
1. Обзор
В этом практическом занятии подробно описано развертывание сервера приложений LIT на платформе Google Cloud Platform (GCP) для взаимодействия с базовыми моделями Vertex AI Gemini и самостоятельно размещенными большими языковыми моделями (LLM) сторонних разработчиков. Также приводятся рекомендации по использованию пользовательского интерфейса LIT для оперативной отладки и интерпретации моделей.
Выполнив эти практические задания, пользователи научатся:
- Настройте LIT-сервер в GCP.
- Подключите сервер LIT к моделям Vertex AI Gemini или другим самостоятельно размещенным LLM-системам.
- Используйте пользовательский интерфейс LIT для анализа, отладки и интерпретации запросов с целью повышения производительности модели и получения более глубокого понимания процесса.
Что такое LIT?
LIT — это визуальный интерактивный инструмент для анализа моделей, поддерживающий текстовые, графические и табличные данные. Он может работать как автономный сервер или в средах Notebook, таких как Google Colab, Jupyter и Google Cloud Vertex AI. LIT доступен на PyPI и GitHub .
Изначально разработанная для понимания моделей классификации и регрессии, в последних обновлениях были добавлены инструменты для отладки подсказок LLM , позволяющие исследовать, как содержимое пользователя, модели и системы влияет на поведение генерации.
Что такое Vertex AI и Model Garden?
Vertex AI — это платформа машинного обучения (ML), которая позволяет обучать и развертывать модели машинного обучения и приложения ИИ, а также настраивать LLM для использования в ваших приложениях на основе ИИ. Vertex AI объединяет рабочие процессы обработки данных, анализа данных и разработки машинного обучения, позволяя вашим командам сотрудничать, используя общий набор инструментов, и масштабировать ваши приложения, используя преимущества Google Cloud.
Vertex Model Garden — это библиотека моделей машинного обучения, которая помогает вам находить, тестировать, настраивать и развертывать собственные модели и ресурсы Google, а также некоторые модели и ресурсы сторонних разработчиков.
Что вы будете делать
Для развертывания контейнера Docker из предварительно созданного образа LIT вы будете использовать Google Cloud Shell и Cloud Run .
Cloud Run — это управляемая вычислительная платформа, позволяющая запускать контейнеры непосредственно на масштабируемой инфраструктуре Google, в том числе на графических процессорах (GPU) .
Набор данных
В демонстрационной версии по умолчанию используется набор данных для отладки командной строки LIT, но вы можете загрузить свой собственный через пользовательский интерфейс.
Прежде чем начать
Для работы с этим руководством вам потребуется проект Google Cloud . Вы можете создать новый проект или выбрать уже созданный.
2. Запустите консоль Google Cloud и оболочку Cloud Shell.
На этом шаге вы запустите консоль Google Cloud и воспользуетесь оболочкой Google Cloud Shell.
2-а: Запуск консоли Google Cloud
Откройте браузер и перейдите в консоль Google Cloud .
Консоль Google Cloud — это мощный и безопасный веб-интерфейс администратора, позволяющий быстро управлять ресурсами Google Cloud. Это инструмент DevOps, доступный в любое время и в любом месте.
2-б: Запуск Google Cloud Shell
Cloud Shell — это онлайн-среда разработки и эксплуатации, доступная из любой точки мира через браузер. Вы можете управлять своими ресурсами с помощью онлайн-терминала, в который предварительно загружены такие утилиты, как инструмент командной строки gcloud, kubectl и другие. Вы также можете разрабатывать, создавать, отлаживать и развертывать свои облачные приложения, используя онлайн-редактор Cloud Shell. Cloud Shell предоставляет готовую к использованию онлайн-среду для разработчиков с предустановленным набором любимых инструментов и 5 ГБ постоянного хранилища. На следующих шагах вы будете использовать командную строку.
Запустите Google Cloud Shell, используя значок в правом верхнем углу строки меню, обведенный синим кругом на следующем скриншоте.

В нижней части страницы вы должны увидеть терминал с оболочкой Bash.

2-c: Настройка проекта Google Cloud
Необходимо указать идентификатор проекта и регион проекта с помощью команды gcloud .
# Set your GCP Project ID.
gcloud config set project your-project-id
# Set your GCP Project Region.
gcloud config set run/region your-project-region
3. Разверните образ Docker для сервера приложений LIT с помощью Cloud Run.
3-а: Развертывание приложения LIT в облаке
Сначала необходимо установить последнюю версию LIT-App в качестве версии, подлежащей развертыванию.
# Set latest version as your LIT_SERVICE_TAG.
export LIT_SERVICE_TAG=latest
# List all the public LIT GCP App server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app
После установки тега версии необходимо присвоить имя сервису.
# Set your lit service name. While 'lit-app-service' is provided as a placeholder, you can customize the service name based on your preferences.
export LIT_SERVICE_NAME=lit-app-service
После этого вы можете выполнить следующую команду, чтобы развернуть контейнер в Cloud Run.
# Use below cmd to deploy the LIT App to Cloud Run.
gcloud run deploy $LIT_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app:$LIT_SERVICE_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--no-allow-unauthenticated
LIT также позволяет добавлять набор данных при запуске сервера. Для этого установите переменную DATASETS , указав в ней данные, которые вы хотите загрузить, используя формат name:path , например, data_foo:/bar/data_2024.jsonl . Формат набора данных должен быть .jsonl, где каждая запись содержит prompt и необязательные поля target и source . Для загрузки нескольких наборов данных разделите их запятой. Если не указано иное, будет загружен пример набора данных для отладки подсказок LIT.
# Set the dataset.
export DATASETS=[DATASETS]
Установив параметр MAX_EXAMPLES, вы можете задать максимальное количество примеров для загрузки из каждого набора данных для оценки.
# Set the max examples.
export MAX_EXAMPLES=[MAX_EXAMPLES]
Затем в команде развертывания можно добавить
--set-env-vars "DATASETS=$DATASETS" \
--set-env-vars "MAX_EXAMPLES=$MAX_EXAMPLES" \
3-б: Просмотр сервиса приложений LIT
После создания сервера приложений LIT вы сможете найти эту службу в разделе Cloud Run в консоли Cloud Console.
Выберите созданную вами службу LIT App. Убедитесь, что имя службы совпадает с LIT_SERVICE_NAME .
