
1. Panoramica
Questo lab fornisce una procedura dettagliata per il deployment di un server delle applicazioni LIT su Google Cloud (GCP) per interagire con i foundation model Gemini di Vertex AI e con i modelli linguistici di grandi dimensioni (LLM) di terze parti self-hosted. Include anche indicazioni su come utilizzare la GUI LIT per il debug dei prompt e l'interpretazione dei modelli.
Seguendo questo lab, gli utenti impareranno a:
- Configura un server LIT su GCP.
- Connetti il server LIT ai modelli Gemini di Vertex AI o ad altri LLM self-hosted.
- Utilizza la UI di LIT per analizzare, eseguire il debug e interpretare i prompt per ottenere prestazioni e approfondimenti migliori del modello.
Che cos'è LIT?
LIT è uno strumento visivo e interattivo per la comprensione dei modelli che supporta dati di testo, immagine e tabulari. Può essere eseguito come server autonomo o all'interno di ambienti notebook come Google Colab, Jupyter e Google Cloud Vertex AI. LIT è disponibile su PyPI e GitHub.
Originariamente creato per comprendere i modelli di classificazione e regressione, i recenti aggiornamenti hanno aggiunto strumenti per il debug dei prompt LLM, consentendoti di esplorare in che modo i contenuti di utenti, modelli e sistemi influenzano il comportamento di generazione.
Che cos'è Vertex AI e Model Garden?
Vertex AI è una piattaforma di machine learning (ML) che ti consente di addestrare ed eseguire il deployment di modelli ML e applicazioni AI e personalizzare LLM da utilizzare nelle tue applicazioni basate sull'AI. Vertex AI combina i workflow di data engineering, data science e ML engineering per consentire ai team di collaborare utilizzando una serie comune di strumenti, nonché scalare le applicazioni sfruttando i vantaggi di Google Cloud.
Vertex Model Garden è una libreria di modelli ML che ti aiuta a scoprire, testare, personalizzare ed eseguire il deployment di modelli e asset proprietari di Google e di terze parti selezionati.
Cosa farai
Utilizzerai Google Cloud Shell e Cloud Run per eseguire il deployment di un container Docker dall'immagine predefinita di LIT.
Cloud Run è una piattaforma di computing gestita che ti consente di eseguire container direttamente sull'infrastruttura scalabile di Google, incluse le GPU.
Set di dati
Per impostazione predefinita, la demo utilizza il set di dati di esempio per il debug dei prompt LIT oppure puoi caricare il tuo tramite l'UI.
Prima di iniziare
Per questa guida di riferimento, hai bisogno di un progetto Google Cloud. Puoi crearne uno nuovo o selezionarne uno già esistente.
2. Avvia la console Google Cloud e Cloud Shell
In questo passaggio avvierai una console Google Cloud e utilizzerai Google Cloud Shell.
2-a: Avvia una console Google Cloud
Avvia un browser e vai alla console Google Cloud.
La console Google Cloud è un'interfaccia di amministrazione web potente e sicura che ti consente di gestire rapidamente le risorse Google Cloud. È uno strumento DevOps ovunque ti trovi.
2b. Avvia una Google Cloud Shell
Cloud Shell è un ambiente operativo e di sviluppo online accessibile ovunque con il browser. Puoi gestire le tue risorse tramite il suo terminale online che dispone di utilità precaricate come lo strumento a riga di comando gcloud, kubectl e molto altro. Puoi anche sviluppare, creare, eseguire il debug e il deployment delle tue app basate su cloud utilizzando l'editor di Cloud Shell online. Cloud Shell fornisce un ambiente online pronto per gli sviluppatori con un insieme di strumenti preferiti preinstallati e 5 GB di spazio di archiviazione permanente. Nei passaggi successivi utilizzerai il prompt dei comandi.
Avvia Google Cloud Shell utilizzando l'icona in alto a destra della barra dei menu, cerchiata in blu nello screenshot seguente.

Nella parte inferiore della pagina dovresti vedere un terminale con una shell Bash.

2-c: Imposta il progetto Google Cloud
Devi impostare l'ID progetto e la regione del progetto utilizzando il comando gcloud.
# Set your GCP Project ID.
gcloud config set project your-project-id
# Set your GCP Project Region.
gcloud config set run/region your-project-region
3. Esegui il deployment dell'immagine Docker del server app LIT con Cloud Run
3-a: Esegui il deployment dell'app LIT in Cloud Run
Devi prima impostare l'ultima versione di LIT-App come versione da implementare.
# Set latest version as your LIT_SERVICE_TAG.
export LIT_SERVICE_TAG=latest
# List all the public LIT GCP App server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app
Dopo aver impostato il tag della versione, devi assegnare un nome al servizio.
# Set your lit service name. While 'lit-app-service' is provided as a placeholder, you can customize the service name based on your preferences.
export LIT_SERVICE_NAME=lit-app-service
Dopodiché, puoi eseguire questo comando per eseguire il deployment del container su Cloud Run.
# Use below cmd to deploy the LIT App to Cloud Run.
gcloud run deploy $LIT_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app:$LIT_SERVICE_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--no-allow-unauthenticated
LIT ti consente anche di aggiungere il set di dati all'avvio del server. Per farlo, imposta la variabile DATASETS in modo che includa i dati che vuoi caricare, utilizzando il formato name:path, ad esempio data_foo:/bar/data_2024.jsonl. Il formato del set di dati deve essere .jsonl, in cui ogni record contiene i campi prompt e, facoltativamente, target e source. Per caricare più set di dati, separali con una virgola. Se non viene impostato, verrà caricato il set di dati di esempio per il debug del prompt LIT.
# Set the dataset.
export DATASETS=[DATASETS]
Impostando MAX_EXAMPLES, puoi impostare il numero massimo di esempi da caricare da ogni set di valutazione.
# Set the max examples.
export MAX_EXAMPLES=[MAX_EXAMPLES]
Poi, nel comando di deployment, puoi aggiungere
--set-env-vars "DATASETS=$DATASETS" \
--set-env-vars "MAX_EXAMPLES=$MAX_EXAMPLES" \
3-b: Visualizza il servizio app LIT
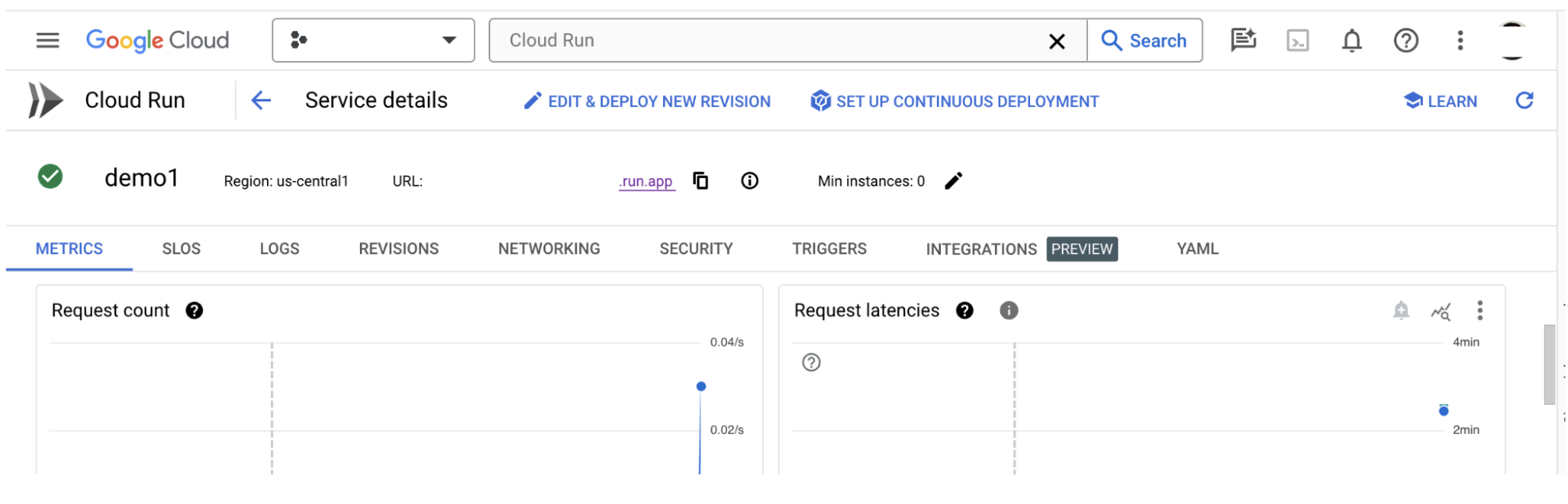
Dopo aver creato il server dell'app LIT, puoi trovare il servizio nella sezione Cloud Run di Cloud Console.
