
1. 總覽
本實驗室提供詳細逐步說明,引導您在 Google Cloud Platform (GCP) 上部署 LIT 應用程式伺服器,與 Vertex AI Gemini 基礎模型和自行代管的第三方大型語言模型 (LLM) 互動。此外,也提供如何使用 LIT UI 進行提示偵錯和模型解讀的指南。
完成本實驗室後,使用者將瞭解如何:
- 在 GCP 上設定 LIT 伺服器。
- 將 LIT 伺服器連線至 Vertex AI Gemini 模型或其他自行代管的 LLM。
- 使用 LIT UI 分析、偵錯及解讀提示,進一步提升模型效能並取得洞察資料。
什麼是 LIT?
LIT 是一項視覺化互動式模型解讀工具,支援文字、圖片和表格資料。您可以將其做為獨立伺服器執行,也可以在 Google Colab、Jupyter 和 Google Cloud Vertex AI 等筆記本環境中執行。LIT 可從 PyPI 和 GitHub 取得。
這個工具最初是為了瞭解分類和迴歸模型而建構,但最近的更新新增了偵錯 LLM 提示的工具,可供您探索使用者、模型和系統內容如何影響生成行為。
什麼是 Vertex AI 和 Model Garden?
Vertex AI 是機器學習 (ML) 平台,可讓您訓練及部署 ML 模型和 AI 應用程式,並自訂 LLM 用於 AI 輔助的應用程式。Vertex AI 結合資料工程、數據資料學和機器學習工程的工作流程。不同的團隊將能運用相同的工具協同合作,並透過 Google Cloud 的強大功能調度應用程式資源。
Vertex Model Garden 是機器學習模型庫,可協助您探索、測試、自訂及部署 Google 專屬模型,以及選取的第三方模型和資產。
課程內容
您將使用 Google Cloud Shell 和 Cloud Run,從 LIT 的預先建構映像檔部署 Docker 容器。
Cloud Run 是代管運算平台,能讓您在 Google 可擴充的基礎架構上直接執行容器,包括 GPU。
資料集
根據預設,這個示範會使用 LIT 提示偵錯範例資料集,您也可以透過使用者介面載入自己的資料集。
事前準備
如要使用本參考指南,您需要 Google Cloud 專案。您可以建立新專案,或選取已建立的專案。
2. 啟動 Google Cloud 控制台和 Cloud Shell
您將在這個步驟啟動 Google Cloud 控制台,並使用 Google Cloud Shell。
2-a:啟動 Google Cloud 控制台
啟動瀏覽器並前往 Google Cloud 控制台。
Google Cloud 控制台是功能強大又安全的網頁管理介面,可讓您快速管理 Google Cloud 資源。隨時隨地處理開發運作工作。
2-b:啟動 Google Cloud Shell
Cloud Shell 是一套線上開發與作業環境,可透過瀏覽器隨時隨地存取。Cloud Shell 的線上終端機已預先載入 kubectl、gcloud 指令列工具等公用程式,方便您管理資源。您也可以使用線上 Cloud Shell 編輯器開發、建構及部署雲端式應用程式,並為應用程式進行偵錯。Cloud Shell 提供線上環境,已預先安裝開發人員常用的工具組合,並提供 5 GB 的永久儲存空間。您將在後續步驟中使用命令提示字元。
使用選單列右上角的圖示啟動 Google Cloud Shell,如下列螢幕截圖中以藍色圓圈標示的位置所示。

頁面底部應該會顯示含有 Bash 殼層的終端機。

2-c:設定 Google Cloud 專案
您必須使用 gcloud 指令設定專案 ID 和專案區域。
# Set your GCP Project ID.
gcloud config set project your-project-id
# Set your GCP Project Region.
gcloud config set run/region your-project-region
3. 使用 Cloud Run 部署 LIT 應用程式伺服器 Docker 映像檔
3-a:將 LIT 應用程式部署至 Cloud Run
首先,您需要將最新版 LIT-App 設為要部署的版本。
# Set latest version as your LIT_SERVICE_TAG.
export LIT_SERVICE_TAG=latest
# List all the public LIT GCP App server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app
設定版本標記後,您需要為服務命名。
# Set your lit service name. While 'lit-app-service' is provided as a placeholder, you can customize the service name based on your preferences.
export LIT_SERVICE_NAME=lit-app-service
完成後,您可以執行下列指令,將容器部署至 Cloud Run。
# Use below cmd to deploy the LIT App to Cloud Run.
gcloud run deploy $LIT_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app:$LIT_SERVICE_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--no-allow-unauthenticated
LIT 也允許您在啟動伺服器時新增資料集。如要這麼做,請使用 name:path 格式,將 DATASETS 變數設為包含要載入的資料,例如 data_foo:/bar/data_2024.jsonl。資料集格式應為 .jsonl,每筆記錄都包含 prompt,以及選用的 target 和 source 欄位。如要載入多個資料集,請以半形逗號分隔。如未設定,系統會載入 LIT 提示偵錯範例資料集。
# Set the dataset.
export DATASETS=[DATASETS]
