
1. סקירה כללית
בשיעור ה-Lab הזה תקבלו הסבר מפורט על פריסת שרת אפליקציות של LIT ב-Google Cloud Platform (GCP) כדי ליצור אינטראקציה עם מודלים בסיסיים של Vertex AI Gemini ומודלים גדולים של שפה (LLM) של צד שלישי שמתארחים באופן עצמאי. בנוסף, יש בו הנחיות לשימוש בממשק המשתמש של LIT לניפוי באגים בהנחיות ולפרשנות של מודלים.
בשיעור ה-Lab הזה תלמדו איך:
- הגדרת שרת LIT ב-GCP.
- חיבור שרת LIT למודלים של Vertex AI Gemini או למודלים אחרים של LLM שמתארחים באופן עצמאי.
- אפשר להשתמש בממשק המשתמש של LIT כדי לנתח הנחיות, לנפות באגים בהנחיות ולפרש אותן, וכך לשפר את הביצועים של המודל ולקבל תובנות.
מה זה LIT?
LIT הוא כלי ויזואלי ואינטראקטיבי להבנת מודלים, שתומך בטקסט, בתמונות ובנתונים בטבלאות. אפשר להריץ אותו כשרת עצמאי, או בתוך סביבות notebook כמו Google Colab, Jupyter ו-Google Cloud Vertex AI. LIT זמין ב-PyPI וב-GitHub.
הכלי הזה נוצר במקור כדי להבין מודלים של סיווג ורגרסיה, אבל בעדכונים האחרונים הוספנו לו כלים לניפוי באגים בהנחיות של LLM. כך תוכלו לבדוק איך תוכן של משתמשים, מודלים ומערכות משפיע על התנהגות היצירה.
מה זה Vertex AI ו-Model Garden?
Vertex AI היא פלטפורמה ללמידת מכונה (ML) שמאפשרת לאמן ולפרוס מודלים של למידת מכונה ואפליקציות מבוססות-AI, ולהתאים אישית מודלים גדולים של שפה (LLM) לשימוש באפליקציות מבוססות-AI. Vertex AI משלב בין הנדסת נתונים, מדעי הנתונים ותהליכי עבודה של הנדסת ML, ומאפשר לצוותים שלכם לשתף פעולה באמצעות ערכת כלים משותפת ולהרחיב את האפליקציות שלכם תוך ניצול היתרונות של Google Cloud.
Vertex Model Garden היא ספרייה של מודלים למידת מכונה (ML) שעוזרת לכם לגלות, לבדוק, להתאים אישית ולפרוס מודלים ונכסים קנייניים של Google ומודלים ונכסים נבחרים של צד שלישי.
מה תעשו
תשתמשו ב-Cloud Shell וב-Cloud Run של Google כדי לפרוס קונטיינר Docker מקובץ אימג' מוכן מראש של LIT.
Cloud Run היא פלטפורמת מחשוב מנוהלת שמאפשרת להריץ קונטיינרים ישירות על גבי התשתית הניתנת להתאמה של Google, כולל מעבדי GPU.
מערך נתונים
כברירת מחדל, ההדגמה משתמשת במערך הנתונים לדוגמה של LIT prompt debugging, אבל אפשר לטעון נתונים משלכם דרך ממשק המשתמש.
לפני שמתחילים
כדי להשתמש במדריך הזה, צריך פרויקט בענן ב-Google Cloud. אפשר ליצור פרויקט חדש או לבחור פרויקט שכבר יצרתם.
2. הפעלת מסוף Google Cloud ו-Cloud Shell
בשלב הזה תפעילו את מסוף Google Cloud ותשתמשו ב-Google Cloud Shell.
2-א: הפעלת מסוף Google Cloud
מפעילים דפדפן ועוברים אל מסוף Google Cloud.
מסוף Google Cloud הוא ממשק ניהול אינטרנטי מאובטח ורב-עוצמה, שמאפשר לכם לנהל את המשאבים של Google Cloud במהירות. זהו כלי DevOps שזמין בכל מקום.
2-ב: הפעלת Google Cloud Shell
Cloud Shell היא סביבת פיתוח ותפעול אונליין שאפשר לגשת אליה מכל מקום באמצעות הדפדפן. אתם יכולים לנהל את המשאבים שלכם באמצעות מסוף אונליין שנטענו בו מראש כלי עזר כמו כלי שורת הפקודה של Google Cloud (gcloud), kubectl ועוד. אפשר גם לפתח, לבנות, לנפות באגים ולפרוס את אפליקציות ה-APP מבוססות הענן באמצעות Cloud Shell Editor אונליין. Cloud Shell מספק סביבה אונליין שמוכנה למפתחים, עם סט כלים מועדף שהותקן מראש ו-5GB של שטח אחסון מתמיד. בשלבים הבאים תשתמשו בשורת הפקודה.
מפעילים את Google Cloud Shell באמצעות הסמל בפינה השמאלית העליונה של סרגל התפריטים, שמסומן בעיגול כחול בצילום המסך הבא.