Seleziona il servizio LIT App appena creato. Assicurati che il nome del servizio sia uguale a LIT_SERVICE_NAME.
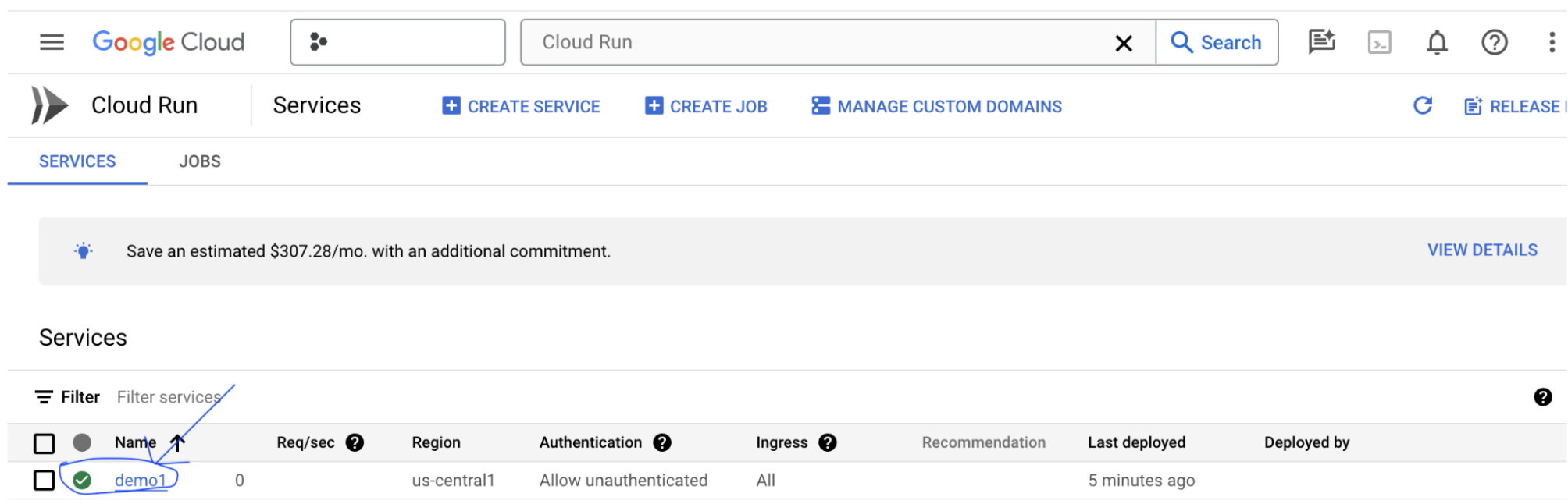
Puoi trovare l'URL del servizio facendo clic sul servizio di cui hai appena eseguito il deployment.
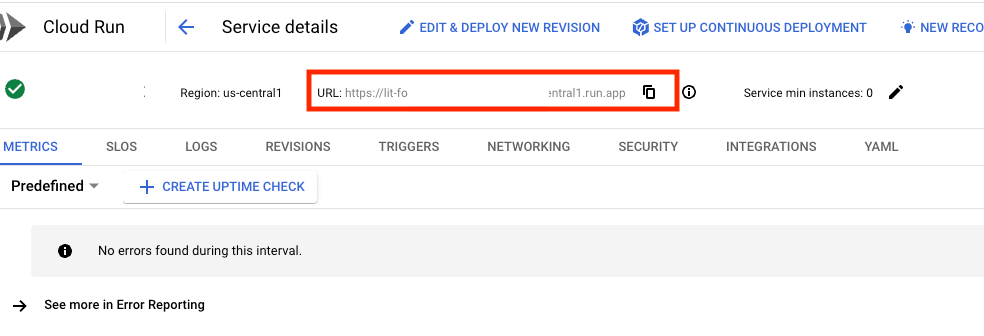
Dovresti quindi essere in grado di visualizzare la UI di LIT. Se si verifica un errore, consulta la sezione Risoluzione dei problemi.
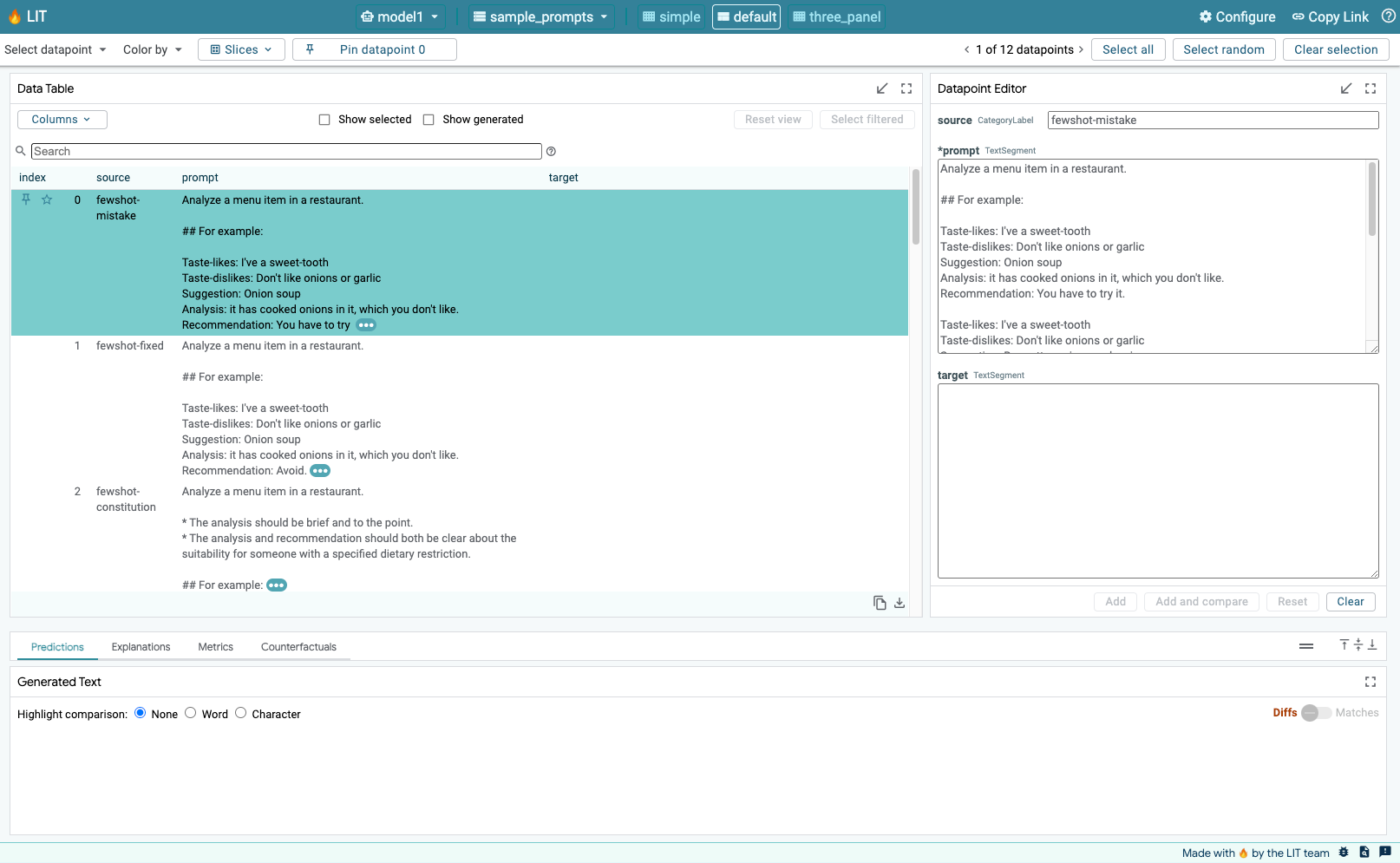
Puoi controllare la sezione LOG per monitorare l'attività, visualizzare i messaggi di errore e monitorare l'avanzamento del deployment.
Puoi controllare la sezione METRICHE per visualizzare le metriche del servizio.