設定 MAX_EXAMPLES 即可指定從每個評估集載入的範例數量上限。
# Set the max examples.
export MAX_EXAMPLES=[MAX_EXAMPLES]
然後,在部署指令中,您可以新增
--set-env-vars "DATASETS=$DATASETS" \
--set-env-vars "MAX_EXAMPLES=$MAX_EXAMPLES" \
3-b:查看 LIT 應用程式服務
建立 LIT 應用程式伺服器後,您可以在 Cloud Console 的「Cloud Run」部分找到該服務。
選取您剛建立的 LIT 應用程式服務。確認服務名稱與 LIT_SERVICE_NAME 相同。

按一下剛部署的服務,即可找到服務網址。
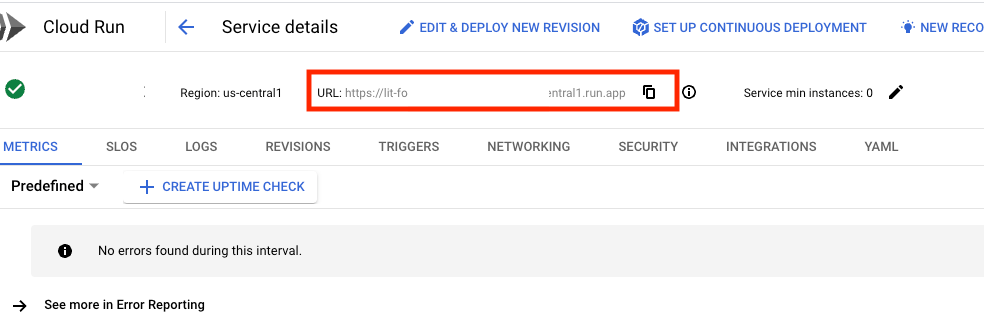
接著,您應該就能查看 LIT UI。如果發生錯誤,請參閱「疑難排解」一節。
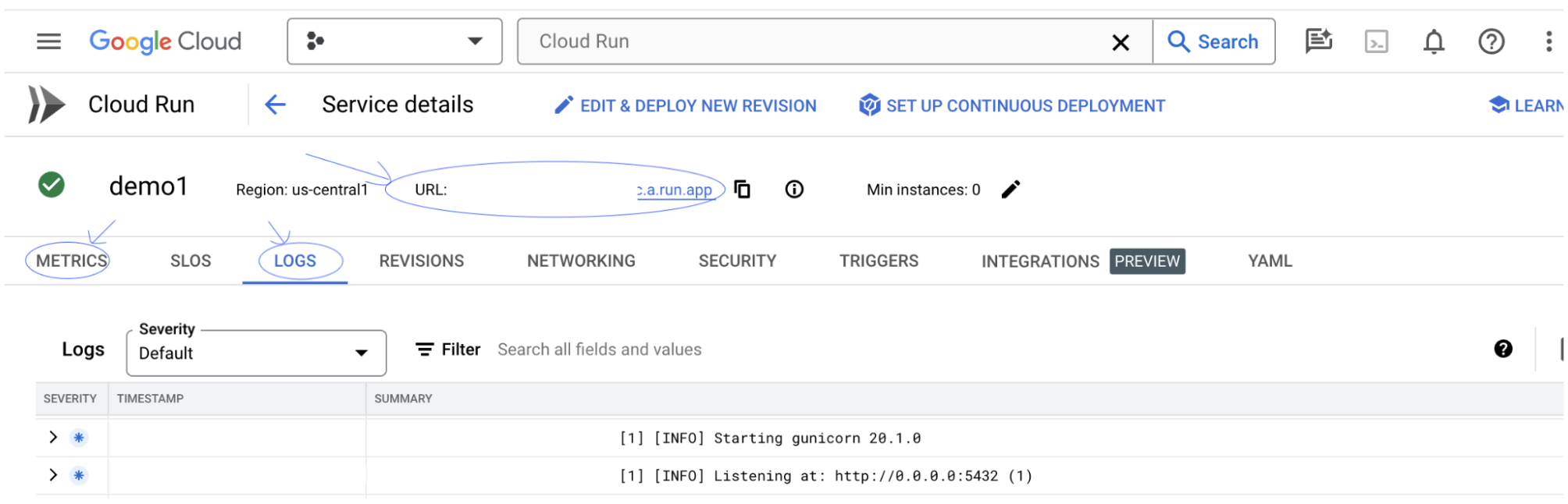
您可以查看「記錄」部分,監控活動、查看錯誤訊息,以及追蹤部署進度。
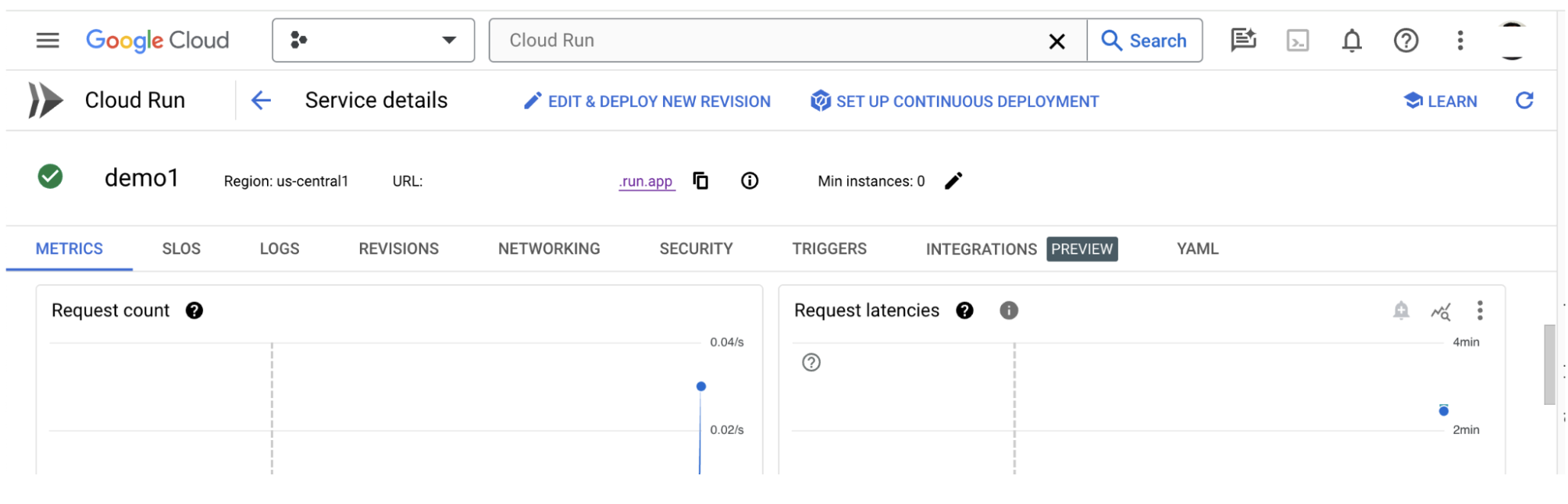
您可以查看「指標」部分,瞭解服務的指標。
3-c:載入資料集
在 LIT UI 中按一下 Configure 選項,然後選取 Dataset。指定名稱並提供資料集網址,即可載入資料集。資料集格式應為 .jsonl,每筆記錄都包含 prompt,以及選用的 target 和 source 欄位。

4. 在 Vertex AI Model Garden 中準備 Gemini 模型
Google 的 Gemini 基礎模型可透過 Vertex AI API 存取。LIT 提供 VertexAIModelGarden 模型包裝函式,可使用這些模型生成內容。只要透過模型名稱參數指定所需版本 (例如「gemini-1.5-pro-001」),使用這些模型的主要優點是不需要額外部署。根據預設,您可以在 GCP 上立即存取 Gemini 1.0 Pro 和 Gemini 1.5 Pro 等模型,不必執行額外的設定步驟。
4-a:授予 Vertex AI 權限
如要在 GCP 中查詢 Gemini,您必須將 Vertex AI 權限授予服務帳戶。請確認服務帳戶名稱為 Default compute service account。複製帳戶的服務帳戶電子郵件地址。
