
1. 概要
このラボでは、Google Cloud Platform(GCP)に LIT アプリケーション サーバーをデプロイして、Vertex AI Gemini 基盤モデルとセルフホストのサードパーティ製大規模言語モデル(LLM)を操作する方法について詳しく説明します。また、プロンプトのデバッグとモデルの解釈に LIT UI を使用する方法に関するガイダンスも含まれています。
このラボでは、次の方法について学習します。
- GCP で LIT サーバーを構成します。
- LIT サーバーを Vertex AI Gemini モデルまたは他のセルフホスト LLM に接続します。
- LIT UI を使用して、プロンプトを分析、デバッグ、解釈し、モデルのパフォーマンスと分析情報を改善します。
LIT とは
LIT は、テキスト、画像、表形式データをサポートする、視覚的でインタラクティブなモデル理解ツールです。スタンドアロンのサーバーとして実行することも、Google Colab、Jupyter、Google Cloud Vertex AI などのノートブック環境内で実行することもできます。LIT は PyPI と GitHub で入手できます。
元々は分類モデルと回帰モデルを理解するために構築されたものですが、最近のアップデートで LLM プロンプトをデバッグするためのツールが追加され、ユーザー、モデル、システム コンテンツが生成動作にどのように影響するかを調べることができるようになりました。
Vertex AI と Model Garden とは何ですか?
Vertex AI は、ML モデルと AI アプリケーションのトレーニングとデプロイを行い、AI を活用したアプリケーションで使用する LLM をカスタマイズできる ML プラットフォームです。Vertex AI は、データ エンジニアリング、データ サイエンス、ML エンジニアリングのワークフローを統合することで、チームが共通のツールセットを使用して連携し、Google Cloud のメリットを利用したアプリケーションをスケーリングできるようにします。
Vertex Model Garden は、Google 独自のモデルやアセット、厳選されたサードパーティのモデルやアセットの検出、テスト、カスタマイズ、デプロイに役立つ ML モデル ライブラリです。
ラボの内容
Google Cloud Shell と Cloud Run を使用して、LIT のビルド済みイメージから Docker コンテナをデプロイします。
Cloud Run は、GPU を含む Google のスケーラブルなインフラストラクチャ上でコンテナを直接実行できるマネージド コンピューティング プラットフォームです。
データセット
デモでは、デフォルトで LIT プロンプト デバッグのサンプル データセットが使用されます。UI から独自のデータセットを読み込むこともできます。
始める前に
このリファレンス ガイドでは、Google Cloud プロジェクトが必要です。新しいプロジェクトを作成することも、すでに作成済みのプロジェクトを選択することもできます。
2. Google Cloud コンソールと Cloud Shell を起動する
この手順では、Google Cloud コンソールを起動して Google Cloud Shell を使用します。
2-a: Google Cloud コンソールを起動する
ブラウザを起動して、Google Cloud コンソールに移動します。
Google Cloud コンソールは、Google Cloud リソースをすばやく管理できる強力で安全なウェブ管理インターフェースです。外出先で DevOps ツールを利用できます。
2-b: Google Cloud Shell を起動する
Cloud Shell は、ブラウザから場所を問わずにアクセスできる、オンラインの開発および運用環境です。gcloud コマンドライン ツールや kubectl などのユーティリティがプリロードされたオンライン ターミナルを使用して、リソースを管理できます。オンラインの Cloud Shell Editor を使用して、クラウドベースのアプリの開発、ビルド、デバッグ、デプロイを行うこともできます。Cloud Shell は、お気に入りのツールセットがプリインストールされ、5 GB の永続ストレージ スペースを備えた、開発者向けのオンライン環境を提供します。次の手順では、コマンド プロンプトを使用します。
次のスクリーンショットで青い丸で囲まれているメニューバーの右上にあるアイコンを使用して、Google Cloud Shell を起動します。

ページの下部に Bash シェルを含むターミナルが表示されます。