בתחתית הדף אמור להופיע מסוף עם מעטפת Bash.

2-ג: הגדרת פרויקט Google Cloud
צריך להגדיר את מזהה הפרויקט ואת האזור של הפרויקט באמצעות הפקודה gcloud.
# Set your GCP Project ID.
gcloud config set project your-project-id
# Set your GCP Project Region.
gcloud config set run/region your-project-region
3. פריסת קובץ האימג' של שרת האפליקציה LIT ב-Docker באמצעות Cloud Run
3-א: פריסת אפליקציית LIT ב-Cloud Run
קודם צריך להגדיר את הגרסה העדכנית של LIT-App כגרסה לפריסה.
# Set latest version as your LIT_SERVICE_TAG.
export LIT_SERVICE_TAG=latest
# List all the public LIT GCP App server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app
אחרי שמגדירים את תג הגרסה, צריך לתת שם לשירות.
# Set your lit service name. While 'lit-app-service' is provided as a placeholder, you can customize the service name based on your preferences.
export LIT_SERVICE_NAME=lit-app-service
אחרי זה, אפשר להריץ את הפקודה הבאה כדי לפרוס את הקונטיינר ב-Cloud Run.
# Use below cmd to deploy the LIT App to Cloud Run.
gcloud run deploy $LIT_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app:$LIT_SERVICE_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--no-allow-unauthenticated
בנוסף, אפשר להוסיף את מערך הנתונים כשמפעילים את השרת. כדי לעשות את זה, מגדירים את המשתנה DATASETS כך שיכלול את הנתונים שרוצים לטעון, באמצעות הפורמט name:path, לדוגמה, data_foo:/bar/data_2024.jsonl. פורמט מערך הנתונים צריך להיות .jsonl, שבו כל רשומה מכילה את השדה prompt ושדות אופציונליים target ו-source. כדי לטעון כמה מערכי נתונים, מפרידים ביניהם באמצעות פסיק. אם לא מגדירים מערך נתונים, מערך הנתונים לדוגמה של LIT לניפוי באגים בהנחיות ייטען.
# Set the dataset.
export DATASETS=[DATASETS]
ההגדרה MAX_EXAMPLES מאפשרת להגדיר את המספר המקסימלי של דוגמאות לטעינה מכל קבוצת הערכה.
# Set the max examples.
export MAX_EXAMPLES=[MAX_EXAMPLES]
אחר כך, בפקודת הפריסה, אפשר להוסיף
--set-env-vars "DATASETS=$DATASETS" \
--set-env-vars "MAX_EXAMPLES=$MAX_EXAMPLES" \
3-ב: הצגת שירות האפליקציות של LIT
אחרי שיוצרים את שרת אפליקציית ה-LIT, אפשר למצוא את השירות בקטע Cloud Run ב-Cloud Console.
בוחרים את שירות אפליקציית LIT שיצרתם. מוודאים ששם השירות זהה ל-LIT_SERVICE_NAME.

כדי למצוא את כתובת ה-URL של השירות, לוחצים על השירות שזה עתה פרסתם.

