
1. Ringkasan
Lab ini memberikan panduan mendetail tentang men-deploy server aplikasi LIT di Google Cloud Platform (GCP) untuk berinteraksi dengan model dasar Gemini Vertex AI dan model bahasa besar (LLM) pihak ketiga yang dihosting sendiri. Panduan ini juga mencakup cara menggunakan UI LIT untuk proses debug perintah dan interpretasi model.
Dengan mengikuti lab ini, pengguna akan mempelajari cara:
- Konfigurasi server LIT di GCP.
- Hubungkan server LIT ke model Gemini Vertex AI atau LLM yang dihosting sendiri lainnya.
- Gunakan UI LIT untuk menganalisis, men-debug, dan menafsirkan perintah untuk mendapatkan performa dan insight model yang lebih baik.
Apa itu LIT?
LIT adalah alat pemahaman model yang visual dan interaktif yang mendukung data teks, gambar, dan tabulasi. Server ini dapat dijalankan sebagai server mandiri, atau di dalam lingkungan notebook seperti Google Colab, Jupyter, dan Google Cloud Vertex AI. LIT tersedia dari PyPI dan GitHub.
Awalnya dibuat untuk memahami model klasifikasi dan regresi, update terbaru telah menambahkan alat untuk men-debug perintah LLM sehingga Anda dapat mempelajari pengaruh konten pengguna, model, dan sistem terhadap perilaku pembuatan.
Apa itu Vertex AI dan Model Garden?
Vertex AI adalah platform machine learning (ML) yang memungkinkan Anda melatih dan men-deploy model ML dan aplikasi AI, serta menyesuaikan LLM untuk digunakan dalam aplikasi yang didukung AI. Vertex AI menggabungkan alur kerja data engineering, data science, dan ML engineering, sehingga tim Anda dapat berkolaborasi menggunakan rangkaian alat yang sama dan menskalakan aplikasi menggunakan manfaat Google Cloud.
Vertex Model Garden adalah library model ML yang membantu Anda menemukan, menguji, menyesuaikan, dan men-deploy model dan aset eksklusif Google serta pihak ketiga tertentu.
Yang akan Anda lakukan
Anda akan menggunakan Cloud Shell dan Cloud Run Google untuk men-deploy container Docker dari image yang telah dibuat sebelumnya oleh LIT.
Cloud Run adalah platform komputasi terkelola yang memungkinkan Anda menjalankan container langsung di atas infrastruktur Google yang bersifat skalabel, termasuk di GPU.
Set data
Secara default, demo menggunakan set data sampel debug perintah LIT, atau Anda dapat memuat set data Anda sendiri melalui UI.
Sebelum memulai
Untuk panduan referensi ini, Anda memerlukan project Google Cloud. Anda dapat membuat project baru atau memilih project yang sudah dibuat.
2. Luncurkan Konsol Google Cloud dan Cloud Shell
Anda akan meluncurkan Konsol Google Cloud dan menggunakan Google Cloud Shell pada langkah ini.
2-a: Luncurkan Konsol Google Cloud
Buka browser dan buka Konsol Google Cloud.
Konsol Google Cloud adalah antarmuka admin web yang canggih dan aman yang memungkinkan Anda mengelola resource Google Cloud dengan cepat. Ini adalah alat DevOps yang dapat digunakan kapan saja di mana saja.
2-b: Luncurkan Google Cloud Shell
Cloud Shell adalah lingkungan operasi dan pengembangan online yang dapat diakses di mana saja melalui browser Anda. Anda dapat mengelola resource dengan terminal online yang telah dilengkapi dengan utilitas seperti alat command line gcloud, kubectl, dan lainnya. Anda juga dapat mengembangkan, membangun, men-debug, dan men-deploy APLIKASI berbasis cloud menggunakan Cloud Shell Editor online. Cloud Shell menyediakan lingkungan online yang siap digunakan developer dengan set alat favorit yang telah diinstal sebelumnya dan ruang penyimpanan persisten sebesar 5 GB. Anda akan menggunakan command prompt pada langkah berikutnya.
Luncurkan Google Cloud Shell menggunakan ikon di kanan atas panel menu, yang dilingkari warna biru pada screenshot berikut.

Anda akan melihat terminal dengan shell Bash di bagian bawah halaman.

2-c: Setel Project Google Cloud
Anda harus menetapkan project ID dan region project menggunakan perintah gcloud.
# Set your GCP Project ID.
gcloud config set project your-project-id
# Set your GCP Project Region.
gcloud config set run/region your-project-region
3. Men-deploy Image Docker Server Aplikasi LIT dengan Cloud Run
3-a: Deploy Aplikasi LIT ke Cloud Run
Pertama, Anda perlu menetapkan versi terbaru LIT-App sebagai versi yang akan di-deploy.
# Set latest version as your LIT_SERVICE_TAG.
export LIT_SERVICE_TAG=latest
# List all the public LIT GCP App server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app
Setelah menetapkan tag versi, Anda perlu memberi nama layanan.
# Set your lit service name. While 'lit-app-service' is provided as a placeholder, you can customize the service name based on your preferences.
export LIT_SERVICE_NAME=lit-app-service
Setelah itu, Anda dapat menjalankan perintah berikut untuk men-deploy container ke Cloud Run.
# Use below cmd to deploy the LIT App to Cloud Run.
gcloud run deploy $LIT_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app:$LIT_SERVICE_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--no-allow-unauthenticated
LIT juga memungkinkan Anda menambahkan set data saat memulai server. Untuk melakukannya, tetapkan variabel DATASETS agar menyertakan data yang ingin Anda muat, menggunakan format name:path, misalnya, data_foo:/bar/data_2024.jsonl. Format set data harus .jsonl, dengan setiap data berisi kolom prompt dan kolom target serta source opsional. Untuk memuat beberapa set data, pisahkan dengan koma. Jika tidak ditetapkan, dataset sampel untuk proses debug perintah LIT akan dimuat.
# Set the dataset.
export DATASETS=[DATASETS]
Dengan menetapkan MAX_EXAMPLES, Anda dapat menetapkan jumlah maksimum contoh yang akan dimuat dari setiap set evaluasi.
# Set the max examples.
export MAX_EXAMPLES=[MAX_EXAMPLES]
Kemudian, di perintah deployment, Anda dapat menambahkan
--set-env-vars "DATASETS=$DATASETS" \
--set-env-vars "MAX_EXAMPLES=$MAX_EXAMPLES" \
3-b: Melihat Layanan Aplikasi LIT
Setelah membuat server Aplikasi LIT, Anda dapat menemukan layanan di bagian Cloud Run di Konsol Cloud.
Pilih layanan LIT App yang baru saja Anda buat. Pastikan nama layanan sama dengan LIT_SERVICE_NAME.
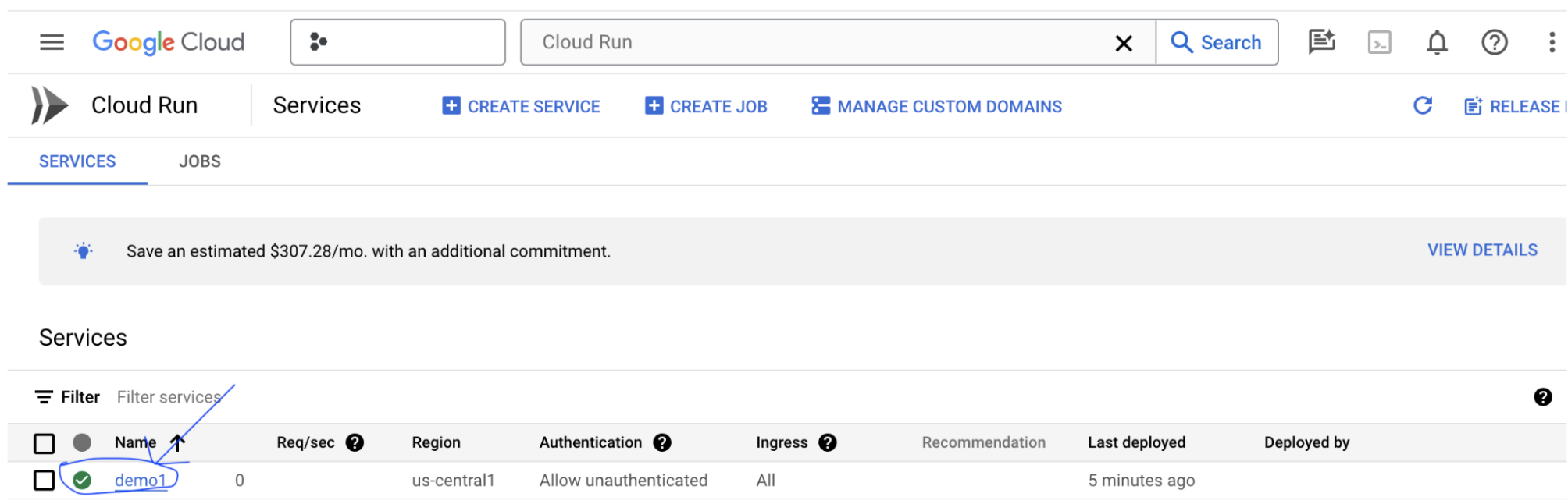
Anda dapat menemukan URL layanan dengan mengklik layanan yang baru saja di-deploy.
