
1. Przegląd
Ten moduł zawiera szczegółowe instrukcje wdrażania serwera aplikacji LIT na platformie Google Cloud Platform (GCP) w celu interakcji z modelami podstawowymi Vertex AI Gemini i samodzielnie hostowanymi modelami językowymi innych firm (LLM). Zawiera też wskazówki dotyczące korzystania z interfejsu LIT do debugowania promptów i interpretowania modeli.
Po ukończeniu tego modułu użytkownicy będą wiedzieć, jak:
- Skonfiguruj serwer LIT na GCP.
- Połącz serwer LIT z modelami Vertex AI Gemini lub innymi samodzielnie hostowanymi modelami LLM.
- Korzystaj z interfejsu LIT, aby analizować, debugować i interpretować prompty, co pozwoli Ci zwiększyć skuteczność modelu i uzyskać lepsze statystyki.
Co to jest LIT?
LIT to wizualne, interaktywne narzędzie do analizowania modeli, które obsługuje dane tekstowe, obrazy i dane w formie tabel. Może działać jako samodzielny serwer lub w środowiskach notatników, takich jak Google Colab, Jupyter i Google Cloud Vertex AI. LIT jest dostępny w PyPI i GitHub.
Pierwotnie narzędzie to zostało stworzone do analizowania modeli klasyfikacji i regresji, ale w ostatnich aktualizacjach dodano narzędzia do debugowania promptów LLM, które umożliwiają sprawdzanie, jak treści użytkownika, modelu i systemu wpływają na zachowanie generowania.
Czym są Vertex AI i baza modeli?
Vertex AI to platforma systemów uczących się, która umożliwia trenowanie i wdrażanie modeli ML oraz aplikacji AI, a także dostosowywanie dużych modeli językowych do użytku w aplikacjach opartych na AI. Vertex AI łączy przepływy pracy związane z inżynierią danych, nauką o danych i inżynierią uczenia maszynowego, dzięki czemu Twoje zespoły mogą współpracować, korzystając z wspólnego zestawu narzędzi, i skalować aplikacje, wykorzystując zalety Google Cloud.
Baza modeli Vertex to biblioteka modeli ML, która pomaga odkrywać, testować, dostosowywać i wdrażać zastrzeżone modele Google oraz wybrane modele i zasoby innych firm.
Co musisz zrobić
Do wdrożenia kontenera Dockera z gotowego obrazu LIT użyjesz Cloud Shell i Cloud Run od Google.
Cloud Run to zarządzana platforma obliczeniowa, która umożliwia uruchamianie kontenerów bezpośrednio w skalowalnej infrastrukturze Google, w tym na procesorach graficznych.
Zbiór danych
Wersja demonstracyjna domyślnie korzysta z przykładowego zbioru danych do debugowania promptów LIT, ale możesz też wczytać własny zbiór danych za pomocą interfejsu.
Zanim zaczniesz
Aby skorzystać z tego przewodnika, musisz mieć projekt Google Cloud. Możesz utworzyć nowy projekt lub wybrać już utworzony.
2. Uruchomienie konsoli Google Cloud i Cloud Shell
W tym kroku uruchomisz konsolę Google Cloud i użyjesz Google Cloud Shell.
2-a. Uruchom konsolę Google Cloud.
Uruchom przeglądarkę i otwórz konsolę Google Cloud.
konsola Google Cloud to zaawansowany i bezpieczny internetowy interfejs administracyjny, który umożliwia szybkie zarządzanie zasobami Google Cloud. To narzędzie DevOps w podróży.
2b. Uruchom Google Cloud Shell
Cloud Shell to środowisko programistyczne i operacyjne online, które można otworzyć w dowolnym miejscu przy użyciu przeglądarki. Możesz zarządzać zasobami za pomocą terminala online wyposażonego w takie narzędzia jak narzędzie wiersza poleceń gcloud czy kubectl. Możesz też tworzyć, kompilować, debugować i wdrażać aplikacje działające w chmurze przy użyciu edytora Cloud Shell online. Cloud Shell to gotowe do użycia środowisko online dla programistów z zainstalowanym ulubionym zestawem narzędzi i 5 GB pamięci trwałej. W kolejnych krokach będziesz używać wiersza poleceń.
Uruchom Google Cloud Shell, klikając ikonę w prawym górnym rogu paska menu (na zrzucie ekranu poniżej jest ona zaznaczona na niebiesko).

U dołu strony powinien pojawić się terminal z powłoką Bash.

2.c. Ustaw projekt Google Cloud
Musisz ustawić identyfikator projektu i region projektu za pomocą polecenia gcloud.
# Set your GCP Project ID.
gcloud config set project your-project-id
# Set your GCP Project Region.
gcloud config set run/region your-project-region
3. Wdrażanie obrazu Dockera serwera aplikacji LIT za pomocą Cloud Run
3a. Wdróż aplikację LIT w Cloud Run
Najpierw musisz ustawić najnowszą wersję LIT-App jako wersję do wdrożenia.
# Set latest version as your LIT_SERVICE_TAG.
export LIT_SERVICE_TAG=latest
# List all the public LIT GCP App server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app
Po ustawieniu tagu wersji musisz nadać nazwę usługi.
# Set your lit service name. While 'lit-app-service' is provided as a placeholder, you can customize the service name based on your preferences.
export LIT_SERVICE_NAME=lit-app-service
Następnie możesz uruchomić to polecenie, aby wdrożyć kontener w Cloud Run.
# Use below cmd to deploy the LIT App to Cloud Run.
gcloud run deploy $LIT_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app:$LIT_SERVICE_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--no-allow-unauthenticated
LIT umożliwia też dodanie zbioru danych podczas uruchamiania serwera. Aby to zrobić, ustaw zmienną DATASETS tak, aby zawierała dane, które chcesz załadować, używając formatu name:path, np. data_foo:/bar/data_2024.jsonl. Format zbioru danych powinien być .jsonl, gdzie każdy rekord zawiera pola prompt oraz opcjonalne pola target i source. Aby wczytać wiele zbiorów danych, rozdziel je przecinkami. Jeśli nie zostanie ustawiony, zostanie wczytany przykładowy zbiór danych do debugowania promptów LIT.
# Set the dataset.
export DATASETS=[DATASETS]
Ustawiając MAX_EXAMPLES, możesz określić maksymalną liczbę przykładów do wczytania z każdego zbioru oceniającego.
# Set the max examples.
export MAX_EXAMPLES=[MAX_EXAMPLES]
Następnie w poleceniu wdrażania możesz dodać
--set-env-vars "DATASETS=$DATASETS" \
--set-env-vars "MAX_EXAMPLES=$MAX_EXAMPLES" \
3b. Wyświetlanie usługi aplikacji LIT
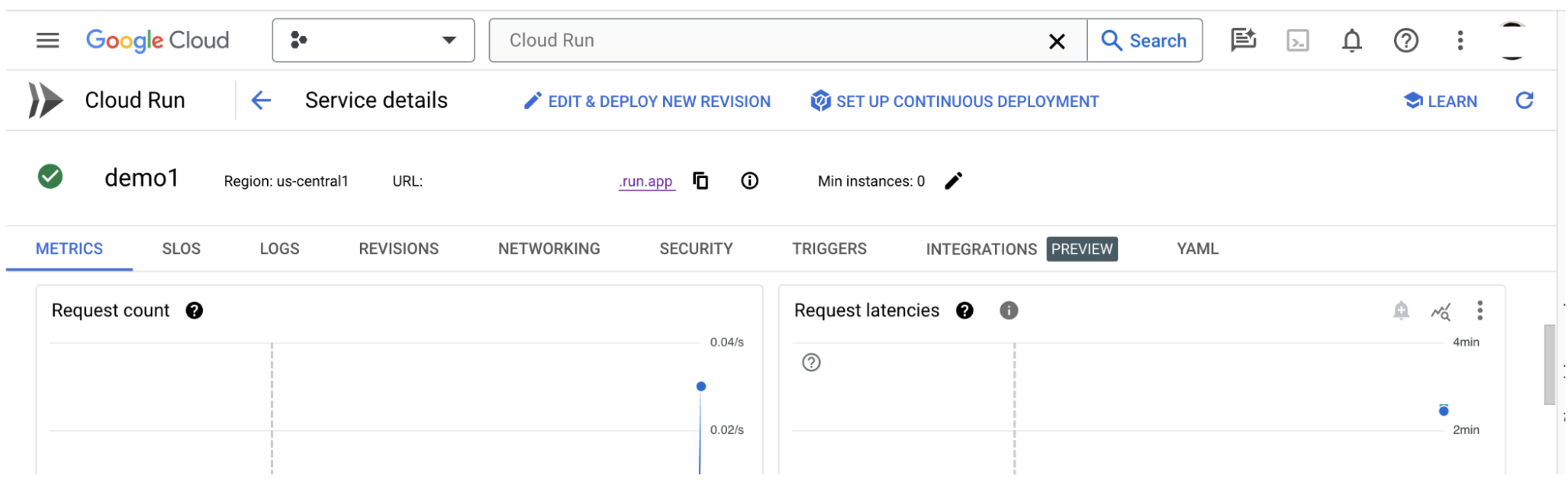
Po utworzeniu serwera aplikacji LIT możesz znaleźć usługę w sekcji Cloud Run w Cloud Console.