2-c: Google Cloud プロジェクトを設定する
gcloud コマンドを使用して、プロジェクト ID とプロジェクト リージョンを設定する必要があります。
# Set your GCP Project ID.
gcloud config set project your-project-id
# Set your GCP Project Region.
gcloud config set run/region your-project-region
3. Cloud Run を使用して LIT アプリサーバーの Docker イメージをデプロイする
3-a: LIT アプリを Cloud Run にデプロイする
まず、デプロイするバージョンとして LIT-App の最新バージョンを設定する必要があります。
# Set latest version as your LIT_SERVICE_TAG.
export LIT_SERVICE_TAG=latest
# List all the public LIT GCP App server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app
バージョンタグを設定したら、サービスに名前を付ける必要があります。
# Set your lit service name. While 'lit-app-service' is provided as a placeholder, you can customize the service name based on your preferences.
export LIT_SERVICE_NAME=lit-app-service
その後、次のコマンドを実行して、コンテナを Cloud Run にデプロイできます。
# Use below cmd to deploy the LIT App to Cloud Run.
gcloud run deploy $LIT_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app:$LIT_SERVICE_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--no-allow-unauthenticated
LIT では、サーバーの起動時にデータセットを追加することもできます。これを行うには、DATASETS 変数を設定して、読み込むデータを含めます。形式は name:path(例: data_foo:/bar/data_2024.jsonl)を使用します。データセットの形式は .jsonl にする必要があります。各レコードには prompt と、必要に応じて target フィールドと source フィールドが含まれます。複数のデータセットを読み込むには、カンマで区切ります。設定しない場合、LIT プロンプト デバッグのサンプル データセットが読み込まれます。
# Set the dataset.
export DATASETS=[DATASETS]
MAX_EXAMPLES を設定すると、各評価セットから読み込む例の最大数を設定できます。
# Set the max examples.
export MAX_EXAMPLES=[MAX_EXAMPLES]
デプロイ コマンドで、
--set-env-vars "DATASETS=$DATASETS" \
--set-env-vars "MAX_EXAMPLES=$MAX_EXAMPLES" \
3-b: LIT App Service を表示する
LIT アプリサーバーを作成すると、Cloud Console の [Cloud Run] セクションでサービスを確認できます。
作成した LIT App サービスを選択します。サービス名が LIT_SERVICE_NAME と同じであることを確認します。
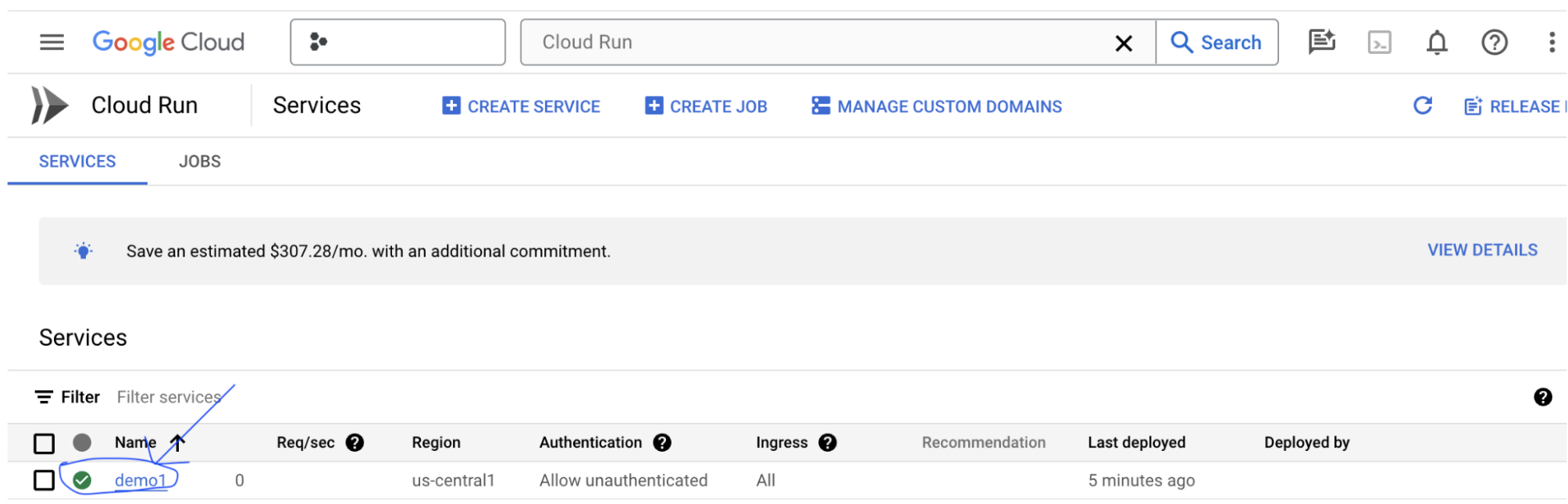
サービス URL は、デプロイしたサービスをクリックすると確認できます。
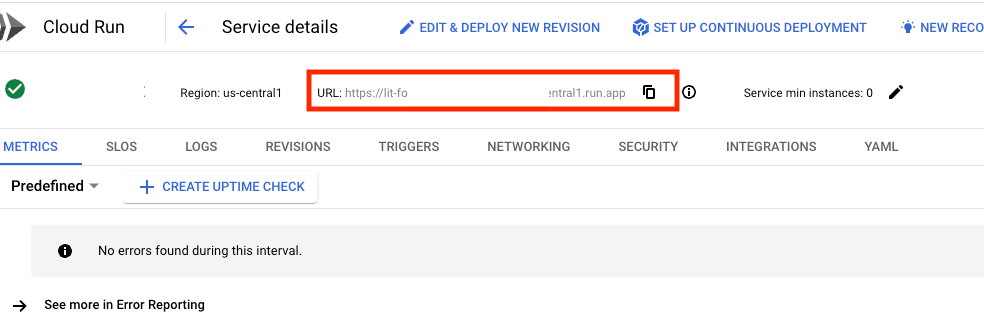
LIT UI が表示されます。エラーが発生した場合は、トラブルシューティングのセクションをご覧ください。
[ログ] セクションで、アクティビティのモニタリング、エラー メッセージの表示、デプロイの進行状況の追跡を行うことができます。
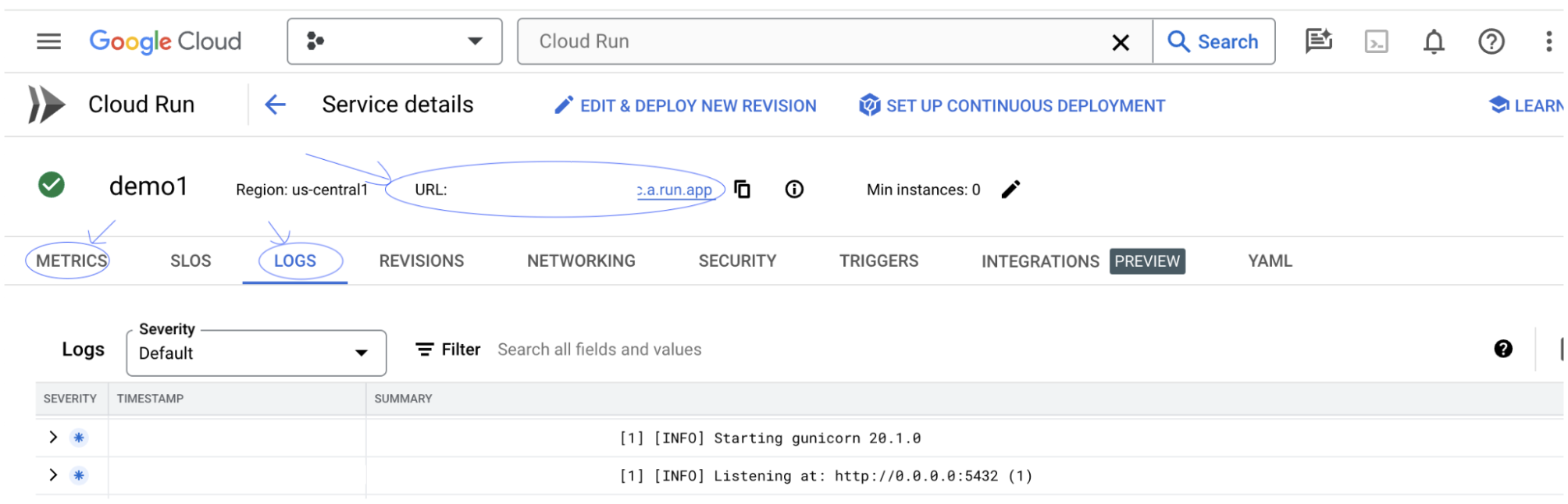
[指標] セクションで、サービスの指標を確認できます。
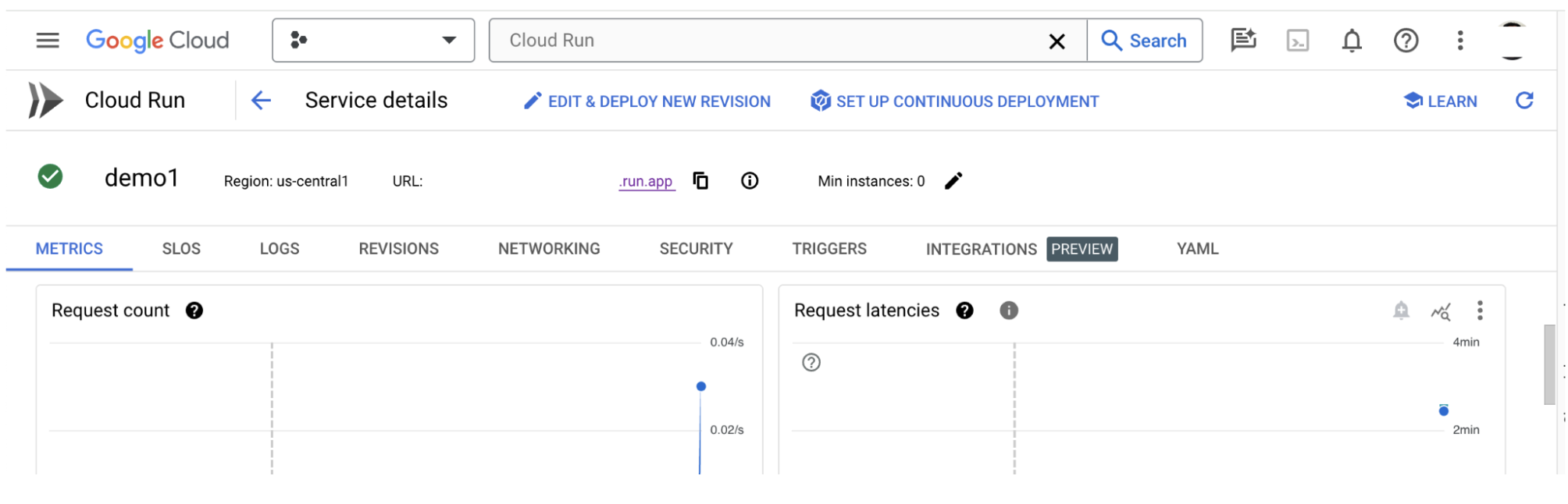