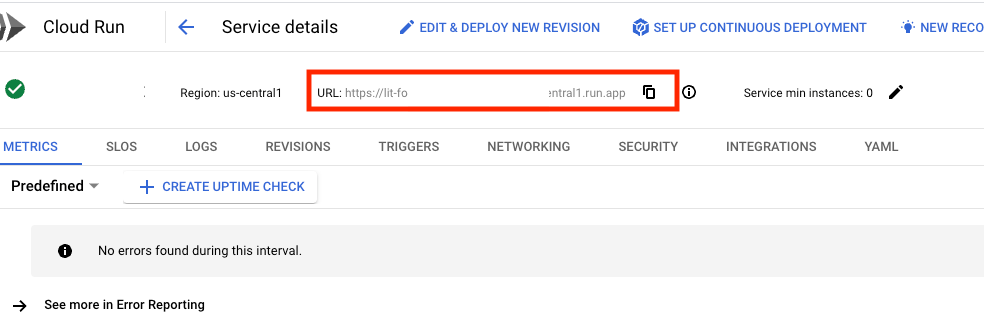
Kemudian, Anda akan dapat melihat UI LIT. Jika Anda mengalami error, lihat bagian Pemecahan masalah.
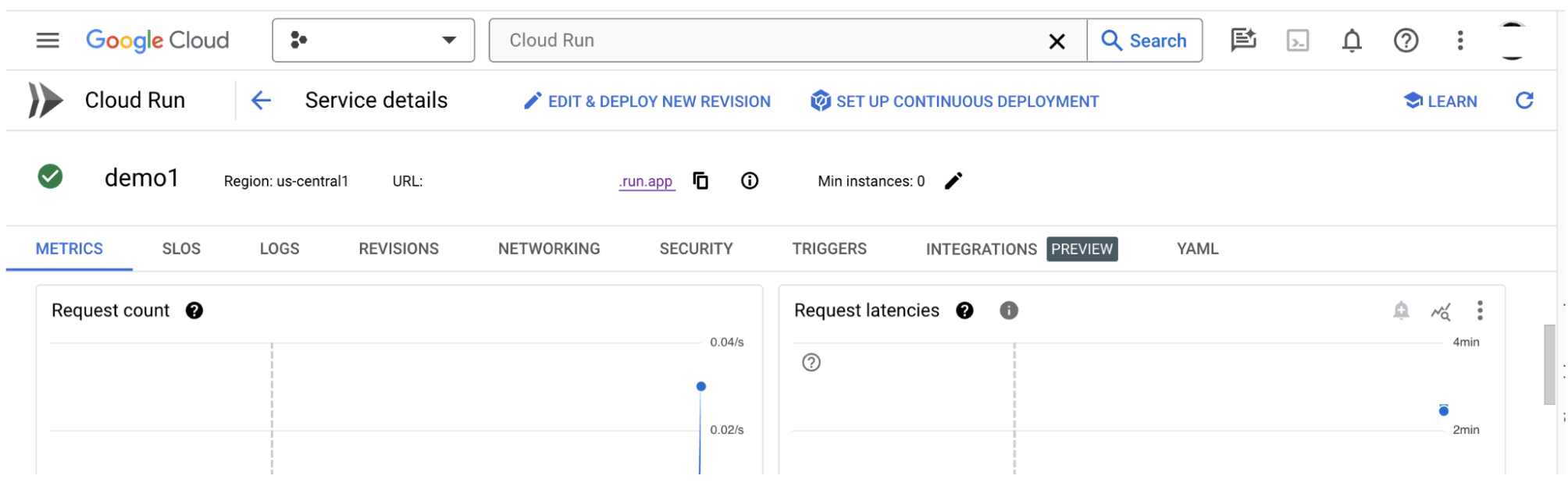
Anda dapat memeriksa bagian LOG untuk memantau aktivitas, melihat pesan error, dan melacak progres deployment.
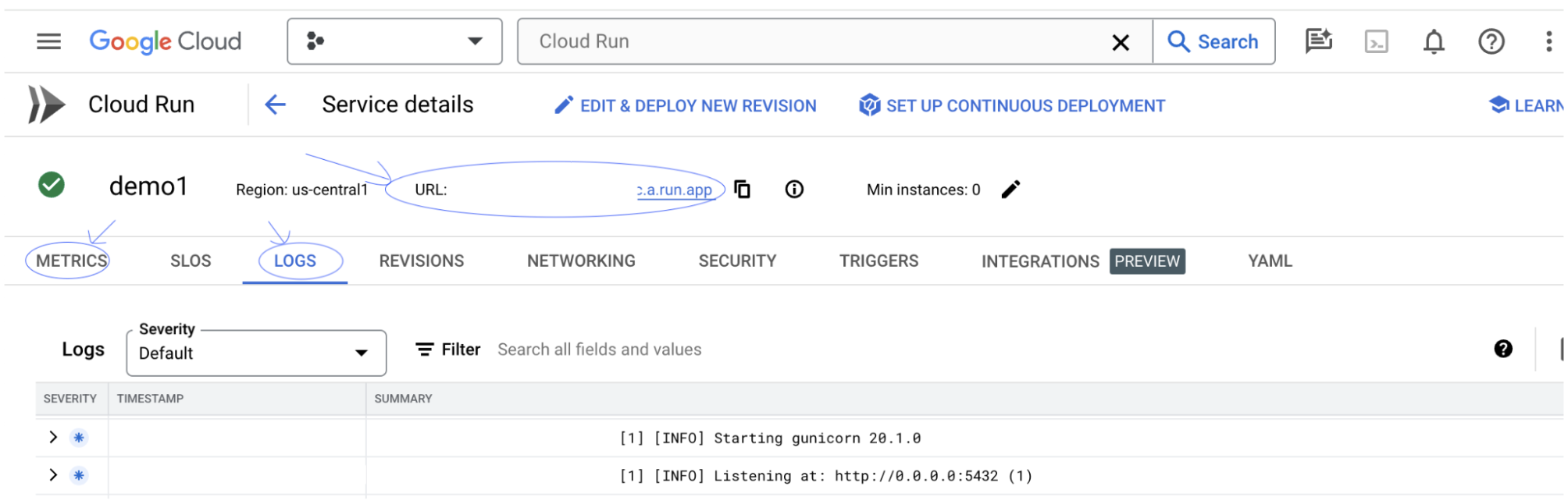
Anda dapat memeriksa bagian METRICS untuk melihat metrik layanan.
