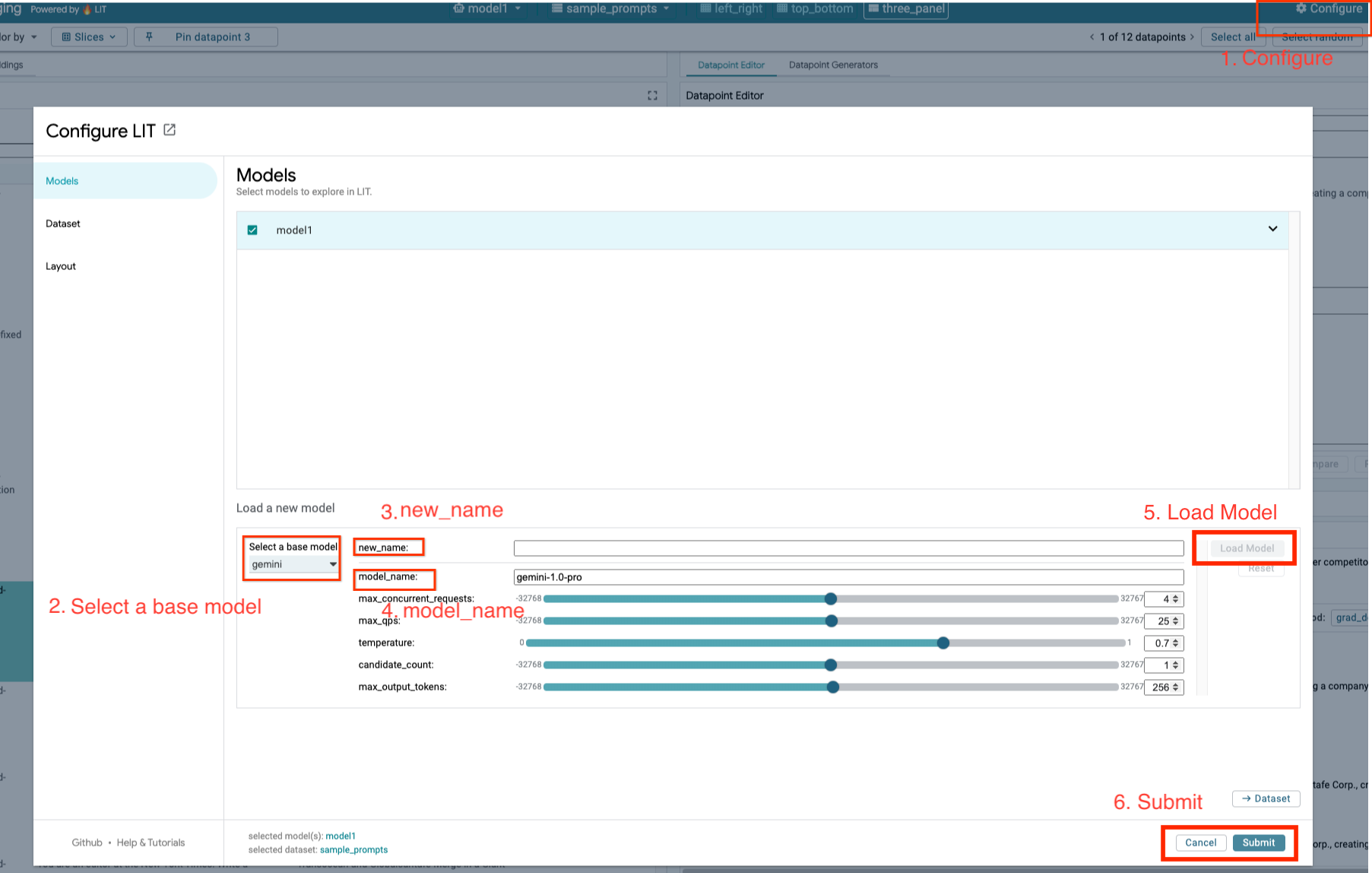
您将按照以下步骤加载 Gemini 模型并调整其参数。
- 点击 LIT 界面中的
Configure选项。
- 点击 LIT 界面中的
- 选择
Select a base model选项下的gemini选项。
- 选择
- 您需要在
new_name中为模型命名。
- 您需要在
- 将所选 Gemini 模型输入为
model_name。
- 将所选 Gemini 模型输入为
- 点击
Load Model。
- 点击
- 点击
Submit。
- 点击
5. 在 GCP 上部署自托管 LLM 模型服务器
通过 LIT 的模型服务器 Docker 映像自行托管 LLM,可让您使用 LIT 的显著性和词元化器函数,从而更深入地了解模型行为。模型服务器映像可与 KerasNLP 或 Hugging Face Transformers 模型搭配使用,包括库提供的权重和自托管权重(例如在 Google Cloud Storage 上)。
5-a:配置模型
每个容器都会加载一个模型,该模型使用环境变量进行配置。
您应通过设置 MODEL_CONFIG 来指定要加载的模型。格式应为 name:path,例如 model_foo:model_foo_path。该路径可以是网址、本地文件路径,也可以是已配置的深度学习框架的预设名称(如需了解详情,请参阅下表)。此服务器已在所有支持的 DL_FRAMEWORK 值上使用 Gemma、GPT2、Llama 和 Mistral 进行测试。其他型号应该也可以使用,但可能需要进行调整。
# Set models you want to load. While 'gemma2b is given as a placeholder, you can load your preferred model by following the instructions above.
