
1. 개요
이 실습에서는 Google Cloud Platform (GCP)에 LIT 애플리케이션 서버를 배포하여 Vertex AI Gemini 파운데이션 모델 및 자체 호스팅 서드 파티 대규모 언어 모델 (LLM)과 상호작용하는 방법을 자세히 안내합니다. 또한 프롬프트 디버깅 및 모델 해석을 위해 LIT UI를 사용하는 방법에 관한 안내도 포함되어 있습니다.
이 실습을 따르면 사용자는 다음 작업을 수행하는 방법을 알게 됩니다.
- GCP에서 LIT 서버를 구성합니다.
- LIT 서버를 Vertex AI Gemini 모델 또는 기타 자체 호스팅 LLM에 연결합니다.
- LIT UI를 활용하여 프롬프트를 분석, 디버그, 해석하여 모델 성능과 통계를 개선하세요.
LIT란 무엇인가요?
LIT는 텍스트, 이미지, 테이블 형식 데이터를 지원하는 대화형의 시각적 모델 이해 도구입니다. 독립형 서버로 실행하거나 Google Colab, Jupyter, Google Cloud Vertex AI와 같은 노트북 환경에서 실행할 수 있습니다. LIT는 PyPI 및 GitHub에서 제공됩니다.
원래 분류 및 회귀 모델을 이해하기 위해 빌드되었으며, 최근 업데이트를 통해 LLM 프롬프트를 디버깅할 수 있는 도구가 추가되어 사용자, 모델, 시스템 콘텐츠가 생성 동작에 미치는 영향을 살펴볼 수 있습니다.
Vertex AI 및 Model Garden이란 무엇인가요?
Vertex AI는 ML 모델과 AI 애플리케이션을 학습시키고 배포하며, AI 기반 애플리케이션에서 사용할 LLM을 맞춤설정할 수 있는 머신러닝 (ML) 플랫폼입니다. Vertex AI는 데이터 엔지니어링, 데이터 과학, ML 엔지니어링 워크플로를 결합합니다. 이를 통해 팀은 공통의 도구 모음을 사용하여 공동으로 작업하고 Google Cloud의 이점을 활용하여 애플리케이션을 확장할 수 있습니다.
Vertex Model Garden은 Google 독점 정보를 검색, 테스트, 맞춤설정, 배포하고 서드 파티 모델 및 애셋을 선택할 수 있도록 지원하는 ML 모델 라이브러리입니다.
실습 내용
Google Cloud Shell 및 Cloud Run을 사용하여 LIT의 사전 빌드 이미지에서 Docker 컨테이너를 배포합니다.
Cloud Run은 GPU를 비롯한 Google의 확장 가능한 인프라에서 직접 컨테이너를 실행할 수 있게 해 주는 관리형 컴퓨팅 플랫폼입니다.
데이터 세트
데모에서는 기본적으로 LIT 프롬프트 디버깅 샘플 데이터 세트를 사용하며, UI를 통해 자체 데이터 세트를 로드할 수도 있습니다.
시작하기 전에
이 참조 가이드에는 Google Cloud 프로젝트가 필요합니다. 새 프로젝트를 만들거나 기존에 만든 프로젝트를 선택할 수 있습니다.
2. Google Cloud 콘솔 및 Cloud Shell 실행
이 단계에서는 Google Cloud 콘솔을 실행하고 Google Cloud Shell을 사용합니다.
2-a: Google Cloud 콘솔 실행
브라우저를 실행하고 Google Cloud 콘솔로 이동합니다.
Google Cloud 콘솔은 Google Cloud 리소스를 빠르게 관리할 수 있는 강력하고 안전한 웹 관리 인터페이스입니다. 언제 어디서나 사용할 수 있는 DevOps 도구입니다.
2-b: Google Cloud Shell 실행
Cloud Shell은 브라우저를 사용해 어디서나 액세스할 수 있는 온라인 개발 및 운영 환경입니다. gcloud 명령줄 도구, kubectl 등의 유틸리티가 미리 로드된 온라인 터미널을 사용해 리소스를 관리할 수 있습니다. 온라인 Cloud Shell 편집기를 사용하여 클라우드 기반 앱을 개발, 빌드, 디버그, 배포할 수도 있습니다. Cloud Shell은 개발자가 바로 사용할 수 있는 온라인 환경으로, 즐겨 사용하는 도구 세트가 사전 설치되어 있으며 5GB의 영구 저장공간이 제공됩니다. 다음 단계에서는 명령 프롬프트를 사용합니다.
다음 스크린샷에서 파란색으로 표시된 메뉴 바의 오른쪽 상단에 있는 아이콘을 사용하여 Google Cloud Shell을 실행합니다.

페이지 하단에 Bash 셸이 있는 터미널이 표시됩니다.

2-c: Google Cloud 프로젝트 설정
gcloud 명령어를 사용하여 프로젝트 ID와 프로젝트 리전을 설정해야 합니다.
# Set your GCP Project ID.
gcloud config set project your-project-id
# Set your GCP Project Region.
gcloud config set run/region your-project-region
3. Cloud Run으로 LIT 앱 서버 Docker 이미지 배포
3-a: Cloud Run에 LIT 앱 배포
먼저 최신 버전의 LIT-App을 배포할 버전으로 설정해야 합니다.
# Set latest version as your LIT_SERVICE_TAG.
export LIT_SERVICE_TAG=latest
# List all the public LIT GCP App server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app
버전 태그를 설정한 후에는 서비스 이름을 지정해야 합니다.
# Set your lit service name. While 'lit-app-service' is provided as a placeholder, you can customize the service name based on your preferences.
export LIT_SERVICE_NAME=lit-app-service
그런 다음 다음 명령어를 실행하여 컨테이너를 Cloud Run에 배포할 수 있습니다.
# Use below cmd to deploy the LIT App to Cloud Run.
gcloud run deploy $LIT_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app:$LIT_SERVICE_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--no-allow-unauthenticated
LIT를 사용하면 서버를 시작할 때 데이터 세트를 추가할 수도 있습니다. 이렇게 하려면 DATASETS 변수를 설정하여 로드하려는 데이터를 포함합니다. 형식은 name:path(예: data_foo:/bar/data_2024.jsonl)을 사용합니다. 데이터 세트 형식은 .jsonl이어야 하며 각 레코드에는 prompt와 선택적 target 및 source 필드가 포함됩니다. 여러 데이터 세트를 로드하려면 쉼표로 구분하세요. 설정하지 않으면 LIT 프롬프트 디버깅 샘플 데이터 세트가 로드됩니다.
# Set the dataset.
export DATASETS=[DATASETS]
MAX_EXAMPLES를 설정하면 각 평가 세트에서 로드할 최대 예시 수를 설정할 수 있습니다.
# Set the max examples.
export MAX_EXAMPLES=[MAX_EXAMPLES]
그런 다음 배포 명령어에 다음을 추가할 수 있습니다.
--set-env-vars "DATASETS=$DATASETS" \
--set-env-vars "MAX_EXAMPLES=$MAX_EXAMPLES" \
3-b: LIT 앱 서비스 보기
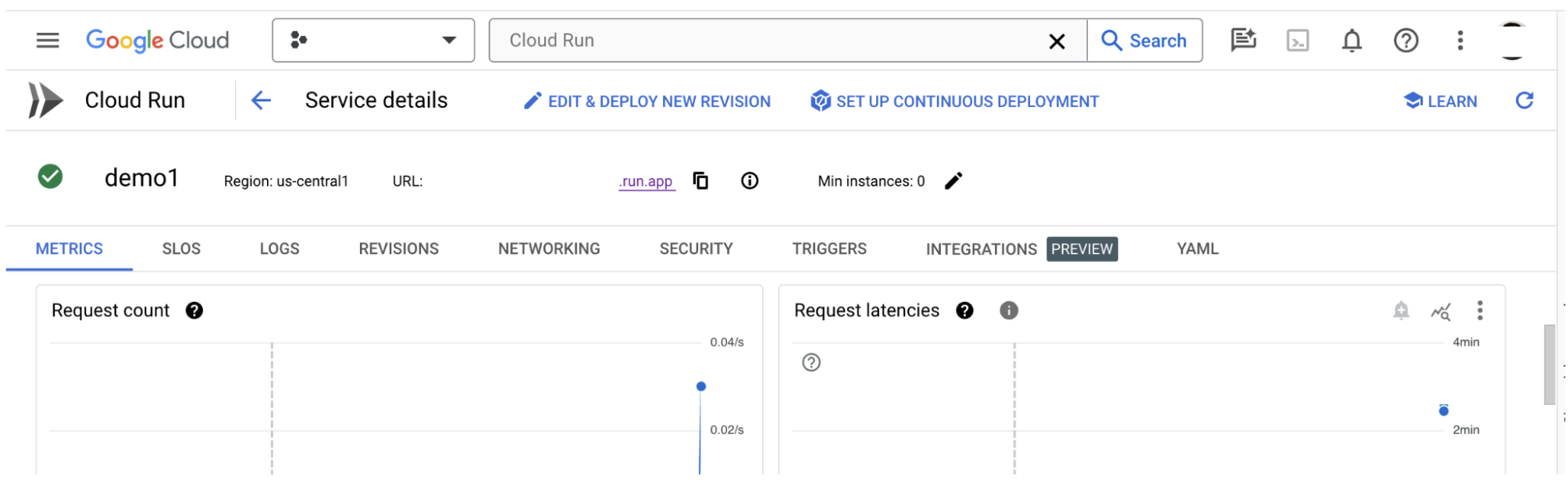
LIT 앱 서버를 만든 후 Cloud Console의 Cloud Run 섹션에서 서비스를 찾을 수 있습니다.
