
1. Übersicht
In diesem Lab wird ausführlich beschrieben, wie Sie einen LIT-Anwendungsserver auf der Google Cloud Platform (GCP) bereitstellen, um mit Vertex AI Gemini Foundation Models und selbst gehosteten Large Language Models (LLMs) von Drittanbietern zu interagieren. Außerdem finden Sie dort Anleitungen zur Verwendung der LIT-Benutzeroberfläche für das Debugging von Prompts und die Modellinterpretation.
In diesem Lab lernen Sie Folgendes:
- Konfigurieren Sie einen LIT-Server auf der GCP.
- Verbinden Sie den LIT-Server mit Vertex AI Gemini-Modellen oder anderen selbst gehosteten LLMs.
- Mit der LIT-Benutzeroberfläche können Sie Prompts analysieren, debuggen und interpretieren, um die Modelleistung und Statistiken zu verbessern.
Was ist LIT?
LIT ist ein visuelles, interaktives Tool zum Analysieren von Modellen, das Text-, Bild- und Tabellendaten unterstützt. Er kann als eigenständiger Server oder in Notebook-Umgebungen wie Google Colab, Jupyter und Google Cloud Vertex AI ausgeführt werden. LIT ist über PyPI und GitHub verfügbar.
Ursprünglich wurde das Tool entwickelt, um Klassifikations- und Regressionsmodelle zu verstehen. Durch die jüngsten Updates wurden Tools zum Debuggen von LLM-Prompts hinzugefügt. So können Sie untersuchen, wie sich Nutzer-, Modell- und Systeminhalte auf das Generierungsverhalten auswirken.
Was ist Vertex AI und Model Garden?
Vertex AI ist eine Plattform für maschinelles Lernen (ML), mit der Sie ML-Modelle und KI-Anwendungen trainieren und bereitstellen können. Außerdem können Sie LLMs für Ihre KI-basierten Anwendungen anpassen. Vertex AI kombiniert Data-Engineering-, Data-Science- und ML-Engineering-Workflows, sodass Ihre Teams mit einheitlichen Tools zusammenarbeiten und Ihre Anwendungen mithilfe von Google Cloud skalieren können.
Vertex Model Garden ist eine ML-Modellbibliothek, mit der Sie Google-eigene Modelle sowie ausgewählte Modelle und Assets von Drittanbietern entdecken, testen, anpassen und bereitstellen können.
Das werden Sie tun
Sie verwenden Cloud Shell und Cloud Run, um einen Docker-Container aus dem vorgefertigten Image von LIT bereitzustellen.
Cloud Run ist eine verwaltete Computing-Plattform, mit der Sie Container direkt auf der skalierbaren Infrastruktur von Google ausführen können, einschließlich GPUs.
Dataset
In der Demo wird standardmäßig das Beispiel-Dataset für die Fehlerbehebung von LIT-Prompts verwendet. Sie können aber auch Ihr eigenes Dataset über die Benutzeroberfläche laden.
Hinweis
Für diese Referenzanleitung benötigen Sie ein Google Cloud-Projekt. Sie können ein neues Projekt erstellen oder ein vorhandenes Projekt auswählen.
2. Google Cloud Console und Cloud Shell starten
In diesem Schritt starten Sie eine Google Cloud Console und verwenden die Google Cloud Shell.
2-a: Google Cloud Console starten
Öffnen Sie einen Browser und rufen Sie die Google Cloud Console auf.
Die Google Cloud Console ist eine leistungsstarke, sichere webbasierte Administratoroberfläche, mit der Sie Ihre Google Cloud-Ressourcen schnell verwalten können. Es ist ein DevOps-Tool für unterwegs.
2b: Google Cloud Shell starten
Cloud Shell ist eine Umgebung für Online-Entwicklung und ‑Betrieb, auf die Sie mit Ihrem Browser von jedem Standort aus zugreifen können. Sie können Ihre Ressourcen mit dem Online-Terminal verwalten, auf dem Dienstprogramme wie unter anderem das gcloud-Befehlszeilentool und kubectl vorinstalliert sind. Mit dem Cloud Shell Editor können Sie außerdem cloudbasierte Anwendungen entwickeln, erstellen, debuggen und bereitstellen. Cloud Shell bietet eine für Entwickler optimierte Onlineumgebung mit einem vorinstallierten Toolset und 5 GB nichtflüchtigem Speicher. Sie verwenden die Eingabeaufforderung in den nächsten Schritten.
Starten Sie Google Cloud Shell über das Symbol rechts oben in der Menüleiste (im folgenden Screenshot blau umrandet).

Unten auf der Seite sollte ein Terminal mit einer Bash-Shell angezeigt werden.