export MODEL_CONFIG=gemma2b:gemma_2b_en
此外,LIT 模型服务器还允许使用以下命令配置各种环境变量。有关详情,请参阅下表。请注意,每个变量都必须单独设置。
# Customize the variable value as needed.
export [VARIABLE]=[VALUE]
变量 | 值 | 说明 |
DL_FRAMEWORK |
| 用于将模型权重加载到指定运行时的建模库。默认为 |
DL_RUNTIME |
| 模型运行所依赖的深度学习后端框架。此服务器加载的所有模型都将使用相同的后端,不兼容会导致错误。默认为 |
PRECISION |
| LLM 模型的浮点精度。默认为 |
BATCH_SIZE | 正整数 | 每个批次要处理的样本数。默认为 |
SEQUENCE_LENGTH | 正整数 | 输入提示和生成文本的序列长度上限。默认为 |
5-b:将模型服务器部署到 Cloud Run
您需要先将最新版本的 Model Server 设置为要部署的版本。
# Set latest as MODEL_VERSION_TAG.
export MODEL_VERSION_TAG=latest
# List all the public LIT GCP model server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server
设置版本标记后,您需要为模型服务器命名。
# Set your Service name.
export MODEL_SERVICE_NAME='gemma2b-model-server'
之后,您可以运行以下命令将容器部署到 Cloud Run。如果您未设置环境变量,系统将应用默认值。由于大多数 LLM 都需要昂贵的计算资源,因此强烈建议使用 GPU。如果您只想在 CPU 上运行(对于 GPT2 等小型模型,这完全没问题),可以移除相关实参 --gpu 1 --gpu-type nvidia-l4 --max-instances 7。
# Deploy the model service container.
gcloud beta run deploy $MODEL_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server:$MODEL_VERSION_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 7 \
--set-env-vars "MODEL_CONFIG=$MODEL_CONFIG" \
--no-allow-unauthenticated
此外,您还可以通过添加以下命令来自定义环境变量。仅包含满足您的特定需求所需的环境变量。
--set-env-vars "DL_FRAMEWORK=$DL_FRAMEWORK" \
--set-env-vars "DL_RUNTIME=$DL_RUNTIME" \
--set-env-vars "PRECISION=$PRECISION" \