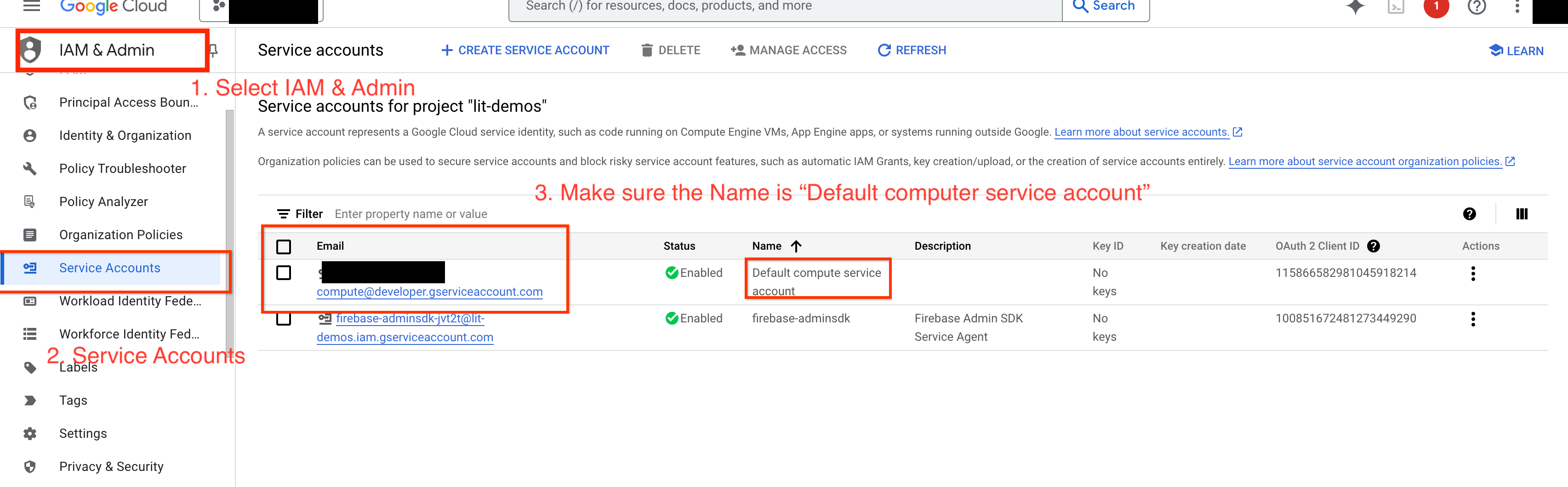
在 IAM 允許清單中,將服務帳戶電子郵件地址新增為具有 Vertex AI User 角色的主體。

4-b:載入 Gemini 模型
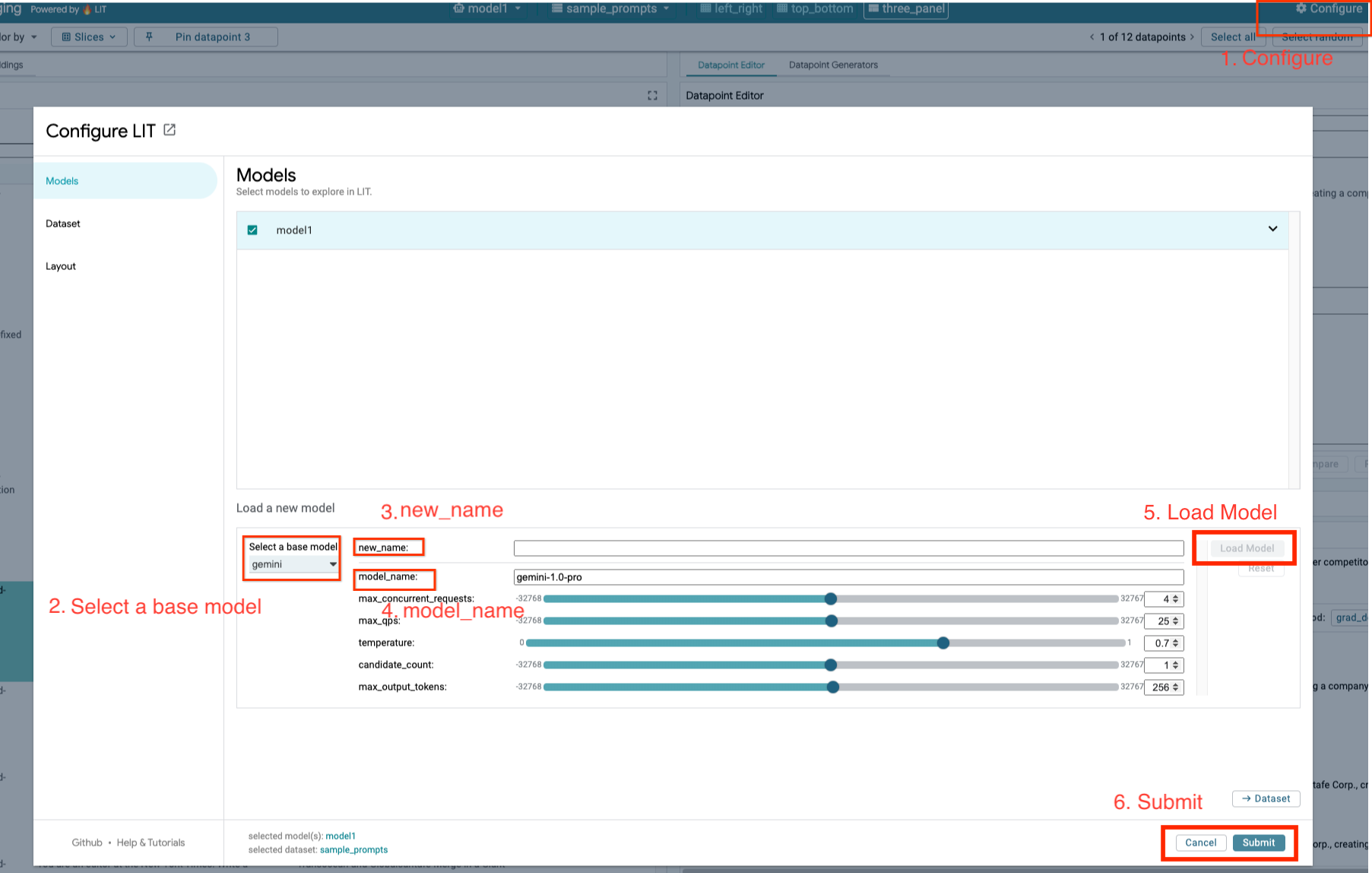
您將按照下列步驟載入 Gemini 模型並調整其參數。
- 按一下 LIT UI 中的
Configure選項。
- 按一下 LIT UI 中的
- 選取「
Select a base model」選項下方的「gemini」選項。
- 選取「
- 您需要在
new_name中為模型命名。
- 您需要在
- 輸入所選的 Gemini 模型做為
model_name。
- 輸入所選的 Gemini 模型做為
- 按一下「
Load Model」。
- 按一下「
- 按一下「
Submit」。
- 按一下「
5. 在 GCP 上部署自架 LLM 模型伺服器
使用 LIT 的模型伺服器 Docker 映像檔自行代管 LLM,即可使用 LIT 的顯著性和權杖化函式,深入瞭解模型行為。模型伺服器映像檔可搭配 KerasNLP 或 Hugging Face Transformers 模型使用,包括程式庫提供的權重和自行代管的權重 (例如 Google Cloud Storage 上的權重)。
5-a:設定模型
每個容器都會載入一個模型,並使用環境變數進行設定。
您應設定 MODEL_CONFIG,指定要載入的模型。格式應為 name:path,例如 model_foo:model_foo_path。路徑可以是網址、本機檔案路徑,或是已設定的深度學習架構預設集名稱 (詳情請參閱下表)。這個伺服器已在所有支援的 DL_FRAMEWORK 值上,使用 Gemma、GPT2、Llama 和 Mistral 進行測試。其他機型應該也能使用,但可能需要調整。
# Set models you want to load. While 'gemma2b is given as a placeholder, you can load your preferred model by following the instructions above.