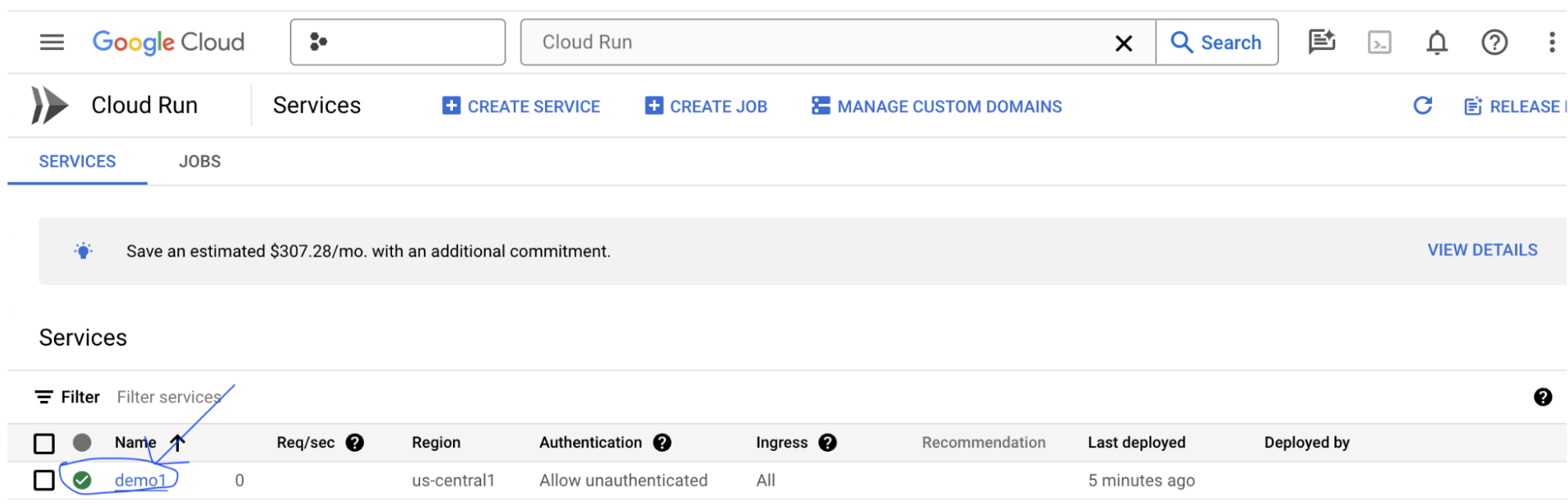
URL-адрес службы можно найти, щелкнув по только что развернутой службе.

После этого вы сможете увидеть пользовательский интерфейс LIT. Если возникнет ошибка, обратитесь к разделу «Устранение неполадок».

В разделе «ЖУРНАЛЫ» можно отслеживать активность, просматривать сообщения об ошибках и следить за ходом развертывания.
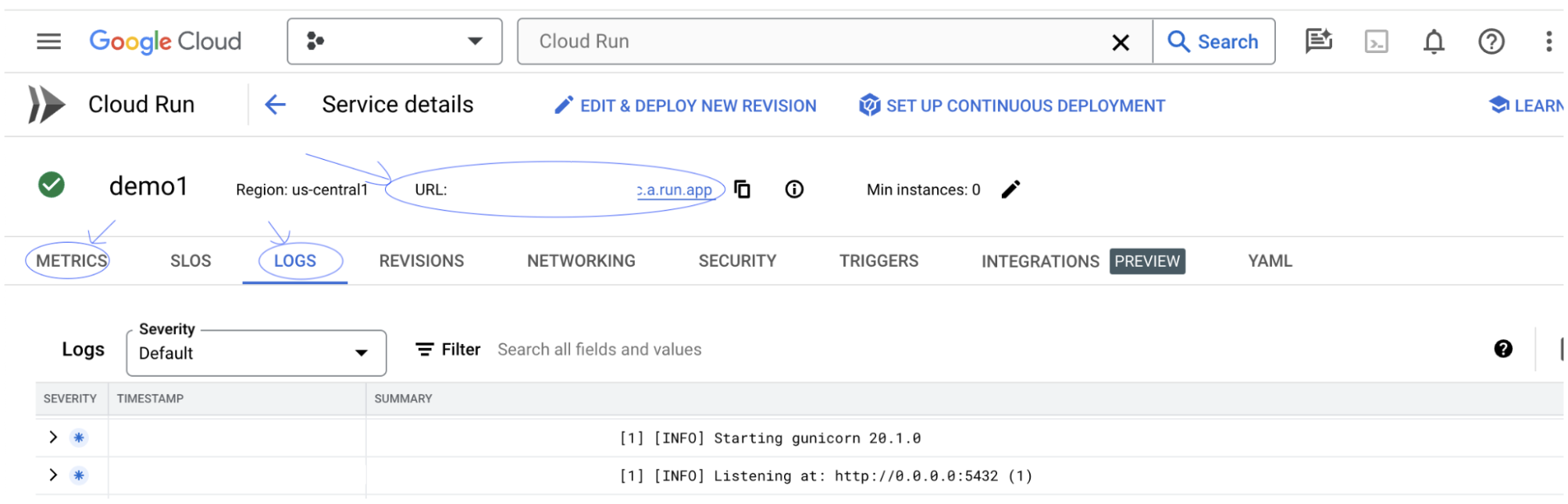
В разделе «МЕТРИКИ» вы можете просмотреть показатели работы сервиса.

3-c: Загрузка наборов данных
В пользовательском интерфейсе LIT нажмите кнопку « Configure , выберите « Dataset . Загрузите набор данных, указав имя и URL-адрес набора данных. Формат набора данных должен быть .jsonl, где каждая запись содержит prompt и необязательные поля target и source .

4. Подготовка моделей Gemini в Vertex AI Model Garden.
Модели Gemini Foundation от Google доступны через API Vertex AI. LIT предоставляет оболочку модели VertexAIModelGarden для использования этих моделей при генерации. Просто укажите желаемую версию (например, "gemini-1.5-pro-001") в параметре имени модели. Ключевое преимущество использования этих моделей заключается в том, что они не требуют дополнительных усилий для развертывания. По умолчанию вы получаете немедленный доступ к таким моделям, как Gemini 1.0 Pro и Gemini 1.5 Pro в GCP, что исключает необходимость дополнительных шагов настройки.