אחרי זה תוכלו לראות את ממשק המשתמש של LIT. אם נתקלתם בשגיאה, כדאי לעיין בקטע 'פתרון בעיות'.

אפשר לבדוק את הקטע 'יומנים' כדי לעקוב אחרי הפעילות, לראות הודעות שגיאה ולעקוב אחרי התקדמות הפריסה.

אפשר לבדוק את הקטע METRICS כדי לראות את המדדים של השירות.

3-c: טעינת קבוצות נתונים
לוחצים על האפשרות Configure בממשק המשתמש של LIT ובוחרים באפשרות Dataset. טוענים את מערך הנתונים על ידי ציון שם וכתובת URL של מערך הנתונים. פורמט מערך הנתונים צריך להיות .jsonl, שבו כל רשומה מכילה את השדה prompt ושדות אופציונליים target ו-source.

4. הכנת מודלים של Gemini ב-Vertex AI Model Garden
מודלים בסיסיים של Gemini מבית Google זמינים דרך Vertex AI API. LIT מספקת את VertexAIModelGarden model wrapper כדי להשתמש במודלים האלה ליצירה. פשוט מציינים את הגרסה הרצויה (למשל, gemini-1.5-pro-001) באמצעות פרמטר שם המודל. יתרון מרכזי בשימוש במודלים האלה הוא שלא נדרש מאמץ נוסף כדי להטמיע אותם. כברירת מחדל, יש לכם גישה מיידית למודלים כמו Gemini 1.0 Pro ו-Gemini 1.5 Pro ב-GCP, כך שאין צורך לבצע שלבי הגדרה נוספים.
4-א: מתן הרשאות ל-Vertex AI
כדי לשלוח שאילתות ל-Gemini ב-GCP, צריך להעניק הרשאות ל-Vertex AI לחשבון השירות. מוודאים שהשם של חשבון השירות הוא Default compute service account. מעתיקים את כתובת האימייל של חשבון השירות.
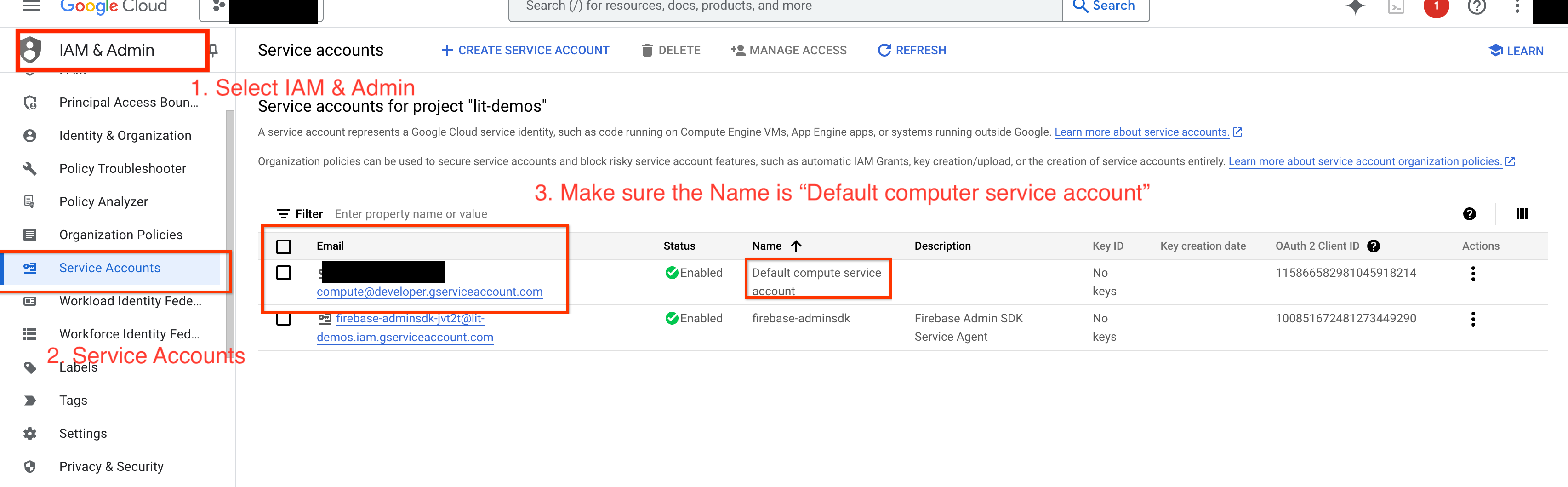
מוסיפים את כתובת האימייל של חשבון השירות כחשבון משתמש עם התפקיד Vertex AI User ברשימת ההיתרים של IAM.