export MODEL_CONFIG=gemma2b:gemma_2b_en
此外,LIT 模型伺服器可讓您使用下列指令設定各種環境變數。詳情請參閱表格。請注意,每個變數都必須個別設定。
# Customize the variable value as needed.
export [VARIABLE]=[VALUE]
變數 | 值 | 說明 |
DL_FRAMEWORK |
| 用於將模型權重載入指定執行階段的建模程式庫。預設值為 |
DL_RUNTIME |
| 模型執行的深度學習後端架構。這個伺服器載入的所有模型都會使用相同的後端,不相容會導致錯誤。預設值為 |
精確度 |
| LLM 模型的浮點精確度。預設值為 |
BATCH_SIZE | 正整數 | 每個批次要處理的範例數。預設值為 |
SEQUENCE_LENGTH | 正整數 | 輸入提示和生成文字的序列長度上限。預設值為 |
5-b:將模型伺服器部署至 Cloud Run
您必須先將最新版模型伺服器設為要部署的版本。
# Set latest as MODEL_VERSION_TAG.
export MODEL_VERSION_TAG=latest
# List all the public LIT GCP model server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server
設定版本標記後,您需要為模型伺服器命名。
# Set your Service name.
export MODEL_SERVICE_NAME='gemma2b-model-server'
完成後,您可以執行下列指令,將容器部署至 Cloud Run。如未設定環境變數,系統會套用預設值。由於大多數 LLM 都需要昂貴的運算資源,因此強烈建議使用 GPU。如果您偏好只在 CPU 上執行 (這適用於 GPT2 等小型模型),可以移除相關引數 --gpu 1 --gpu-type nvidia-l4 --max-instances 7。