4-а: Предоставить Vertex AI разрешения
Для выполнения запросов к Gemini в GCP необходимо предоставить учетной записи службы права доступа к Vertex AI. Убедитесь, что имя учетной записи службы — Default compute service account . Скопируйте адрес электронной почты учетной записи службы.

Добавьте адрес электронной почты сервисной учетной записи в качестве субъекта с ролью Vertex AI User в список разрешенных пользователей IAM .

4-b: Загрузка моделей Gemini
Вы будете загружать модели Gemini и настраивать их параметры, следуя описанным ниже шагам.
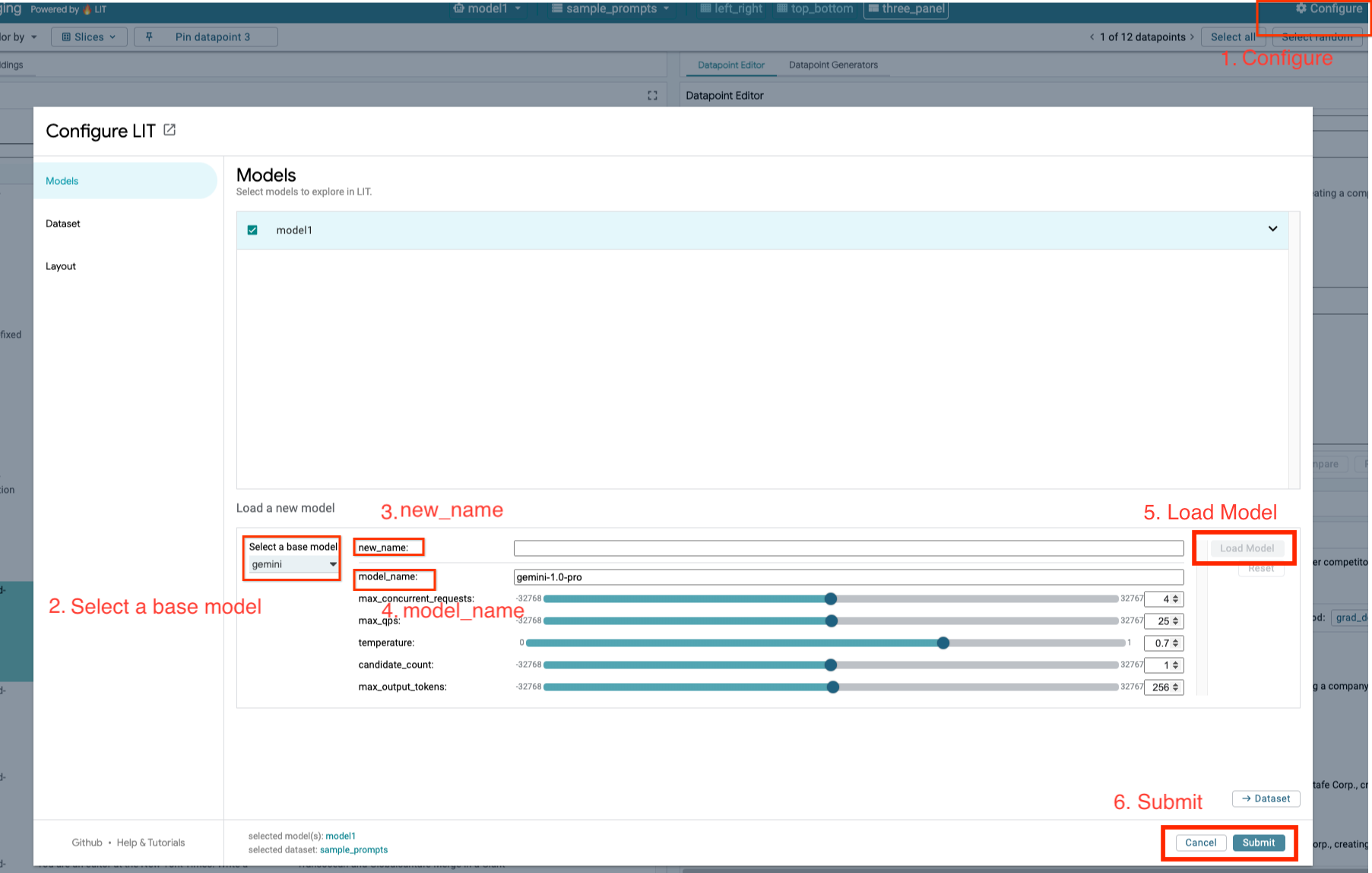
- В пользовательском интерфейсе LIT нажмите кнопку «
Configure».
- В пользовательском интерфейсе LIT нажмите кнопку «
- Выберите вариант
geminiв разделеSelect a base model.
- Выберите вариант
- Необходимо присвоить модели имя в
new_name.
- Необходимо присвоить модели имя в
- Введите название выбранной вами модели Gemini в поле
model_name.
- Введите название выбранной вами модели Gemini в поле
- Нажмите
Load Model.
- Нажмите
- Нажмите
Submit.
- Нажмите
5. Разверните сервер модели LLM с самостоятельным размещением на GCP.
Самостоятельное размещение моделей LLM с помощью образа Docker для сервера моделей LIT позволяет использовать функции определения значимости и токенизации LIT для получения более глубокого понимания поведения модели. Образ сервера моделей работает с моделями KerasNLP или Hugging Face Transformers , включая веса, предоставляемые библиотекой, и веса, размещаемые самостоятельно, например, в Google Cloud Storage.
5-а: Настройка моделей
Каждый контейнер загружает одну модель, настроенную с помощью переменных среды.
Необходимо указать модели для загрузки, задав параметр MODEL_CONFIG. Формат должен быть name:path , например model_foo:model_foo_path . Путь может быть URL-адресом, путем к локальному файлу или именем предустановки для настроенной платформы глубокого обучения (подробнее см. в следующей таблице). Этот сервер протестирован с Gemma, GPT2, Llama и Mistral на всех поддерживаемых значениях DL_FRAMEWORK . Другие модели также должны работать, но могут потребоваться корректировки.
# Set models you want to load. While 'gemma2b is given as a placeholder, you can load your preferred model by following the instructions above.
export MODEL_CONFIG=gemma2b:gemma_2b_en
Кроме того, сервер модели LIT позволяет настраивать различные переменные среды с помощью приведенной ниже команды. Подробности см. в таблице. Обратите внимание, что каждую переменную необходимо устанавливать отдельно.