4-ב: טעינת המודלים של Gemini
תטעינו מודלים של Gemini ותשנו את הפרמטרים שלהם לפי השלבים הבאים.
- לוחצים על האפשרות
Configureבממשק המשתמש של LIT.
- לוחצים על האפשרות
- בוחרים באפשרות
geminiבאפשרותSelect a base model.
- בוחרים באפשרות
- צריך לתת שם למודל ב-
new_name.
- צריך לתת שם למודל ב-
- מזינים את המודלים של Gemini שנבחרו בתור
model_name.
- מזינים את המודלים של Gemini שנבחרו בתור
- לוחצים על
Load Model.
- לוחצים על
- לוחצים על
Submit.
- לוחצים על

5. פריסת שרת מודלים של LLM באירוח עצמי ב-GCP
אירוח עצמי של מודלים גדולים של שפה (LLM) באמצעות תמונת Docker של שרת המודלים של LIT מאפשר לכם להשתמש בפונקציות של LIT לזיהוי מאפיינים בולטים וליצירת טוקנים כדי לקבל תובנות מעמיקות יותר לגבי התנהגות המודל. קובץ האימג' של שרת המודל פועל עם מודלים של KerasNLP או Hugging Face Transformers, כולל משקלים שסופקו על ידי הספריות ומשקלים באירוח עצמי, למשל ב-Google Cloud Storage.
5א: הגדרת מודלים
כל מאגר טוען מודל אחד, שמוגדר באמצעות משתני סביבה.
כדי לציין אילו מודלים לטעון, צריך להגדיר את MODEL_CONFIG. הפורמט צריך להיות name:path, למשל model_foo:model_foo_path. הנתיב יכול להיות כתובת URL, נתיב של קובץ מקומי או שם של הגדרה קבועה מראש למסגרת למידה עמוקה שהוגדרה (מידע נוסף מופיע בטבלה הבאה). השרת הזה נבדק עם Gemma, GPT2, Llama ו-Mistral בכל הערכים הנתמכים של DL_FRAMEWORK. מודלים אחרים אמורים לעבוד, אבל יכול להיות שיהיה צורך לבצע התאמות.
# Set models you want to load. While 'gemma2b is given as a placeholder, you can load your preferred model by following the instructions above.
export MODEL_CONFIG=gemma2b:gemma_2b_en
בנוסף, שרת המודלים של LIT מאפשר להגדיר משתני סביבה שונים באמצעות הפקודה שלמטה. הפרטים מופיעים בטבלה הבאה. חשוב לזכור שצריך להגדיר כל משתנה בנפרד.
# Customize the variable value as needed.
export [VARIABLE]=[VALUE]
משתנה | ערכים | תיאור |
DL_FRAMEWORK |
| ספריית המודלים שמשמשת לטעינת משקלי המודל בסביבת זמן הריצה שצוינה. ברירת המחדל היא |
DL_RUNTIME |
| מסגרת ה-Backend של למידה עמוקה שהמודל פועל עליה. כל המודלים שנטענו על ידי השרת הזה ישתמשו באותו קצה עורפי, ואי-תאימות תוביל לשגיאות. ברירת המחדל היא |
PRECISION |
| רמת הדיוק של נקודה צפה (floating-point) במודלים של LLM. ברירת המחדל היא |
BATCH_SIZE | מספרים שלמים חיוביים | מספר הדוגמאות לעיבוד בכל אצווה. ברירת המחדל היא |
SEQUENCE_LENGTH | מספרים שלמים חיוביים | האורך המקסימלי של רצף התווים בהנחיה ובטקסט שנוצר. ברירת המחדל היא |
5-ב: פריסת שרת מודלים ב-Cloud Run
קודם צריך להגדיר את הגרסה העדכנית של Model Server כגרסה שרוצים לפרוס.
# Set latest as MODEL_VERSION_TAG.
export MODEL_VERSION_TAG=latest
