
1. Visão geral
Este laboratório oferece um tutorial detalhado sobre como implantar um servidor de aplicativos LIT no Google Cloud Platform (GCP) para interagir com os modelos de fundação do Gemini da Vertex AI e modelos de linguagem grandes (LLMs) de terceiros auto-hospedados. Ela também inclui orientações sobre como usar a interface da LIT para depuração de comandos e interpretação de modelos.
Ao seguir este laboratório, os usuários vão aprender a:
- Configure um servidor LIT no GCP.
- Conecte o servidor LIT aos modelos Gemini da Vertex AI ou a outros LLMs autohospedados.
- Use a interface do LIT para analisar, depurar e interpretar comandos e melhorar a performance e os insights do modelo.
O que é LIT?
A LIT é uma ferramenta visual e interativa de compreensão de modelos que oferece suporte a textos, imagens e dados tabulares. Ela pode ser executada como um servidor independente ou em ambientes de notebook, como Google Colab, Jupyter e Google Cloud Vertex AI. O LIT está disponível no PyPI e no GitHub.
Originalmente criado para entender modelos de classificação e regressão, as atualizações recentes adicionaram ferramentas para depurar comandos de LLM, permitindo que você saiba como o conteúdo do usuário, do modelo e do sistema influencia o comportamento de geração.
O que são a Vertex AI e o Model Garden?
A Vertex AI é uma plataforma de machine learning (ML) que permite treinar e implantar modelos de ML e aplicativos de IA, além de personalizar LLMs para uso em aplicativos com tecnologia de IA. A Vertex AI combina fluxos de trabalho de engenharia de dados, ciência de dados e engenharia de ML para permitir que suas equipes colaborem usando um conjunto de ferramentas comum e escalonem seus aplicativos aproveitando os benefícios do Google Cloud.
O Vertex Model Garden é uma biblioteca de modelos de ML que ajuda a descobrir, testar, personalizar e implantar modelos e recursos reservados do Google e de terceiros selecionados.
O que você vai fazer
Você vai usar o Cloud Shell e o Cloud Run do Google para implantar um contêiner Docker com base na imagem pré-criada do LIT.
O Cloud Run é uma plataforma de computação gerenciada que permite executar contêineres diretamente na infraestrutura escalonável do Google, incluindo em GPUs.
Conjunto de dados
Por padrão, a demonstração usa o conjunto de dados de amostra de depuração de comandos do LIT, mas você pode carregar o seu próprio pela interface.
Antes de começar
Para este guia de referência, você precisa de um projeto do Google Cloud. É possível criar um novo projeto ou selecionar um que já foi criado.
2. Iniciar o console do Google Cloud e um Cloud Shell
Nesta etapa, você vai iniciar um console do Google Cloud e usar o Google Cloud Shell.
2a: iniciar um console do Google Cloud
Abra um navegador e acesse o console do Google Cloud.
O console do Google Cloud é uma interface de administrador da Web poderosa e segura que permite gerenciar seus recursos do Google Cloud rapidamente. É uma ferramenta de DevOps em qualquer lugar.
2b: iniciar um Google Cloud Shell
O Cloud Shell é um ambiente de desenvolvimento e operações on-line acessível pelo navegador em qualquer lugar. É possível gerenciar os recursos com este terminal on-line pré-carregado com utilitários como a ferramenta de linha de comando gcloud, kubectl e muito mais. Também é possível desenvolver, criar, depurar e implantar seus apps baseados na nuvem usando o Editor do Cloud Shell on-line. O Cloud Shell oferece um ambiente on-line pronto para desenvolvedores com um conjunto de ferramentas favoritas pré-instaladas e 5 GB de espaço de armazenamento permanente. Você vai usar o prompt de comando nas próximas etapas.
Inicie um Google Cloud Shell usando o ícone no canto superior direito da barra de menus, circulado em azul na captura de tela a seguir.

Um terminal com um shell Bash vai aparecer na parte de baixo da página.

2c: definir o projeto do Google Cloud
Defina o ID e a região do projeto usando o comando gcloud.
# Set your GCP Project ID.
gcloud config set project your-project-id
# Set your GCP Project Region.
gcloud config set run/region your-project-region
3. Implantar a imagem do Docker do servidor de apps do LIT com o Cloud Run
3a: implantar o app LIT no Cloud Run
Primeiro, defina a versão mais recente do LIT-App como a versão a ser implantada.
# Set latest version as your LIT_SERVICE_TAG.
export LIT_SERVICE_TAG=latest
# List all the public LIT GCP App server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app
Depois de definir a tag de versão, você precisa nomear o serviço.
# Set your lit service name. While 'lit-app-service' is provided as a placeholder, you can customize the service name based on your preferences.
export LIT_SERVICE_NAME=lit-app-service
Depois disso, execute o comando a seguir para implantar o contêiner no Cloud Run.