# Deploy the model service container.
gcloud beta run deploy $MODEL_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server:$MODEL_VERSION_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 7 \
--set-env-vars "MODEL_CONFIG=$MODEL_CONFIG" \
--no-allow-unauthenticated
此外,您也可以新增下列指令,自訂環境變數。只納入特定需求所需的環境變數。
--set-env-vars "DL_FRAMEWORK=$DL_FRAMEWORK" \
--set-env-vars "DL_RUNTIME=$DL_RUNTIME" \
--set-env-vars "PRECISION=$PRECISION" \
--set-env-vars "BATCH_SIZE=$BATCH_SIZE" \
--set-env-vars "SEQUENCE_LENGTH=$SEQUENCE_LENGTH" \
如要存取特定模型,可能需要額外環境變數。請參閱 Kaggle Hub (用於 KerasNLP 模型) 和 Hugging Face Hub 的操作說明。
5-c:存取模型伺服器
建立模型伺服器後,您可以在 GCP 專案的「Cloud Run」部分找到已啟動的服務。
選取剛建立好的模型伺服器。確認服務名稱與 MODEL_SERVICE_NAME 相同。
點選您剛部署的模型服務,即可找到服務網址。
您可以查看「記錄」部分,監控活動、查看錯誤訊息,以及追蹤部署進度。
您可以查看「指標」部分,瞭解服務的指標。
5-d:載入自行託管的模型
如果您在步驟 3 中將 LIT 伺服器設為 Proxy (請參閱「疑難排解」一節),則需要執行下列指令來取得 GCP 身分識別權杖。
# Find your GCP identity token.
gcloud auth print-identity-token
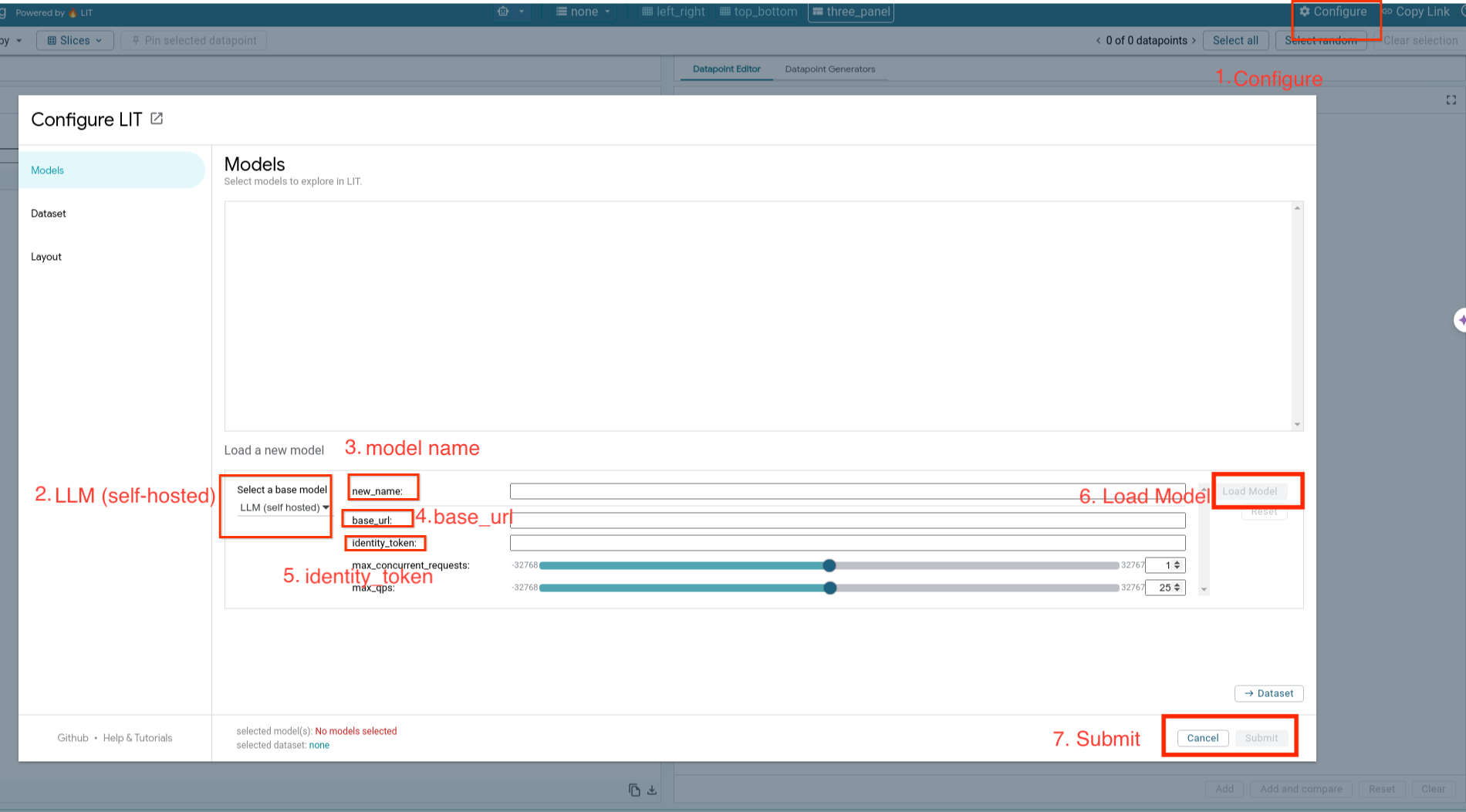