Wybierz utworzoną usługę LIT App. Upewnij się, że nazwa usługi jest taka sama jak LIT_SERVICE_NAME.
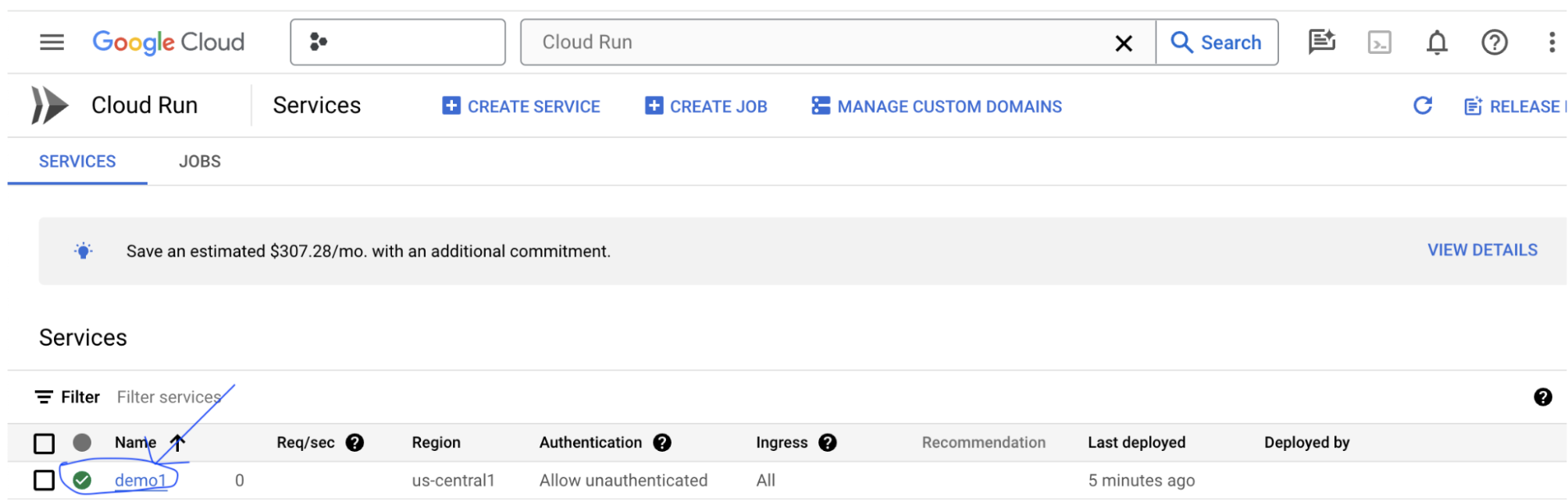
Adres URL usługi znajdziesz, klikając wdrożoną właśnie usługę.
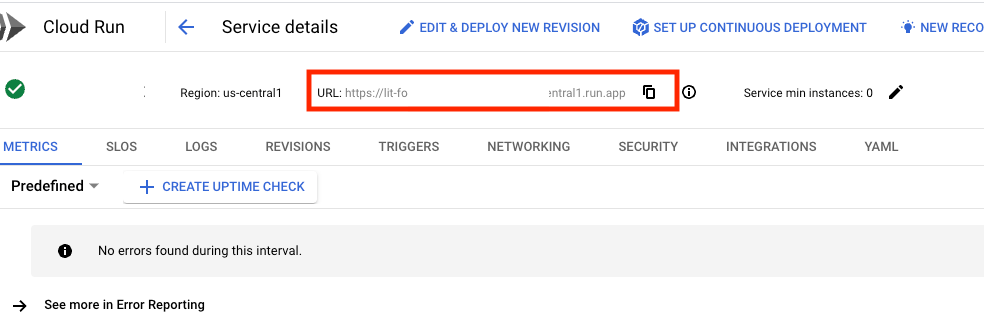
Powinien być widoczny interfejs LIT. Jeśli pojawi się błąd, zapoznaj się z sekcją Rozwiązywanie problemów.
W sekcji DZIENNIKI możesz monitorować aktywność, wyświetlać komunikaty o błędach i śledzić postęp wdrażania.
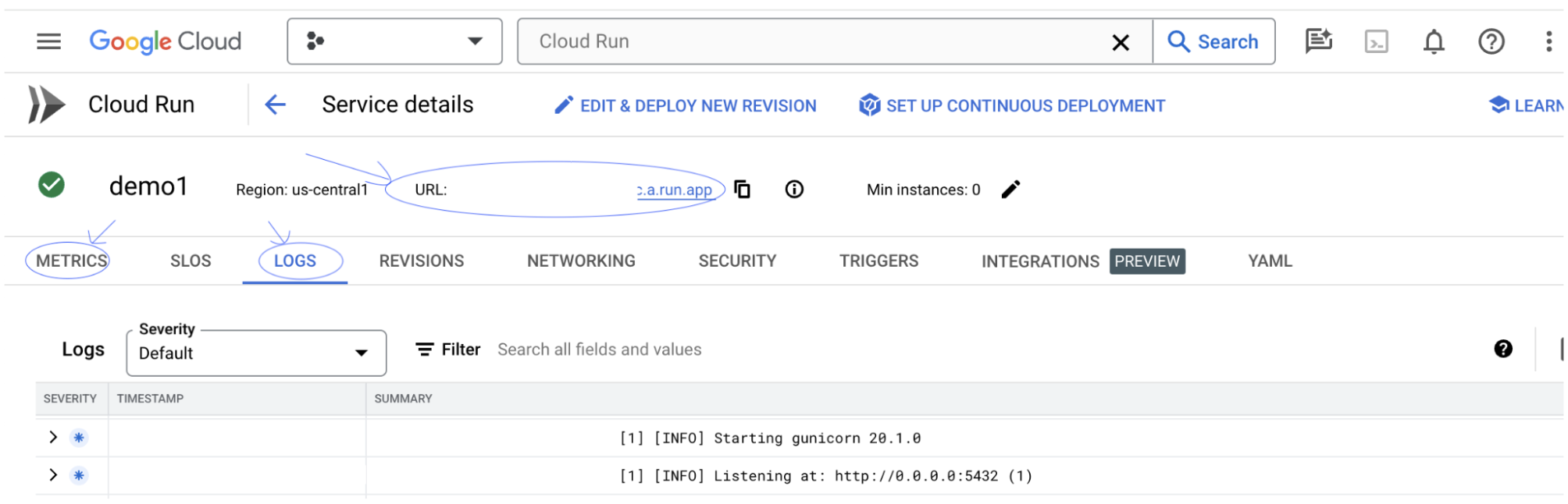
W sekcji DANE możesz wyświetlić dane usługi.