--set-env-vars "BATCH_SIZE=$BATCH_SIZE" \
--set-env-vars "SEQUENCE_LENGTH=$SEQUENCE_LENGTH" \
可能需要其他环境变量才能访问某些模型。请根据需要参阅 Kaggle Hub(用于 KerasNLP 模型)和 Hugging Face Hub 中的说明。
5-c:访问模型服务器
创建模型服务器后,您可以在 GCP 项目的 Cloud Run 部分中找到已启动的服务。
选择您刚刚创建的模型服务器。确保服务名称与 MODEL_SERVICE_NAME 相同。
您可以点击刚刚部署的模型服务,找到服务网址。
您可以查看“日志”部分,以监控活动、查看错误消息并跟踪部署进度。
您可以查看“指标”部分,了解服务的指标。
5-d:加载自行托管的模型
如果您在第 3 步中代理了 LIT 服务器(请参阅问题排查部分),则需要运行以下命令来获取 GCP 身份令牌。
# Find your GCP identity token.
gcloud auth print-identity-token
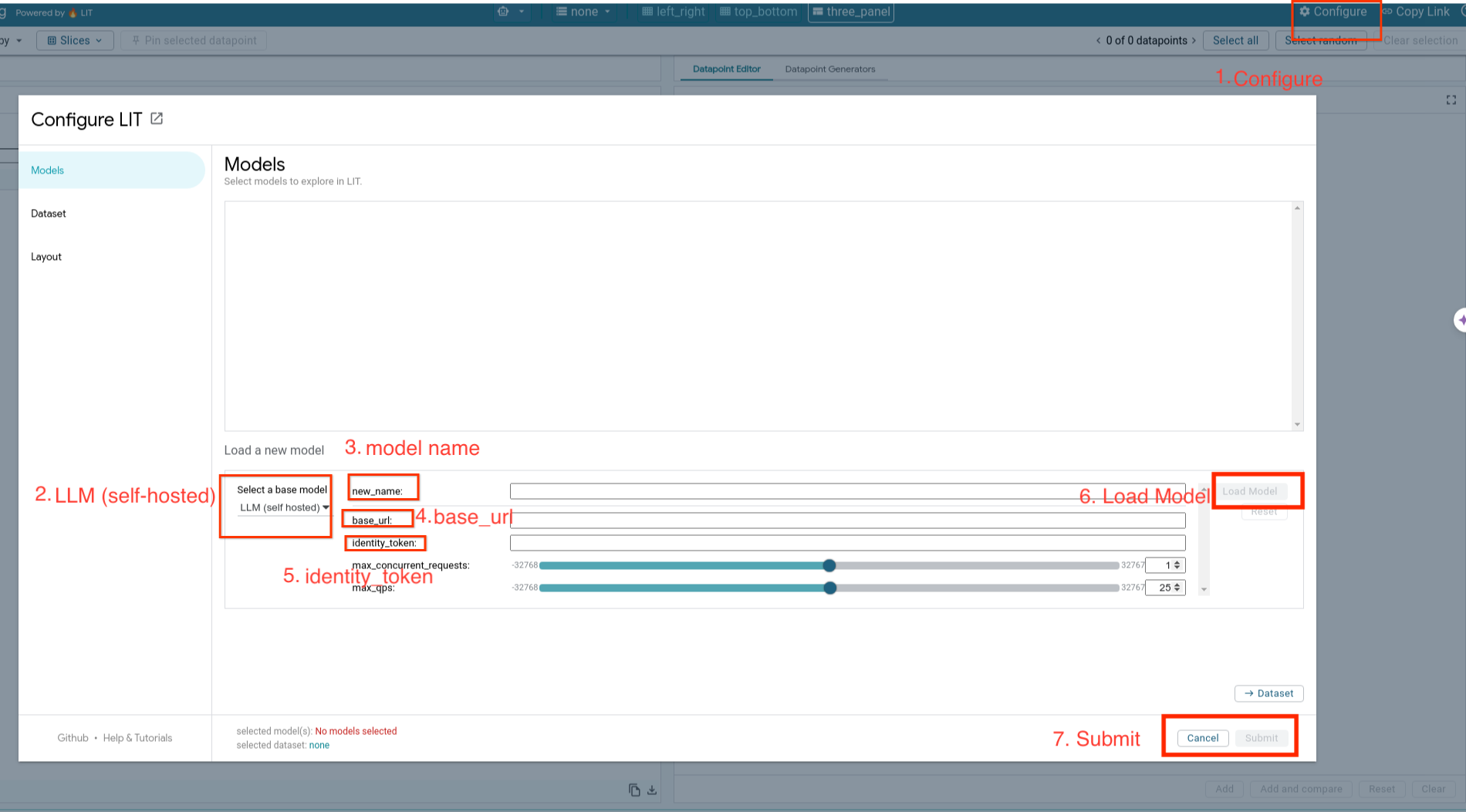
您将按照以下步骤加载自行托管的模型并调整其参数。
- 点击 LIT 界面中的
Configure选项。 - 选择
Select a base model选项下的LLM (self hosted)选项。 - 您需要在
new_name中为模型命名。 - 将模型服务器网址输入为