2c: Google Cloud-Projekt festlegen
Sie müssen die Projekt-ID und die Projektregion mit dem Befehl gcloud festlegen.
# Set your GCP Project ID.
gcloud config set project your-project-id
# Set your GCP Project Region.
gcloud config set run/region your-project-region
3. LIT App Server-Docker-Image mit Cloud Run bereitstellen
3-a: LIT-App in Cloud Run bereitstellen
Sie müssen zuerst die aktuelle Version der LIT-App als die Version festlegen, die bereitgestellt werden soll.
# Set latest version as your LIT_SERVICE_TAG.
export LIT_SERVICE_TAG=latest
# List all the public LIT GCP App server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app
Nachdem Sie das Versionstag festgelegt haben, müssen Sie den Dienst benennen.
# Set your lit service name. While 'lit-app-service' is provided as a placeholder, you can customize the service name based on your preferences.
export LIT_SERVICE_NAME=lit-app-service
Danach können Sie den folgenden Befehl ausführen, um den Container in Cloud Run bereitzustellen.
# Use below cmd to deploy the LIT App to Cloud Run.
gcloud run deploy $LIT_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app:$LIT_SERVICE_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--no-allow-unauthenticated
Mit LIT können Sie das Dataset auch beim Starten des Servers hinzufügen. Legen Sie dazu die Variable DATASETS so fest, dass sie die Daten enthält, die Sie laden möchten. Verwenden Sie dazu das Format name:path, z. B. data_foo:/bar/data_2024.jsonl. Das Dataset muss im JSONL-Format vorliegen, wobei jeder Datensatz die Felder prompt und optional target und source enthält. Wenn Sie mehrere Datasets laden möchten, trennen Sie sie durch ein Komma. Wenn nicht festgelegt, wird das Beispieldataset für das Debugging von LIT-Prompts geladen.
# Set the dataset.
export DATASETS=[DATASETS]
Mit MAX_EXAMPLES können Sie die maximale Anzahl der Beispiele festlegen, die aus jedem Auswertungsset geladen werden sollen.
# Set the max examples.
export MAX_EXAMPLES=[MAX_EXAMPLES]
Im Bereitstellungsbefehl können Sie dann
--set-env-vars "DATASETS=$DATASETS" \
--set-env-vars "MAX_EXAMPLES=$MAX_EXAMPLES" \
3b: LIT App Service ansehen
Nachdem Sie den LIT App-Server erstellt haben, finden Sie den Dienst in der Cloud Console im Bereich Cloud Run.
Wählen Sie den LIT App-Dienst aus, den Sie gerade erstellt haben. Achten Sie darauf, dass der Dienstname mit LIT_SERVICE_NAME übereinstimmt.

Sie finden die Dienst-URL, indem Sie auf den gerade bereitgestellten Dienst klicken.

Anschließend sollten Sie die LIT-Benutzeroberfläche sehen können. Wenn ein Fehler auftritt, lesen Sie den Abschnitt zur Fehlerbehebung.

Im Bereich „LOGS“ (LOGS) können Sie die Aktivität überwachen, Fehlermeldungen ansehen und den Fortschritt des Deployments verfolgen.

Im Abschnitt „MESSWERTE“ können Sie sich die Messwerte des Dienstes ansehen.

3c: Datasets laden
Klicken Sie in der LIT-Benutzeroberfläche auf die Option Configure und wählen Sie Dataset aus. Laden Sie das Dataset, indem Sie einen Namen und die Dataset-URL angeben. Das Dataset muss im JSONL-Format vorliegen, wobei jeder Datensatz die Felder prompt und optional target und source enthält.
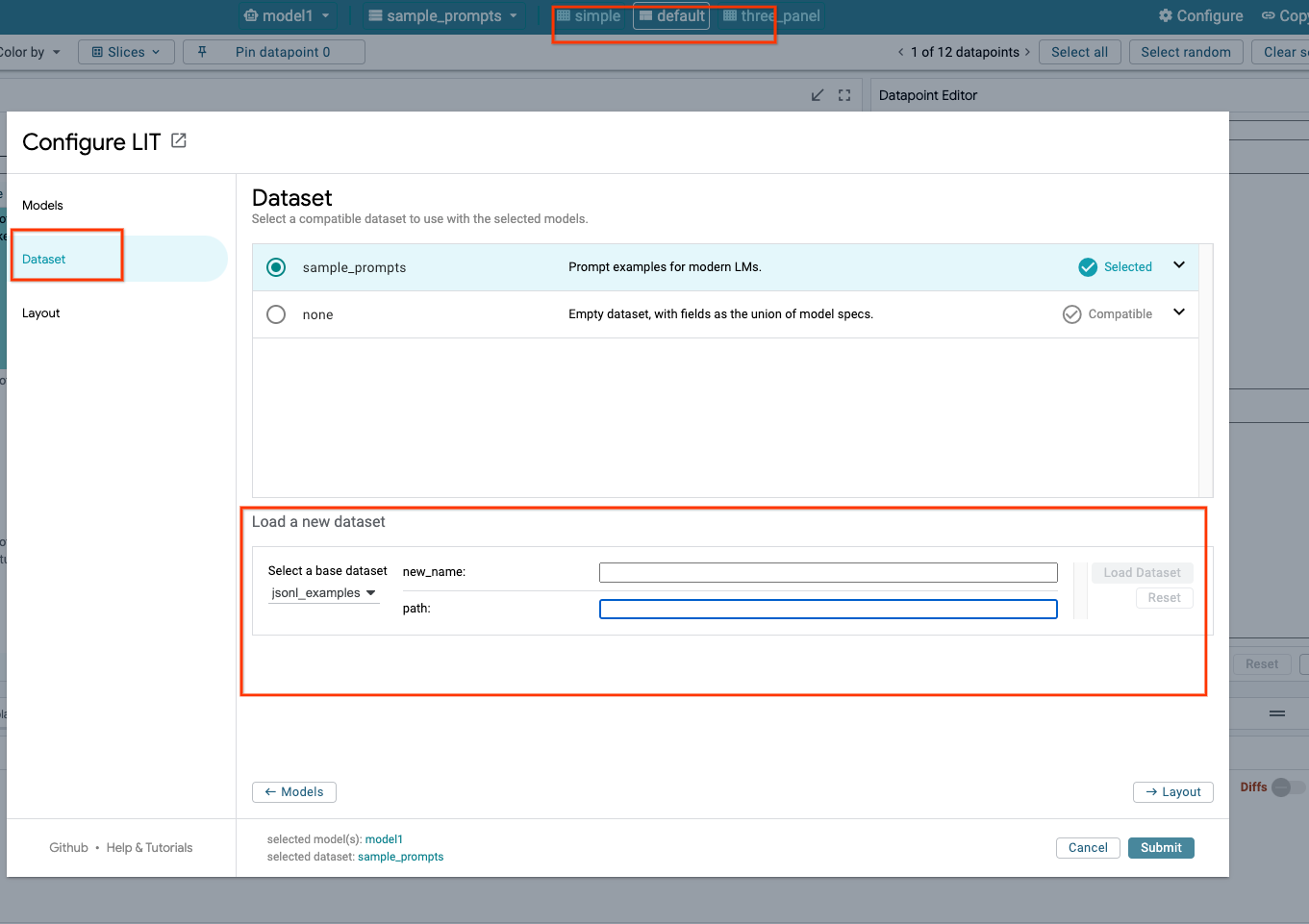
4. Gemini-Modelle in Vertex AI Model Garden vorbereiten
Die Gemini-Foundation Models von Google sind über die Vertex AI API verfügbar. LIT bietet den VertexAIModelGarden-Modell-Wrapper, mit dem diese Modelle für die Generierung verwendet werden können. Geben Sie einfach die gewünschte Version (z.B. „gemini-1.5-pro-001“) über den Parameter „model name“ an. Ein wichtiger Vorteil dieser Modelle ist, dass für die Bereitstellung kein zusätzlicher Aufwand erforderlich ist. Standardmäßig haben Sie sofortigen Zugriff auf Modelle wie Gemini 1.0 Pro und Gemini 1.5 Pro in GCP, sodass keine zusätzlichen Konfigurationsschritte erforderlich sind.
4a: Vertex AI-Berechtigungen erteilen
Wenn Sie Gemini in GCP abfragen möchten, müssen Sie dem Dienstkonto Vertex AI-Berechtigungen erteilen. Prüfen Sie, ob der Name des Dienstkontos Default compute service account lautet. Kopieren Sie die E‑Mail-Adresse des Dienstkontos.