방금 만든 LIT 앱 서비스를 선택합니다. 서비스 이름이 LIT_SERVICE_NAME와 동일한지 확인합니다.
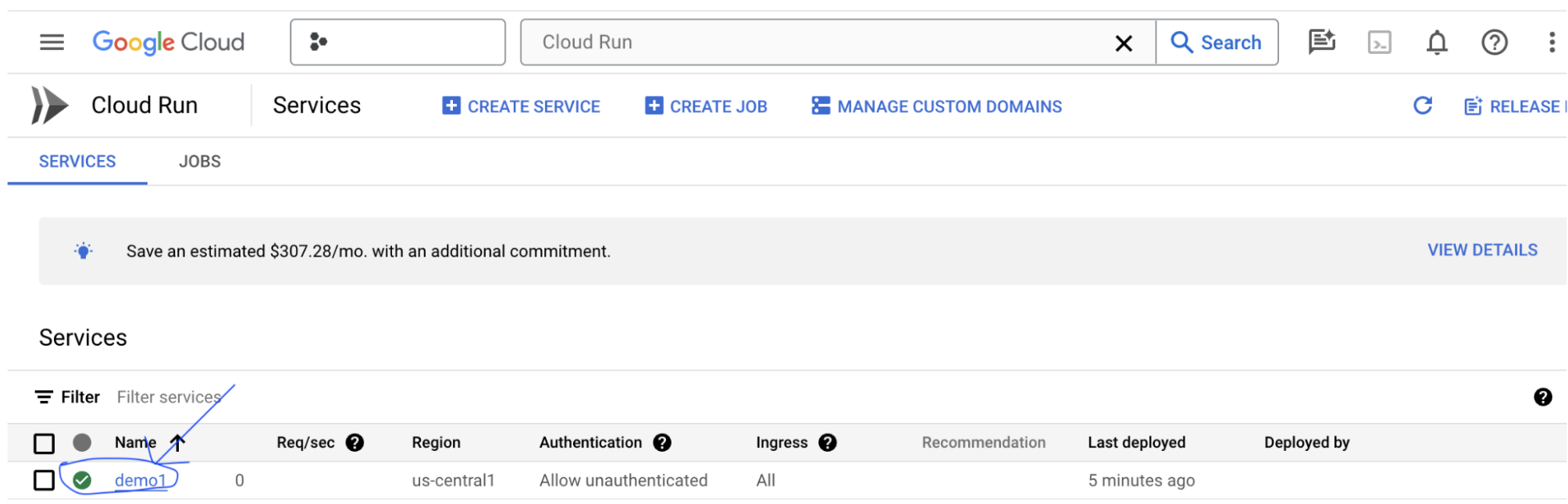
방금 배포한 서비스를 클릭하면 서비스 URL을 확인할 수 있습니다.
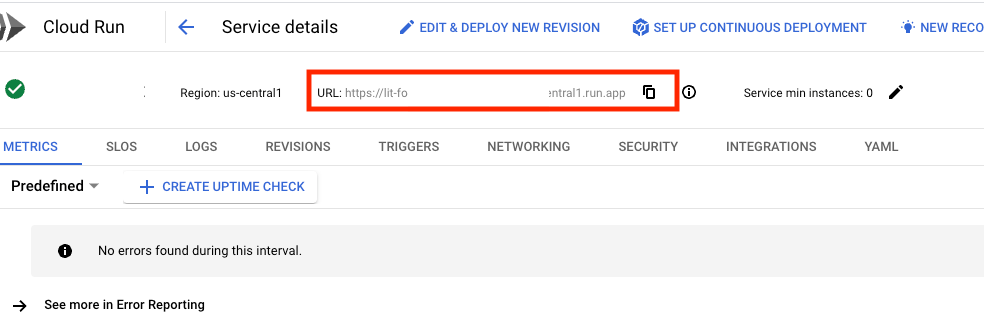
그러면 LIT UI를 볼 수 있습니다. 오류가 발생하면 문제 해결 섹션을 확인하세요.
로그 섹션을 확인하여 활동을 모니터링하고, 오류 메시지를 확인하고, 배포 진행 상황을 추적할 수 있습니다.
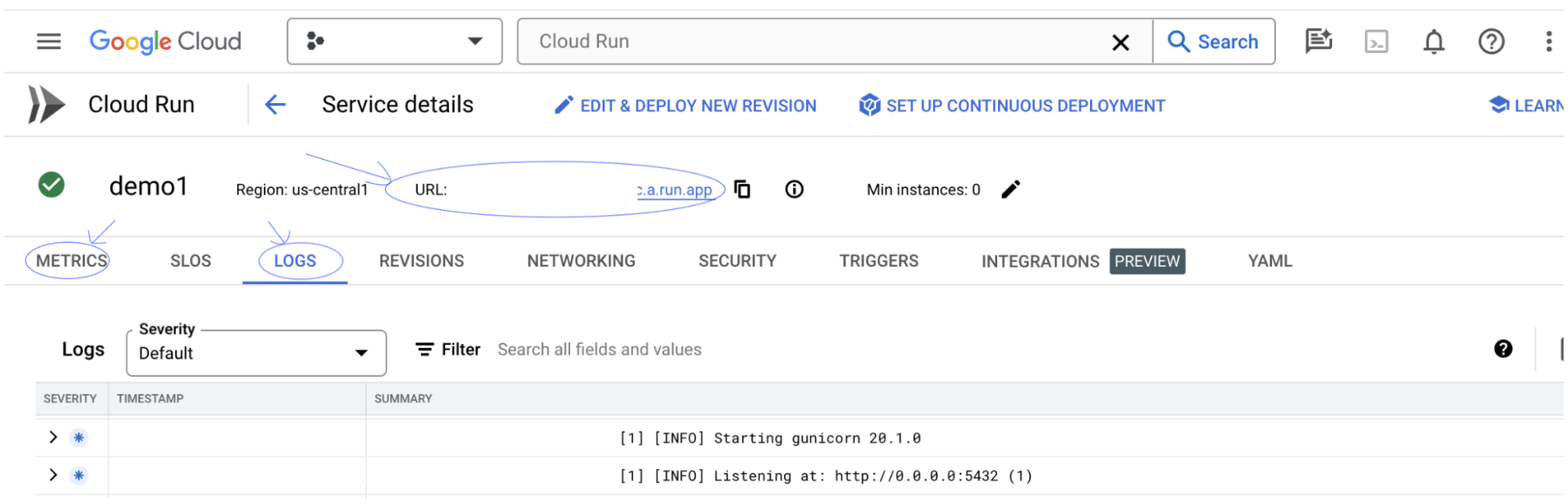
측정항목 섹션에서 서비스의 측정항목을 확인할 수 있습니다.
