
1. Présentation
Cet atelier fournit un guide détaillé sur le déploiement d'un serveur d'application LIT sur Google Cloud Platform (GCP) pour interagir avec les modèles de fondation Gemini de Vertex AI et les grands modèles de langage (LLM) tiers auto-hébergés. Il comprend également des conseils sur l'utilisation de l'interface utilisateur LIT pour le débogage des requêtes et l'interprétation des modèles.
À la fin de cet atelier, les utilisateurs sauront :
- Configurez un serveur LIT sur GCP.
- Connectez le serveur LIT aux modèles Gemini de Vertex AI ou à d'autres LLM auto-hébergés.
- Utilisez l'UI LIT pour analyser, déboguer et interpréter les requêtes afin d'améliorer les performances et les insights du modèle.
Qu'est-ce que LIT ?
LIT est un outil visuel et interactif de compréhension des modèles qui prend en charge les données textuelles, d'images et tabulaires. Il peut être exécuté en tant que serveur autonome, ou au sein d'environnements de notebook tels que Google Colab, Jupyter et Google Cloud Vertex AI. LIT est disponible sur PyPI et GitHub.
Initialement conçue pour comprendre les modèles de classification et de régression, elle a récemment été mise à jour pour inclure des outils de débogage des requêtes LLM. Vous pouvez ainsi explorer l'influence du contenu utilisateur, du modèle et du système sur le comportement de génération.
Qu'est-ce que Vertex AI et Model Garden ?
Vertex AI est une plate-forme de machine learning (ML) qui vous permet d'entraîner et de déployer des modèles de ML et des applications d'IA, ainsi que de personnaliser des LLM pour les utiliser dans vos applications optimisées par l'IA. Vertex AI combine les workflows d'ingénierie des données, de data science et d'ingénierie de ML, ce qui permet à vos équipes de collaborer à l'aide d'un ensemble d'outils commun et de faire évoluer vos applications en tirant parti des avantages de Google Cloud.
Vertex Model Garden est une bibliothèque de modèles de ML qui vous aide à découvrir, tester, personnaliser et déployer des modèles et des éléments propriétaires de Google et de sélectionner des modèles et des éléments tiers.
Objectifs de l'atelier
Vous utiliserez Google Cloud Shell et Cloud Run pour déployer un conteneur Docker à partir de l'image prédéfinie de LIT.
Cloud Run est une plate-forme de calcul gérée qui vous permet d'exécuter des conteneurs directement sur l'infrastructure évolutive de Google, y compris sur les GPU.
Ensemble de données
La démo utilise l'exemple d'ensemble de données de débogage des requêtes LIT par défaut, mais vous pouvez charger le vôtre via l'UI.
Avant de commencer
Pour ce guide de référence, vous avez besoin d'un projet Google Cloud. Vous pouvez en créer un ou sélectionner un projet existant.
2. Lancer la console Google Cloud et Cloud Shell
Dans cette étape, vous allez lancer une console Google Cloud et utiliser Google Cloud Shell.
2-a : Lancez une console Google Cloud
Ouvrez un navigateur et accédez à la console Google Cloud.
La console Google Cloud est une interface d'administration Web puissante et sécurisée qui vous permet de gérer rapidement vos ressources Google Cloud. Il s'agit d'un outil DevOps mobile.
2-b : Lancer un Google Cloud Shell
Cloud Shell est un environnement de développement et d'opérations en ligne, accessible depuis votre navigateur, où que vous soyez. Vous pouvez y gérer vos ressources grâce à un terminal en ligne comportant des utilitaires préchargés tels que l'outil de ligne de commande gcloud, kubectl et bien plus encore. Vous pouvez également développer, compiler, déboguer et déployer vos applications cloud à l'aide de l'éditeur Cloud Shell en ligne. Cloud Shell fournit un environnement en ligne prêt pour les développeurs, avec un ensemble d'outils favoris préinstallés et 5 Go d'espace de stockage persistant. Vous utiliserez l'invite de commandes lors des prochaines étapes.
Lancez Google Cloud Shell à l'aide de l'icône située en haut à droite de la barre de menu, entourée en bleu dans la capture d'écran suivante.

Un terminal avec un shell Bash doit s'afficher en bas de la page.

2-c : Définir le projet Google Cloud
Vous devez définir l'ID et la région du projet à l'aide de la commande gcloud.
# Set your GCP Project ID.
gcloud config set project your-project-id
# Set your GCP Project Region.
gcloud config set run/region your-project-region
3. Déployer l'image Docker du serveur d'application LIT avec Cloud Run
3-a : Déployer l'application LIT sur Cloud Run
Vous devez d'abord définir la dernière version de LIT-App comme version à déployer.
# Set latest version as your LIT_SERVICE_TAG.
export LIT_SERVICE_TAG=latest
# List all the public LIT GCP App server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app
Après avoir défini le tag de version, vous devez nommer le service.
# Set your lit service name. While 'lit-app-service' is provided as a placeholder, you can customize the service name based on your preferences.
export LIT_SERVICE_NAME=lit-app-service
Vous pouvez ensuite exécuter la commande suivante pour déployer le conteneur sur Cloud Run.
# Use below cmd to deploy the LIT App to Cloud Run.
gcloud run deploy $LIT_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app:$LIT_SERVICE_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--no-allow-unauthenticated
LIT vous permet également d'ajouter l'ensemble de données lorsque vous démarrez le serveur. Pour ce faire, définissez la variable DATASETS pour inclure les données que vous souhaitez charger, au format name:path, par exemple data_foo:/bar/data_2024.jsonl. Le format de l'ensemble de données doit être .jsonl, où chaque enregistrement contient prompt et les champs facultatifs target et source. Pour charger plusieurs ensembles de données, séparez-les par une virgule. Si ce paramètre n'est pas défini, l'ensemble de données d'exemple de débogage des requêtes LIT sera chargé.
# Set the dataset.
export DATASETS=[DATASETS]
En définissant MAX_EXAMPLES, vous pouvez définir le nombre maximal d'exemples à charger à partir de chaque ensemble d'évaluation.
# Set the max examples.
export MAX_EXAMPLES=[MAX_EXAMPLES]
Ensuite, dans la commande de déploiement, vous pouvez ajouter
--set-env-vars "DATASETS=$DATASETS" \
--set-env-vars "MAX_EXAMPLES=$MAX_EXAMPLES" \
3-b : Afficher le service d'application LIT
Une fois le serveur de l'application LIT créé, vous pouvez trouver le service dans la section Cloud Run de la console Cloud.
Sélectionnez le service d'application LIT que vous venez de créer. Assurez-vous que le nom du service est identique à LIT_SERVICE_NAME.
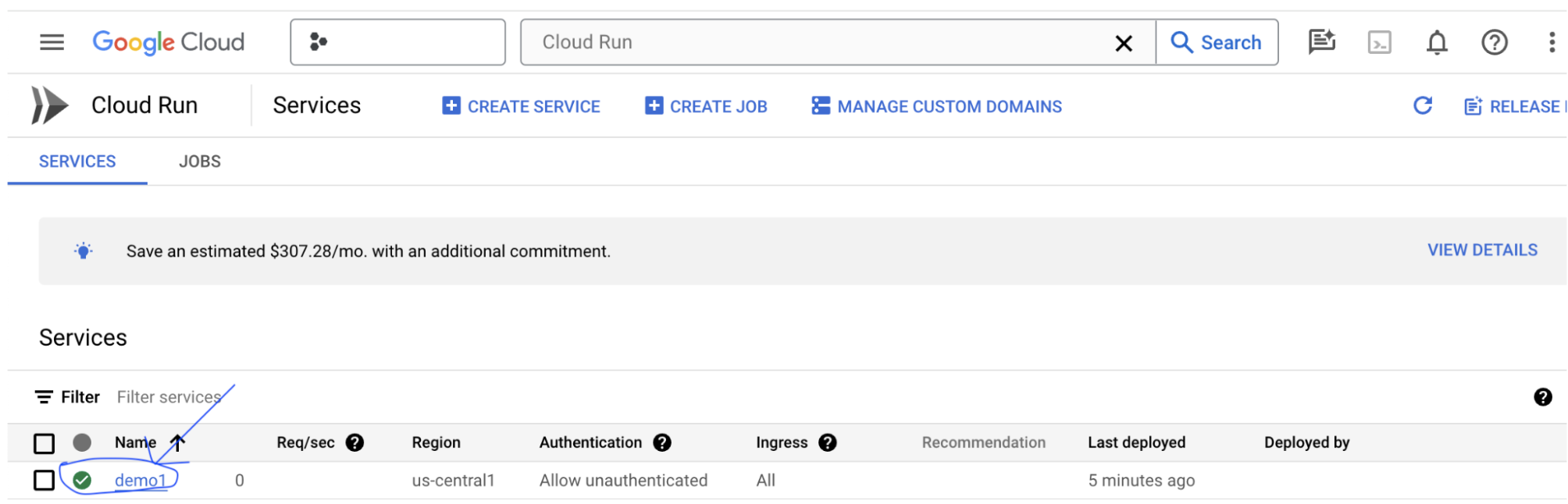
Vous pouvez trouver l'URL du service en cliquant sur le service que vous venez de déployer.