Fügen Sie die E-Mail-Adresse des Dienstkontos als Hauptkonto mit der Rolle Vertex AI User in Ihre IAM-Zulassungsliste ein.

4b: Gemini-Modelle laden
Sie laden Gemini-Modelle und passen die Parameter an, indem Sie die folgenden Schritte ausführen.
- Klicken Sie in der LIT-Benutzeroberfläche auf die Option
Configure.
- Klicken Sie in der LIT-Benutzeroberfläche auf die Option
- Wählen Sie unter der Option
Select a base modeldie Optiongeminiaus.
- Wählen Sie unter der Option
- Sie müssen das Modell in
new_namebenennen.
- Sie müssen das Modell in
- Geben Sie die ausgewählten Gemini-Modelle als
model_nameein.
- Geben Sie die ausgewählten Gemini-Modelle als
- Klicken Sie auf
Load Model.
- Klicken Sie auf
- Klicken Sie auf
Submit.
- Klicken Sie auf

5. Selbst gehosteten LLMs-Modellserver auf der GCP bereitstellen
Wenn Sie LLMs selbst hosten und das Docker-Image des LIT-Modellservers verwenden, können Sie die Funktionen für Salienz und Tokenisierung von LIT nutzen, um das Modellverhalten besser zu verstehen. Das Modellserver-Image funktioniert mit KerasNLP- oder Hugging Face Transformers-Modellen, einschließlich bibliotheksinterner und selbst gehosteter Gewichte, z.B. in Google Cloud Storage.
5a: Modelle konfigurieren
In jedem Container wird ein Modell geladen, das mit Umgebungsvariablen konfiguriert wird.
Sie sollten die zu ladenden Modelle angeben, indem Sie MODEL_CONFIG festlegen. Das Format sollte name:path sein, z. B. model_foo:model_foo_path. Der Pfad kann eine URL, ein lokaler Dateipfad oder der Name einer Voreinstellung für das konfigurierte Deep-Learning-Framework sein (siehe Tabelle unten). Dieser Server wurde mit Gemma, GPT2, Llama und Mistral für alle unterstützten DL_FRAMEWORK-Werte getestet. Andere Modelle sollten funktionieren, es sind aber möglicherweise Anpassungen erforderlich.
# Set models you want to load. While 'gemma2b is given as a placeholder, you can load your preferred model by following the instructions above.
export MODEL_CONFIG=gemma2b:gemma_2b_en
Außerdem können Sie mit dem folgenden Befehl verschiedene Umgebungsvariablen für den LIT-Modellserver konfigurieren. Weitere Informationen finden Sie in der Tabelle. Jede Variable muss einzeln festgelegt werden.
# Customize the variable value as needed.
export [VARIABLE]=[VALUE]
Variable | Werte | Beschreibung |
DL_FRAMEWORK |
| Die Modellierungsbibliothek, die zum Laden der Modellgewichte in die angegebene Laufzeit verwendet wird. Die Standardeinstellung ist |
DL_RUNTIME |
| Das Deep-Learning-Backend-Framework, auf dem das Modell ausgeführt wird. Alle von diesem Server geladenen Modelle verwenden dasselbe Backend. Inkompatibilitäten führen zu Fehlern. Die Standardeinstellung ist |
GENAUIGKEIT |
| Gleitkomma-Genauigkeit für die LLM-Modelle. Die Standardeinstellung ist |
BATCH_SIZE | Positive Ganzzahlen | Die Anzahl der Beispiele, die pro Batch verarbeitet werden sollen. Die Standardeinstellung ist |
SEQUENCE_LENGTH | Positive Ganzzahlen | Die maximale Sequenzlänge des Eingabe-Prompts plus generiertem Text. Die Standardeinstellung ist |
5b: Modellserver in Cloud Run bereitstellen
Sie müssen zuerst die neueste Version von Model Server als die Version festlegen, die bereitgestellt werden soll.
# Set latest as MODEL_VERSION_TAG.
export MODEL_VERSION_TAG=latest
# List all the public LIT GCP model server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server
Nachdem Sie das Versionstag festgelegt haben, müssen Sie Ihrem Modellserver einen Namen geben.
# Set your Service name.
export MODEL_SERVICE_NAME='gemma2b-model-server'
Danach können Sie den folgenden Befehl ausführen, um den Container in Cloud Run bereitzustellen. Wenn Sie die Umgebungsvariablen nicht festlegen, werden Standardwerte angewendet. Da für die meisten LLMs teure Rechenressourcen erforderlich sind, wird dringend empfohlen, GPUs zu verwenden. Wenn Sie die Ausführung lieber nur auf der CPU vornehmen möchten (was für kleine Modelle wie GPT2 gut funktioniert), können Sie die entsprechenden Argumente --gpu 1 --gpu-type nvidia-l4 --max-instances 7 entfernen.
# Deploy the model service container.
gcloud beta run deploy $MODEL_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server:$MODEL_VERSION_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 7 \
--set-env-vars "MODEL_CONFIG=$MODEL_CONFIG" \
--no-allow-unauthenticated
Außerdem können Sie Umgebungsvariablen anpassen, indem Sie die folgenden Befehle hinzufügen. Fügen Sie nur die Umgebungsvariablen hinzu, die für Ihre spezifischen Anforderungen erforderlich sind.
--set-env-vars "DL_FRAMEWORK=$DL_FRAMEWORK" \
--set-env-vars "DL_RUNTIME=$DL_RUNTIME" \
--set-env-vars "PRECISION=$PRECISION" \
--set-env-vars "BATCH_SIZE=$BATCH_SIZE" \
--set-env-vars "SEQUENCE_LENGTH=$SEQUENCE_LENGTH" \
Für den Zugriff auf bestimmte Modelle sind möglicherweise zusätzliche Umgebungsvariablen erforderlich. Entsprechende Anleitungen finden Sie im Kaggle Hub (für KerasNLP-Modelle) und im Hugging Face Hub.
5c: Auf Modellserver zugreifen
Nachdem Sie den Modellserver erstellt haben, finden Sie den gestarteten Dienst im Bereich Cloud Run Ihres GCP-Projekts.
Wählen Sie den soeben erstellten Modellserver aus. Achten Sie darauf, dass der Dienstname mit MODEL_SERVICE_NAME übereinstimmt.
Sie finden die Dienst-URL, indem Sie auf den gerade bereitgestellten Modelldienst klicken.
Im Bereich „LOGS“ (LOGS) können Sie die Aktivität überwachen, Fehlermeldungen ansehen und den Fortschritt des Deployments verfolgen.
Im Abschnitt „MESSWERTE“ können Sie sich die Messwerte des Dienstes ansehen.
5d. Selbst gehostete Modelle laden
Wenn Sie Ihren LIT-Server in Schritt 3 per Proxy weiterleiten (siehe Abschnitt „Fehlerbehebung“), müssen Sie Ihr GCP-Identitätstoken mit dem folgenden Befehl abrufen.
# Find your GCP identity token.
gcloud auth print-identity-token
Sie laden selbst gehostete Modelle und passen die Parameter gemäß den folgenden Schritten an.
- Klicken Sie in der LIT-Benutzeroberfläche auf die Option
Configure. - Wählen Sie unter der Option
Select a base modeldie OptionLLM (self hosted)aus. - Sie müssen das Modell in
new_namebenennen. - Geben Sie die URL Ihres Modellservers als
base_urlein. - Geben Sie das abgerufene Identitätstoken in
identity_tokenein, wenn Sie den LIT App-Server als Proxy verwenden (siehe Schritt 3 und Schritt 7). Andernfalls lassen Sie das Feld leer. - Klicken Sie auf
Load Model. - Klicken Sie auf
Submit.