# Use below cmd to deploy the LIT App to Cloud Run.
gcloud run deploy $LIT_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app:$LIT_SERVICE_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--no-allow-unauthenticated
O LIT também permite adicionar o conjunto de dados ao iniciar o servidor. Para fazer isso, defina a variável DATASETS para incluir os dados que você quer carregar, usando o formato name:path, por exemplo, data_foo:/bar/data_2024.jsonl. O formato do conjunto de dados precisa ser .jsonl, em que cada registro contém os campos prompt e, opcionalmente, target e source. Para carregar vários conjuntos de dados, separe-os com uma vírgula. Se não for definido, o conjunto de dados de amostra de depuração de comandos do LIT será carregado.
# Set the dataset.
export DATASETS=[DATASETS]
Ao definir MAX_EXAMPLES, é possível definir o número máximo de exemplos a serem carregados de cada conjunto de avaliação.
# Set the max examples.
export MAX_EXAMPLES=[MAX_EXAMPLES]
Em seguida, no comando de implantação, adicione
--set-env-vars "DATASETS=$DATASETS" \
--set-env-vars "MAX_EXAMPLES=$MAX_EXAMPLES" \
3b: ver o serviço de app LIT
Depois de criar o servidor do app LIT, você pode encontrar o serviço na seção Cloud Run do console do Cloud.
Selecione o serviço do app LIT que você acabou de criar. Verifique se o nome do serviço é o mesmo que LIT_SERVICE_NAME.

Para encontrar o URL do serviço, clique no serviço que você acabou de implantar.

Assim, você poderá acessar a interface do LIT. Se você encontrar um erro, consulte a seção "Solução de problemas".

Verifique a seção "REGISTROS" para monitorar a atividade, ver mensagens de erro e acompanhar o progresso da implantação.

Confira a seção "MÉTRICAS" para ver as métricas do serviço.

3c: carregar conjuntos de dados
Clique na opção Configure na interface do LIT e selecione Dataset. Carregue o conjunto de dados especificando um nome e fornecendo o URL dele. O formato do conjunto de dados precisa ser .jsonl, em que cada registro contém os campos prompt e, opcionalmente, target e source.

4. Preparar modelos do Gemini no Model Garden da Vertex AI
Os modelos de fundação do Gemini do Google estão disponíveis na API Vertex AI. A LIT fornece o wrapper do modelo VertexAIModelGarden para usar esses modelos na geração. Basta especificar a versão desejada (por exemplo, "gemini-1.5-pro-001") usando o parâmetro de nome do modelo. Uma das principais vantagens de usar esses modelos é que eles não exigem nenhum esforço extra para implantação. Por padrão, você tem acesso imediato a modelos como o Gemini 1.0 Pro e o Gemini 1.5 Pro no GCP, eliminando a necessidade de etapas extras de configuração.
4a: conceder permissões da Vertex AI
Para consultar o Gemini no GCP, é necessário conceder permissões da Vertex AI à conta de serviço. Verifique se o nome da conta de serviço é Default compute service account. Copie o e-mail da conta de serviço.

Adicione o e-mail da conta de serviço como um principal com a função Vertex AI User na sua lista de permissões do IAM.

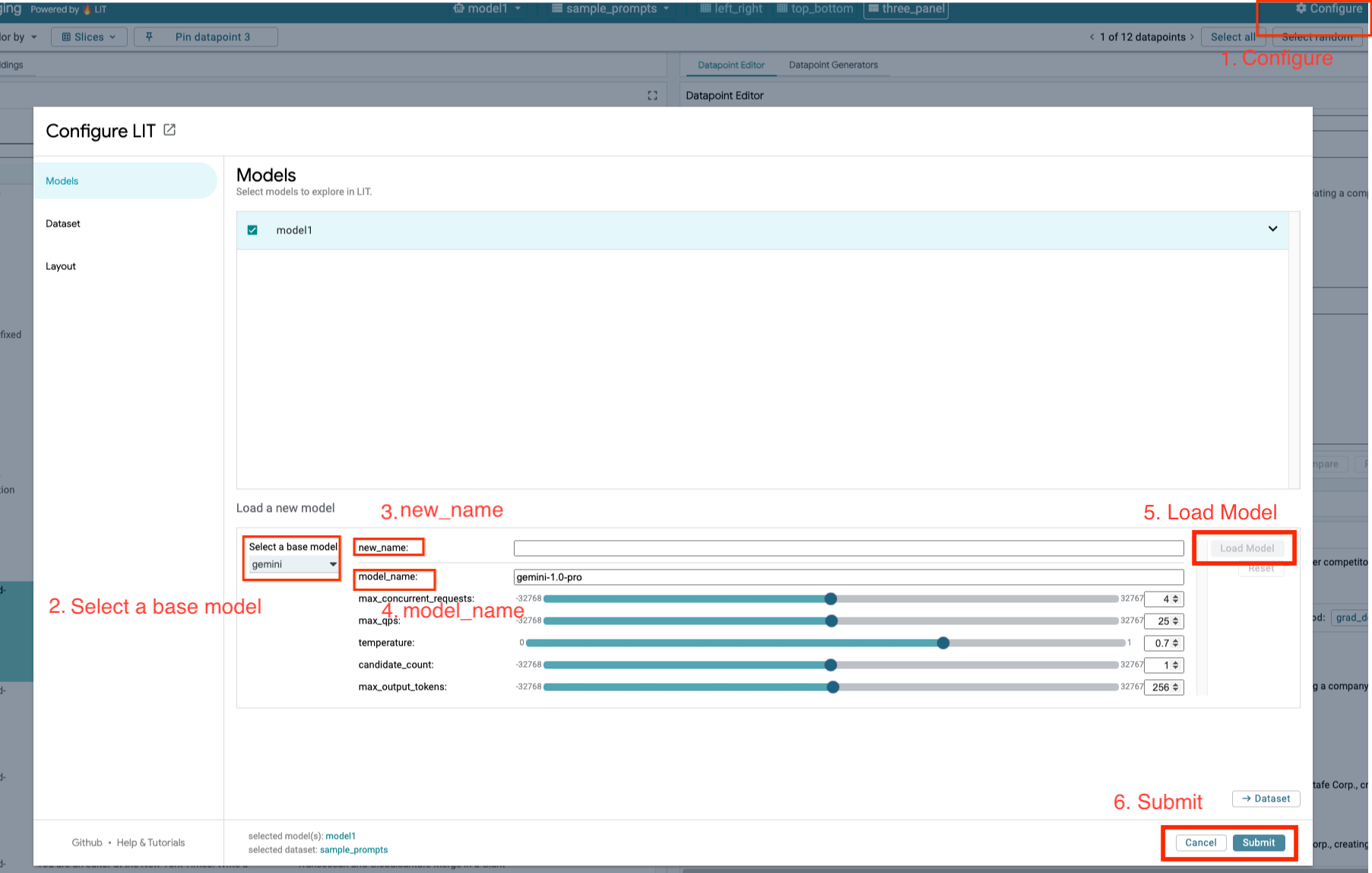
4b: carregar modelos do Gemini
Você vai carregar modelos do Gemini e ajustar os parâmetros seguindo as etapas abaixo.
- Clique na opção
Configurena interface do LIT.
- Clique na opção
- Selecione a opção
geminiemSelect a base model.
- Selecione a opção
- Você precisa nomear o modelo em