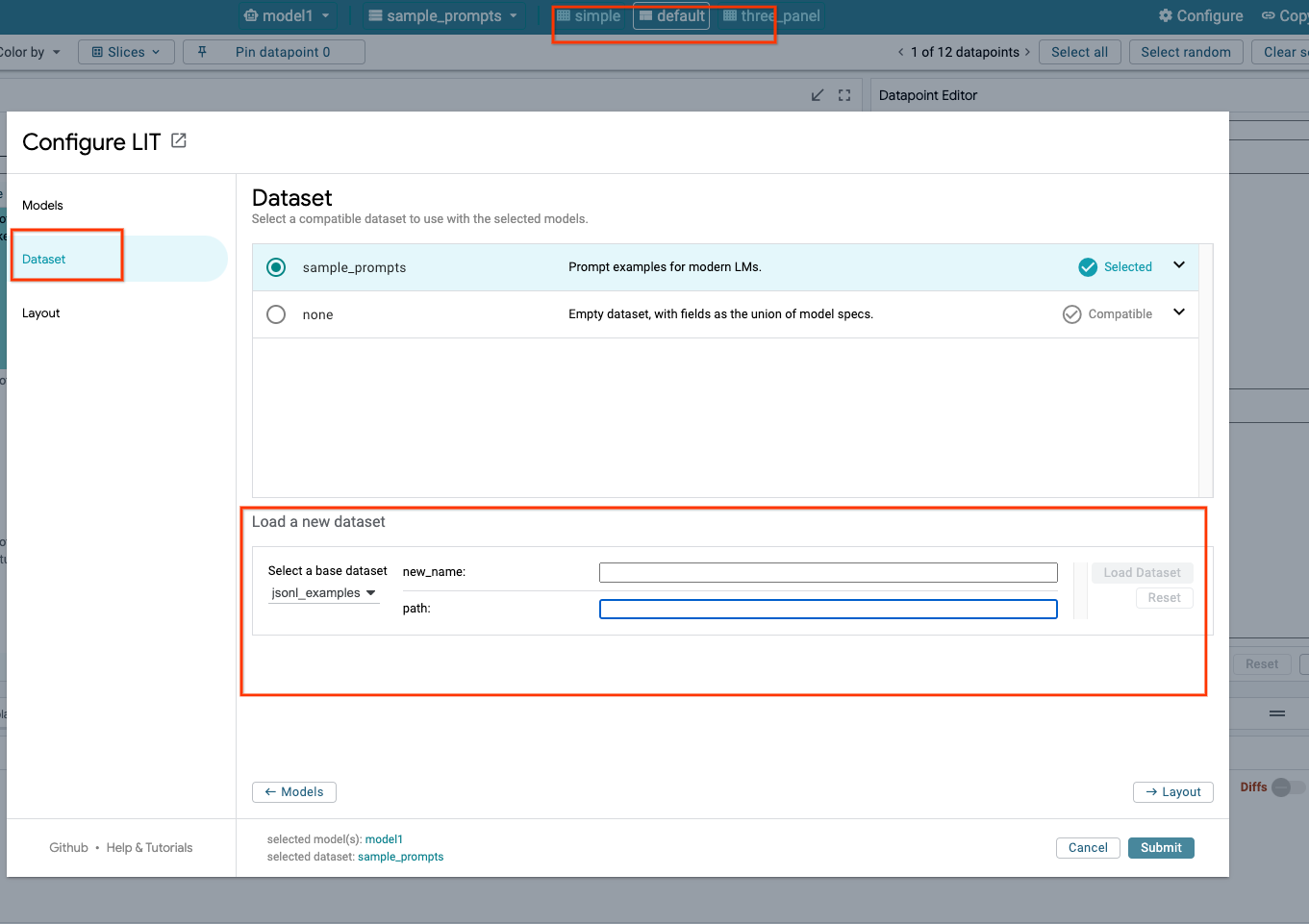
3-c: 데이터 세트 로드
LIT UI에서 Configure 옵션을 클릭하고 Dataset을 선택합니다. 이름을 지정하고 데이터 세트 URL을 제공하여 데이터 세트를 로드합니다. 데이터 세트 형식은 .jsonl이어야 하며 각 레코드에는 prompt와 선택적 target 및 source 필드가 포함됩니다.
4. Vertex AI Model Garden에서 Gemini 모델 준비
Google의 Gemini 기반 모델은 Vertex AI API에서 사용할 수 있습니다. LIT는 이러한 모델을 생성에 사용할 수 있도록 VertexAIModelGarden 모델 래퍼를 제공합니다. 모델 이름 매개변수를 통해 원하는 버전 (예: 'gemini-1.5-pro-001')을 지정하면 됩니다. 이러한 모델을 사용하면 배포를 위해 추가 작업을 할 필요가 없다는 것이 큰 장점입니다. 기본적으로 GCP에서 Gemini 1.0 Pro 및 Gemini 1.5 Pro와 같은 모델에 즉시 액세스할 수 있으므로 추가 구성 단계가 필요하지 않습니다.
4-a: Vertex AI 권한 부여
GCP에서 Gemini를 쿼리하려면 서비스 계정에 Vertex AI 권한을 부여해야 합니다. 서비스 계정 이름이 Default compute service account인지 확인합니다. 계정의 서비스 계정 이메일을 복사합니다.
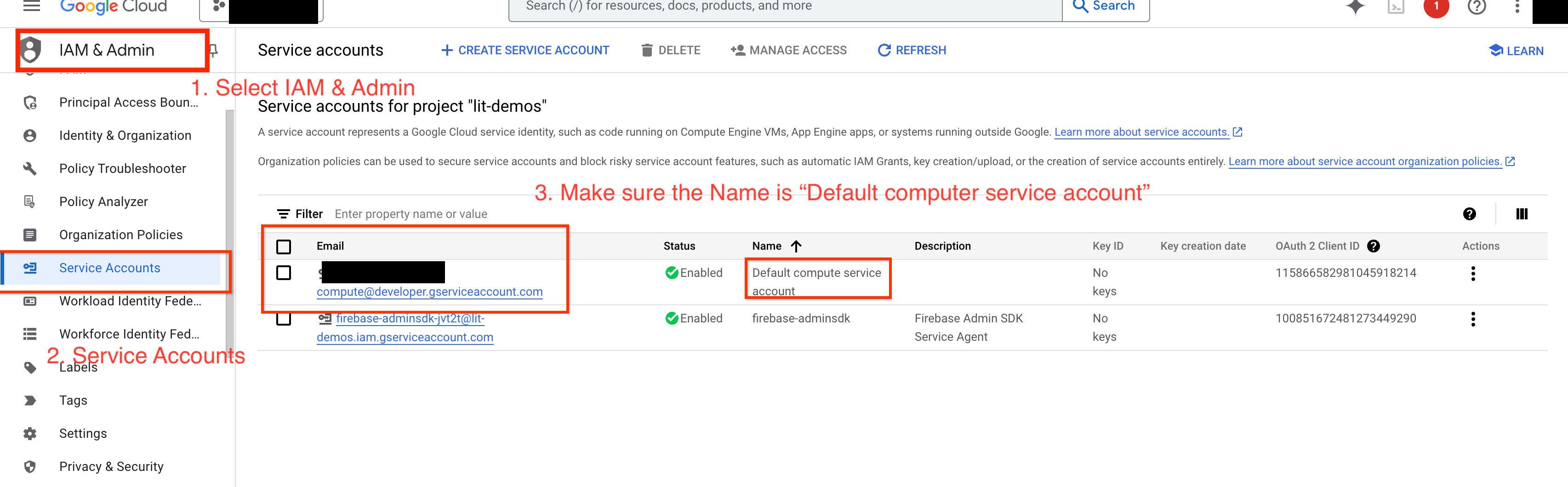
IAM 허용 목록에 서비스 계정 이메일을 Vertex AI User 역할이 있는 주 구성원으로 추가합니다.