6. Mit LIT auf der GCP interagieren
LIT bietet eine Vielzahl von Funktionen, mit denen Sie das Modellverhalten debuggen und nachvollziehen können. Sie können das Modell ganz einfach abfragen, indem Sie Text in ein Feld eingeben und sich die Modellvorhersagen ansehen. Oder Sie können die Modelle mit den leistungsstarken Funktionen von LIT genauer untersuchen, z. B.:
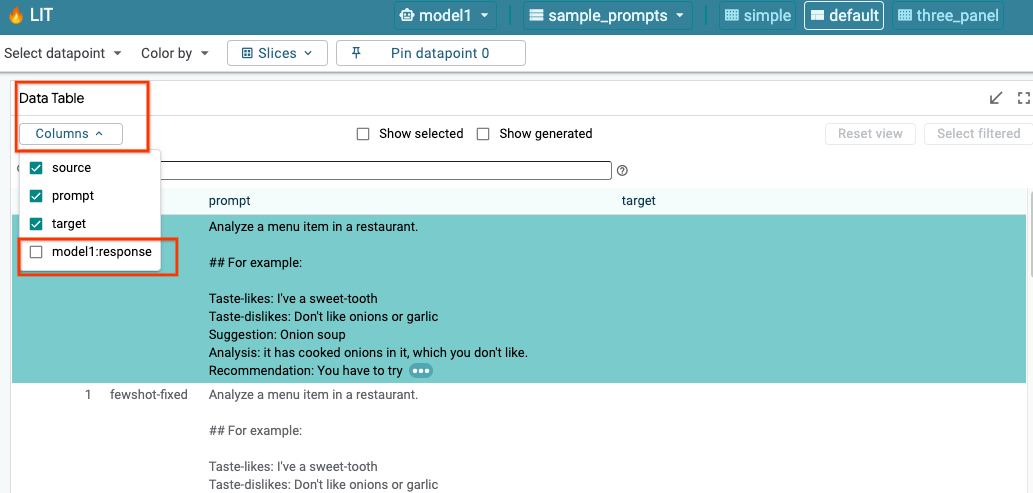
6a: Modell über LIT abfragen
LIT fragt das Dataset automatisch nach dem Laden von Modell und Dataset ab. Sie können die Antwort jedes Modells ansehen, indem Sie die Antwort in den Spalten auswählen.