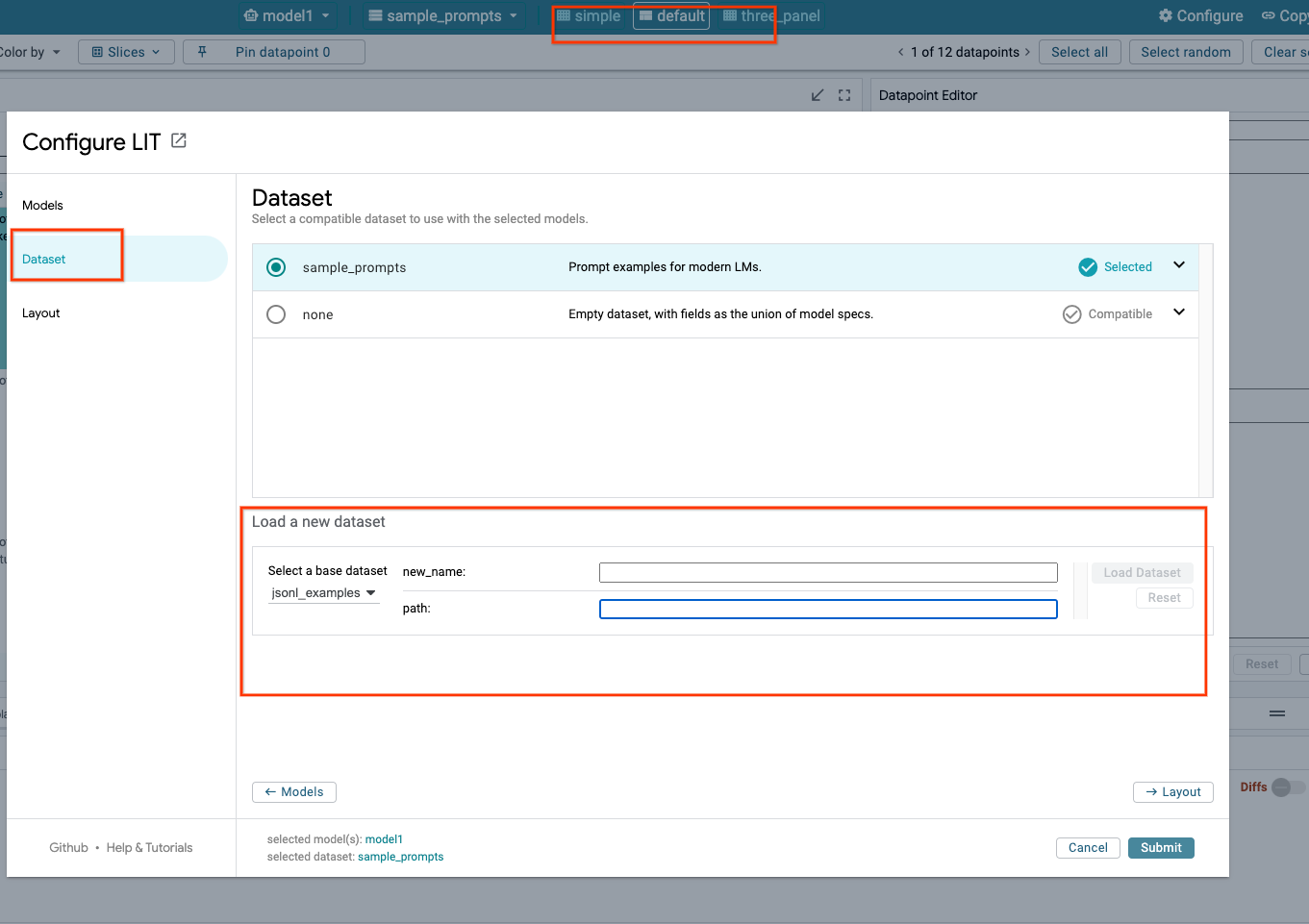
3-c: Carica i set di dati
Fai clic sull'opzione Configure nell'interfaccia utente di LIT, seleziona Dataset. Carica il set di dati specificando un nome e fornendo l'URL del set di dati. Il formato del set di dati deve essere .jsonl, in cui ogni record contiene i campi prompt e, facoltativamente, target e source.
4. Prepara i modelli Gemini in Vertex AI Model Garden
I foundation model Gemini di Google sono disponibili dall'API Vertex AI. LIT fornisce il wrapper del modello VertexAIModelGarden per utilizzare questi modelli per la generazione. Specifica semplicemente la versione desiderata (ad es. "gemini-1.5-pro-001") tramite il parametro del nome del modello. Uno dei principali vantaggi dell'utilizzo di questi modelli è che non richiedono alcuno sforzo aggiuntivo per il deployment. Per impostazione predefinita, hai accesso immediato a modelli come Gemini 1.0 Pro e Gemini 1.5 Pro su GCP, eliminando la necessità di ulteriori passaggi di configurazione.
4a: Concedi le autorizzazioni Vertex AI
Per eseguire query su Gemini in Google Cloud, devi concedere le autorizzazioni Vertex AI al service account. Assicurati che il nome del service account sia Default compute service account. Copia l'indirizzo email del service account.
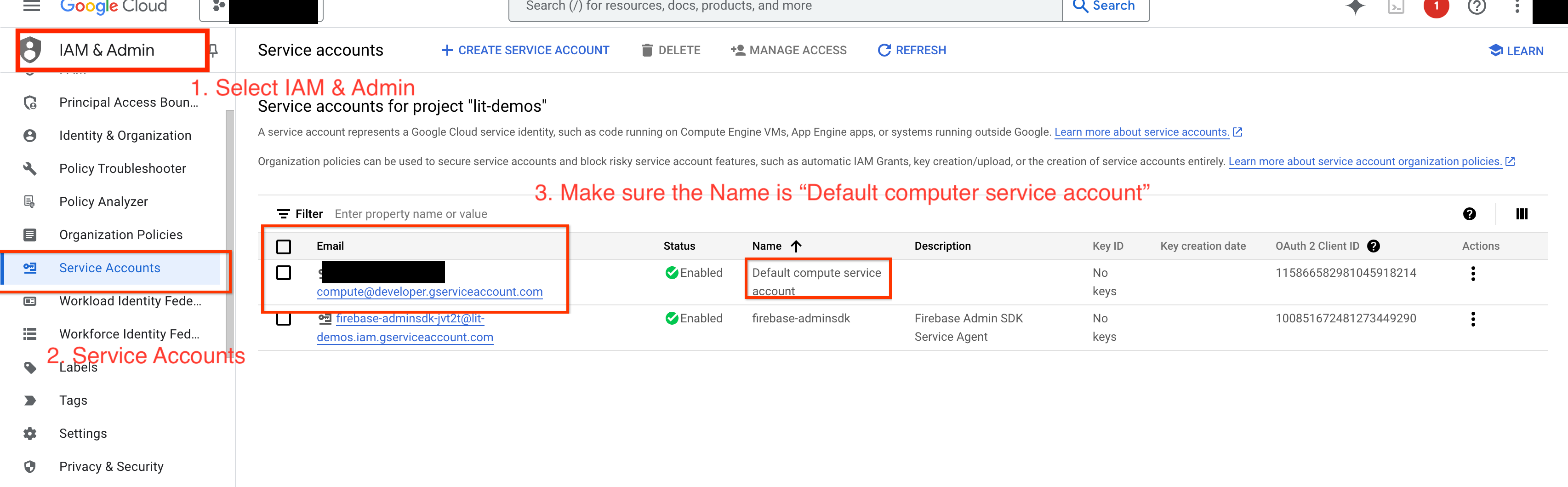
Aggiungi l'email del service account come entità con il ruolo Vertex AI User nella lista consentita IAM.