4-b: Gemini 모델 로드
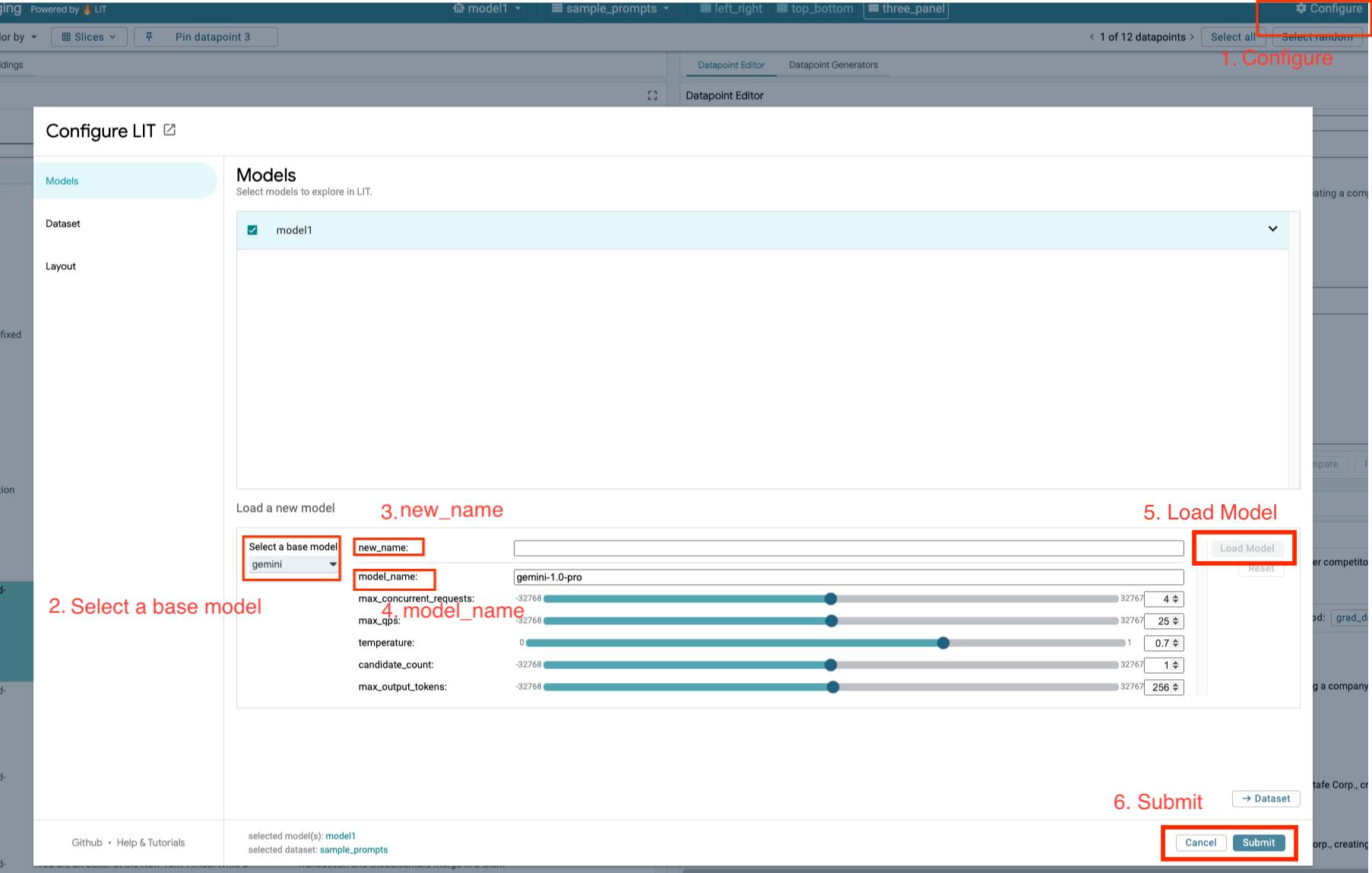
아래 단계에 따라 Gemini 모델을 로드하고 매개변수를 조정합니다.
- LIT UI에서
Configure옵션을 클릭합니다.
- LIT UI에서
Select a base model옵션에서gemini옵션을 선택합니다.
new_name에서 모델 이름을 지정해야 합니다.
- 선택한 Gemini 모델을
model_name로 입력합니다.
- 선택한 Gemini 모델을
Load Model을 클릭합니다.
Submit을 클릭합니다.
5. GCP에 자체 호스팅 LLM 모델 서버 배포
LIT의 모델 서버 Docker 이미지를 사용하여 LLM을 자체 호스팅하면 LIT의 salience 및 토큰화 함수를 사용하여 모델 동작에 대한 더 깊은 통계를 얻을 수 있습니다. 모델 서버 이미지는 라이브러리 제공 및 자체 호스팅 가중치(예: Google Cloud Storage)를 비롯한 KerasNLP 또는 Hugging Face Transformers 모델과 호환됩니다.
5-a: 모델 구성
각 컨테이너는 환경 변수를 사용하여 구성된 모델 하나를 로드합니다.
MODEL_CONFIG를 설정하여 로드할 모델을 지정해야 합니다. 형식은 name:path이어야 합니다(예: model_foo:model_foo_path). 경로는 URL, 로컬 파일 경로 또는 구성된 딥 러닝 프레임워크의 사전 설정 이름일 수 있습니다 (자세한 내용은 다음 표 참고). 이 서버는 지원되는 모든 DL_FRAMEWORK 값에서 Gemma, GPT2, Llama, Mistral로 테스트됩니다. 다른 모델도 작동하지만 조정이 필요할 수 있습니다.
# Set models you want to load. While 'gemma2b is given as a placeholder, you can load your preferred model by following the instructions above.
export MODEL_CONFIG=gemma2b:gemma_2b_en
또한 LIT 모델 서버를 사용하면 아래 명령어를 사용하여 다양한 환경 변수를 구성할 수 있습니다. 자세한 내용은 표를 참고하세요. 각 변수는 개별적으로 설정해야 합니다.
# Customize the variable value as needed.
export [VARIABLE]=[VALUE]
변수 | 값 | 설명 |
DL_FRAMEWORK |
| 지정된 런타임에 모델 가중치를 로드하는 데 사용되는 모델링 라이브러리입니다. 기본값은 |
DL_RUNTIME |
| 모델이 실행되는 딥 러닝 백엔드 프레임워크입니다. 이 서버에서 로드된 모든 모델은 동일한 백엔드를 사용하며, 비호환성으로 인해 오류가 발생합니다. 기본값은 |
정밀도 |
| LLM 모델의 부동 소수점 정밀도입니다. 기본값은 |
BATCH_SIZE | 양의 정수 | 배치당 처리할 예시 수입니다. 기본값은 |
SEQUENCE_LENGTH | 양의 정수 | 입력 프롬프트와 생성된 텍스트의 최대 시퀀스 길이입니다. 기본값은 |
5-b: Cloud Run에 모델 서버 배포
먼저 배포할 버전으로 최신 버전의 모델 서버를 설정해야 합니다.
# Set latest as MODEL_VERSION_TAG.
export MODEL_VERSION_TAG=latest
# List all the public LIT GCP model server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server
버전 태그를 설정한 후 모델 서버의 이름을 지정해야 합니다.
# Set your Service name.
export MODEL_SERVICE_NAME='gemma2b-model-server'
그런 다음 다음 명령어를 실행하여 컨테이너를 Cloud Run에 배포할 수 있습니다. 환경 변수를 설정하지 않으면 기본값이 적용됩니다. 대부분의 LLM에는 비용이 많이 드는 컴퓨팅 리소스가 필요하므로 GPU를 사용하는 것이 좋습니다. CPU에서만 실행하려면 (GPT2와 같은 소형 모델에 적합) 관련 인수 --gpu 1 --gpu-type nvidia-l4 --max-instances 7를 삭제하면 됩니다.
# Deploy the model service container.
gcloud beta run deploy $MODEL_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server:$MODEL_VERSION_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 7 \
--set-env-vars "MODEL_CONFIG=$MODEL_CONFIG" \
--no-allow-unauthenticated
다음 명령어를 추가하여 환경 변수를 맞춤설정할 수도 있습니다. 특정 요구사항에 필요한 환경 변수만 포함합니다.
--set-env-vars "DL_FRAMEWORK=$DL_FRAMEWORK" \
--set-env-vars "DL_RUNTIME=$DL_RUNTIME" \
--set-env-vars "PRECISION=$PRECISION" \
--set-env-vars "BATCH_SIZE=$BATCH_SIZE" \
--set-env-vars "SEQUENCE_LENGTH=$SEQUENCE_LENGTH" \
특정 모델에 액세스하려면 추가 환경 변수가 필요할 수 있습니다. Kaggle Hub (KerasNLP 모델에 사용) 및 Hugging Face Hub의 안내를 적절히 참고하세요.
5-c: 모델 서버 액세스
모델 서버를 만든 후 시작된 서비스는 GCP 프로젝트의 Cloud Run 섹션에서 확인할 수 있습니다.
방금 만든 모델 서버를 선택합니다. 서비스 이름이 MODEL_SERVICE_NAME와 동일한지 확인합니다.
방금 배포한 모델 서비스를 클릭하면 서비스 URL을 확인할 수 있습니다.
로그 섹션을 확인하여 활동을 모니터링하고, 오류 메시지를 확인하고, 배포 진행 상황을 추적할 수 있습니다.
측정항목 섹션에서 서비스의 측정항목을 확인할 수 있습니다.
5-d: 자체 호스팅 모델 로드
3단계에서 LIT 서버를 프록시하는 경우 (문제 해결 섹션 참고) 다음 명령어를 실행하여 GCP ID 토큰을 가져와야 합니다.
# Find your GCP identity token.
gcloud auth print-identity-token
아래 단계에 따라 자체 호스팅 모델을 로드하고 매개변수를 조정합니다.