base_url。 - 如果您代理 LIT 应用服务器,请在
identity_token中输入获得的身份令牌(请参阅第 3 步和第 7 步)。否则,请将其留空。 - 点击
Load Model。 - 点击
Submit。
6. 在 GCP 上与 LIT 互动
LIT 提供了一组丰富的功能,可帮助您调试和了解模型行为。您可以执行简单的操作,例如在框中输入文字来查询模型并查看模型预测,也可以使用 LIT 的一系列强大功能深入检查模型,包括:
6-a:通过 LIT 查询模型
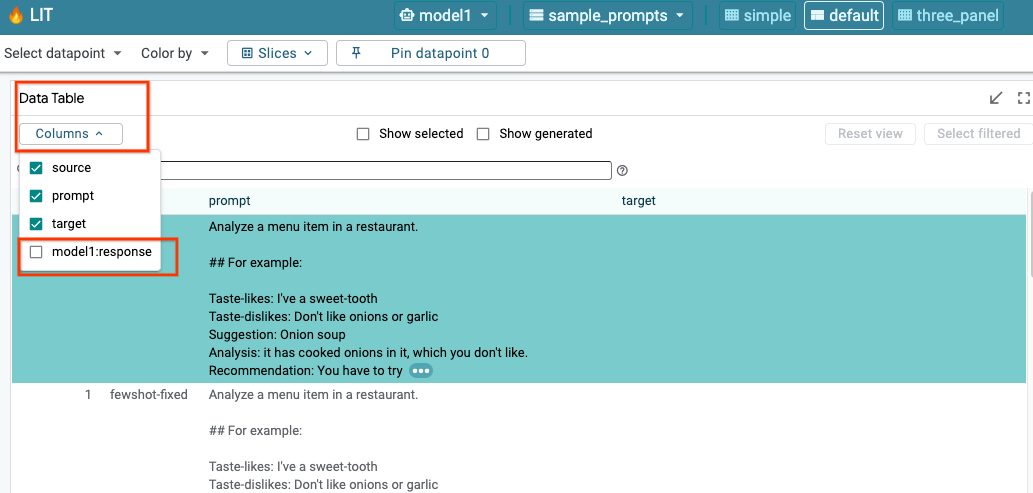
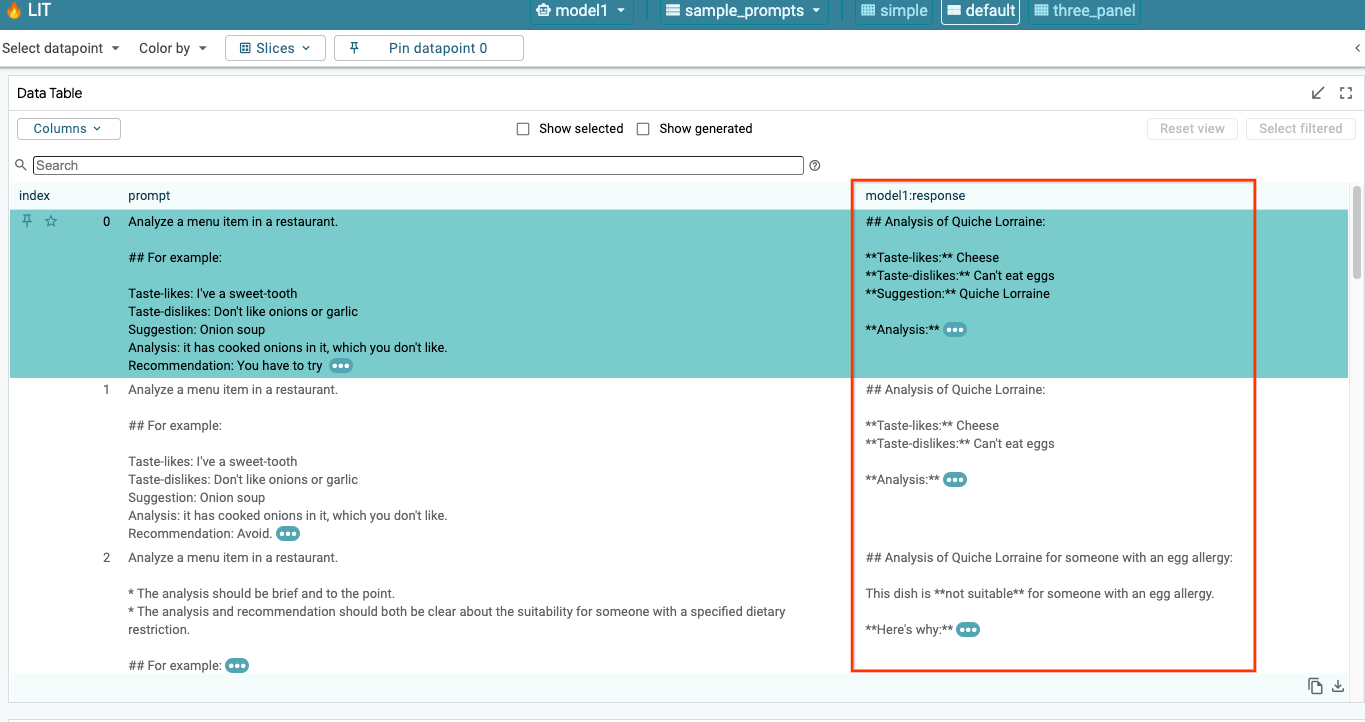
LIT 会在加载模型和数据集后自动查询数据集。您可以通过选择列中的回答来查看每个模型的回答。
6-b:使用序列显著性技术
目前,LIT 上的序列显著性技术仅支持自托管模型。
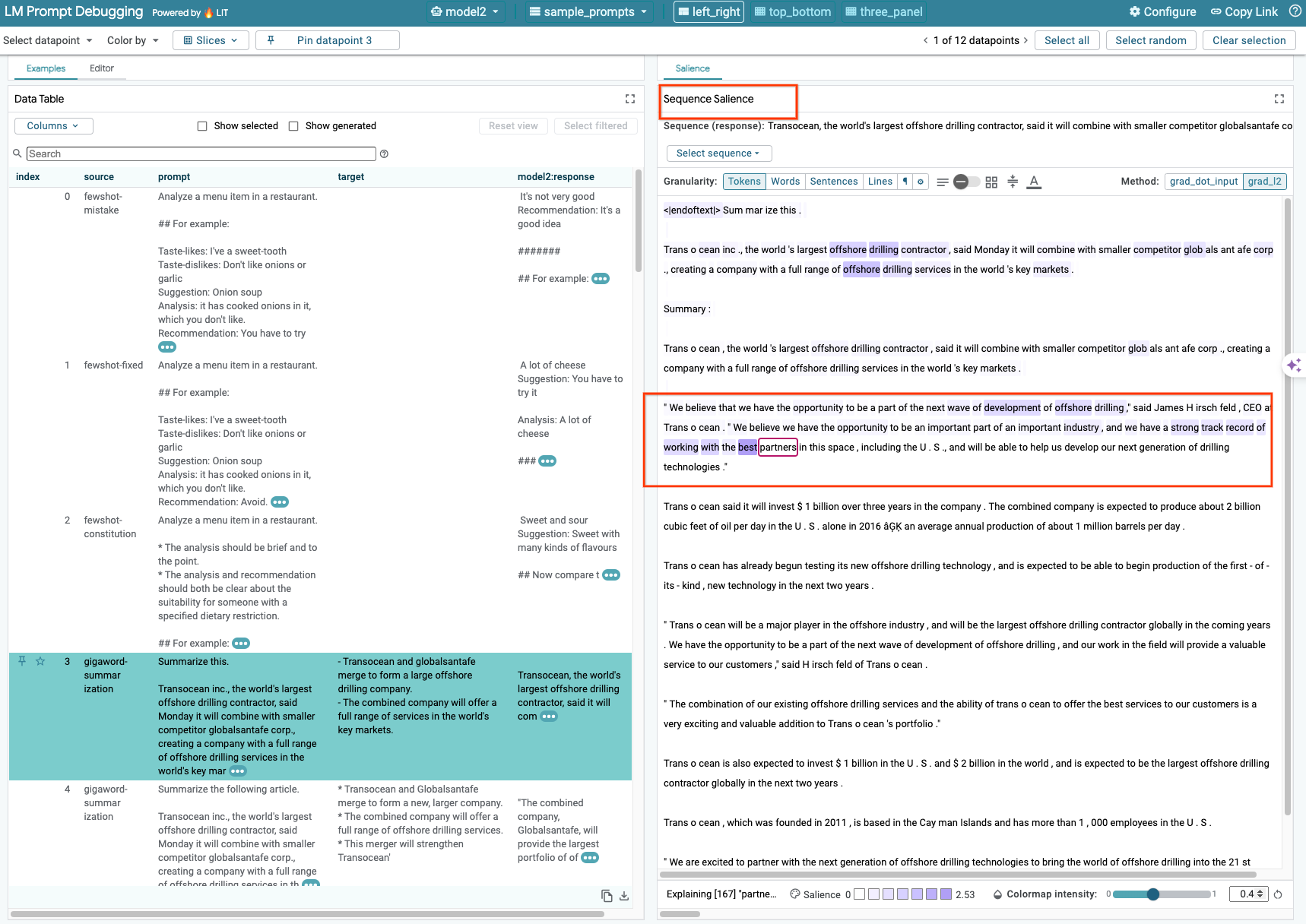
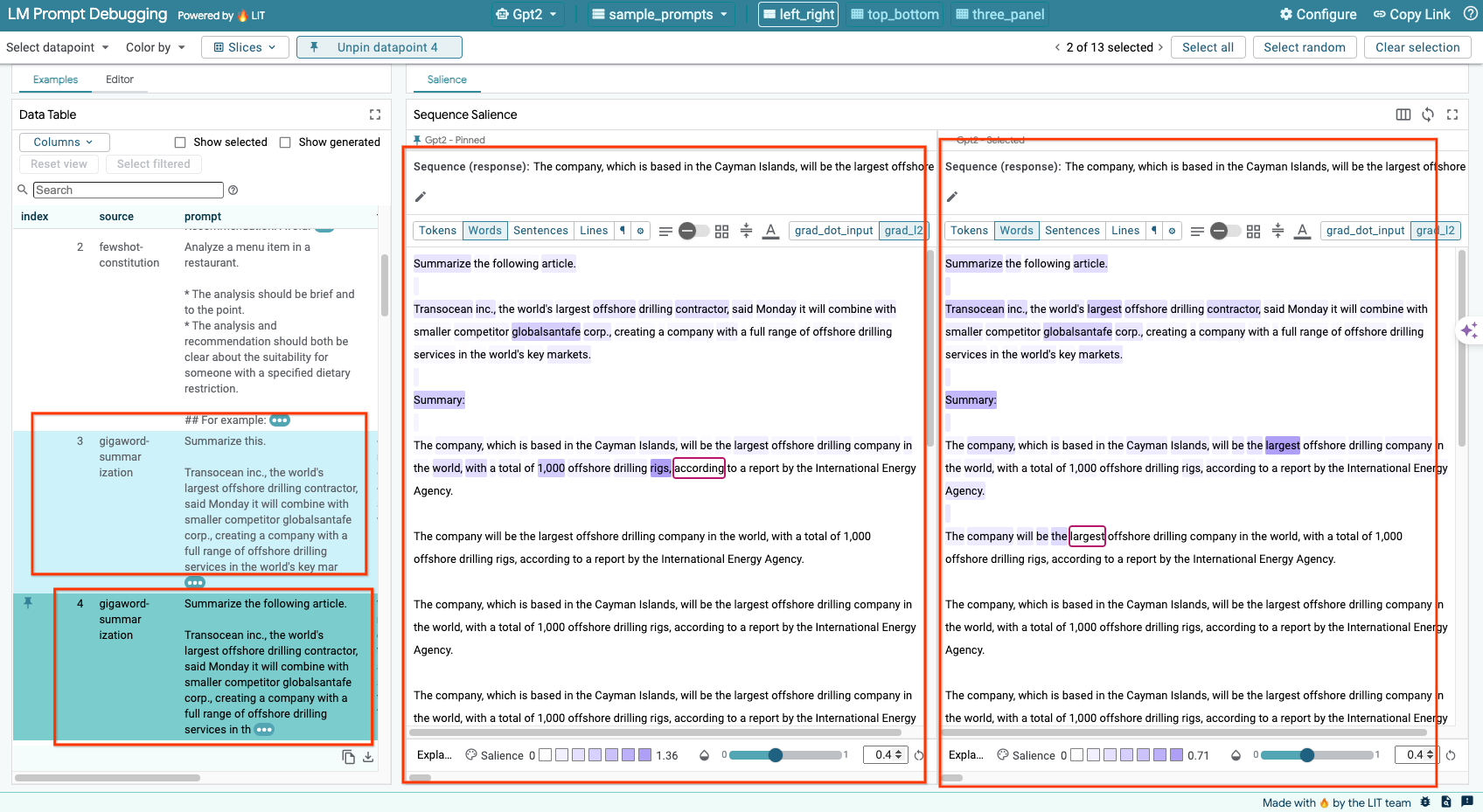
序列显著性是一种可视化工具,可突出显示提示中对给定输出最重要的部分,从而帮助调试 LLM 提示。如需详细了解序列显著性,请查看完整教程,详细了解如何使用此功能。
如需访问显著性结果,请点击提示或回答中的任意输入或输出,系统随即会显示显著性结果。
6-c:手动修改提示和目标
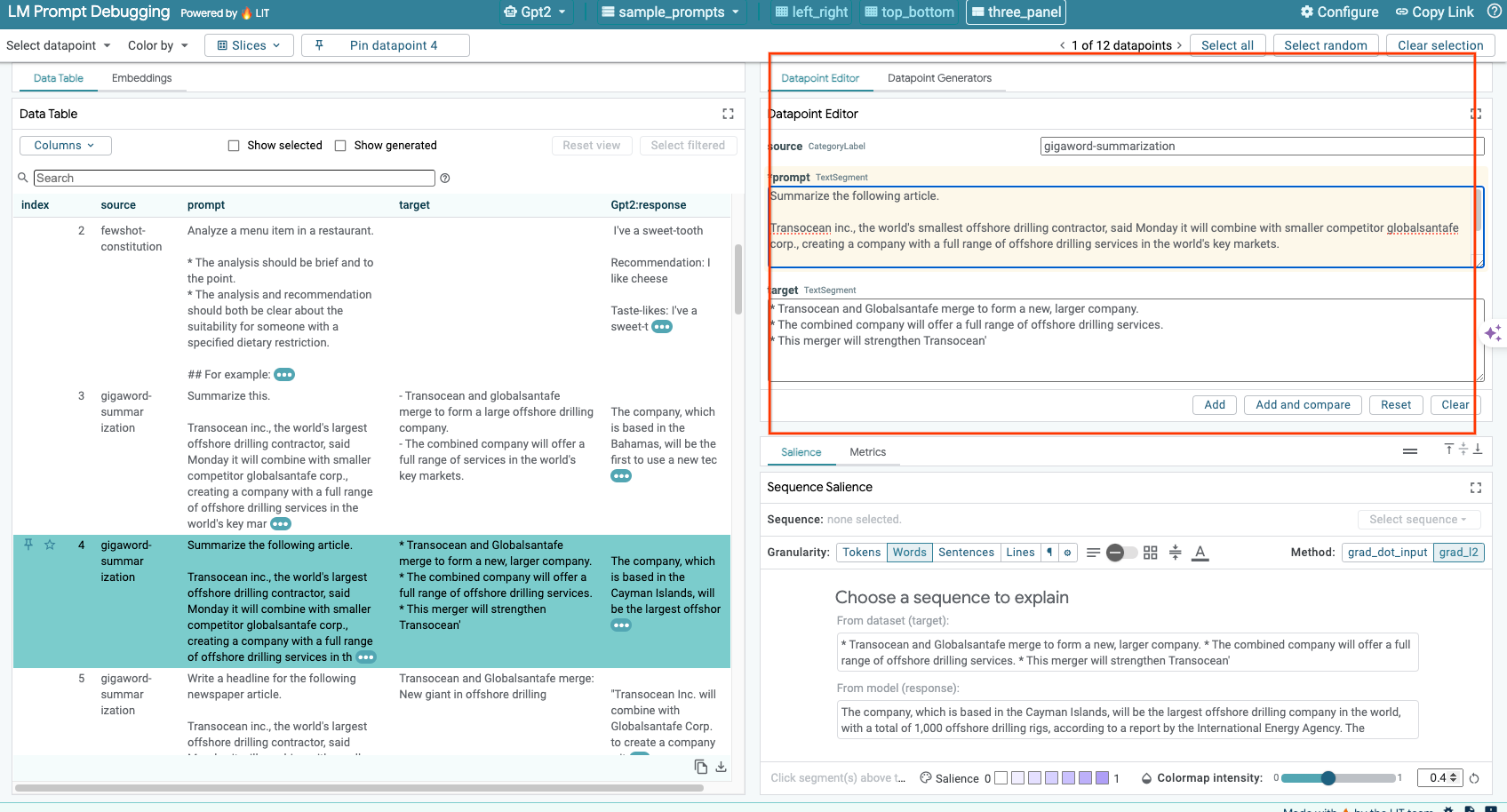