# List all the public LIT GCP model server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server
אחרי שמגדירים את תג הגרסה, צריך לתת שם לשרת המודלים.
# Set your Service name.
export MODEL_SERVICE_NAME='gemma2b-model-server'
אחרי זה, אפשר להריץ את הפקודה הבאה כדי לפרוס את הקונטיינר ב-Cloud Run. אם לא מגדירים את משתני הסביבה, המערכת תחיל ערכי ברירת מחדל. רוב מודלי ה-LLM דורשים משאבי מחשוב יקרים, ולכן מומלץ מאוד להשתמש ב-GPU. אם אתם מעדיפים להריץ רק על CPU (שזה בסדר גמור למודלים קטנים כמו GPT2), אתם יכולים להסיר את הארגומנטים שקשורים לכך --gpu 1 --gpu-type nvidia-l4 --max-instances 7.
# Deploy the model service container.
gcloud beta run deploy $MODEL_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server:$MODEL_VERSION_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 7 \
--set-env-vars "MODEL_CONFIG=$MODEL_CONFIG" \
--no-allow-unauthenticated
בנוסף, אתם יכולים להתאים אישית את משתני הסביבה על ידי הוספת הפקודות הבאות. כדאי לכלול רק את משתני הסביבה שדרושים לצרכים הספציפיים שלכם.
--set-env-vars "DL_FRAMEWORK=$DL_FRAMEWORK" \
--set-env-vars "DL_RUNTIME=$DL_RUNTIME" \
--set-env-vars "PRECISION=$PRECISION" \
--set-env-vars "BATCH_SIZE=$BATCH_SIZE" \
--set-env-vars "SEQUENCE_LENGTH=$SEQUENCE_LENGTH" \
יכול להיות שיהיה צורך במשתני סביבה נוספים כדי לגשת למודלים מסוימים. אפשר לעיין בהוראות מ-Kaggle Hub (לשימוש בתבניות KerasNLP) ומ-Hugging Face Hub לפי הצורך.
5-ג': גישה לשרת המודל
אחרי שיוצרים את שרת המודל, אפשר למצוא את השירות שהופעל בקטע Cloud Run בפרויקט GCP.
בוחרים את שרת המודל שיצרתם. מוודאים ששם השירות זהה ל-MODEL_SERVICE_NAME.
כדי למצוא את כתובת ה-URL של השירות, לוחצים על שירות המודל שפרסתם.
אפשר לבדוק את הקטע 'יומנים' כדי לעקוב אחרי הפעילות, לראות הודעות שגיאה ולעקוב אחרי התקדמות הפריסה.
אפשר לבדוק את הקטע METRICS כדי לראות את המדדים של השירות.
5-ד: טעינת מודלים שמתארחים באופן עצמאי
אם אתם משתמשים בשרת LIT כפרוקסי בשלב 3 (ראו את הקטע 'פתרון בעיות'), תצטרכו להריץ את הפקודה הבאה כדי לקבל את אסימון הזהות שלכם ב-GCP.
# Find your GCP identity token.
gcloud auth print-identity-token
תצטרכו לטעון מודלים באירוח עצמי ולשנות את הפרמטרים שלהם לפי השלבים הבאים.
- לוחצים על האפשרות
Configureבממשק המשתמש של LIT. - בוחרים באפשרות
LLM (self hosted)באפשרותSelect a base model. - צריך לתת שם למודל ב-
new_name. - מזינים את כתובת ה-URL של שרת המודל בתור
base_url. - אם אתם משתמשים ב-proxy לשרת של אפליקציית LIT, מזינים את טוקן הזהות שהתקבל ב-
identity_token(ראו שלב 3 ושלב 7). אחרת, משאירים את השדה ריק. - לוחצים על
Load Model. - לוחצים על
Submit.