4-b: Carica i modelli Gemini
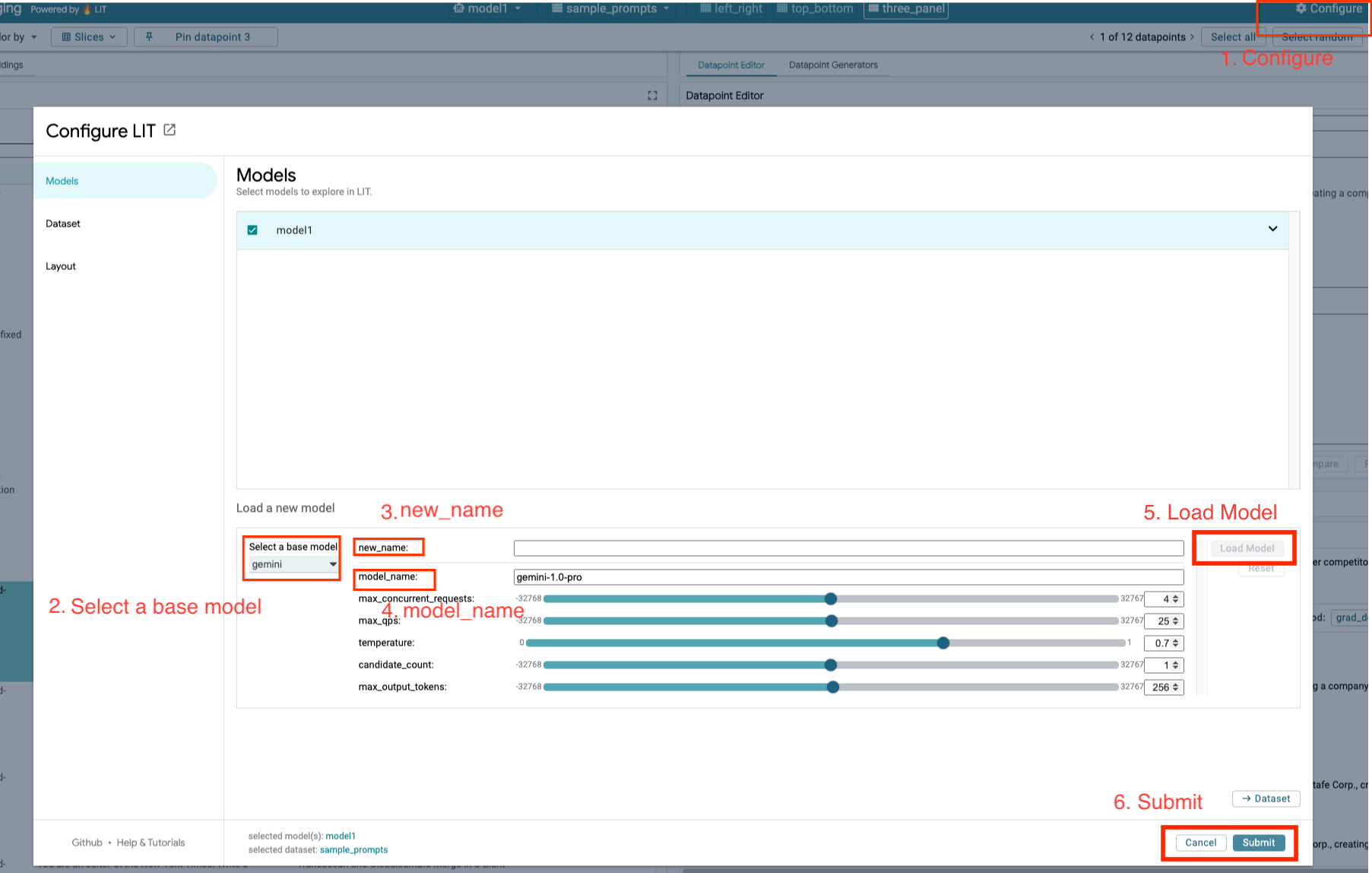
Caricherai i modelli Gemini e regolerai i relativi parametri seguendo i passaggi riportati di seguito.
- Fai clic sull'opzione
Configurenell'interfaccia utente di LIT.
- Fai clic sull'opzione
- Seleziona l'opzione
gemininella sezioneSelect a base model.
- Seleziona l'opzione
- Devi assegnare un nome al modello in
new_name.
- Devi assegnare un nome al modello in
- Inserisci i modelli Gemini selezionati come
model_name.
- Inserisci i modelli Gemini selezionati come
- Fai clic su
Load Model.
- Fai clic su
- Fai clic su
Submit.
- Fai clic su
5. Esegui il deployment del server di modelli LLM autogestiti su GCP
L'hosting autonomo di LLM con l'immagine Docker del server di modelli di LIT ti consente di utilizzare le funzioni di salienza e tokenizzazione di LIT per ottenere informazioni più approfondite sul comportamento del modello. L'immagine del server del modello funziona con i modelli KerasNLP o Hugging Face Transformers, inclusi i pesi forniti dalla libreria e quelli ospitati autonomamente, ad esempio su Google Cloud Storage.
5-a: Configura modelli
Ogni container carica un modello, configurato utilizzando le variabili di ambiente.
Devi specificare i modelli da caricare impostando MODEL_CONFIG. Il formato deve essere name:path, ad esempio model_foo:model_foo_path. Il percorso può essere un URL, un percorso di file locale o il nome di un preset per il framework di deep learning configurato (vedi la tabella seguente per maggiori dettagli). Questo server è testato con Gemma, GPT2, Llama e Mistral su tutti i valori DL_FRAMEWORK supportati. Dovrebbero funzionare anche altri modelli, ma potrebbero essere necessari degli aggiustamenti.
# Set models you want to load. While 'gemma2b is given as a placeholder, you can load your preferred model by following the instructions above.
export MODEL_CONFIG=gemma2b:gemma_2b_en
Inoltre, il server del modello LIT consente la configurazione di varie variabili di ambiente utilizzando il comando riportato di seguito. Per maggiori dettagli, consulta la tabella. Tieni presente che ogni variabile deve essere impostata singolarmente.
# Customize the variable value as needed.
export [VARIABLE]=[VALUE]
Variabile | Valori | Descrizione |
DL_FRAMEWORK |
| La libreria di modellazione utilizzata per caricare i pesi del modello sul runtime specificato. Il valore predefinito è |
DL_RUNTIME |
| Il framework di backend di deep learning su cui viene eseguito il modello. Tutti i modelli caricati da questo server utilizzeranno lo stesso backend e le incompatibilità comporteranno errori. Il valore predefinito è |
PRECISIONE |
| Precisione in virgola mobile per i modelli LLM. Il valore predefinito è |
BATCH_SIZE | Numeri interi positivi | Il numero di esempi da elaborare per batch. Il valore predefinito è |
SEQUENCE_LENGTH | Numeri interi positivi | La lunghezza massima della sequenza del prompt di input più il testo generato. Il valore predefinito è |
5-b: Esegui il deployment di Model Server su Cloud Run
Devi prima impostare l'ultima versione di Model Server come versione da implementare.
# Set latest as MODEL_VERSION_TAG.
export MODEL_VERSION_TAG=latest
# List all the public LIT GCP model server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server
Dopo aver impostato il tag della versione, devi assegnare un nome al server del modello.
# Set your Service name.
export MODEL_SERVICE_NAME='gemma2b-model-server'
Dopodiché, puoi eseguire questo comando per eseguire il deployment del container su Cloud Run. Se non imposti le variabili di ambiente, verranno applicati i valori predefiniti. Poiché la maggior parte dei LLM richiede risorse di calcolo costose, è consigliabile utilizzare la GPU. Se preferisci eseguire solo sulla CPU (il che funziona bene per modelli piccoli come GPT2), puoi rimuovere gli argomenti correlati --gpu 1 --gpu-type nvidia-l4 --max-instances 7.
# Deploy the model service container.
gcloud beta run deploy $MODEL_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server:$MODEL_VERSION_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 7 \
--set-env-vars "MODEL_CONFIG=$MODEL_CONFIG" \
--no-allow-unauthenticated
Inoltre, puoi personalizzare le variabili di ambiente aggiungendo i seguenti comandi. Includi solo le variabili di ambiente necessarie per le tue esigenze specifiche.
--set-env-vars "DL_FRAMEWORK=$DL_FRAMEWORK" \
--set-env-vars "DL_RUNTIME=$DL_RUNTIME" \
--set-env-vars "PRECISION=$PRECISION" \
--set-env-vars "BATCH_SIZE=$BATCH_SIZE" \
--set-env-vars "SEQUENCE_LENGTH=$SEQUENCE_LENGTH" \
Per accedere a determinati modelli potrebbero essere necessarie variabili di ambiente aggiuntive. Consulta le istruzioni di Kaggle Hub (utilizzato per i modelli KerasNLP) e di Hugging Face Hub, a seconda dei casi.
5-c: Accedi al server del modello
Dopo aver creato il server del modello, il servizio avviato può essere trovato nella sezione Cloud Run del tuo progetto GCP.
Seleziona il server di modelli che hai appena creato. Assicurati che il nome del servizio sia uguale a MODEL_SERVICE_NAME.
Puoi trovare l'URL del servizio facendo clic sul servizio di modello di cui hai appena eseguito il deployment.
Puoi controllare la sezione LOG per monitorare l'attività, visualizzare i messaggi di errore e monitorare l'avanzamento del deployment.
Puoi controllare la sezione METRICHE per visualizzare le metriche del servizio.