3-c: データセットを読み込む
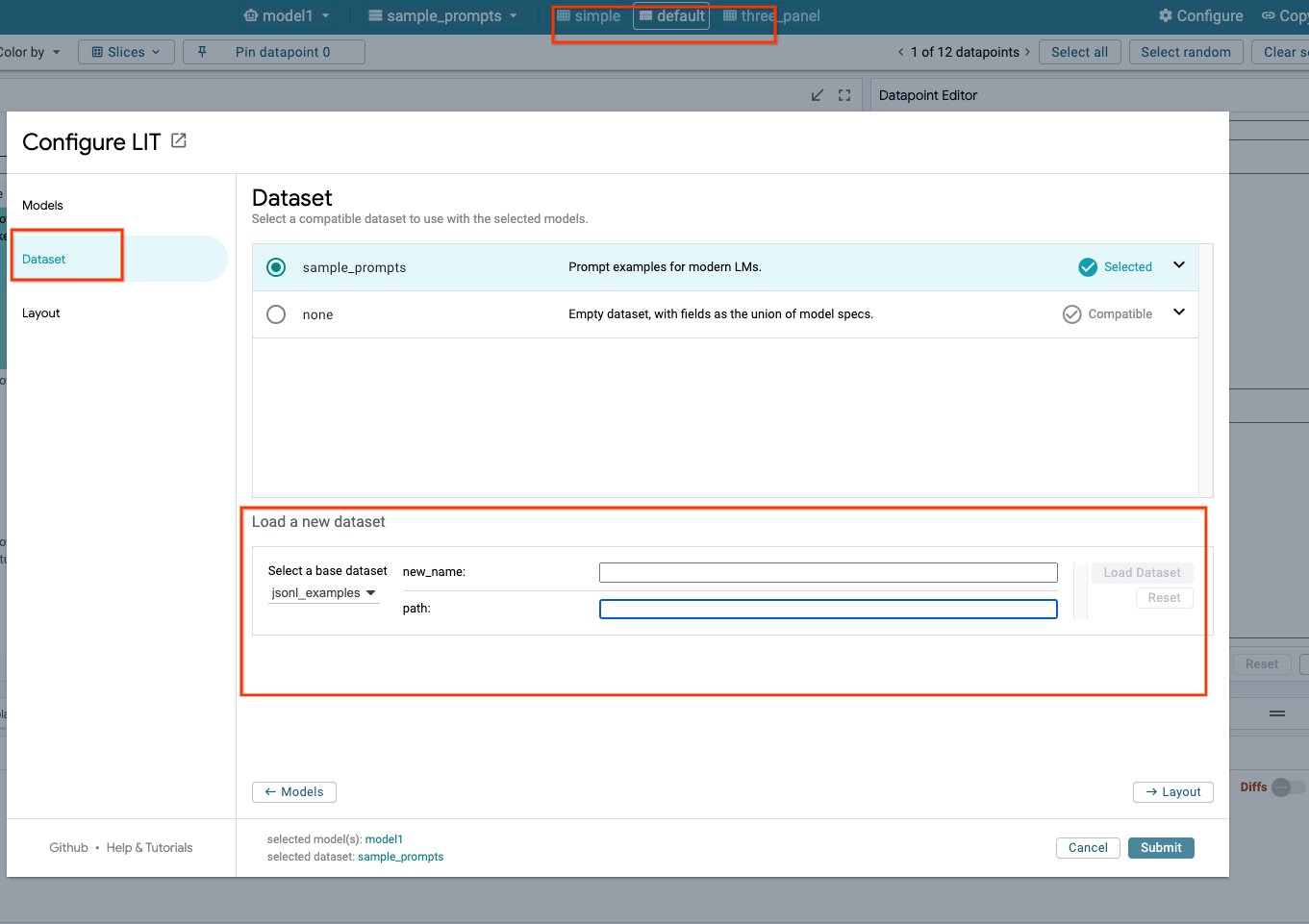
LIT UI で Configure オプションをクリックし、Dataset を選択します。名前を指定してデータセットの URL を指定し、データセットを読み込みます。データセットの形式は .jsonl にする必要があります。各レコードには prompt と、必要に応じて target フィールドと source フィールドが含まれます。
4. Vertex AI Model Garden で Gemini モデルを準備する
Google の Gemini 基盤モデルは、Vertex AI API から利用できます。LIT は、これらのモデルを生成に使用するための VertexAIModelGarden モデルラッパーを提供します。モデル名パラメータで目的のバージョン(「gemini-1.5-pro-001」など)を指定するだけです。これらのモデルを使用する主なメリットは、デプロイに追加の作業が必要ないことです。デフォルトでは、GCP で Gemini 1.0 Pro や Gemini 1.5 Pro などのモデルにすぐにアクセスできるため、追加の構成手順は必要ありません。
4-a: Vertex AI 権限を付与する
GCP で Gemini をクエリするには、サービス アカウントに Vertex AI 権限を付与する必要があります。サービス アカウント名が Default compute service account であることを確認します。アカウントのサービス アカウントのメールアドレスをコピーします。
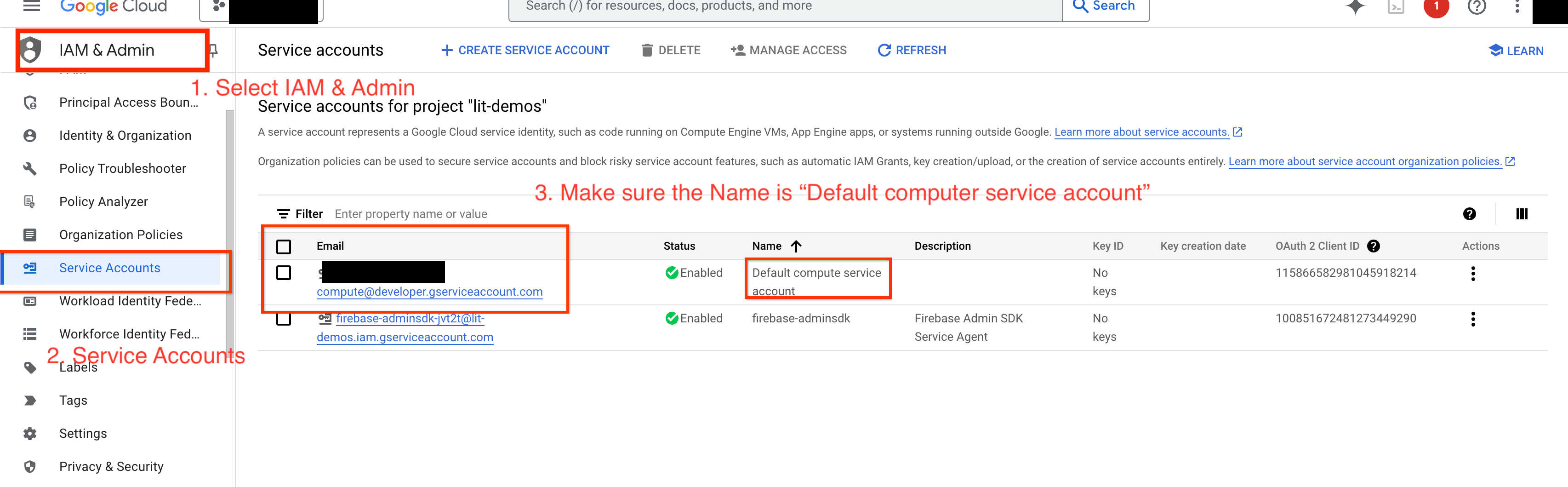
サービス アカウントのメールアドレスを、IAM 許可リストの Vertex AI User ロールを持つプリンシパルとして追加します。

4-b: Gemini モデルを読み込む
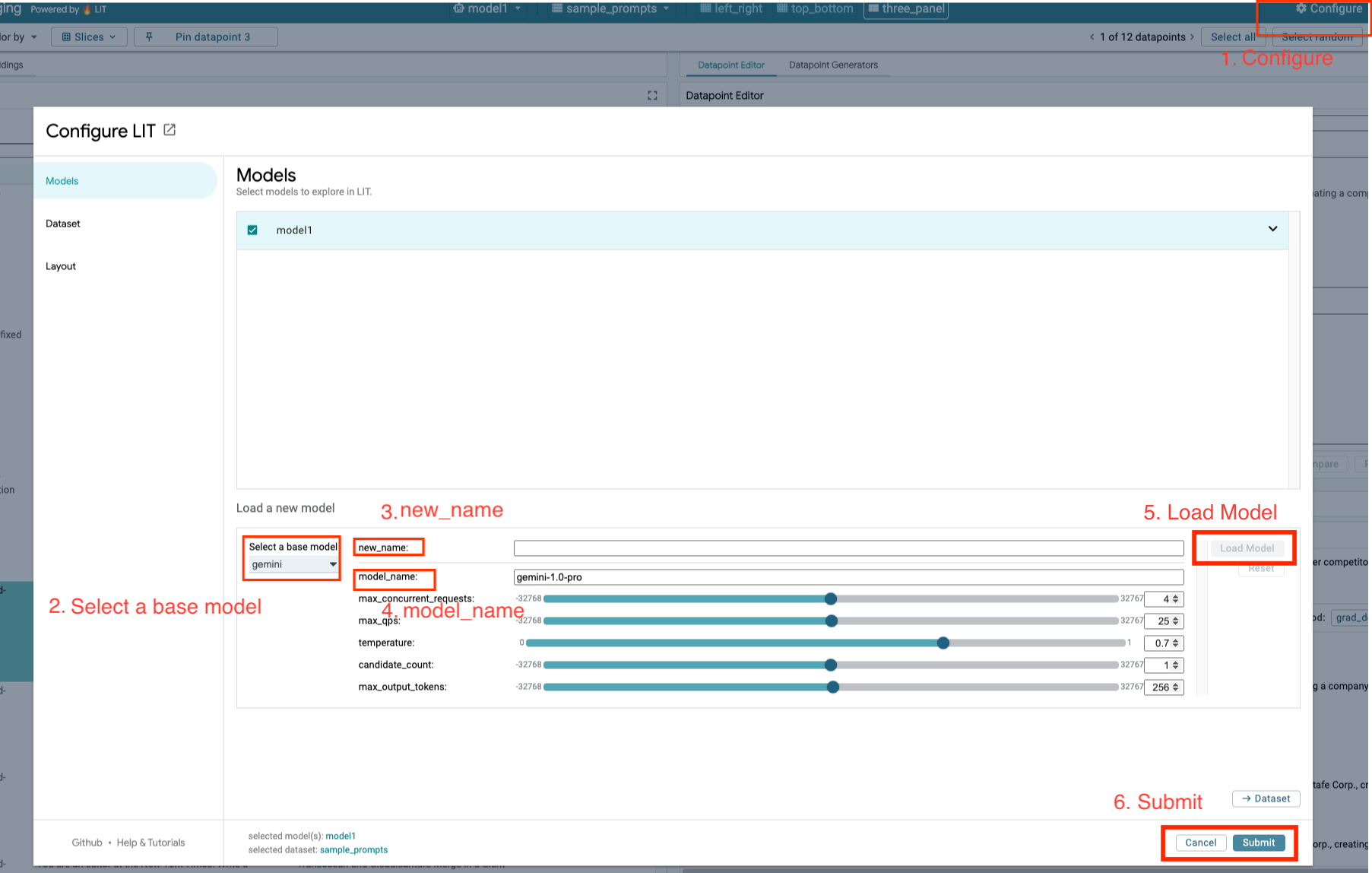
以下の手順に沿って、Gemini モデルを読み込み、パラメータを調整します。
- LIT UI で
Configureオプションをクリックします。
- LIT UI で
- [
Select a base model] オプションで [gemini] オプションを選択します。
- [
- モデルに
new_nameで名前を付ける必要があります。
- モデルに
- 選択した Gemini モデルを
model_nameとして入力します。
- 選択した Gemini モデルを
- [
Load Model] をクリックします。
- [
- [
Submit] をクリックします。
- [
5. GCP にセルフホスト型 LLM モデルサーバーをデプロイする
LIT のモデルサーバー Docker イメージを使用して LLM をセルフホスティングすると、LIT の顕著性とトークン化関数を使用して、モデルの動作に関する詳細な分析情報を取得できます。モデルサーバー イメージは、ライブラリ提供の重みやセルフホストの重み(Google Cloud Storage など)を含む KerasNLP モデルまたは Hugging Face Transformers モデルで動作します。
5-a: モデルを構成する
各コンテナは、環境変数を使用して構成された 1 つのモデルを読み込みます。
読み込むモデルを指定するには、MODEL_CONFIG を設定します。形式は name:path にする必要があります(例: model_foo:model_foo_path)。パスには、URL、ローカル ファイルパス、構成されたディープ ラーニング フレームワークのプリセットの名前を指定できます(詳細については、次の表をご覧ください)。このサーバーは、サポートされているすべての DL_FRAMEWORK 値で Gemma、GPT2、Llama、Mistral を使用してテストされています。他のモデルでも動作するはずですが、調整が必要になる場合があります。
# Set models you want to load. While 'gemma2b is given as a placeholder, you can load your preferred model by following the instructions above.
export MODEL_CONFIG=gemma2b:gemma_2b_en
また、LIT モデルサーバーでは、次のコマンドを使用してさまざまな環境変数を構成できます。詳しくは、以下の表をご覧ください。各変数は個別に設定する必要があります。