new_name.
- Você precisa nomear o modelo em
- Insira os modelos do Gemini selecionados como
model_name.
- Insira os modelos do Gemini selecionados como
- Clique em
Load Model.
- Clique em
- Clique em
Submit.
- Clique em
5. Implantar o servidor de modelos de LLMs autohospedados no GCP
O auto-hospedagem de LLMs com a imagem do Docker do servidor de modelos do LIT permite usar as funções de saliência e tokenização do LIT para ter insights mais profundos sobre o comportamento do modelo. A imagem do servidor de modelo funciona com modelos KerasNLP ou Hugging Face Transformers, incluindo pesos fornecidos pela biblioteca e auto-hospedados, por exemplo, no Google Cloud Storage.
5a: Configurar modelos
Cada contêiner carrega um modelo, configurado usando variáveis de ambiente.
Especifique os modelos a serem carregados definindo MODEL_CONFIG. O formato precisa ser name:path, por exemplo, model_foo:model_foo_path. O caminho pode ser um URL, um caminho de arquivo local ou o nome de uma predefinição para a estrutura de aprendizado profundo configurada. Consulte a tabela a seguir para mais informações. Esse servidor é testado com Gemma, GPT2, Llama e Mistral em todos os valores DL_FRAMEWORK compatíveis. Outros modelos podem funcionar, mas talvez seja necessário fazer ajustes.
# Set models you want to load. While 'gemma2b is given as a placeholder, you can load your preferred model by following the instructions above.
export MODEL_CONFIG=gemma2b:gemma_2b_en
Além disso, o servidor de modelo do LIT permite a configuração de várias variáveis de ambiente usando o comando abaixo. Consulte a tabela para mais detalhes. Cada variável precisa ser definida individualmente.
# Customize the variable value as needed.
export [VARIABLE]=[VALUE]
Variável | Valores | Descrição |
DL_FRAMEWORK |
| A biblioteca de modelagem usada para carregar os pesos do modelo no tempo de execução especificado. O valor padrão é |
DL_RUNTIME |
| A estrutura de back-end de aprendizado profundo em que o modelo é executado. Todos os modelos carregados por esse servidor vão usar o mesmo back-end, e incompatibilidades vão resultar em erros. O valor padrão é |
PRECISÃO |
| Precisão de ponto flutuante para os modelos de LLM. O valor padrão é |
BATCH_SIZE | Números inteiros positivos | O número de exemplos a serem processados por lote. O valor padrão é |
SEQUENCE_LENGTH | Números inteiros positivos | O tamanho máximo da sequência do comando de entrada mais o texto gerado. O valor padrão é |
5b: Implantar o servidor de modelos no Cloud Run
Primeiro, defina a versão mais recente do Model Server como a versão a ser implantada.
# Set latest as MODEL_VERSION_TAG.
export MODEL_VERSION_TAG=latest
# List all the public LIT GCP model server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server
Depois de definir a tag de versão, você precisa nomear o modelo-servidor.
# Set your Service name.
export MODEL_SERVICE_NAME='gemma2b-model-server'
Depois disso, execute o comando a seguir para implantar o contêiner no Cloud Run. Se você não definir as variáveis de ambiente, os valores padrão serão aplicados. Como a maioria dos LLMs exige recursos de computação caros, é altamente recomendável usar uma GPU. Se você preferir executar apenas na CPU (o que funciona bem para modelos pequenos como o GPT2), remova os argumentos relacionados --gpu 1 --gpu-type nvidia-l4 --max-instances 7.