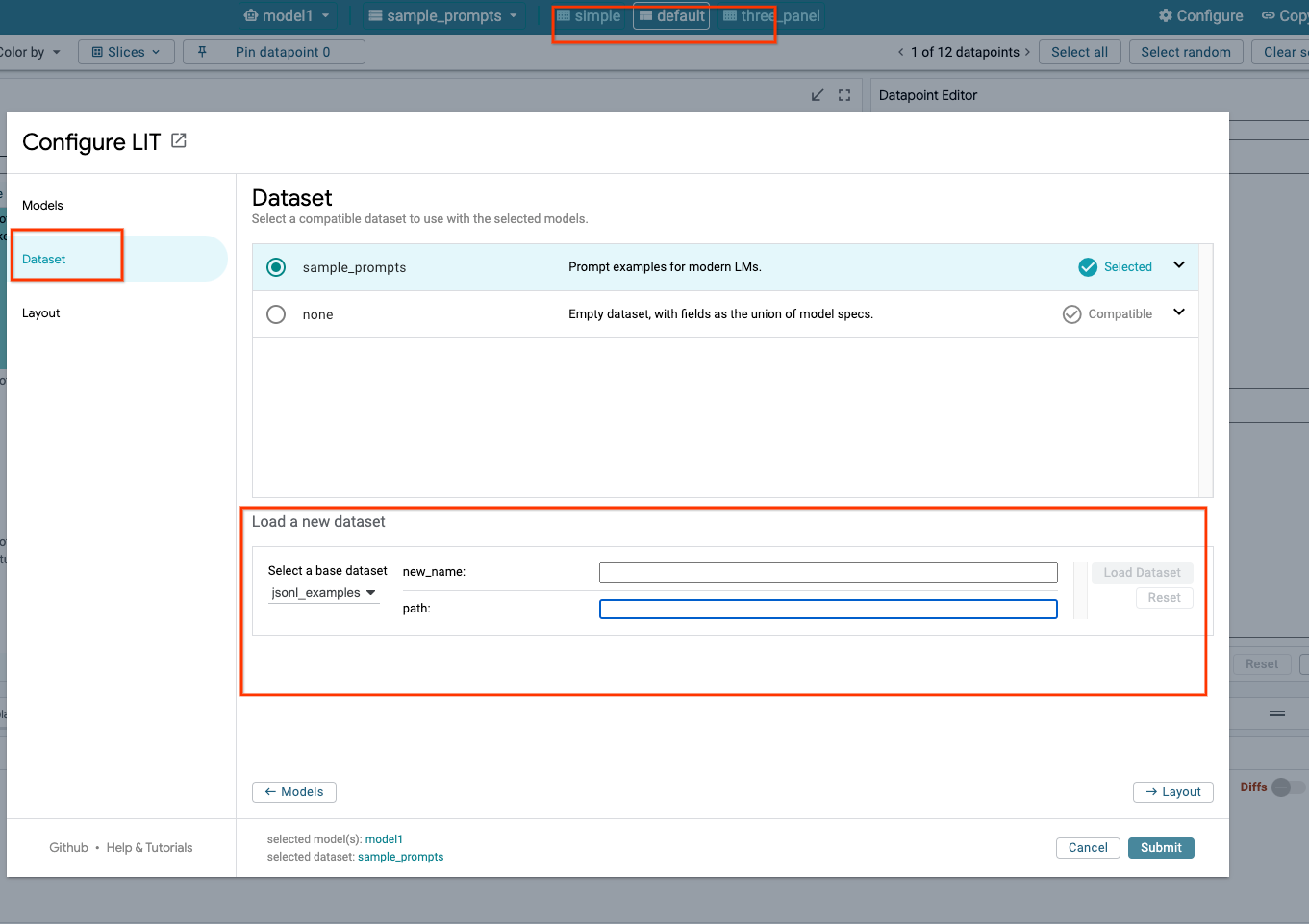
3-c: Memuat Set Data
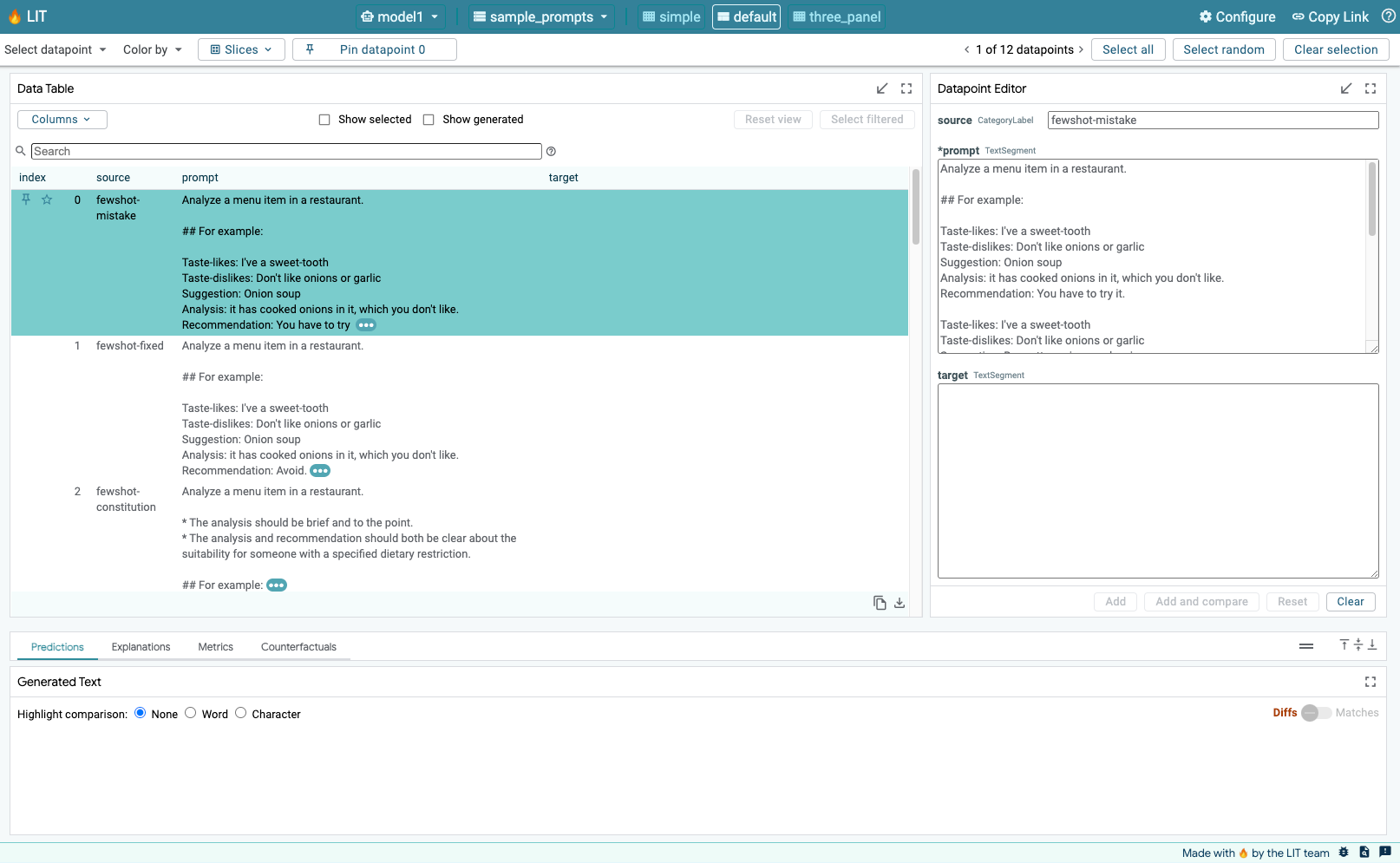
Klik opsi Configure di UI LIT, pilih Dataset. Muat set data dengan menentukan nama dan memberikan URL set data. Format set data harus .jsonl, dengan setiap data berisi kolom prompt dan kolom target serta source opsional.
4. Menyiapkan Model Gemini di Model Garden Vertex AI
Model dasar Gemini Google tersedia dari Vertex AI API. LIT menyediakan wrapper model VertexAIModelGarden untuk menggunakan model ini dalam pembuatan. Cukup tentukan versi yang diinginkan (misalnya, "gemini-1.5-pro-001") melalui parameter nama model. Keuntungan utama menggunakan model ini adalah tidak memerlukan upaya tambahan untuk deployment. Secara default, Anda memiliki akses langsung ke model seperti Gemini 1.0 Pro dan Gemini 1.5 Pro di GCP, sehingga tidak memerlukan langkah-langkah konfigurasi tambahan.
4-a: Berikan Izin Vertex AI
Untuk membuat kueri Gemini di GCP, Anda harus memberikan izin Vertex AI ke akun layanan. Pastikan nama akun layanan adalah Default compute service account. Salin email akun layanan.
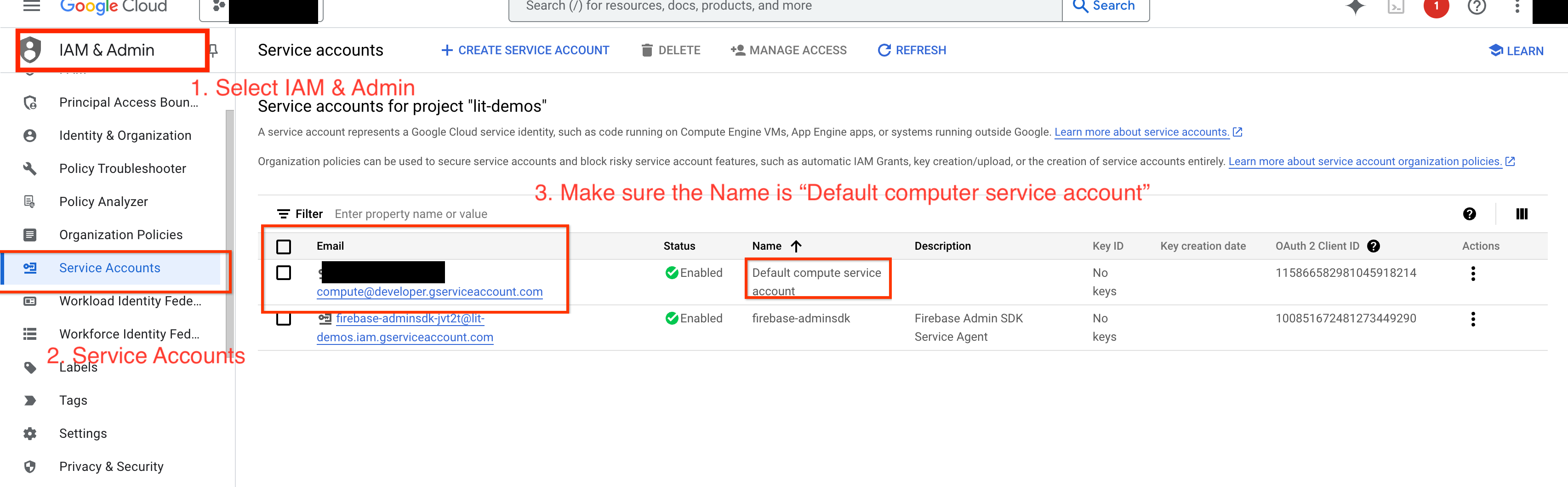
Tambahkan email akun layanan sebagai akun utama dengan peran Vertex AI User di daftar yang diizinkan IAM Anda.