# Customize the variable value as needed.
export [VARIABLE]=[VALUE]
変数 | 値 | 説明 |
DL_FRAMEWORK |
| 指定されたランタイムにモデルの重みを読み込むために使用されるモデリング ライブラリ。デフォルトは |
DL_RUNTIME |
| モデルが実行されるディープ ラーニング バックエンド フレームワーク。このサーバーによって読み込まれるすべてのモデルは同じバックエンドを使用します。互換性がないとエラーが発生します。デフォルトは |
PRECISION |
| LLM モデルの浮動小数点精度。デフォルトは |
BATCH_SIZE | 正の整数 | バッチごとに処理するサンプル数。デフォルトは |
SEQUENCE_LENGTH | 正の整数 | 入力プロンプトと生成されたテキストの最大シーケンス長。デフォルトは |
5-b: Model Server を Cloud Run にデプロイする
まず、デプロイするバージョンとして Model Server の最新バージョンを設定する必要があります。
# Set latest as MODEL_VERSION_TAG.
export MODEL_VERSION_TAG=latest
# List all the public LIT GCP model server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server
バージョンタグを設定したら、モデルサーバーに名前を付ける必要があります。
# Set your Service name.
export MODEL_SERVICE_NAME='gemma2b-model-server'
その後、次のコマンドを実行して、コンテナを Cloud Run にデプロイできます。環境変数を設定しない場合は、デフォルト値が適用されます。ほとんどの LLM は高価なコンピューティング リソースを必要とするため、GPU を使用することを強くおすすめします。CPU のみで実行する場合は(GPT2 などの小規模モデルでは問題ありません)、関連する引数 --gpu 1 --gpu-type nvidia-l4 --max-instances 7 を削除できます。
# Deploy the model service container.
gcloud beta run deploy $MODEL_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server:$MODEL_VERSION_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 7 \
--set-env-vars "MODEL_CONFIG=$MODEL_CONFIG" \
--no-allow-unauthenticated
また、次のコマンドを追加して環境変数をカスタマイズすることもできます。特定のニーズに必要な環境変数のみを含めます。
--set-env-vars "DL_FRAMEWORK=$DL_FRAMEWORK" \
--set-env-vars "DL_RUNTIME=$DL_RUNTIME" \
--set-env-vars "PRECISION=$PRECISION" \
--set-env-vars "BATCH_SIZE=$BATCH_SIZE" \
--set-env-vars "SEQUENCE_LENGTH=$SEQUENCE_LENGTH" \
特定のモデルにアクセスするには、追加の環境変数が必要になることがあります。必要に応じて、Kaggle Hub(KerasNLP モデルに使用)と Hugging Face Hub の手順をご覧ください。
5-c: モデルサーバーにアクセスする
モデルサーバーを作成すると、開始されたサービスが GCP プロジェクトの [Cloud Run] セクションに表示されます。
作成したモデルサーバーを選択します。サービス名が MODEL_SERVICE_NAME と同じであることを確認します。
サービス URL は、デプロイしたモデルサービスをクリックすると確認できます。
[ログ] セクションで、アクティビティのモニタリング、エラー メッセージの表示、デプロイの進行状況の追跡を行うことができます。
[指標] セクションで、サービスの指標を確認できます。
5-d: セルフホスト型モデルを読み込む
ステップ 3 で LIT サーバーをプロキシする場合は(トラブルシューティング セクションを参照)、次のコマンドを実行して GCP ID トークンを取得する必要があります。