5-d: Carica modelli self-hosted
Se esegui il proxy del server LIT nel passaggio 3 (consulta la sezione Risoluzione dei problemi), devi ottenere il token di identità GCP eseguendo il seguente comando.
# Find your GCP identity token.
gcloud auth print-identity-token
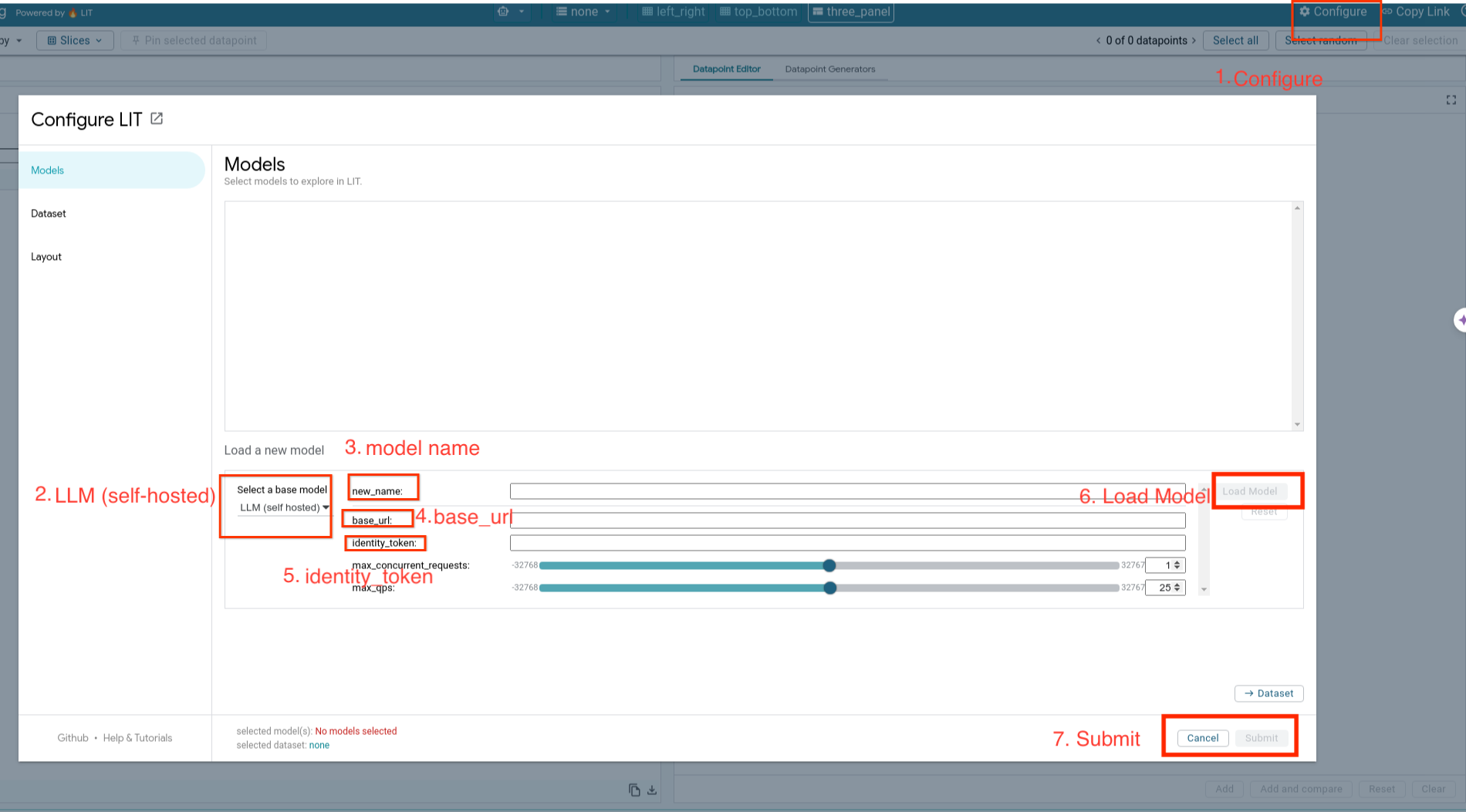
Caricherai i modelli self-hosted e ne regolerai i parametri seguendo i passaggi riportati di seguito.
- Fai clic sull'opzione
Configurenell'interfaccia utente di LIT. - Seleziona l'opzione
LLM (self hosted)nella sezioneSelect a base model. - Devi assegnare un nome al modello in
new_name. - Inserisci l'URL del server del modello come
base_url. - Inserisci il token di identità ottenuto in
identity_tokense esegui il proxy del server dell'app LIT (vedi passaggio 3 e passaggio 7). In caso contrario, lascia vuoto il campo. - Fai clic su
Load Model. - Fai clic su
Submit.
6. Interagire con LIT su GCP
LIT offre un ricco insieme di funzionalità per aiutarti a eseguire il debug e comprendere i comportamenti del modello. Puoi fare qualcosa di semplice come interrogare il modello digitando del testo in una casella e visualizzando le previsioni del modello oppure esaminare i modelli in modo approfondito con la suite di potenti funzionalità di LIT, tra cui:
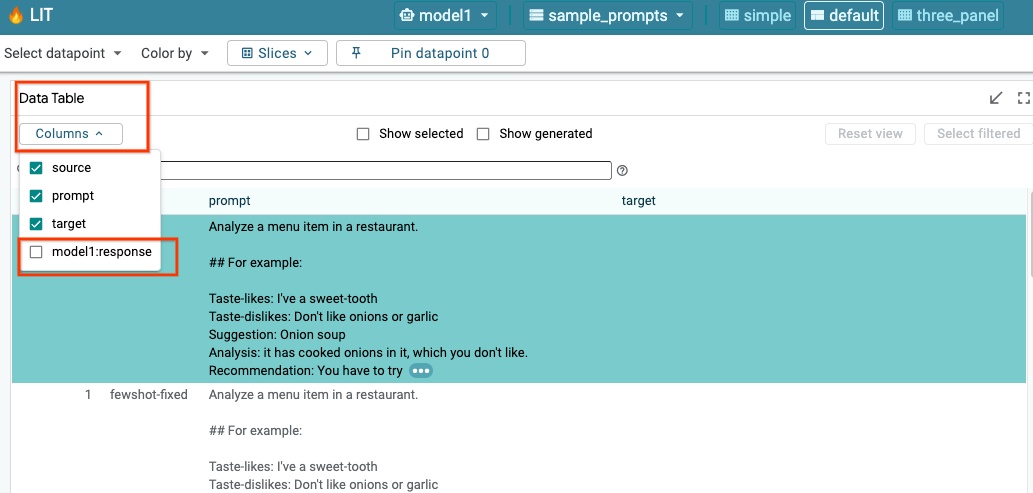
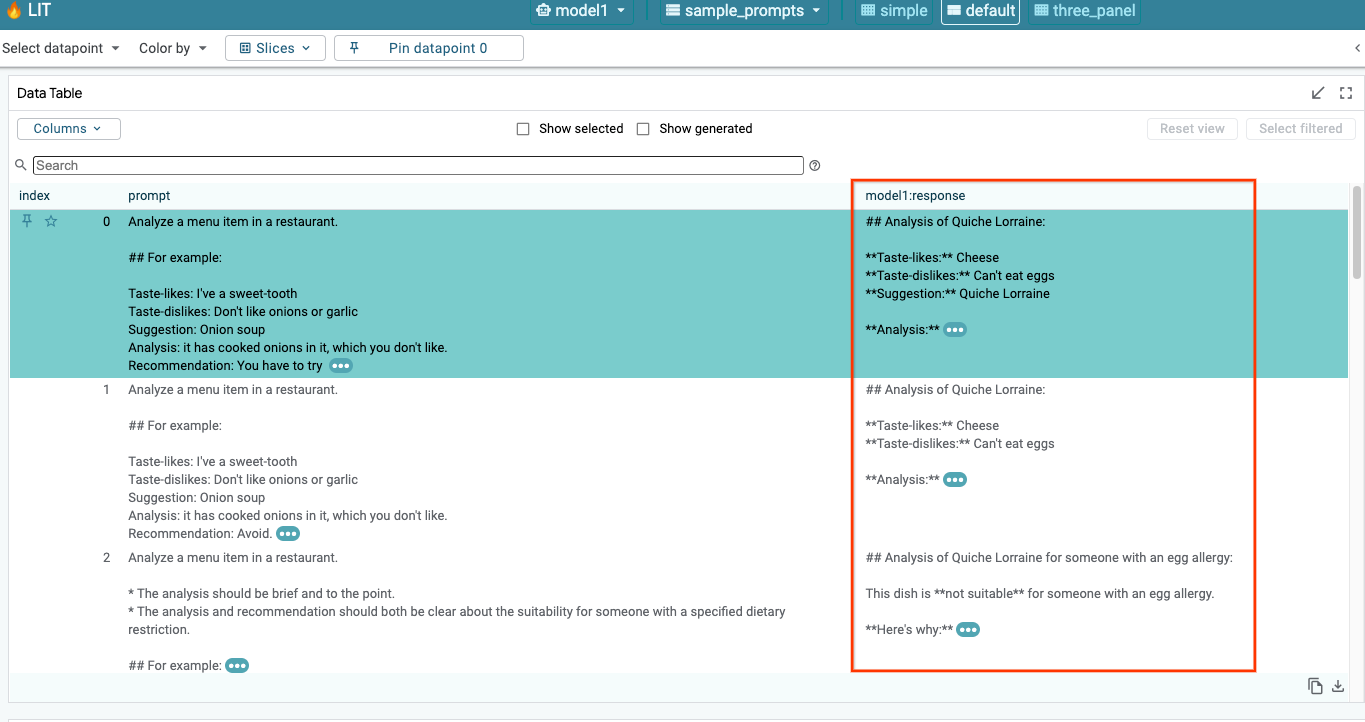
6a: Esegui query sul modello tramite LIT
LIT esegue automaticamente query sul set di dati dopo il caricamento del modello e del set di dati. Puoi visualizzare la risposta di ogni modello selezionandola nelle colonne.