4-b: Memuat Model Gemini
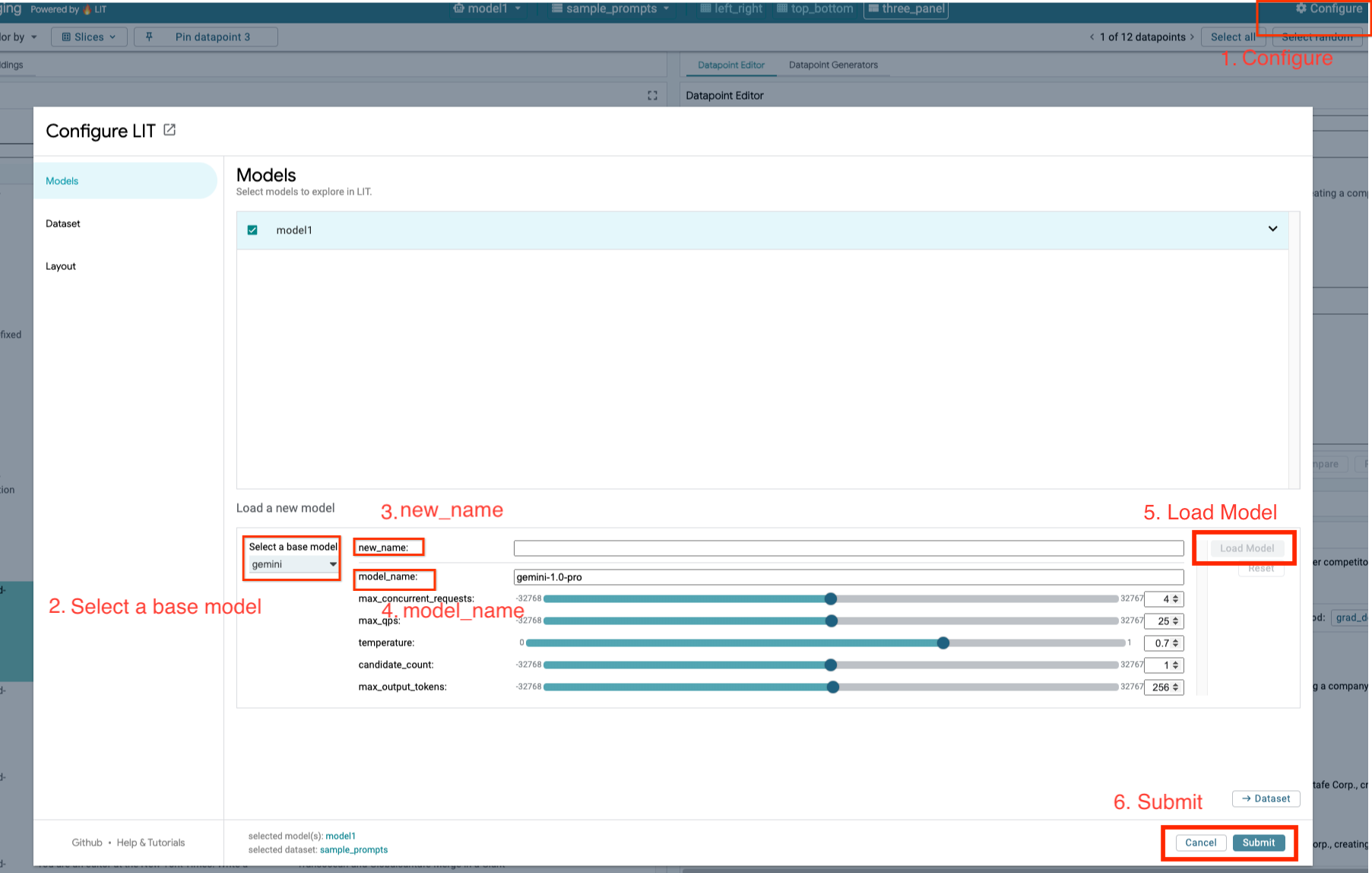
Anda akan memuat model Gemini dan menyesuaikan parameternya dengan mengikuti langkah-langkah di bawah.
- Klik opsi
Configuredi UI LIT.
- Klik opsi
- Pilih opsi
geminidi bagian opsiSelect a base model.
- Pilih opsi
- Anda perlu memberi nama model di
new_name.
- Anda perlu memberi nama model di
- Masukkan model gemini yang Anda pilih sebagai
model_name.
- Masukkan model gemini yang Anda pilih sebagai
- Klik
Load Model.
- Klik
- Klik
Submit.
- Klik
5. Men-deploy Server Model LLM yang Dihosting Sendiri di GCP
Dengan menghosting sendiri LLM menggunakan image Docker server model LIT, Anda dapat menggunakan fungsi keunggulan dan tokenisasi LIT untuk mendapatkan insight yang lebih mendalam tentang perilaku model. Image server model berfungsi dengan model KerasNLP atau Hugging Face Transformers, termasuk bobot yang disediakan library dan dihosting sendiri, misalnya, di Google Cloud Storage.
5-a: Mengonfigurasi Model
Setiap container memuat satu model, yang dikonfigurasi menggunakan variabel lingkungan.
Anda harus menentukan model yang akan dimuat dengan menyetel MODEL_CONFIG. Formatnya harus name:path, misalnya model_foo:model_foo_path. Jalur dapat berupa URL, jalur file lokal, atau nama preset untuk framework Deep Learning yang dikonfigurasi (lihat tabel berikut untuk mengetahui informasi selengkapnya). Server ini diuji dengan Gemma, GPT2, Llama, dan Mistral pada semua nilai DL_FRAMEWORK yang didukung. Model lain akan berfungsi, tetapi penyesuaian mungkin diperlukan.
# Set models you want to load. While 'gemma2b is given as a placeholder, you can load your preferred model by following the instructions above.
export MODEL_CONFIG=gemma2b:gemma_2b_en
Selain itu, server model LIT memungkinkan konfigurasi berbagai variabel lingkungan menggunakan perintah di bawah. Lihat tabel untuk mengetahui detailnya. Perhatikan bahwa setiap variabel harus disetel satu per satu.
# Customize the variable value as needed.
export [VARIABLE]=[VALUE]
Variabel | Nilai | Deskripsi |
DL_FRAMEWORK |
| Library pemodelan yang digunakan untuk memuat bobot model ke runtime yang ditentukan. Default-nya adalah |
DL_RUNTIME |
| Framework backend deep learning tempat model berjalan. Semua model yang dimuat oleh server ini akan menggunakan backend yang sama, dan ketidakcocokan akan menyebabkan error. Default-nya adalah |
PRESISI |
| Presisi floating point untuk model LLM. Default-nya adalah |
BATCH_SIZE | Bilangan Bulat Positif | Jumlah contoh yang akan diproses per batch. Default-nya adalah |
SEQUENCE_LENGTH | Bilangan Bulat Positif | Panjang urutan maksimum dari perintah input ditambah teks yang dihasilkan. Default-nya adalah |
5-b: Men-deploy Server Model ke Cloud Run
Pertama, Anda perlu menetapkan versi terbaru Model Server sebagai versi yang akan di-deploy.
# Set latest as MODEL_VERSION_TAG.
export MODEL_VERSION_TAG=latest
# List all the public LIT GCP model server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server
Setelah menetapkan tag versi, Anda perlu memberi nama server model.
# Set your Service name.
export MODEL_SERVICE_NAME='gemma2b-model-server'
Setelah itu, Anda dapat menjalankan perintah berikut untuk men-deploy container ke Cloud Run. Jika Anda tidak menyetel variabel lingkungan, nilai default akan diterapkan. Karena sebagian besar LLM memerlukan resource komputasi yang mahal, sangat direkomendasikan untuk menggunakan GPU. Jika Anda lebih memilih untuk menjalankan hanya di CPU (yang berfungsi dengan baik untuk model kecil seperti GPT2), Anda dapat menghapus argumen terkait --gpu 1 --gpu-type nvidia-l4 --max-instances 7.
# Deploy the model service container.
gcloud beta run deploy $MODEL_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server:$MODEL_VERSION_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 7 \
--set-env-vars "MODEL_CONFIG=$MODEL_CONFIG" \
--no-allow-unauthenticated
Selain itu, Anda dapat menyesuaikan variabel lingkungan dengan menambahkan perintah berikut. Hanya sertakan variabel lingkungan yang diperlukan untuk kebutuhan spesifik Anda.