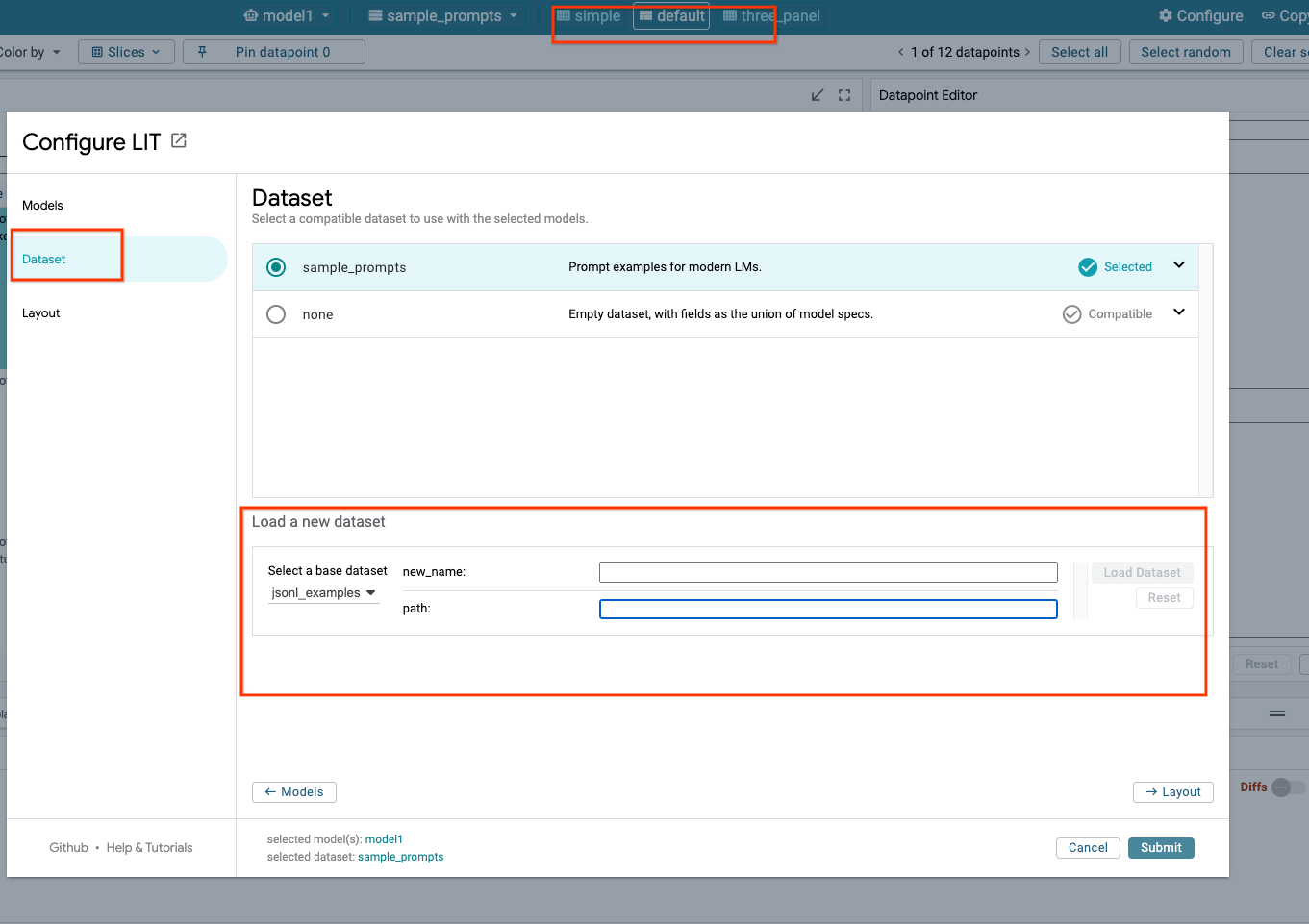
3.c. Wczytaj zbiory danych
W interfejsie LIT kliknij opcję Configure, a następnie wybierz Dataset. Wczytaj zbiór danych, podając jego nazwę i adres URL. Format zbioru danych powinien być .jsonl, gdzie każdy rekord zawiera pola prompt oraz opcjonalne pola target i source.
4. Przygotowywanie modeli Gemini w bazie modeli Vertex AI
Modele podstawowe Gemini od Google są dostępne w interfejsie Vertex AI API. LIT udostępnia VertexAIModelGarden otokę modelu, która umożliwia używanie tych modeli do generowania treści. Wystarczy podać odpowiednią wersję (np. „gemini-1.5-pro-001”) za pomocą parametru nazwy modelu. Główną zaletą tych modeli jest to, że nie wymagają one dodatkowego wysiłku przy wdrażaniu. Domyślnie masz natychmiastowy dostęp do modeli takich jak Gemini 1.0 Pro i Gemini 1.5 Pro w GCP, co eliminuje konieczność wykonywania dodatkowych kroków konfiguracji.
4a. Przyznaj uprawnienia Vertex AI
Aby wysyłać zapytania do Gemini w GCP, musisz przyznać kontu usługi uprawnienia do Vertex AI. Sprawdź, czy nazwa konta usługi to Default compute service account. Skopiuj adres e-mail konta usługi.
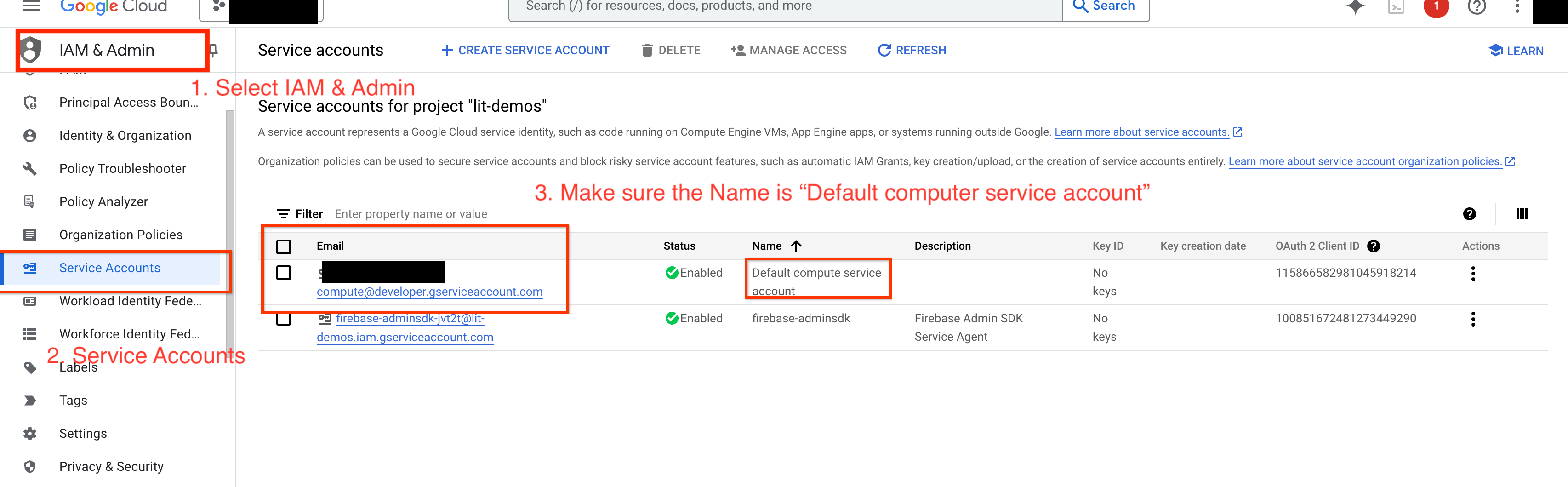
Dodaj adres e-mail konta usługi jako podmiot zabezpieczeń z rolą Vertex AI User na liście dozwolonych uprawnień.