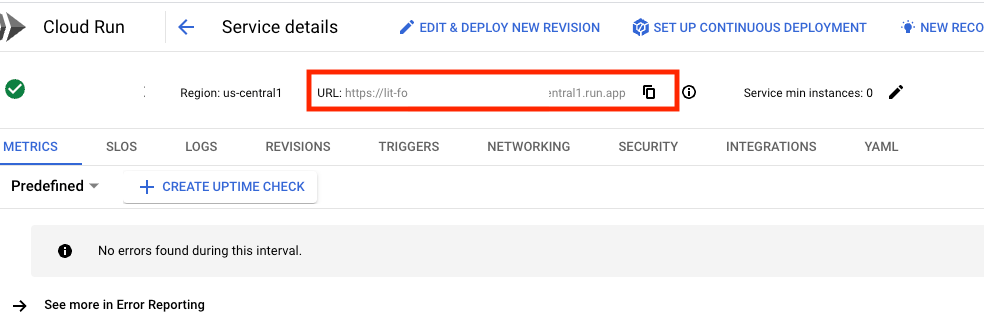
Vous devriez alors pouvoir afficher l'UI LIT. Si vous rencontrez une erreur, consultez la section "Dépannage".
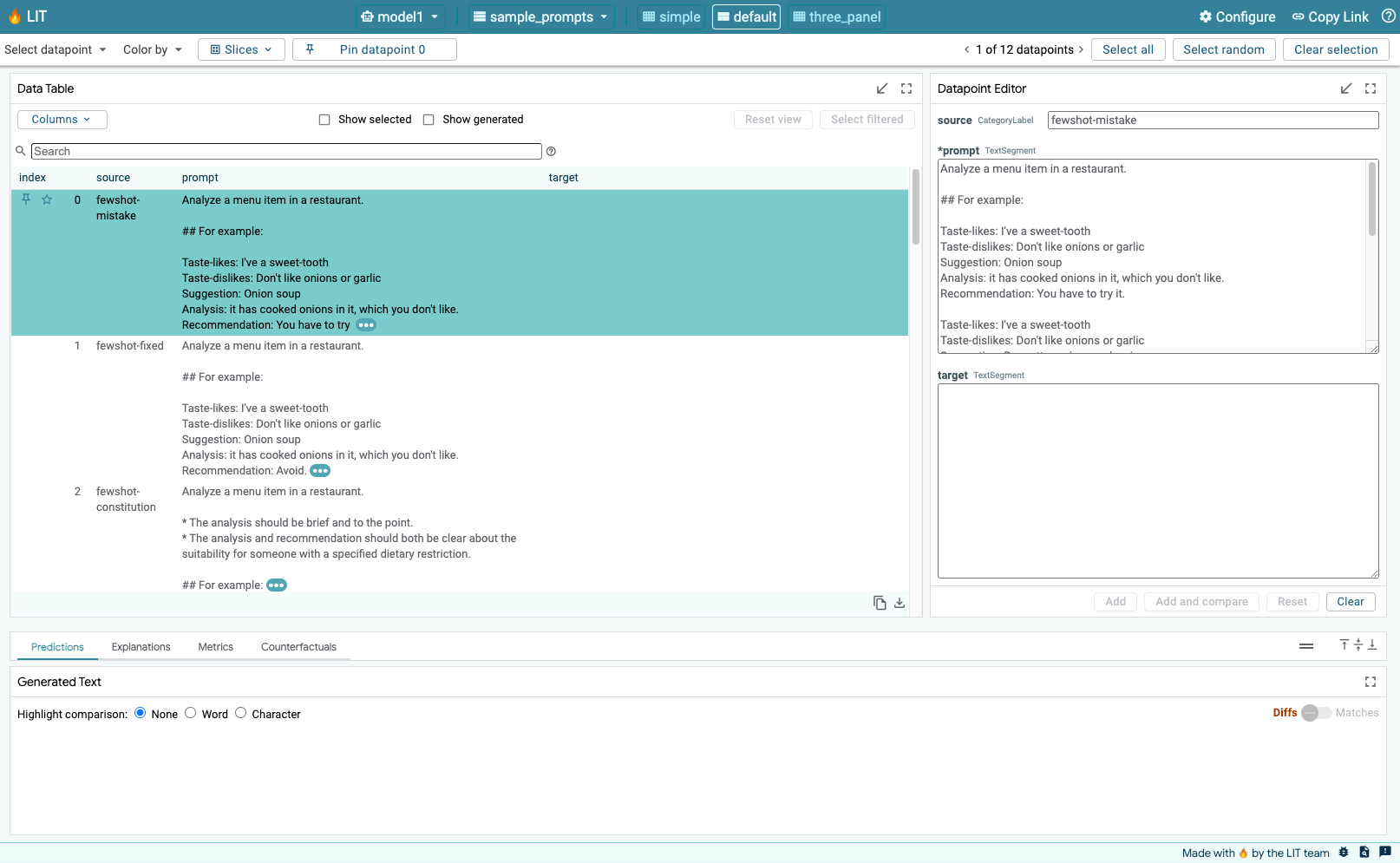
Vous pouvez consulter la section "JOURNAUX" pour surveiller l'activité, afficher les messages d'erreur et suivre la progression du déploiement.
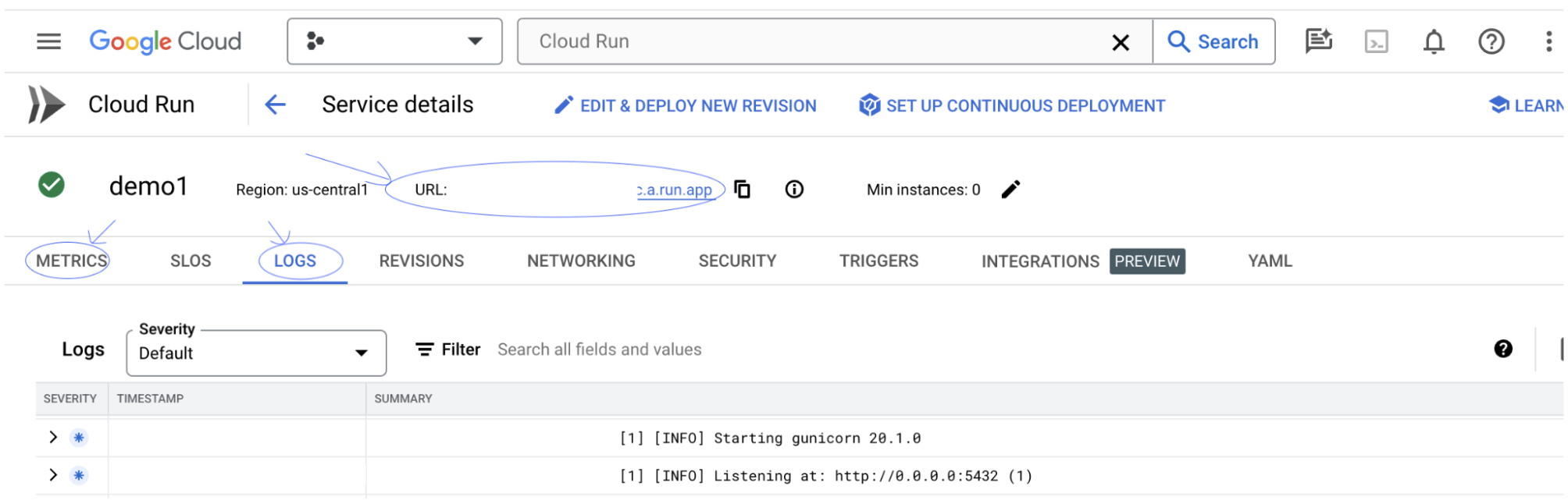
Vous pouvez consulter la section "MÉTRIQUES" pour afficher les métriques du service.