# Deploy the model service container.
gcloud beta run deploy $MODEL_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server:$MODEL_VERSION_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 7 \
--set-env-vars "MODEL_CONFIG=$MODEL_CONFIG" \
--no-allow-unauthenticated
Além disso, é possível personalizar as variáveis de ambiente adicionando os seguintes comandos. Inclua apenas as variáveis de ambiente necessárias para suas necessidades específicas.
--set-env-vars "DL_FRAMEWORK=$DL_FRAMEWORK" \
--set-env-vars "DL_RUNTIME=$DL_RUNTIME" \
--set-env-vars "PRECISION=$PRECISION" \
--set-env-vars "BATCH_SIZE=$BATCH_SIZE" \
--set-env-vars "SEQUENCE_LENGTH=$SEQUENCE_LENGTH" \
Outras variáveis de ambiente podem ser necessárias para acessar determinados modelos. Consulte as instruções do Kaggle Hub (usado para modelos KerasNLP) e do Hugging Face Hub, conforme necessário.
5c: acessar o servidor de modelo
Depois de criar o servidor de modelos, o serviço iniciado pode ser encontrado na seção Cloud Run do seu projeto do GCP.
Selecione o servidor de modelo que você acabou de criar. Verifique se o nome do serviço é o mesmo que MODEL_SERVICE_NAME.
Para encontrar o URL do serviço, clique no serviço de modelo que você acabou de implantar.
Verifique a seção "REGISTROS" para monitorar a atividade, ver mensagens de erro e acompanhar o progresso da implantação.
Confira a seção "MÉTRICAS" para ver as métricas do serviço.
5-d: carregar modelos auto-hospedados
Se você fizer proxy do servidor LIT na etapa 3 (confira a seção "Solução de problemas"), será necessário conseguir seu token de identidade do GCP executando o seguinte comando:
# Find your GCP identity token.
gcloud auth print-identity-token
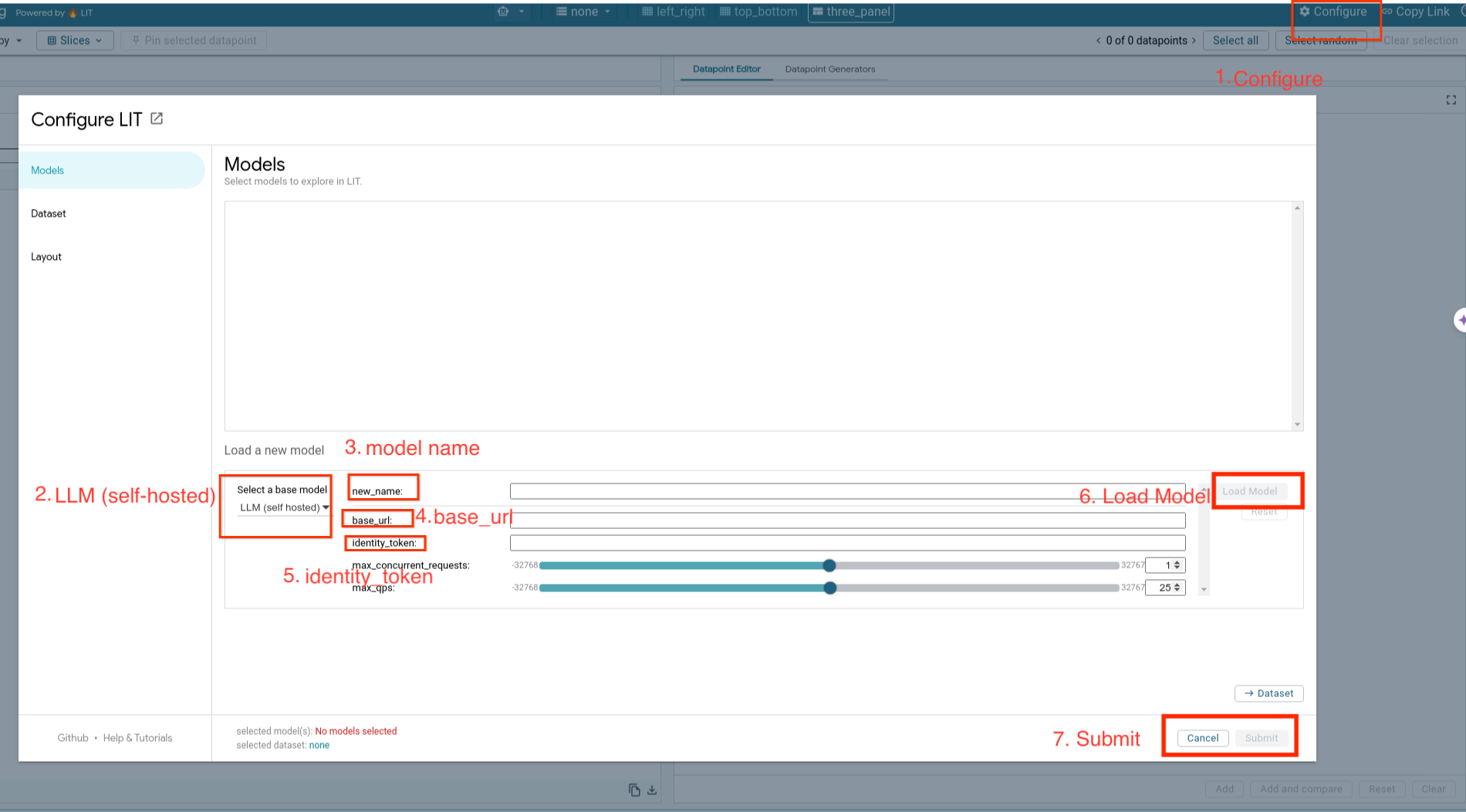
Você vai carregar modelos auto-hospedados e ajustar os parâmetros deles seguindo as etapas abaixo.