4b. Wczytaj modele Gemini
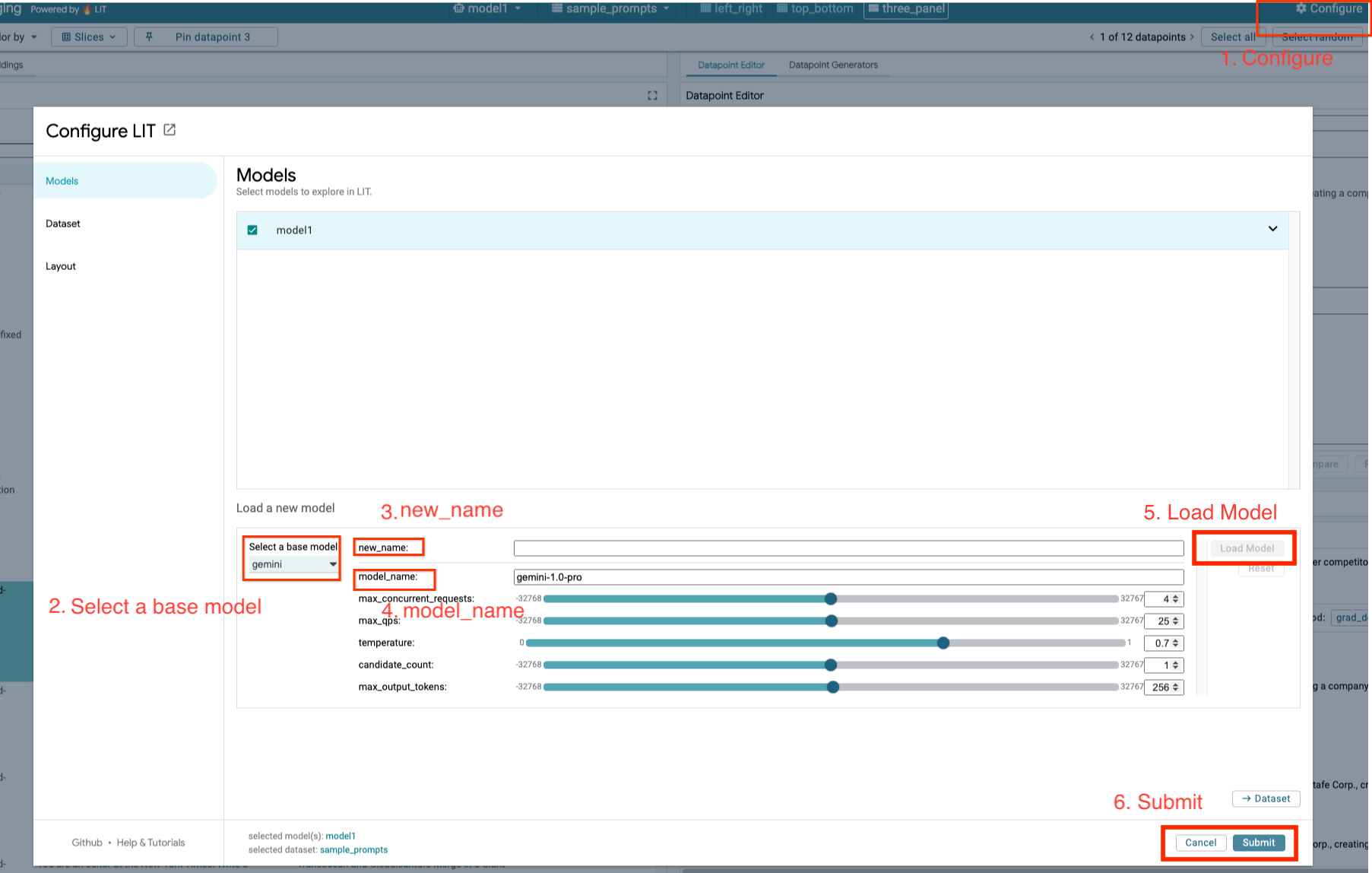
Modele Gemini będziesz wczytywać i dostosowywać ich parametry, wykonując te czynności:
- W interfejsie LIT kliknij opcję
Configure.
- W interfejsie LIT kliknij opcję
- Wybierz opcję
geminiw sekcjiSelect a base model.
- Wybierz opcję
- Musisz nazwać model w
new_name.
- Musisz nazwać model w
- Wpisz wybrane modele Gemini jako
model_name.
- Wpisz wybrane modele Gemini jako
- Kliknij
Load Model.
- Kliknij
- Kliknij
Submit.
- Kliknij
5. Wdrażanie serwera modelu LLM hostowanego samodzielnie w GCP
Samodzielne hostowanie dużych modeli językowych za pomocą obrazu Dockera serwera modeli LIT umożliwia korzystanie z funkcji LIT dotyczących istotności i tokenizacji, aby uzyskać głębszy wgląd w zachowanie modelu. Obraz serwera modelu działa z modelami KerasNLP lub Hugging Face Transformers, w tym z wagami dostarczonymi przez bibliotekę i hostowanymi samodzielnie, np. w Google Cloud Storage.
5a. Skonfiguruj modele
Każdy kontener wczytuje 1 model skonfigurowany za pomocą zmiennych środowiskowych.
Modele do wczytania należy określić, ustawiając zmienną MODEL_CONFIG. Format powinien wyglądać tak: name:path, np. model_foo:model_foo_path. Ścieżka może być adresem URL, ścieżką do pliku lokalnego lub nazwą gotowego ustawienia wstępnego dla skonfigurowanej platformy uczenia głębokiego (więcej informacji znajdziesz w tabeli poniżej). Ten serwer jest testowany z modelami Gemma, GPT2, Llama i Mistral we wszystkich obsługiwanych wartościach DL_FRAMEWORK. Inne modele powinny działać, ale może być konieczne wprowadzenie zmian.
# Set models you want to load. While 'gemma2b is given as a placeholder, you can load your preferred model by following the instructions above.
export MODEL_CONFIG=gemma2b:gemma_2b_en
Serwer modelu LIT umożliwia też konfigurowanie różnych zmiennych środowiskowych za pomocą tego polecenia: Szczegóły znajdziesz w tabeli. Pamiętaj, że każdą zmienną musisz ustawić osobno.
# Customize the variable value as needed.
export [VARIABLE]=[VALUE]
Zmienna | Wartości | Opis |
DL_FRAMEWORK |
| Biblioteka modelowania używana do wczytywania wag modelu w określonym środowisku wykonawczym. Domyślna wartość to |
DL_RUNTIME |
| Platforma backendu uczenia głębokiego, na której działa model. Wszystkie modele wczytane przez ten serwer będą korzystać z tego samego backendu, a niezgodności spowodują błędy. Domyślna wartość to |
PRECISION |
| Precyzja zmiennoprzecinkowa w przypadku modeli LLM. Domyślna wartość to |
BATCH_SIZE | Liczby naturalne dodatnie | Liczba przykładów do przetworzenia w każdej partii. Domyślna wartość to |
SEQUENCE_LENGTH | Liczby naturalne dodatnie | Maksymalna długość sekwencji promptu wejściowego i wygenerowanego tekstu. Domyślna wartość to |
5b. Wdrażanie serwera modelu w Cloud Run
Najpierw musisz ustawić najnowszą wersję serwera modelu jako wersję do wdrożenia.
# Set latest as MODEL_VERSION_TAG.
export MODEL_VERSION_TAG=latest
# List all the public LIT GCP model server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server
Po ustawieniu tagu wersji musisz nadać nazwę serwerowi modelu.
# Set your Service name.
export MODEL_SERVICE_NAME='gemma2b-model-server'
Następnie możesz uruchomić to polecenie, aby wdrożyć kontener w Cloud Run. Jeśli nie ustawisz zmiennych środowiskowych, zostaną zastosowane wartości domyślne. Większość LLM wymaga kosztownych zasobów obliczeniowych, dlatego zdecydowanie zalecamy używanie GPU. Jeśli wolisz uruchamiać model tylko na procesorze (co sprawdza się w przypadku małych modeli, takich jak GPT2), możesz usunąć powiązane argumenty --gpu 1 --gpu-type nvidia-l4 --max-instances 7.
# Deploy the model service container.
gcloud beta run deploy $MODEL_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server:$MODEL_VERSION_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 7 \
--set-env-vars "MODEL_CONFIG=$MODEL_CONFIG" \
--no-allow-unauthenticated
Możesz też dostosować zmienne środowiskowe, dodając te polecenia: Uwzględnij tylko zmienne środowiskowe, które są niezbędne w Twoim przypadku.
--set-env-vars "DL_FRAMEWORK=$DL_FRAMEWORK" \
--set-env-vars "DL_RUNTIME=$DL_RUNTIME" \
--set-env-vars "PRECISION=$PRECISION" \
--set-env-vars "BATCH_SIZE=$BATCH_SIZE" \
--set-env-vars "SEQUENCE_LENGTH=$SEQUENCE_LENGTH" \
Aby uzyskać dostęp do niektórych modeli, może być konieczne użycie dodatkowych zmiennych środowiskowych. Postępuj zgodnie z instrukcjami z Kaggle Hub (w przypadku modeli KerasNLP) i Hugging Face Hub.
5.c. Dostęp do serwera modelu
Po utworzeniu serwera modelu uruchomioną usługę można znaleźć w sekcji Cloud Run w projekcie GCP.
Wybierz utworzony serwer modelu. Upewnij się, że nazwa usługi jest taka sama jak MODEL_SERVICE_NAME.
Adres URL usługi znajdziesz, klikając wdrożoną właśnie usługę modelu.
W sekcji DZIENNIKI możesz monitorować aktywność, wyświetlać komunikaty o błędach i śledzić postęp wdrażania.
W sekcji DANE możesz wyświetlić dane usługi.
5d. Wczytywanie modeli hostowanych samodzielnie
Jeśli w kroku 3 używasz serwera LIT jako serwera proxy (patrz sekcja Rozwiązywanie problemów), musisz uzyskać token tożsamości GCP, uruchamiając to polecenie.