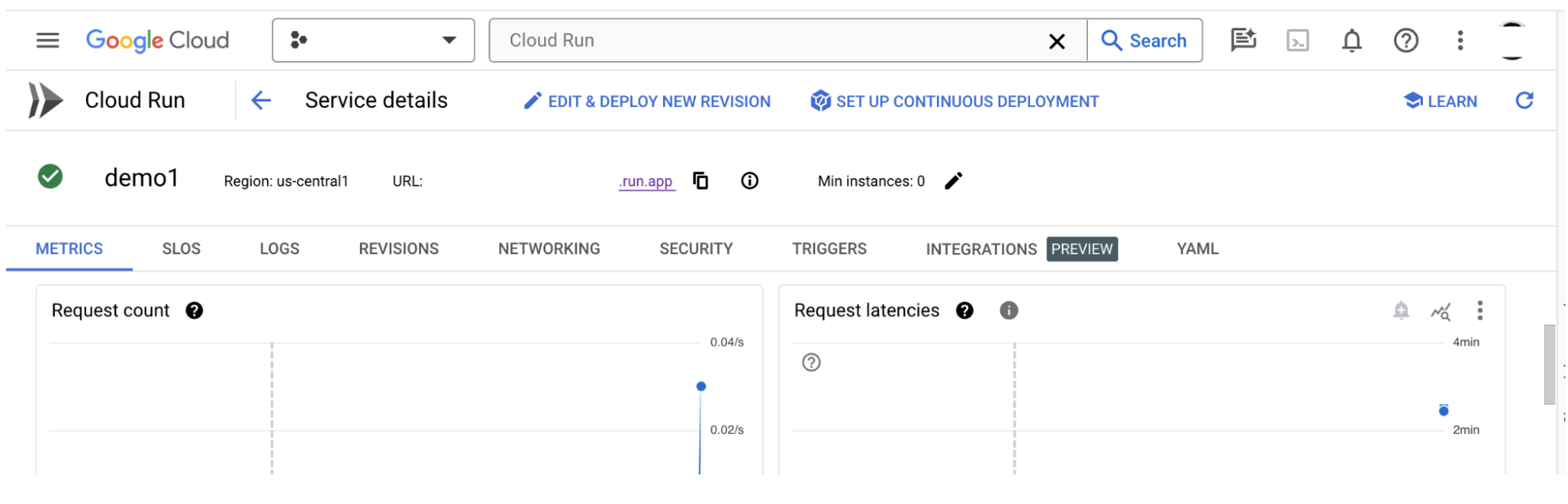
3-c : Charger les ensembles de données
Cliquez sur l'option Configure dans l'UI LIT, puis sélectionnez Dataset. Chargez l'ensemble de données en spécifiant un nom et en fournissant l'URL de l'ensemble de données. Le format de l'ensemble de données doit être .jsonl, où chaque enregistrement contient prompt et les champs facultatifs target et source.
4. Préparer les modèles Gemini dans Vertex AI Model Garden
Les modèles de fondation Gemini de Google sont disponibles dans l'API Vertex AI. LIT fournit le wrapper de modèle VertexAIModelGarden pour utiliser ces modèles pour la génération. Il vous suffit de spécifier la version souhaitée (par exemple, "gemini-1.5-pro-001") à l'aide du paramètre de nom de modèle. L'un des principaux avantages de ces modèles est qu'ils ne nécessitent aucun effort supplémentaire pour le déploiement. Par défaut, vous avez un accès immédiat à des modèles tels que Gemini 1.0 Pro et Gemini 1.5 Pro sur GCP, ce qui vous évite d'effectuer des étapes de configuration supplémentaires.
4-a : Accorder des autorisations Vertex AI
Pour interroger Gemini dans GCP, vous devez accorder des autorisations Vertex AI au compte de service. Assurez-vous que le nom du compte de service est Default compute service account. Copiez l'adresse e-mail du compte de service.
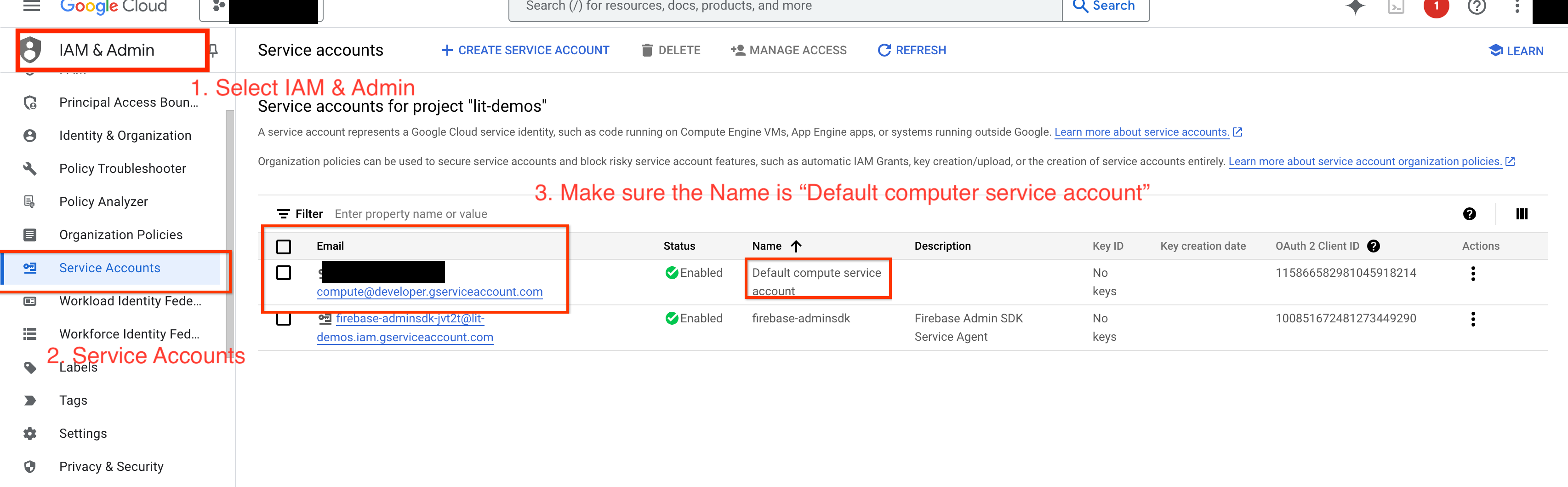
Ajoutez l'adresse e-mail du compte de service en tant qu'entité principale avec le rôle Vertex AI User dans votre liste d'autorisation IAM.