- Clique na opção
Configurena interface do LIT. - Selecione a opção
LLM (self hosted)emSelect a base model. - Você precisa nomear o modelo em
new_name. - Insira o URL do servidor de modelo como
base_url. - Insira o token de identidade obtido no
identity_tokense você fizer proxy do servidor do app LIT (consulte as etapas 3 e 7). Caso contrário, deixe em branco. - Clique em
Load Model. - Clique em
Submit.
6. Interagir com o LIT no GCP
A LIT oferece um conjunto avançado de recursos para ajudar você a depurar e entender os comportamentos do modelo. Você pode fazer algo tão simples quanto consultar o modelo digitando texto em uma caixa e vendo as previsões dele ou inspecionar os modelos em profundidade com o conjunto de recursos avançados do LIT, incluindo:
6a: consultar o modelo usando o LIT
O LIT consulta automaticamente o conjunto de dados depois do carregamento do modelo e do conjunto de dados. Para conferir a resposta de cada modelo, selecione a resposta nas colunas.


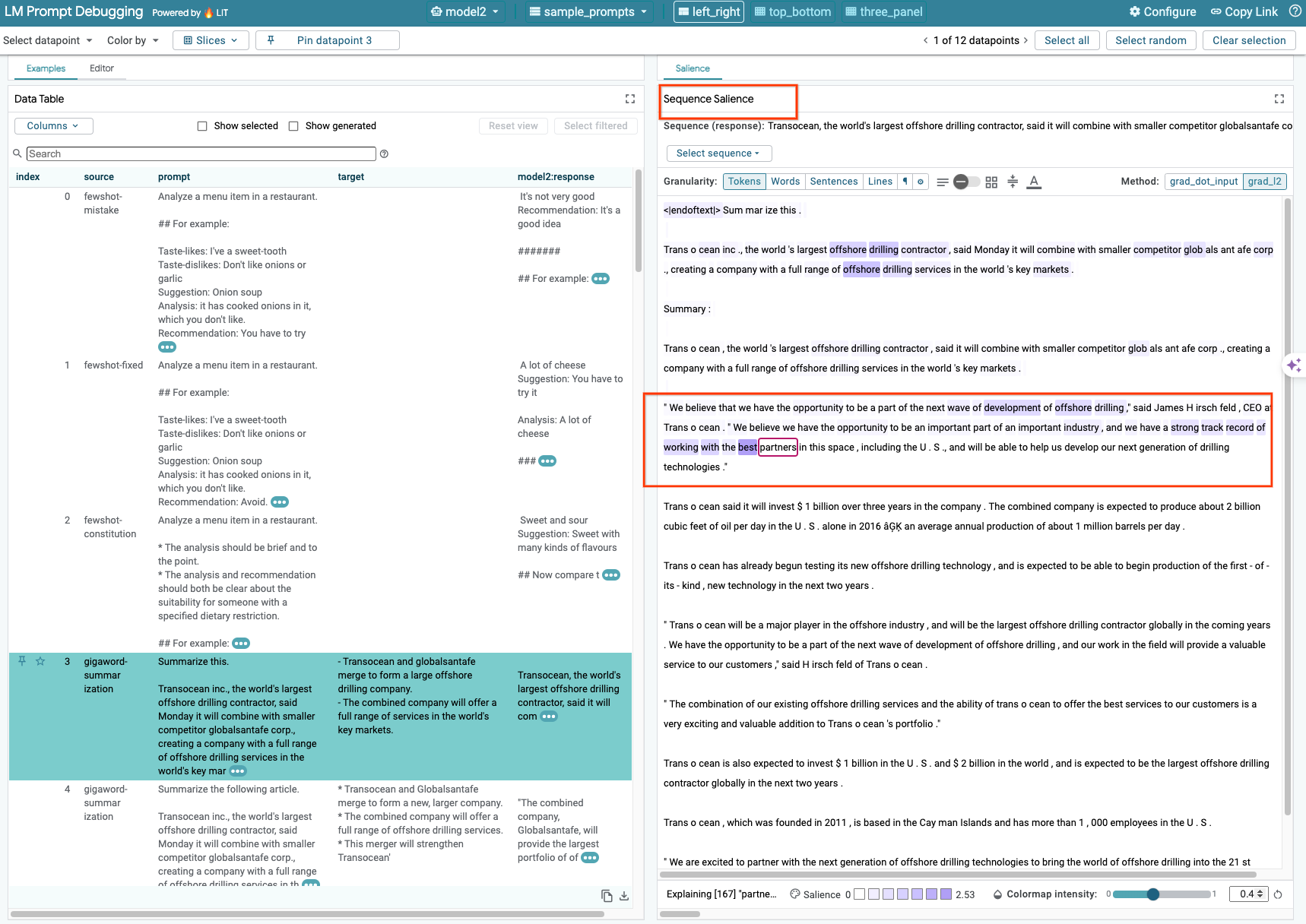
6-b: usar a técnica de saliência de sequência
No momento, a técnica de saliência de sequência no LIT só é compatível com modelos auto-hospedados.