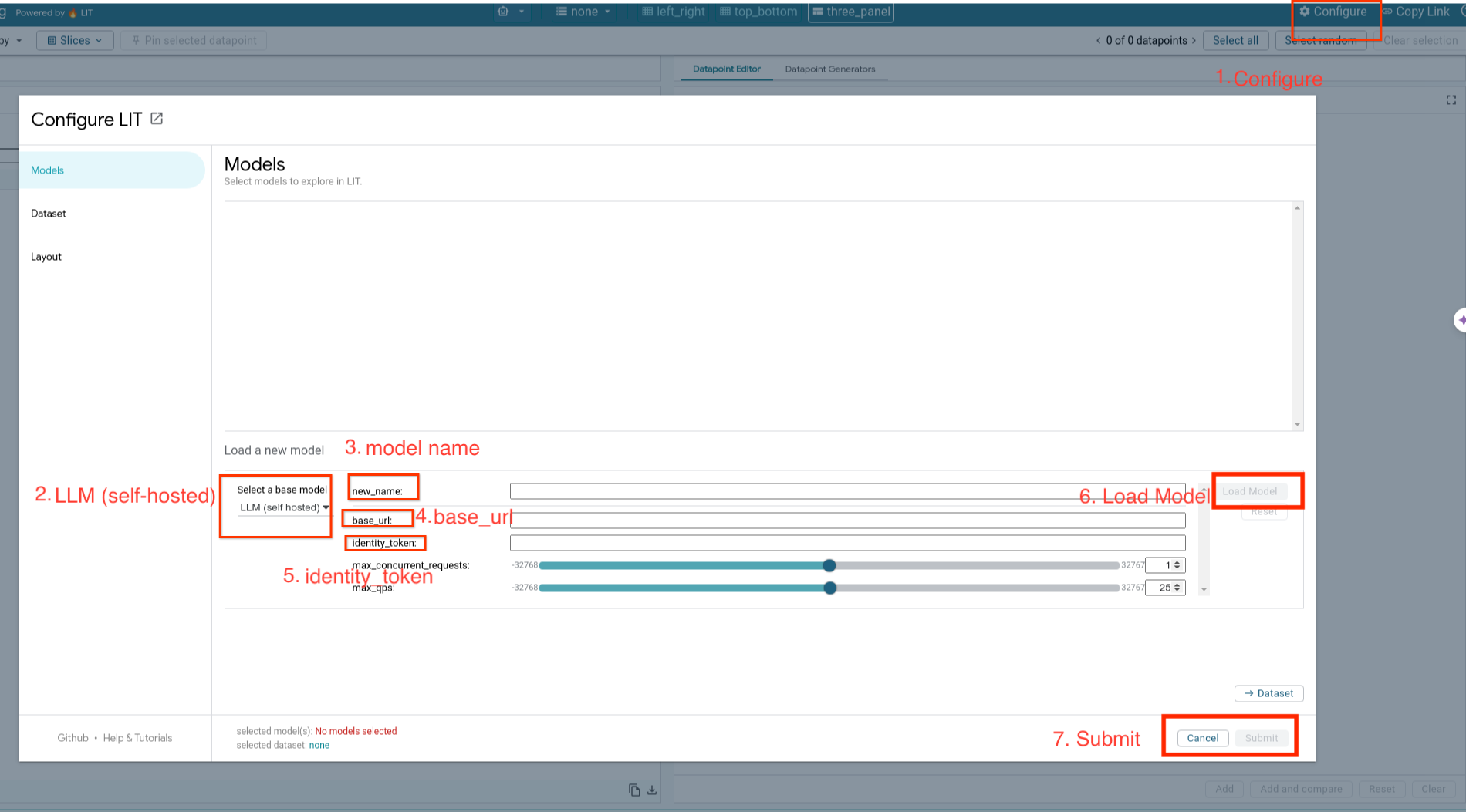
- LIT UI에서
Configure옵션을 클릭합니다. Select a base model옵션에서LLM (self hosted)옵션을 선택합니다.new_name에서 모델 이름을 지정해야 합니다.- 모델 서버 URL을
base_url로 입력합니다. - LIT 앱 서버를 프록시하는 경우 획득한 ID 토큰을
identity_token에 입력합니다 (3단계 및 7단계 참고). 그렇지 않으면 비워 둡니다. Load Model을 클릭합니다.Submit을 클릭합니다.
6. GCP에서 LIT와 상호작용
LIT는 모델 동작을 디버그하고 이해하는 데 도움이 되는 다양한 기능을 제공합니다. 상자에 텍스트를 입력하고 모델 예측을 확인하여 모델을 쿼리하는 것과 같은 간단한 작업을 수행하거나 다음을 비롯한 LIT의 강력한 기능 모음으로 모델을 심층적으로 검사할 수 있습니다.
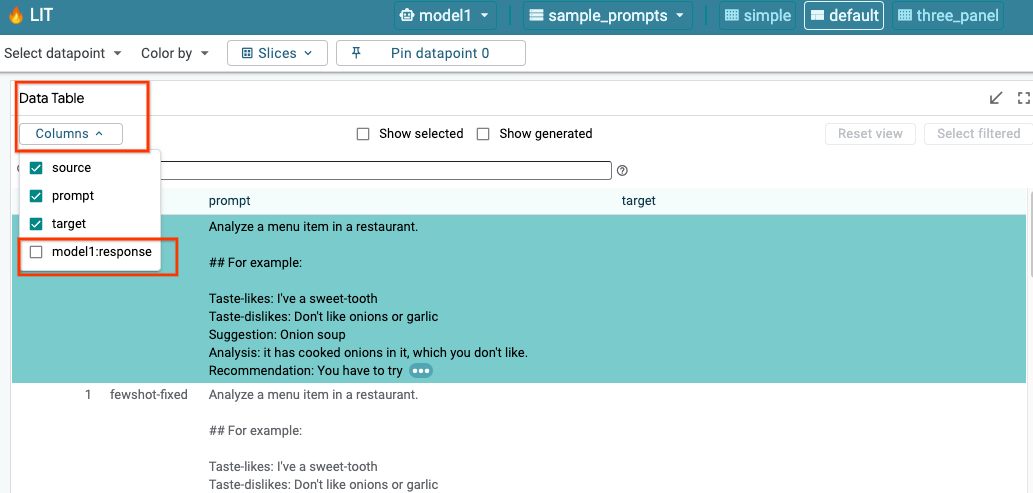
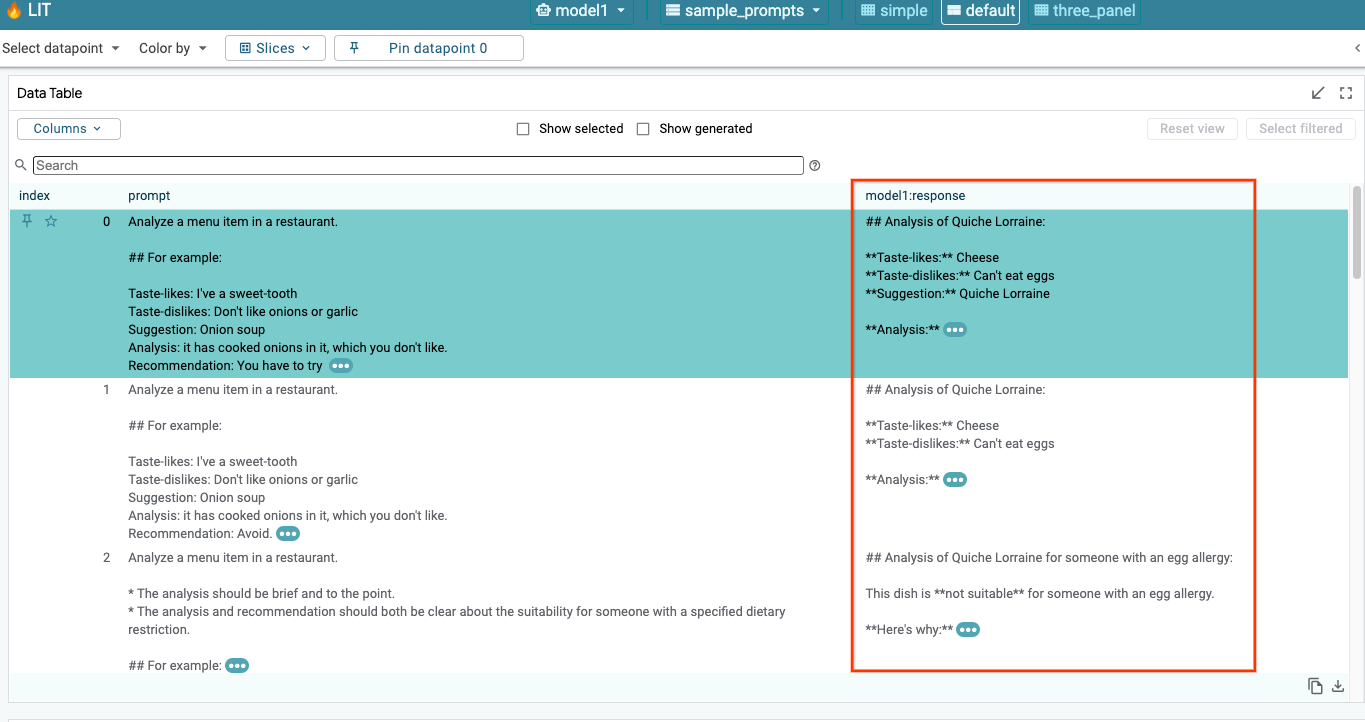
6-a: LIT를 통해 모델 쿼리
LIT는 모델과 데이터 세트가 로드된 후 데이터 세트를 자동으로 쿼리합니다. 열에서 대답을 선택하여 각 모델의 대답을 확인할 수 있습니다.