--set-env-vars "DL_FRAMEWORK=$DL_FRAMEWORK" \
--set-env-vars "DL_RUNTIME=$DL_RUNTIME" \
--set-env-vars "PRECISION=$PRECISION" \
--set-env-vars "BATCH_SIZE=$BATCH_SIZE" \
--set-env-vars "SEQUENCE_LENGTH=$SEQUENCE_LENGTH" \
Variabel lingkungan tambahan mungkin diperlukan untuk mengakses model tertentu. Lihat petunjuk dari Kaggle Hub (digunakan untuk model KerasNLP) dan Hugging Face Hub sebagaimana mestinya.
5-c: Akses Server Model
Setelah membuat server model, layanan yang dimulai dapat ditemukan di bagian Cloud Run project GCP Anda.
Pilih server model yang baru saja Anda buat. Pastikan nama layanan sama dengan MODEL_SERVICE_NAME.
Anda dapat menemukan URL layanan dengan mengklik layanan model yang baru saja di-deploy.
Anda dapat memeriksa bagian LOG untuk memantau aktivitas, melihat pesan error, dan melacak progres deployment.
Anda dapat memeriksa bagian METRICS untuk melihat metrik layanan.
5-d: Memuat Model yang Dihosting Sendiri
Jika Anda mem-proxy server LIT di Langkah 3 (lihat bagian Pemecahan Masalah), Anda harus mendapatkan token identitas GCP dengan menjalankan perintah berikut.
# Find your GCP identity token.
gcloud auth print-identity-token
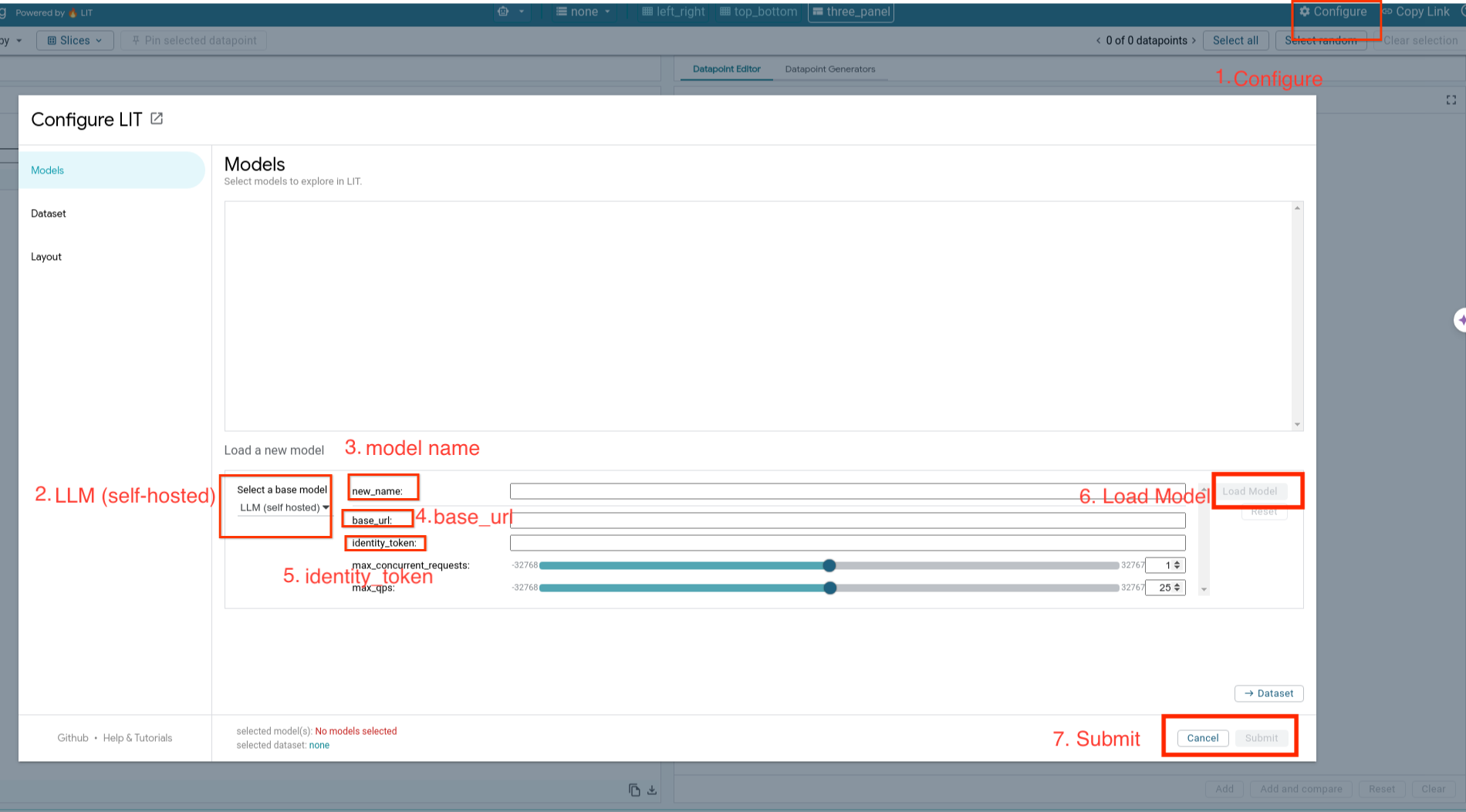
Anda akan memuat model yang dihosting sendiri dan menyesuaikan parameternya dengan mengikuti langkah-langkah di bawah.
- Klik opsi
Configuredi UI LIT. - Pilih opsi
LLM (self hosted)di bagian opsiSelect a base model. - Anda perlu memberi nama model di
new_name. - Masukkan URL server model Anda sebagai
base_url. - Masukkan token identitas yang diperoleh di
identity_tokenjika Anda memproksi server Aplikasi LIT (Lihat Langkah 3 dan Langkah 7). Jika tidak, biarkan kosong. - Klik
Load Model. - Klik
Submit.
6. Berinteraksi dengan LIT di GCP
LIT menawarkan serangkaian fitur lengkap untuk membantu Anda men-debug dan memahami perilaku model. Anda dapat melakukan hal sederhana seperti membuat kueri model, dengan mengetik teks dalam kotak dan melihat prediksi model, atau memeriksa model secara mendalam dengan serangkaian fitur canggih LIT, termasuk:
6-a: Mengirim Kueri ke Model melalui LIT
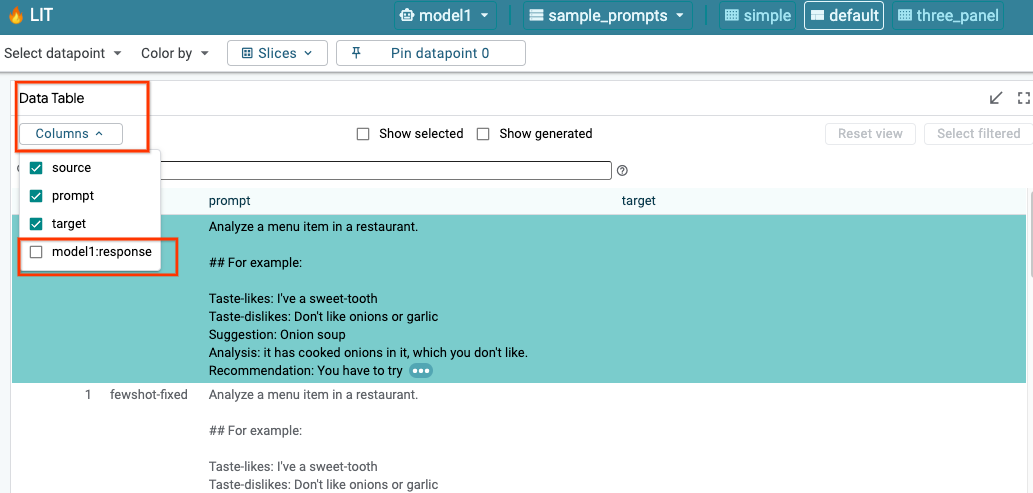
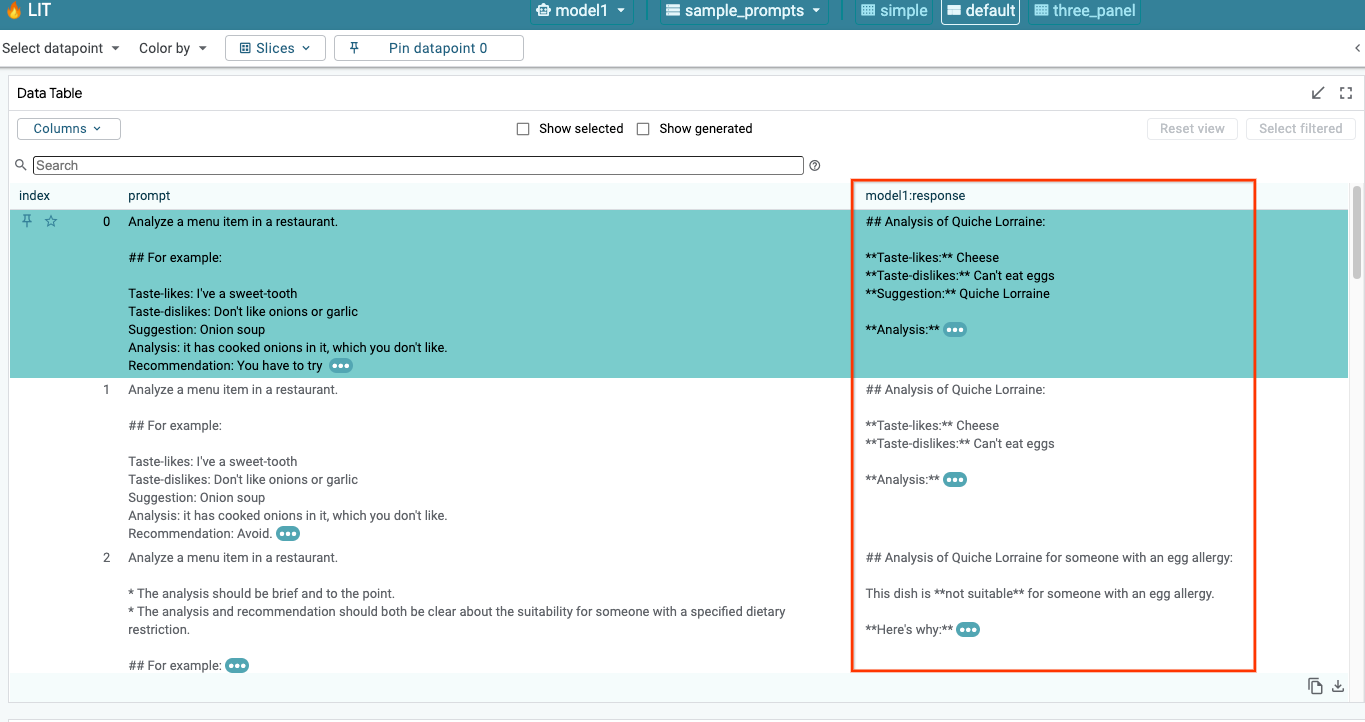
LIT akan otomatis membuat kueri set data setelah pemuatan model dan set data. Anda dapat melihat respons setiap model dengan memilih respons di kolom.