A saliência de sequência é uma ferramenta visual que ajuda a depurar comandos de LLM, destacando quais partes de um comando são mais importantes para uma determinada saída. Para mais informações sobre a relevância da sequência, confira o tutorial completo sobre como usar esse recurso.
Para acessar os resultados de saliência, clique em qualquer entrada ou saída no comando ou na resposta. Os resultados de saliência vão aparecer.
6c: Editar manualmente o comando e a segmentação
Com o LIT, é possível editar manualmente qualquer prompt e target para um ponto de dados existente. Ao clicar em Add, a nova entrada será adicionada ao conjunto de dados.

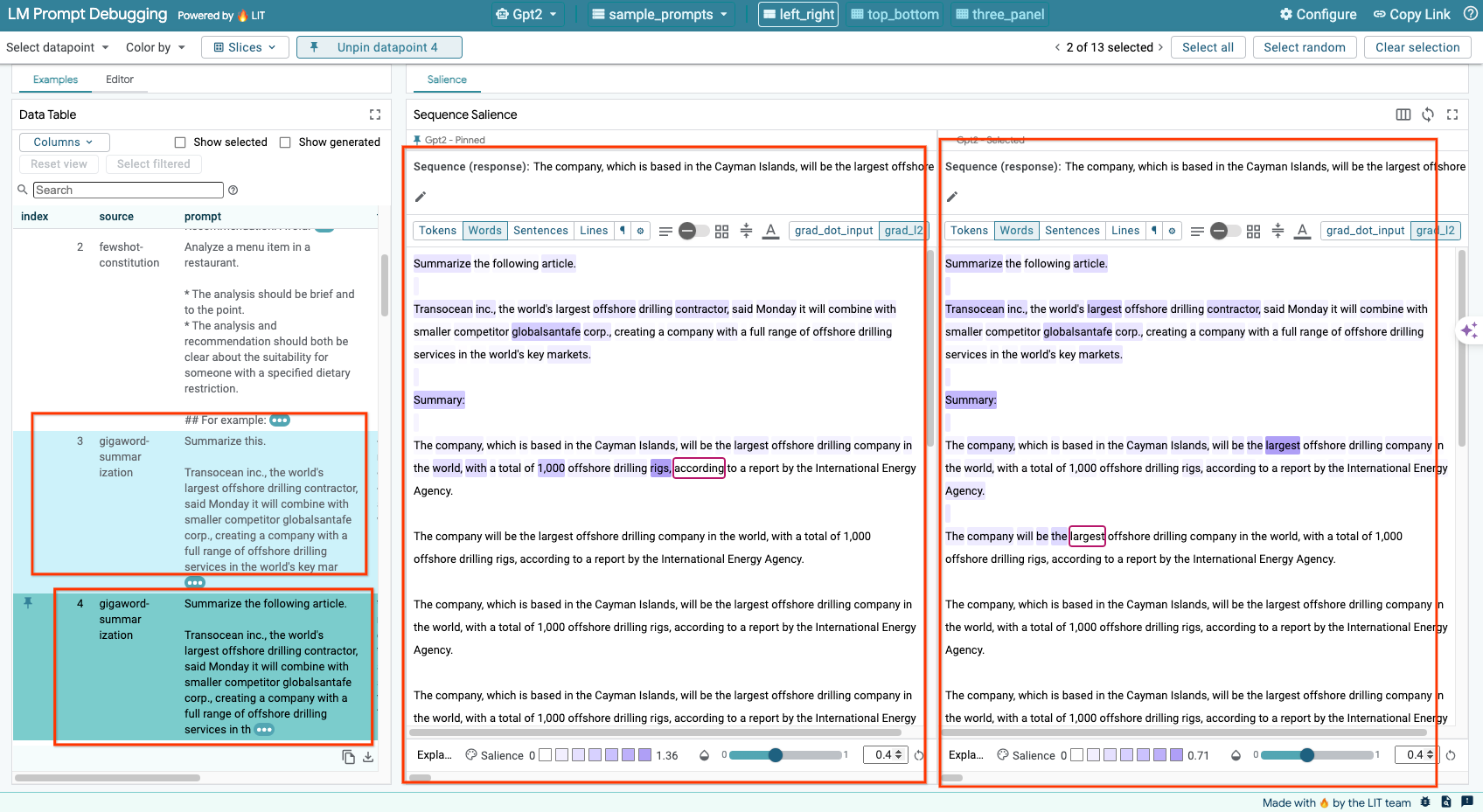
6-d: Comparar comandos lado a lado
Com o LIT, é possível comparar comandos lado a lado em exemplos originais e editados. Você pode editar manualmente um exemplo e conferir o resultado da previsão e a análise de saliência da sequência para as versões original e editada simultaneamente. Você pode modificar o comando para cada ponto de dados, e o LIT vai gerar a resposta correspondente consultando o modelo.