借助 LIT,您可以手动修改现有数据点的任何 prompt 和 target。点击 Add 后,新输入内容将添加到数据集中。
6-d:并排比较提示
借助 LIT,您可以并排比较原始示例和编辑后的示例中的提示。您可以手动修改示例,并同时查看原始版本和修改版本的预测结果以及序列显著性分析。您可以修改每个数据点的提示,LIT 将通过查询模型生成相应的回答。
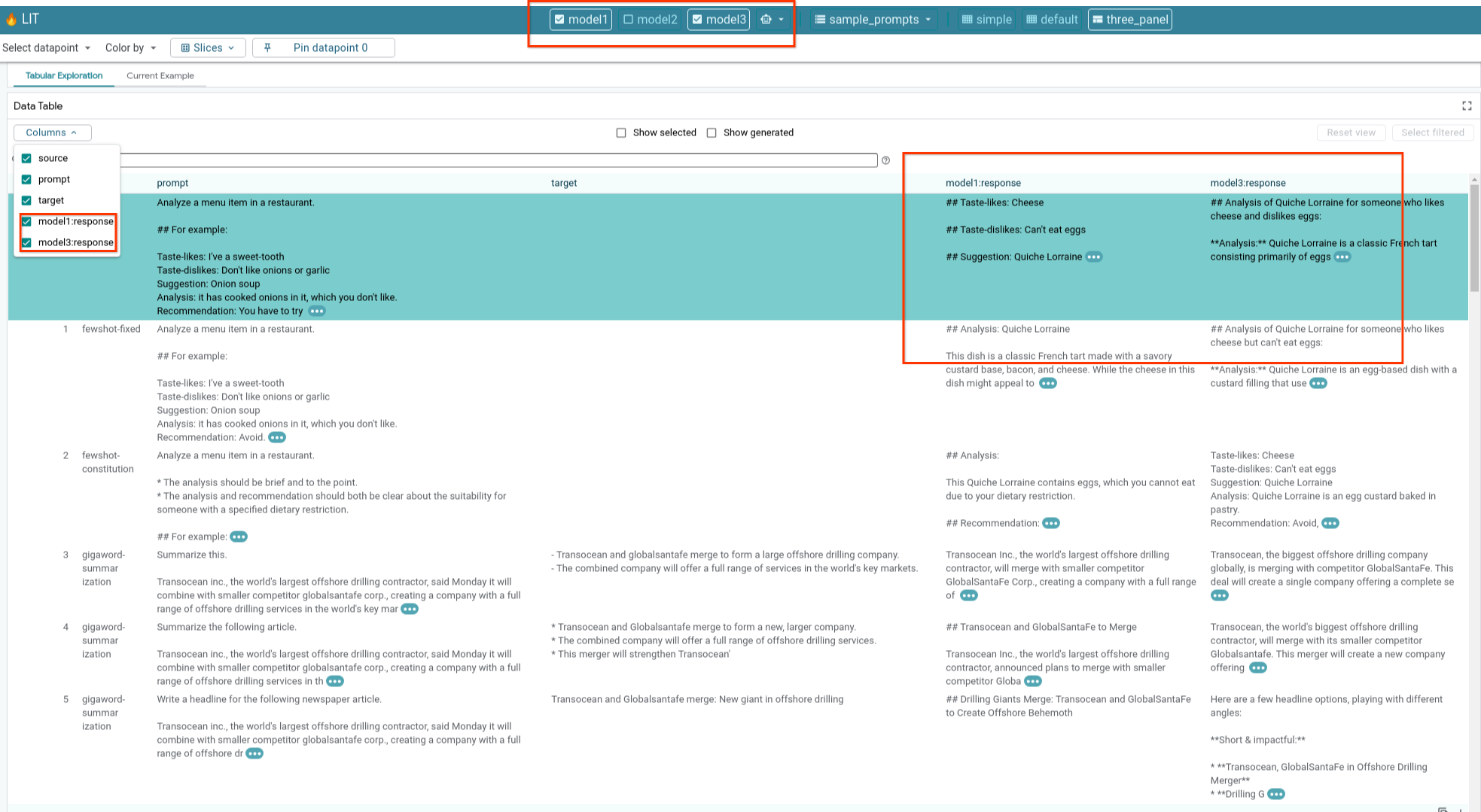
6-e:并排比较多个模型
借助 LIT,您可以并排对照比较模型在单个文本生成和评分示例以及特定指标的汇总示例方面的表现。通过查询各种已加载的模型,您可以轻松比较它们回答的差异。
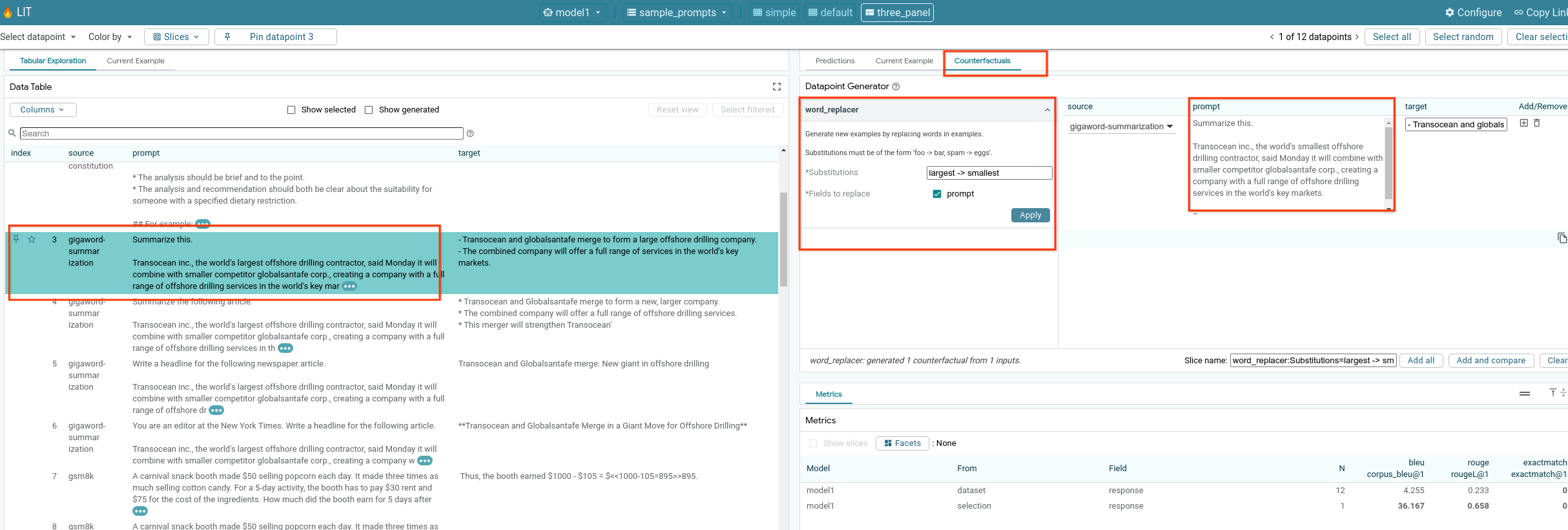
6-f:自动反事实生成器
您可以使用自动反事实生成器创建替代输入,并立即查看模型在这些输入上的表现。
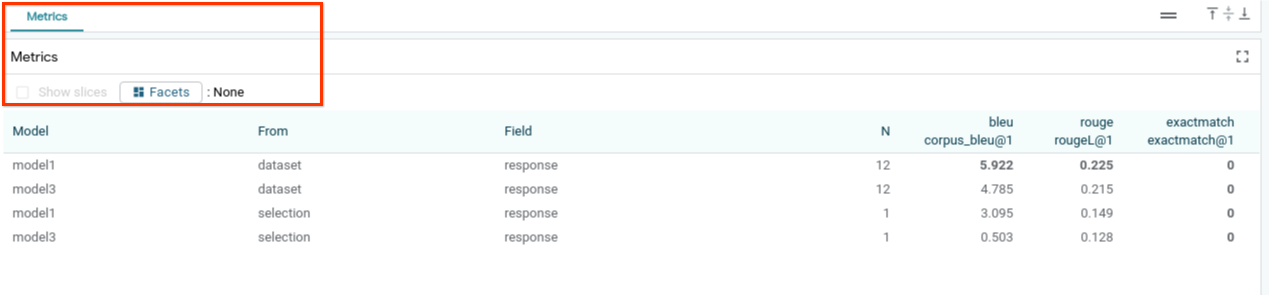
6-g:评估模型性能
您可以针对整个数据集或任何过滤或选择的示例子集,使用指标(目前支持文本生成的 BLEU 和 ROUGE 分数)评估模型性能。
7. 问题排查
7-a:潜在的访问权限问题和解决方案
由于在部署到 Cloud Run 时会应用 --no-allow-unauthenticated,因此您可能会遇到如下所示的禁止错误。

您可以通过两种方式访问 LIT App 服务。
1. 代理到本地服务
您可以使用以下命令将服务代理到本地主机。