6-b: 시퀀스 현저성 기법 사용
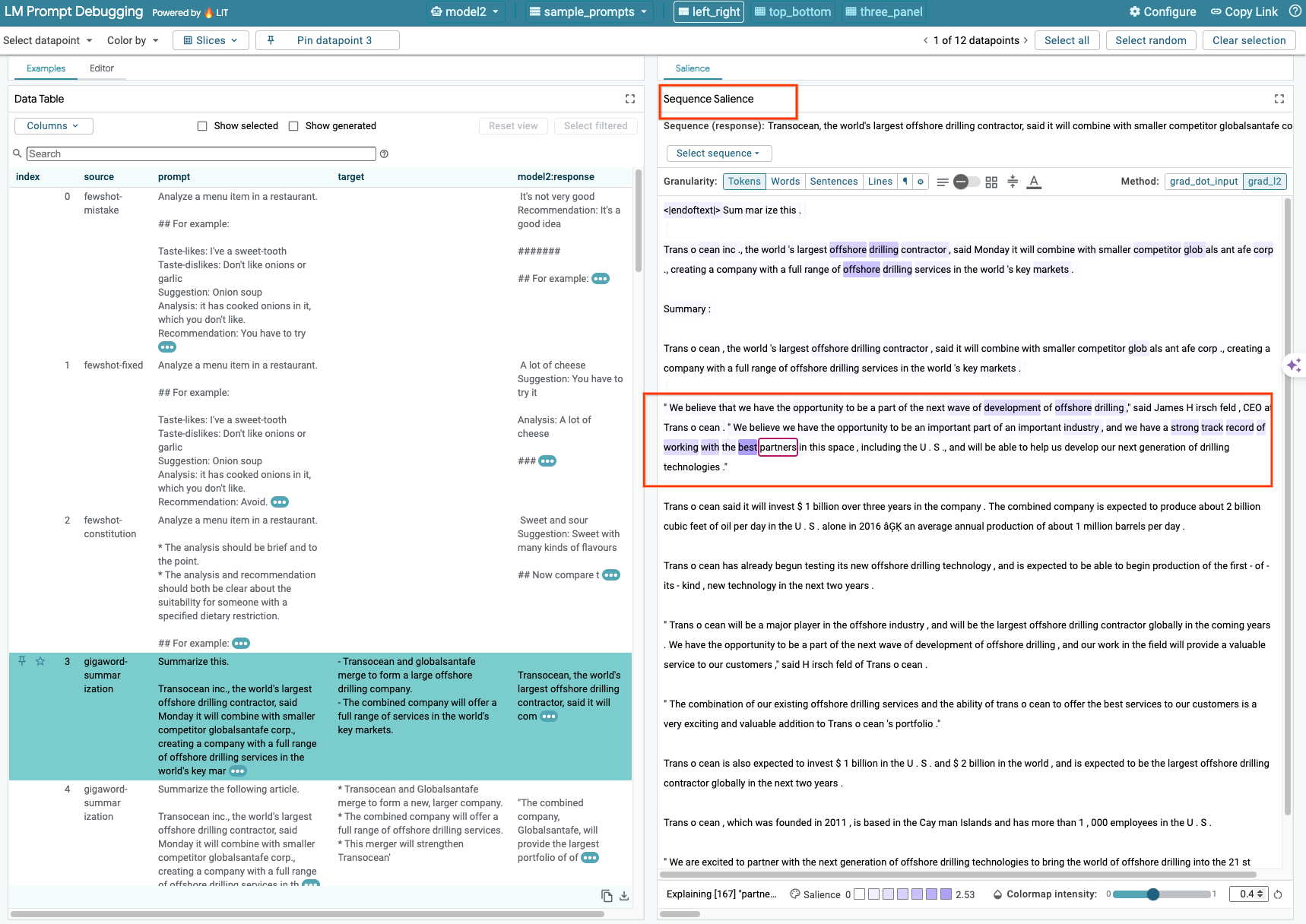
현재 LIT의 시퀀스 현저성 기법은 자체 호스팅 모델만 지원합니다.
시퀀스 현저성은 프롬프트의 어떤 부분이 특정 출력에 가장 중요한지 강조 표시하여 LLM 프롬프트를 디버그하는 데 도움이 되는 시각적 도구입니다. 시퀀스 강조에 관한 자세한 내용은 전체 튜토리얼에서 이 기능을 사용하는 방법을 참고하세요.
유의성 결과에 액세스하려면 프롬프트 또는 대답에서 입력 또는 출력을 클릭하면 유의성 결과가 표시됩니다.
6-c: 프롬프트 및 타겟 수동 수정
LIT를 사용하면 기존 데이터 포인트의 prompt 및 target를 수동으로 수정할 수 있습니다. Add을 클릭하면 새 입력이 데이터 세트에 추가됩니다.
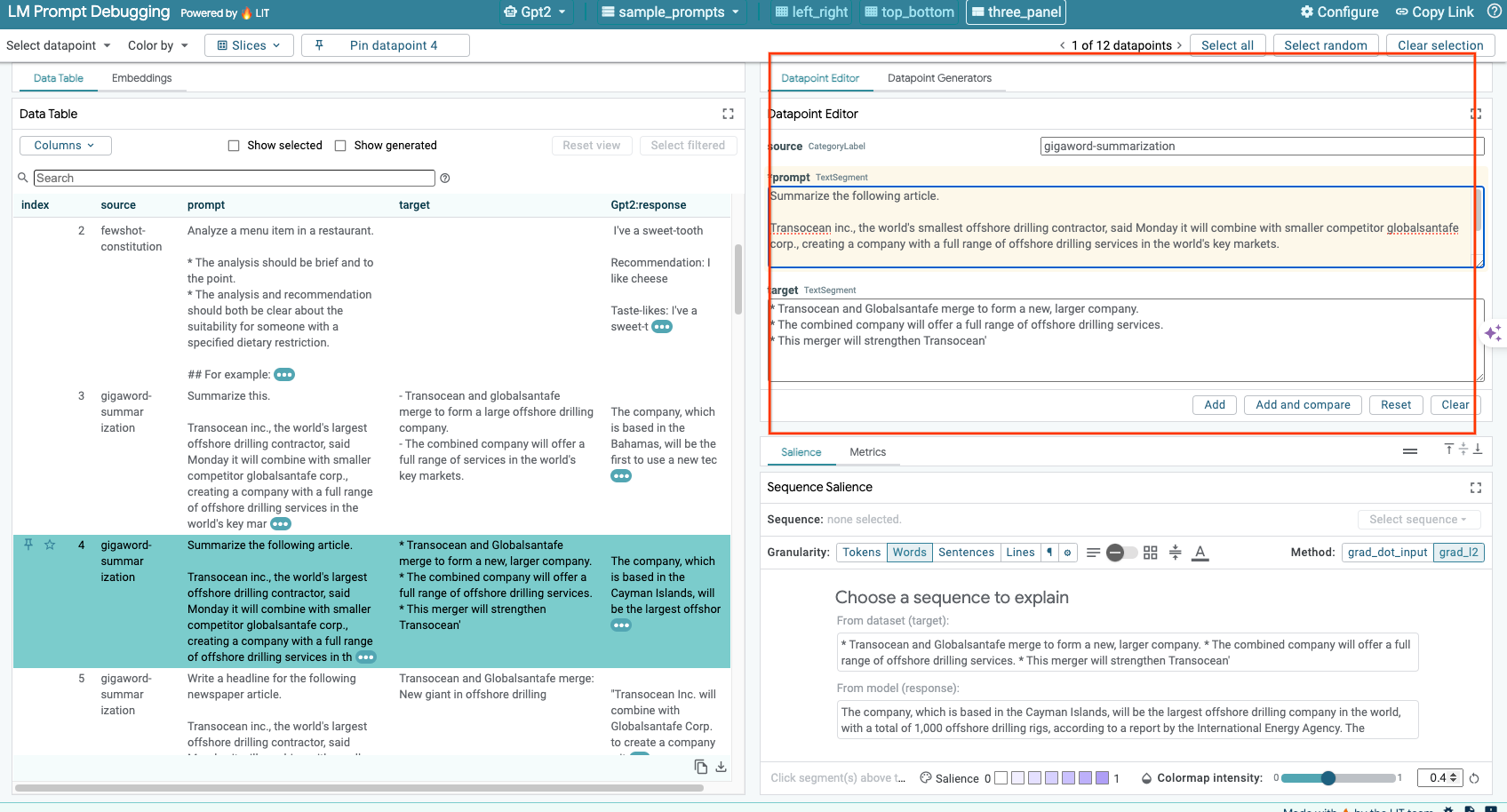
6-d: 프롬프트를 나란히 비교
LIT를 사용하면 원본 예시와 수정된 예시에서 프롬프트를 나란히 비교할 수 있습니다. 예를 수동으로 수정하고 원본 버전과 수정된 버전의 예측 결과와 시퀀스 현저성 분석을 동시에 볼 수 있습니다. 각 데이터 포인트의 프롬프트를 수정하면 LIT가 모델을 쿼리하여 해당 응답을 생성합니다.