# Find your GCP identity token.
gcloud auth print-identity-token
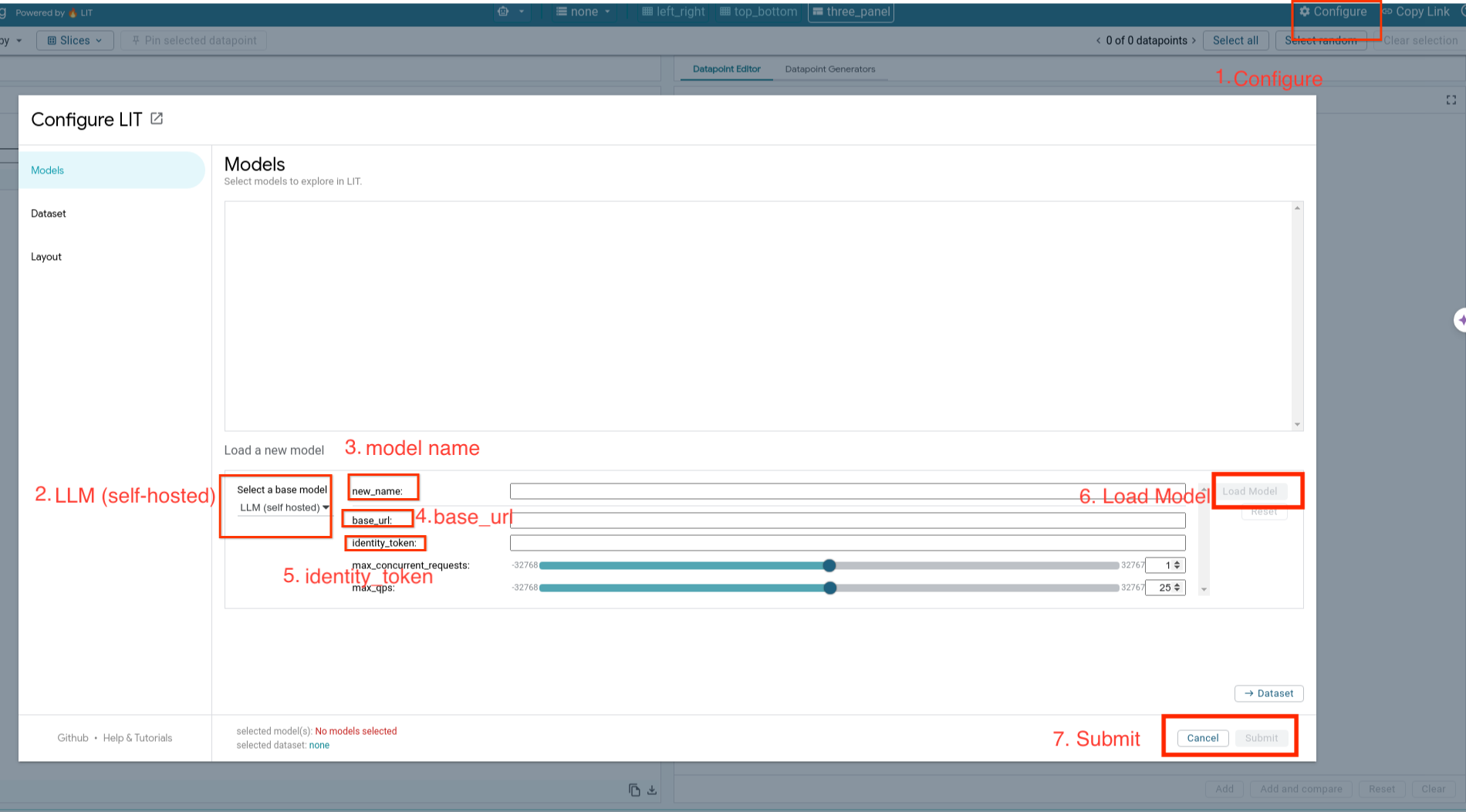
セルフホスト モデルを読み込み、次の手順に沿ってパラメータを調整します。
- LIT UI で
Configureオプションをクリックします。 - [
Select a base model] オプションで [LLM (self hosted)] オプションを選択します。 - モデルに
new_nameで名前を付ける必要があります。 - モデルサーバーの URL を
base_urlとして入力します。 - LIT アプリサーバーをプロキシする場合は、取得した ID トークンを
identity_tokenに入力します(手順 3 と手順 7 を参照)。それ以外の場合は、空欄のままにします。 - [
Load Model] をクリックします。 - [
Submit] をクリックします。
6. GCP で LIT を操作する
LIT には、モデルの動作をデバッグして理解するのに役立つ豊富な機能が用意されています。ボックスにテキストを入力してモデルの予測を確認するような簡単なモデルのクエリを実行したり、LIT の強力な機能スイートを使用してモデルを詳細に検査したりできます。
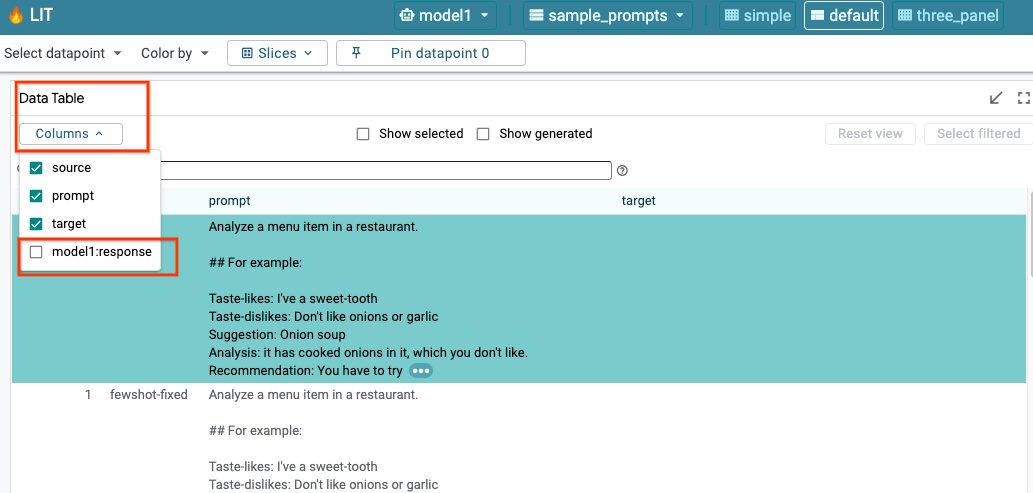
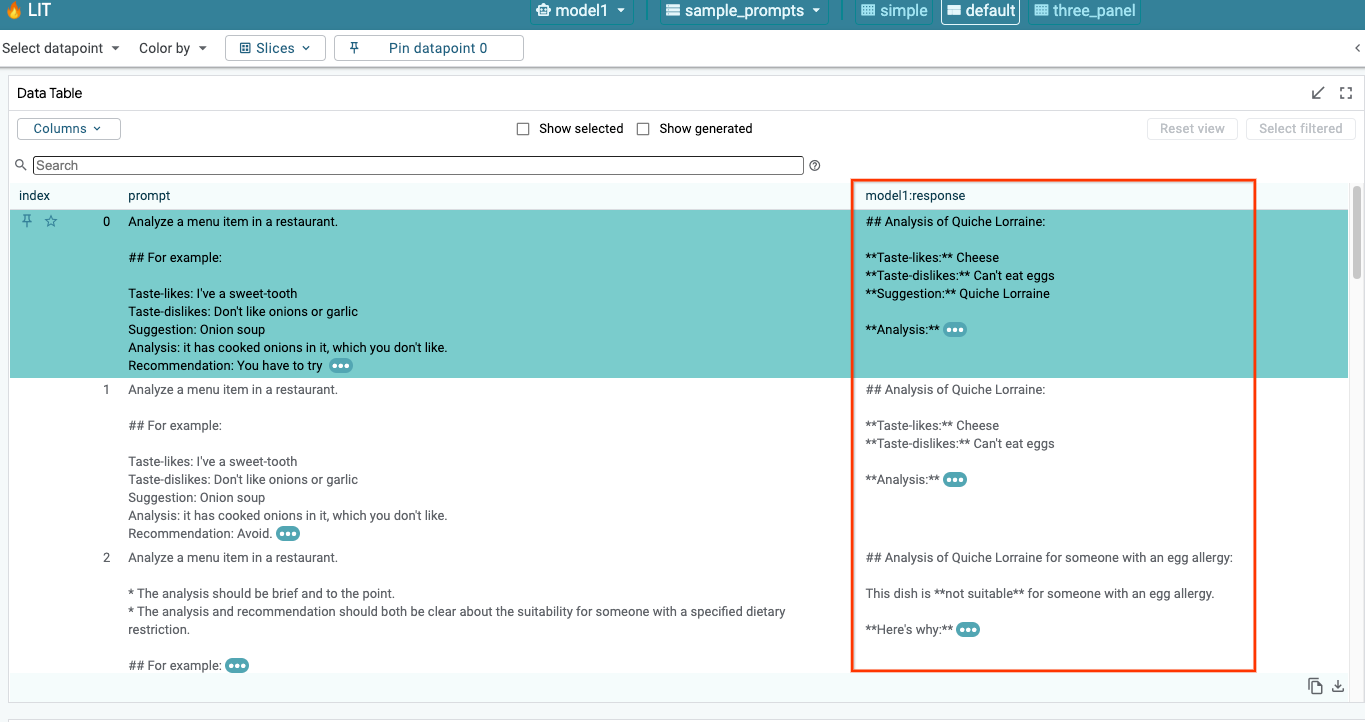
6-a: LIT を使用してモデルをクエリする
LIT は、モデルとデータセットの読み込み後にデータセットを自動的にクエリします。列でレスポンスを選択すると、各モデルのレスポンスを表示できます。
6-b: シーケンスの顕著性手法を使用する
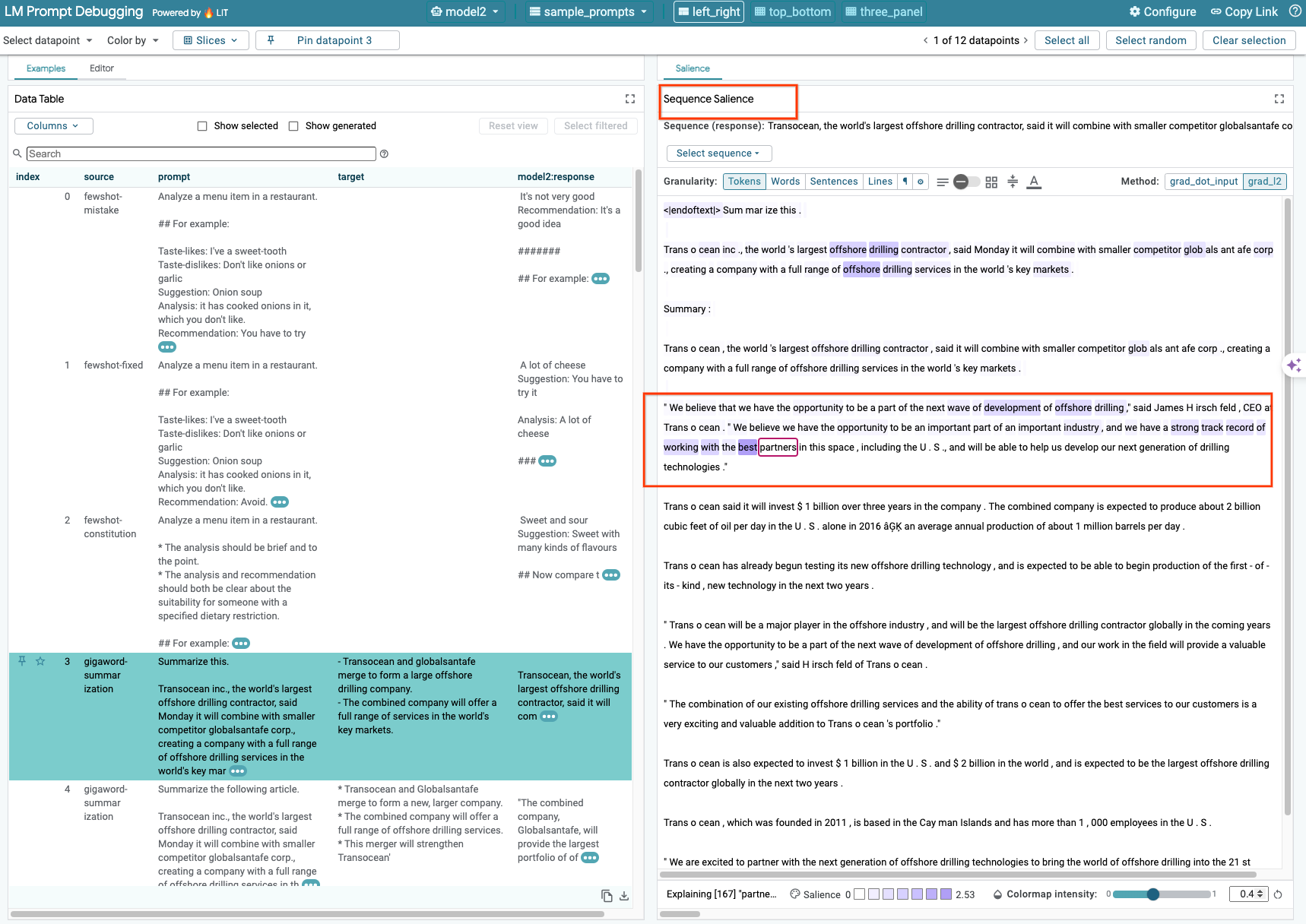
現在、LIT の Sequence Salience 手法はセルフホスト モデルのみをサポートしています。