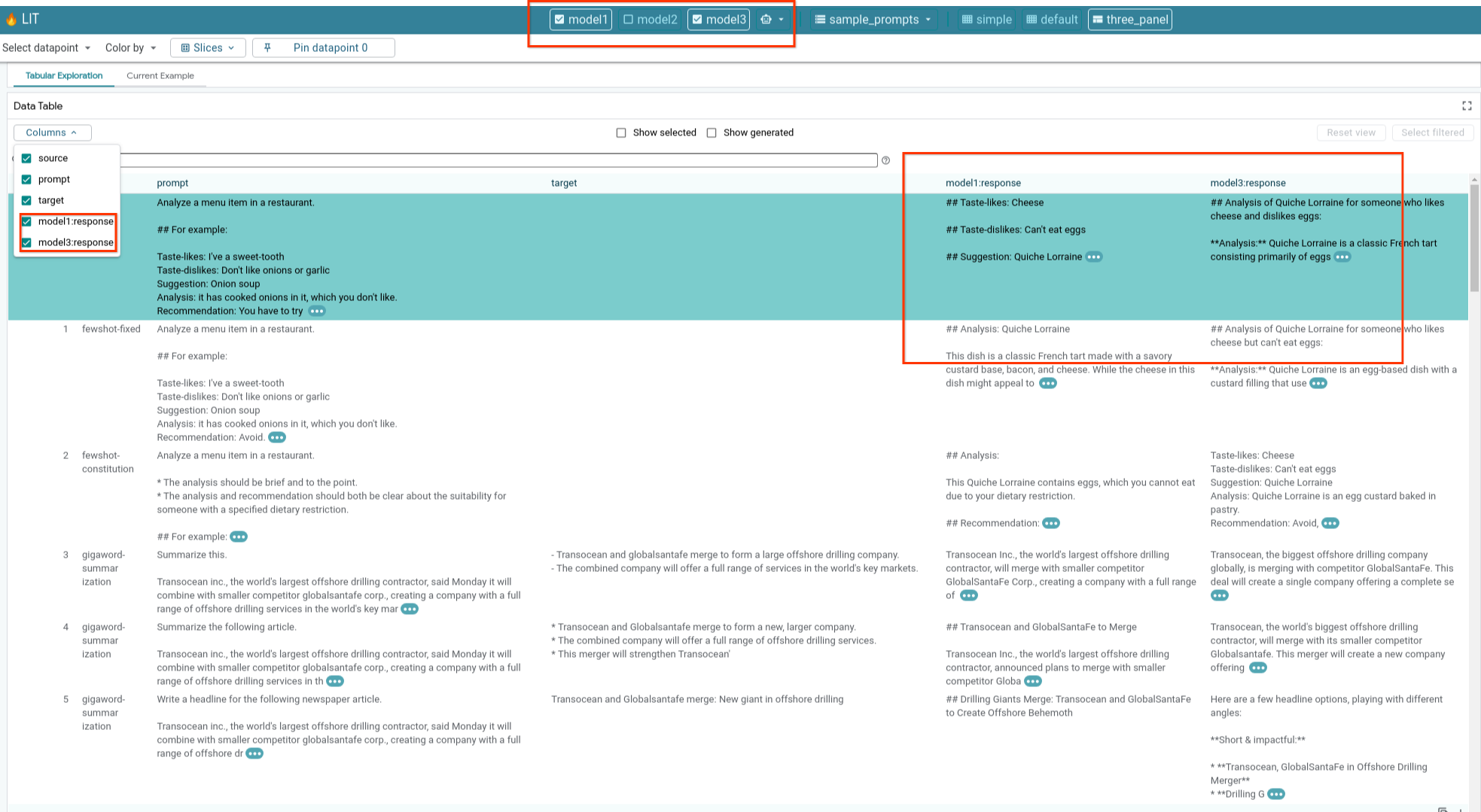
6-e: Compare vários modelos lado a lado
O LIT permite a comparação lado a lado de modelos em exemplos individuais de geração e pontuação de texto, bem como em exemplos agregados para métricas específicas. Ao consultar vários modelos carregados, você pode comparar facilmente as diferenças nas respostas.