4-b : Charger les modèles Gemini
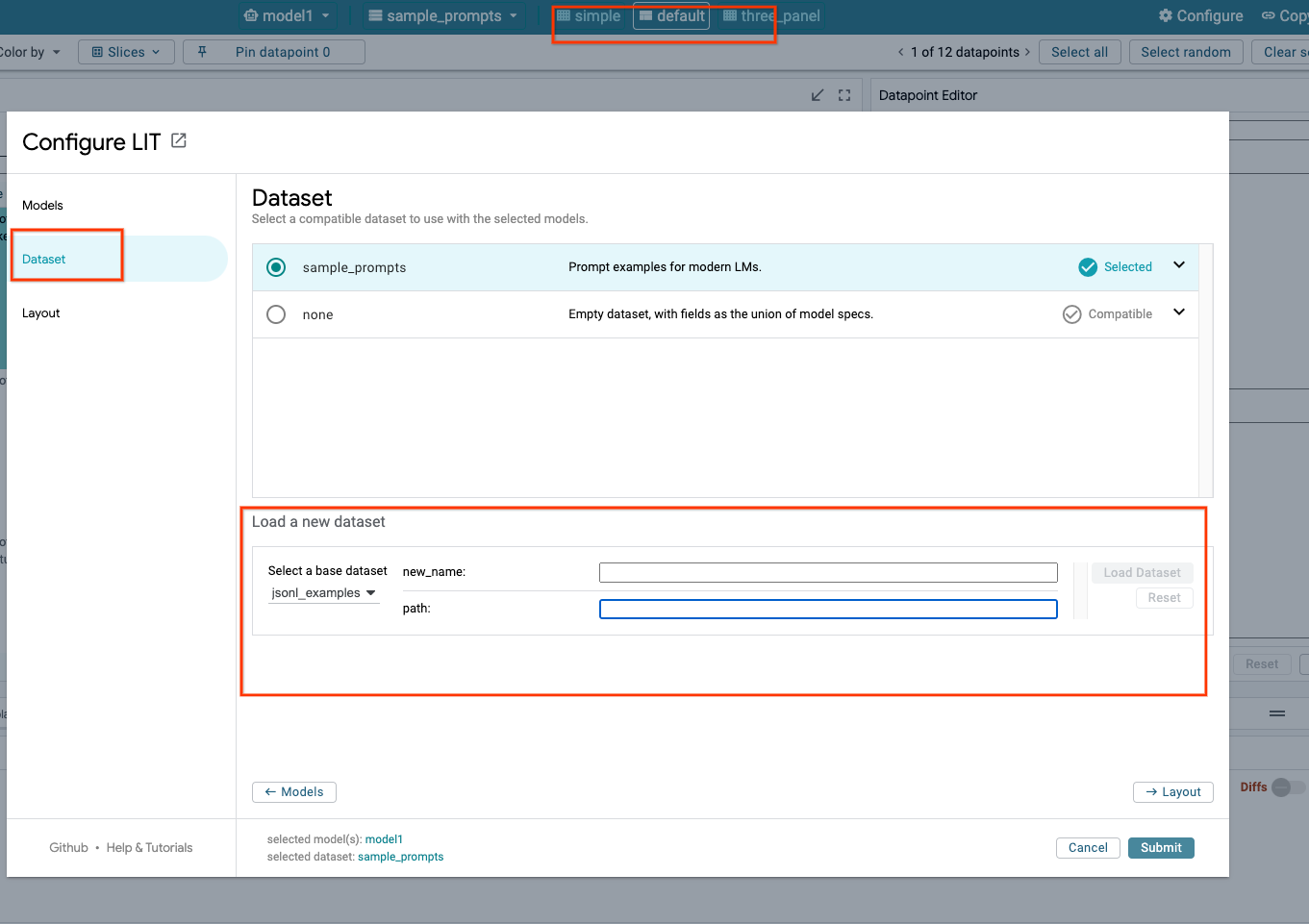
Vous allez charger des modèles Gemini et ajuster leurs paramètres en suivant les étapes ci-dessous.
- Cliquez sur l'option
Configuredans l'UI LIT.
- Cliquez sur l'option
- Sélectionnez l'option
geminisous l'optionSelect a base model.
- Sélectionnez l'option
- Vous devez nommer le modèle dans
new_name.
- Vous devez nommer le modèle dans
- Saisissez les modèles Gemini sélectionnés en tant que
model_name.
- Saisissez les modèles Gemini sélectionnés en tant que
- Cliquez sur
Load Model.
- Cliquez sur
- Cliquez sur
Submit.
- Cliquez sur
5. Déployer un serveur de modèles LLM auto-hébergés sur GCP
L'auto-hébergement de LLM avec l'image Docker du serveur de modèle LIT vous permet d'utiliser les fonctions de saillance et de tokenisation de LIT pour obtenir des insights plus approfondis sur le comportement du modèle. L'image du serveur de modèle fonctionne avec les modèles KerasNLP ou Hugging Face Transformers, y compris les poids fournis par la bibliothèque et auto-hébergés (par exemple, sur Google Cloud Storage).
5-a : Configurer les modèles
Chaque conteneur charge un modèle, configuré à l'aide de variables d'environnement.
Vous devez spécifier les modèles à charger en définissant MODEL_CONFIG. Le format doit être name:path, par exemple model_foo:model_foo_path. Le chemin d'accès peut être une URL, un chemin d'accès à un fichier local ou le nom d'un préréglage pour le framework de deep learning configuré (voir le tableau ci-dessous pour en savoir plus). Ce serveur est testé avec Gemma, GPT2, Llama et Mistral pour toutes les valeurs DL_FRAMEWORK compatibles. D'autres modèles devraient fonctionner, mais des ajustements peuvent être nécessaires.
# Set models you want to load. While 'gemma2b is given as a placeholder, you can load your preferred model by following the instructions above.
export MODEL_CONFIG=gemma2b:gemma_2b_en
De plus, le serveur de modèle LIT permet de configurer différentes variables d'environnement à l'aide de la commande ci-dessous. Pour en savoir plus, consultez le tableau. Notez que chaque variable doit être définie individuellement.
# Customize the variable value as needed.
export [VARIABLE]=[VALUE]
Variable | Valeurs | Description |
DL_FRAMEWORK |
| Bibliothèque de modélisation utilisée pour charger les pondérations du modèle sur le runtime spécifié. La valeur par défaut est |
DL_RUNTIME |
| Framework de backend de deep learning sur lequel le modèle s'exécute. Tous les modèles chargés par ce serveur utiliseront le même backend. Les incompatibilités entraîneront des erreurs. La valeur par défaut est |
PRÉCISION |
| Précision à virgule flottante pour les modèles LLM. La valeur par défaut est |
BATCH_SIZE | Entiers positifs | Nombre d'exemples à traiter par lot. La valeur par défaut est |
SEQUENCE_LENGTH | Entiers positifs | Longueur maximale de la séquence du texte d'entrée et du texte généré. La valeur par défaut est |
5-b : Déployer le serveur de modèle sur Cloud Run
Vous devez d'abord définir la dernière version de Model Server comme version à déployer.
# Set latest as MODEL_VERSION_TAG.
export MODEL_VERSION_TAG=latest
# List all the public LIT GCP model server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server
Après avoir défini le tag de version, vous devez nommer votre serveur de modèle.
# Set your Service name.
export MODEL_SERVICE_NAME='gemma2b-model-server'
Vous pouvez ensuite exécuter la commande suivante pour déployer le conteneur sur Cloud Run. Si vous ne définissez pas les variables d'environnement, des valeurs par défaut seront appliquées. Comme la plupart des LLM nécessitent des ressources de calcul coûteuses, il est vivement recommandé d'utiliser un GPU. Si vous préférez n'utiliser que le processeur (ce qui fonctionne bien pour les petits modèles comme GPT2), vous pouvez supprimer les arguments associés --gpu 1 --gpu-type nvidia-l4 --max-instances 7.
# Deploy the model service container.
gcloud beta run deploy $MODEL_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server:$MODEL_VERSION_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 7 \
--set-env-vars "MODEL_CONFIG=$MODEL_CONFIG" \
--no-allow-unauthenticated
Vous pouvez également personnaliser les variables d'environnement en ajoutant les commandes suivantes. N'incluez que les variables d'environnement nécessaires à vos besoins spécifiques.
--set-env-vars "DL_FRAMEWORK=$DL_FRAMEWORK" \
--set-env-vars "DL_RUNTIME=$DL_RUNTIME" \
--set-env-vars "PRECISION=$PRECISION" \
--set-env-vars "BATCH_SIZE=$BATCH_SIZE" \
--set-env-vars "SEQUENCE_LENGTH=$SEQUENCE_LENGTH" \
Des variables d'environnement supplémentaires peuvent être nécessaires pour accéder à certains modèles. Consultez les instructions de Kaggle Hub (utilisé pour les modèles KerasNLP) et de Hugging Face Hub, selon le cas.
5-c : Accéder au serveur de modèles
Une fois le serveur de modèle créé, le service démarré est disponible dans la section Cloud Run de votre projet GCP.
Sélectionnez le serveur de modèle que vous venez de créer. Assurez-vous que le nom du service est identique à MODEL_SERVICE_NAME.
Vous pouvez trouver l'URL du service en cliquant sur le service de modèle que vous venez de déployer.
Vous pouvez consulter la section "JOURNAUX" pour surveiller l'activité, afficher les messages d'erreur et suivre la progression du déploiement.
Vous pouvez consulter la section "MÉTRIQUES" pour afficher les métriques du service.
5-d : Charger des modèles auto-hébergés
Si vous configurez un proxy pour votre serveur LIT à l'étape 3 (consultez la section "Dépannage"), vous devrez obtenir votre jeton d'identité GCP en exécutant la commande suivante.