シーケンスの顕著性は、プロンプトのどの部分が特定の出力にとって最も重要であるかをハイライト表示することで、LLM プロンプトのデバッグに役立つ視覚的なツールです。シーケンスの顕著性について詳しくは、この機能の使用方法に関するチュートリアルをご覧ください。
重要度結果にアクセスするには、プロンプトまたはレスポンスの入力または出力をクリックします。重要度結果が表示されます。
6-c: プロンプトとターゲットを手動で編集する
LIT では、既存のデータポイントの prompt と target を手動で編集できます。Add をクリックすると、新しい入力がデータセットに追加されます。
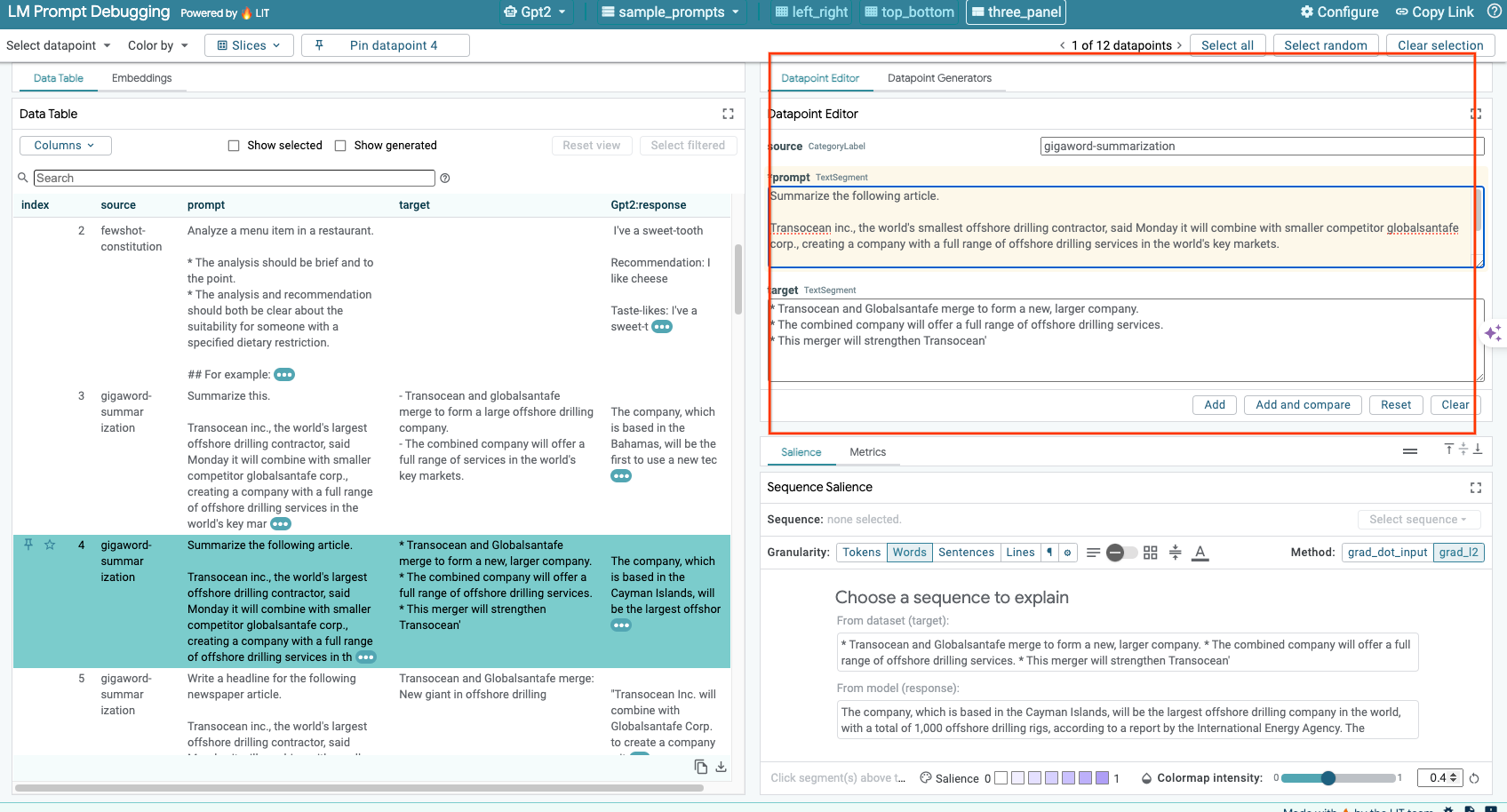
6-d: プロンプトを並べて比較する
LIT を使用すると、元の例と編集した例でプロンプトを並べて比較できます。例を手動で編集し、元のバージョンと編集後のバージョンの両方の予測結果とシーケンスの顕著性分析を同時に表示できます。各データポイントのプロンプトを変更すると、LIT はモデルにクエリを実行して対応するレスポンスを生成します。
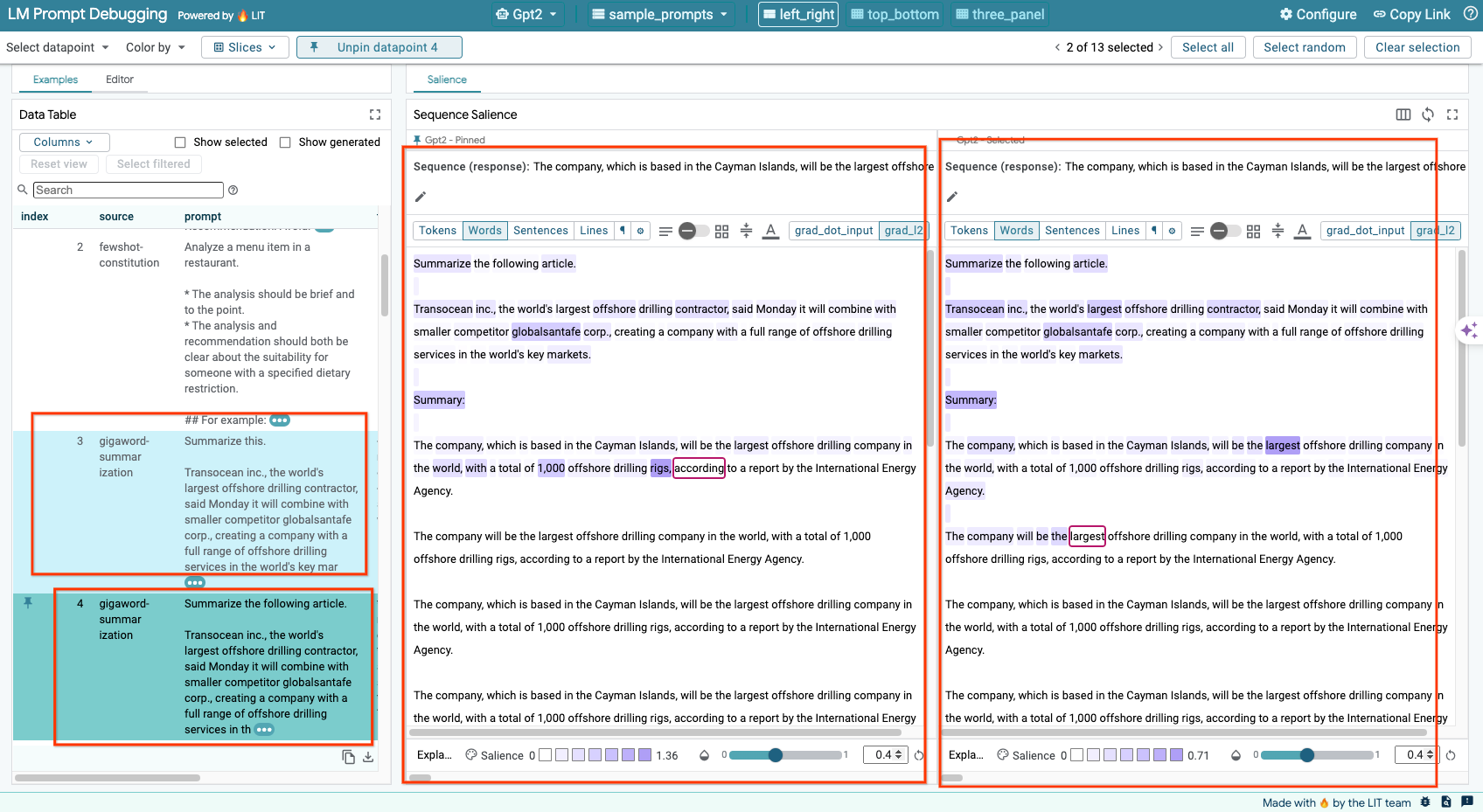
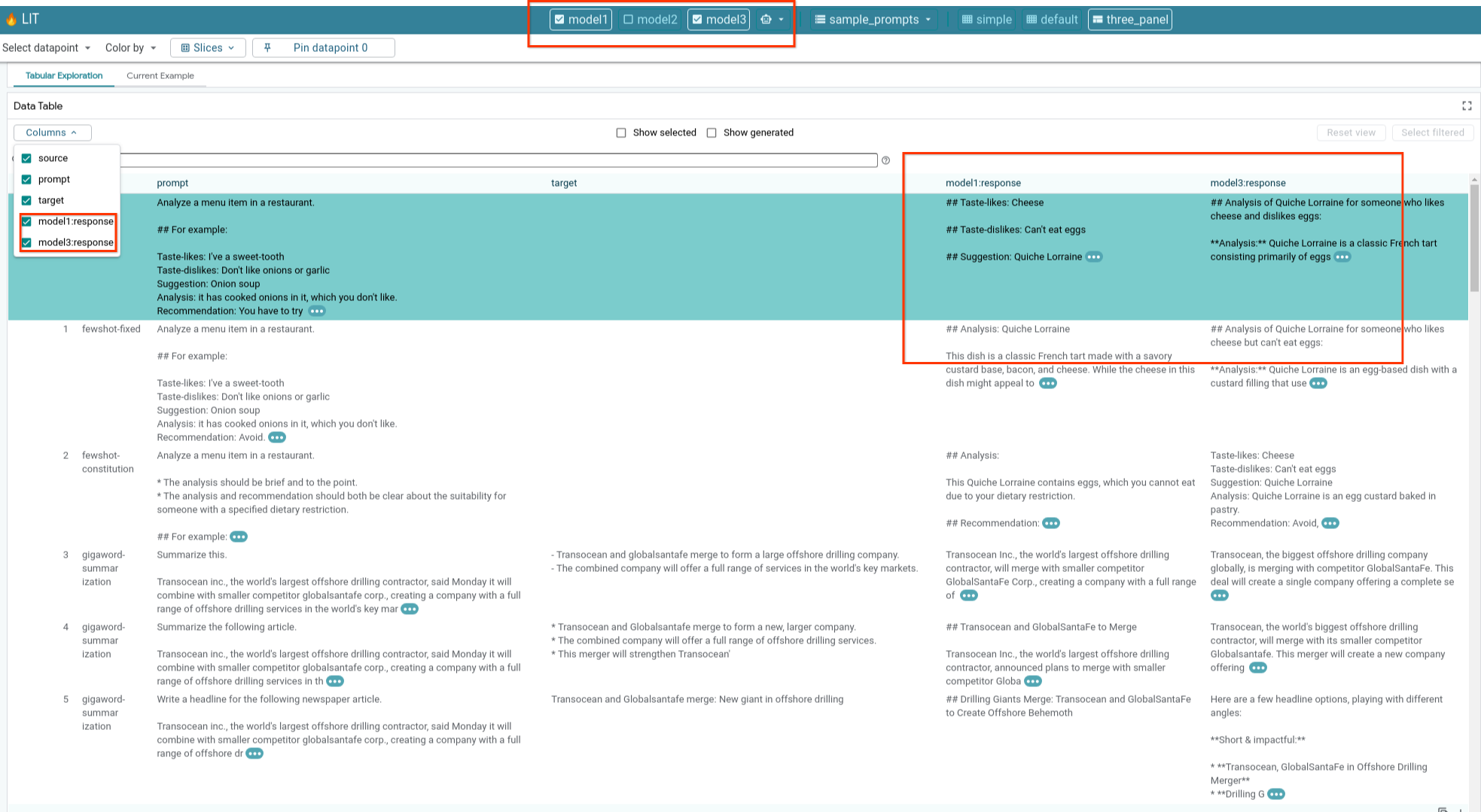
6-e: 複数のモデルを並べて比較する
LIT を使用すると、個々のテキスト生成とスコアリングの例、および特定の指標の集計例でモデルを並べて比較できます。読み込まれたさまざまなモデルをクエリすることで、回答の違いを簡単に比較できます。
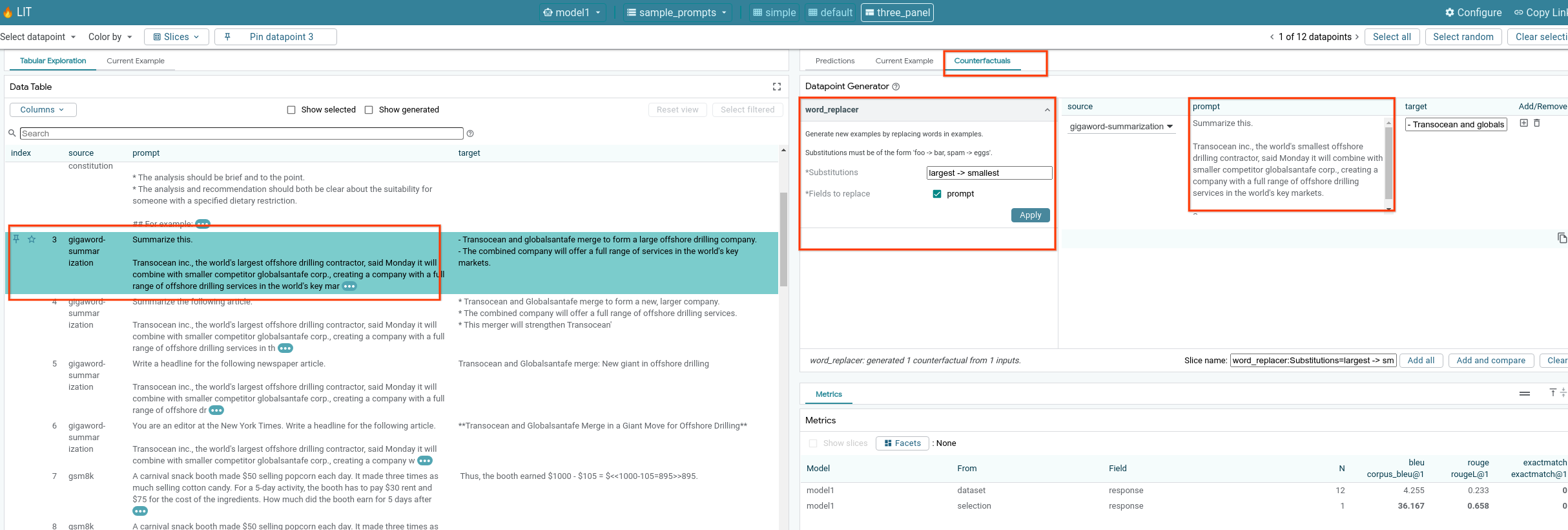
6-f: 自動反事実的生成ツール
自動反事実生成ツールを使用して代替入力を作成し、モデルがそれらの入力に対してどのように動作するかをすぐに確認できます。
6-g: モデルのパフォーマンスを評価する
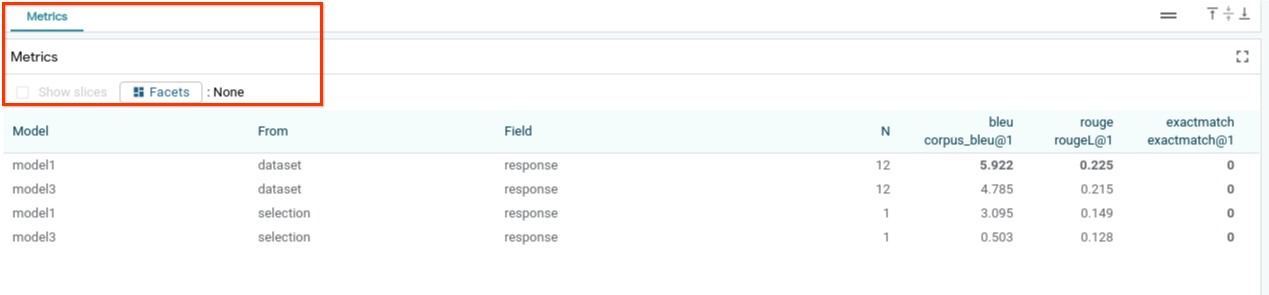
データセット全体、またはフィルタリングされた例や選択された例のサブセット全体で、指標(現在、テキスト生成の BLEU スコアと ROUGE スコアをサポート)を使用してモデルのパフォーマンスを評価できます。