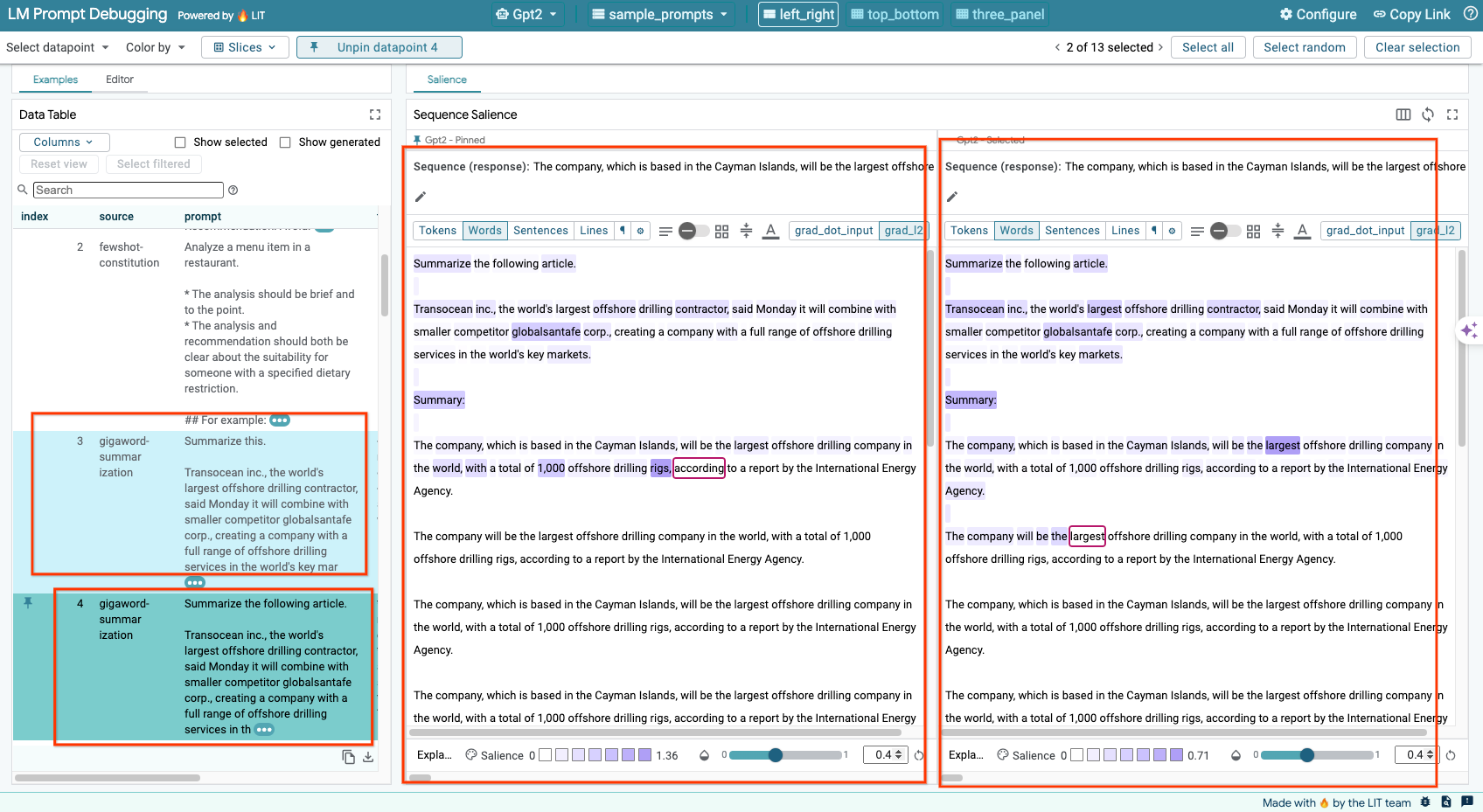
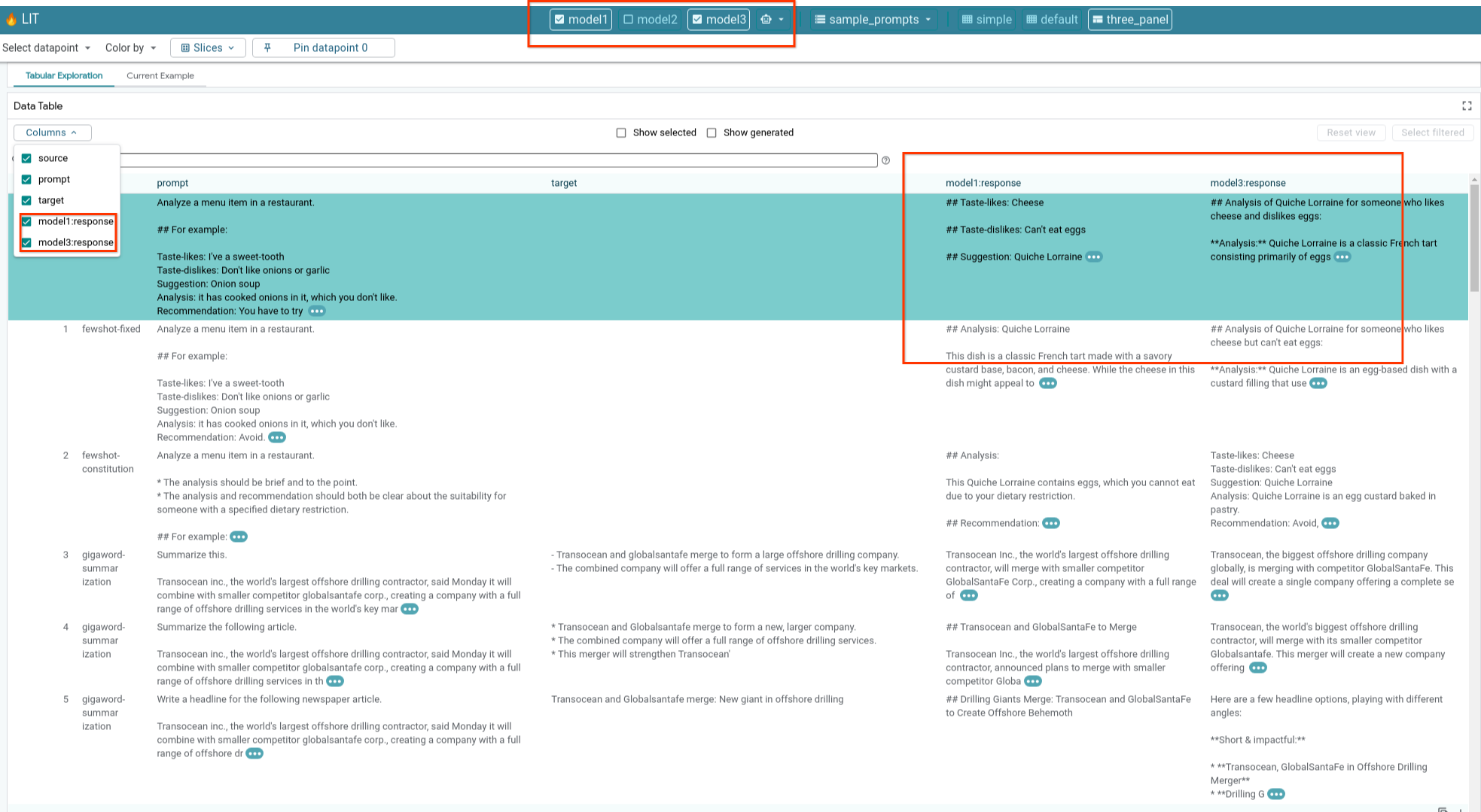
6-e: 여러 모델 나란히 비교
LIT를 사용하면 개별 텍스트 생성 및 점수 매기기 예시뿐만 아니라 특정 측정항목의 집계된 예시에서 모델을 나란히 비교할 수 있습니다. 다양한 로드된 모델을 쿼리하여 응답의 차이를 쉽게 비교할 수 있습니다.