您將載入自行代管的模型,並按照下列步驟調整模型參數。
- 按一下 LIT UI 中的
Configure選項。 - 選取「
Select a base model」選項下方的「LLM (self hosted)」選項。 - 您需要在
new_name中為模型命名。 - 輸入模型伺服器網址做為
base_url。 - 如果您是透過 LIT 應用程式伺服器 (請參閱步驟 3 和步驟 7) 進行 Proxy,請在
identity_token中輸入取得的 ID 權杖。否則請將這個欄位留空。 - 按一下「
Load Model」。 - 按一下「
Submit」。
6. 在 GCP 上與 LIT 互動
LIT 提供豐富的功能,可協助您偵錯及瞭解模型行為。您可以簡單地查詢模型,只要在方塊中輸入文字並查看模型預測即可,也可以使用 LIT 的強大功能套件深入檢查模型,包括:
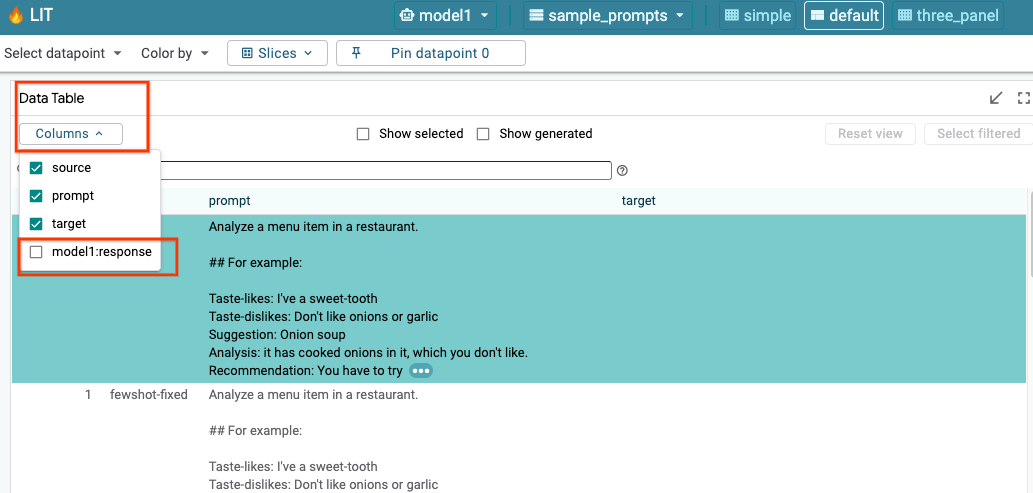
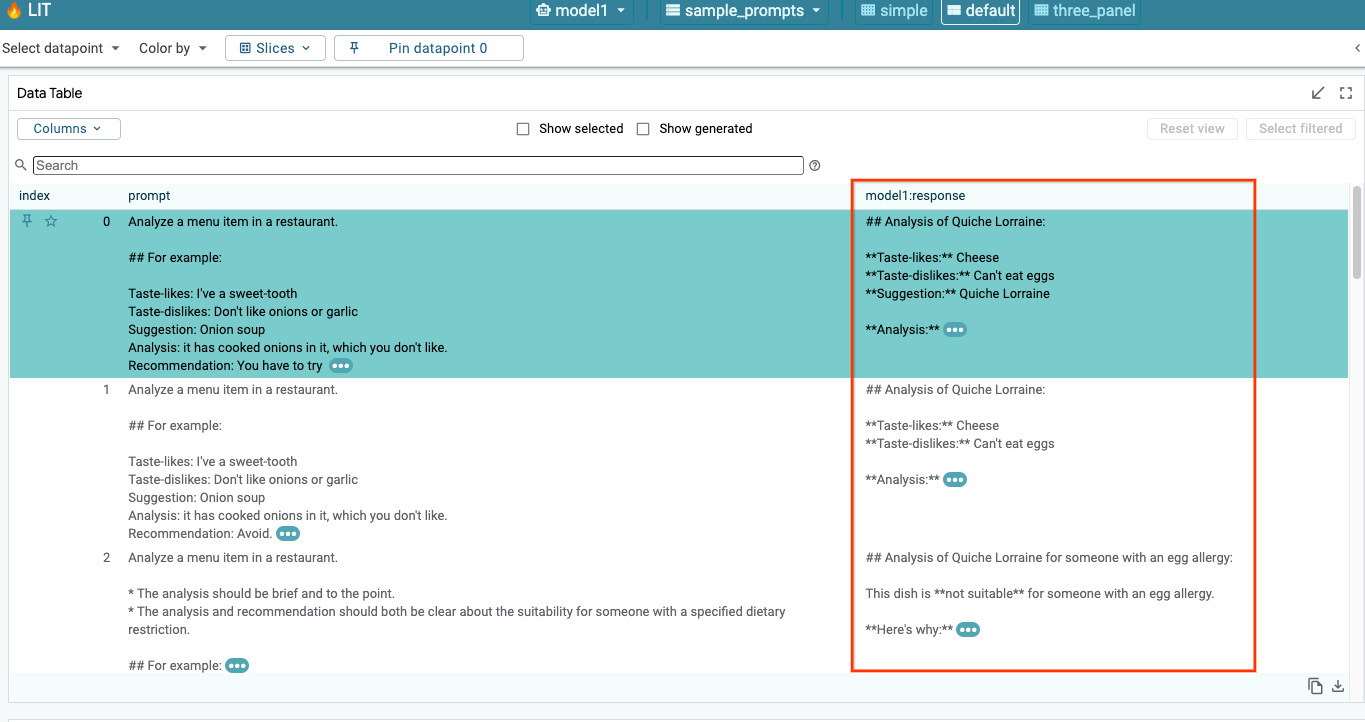
6-a:透過 LIT 查詢模型
載入模型和資料集後,LIT 會自動查詢資料集。如要查看各模型的回答,請選取資料欄中的回答。
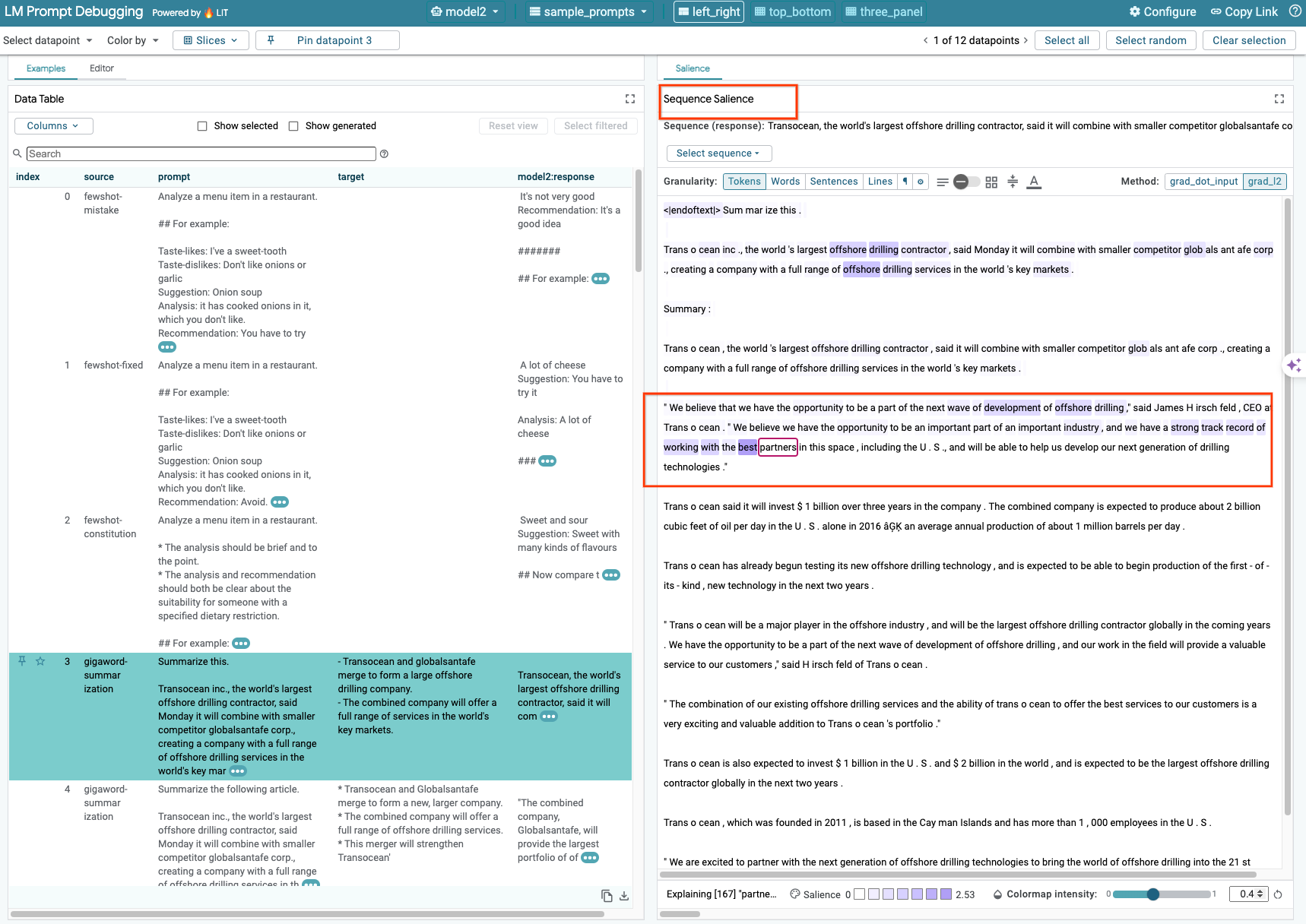
6-b:使用序列顯著性技術
目前 LIT 的序列顯著性技術僅支援自行代管的模型。
序列顯著性是一項視覺化工具,可醒目顯示提示中對特定輸出內容最重要的部分,協助偵錯 LLM 提示。如要進一步瞭解序列顯著性,請參閱完整教學課程,進一步瞭解如何使用這項功能。
如要查看顯著性結果,請按一下提示或回覆中的任何輸入或輸出內容,系統就會顯示顯著性結果。
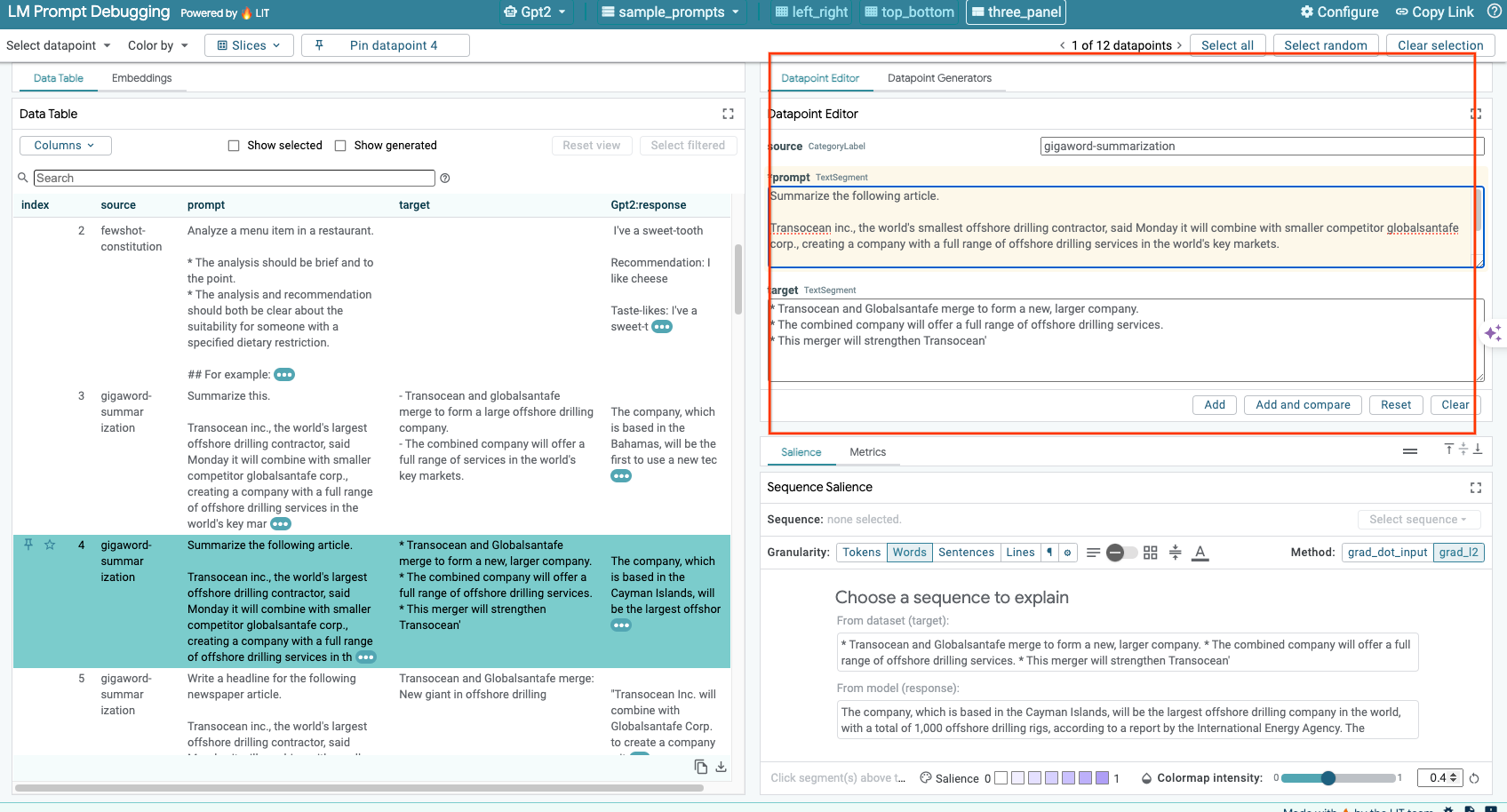
6-c:手動編輯提示和目標
LIT 可讓您手動編輯現有資料點的任何 prompt 和 target。按一下 Add,即可將新輸入內容新增至資料集。
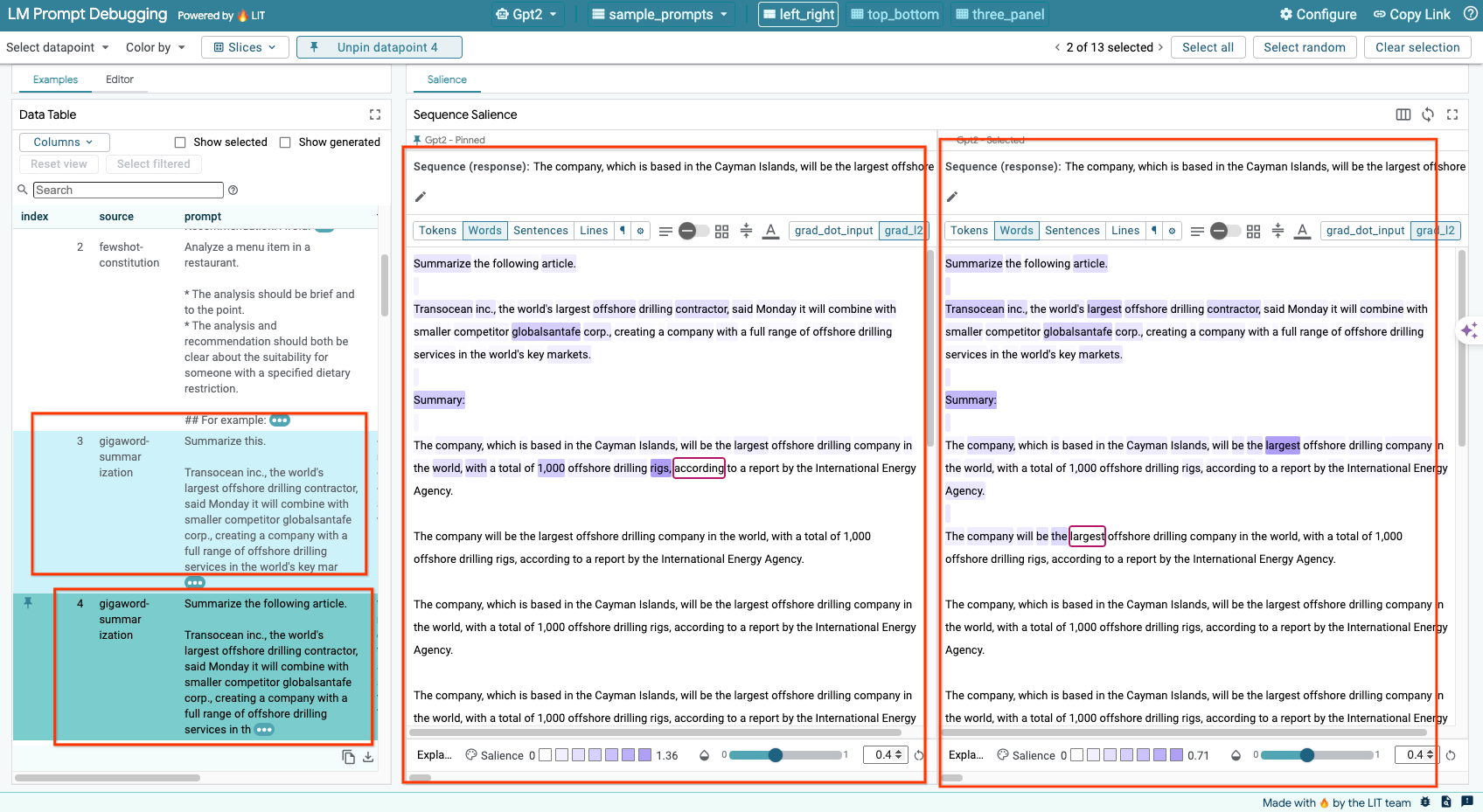
6-d:並排比較提示