# Find your GCP identity token.
gcloud auth print-identity-token
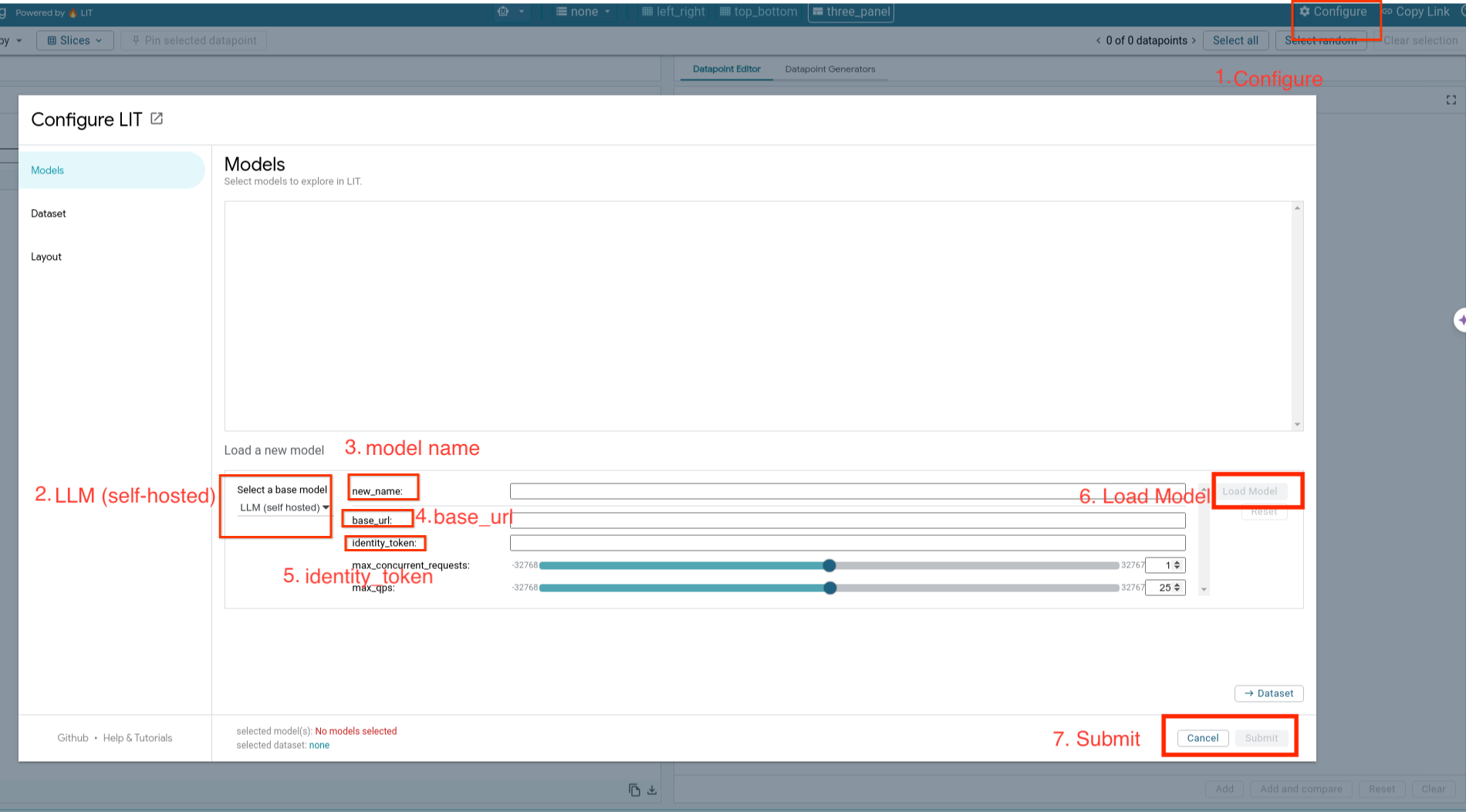
Modele hostowane samodzielnie będziesz wczytywać i dostosowywać ich parametry, wykonując te czynności:
- W interfejsie LIT kliknij opcję
Configure. - Wybierz opcję
LLM (self hosted)w sekcjiSelect a base model. - Musisz nazwać model w
new_name. - Wpisz adres URL serwera modelu jako
base_url. - Wpisz uzyskany token tożsamości w
identity_token, jeśli serwer aplikacji LIT jest serwerem proxy (patrz kroki 3 i 7). W przeciwnym razie pozostaw to pole puste. - Kliknij
Load Model. - Kliknij
Submit.
6. Interakcje z LIT w GCP
LIT oferuje bogaty zestaw funkcji, które pomagają debugować i analizować zachowania modelu. Możesz na przykład wysłać zapytanie do modelu, wpisując tekst w polu i sprawdzając jego prognozy, lub dokładnie zbadać modele za pomocą pakietu zaawansowanych funkcji LIT, takich jak:
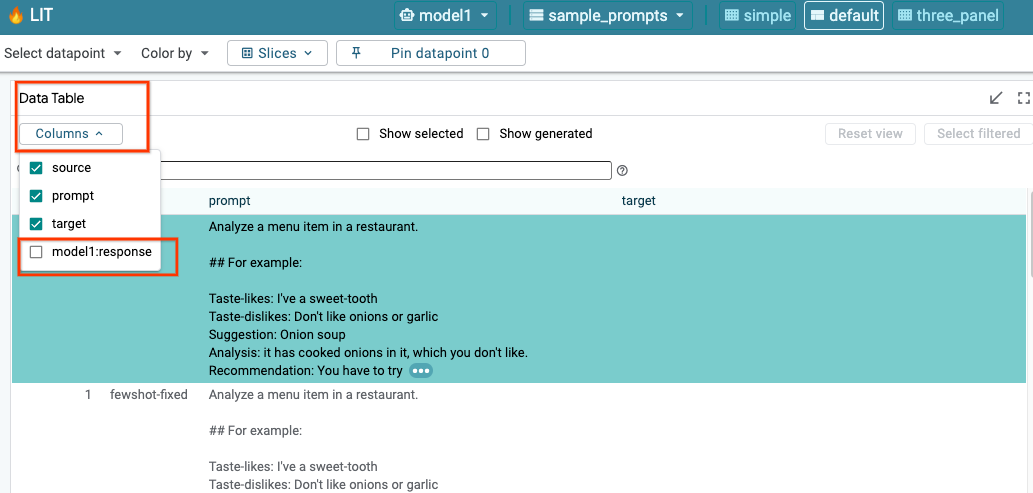
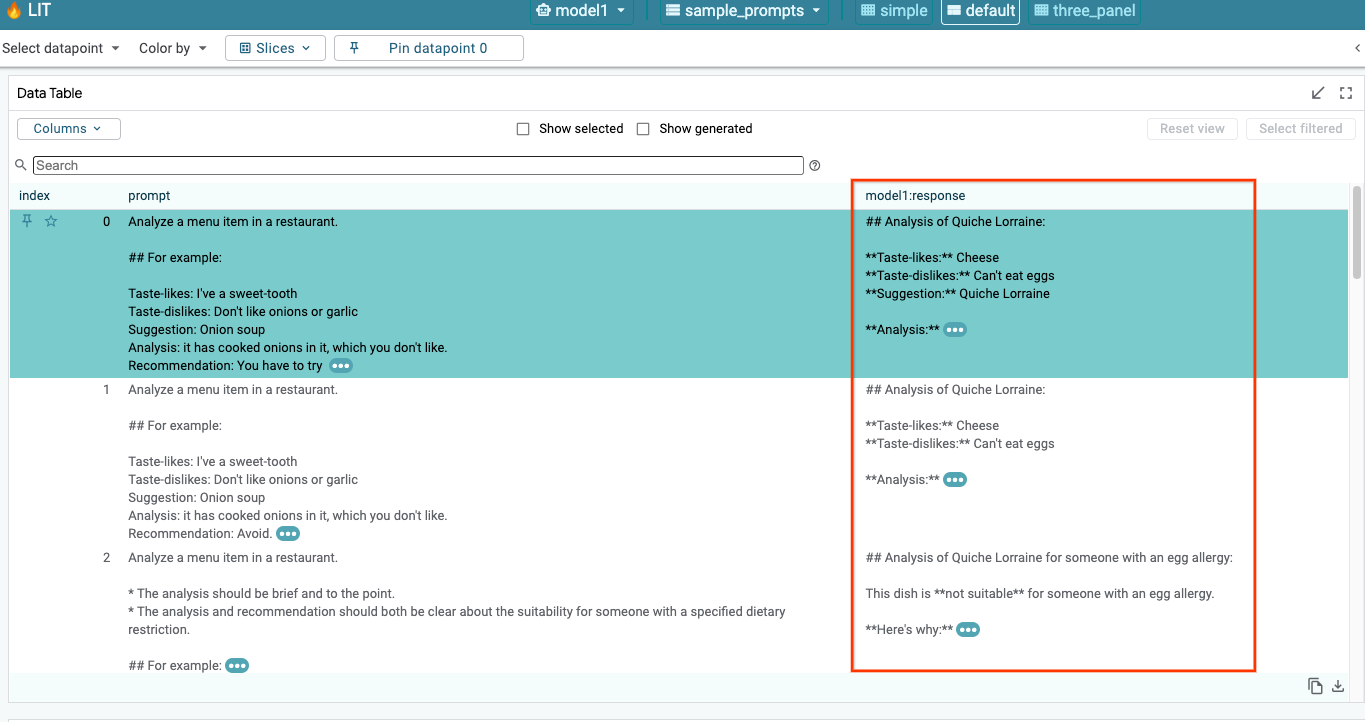
6a. Wyślij zapytanie do modelu za pomocą LIT
Po wczytaniu modelu i zbioru danych LIT automatycznie wysyła zapytanie do zbioru danych. Odpowiedź każdego modelu możesz wyświetlić, wybierając ją w kolumnach.