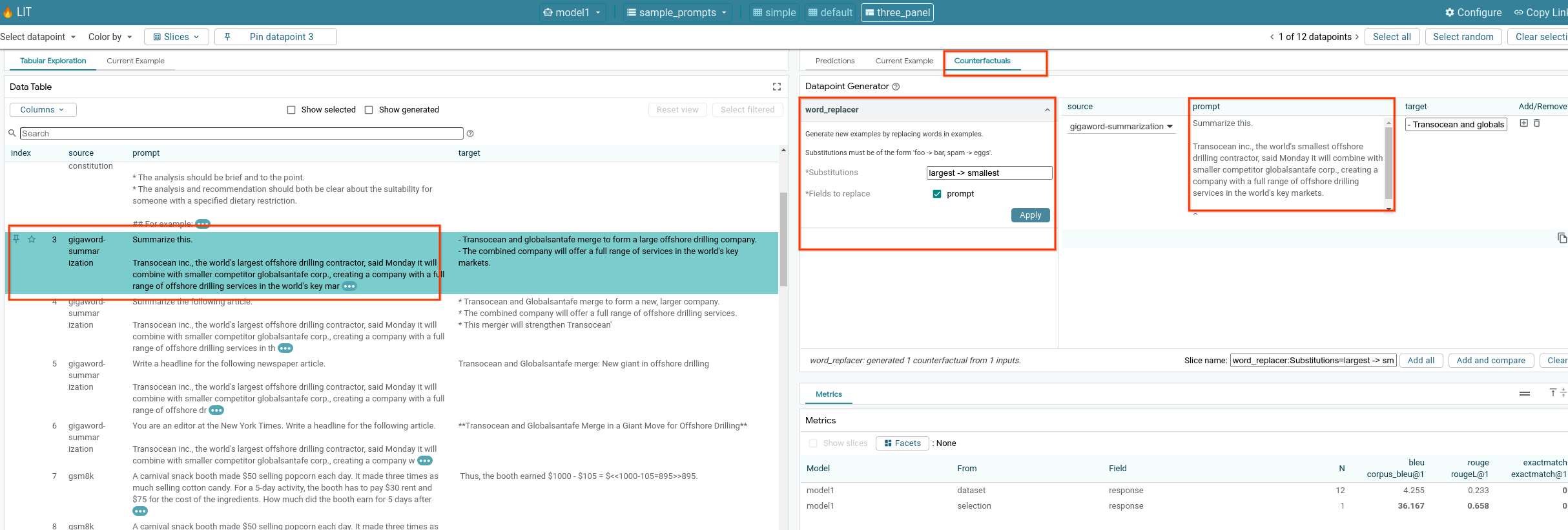
6-f: Geradores contrafactuais automáticos
Você pode usar geradores automáticos de contrafatos para criar entradas alternativas e ver como o modelo se comporta nelas imediatamente.
6-g: Avaliar o desempenho do modelo
É possível avaliar o desempenho do modelo usando métricas (atualmente compatíveis com pontuações BLEU e ROUGE para geração de texto) em todo o conjunto de dados ou em qualquer subconjunto de exemplos filtrados ou selecionados.

7. Solução de problemas
7a: possíveis problemas de acesso e soluções
Como --no-allow-unauthenticated é aplicado ao implantar no Cloud Run, você pode encontrar erros proibidos, conforme mostrado abaixo.

Há duas abordagens para acessar o serviço do app LIT.
1. Proxy para serviço local
É possível fazer proxy do serviço para o host local usando o comando abaixo.
# Proxy the service to local host.
gcloud run services proxy $LIT_SERVICE_NAME
Em seguida, clique no link do serviço proxy para acessar o servidor LIT.
2. Autenticar usuários diretamente
Siga este link para autenticar usuários e permitir o acesso direto ao serviço do app LIT. Essa abordagem também pode permitir que um grupo de usuários acesse o serviço. Para desenvolvimento que envolve colaboração com várias pessoas, essa é uma opção mais eficaz.
7-b: verificações para garantir que o servidor de modelo foi iniciado com sucesso
Para garantir que o servidor de modelo foi iniciado corretamente, envie uma consulta diretamente. O servidor de modelo fornece três endpoints: predict, tokenize e salience. Forneça os campos prompt e target na sua solicitação.
# Query the model server predict endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/predict -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server tokenize endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/tokenize -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server salience endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/salience -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
Se você tiver um problema de acesso, consulte a seção 7-a acima.
8. Parabéns
Você concluiu o codelab. Hora de relaxar!
Limpar
Para limpar o laboratório, exclua todos os serviços do Google Cloud criados para ele. Use o Google Cloud Shell para executar os comandos a seguir.
Se a conexão com o Google Cloud for perdida devido à inatividade, redefina as variáveis seguindo as etapas anteriores.
# Delete the LIT App Service.
gcloud run services delete $LIT_SERVICE_NAME
Se você iniciou o servidor de modelo, também precisa excluí-lo.
# Delete the Model Service.
gcloud run services delete $MODEL_SERVICE_NAME
Leia mais
Continue aprendendo sobre os recursos da ferramenta LIT com os materiais abaixo:
- Gemma: Link
- Base de código aberto do LIT: repositório Git
- Artigo do LIT: ArXiv
- Documento de depuração de comandos da LIT: ArXiv
- Vídeo de demonstração do recurso LIT: YouTube
- Demonstração de depuração de comandos do LIT: YouTube
- Kit de ferramentas de IA generativa responsável: link
Contato
Se tiver dúvidas ou problemas com este codelab, entre em contato com nossa equipe no GitHub.
Licença
Este trabalho está sob a licença Atribuição 4.0 Genérica da Creative Commons.