6-b: Menggunakan Teknik Keunggulan Urutan
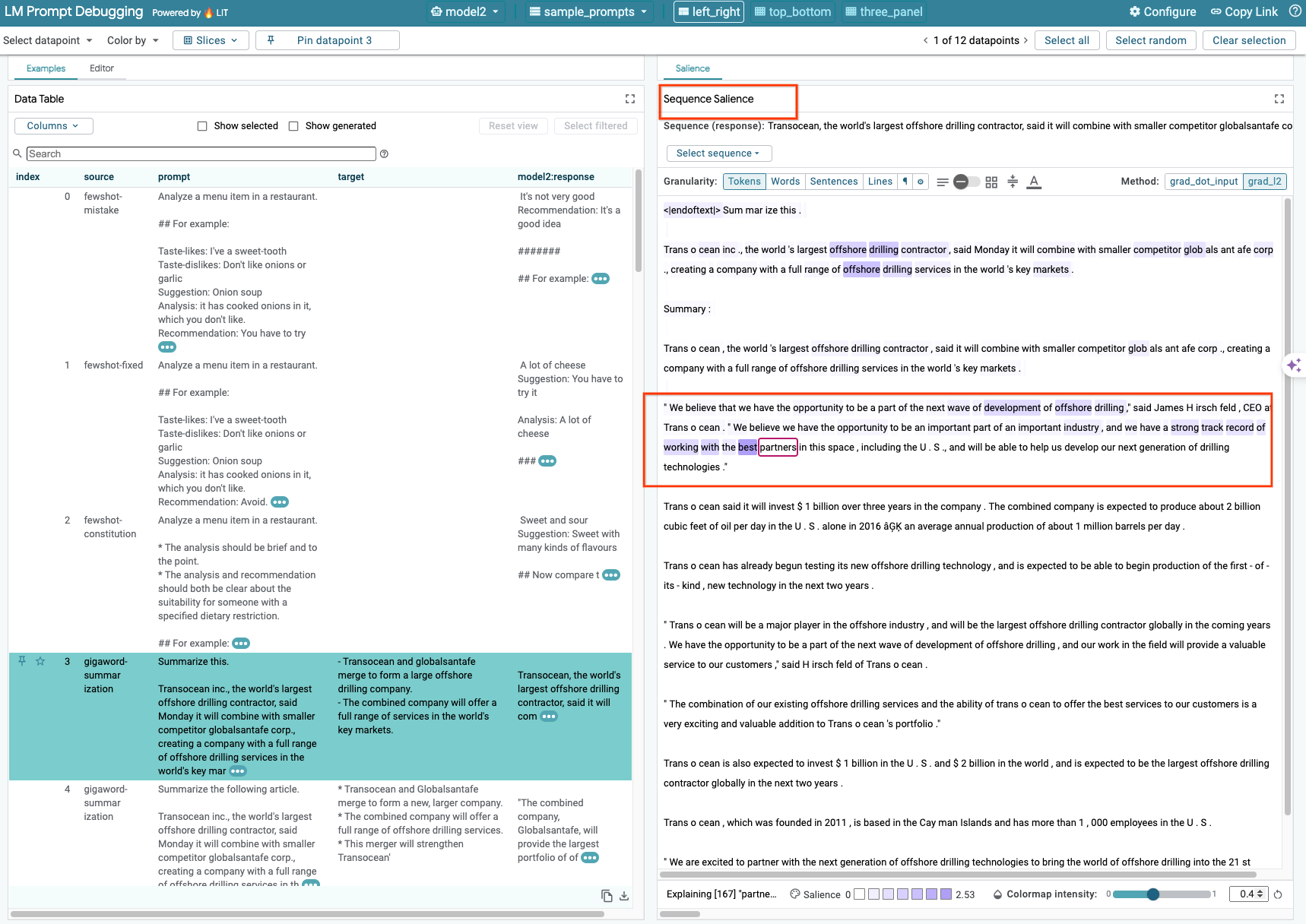
Saat ini, teknik Sequence Salience di LIT hanya mendukung model yang dihosting sendiri.
Keunggulan Urutan adalah alat visual yang membantu men-debug perintah LLM dengan menandai bagian perintah yang paling penting untuk output tertentu. Untuk mengetahui informasi selengkapnya tentang Keunggulan Urutan, lihat tutorial lengkap untuk mengetahui lebih lanjut cara menggunakan fitur ini.
Untuk mengakses hasil keutamaan, klik input atau output apa pun dalam perintah atau respons, dan hasil keutamaan akan ditampilkan.
6-c: Mengedit Perintah dan Target Secara Manual
LIT memungkinkan Anda mengedit prompt dan target secara manual untuk titik data yang ada. Dengan mengklik Add, input baru akan ditambahkan ke set data.