6-b: Utilizzare la tecnica di salienza della sequenza
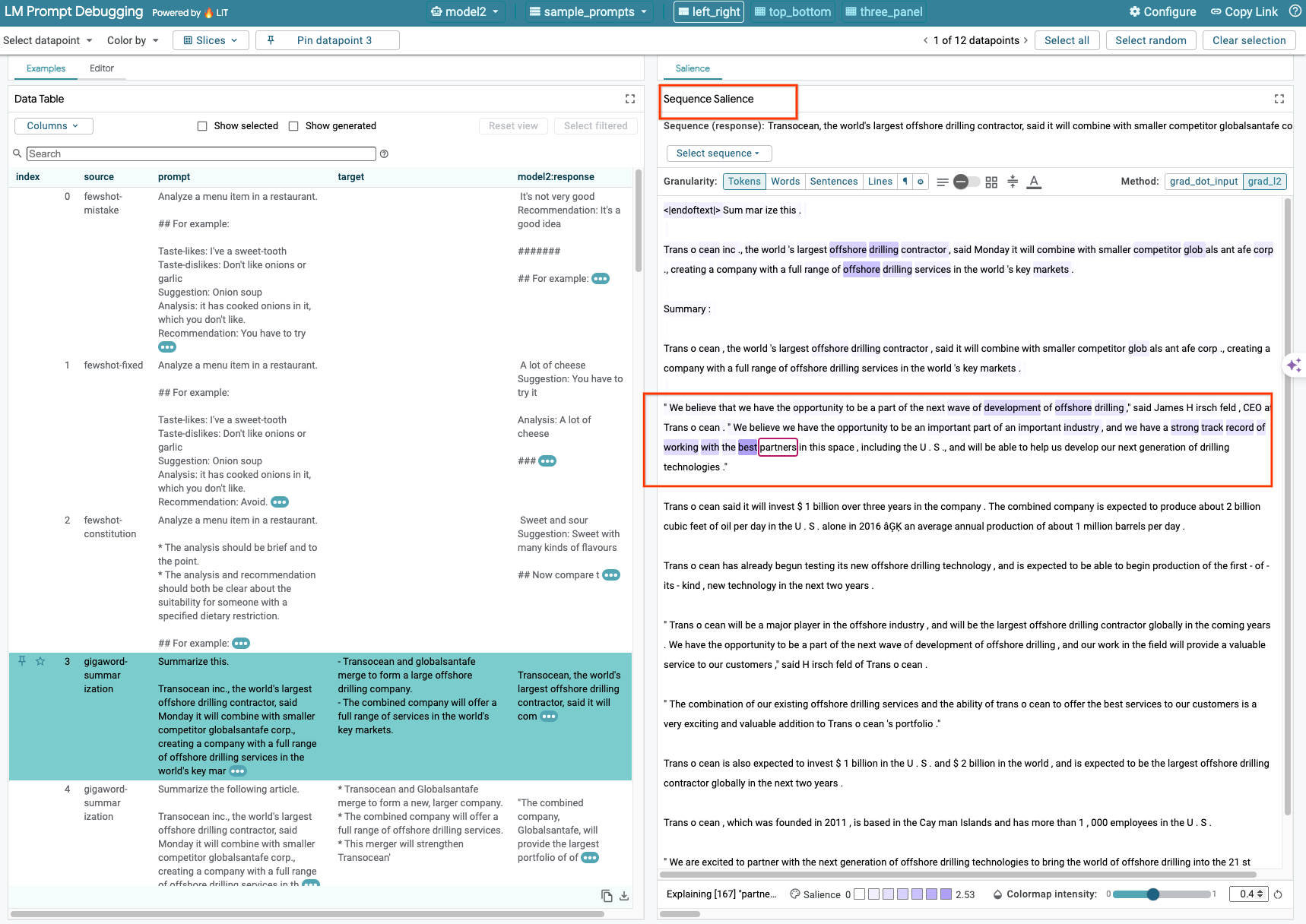
Al momento, la tecnica Sequence Salience su LIT supporta solo i modelli self-hosted.
Sequence Salience è uno strumento visivo che aiuta a eseguire il debug dei prompt LLM evidenziando le parti di un prompt più importanti per un determinato output. Per ulteriori informazioni su Sequence Salience, consulta il tutorial completo per scoprire di più su come utilizzare questa funzionalità.
Per accedere ai risultati di salienza, fai clic su qualsiasi input o output nel prompt o nella risposta e verranno visualizzati i risultati di salienza.
6-c: Modifica manualmente il prompt e il target
LIT ti consente di modificare manualmente qualsiasi prompt e target per il punto dati esistente. Se fai clic su Add, il nuovo input verrà aggiunto al set di dati.
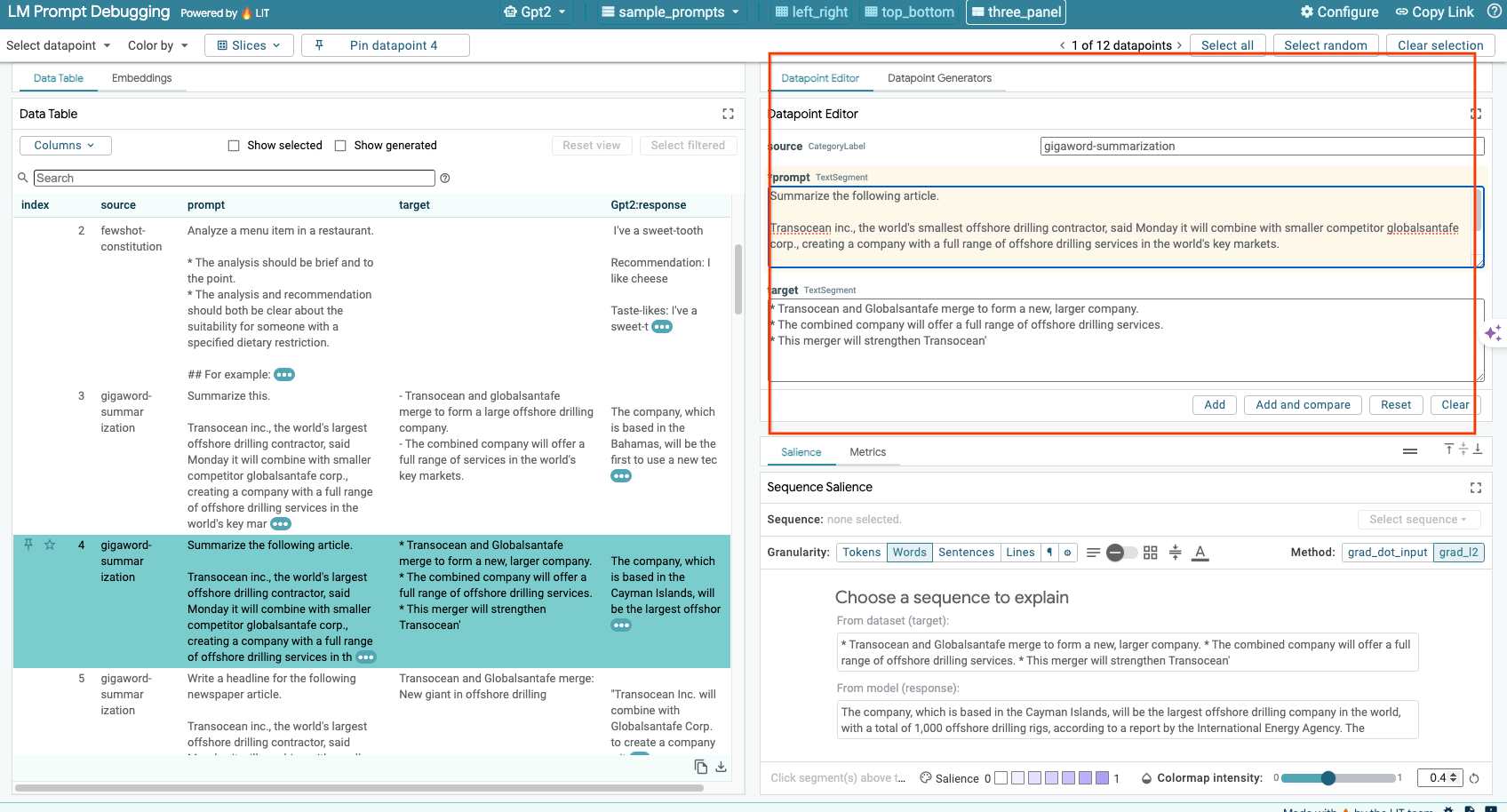
6-d: Confronta i prompt affiancati
LIT ti consente di confrontare i prompt affiancati negli esempi originali e modificati. Puoi modificare manualmente un esempio e visualizzare contemporaneamente il risultato della previsione e l'analisi della salienza della sequenza sia per la versione originale sia per quella modificata. Puoi modificare il prompt per ogni punto dati e LIT genererà la risposta corrispondente eseguendo una query sul modello.