# Customize the variable value as needed.
export [VARIABLE]=[VALUE]
Переменная | Ценности | Описание |
DL_FRAMEWORK | | Библиотека моделирования, используемая для загрузки весов модели в указанную среду выполнения. По умолчанию используется |
DL_RUNTIME | | Фреймворк для глубокого обучения, на котором работает модель. Все модели, загружаемые этим сервером, будут использовать один и тот же бэкенд, несовместимость приведет к ошибкам. По умолчанию используется |
ТОЧНОСТЬ | | Точность чисел с плавающей запятой для моделей LLM. По умолчанию используется |
РАЗМЕР ПАРТИИ | Положительные целые числа | Количество примеров для обработки за один пакет. По умолчанию — |
ДЛИНА_ПОСЛЕДОВАТЕЛЬНОСТИ | Положительные целые числа | Максимальная длина последовательности, включающая входной запрос и сгенерированный текст. По умолчанию — |
5-b: Развертывание сервера моделей в облаке
Сначала необходимо установить последнюю версию Model Server в качестве версии, подлежащей развертыванию.
# Set latest as MODEL_VERSION_TAG.
export MODEL_VERSION_TAG=latest
# List all the public LIT GCP model server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server
После установки тега версии необходимо присвоить имя вашему серверу моделей.
# Set your Service name.
export MODEL_SERVICE_NAME='gemma2b-model-server'
После этого вы можете выполнить следующую команду для развертывания контейнера в Cloud Run. Если вы не зададите переменные среды, будут применены значения по умолчанию. Поскольку большинство LLM-моделей требуют дорогостоящих вычислительных ресурсов, настоятельно рекомендуется использовать GPU. Если вы предпочитаете работать только на CPU (что хорошо подходит для небольших моделей, таких как GPT2), вы можете удалить соответствующие аргументы --gpu 1 --gpu-type nvidia-l4 --max-instances 7 .
# Deploy the model service container.
gcloud beta run deploy $MODEL_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server:$MODEL_VERSION_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 7 \
--set-env-vars "MODEL_CONFIG=$MODEL_CONFIG" \
--no-allow-unauthenticated
Кроме того, вы можете настроить переменные среды, добавив следующие команды. Включайте только те переменные среды, которые необходимы для ваших конкретных нужд.
--set-env-vars "DL_FRAMEWORK=$DL_FRAMEWORK" \
--set-env-vars "DL_RUNTIME=$DL_RUNTIME" \
--set-env-vars "PRECISION=$PRECISION" \
--set-env-vars "BATCH_SIZE=$BATCH_SIZE" \
--set-env-vars "SEQUENCE_LENGTH=$SEQUENCE_LENGTH" \
Для доступа к некоторым моделям могут потребоваться дополнительные переменные среды. См. инструкции на Kaggle Hub (используется для моделей KerasNLP) и Hugging Face Hub, в зависимости от ситуации.
5-c: Сервер модели доступа
После создания модельного сервера запущенную службу можно найти в разделе Cloud Run вашего проекта GCP.