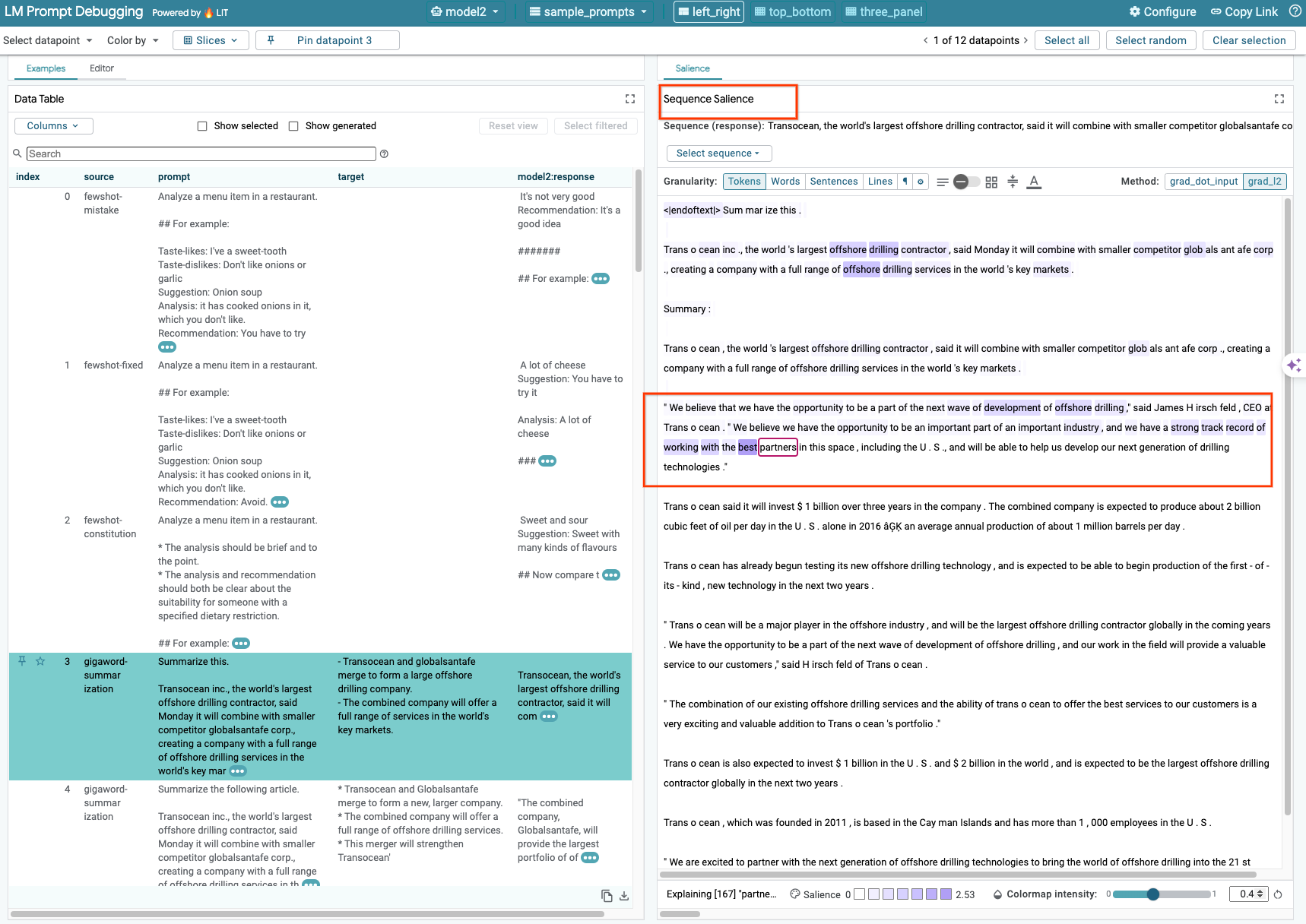
6b: Sequence Salience Technique verwenden
Derzeit werden selbst gehostete Modelle nur für die Sequence Salience-Technik in LIT unterstützt.
„Sequence Salience“ ist ein visuelles Tool, mit dem Sie LLM-Prompts debuggen können. Es hebt hervor, welche Teile eines Prompts für eine bestimmte Ausgabe am wichtigsten sind. Weitere Informationen zur Sequenzrelevanz finden Sie im vollständigen Tutorial.
Wenn Sie auf eine Eingabe oder Ausgabe im Prompt oder in der Antwort klicken, werden die Ergebnisse zur Auffälligkeit angezeigt.
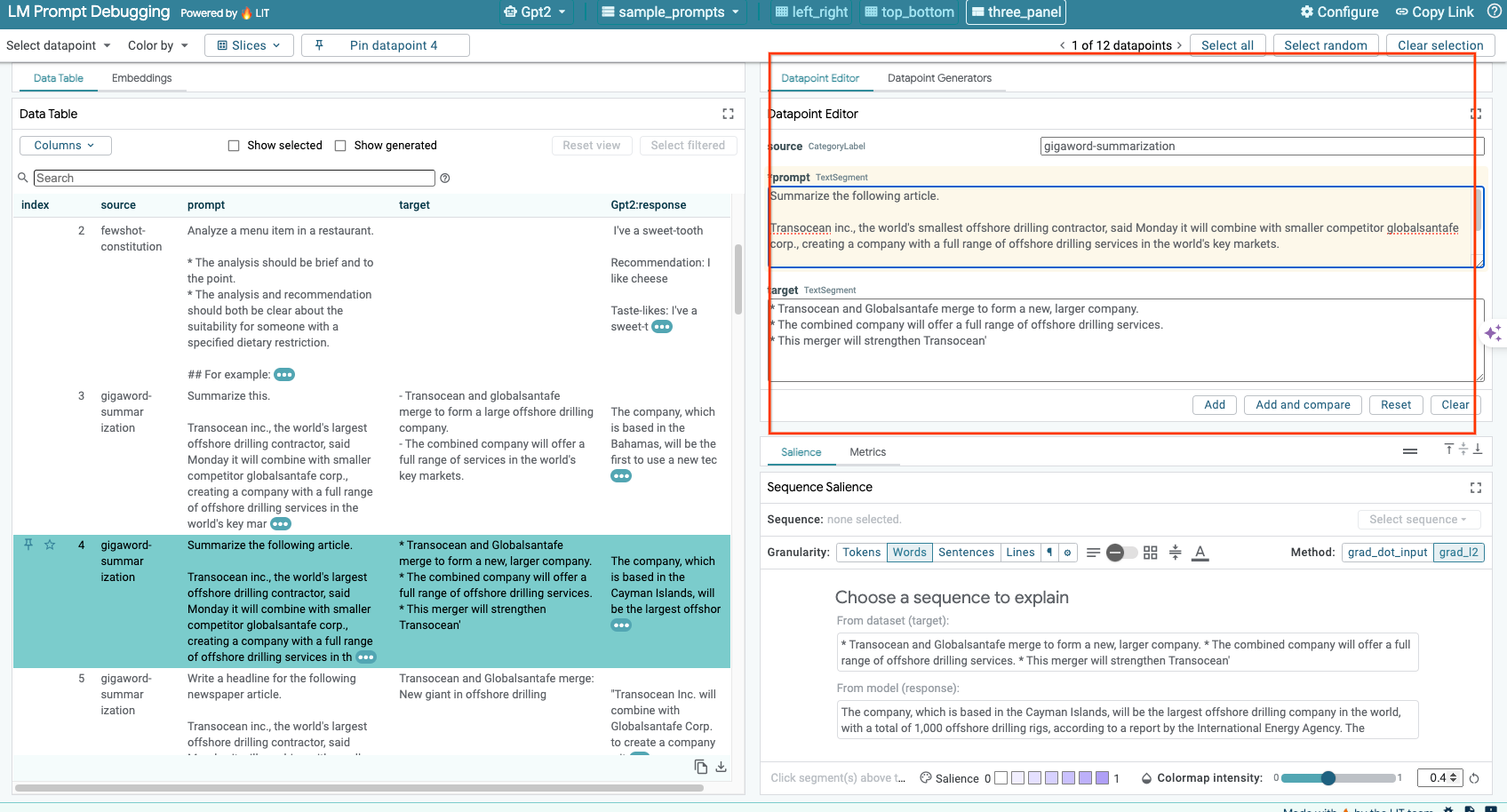
6c: Prompt und Ziel manuell bearbeiten
Mit LIT können Sie alle prompt und target für vorhandene Datenpunkte manuell bearbeiten. Wenn Sie auf Add klicken, wird die neue Eingabe dem Dataset hinzugefügt.
6d: Prompts nebeneinander vergleichen
Mit LIT können Sie Prompts anhand von Original- und bearbeiteten Beispielen nebeneinander vergleichen. Sie können ein Beispiel manuell bearbeiten und sich gleichzeitig das Vorhersageergebnis und die Analyse der Sequenzrelevanz für die Original- und die bearbeitete Version ansehen. Sie können den Prompt für jeden Datenpunkt ändern. LIT generiert dann die entsprechende Antwort, indem das Modell abgefragt wird.