LIT 可讓您並排比較原始和編輯過的範例提示。您可以手動編輯範例,並同時查看原始和編輯版本的預測結果和序列顯著性分析。您可以修改每個資料點的提示,LIT 會查詢模型並產生相應的回覆。
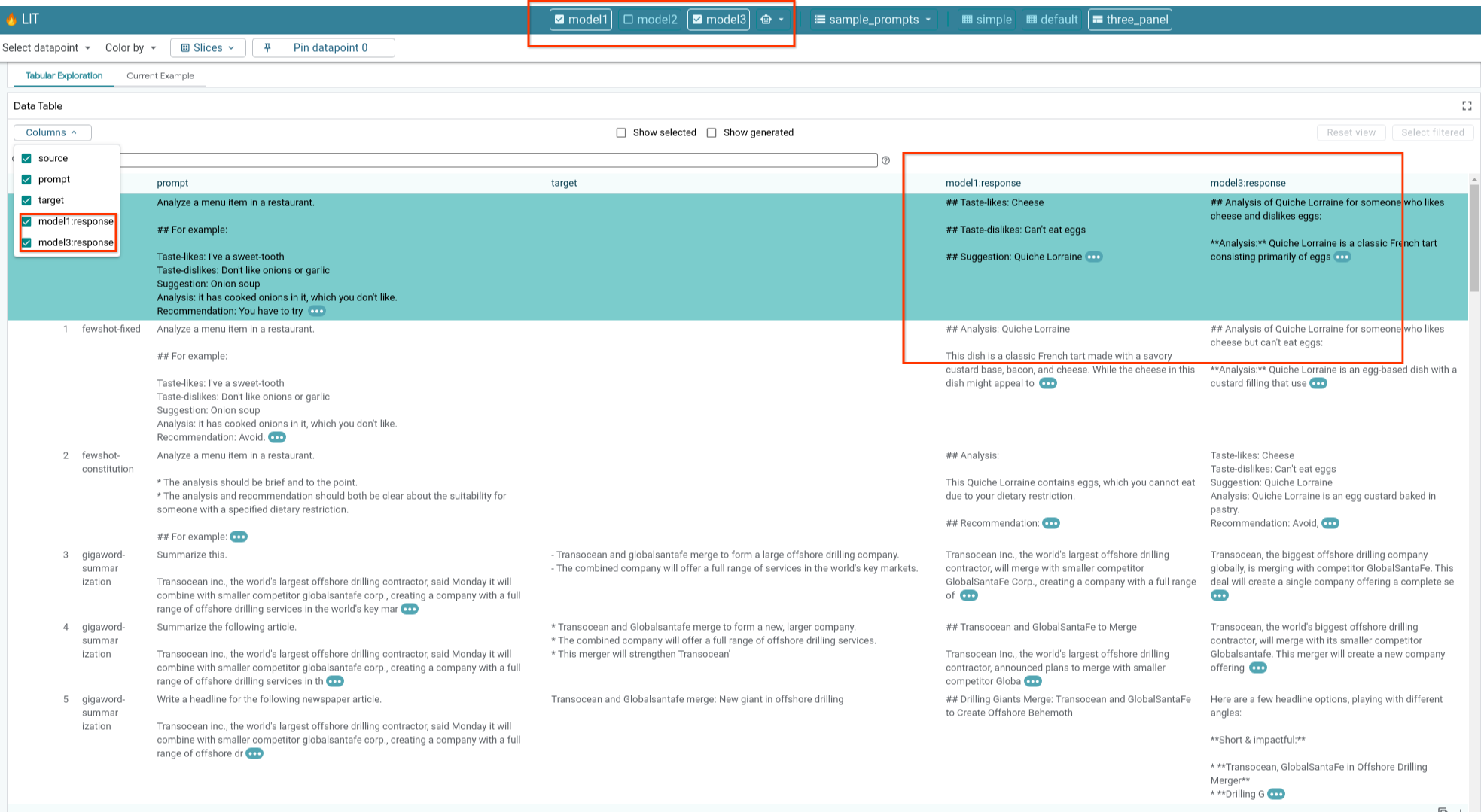
6-e:並列比較多個模型
LIT 可讓您並排比較模型在個別文字生成和評分範例,以及特定指標匯總範例中的表現。查詢各種已載入的模型,即可輕鬆比較回覆內容的差異。
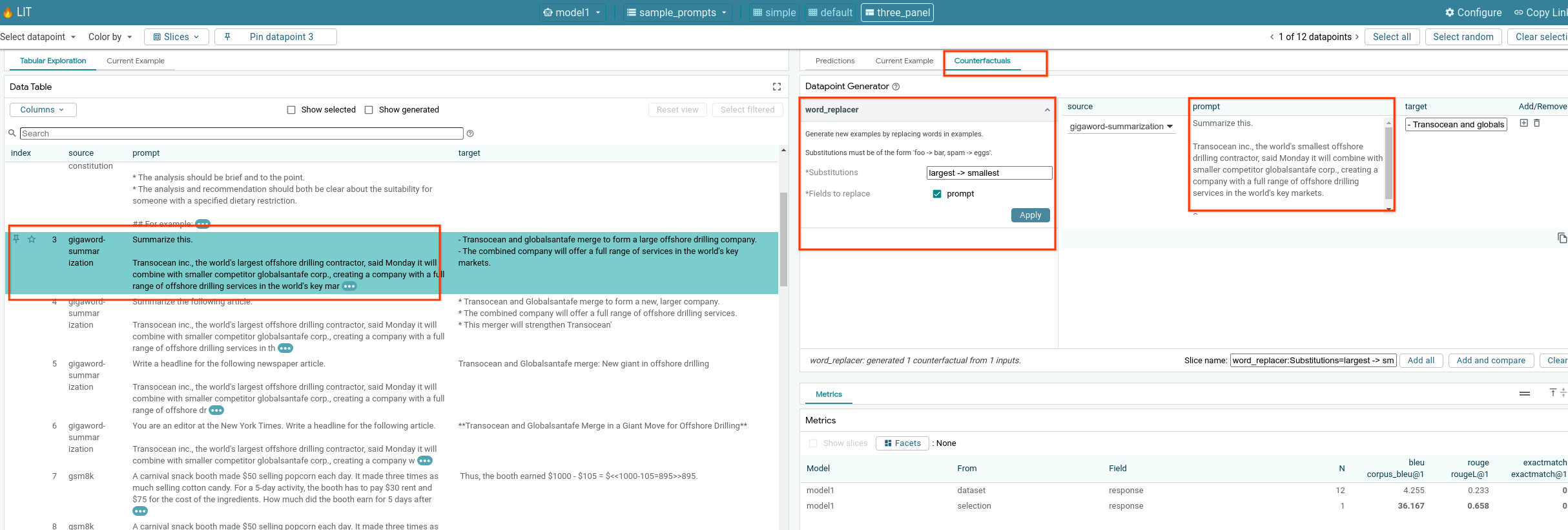
6-f:自動反事實生成器
您可以使用自動反事實生成器建立替代輸入內容,並立即查看模型在這些內容上的行為。
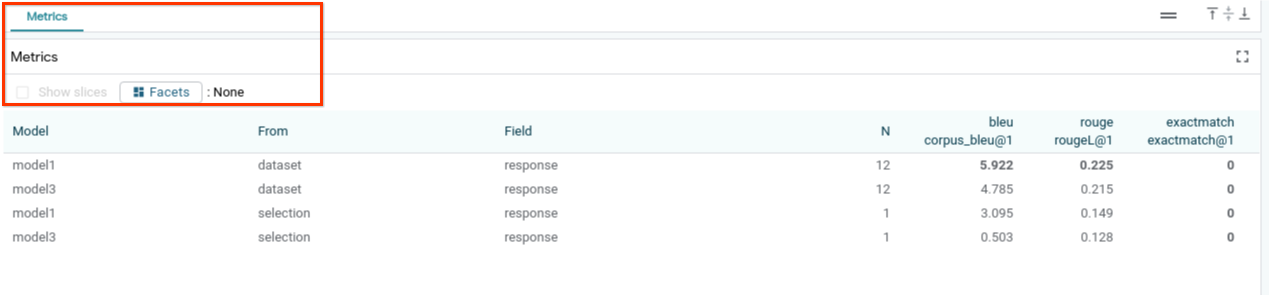
6-g:評估模型效能
您可以透過指標 (目前支援文字生成的 BLEU 和 ROUGE 分數) 評估整個資料集或任何經過篩選或選取的範例子集的模型成效。
7. 疑難排解
7-a:潛在存取權問題和解決方案
由於部署至 Cloud Run 時會套用 --no-allow-unauthenticated,您可能會遇到下列禁止錯誤。

存取 LIT 應用程式服務的方法有兩種。
1. Proxy 至本機服務
您可以使用下列指令,將服務 Proxy 至本機主機。
# Proxy the service to local host.
gcloud run services proxy $LIT_SERVICE_NAME
接著點選已透過 Proxy 服務連結的服務,即可存取 LIT 伺服器。
2. 直接驗證使用者
您可以按照這個連結驗證使用者身分,允許直接存取 LIT 應用程式服務。這種做法也能讓使用者群組存取服務。如果開發作業需要多人協作,這個選項會更有效率。
7-b:檢查以確保模型伺服器已順利啟動
如要確保模型伺服器已順利啟動,您可以傳送要求,直接查詢模型伺服器。模型伺服器提供三個端點:predict、tokenize 和 salience。請務必在要求中提供 prompt 欄位和 target 欄位。