# Find your GCP identity token.
gcloud auth print-identity-token
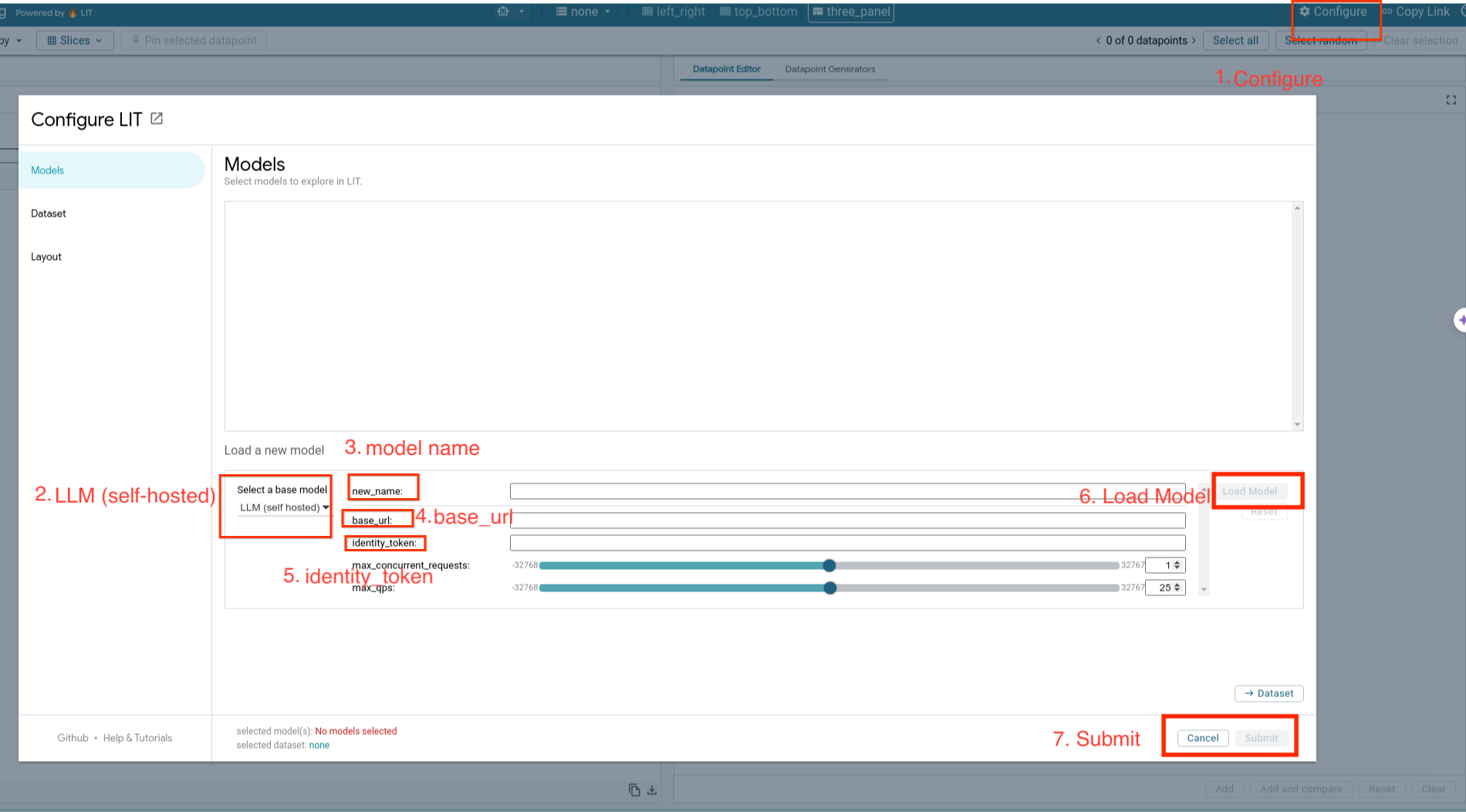
Vous allez charger des modèles auto-hébergés et ajuster leurs paramètres en suivant les étapes ci-dessous.
- Cliquez sur l'option
Configuredans l'UI LIT. - Sélectionnez l'option
LLM (self hosted)sous l'optionSelect a base model. - Vous devez nommer le modèle dans
new_name. - Saisissez l'URL de votre serveur de modèles en tant que
base_url. - Saisissez le jeton d'identité obtenu dans
identity_tokensi vous utilisez un proxy pour le serveur de l'application LIT (voir les étapes 3 et 7). Sinon, laissez-le vide. - Cliquez sur
Load Model. - Cliquez sur
Submit.
6. Interagir avec LIT sur GCP
LIT propose un large éventail de fonctionnalités pour vous aider à déboguer et à comprendre les comportements des modèles. Vous pouvez effectuer une requête simple auprès du modèle en saisissant du texte dans une zone et en affichant les prédictions du modèle, ou inspecter les modèles en profondeur grâce à la suite de fonctionnalités puissantes de LIT, y compris :
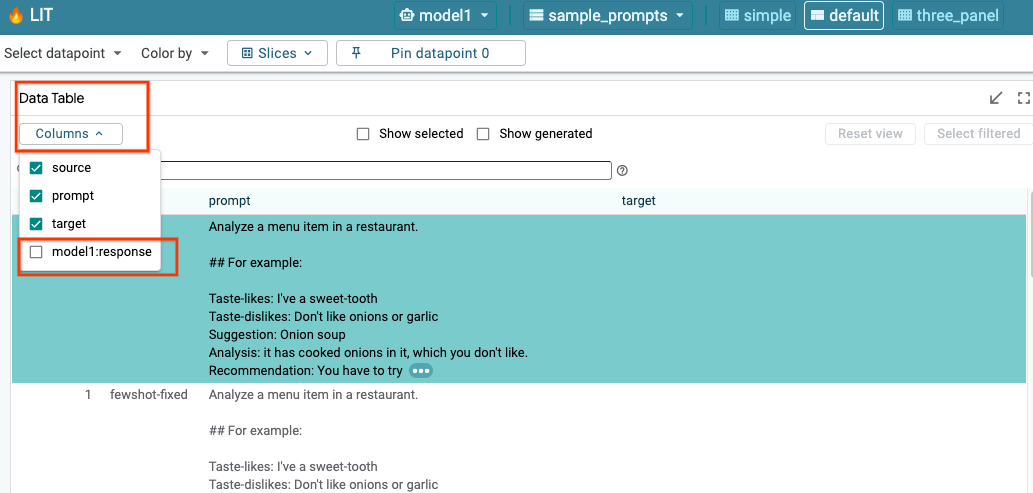
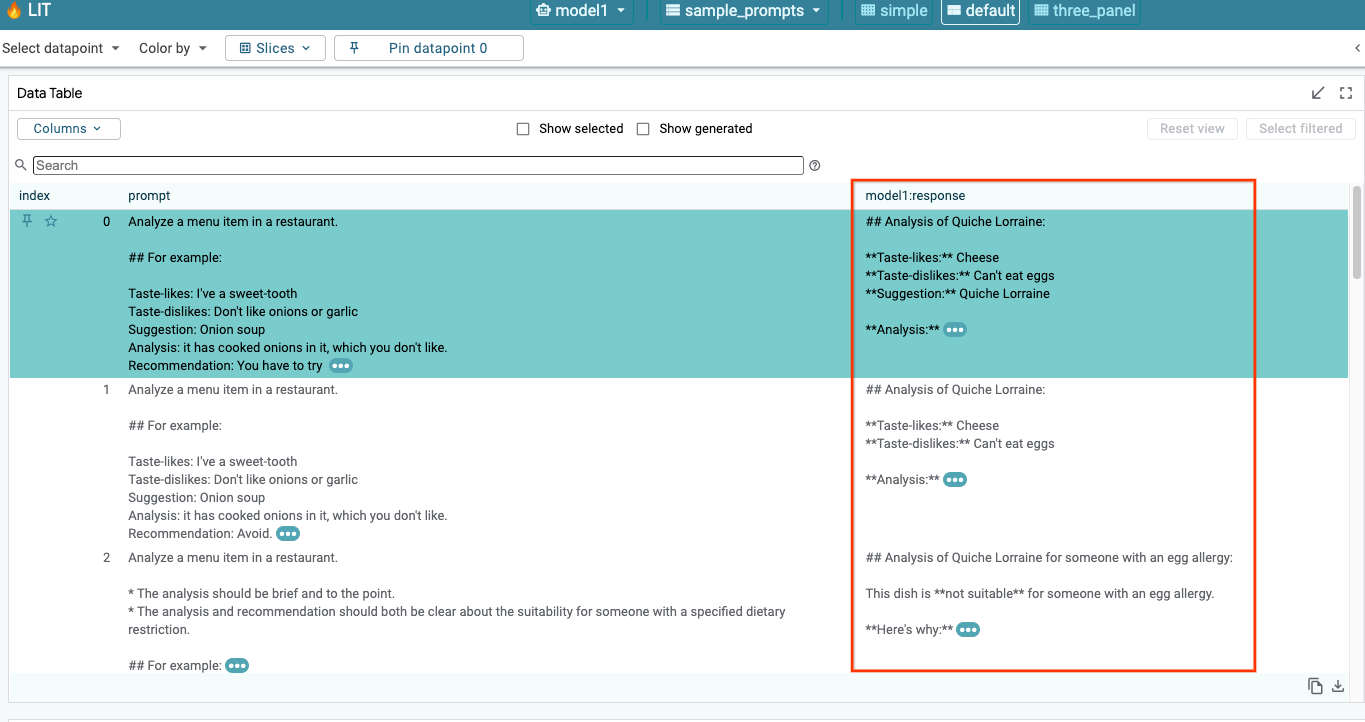
6-a : Interroger le modèle via LIT
LIT interroge automatiquement l'ensemble de données après le chargement du modèle et de l'ensemble de données. Vous pouvez afficher la réponse de chaque modèle en la sélectionnant dans les colonnes.