6-f: 자동 반사실적 생성기
자동 반사실적 생성기를 사용하여 대체 입력을 만들고 모델이 이러한 입력에서 어떻게 작동하는지 바로 확인할 수 있습니다.
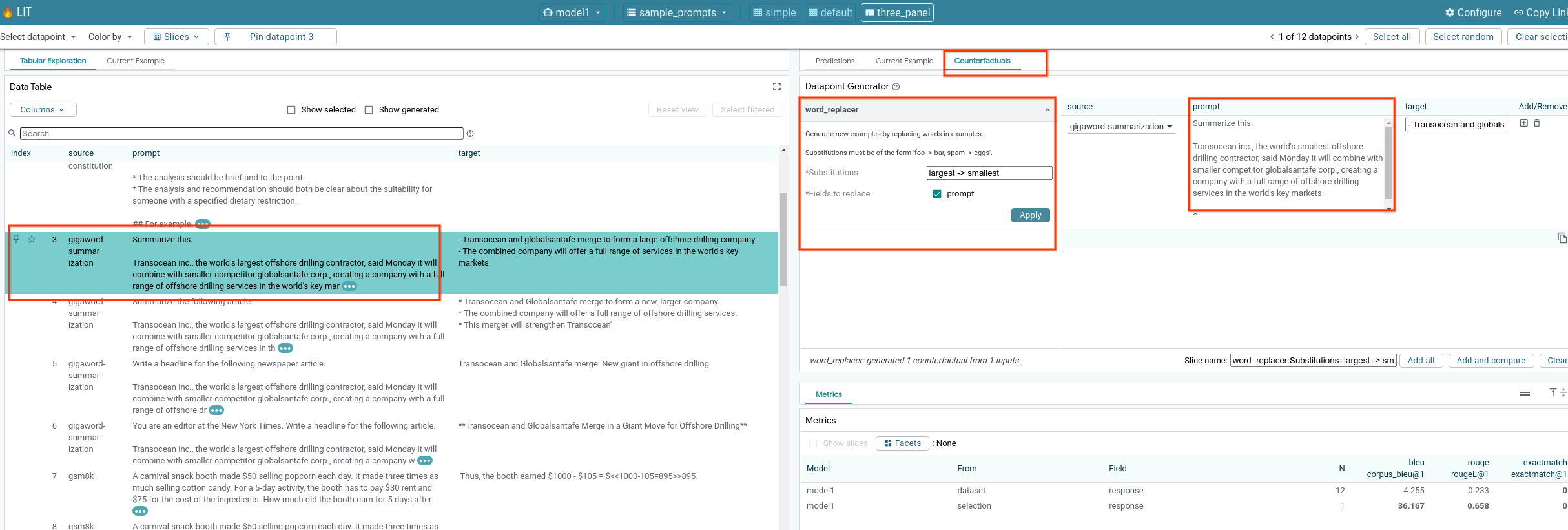
6-g: 모델 성능 평가
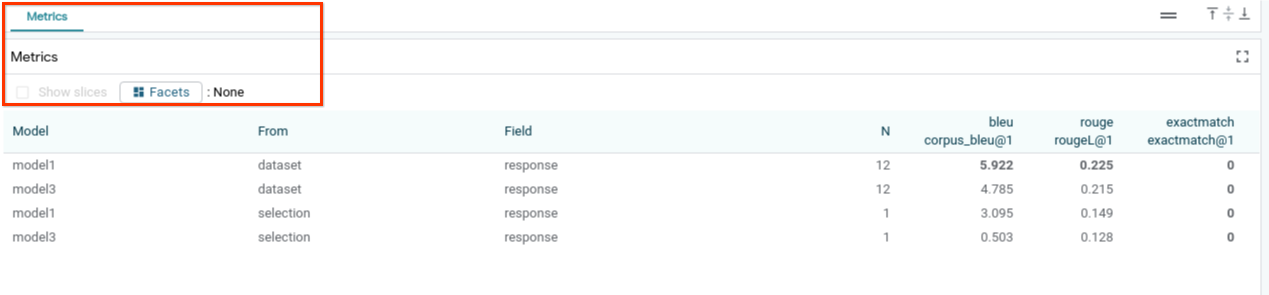
전체 데이터 세트 또는 필터링되거나 선택된 예시의 하위 집합에서 측정항목 (현재 텍스트 생성의 BLEU 및 ROUGE 점수 지원)을 사용하여 모델 성능을 평가할 수 있습니다.
7. 문제 해결
7-a: 잠재적인 액세스 문제 및 해결 방법
Cloud Run에 배포할 때 --no-allow-unauthenticated가 적용되므로 아래와 같이 금지된 오류가 발생할 수 있습니다.

LIT 앱 서비스에 액세스하는 방법에는 두 가지가 있습니다.
1. 지역 서비스에 대한 프록시
아래 명령어를 사용하여 서비스를 로컬 호스트로 프록시할 수 있습니다.
# Proxy the service to local host.
gcloud run services proxy $LIT_SERVICE_NAME
그런 다음 프록시 처리된 서비스 링크를 클릭하여 LIT 서버에 액세스할 수 있습니다.
2. 사용자 직접 인증
이 링크를 따라 사용자를 인증하여 LIT 앱 서비스에 직접 액세스할 수 있습니다. 이 방법을 사용하면 사용자 그룹이 서비스에 액세스할 수도 있습니다. 여러 사용자와 공동작업하는 개발의 경우 이 옵션이 더 효과적입니다.
7-b: 모델 서버가 성공적으로 실행되었는지 확인합니다.
모델 서버가 성공적으로 실행되었는지 확인하려면 요청을 전송하여 모델 서버를 직접 쿼리하면 됩니다. 모델 서버는 predict, tokenize, salience의 세 가지 엔드포인트를 제공합니다. 요청에 prompt 필드와 target 필드를 모두 제공해야 합니다.
# Query the model server predict endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/predict -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server tokenize endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/tokenize -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server salience endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/salience -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
액세스 문제가 발생하면 위의 섹션 7-a를 확인하세요.
8. 축하합니다
Codelab을 완료했습니다. 이제 휴식을 취할 시간입니다.
삭제
실습을 정리하려면 실습을 위해 생성된 모든 Google Cloud 서비스를 삭제합니다. Google Cloud Shell을 사용하여 다음 명령어를 실행합니다.
비활성으로 인해 Google Cloud 연결이 끊어진 경우 이전 단계에 따라 변수를 재설정합니다.
# Delete the LIT App Service.
gcloud run services delete $LIT_SERVICE_NAME
모델 서버를 시작한 경우 모델 서버도 삭제해야 합니다.
# Delete the Model Service.
gcloud run services delete $MODEL_SERVICE_NAME
추가 자료
아래 자료를 통해 LIT 도구 기능을 계속 학습하세요.
- Gemma: 링크
- LIT 오픈소스 코드 베이스: Git 저장소
- LIT 논문: ArXiv
- LIT 프롬프트 디버깅 논문: ArXiv
- LIT 기능 동영상 데모: YouTube
- LIT 프롬프트 디버깅 데모: YouTube
- 책임감 있는 생성형 AI 툴킷: 링크
연락처
이 Codelab과 관련해 궁금한 점이나 문제가 있으면 GitHub에 문의하세요.
라이선스
이 작업물은 Creative Commons Attribution 4.0 일반 라이선스에 따라 사용이 허가되었습니다.