# Proxy the service to local host.
gcloud run services proxy $LIT_SERVICE_NAME
然后,您应该能够通过点击代理服务链接来访问 LIT 服务器。
2. 直接对用户进行身份验证
您可以点击此链接来验证用户身份,从而允许用户直接访问 LIT App 服务。此方法还可以让一组用户访问该服务。对于涉及与多人协作的开发,此选项更有效。
7-b:检查以确保模型服务器已成功启动
为确保模型服务器已成功启动,您可以通过发送请求直接查询模型服务器。模型服务器提供三个端点:predict、tokenize 和 salience。请确保在请求中同时提供 prompt 字段和 target 字段。
# Query the model server predict endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/predict -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server tokenize endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/tokenize -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server salience endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/salience -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
如果您遇到访问权限问题,请参阅上文第 7-a 部分。
8. 恭喜
恭喜您完成此 Codelab!放松一下!
清理
如需清理实验,请删除为实验创建的所有 Google Cloud 服务。使用 Google Cloud Shell 运行以下命令。
如果 Google Cloud 连接因不活动而断开,请按照之前的步骤重置变量。
# Delete the LIT App Service.
gcloud run services delete $LIT_SERVICE_NAME
如果您启动了模型服务器,还需要删除模型服务器。
# Delete the Model Service.
gcloud run services delete $MODEL_SERVICE_NAME
深入阅读
通过以下材料继续学习 LIT 工具功能:
- Gemma:链接
- LIT 开源代码库:Git 代码库
- LIT 论文:ArXiv
- LIT 提示调试论文:ArXiv
- LIT 功能视频演示:YouTube
- LIT 提示调试演示:YouTube
- Responsible GenAI Toolkit:链接
联系
如果您对此 Codelab 有任何疑问或遇到任何问题,请在 GitHub 上与我们联系。
许可
此作品已获得 知识共享署名 4.0 通用许可授权。