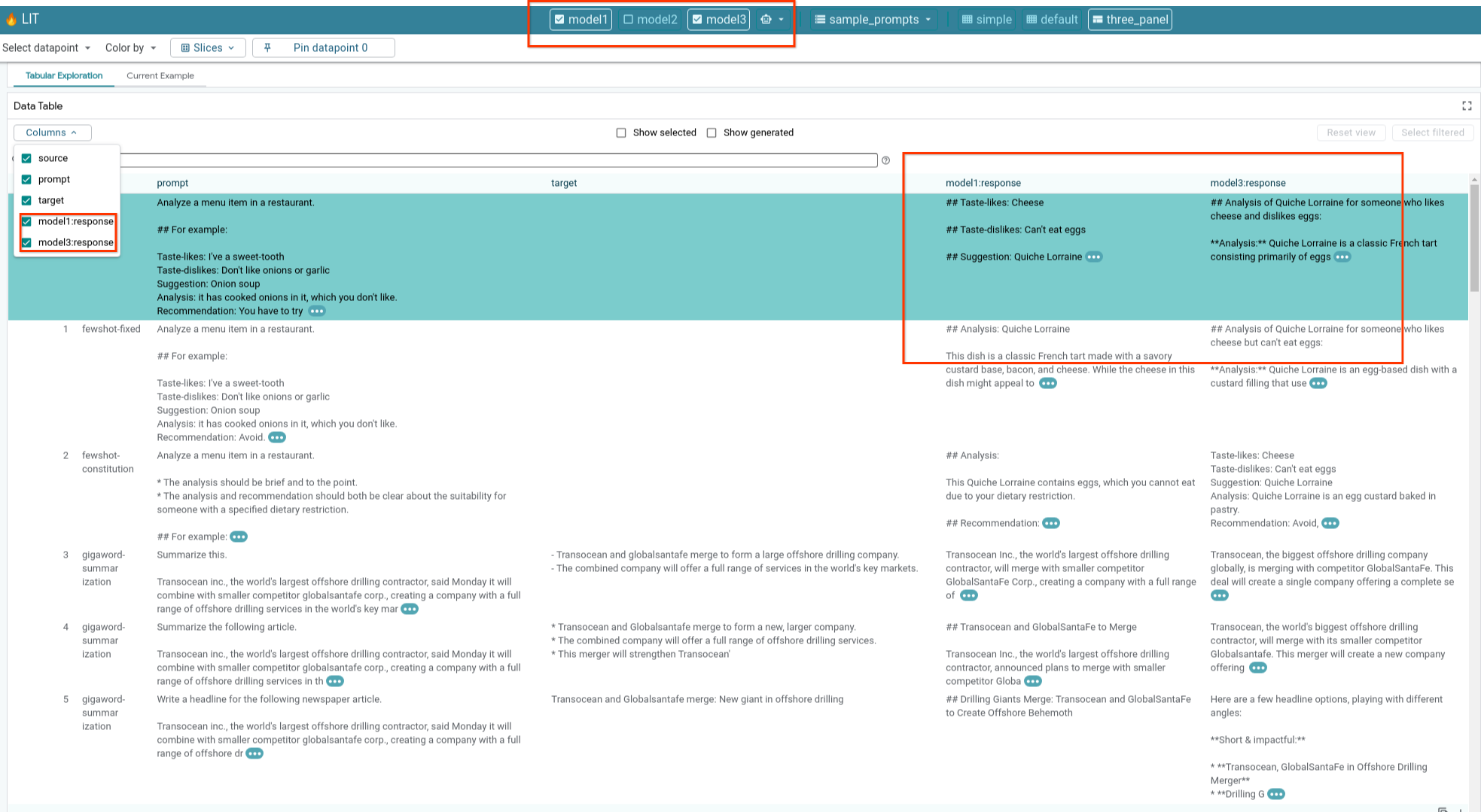
6e: Mehrere Modelle nebeneinander vergleichen
Mit LIT können Modelle anhand einzelner Beispiele für die Textgenerierung und ‑bewertung sowie anhand aggregierter Beispiele für bestimmte Messwerte nebeneinander verglichen werden. Wenn Sie verschiedene geladene Modelle abfragen, können Sie die Unterschiede in ihren Antworten ganz einfach vergleichen.
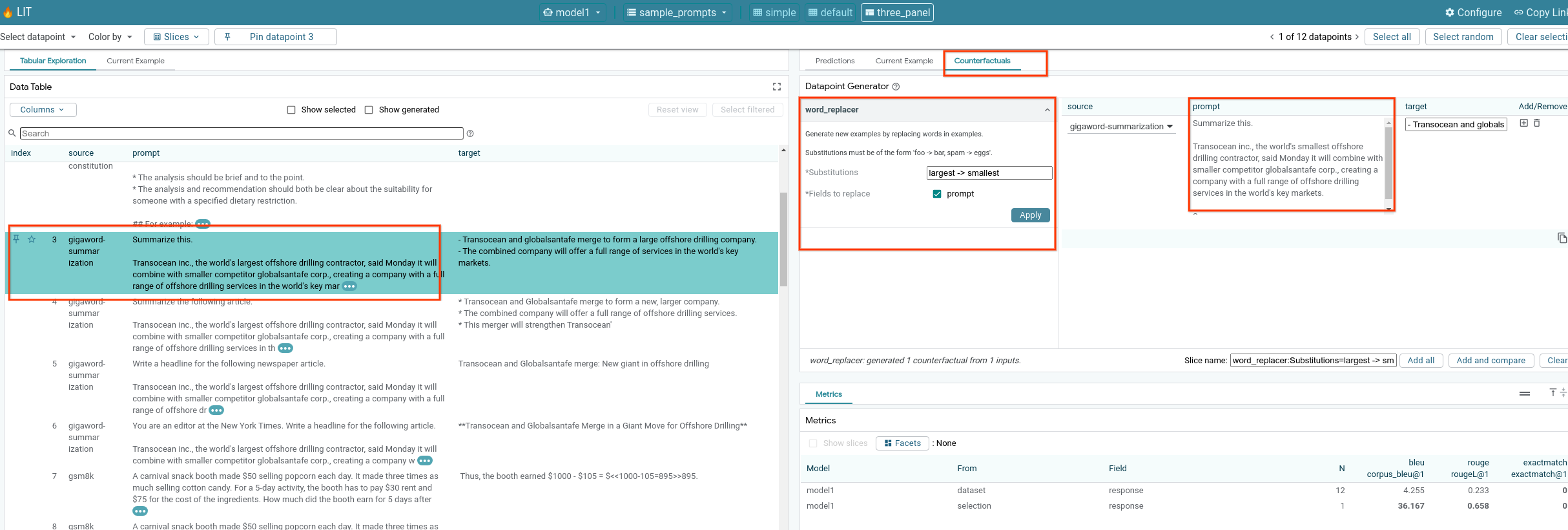
6‑f: Automatische kontrafaktische Generatoren
Mit automatischen kontrafaktischen Generatoren können Sie alternative Eingaben erstellen und sofort sehen, wie sich Ihr Modell daraufhin verhält.
6-g: Modellleistung bewerten
Sie können die Modellleistung anhand von Messwerten (derzeit werden BLEU- und ROUGE-Werte für die Textgenerierung unterstützt) für das gesamte Dataset oder für beliebige Teilmengen gefilterter oder ausgewählter Beispiele bewerten.