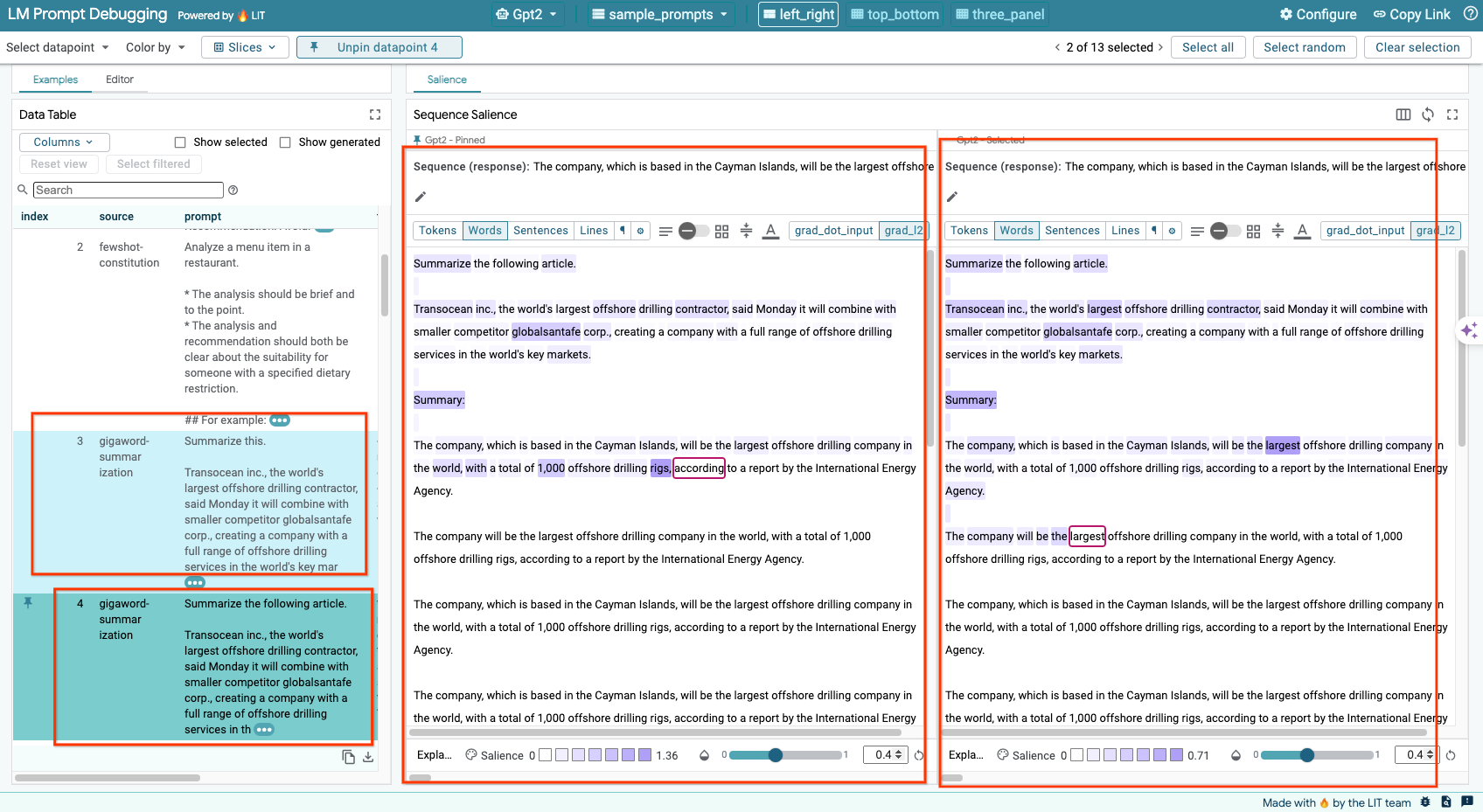
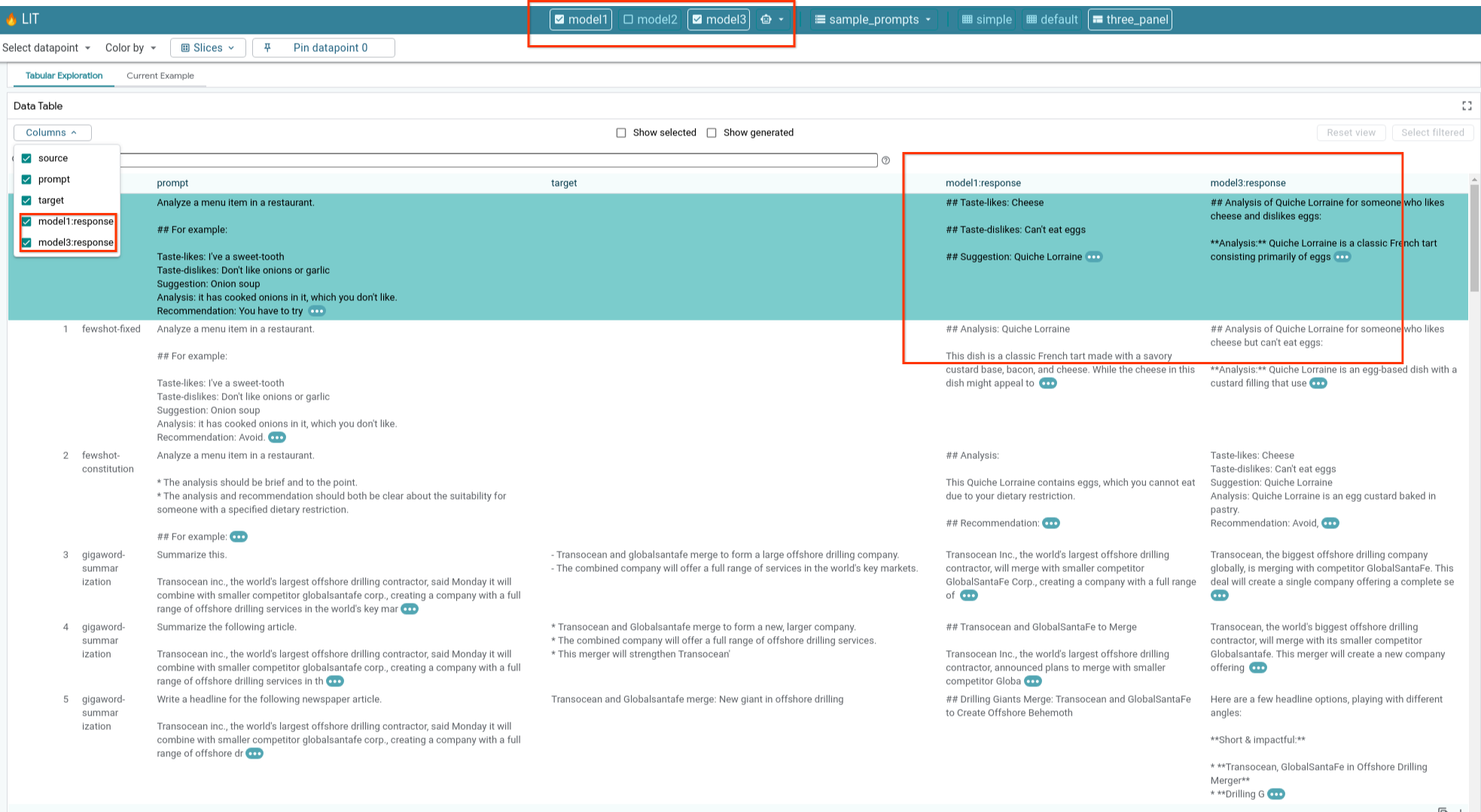
6-e: Confronta più modelli affiancati
LIT consente il confronto affiancato dei modelli su singoli esempi di generazione e assegnazione di punteggio del testo, nonché su esempi aggregati per metriche specifiche. Eseguendo query su vari modelli caricati, puoi confrontare facilmente le differenze nelle loro risposte.