6-b. Użyj techniki istotności sekwencji
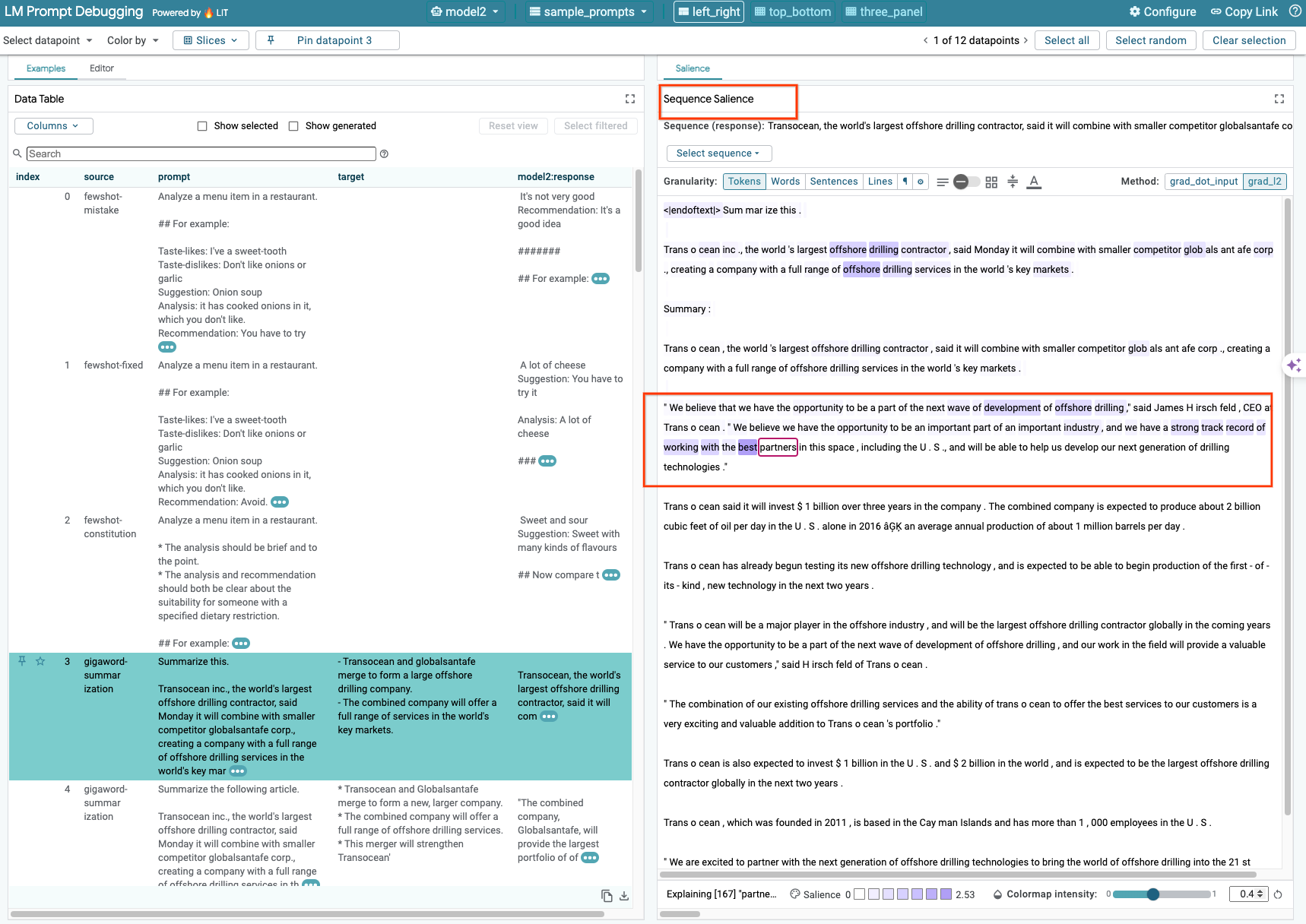
Obecnie technika Sequence Salience w narzędziu LIT obsługuje tylko modele hostowane samodzielnie.
Sequence Salience to narzędzie wizualne, które pomaga debugować prompty LLM, wyróżniając te części promptu, które są najważniejsze w przypadku danego wyniku. Więcej informacji o znaczeniu sekwencji znajdziesz w pełnym samouczku, w którym opisujemy, jak korzystać z tej funkcji.
Aby uzyskać dostęp do wyników istotności, kliknij dowolne dane wejściowe lub wyjściowe w prompcie lub odpowiedzi. Wyświetlą się wyniki istotności.
6-c. Ręczne edytowanie prompta i kierowania
Narzędzie LIT umożliwia ręczne edytowanie dowolnych prompt i target w przypadku istniejącego punktu danych. Kliknięcie Add spowoduje dodanie nowego wejścia do zbioru danych.
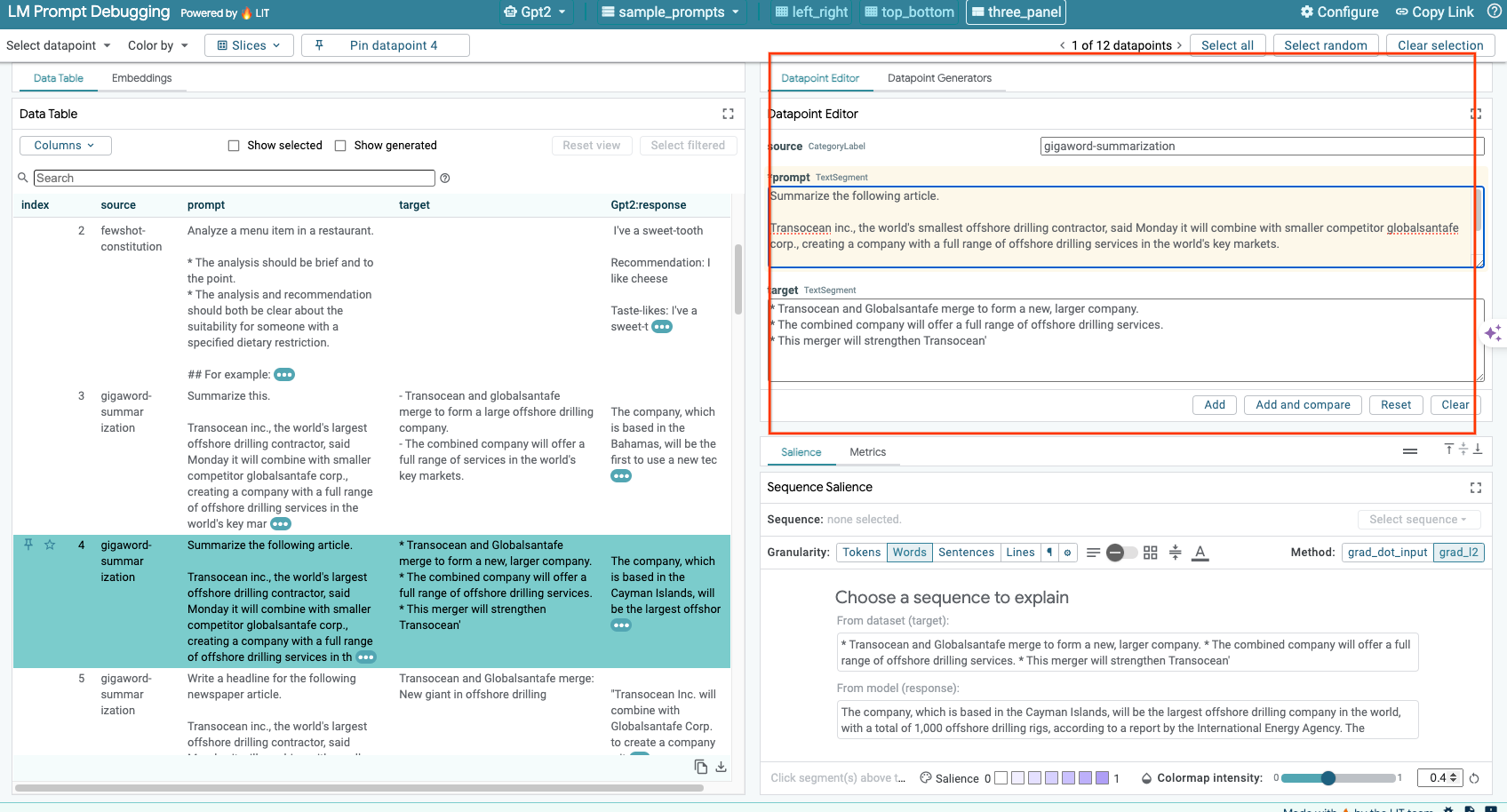
6d. Porównaj prompt obok siebie
LIT umożliwia porównywanie promptów obok siebie na przykładach oryginalnych i zmodyfikowanych. Możesz ręcznie edytować przykład i jednocześnie wyświetlać wynik prognozy oraz analizę istotności sekwencji zarówno w przypadku wersji oryginalnej, jak i zmodyfikowanej. Możesz zmodyfikować prompt dla każdego punktu danych, a LIT wygeneruje odpowiednią odpowiedź, wysyłając zapytanie do modelu.