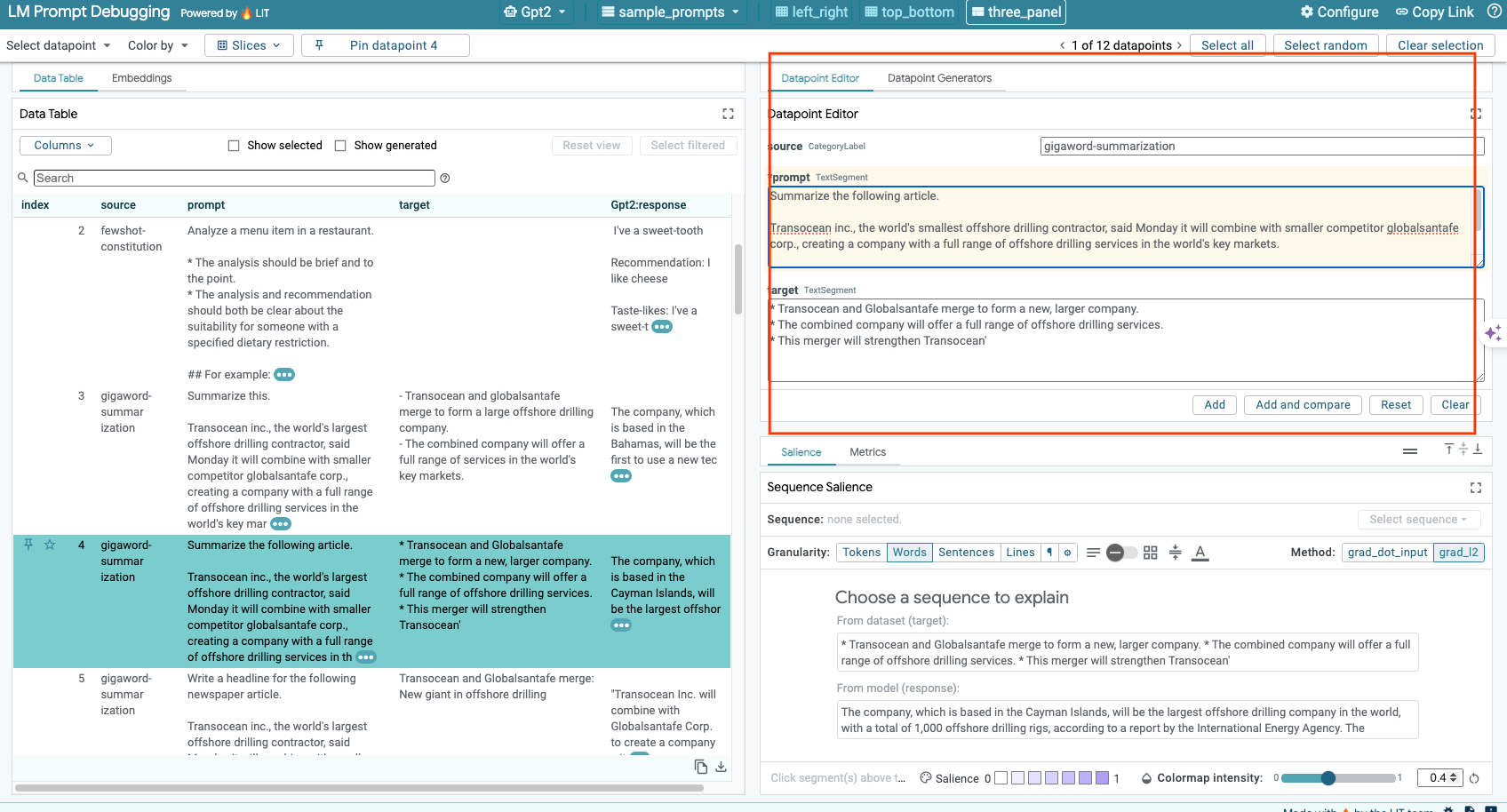
6-d: Membandingkan Perintah Berdampingan
LIT memungkinkan Anda membandingkan perintah secara berdampingan pada contoh asli dan yang telah diedit. Anda dapat mengedit contoh secara manual dan melihat hasil prediksi serta analisis Keunggulan Urutan untuk versi asli dan versi yang diedit secara bersamaan. Anda dapat mengubah perintah untuk setiap titik data, dan LIT akan menghasilkan respons yang sesuai dengan membuat kueri model.
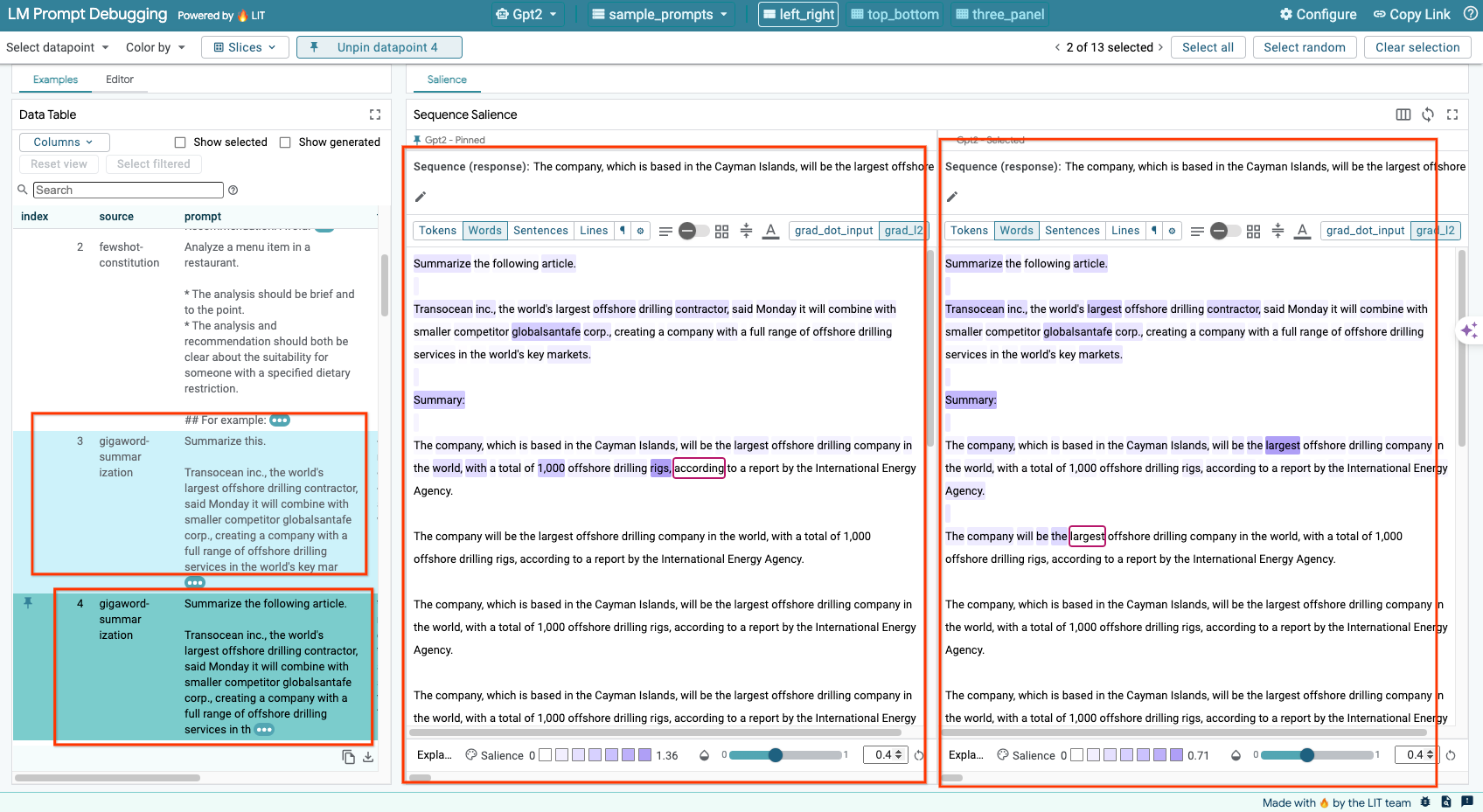
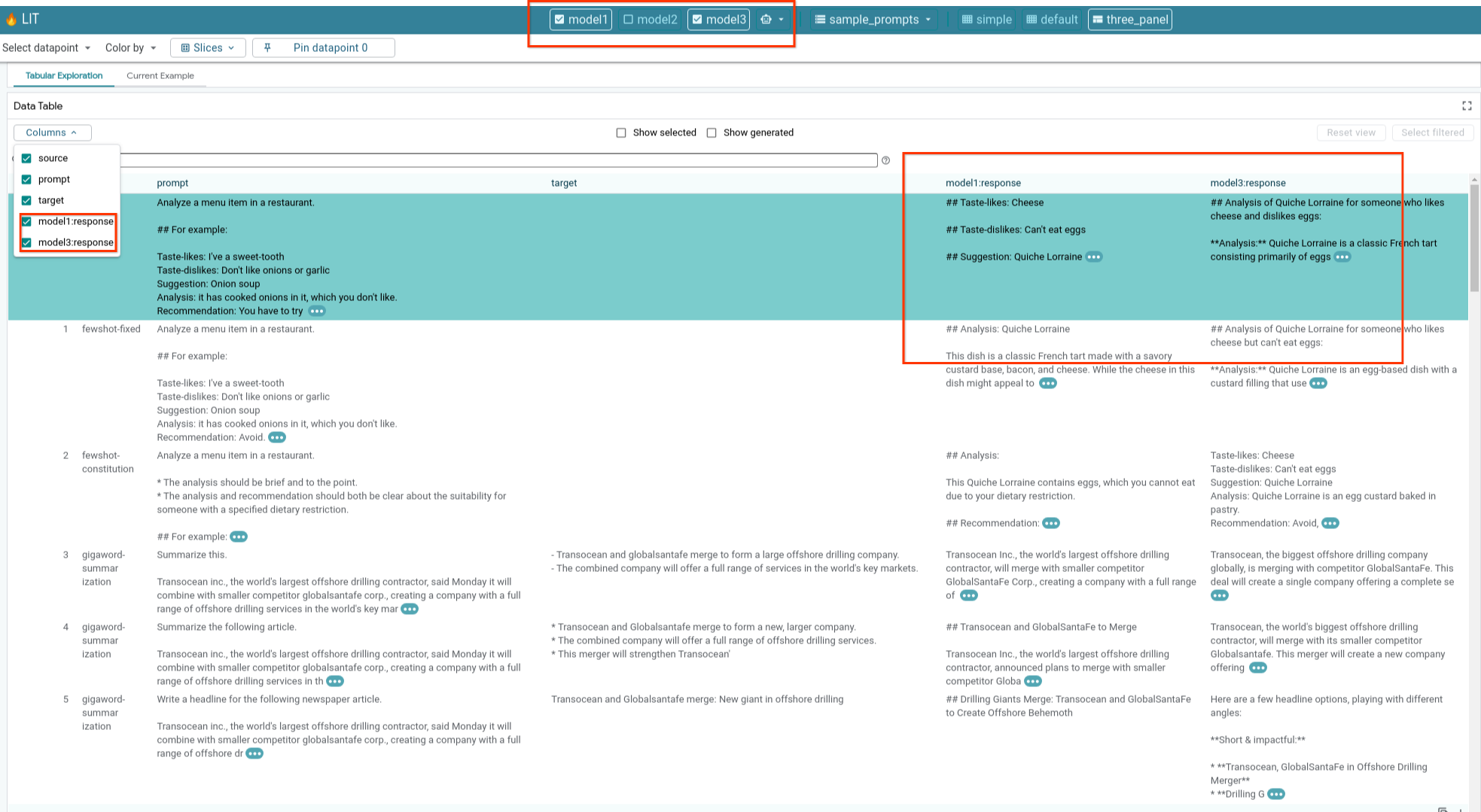
6-e: Membandingkan Beberapa Model secara Berdampingan
LIT memungkinkan perbandingan model secara berdampingan pada contoh pembuatan dan pemberian skor teks individual, serta pada contoh gabungan untuk metrik tertentu. Dengan membuat kueri berbagai model yang dimuat, Anda dapat dengan mudah membandingkan perbedaan dalam responsnya.