Выберите созданный вами сервер модели. Убедитесь, что имя службы совпадает с MODEL_SERVICE_NAME .
URL-адрес службы можно найти, щелкнув по модели службы, которую вы только что развернули.
В разделе «ЖУРНАЛЫ» можно отслеживать активность, просматривать сообщения об ошибках и следить за ходом развертывания.
В разделе «МЕТРИКИ» вы можете просмотреть показатели работы сервиса.
5-d: Загрузка саморазмещаемых моделей
Если вы используете прокси для своего LIT-сервера на шаге 3 (см. раздел «Устранение неполадок»), вам потребуется получить токен идентификации GCP, выполнив следующую команду.
# Find your GCP identity token.
gcloud auth print-identity-token
Вы будете загружать самостоятельно размещенные модели и настраивать их параметры, следуя описанным ниже шагам.
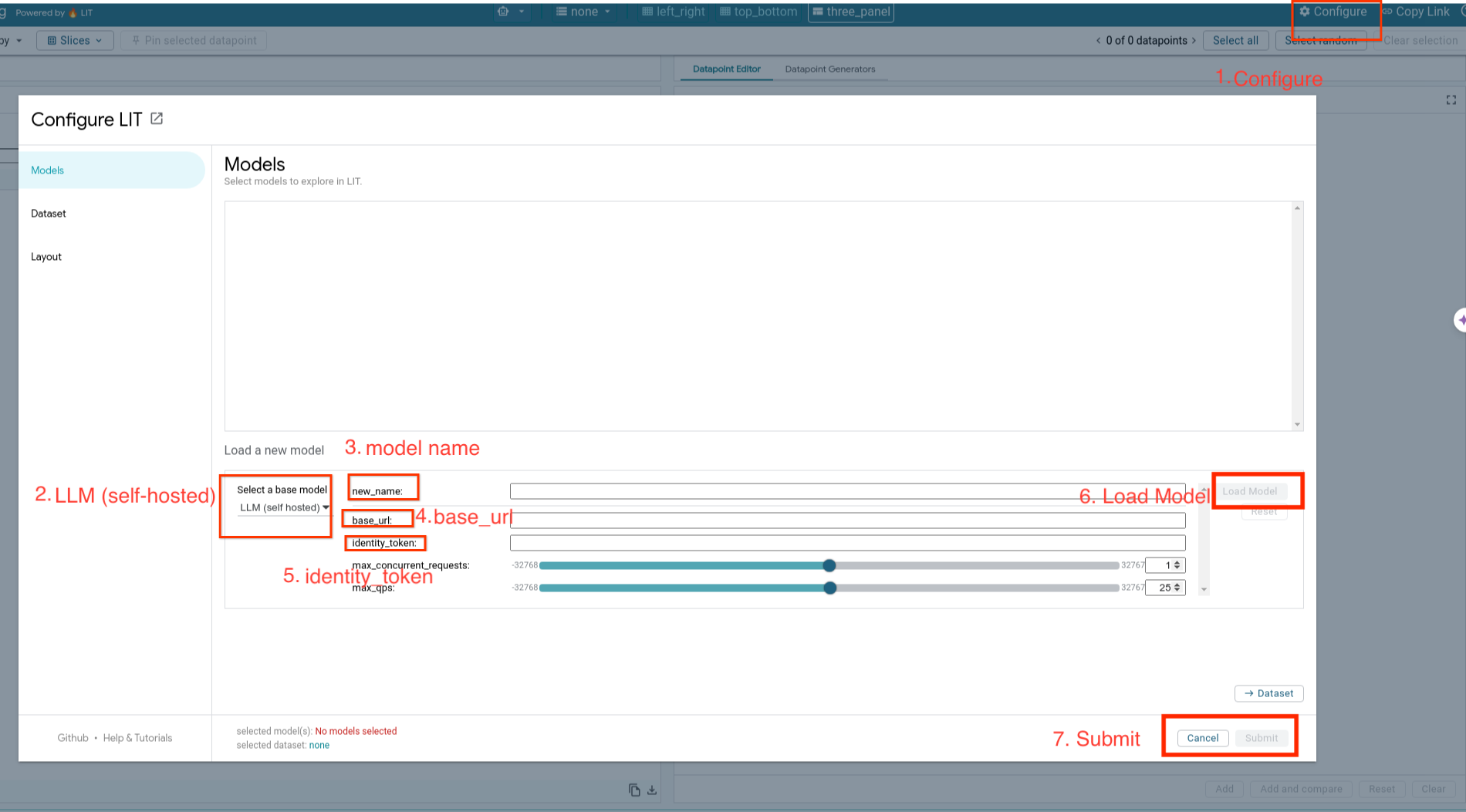
- В пользовательском интерфейсе LIT нажмите кнопку «
Configure». - В разделе
Select a base model» выберите опциюLLM (self hosted). - Необходимо присвоить модели имя в
new_name. - В качестве параметра
base_urlукажите URL-адрес вашего сервера моделей. - Введите полученный токен идентификации в поле
identity_tokenесли вы используете проксирование к серверу приложения LIT (см. Шаги 3 и 7). В противном случае оставьте это поле пустым. - Нажмите
Load Model. - Нажмите
Submit.
6. Взаимодействие с LIT на GCP.
LIT предлагает богатый набор функций, которые помогут вам отлаживать и понимать поведение моделей. Вы можете выполнять простые действия, например, запрашивать информацию у модели, вводя текст в поле и просматривая прогнозы модели, или углубленно изучать модели с помощью мощного набора функций LIT, включая:
6-а: Запрос к модели через LIT
LIT автоматически запрашивает данные из набора данных после загрузки модели и самого набора данных. Вы можете просмотреть ответ каждой модели, выбрав соответствующий ответ в столбцах.


6-б: Использование техники последовательной значимости
В настоящее время метод Sequence Salience в LIT поддерживает только модели, размещенные на собственном сервере.
Функция «Выделение важных частей последовательности» — это визуальный инструмент, помогающий отлаживать подсказки LLM, выделяя наиболее важные части подсказки для заданного результата. Более подробную информацию о функции «Выделение важных частей последовательности» можно найти в полном руководстве по её использованию.
Чтобы просмотреть результаты анализа значимости, щелкните по любому полю ввода или вывода в запросе или ответе, и результаты анализа значимости будут отображены.
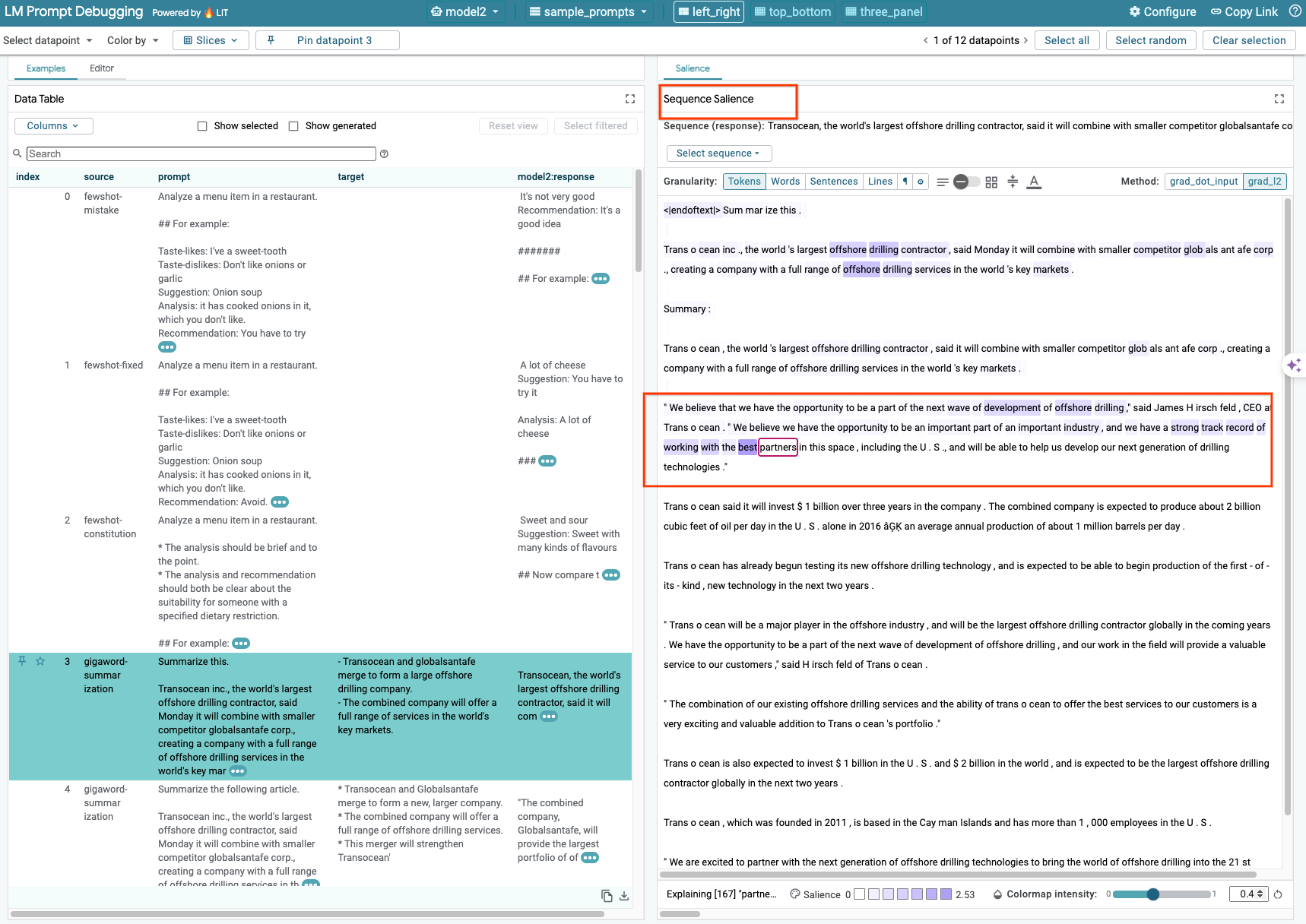
6-c: Запрос на ручное редактирование и целевой объект
LIT позволяет вручную редактировать любой prompt и target для существующей точки данных. Нажав кнопку Add , вы добавите новый входной параметр в набор данных.