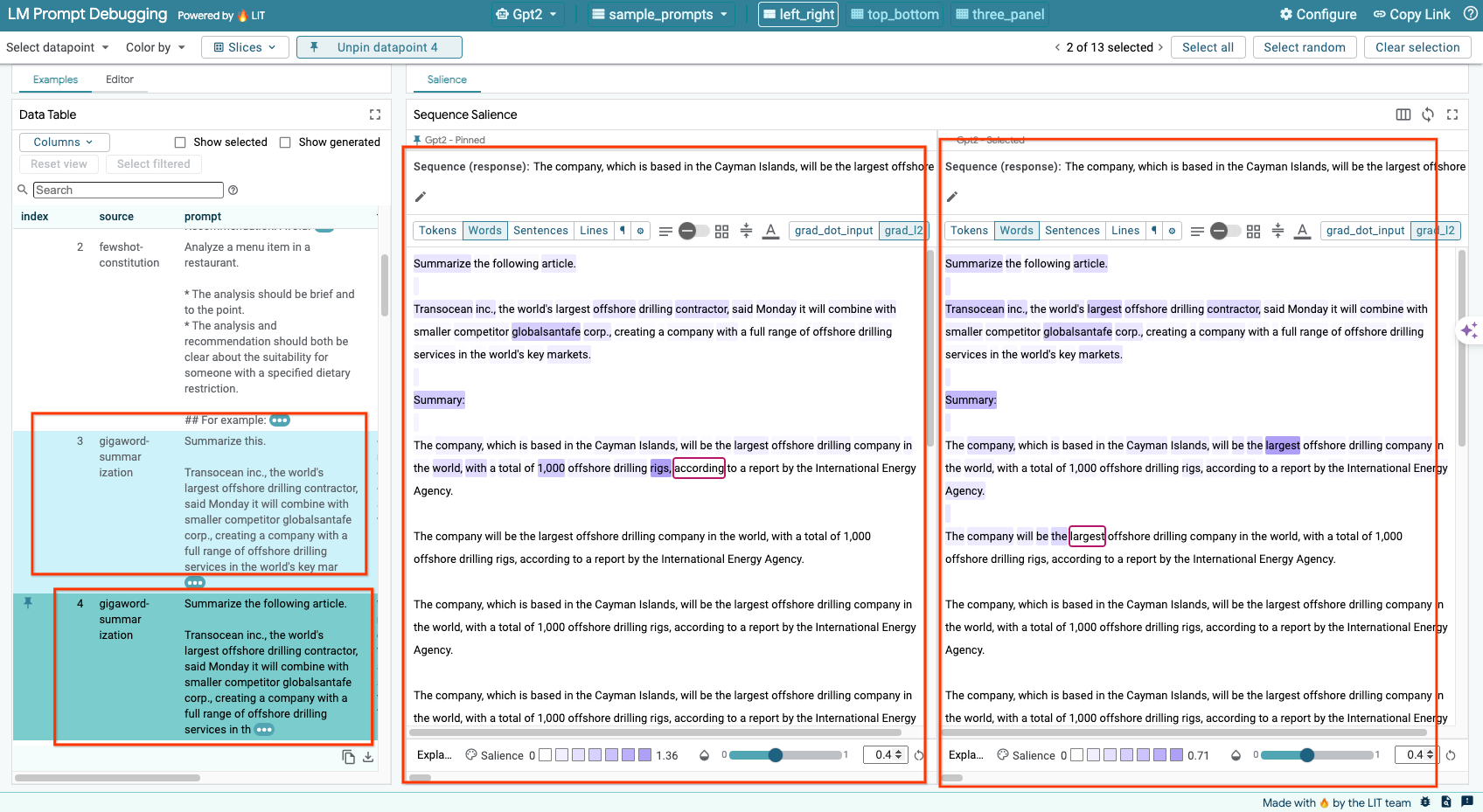
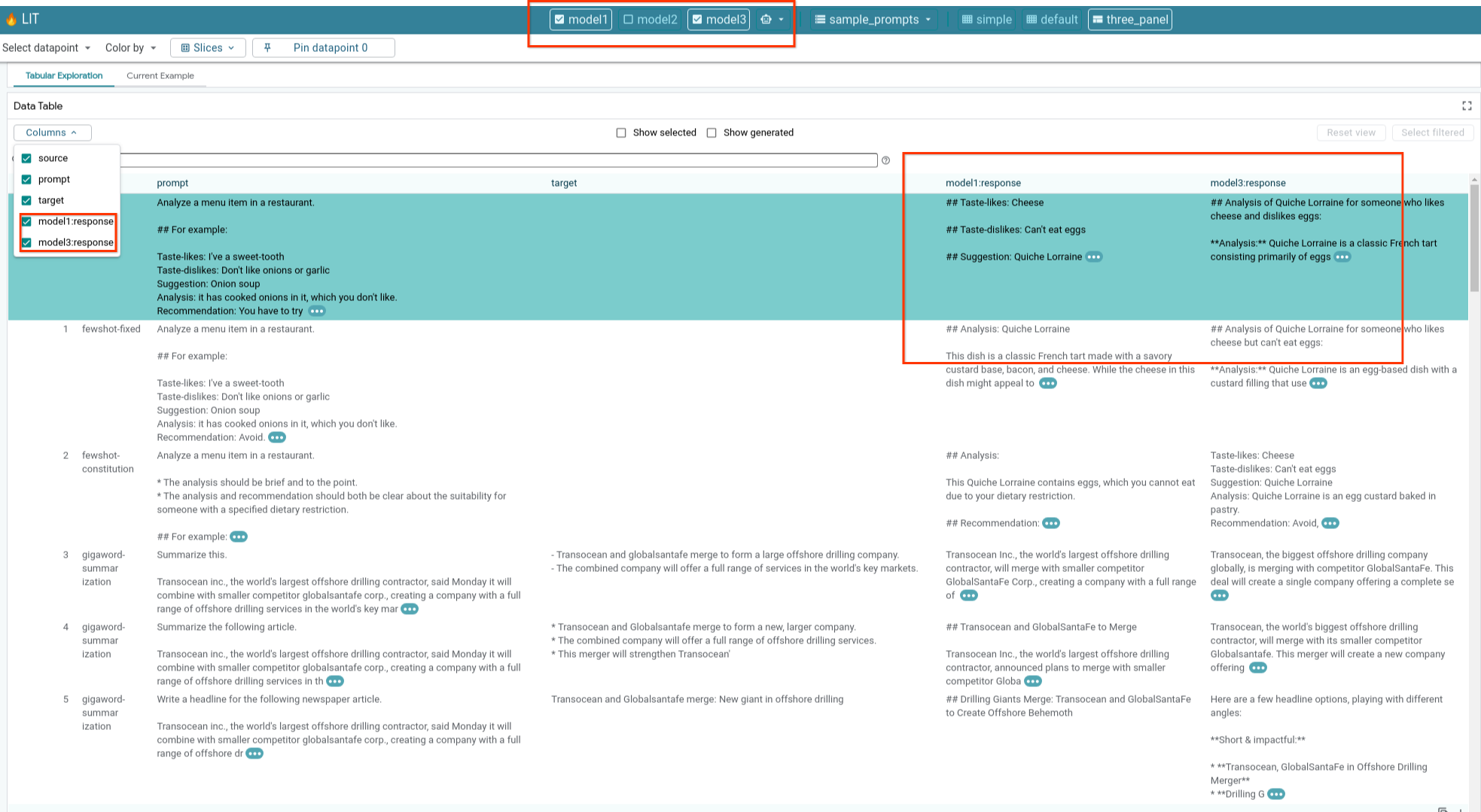
6e. Porównywanie wielu modeli obok siebie
LIT umożliwia porównywanie modeli obok siebie na podstawie poszczególnych przykładów generowania tekstu i oceniania, a także na podstawie zagregowanych przykładów dla określonych danych. Wysyłając zapytania do różnych załadowanych modeli, możesz łatwo porównać różnice w ich odpowiedziach.