6-b : Utiliser la technique de saillance de séquence
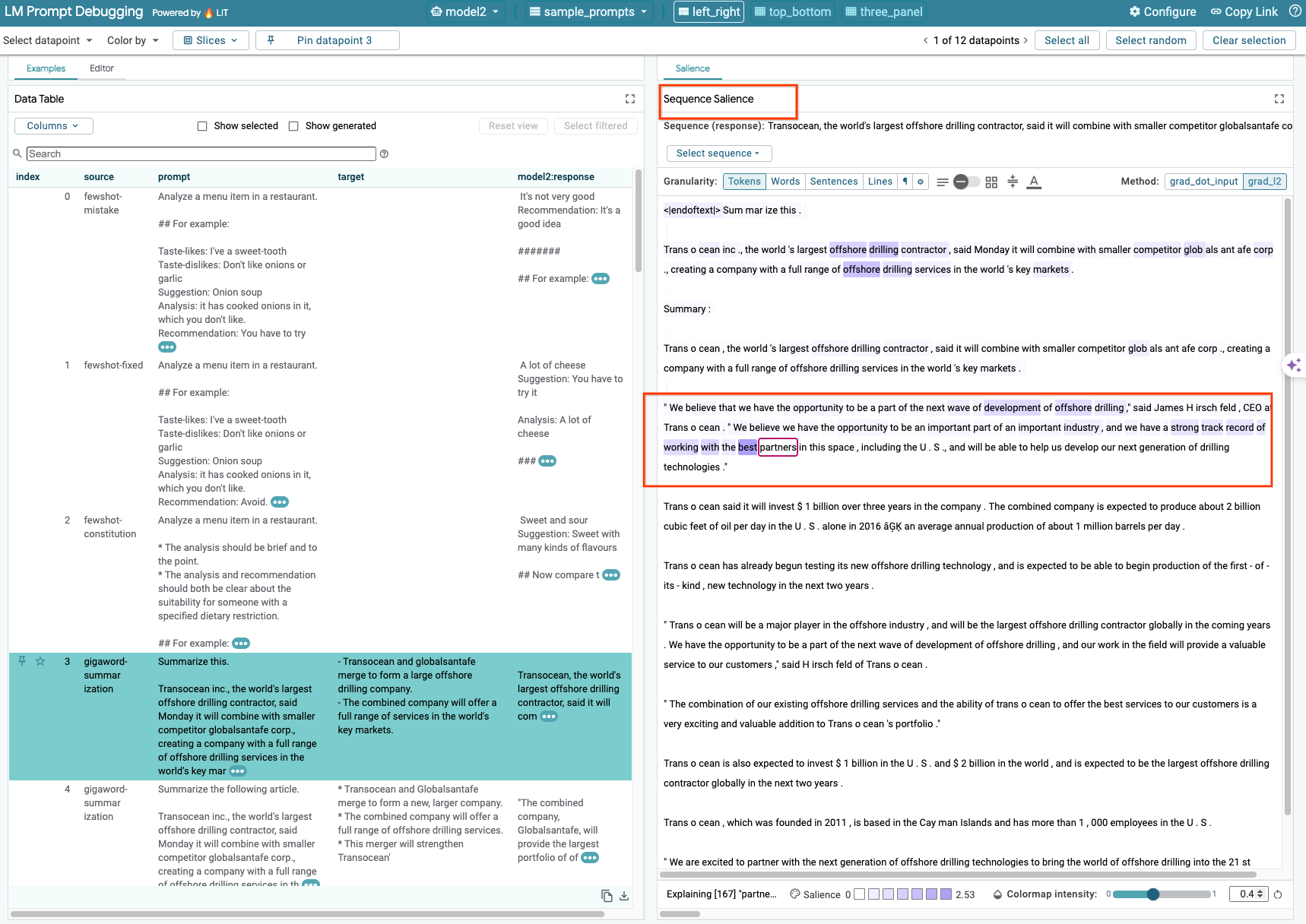
Actuellement, la technique de saillance de séquence sur LIT n'est compatible qu'avec les modèles auto-hébergés.
La saillance de séquence est un outil visuel qui permet de déboguer les requêtes LLM en mettant en évidence les parties d'une requête les plus importantes pour une sortie donnée. Pour en savoir plus sur la saillance de séquence, consultez le tutoriel complet sur l'utilisation de cette fonctionnalité.
Pour accéder aux résultats de saillance, cliquez sur une entrée ou une sortie dans la requête ou la réponse. Les résultats de saillance s'affichent alors.
6-c : Modifier manuellement le prompt et la cible
LIT vous permet de modifier manuellement les prompt et target pour les points de données existants. En cliquant sur Add, la nouvelle entrée est ajoutée à l'ensemble de données.