7. Fehlerbehebung
7-a: Mögliche Zugriffsprobleme und Lösungen
Da --no-allow-unauthenticated bei der Bereitstellung in Cloud Run angewendet wird, können verbotene Fehler wie unten gezeigt auftreten.

Es gibt zwei Möglichkeiten, auf den LIT App-Dienst zuzugreifen.
1. Proxy für lokalen Dienst
Mit dem folgenden Befehl können Sie den Dienst an den lokalen Host weiterleiten.
# Proxy the service to local host.
gcloud run services proxy $LIT_SERVICE_NAME
Anschließend sollten Sie auf den LIT-Server zugreifen können, indem Sie auf den Link des Proxy-Dienstes klicken.
2. Nutzer direkt authentifizieren
Über diesen Link können Sie Nutzer authentifizieren und so den direkten Zugriff auf den LIT App-Dienst ermöglichen. Mit diesem Ansatz kann auch einer Gruppe von Nutzern der Zugriff auf den Dienst ermöglicht werden. Für die Entwicklung in Zusammenarbeit mit mehreren Personen ist dies eine effektivere Option.
7-b: Prüfen, ob der Modellserver erfolgreich gestartet wurde
Um zu prüfen, ob der Modellserver erfolgreich gestartet wurde, können Sie ihn direkt abfragen, indem Sie eine Anfrage senden. Der Modellserver bietet drei Endpunkte: predict, tokenize und salience. Achten Sie darauf, dass Sie in Ihrer Anfrage sowohl das Feld prompt als auch die Felder target angeben.
# Query the model server predict endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/predict -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server tokenize endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/tokenize -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server salience endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/salience -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
Wenn Sie Probleme beim Zugriff haben, lesen Sie den Abschnitt 7a oben.
8. Glückwunsch
Glückwunsch! Sie haben das Codelab abgeschlossen. Zeit zum Chillen!
Bereinigen
Wenn Sie das Lab bereinigen möchten, löschen Sie alle für das Lab erstellten Google Cloud-Dienste. Verwenden Sie Google Cloud Shell, um die folgenden Befehle auszuführen.
Wenn die Google Cloud-Verbindung aufgrund von Inaktivität verloren geht, setzen Sie die Variablen gemäß den vorherigen Schritten zurück.
# Delete the LIT App Service.
gcloud run services delete $LIT_SERVICE_NAME
Wenn Sie den Modellserver gestartet haben, müssen Sie ihn auch löschen.
# Delete the Model Service.
gcloud run services delete $MODEL_SERVICE_NAME
Weitere Informationen
Mit den folgenden Materialien können Sie mehr über die Funktionen des LIT-Tools erfahren:
- Gemma: Link
- LIT-Open-Source-Codebasis: Git-Repository
- LIT-Dokument: ArXiv
- LIT-Prompt-Debugging-Dokument: ArXiv
- LIT-Funktionsvideo: YouTube
- Demo zum Debuggen von LIT-Prompts: YouTube
- Responsible GenAI Toolkit: Link
Kontakt
Bei Fragen oder Problemen mit diesem Codelab wenden Sie sich bitte an uns auf GitHub.
Lizenz
Dieses Werk ist mit einer Creative Commons Attribution 4.0 Generic License lizenziert.