6. אינטראקציה עם LIT ב-GCP
LIT מציע מגוון רחב של תכונות שיעזרו לכם לנפות באגים בהתנהגויות של מודלים ולהבין אותן. אתם יכולים לבצע פעולה פשוטה כמו שאילתת המודל, על ידי הקלדת טקסט בתיבה וצפייה בתחזיות של המודל, או לבדוק את המודלים לעומק באמצעות חבילת התכונות העוצמתיות של LIT, כולל:
6א: שליחת שאילתה למודל באמצעות LIT
אחרי טעינת המודל ומערך הנתונים, LIT יוצר שאילתה אוטומטית במערך הנתונים. כדי לראות את התשובה של כל מודל, בוחרים את התשובה בעמודות.

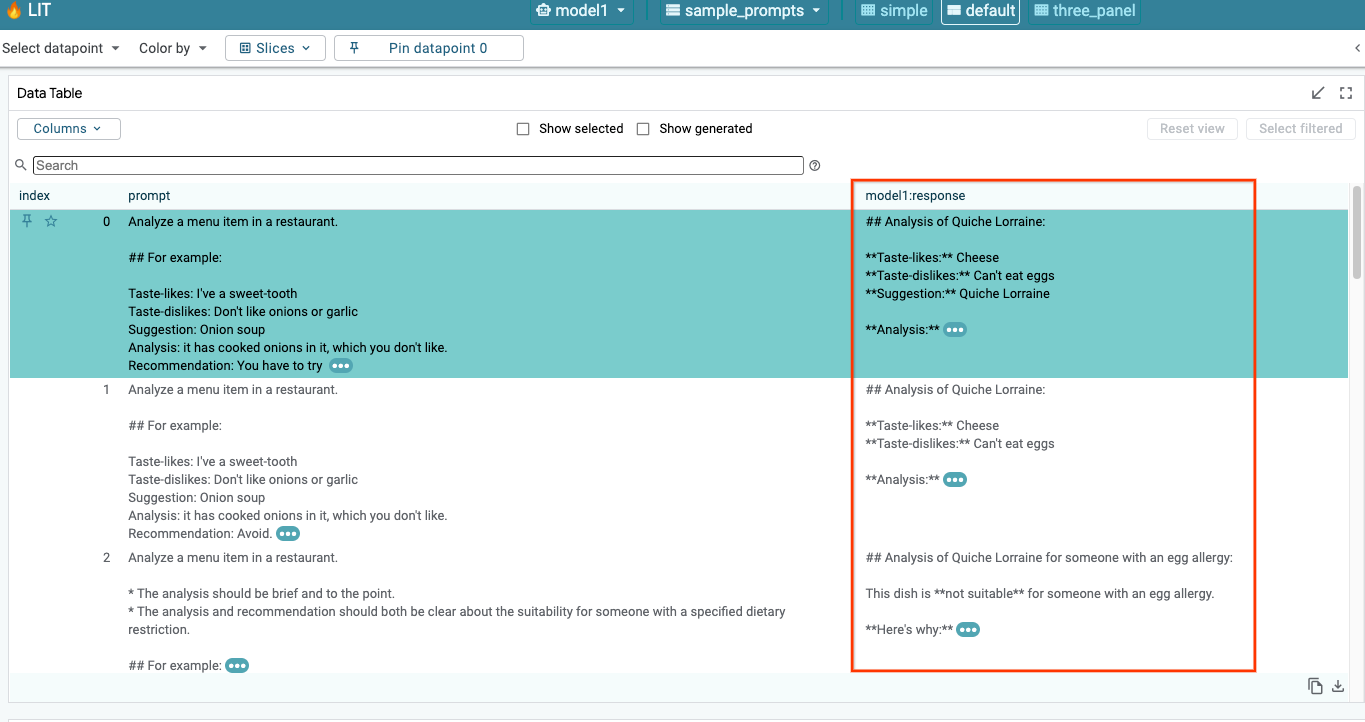
6-ב: שימוש בטכניקת בולטות הרצף
נכון לעכשיו, טכניקת Sequence Salience ב-LIT תומכת רק במודלים שמתארחים באופן עצמאי.
הכלי 'בולטות רצף' הוא כלי ויזואלי שעוזר לנפות באגים בהנחיות ל-LLM. הוא מדגיש אילו חלקים בהנחיה חשובים ביותר לפלט מסוים. למידע נוסף על חשיבות הרצף, אפשר לעיין במדריך המלא.
כדי לגשת לתוצאות של מידת הבולטות, לוחצים על קלט או פלט בהנחיה או בתשובה, והתוצאות של מידת הבולטות יוצגו.