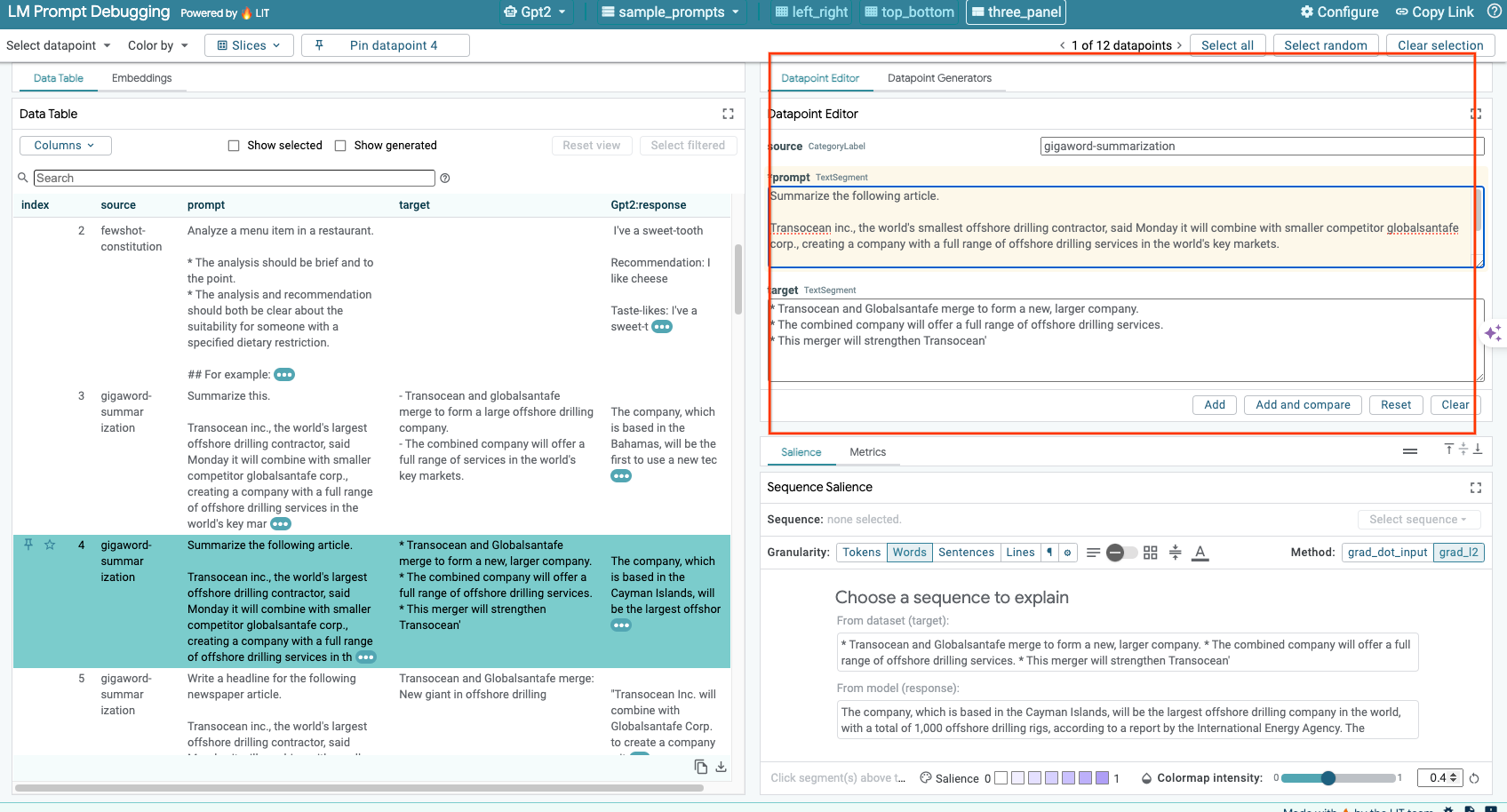
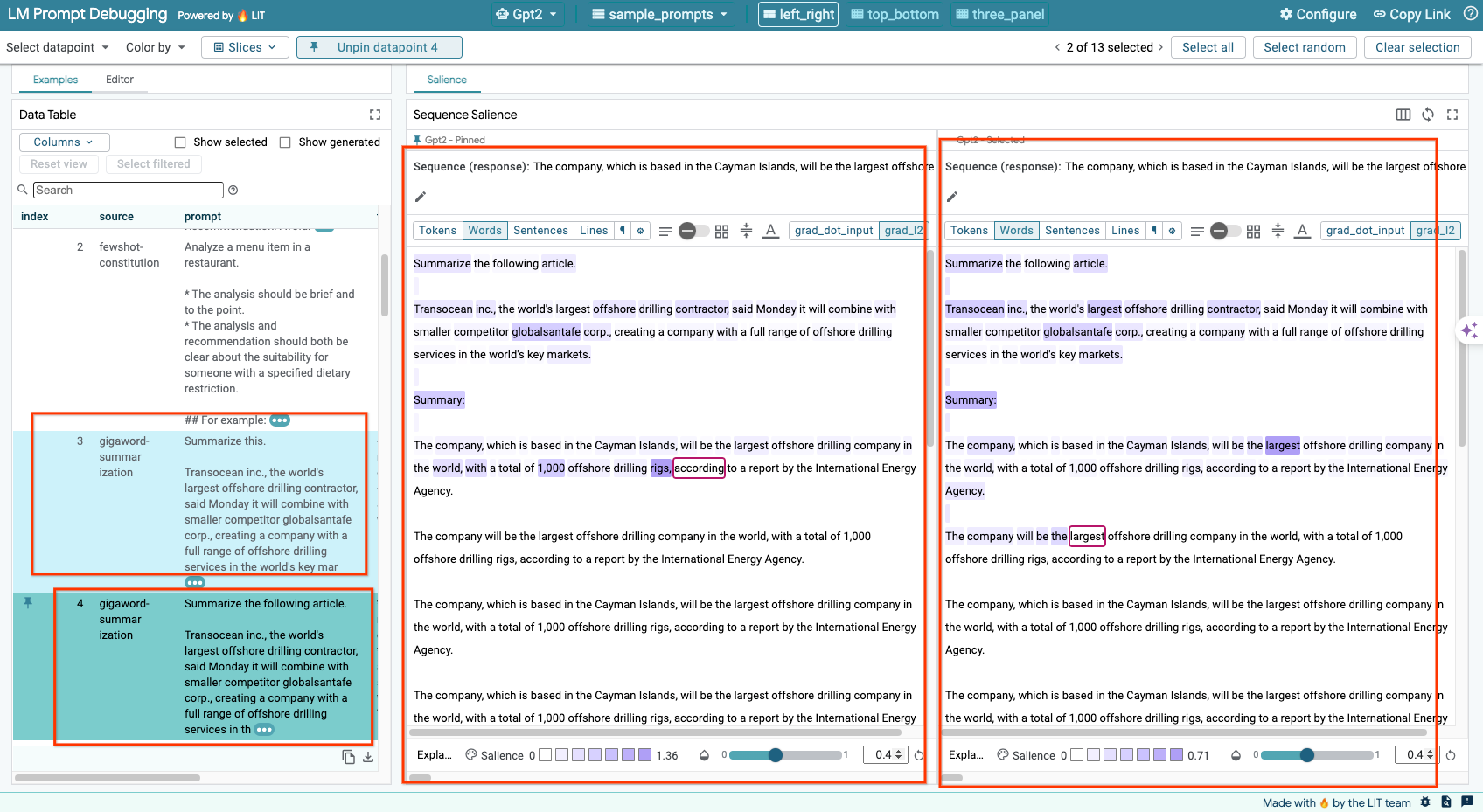
6-d: Сравните подсказки, расположенные рядом.
LIT позволяет сравнивать подсказки для исходных и отредактированных примеров. Вы можете вручную отредактировать пример и одновременно просмотреть