7. トラブルシューティング
7-a: アクセスに関する潜在的な問題と解決策
Cloud Run にデプロイするときに --no-allow-unauthenticated が適用されるため、次のような禁止エラーが発生する可能性があります。

LIT App サービスにアクセスするには、次の 2 つの方法があります。
1. ローカル サービスへのプロキシ
次のコマンドを使用して、サービスをローカルホストにプロキシできます。
# Proxy the service to local host.
gcloud run services proxy $LIT_SERVICE_NAME
その後、プロキシ サービス リンクをクリックして LIT サーバーにアクセスできるようになります。
2. ユーザーを直接認証する
こちらのリンクからユーザーを認証すると、LIT App サービスに直接アクセスできるようになります。この方法では、ユーザー グループがサービスにアクセスすることもできます。複数のユーザーと共同で開発を行う場合は、この方法がより効果的です。
7-b: モデルサーバーが正常に起動したことを確認するチェック
モデルサーバーが正常に起動したことを確認するには、リクエストを送信してモデルサーバーを直接クエリします。モデルサーバーは、predict、tokenize、salience の 3 つのエンドポイントを提供します。リクエストで prompt フィールドと target フィールドの両方を指定してください。
# Query the model server predict endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/predict -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server tokenize endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/tokenize -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server salience endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/salience -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
アクセスに関する問題が発生した場合は、上記のセクション 7-a をご覧ください。
8. 完了
この Codelab は以上です。くつろぎの時間!
クリーンアップ
ラボをクリーンアップするには、ラボ用に作成したすべての Google Cloud サービスを削除します。Google Cloud Shell を使用して、次のコマンドを実行します。
非アクティブ状態が原因で Google Cloud 接続が失われた場合は、前の手順に沿って変数をリセットします。
# Delete the LIT App Service.
gcloud run services delete $LIT_SERVICE_NAME
モデルサーバーを起動した場合は、モデルサーバーも削除する必要があります。
# Delete the Model Service.
gcloud run services delete $MODEL_SERVICE_NAME
参考資料
以下の資料で LIT ツールの機能について学習を続けてください。
- Gemma: リンク
- LIT オープンソース コードベース: Git リポジトリ
- LIT 論文: ArXiv
- LIT プロンプトのデバッグに関する論文: ArXiv
- LIT 機能のデモ動画: YouTube
- LIT プロンプトのデバッグ デモ: YouTube
- 責任ある生成 AI ツールキット: リンク
連絡先
この Codelab に関するご質問や問題がございましたら、GitHub でお問い合わせください。
ライセンス
この作業はクリエイティブ・コモンズの表示 4.0 汎用ライセンスにより使用許諾されています。