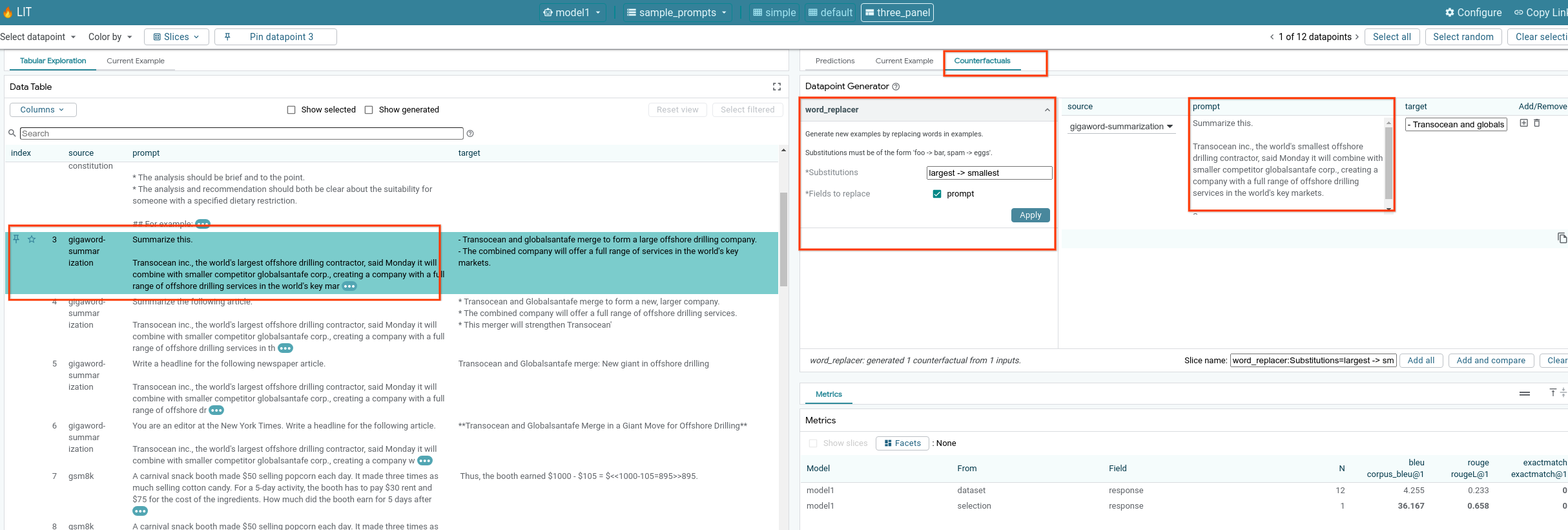
6-f: Generator Kontrafaktual Otomatis
Anda dapat menggunakan generator kontrafaktual otomatis untuk membuat input alternatif, dan langsung melihat perilaku model Anda pada input tersebut.
6-g: Mengevaluasi performa model
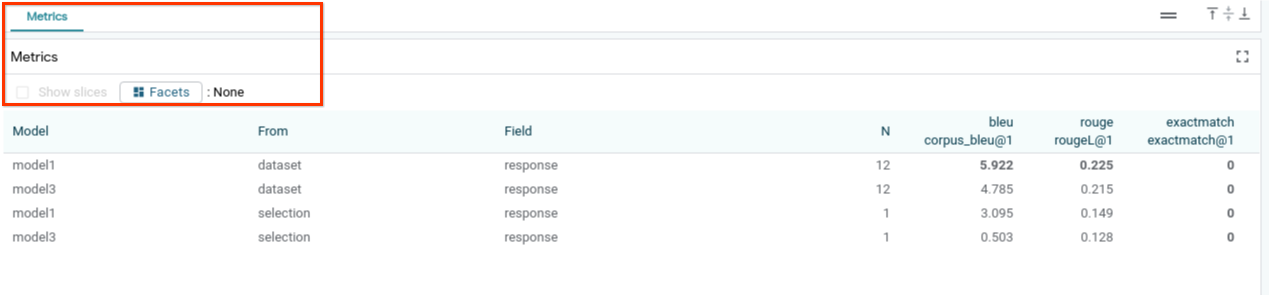
Anda dapat menilai performa model menggunakan metrik (saat ini mendukung skor BLEU dan ROUGE untuk pembuatan teks) di seluruh set data, atau subkumpulan contoh yang difilter atau dipilih.
7. Pemecahan masalah
7-a: Kemungkinan masalah akses dan solusinya
Karena --no-allow-unauthenticated diterapkan saat men-deploy ke Cloud Run, Anda mungkin mengalami error terlarang seperti yang ditunjukkan di bawah.

Ada dua pendekatan untuk mengakses layanan Aplikasi LIT.
1. Proxy ke Layanan Lokal
Anda dapat melakukan proxy layanan ke host lokal menggunakan perintah di bawah.
# Proxy the service to local host.
gcloud run services proxy $LIT_SERVICE_NAME
Kemudian, Anda akan dapat mengakses server LIT dengan mengklik link layanan yang di-proxy.
2. Mengautentikasi Pengguna Secara Langsung
Anda dapat membuka link ini untuk mengautentikasi pengguna, sehingga memungkinkan akses langsung ke layanan Aplikasi LIT. Pendekatan ini juga dapat memungkinkan sekelompok pengguna mengakses layanan. Untuk pengembangan yang melibatkan kolaborasi dengan banyak orang, opsi ini lebih efektif.
7-b: Pemeriksaan untuk memastikan Server Model telah berhasil diluncurkan
Untuk memastikan server model telah diluncurkan dengan berhasil, Anda dapat langsung membuat kueri server model dengan mengirimkan permintaan. Server model menyediakan tiga endpoint, predict, tokenize, dan salience. Pastikan Anda memberikan kolom prompt dan target dalam permintaan Anda.
# Query the model server predict endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/predict -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server tokenize endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/tokenize -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server salience endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/salience -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
Jika Anda mengalami masalah akses, lihat bagian 7-a di atas.
8. Selamat
Selamat, Anda telah menyelesaikan codelab. Saatnya bersantai!
Pembersihan
Untuk membersihkan lab, hapus semua Layanan Google Cloud yang dibuat untuk lab. Gunakan Google Cloud Shell untuk menjalankan perintah berikut.
Jika Koneksi Google Cloud terputus karena tidak ada aktivitas, reset variabel dengan mengikuti langkah-langkah sebelumnya.
# Delete the LIT App Service.
gcloud run services delete $LIT_SERVICE_NAME
Jika Anda memulai server model, Anda juga perlu menghapus server model.
# Delete the Model Service.
gcloud run services delete $MODEL_SERVICE_NAME
Bacaan lebih lanjut
Lanjutkan mempelajari fitur alat LIT dengan materi di bawah ini:
- Gemma: Link
- Dasar kode open source LIT: Repositori Git
- Makalah LIT: ArXiv
- Makalah debug perintah LIT: ArXiv
- Demo video fitur LIT: YouTube
- Demo debug perintah LIT: YouTube
- Toolkit GenAI yang Bertanggung Jawab: Link
Kontak
Jika ada pertanyaan atau masalah terkait codelab ini, hubungi kami di GitHub.
Lisensi
Karya ini dilisensikan berdasarkan Lisensi Umum Creative Commons Attribution 4.0.