результат прогнозирования и анализ значимости последовательности для обеих версий. Вы можете изменить подсказку для каждой точки данных, и LIT сгенерирует соответствующий ответ, запросив модель.
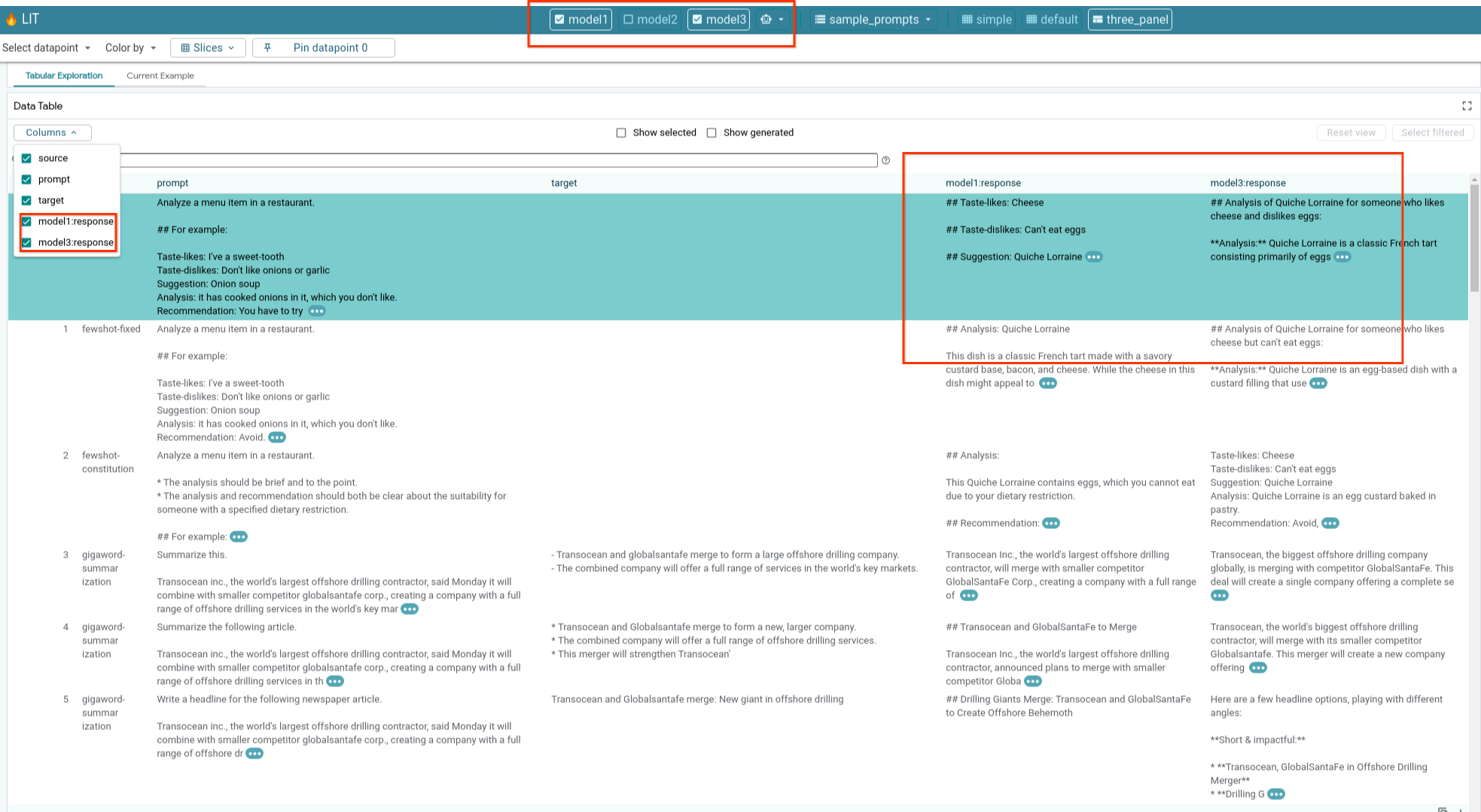
6-е: Сравните несколько моделей бок о бок.