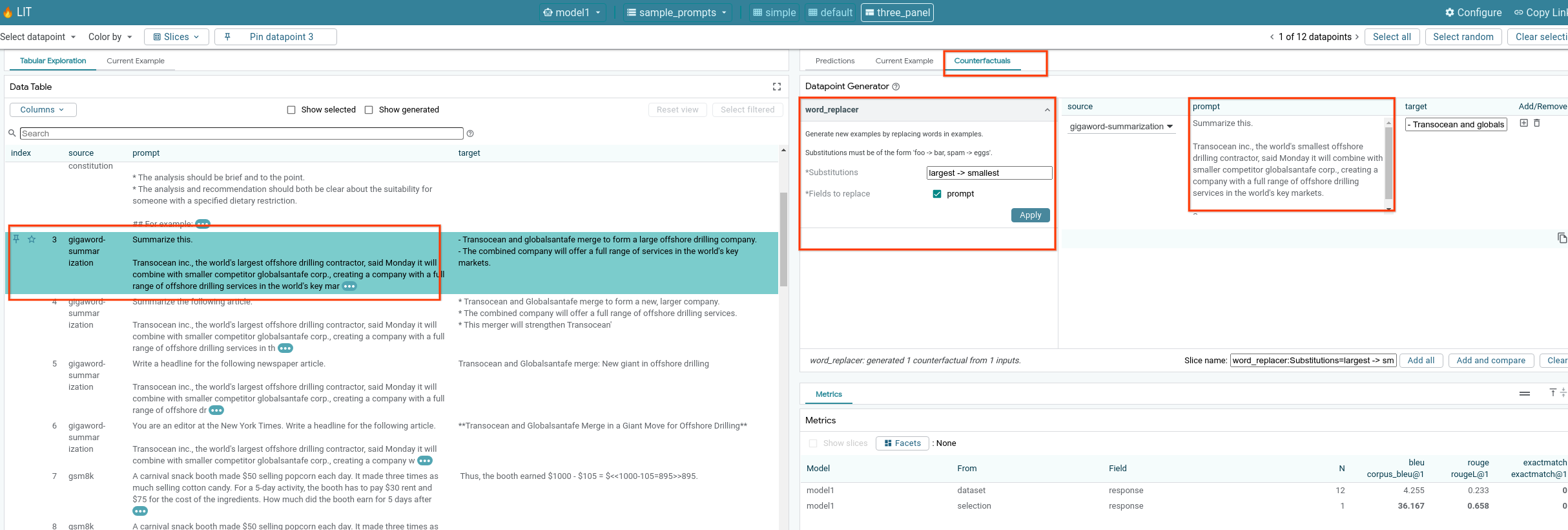
6-f: Automatic Counterfactual Generators
Puoi utilizzare generatori di scenari controfattuali automatici per creare input alternativi e vedere immediatamente il comportamento del modello.
6-g: Valuta le prestazioni del modello
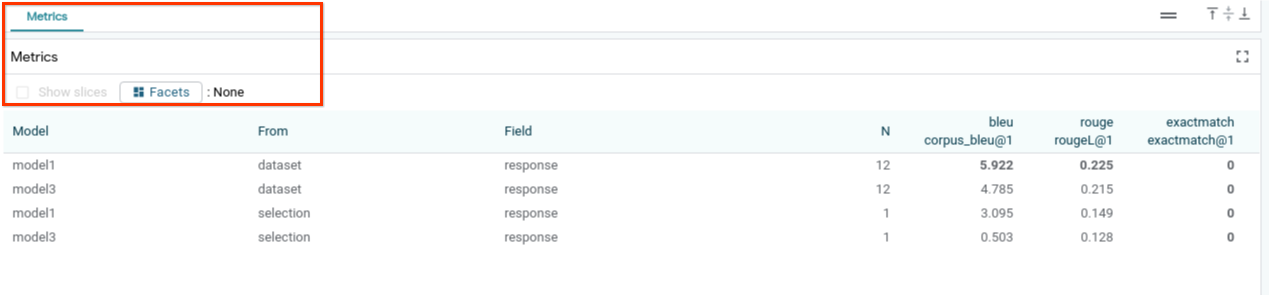
Puoi valutare il rendimento del modello utilizzando le metriche (attualmente supporta i punteggi BLEU e ROUGE per la generazione di testo) nell'intero set di dati o in qualsiasi sottoinsieme di esempi filtrati o selezionati.
7. Risoluzione dei problemi
7-a: Potenziali problemi di accesso e soluzioni
Poiché --no-allow-unauthenticated viene applicato durante il deployment in Cloud Run, potresti riscontrare errori di accesso negato come mostrato di seguito.

Esistono due approcci per accedere al servizio LIT App.
1. Proxy per il servizio locale
Puoi eseguire il proxy del servizio sull'host locale utilizzando il comando riportato di seguito.
# Proxy the service to local host.
gcloud run services proxy $LIT_SERVICE_NAME
Dovresti quindi essere in grado di accedere al server LIT facendo clic sul link del servizio proxy.
2. Autenticare direttamente gli utenti
Puoi seguire questo link per autenticare gli utenti, consentendo l'accesso diretto al servizio LIT App. Questo approccio può anche consentire a un gruppo di utenti di accedere al servizio. Per lo sviluppo che prevede la collaborazione con più persone, questa è un'opzione più efficace.
7-b: Controlli per assicurarsi che il server del modello sia stato avviato correttamente
Per assicurarti che il server del modello sia stato avviato correttamente, puoi eseguire una query direttamente sul server del modello inviando una richiesta. Il server del modello fornisce tre endpoint: predict, tokenize e salience. Assicurati di fornire sia il campo prompt sia i campi target nella richiesta.
# Query the model server predict endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/predict -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server tokenize endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/tokenize -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server salience endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/salience -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
Se riscontri un problema di accesso, consulta la sezione 7-a precedente.
8. Complimenti
Complimenti per aver completato il codelab. È ora di rilassarsi.
Esegui la pulizia
Per pulire il lab, elimina tutti i servizi Google Cloud creati per il lab. Utilizza Google Cloud Shell per eseguire i seguenti comandi.
Se la connessione Google Cloud viene persa a causa dell'inattività, reimposta le variabili seguendo i passaggi precedenti.
# Delete the LIT App Service.
gcloud run services delete $LIT_SERVICE_NAME
Se hai avviato il server del modello, devi eliminarlo.
# Delete the Model Service.
gcloud run services delete $MODEL_SERVICE_NAME
Further reading
Continua a scoprire le funzionalità dello strumento LIT con i materiali riportati di seguito:
- Gemma: Link
- Base di codice open source LIT: repository Git
- Documento LIT: ArXiv
- Documento sul debug dei prompt LIT: ArXiv
- Video dimostrativo della funzionalità LIT: YouTube
- Demo di debug del prompt LIT: YouTube
- Responsible GenAI Toolkit: link
Contatto
Per qualsiasi domanda o problema relativo a questo codelab, contattaci su GitHub.
Licenza
Questo lavoro è concesso in licenza ai sensi di una licenza Creative Commons Attribution 4.0 Generic.