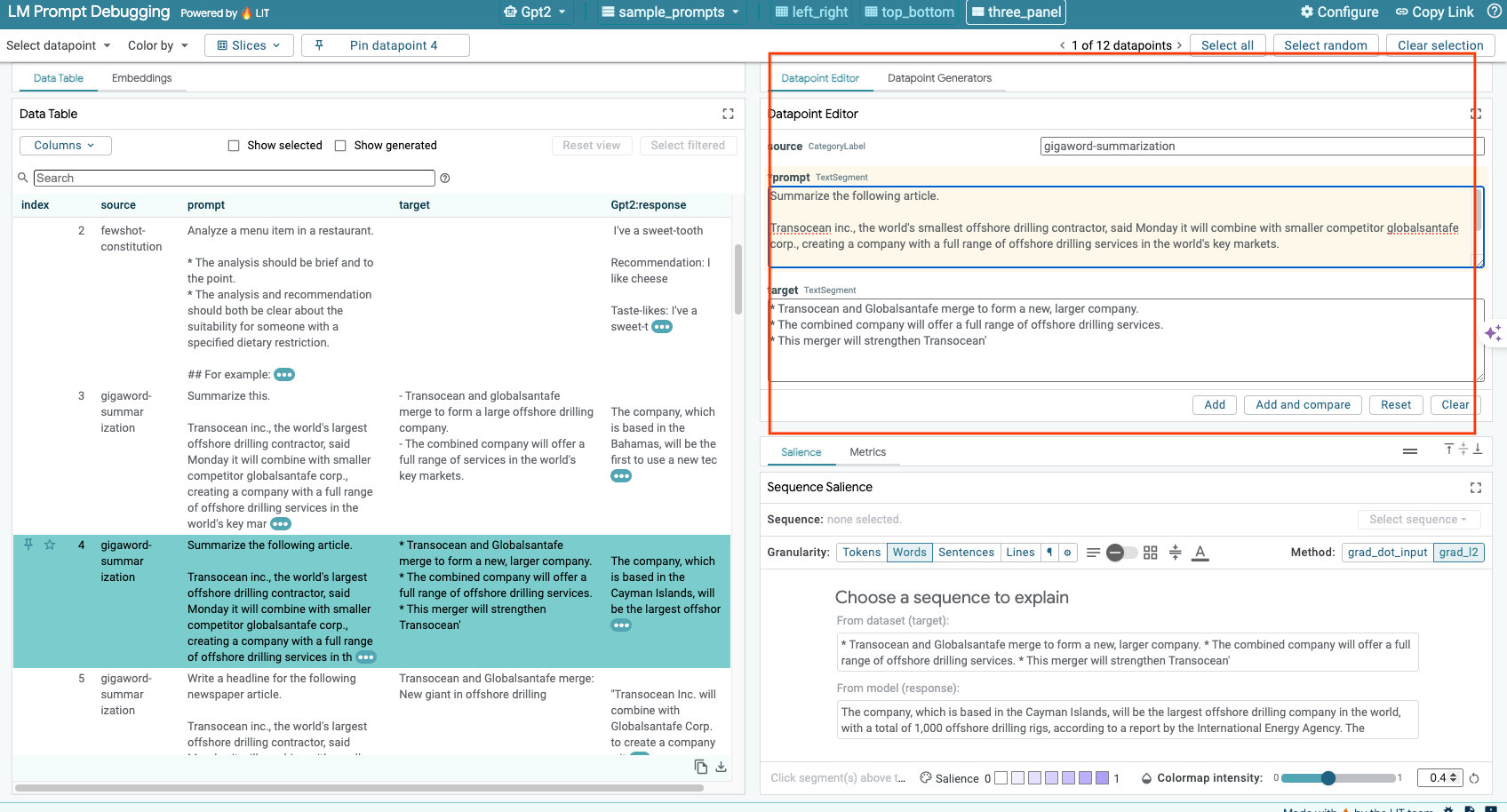
6-d : Comparer les requêtes côte à côte
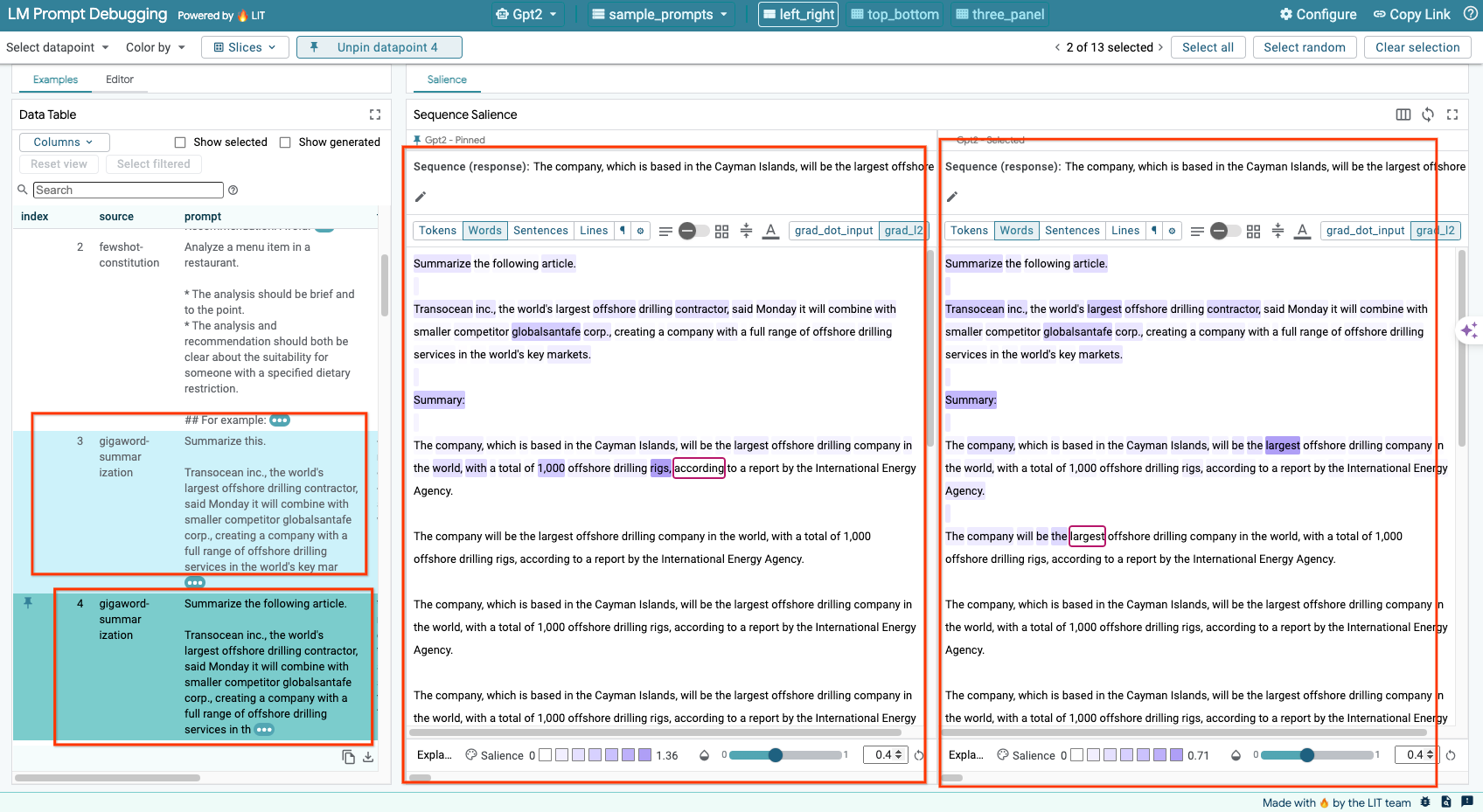
LIT vous permet de comparer des requêtes côte à côte sur des exemples originaux et modifiés. Vous pouvez modifier manuellement un exemple et afficher simultanément le résultat de la prédiction et l'analyse de la saillance de séquence pour les versions d'origine et modifiée. Vous pouvez modifier la requête pour chaque point de données. LIT générera la réponse correspondante en interrogeant le modèle.
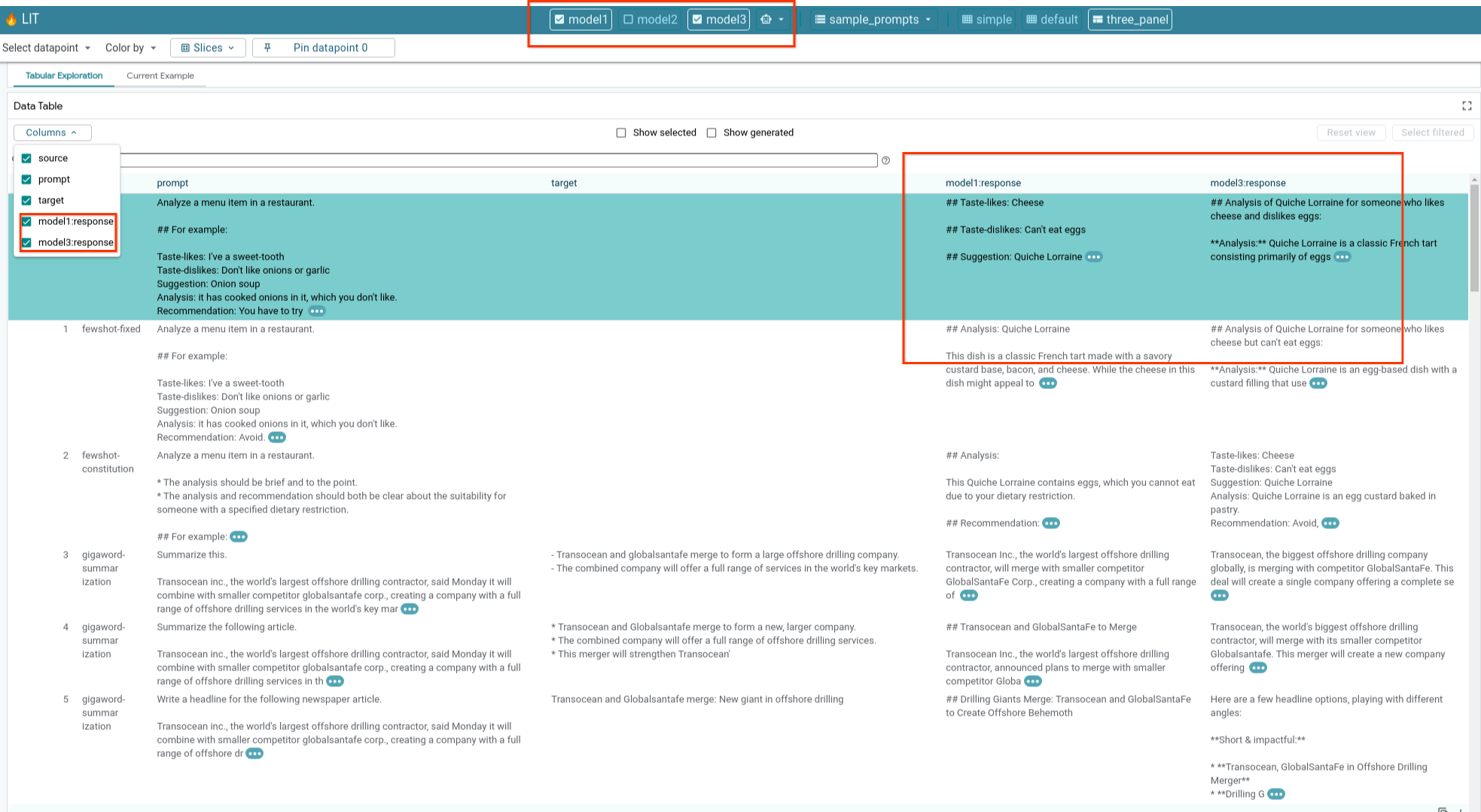
6-e : Comparer plusieurs modèles côte à côte
LIT permet de comparer côte à côte des modèles sur des exemples individuels de génération et de notation de texte, ainsi que sur des exemples agrégés pour des métriques spécifiques. En interrogeant différents modèles chargés, vous pouvez facilement comparer les différences dans leurs réponses.