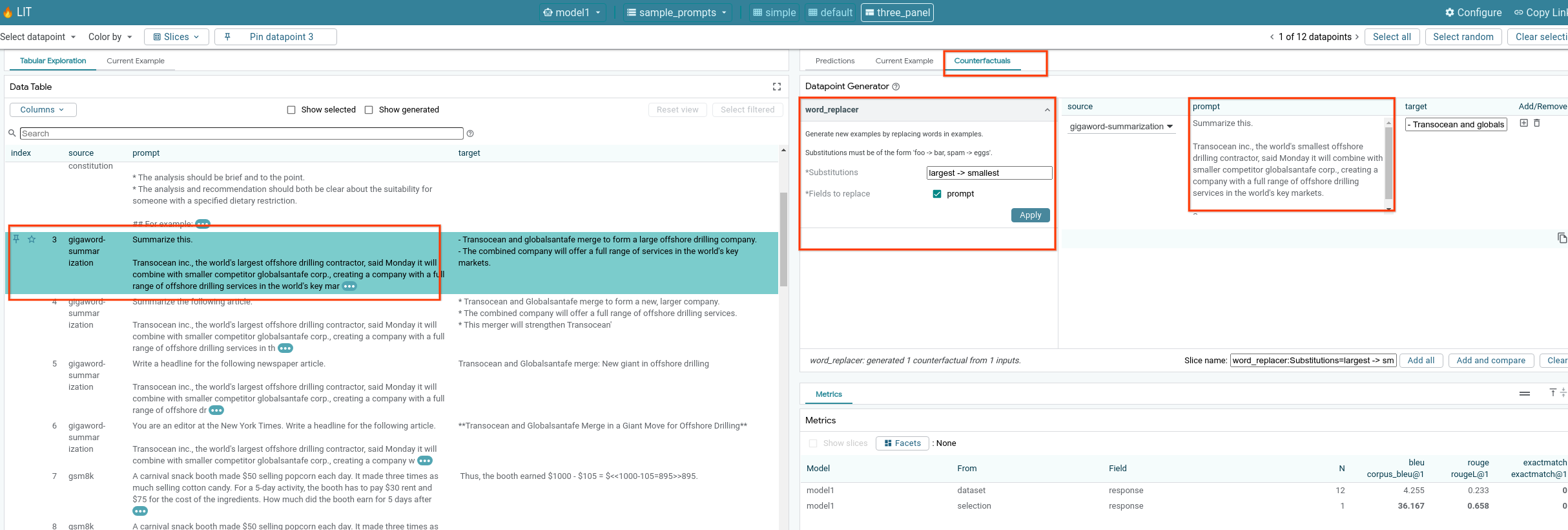
6-f. Automatyczne generatory kontrfaktyczne
Możesz używać automatycznych generatorów kontrfaktycznych, aby tworzyć alternatywne dane wejściowe i od razu sprawdzać, jak model się na nich zachowuje.
6. g. Ocena skuteczności modelu
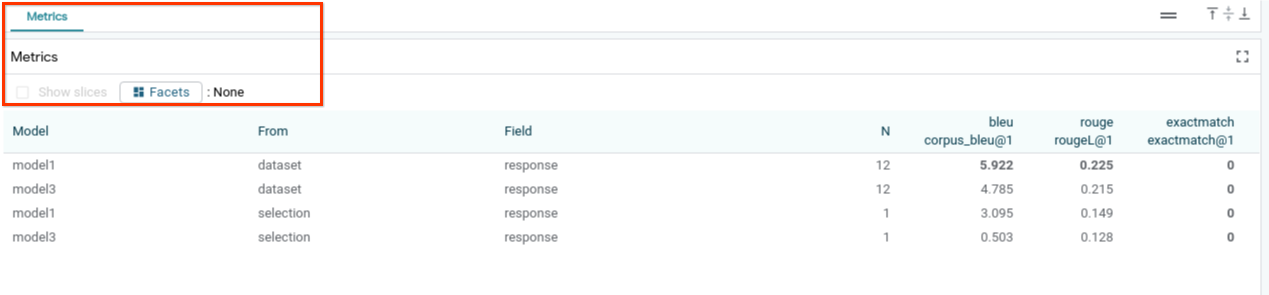
Możesz oceniać wydajność modelu za pomocą danych (obecnie obsługujemy wyniki BLEU i ROUGE w przypadku generowania tekstu) w całym zbiorze danych lub w dowolnych podzbiorach przefiltrowanych lub wybranych przykładów.
7. Rozwiązywanie problemów
7a. Potencjalne problemy z dostępem i rozwiązania
Gdy wdrażasz w Cloud Run, stosowana jest --no-allow-unauthenticated, więc możesz napotkać błędy zabronione, jak pokazano poniżej.

Usługę aplikacji LIT można uzyskać na 2 sposoby.
1. Pośredniczenie w przekazywaniu żądań do usługi lokalnej
Możesz przekierować usługę na hosta lokalnego za pomocą tego polecenia.
# Proxy the service to local host.
gcloud run services proxy $LIT_SERVICE_NAME
Następnie możesz uzyskać dostęp do serwera LIT, klikając link do usługi proxy.
2. Bezpośrednie uwierzytelnianie użytkowników
Aby uwierzytelnić użytkowników i umożliwić im bezpośredni dostęp do usługi LIT App, kliknij ten link. Dzięki temu grupa użytkowników może uzyskać dostęp do usługi. W przypadku prac rozwojowych, w których uczestniczy wiele osób, jest to bardziej efektywne rozwiązanie.
7b. Sprawdź, czy serwer modelu został uruchomiony.
Aby mieć pewność, że serwer modelu został uruchomiony prawidłowo, możesz wysłać żądanie bezpośrednio do serwera modelu. Serwer modelu udostępnia 3 punkty końcowe: predict, tokenize i salience. W prośbie podaj zarówno pole prompt, jak i pole target.
# Query the model server predict endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/predict -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server tokenize endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/tokenize -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server salience endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/salience -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
Jeśli napotkasz problem z dostępem, zapoznaj się z sekcją 7a powyżej.
8. Gratulacje
Gratulujemy ukończenia ćwiczeń z programowania. Czas na relaks.
Czyszczenie danych
Aby wyczyścić środowisko, usuń wszystkie usługi Google Cloud utworzone na potrzeby tego ćwiczenia. Uruchom te polecenia w Google Cloud Shell.
Jeśli połączenie z Google Cloud zostanie utracone z powodu braku aktywności, zresetuj zmienne, wykonując poprzednie czynności.
# Delete the LIT App Service.
gcloud run services delete $LIT_SERVICE_NAME
Jeśli serwer modelu został uruchomiony, musisz go też usunąć.
# Delete the Model Service.
gcloud run services delete $MODEL_SERVICE_NAME
Więcej informacji
Aby dowiedzieć się więcej o funkcjach narzędzia LIT, zapoznaj się z tymi materiałami:
- Gemma: Link
- Baza kodu open source LIT: repozytorium Git
- Artykuł o LIT: ArXiv
- Artykuł o debugowaniu promptów LIT: ArXiv
- Film demonstracyjny funkcji LIT: YouTube
- Prezentacja debugowania promptów LIT: YouTube
- Zestaw narzędzi odpowiedzialnej generatywnej AI: link
Kontakt
Jeśli masz pytania lub problemy dotyczące tego ćwiczenia, skontaktuj się z nami na GitHub.
Licencja
Ten utwór jest dostępny na licencji Creative Commons Uznanie autorstwa 4.0.