LIT позволяет сравнивать модели параллельно на отдельных примерах генерации текста и оценки, а также на агрегированных примерах по конкретным метрикам. Запрашивая данные у различных загруженных моделей, вы можете легко сравнить различия в их ответах.
6-f: Автоматические генераторы контрфактических утверждений
Вы можете использовать автоматические генераторы контрфактических сценариев для создания альтернативных входных данных и сразу же увидеть, как ваша модель ведет себя на них.
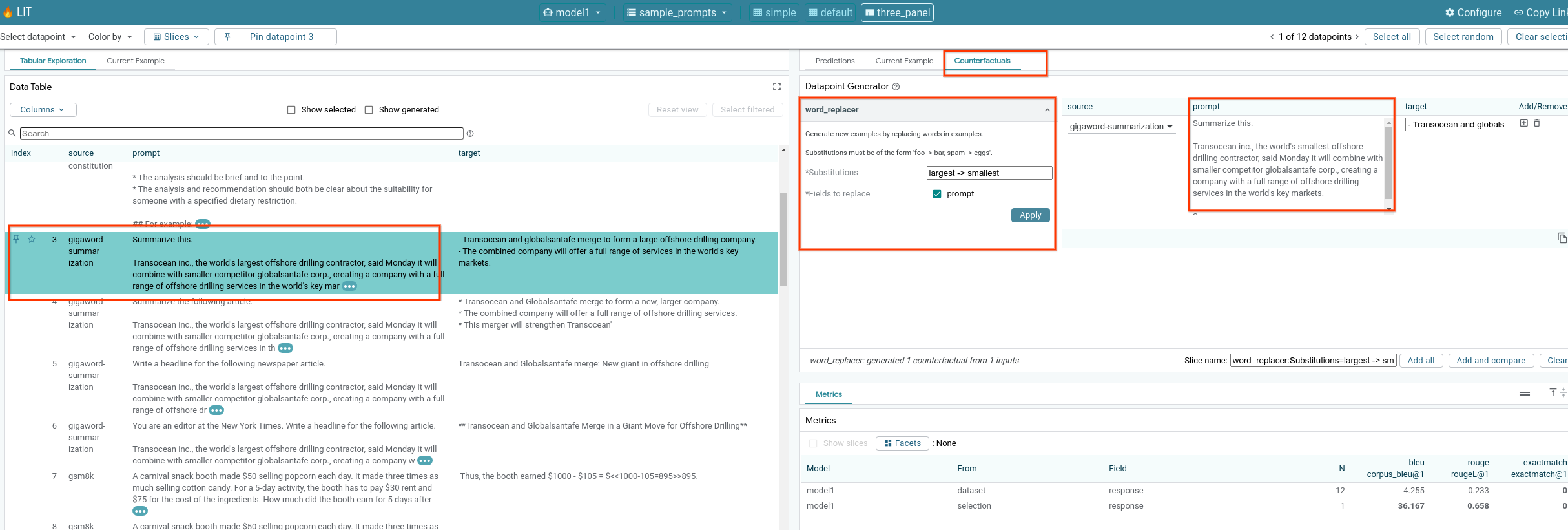
6-g: Оценка производительности модели
Оценить производительность модели можно с помощью метрик (в настоящее время поддерживаются оценки BLEU и ROUGE для генерации текста) по всему набору данных или по любым подмножествам отфильтрованных или выбранных примеров.

7. Устранение неполадок
7-а: Возможные проблемы доступа и пути их решения.
Поскольку при развертывании в Cloud Run применяется --no-allow-unauthenticated , вы можете столкнуться с ошибками доступа, как показано ниже.

Доступ к сервису LIT App возможен двумя способами.
1. Прокси для локального сервиса
Вы можете перенаправить сервис на локальный хост, используя приведенную ниже команду.
# Proxy the service to local host.
gcloud run services proxy $LIT_SERVICE_NAME
После этого вы сможете получить доступ к серверу LIT, щелкнув ссылку на прокси-сервис.
2. Прямая аутентификация пользователей
Вы можете перейти по этой ссылке для аутентификации пользователей, что обеспечит им прямой доступ к сервису LIT App. Такой подход также позволяет группе пользователей получить доступ к сервису. Для разработки, предполагающей совместную работу нескольких человек, это более эффективный вариант.
7-b: Проверки для подтверждения успешного запуска сервера моделей.
Чтобы убедиться в успешном запуске сервера моделей, вы можете напрямую отправить запрос к нему. Сервер моделей предоставляет три конечные точки: predict , tokenize и salience . Убедитесь, что вы указали в запросе как поле prompt , так и поле target .
# Query the model server predict endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/predict -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server tokenize endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/tokenize -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server salience endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/salience -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
Если у вас возникли проблемы с доступом, обратитесь к разделу 7-а выше.
8. Поздравляем!
Отлично справились с лабораторной работой! Пора отдохнуть!
Уборка
Для очистки лаборатории удалите все созданные для нее сервисы Google Cloud. Используйте Google Cloud Shell для выполнения следующих команд.
Если соединение с Google Cloud потеряно из-за бездействия, сбросьте параметры, выполнив предыдущие шаги.
# Delete the LIT App Service.
gcloud run services delete $LIT_SERVICE_NAME
Если вы запустили сервер моделей, вам также необходимо удалить сервер моделей.
# Delete the Model Service.
gcloud run services delete $MODEL_SERVICE_NAME
Дополнительная информация
Продолжите изучение возможностей инструмента LIT, используя приведенные ниже материалы:
- Джемма: Ссылка
- База открытого исходного кода LIT: репозиторий Git
- Статья в LIT: ArXiv
- Статья по отладке подсказок LIT: ArXiv
- Демонстрационный видеоролик LIT: YouTube
- Демонстрация отладки в командной строке LIT: YouTube
- Набор инструментов для ответственного создания искусственного интеллекта: ссылка
Контакт
По любым вопросам или проблемам, связанным с этим практическим заданием, пожалуйста, свяжитесь с нами через GitHub .
Лицензия
Данная работа распространяется под лицензией Creative Commons Attribution 4.0 Generic.