# Query the model server predict endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/predict -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server tokenize endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/tokenize -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server salience endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/salience -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
如果遇到存取問題,請參閱上方的 7-a 節。
8. 恭喜
恭喜您完成本程式碼研究室!放鬆一下!
清除所用資源
如要清除實驗室,請刪除為實驗室建立的所有 Google Cloud 服務。使用 Google Cloud Shell 執行下列指令。
如果 Google Cloud 連線因閒置而中斷,請按照先前的步驟重設變數。
# Delete the LIT App Service.
gcloud run services delete $LIT_SERVICE_NAME
如果您啟動了模型伺服器,也需要刪除模型伺服器。
# Delete the Model Service.
gcloud run services delete $MODEL_SERVICE_NAME
其他資訊
如要繼續瞭解 LIT 工具功能,請參閱下列資料:
- Gemma:連結
- LIT 開放原始碼庫:Git 存放區
- LIT 論文:ArXiv
- LIT 提示偵錯論文:ArXiv
- LIT 功能影片示範:YouTube
- LIT 提示詞偵錯示範:YouTube
- 負責任的生成式 AI 工具包:連結
聯絡人
如果對本程式碼研究室有任何疑問或問題,請透過 GitHub 與我們聯絡。
授權
這項內容採用的授權為 Creative Commons 姓名標示 4.0 通用授權。