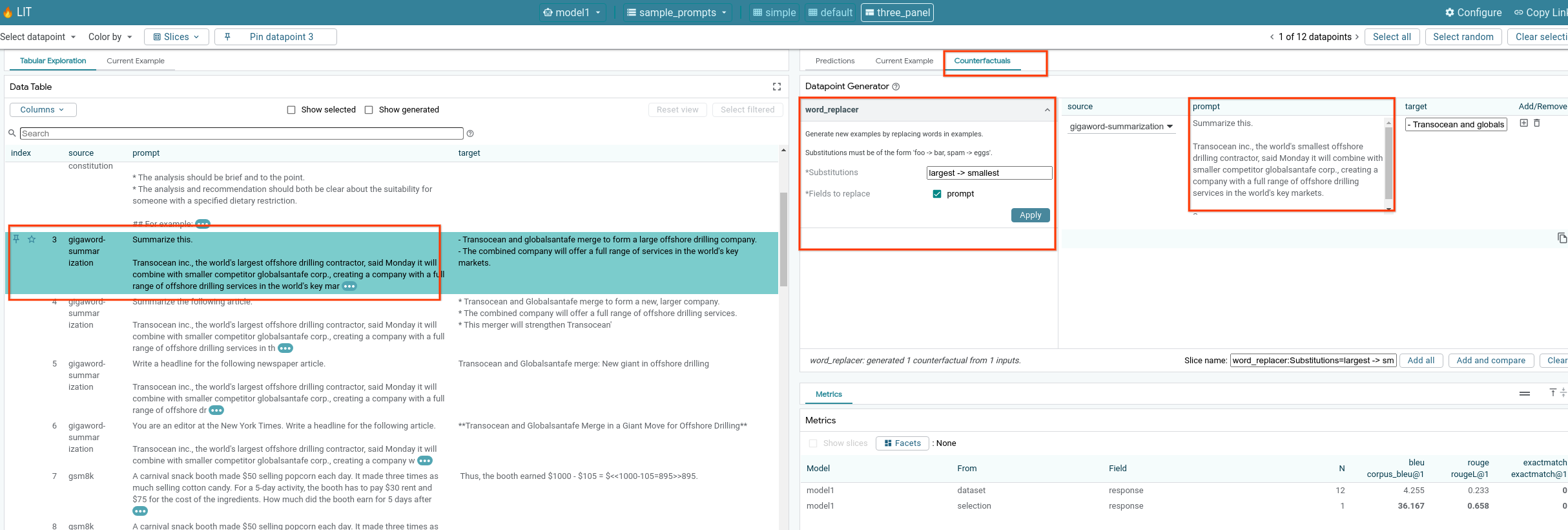
6-f : Générateurs de contrefactuels automatiques
Vous pouvez utiliser des générateurs de contrefactuels automatiques pour créer des entrées alternatives et voir immédiatement comment votre modèle se comporte avec celles-ci.
6-g : Évaluer les performances du modèle
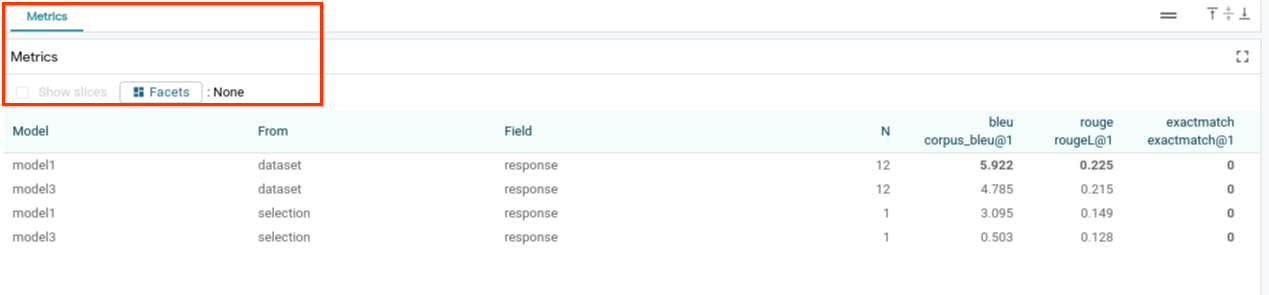
Vous pouvez évaluer les performances du modèle à l'aide de métriques (actuellement, les scores BLEU et ROUGE pour la génération de texte) sur l'ensemble de données ou sur des sous-ensembles d'exemples filtrés ou sélectionnés.
7. Dépannage
7-a : Problèmes d'accès potentiels et solutions
Étant donné que --no-allow-unauthenticated est appliqué lors du déploiement sur Cloud Run, vous pouvez rencontrer des erreurs d'accès interdit, comme indiqué ci-dessous.

Il existe deux façons d'accéder au service de l'application LIT.
1. Proxy vers un service local
Vous pouvez relayer le service vers l'hôte local à l'aide de la commande ci-dessous.
# Proxy the service to local host.
gcloud run services proxy $LIT_SERVICE_NAME
Vous devriez ensuite pouvoir accéder au serveur LIT en cliquant sur le lien du service proxy.
2. Authentifier directement les utilisateurs
Vous pouvez suivre ce lien pour authentifier les utilisateurs, ce qui leur permet d'accéder directement au service LIT App. Cette approche peut également permettre à un groupe d'utilisateurs d'accéder au service. Il s'agit d'une option plus efficace pour le développement impliquant une collaboration avec plusieurs personnes.
7-b : vérifications pour s'assurer que le serveur de modèle a bien été lancé
Pour vous assurer que le serveur de modèles a bien été lancé, vous pouvez l'interroger directement en envoyant une requête. Le serveur de modèle fournit trois points de terminaison : predict, tokenize et salience. Assurez-vous de fournir les champs prompt et target dans votre demande.
# Query the model server predict endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/predict -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server tokenize endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/tokenize -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server salience endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/salience -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
Si vous rencontrez un problème d'accès, consultez la section 7-a ci-dessus.
8. Félicitations
Bravo ! Vous avez terminé cet atelier de programmation. C'est l'heure de se détendre !
Effectuer un nettoyage
Pour nettoyer l'atelier, supprimez tous les services Google Cloud créés pour l'atelier. Utilisez Google Cloud Shell pour exécuter les commandes suivantes.
Si la connexion Google Cloud est perdue en raison de l'inactivité, réinitialisez les variables en suivant les étapes précédentes.
# Delete the LIT App Service.
gcloud run services delete $LIT_SERVICE_NAME
Si vous avez démarré le serveur de modèle, vous devez également le supprimer.
# Delete the Model Service.
gcloud run services delete $MODEL_SERVICE_NAME
Complément d'informations
Continuez à découvrir les fonctionnalités de l'outil LIT grâce aux ressources ci-dessous :
- Gemma : lien
- Base de code Open Source LIT : dépôt Git
- Document LIT : ArXiv
- Document sur le débogage des invites LIT : ArXiv
- Vidéo de démonstration de la fonctionnalité LIT : YouTube
- Démonstration du débogage des invites LIT : YouTube
- Boîte à outils pour une IA générative responsable : lien
Contact
Pour toute question ou problème concernant cet atelier de programmation, veuillez nous contacter sur GitHub.
Licence
Ce document est publié sous une licence Creative Commons Attribution 4.0 Generic.