6-c: עריכה ידנית של ההנחיה והיעד
הכלי LIT מאפשר לערוך באופן ידני כל prompt וtarget של נקודת נתונים קיימת. לחיצה על Add תוסיף את הקלט החדש למערך הנתונים.

6ד: השוואה בין הנחיות זו לצד זו
בעזרת LIT אפשר להשוות בין הנחיות זו לצד זו בדוגמאות מקוריות וערוכות. אפשר לערוך דוגמה באופן ידני ולראות את תוצאת החיזוי ואת ניתוח הבולטות של הרצף גם לגרסה המקורית וגם לגרסה הערוכה בו-זמנית. אפשר לשנות את ההנחיה לכל נקודת נתונים, ו-LIT ייצור את התשובה המתאימה על ידי שליחת שאילתה למודל.

6-e: השוואה בין כמה מודלים זה לצד זה
בעזרת LIT אפשר להשוות בין מודלים בטבלה בדוגמאות של יצירת טקסט ומתן ניקוד, וגם בדוגמאות מצטברות של מדדים ספציפיים. באמצעות שאילתות של מודלים שונים שנטענו, אפשר להשוות בקלות בין התשובות שלהם.

6-f: גנרטורים אוטומטיים של תרחישים היפותטיים
אתם יכולים להשתמש בגנרטורים אוטומטיים של תרחישים היפותטיים כדי ליצור קלט חלופי ולראות איך המודל מתנהג לגביו באופן מיידי.

6-g: הערכת ביצועי המודל
אתם יכולים להעריך את ביצועי המודל באמצעות מדדים (בשלב הזה יש תמיכה בציוני BLEU ו-ROUGE ליצירת טקסט) בכל מערך הנתונים, או בכל קבוצת משנה של דוגמאות מסוננות או נבחרות.

7. פתרון בעיות
7-א: בעיות גישה פוטנציאליות ופתרונות
ההרשאות של --no-allow-unauthenticated מוחלות כשפורסים ל-Cloud Run, ולכן יכול להיות שתיתקלו בשגיאות שקשורות להרשאות, כמו אלה שמוצגות בהמשך.

יש שתי גישות לגישה לשירות אפליקציית LIT.
1. Proxy to Local Service
אפשר להעביר את השירות באמצעות פרוקסי למארח מקומי באמצעות הפקודה שלמטה.
# Proxy the service to local host.
gcloud run services proxy $LIT_SERVICE_NAME
אחרי זה תוכלו לגשת לשרת LIT בלחיצה על הקישור לשירות הפרוקסי.
2. אימות ישיר של משתמשים
אפשר ללחוץ על הקישור הזה כדי לאמת משתמשים ולאפשר גישה ישירה לשירות של אפליקציית LIT. הגישה הזו יכולה לאפשר לקבוצת משתמשים לגשת לשירות. זו אפשרות יעילה יותר לפיתוח שכולל שיתוף פעולה עם כמה אנשים.
7-ב: בדיקות לוודא שהשרת של המודל הופעל בהצלחה
כדי לוודא ששרת המודל הופעל בהצלחה, אפשר לשלוח בקשה לשרת המודל כדי לבצע שאילתה ישירה. שרת המודל מספק שלוש נקודות קצה: predict, tokenize ו-salience. חשוב לוודא שציינתם בבקשה גם את השדה prompt וגם את השדות target.
# Query the model server predict endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/predict -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server tokenize endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/tokenize -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server salience endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/salience -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
אם נתקלתם בבעיית גישה, כדאי לעיין בסעיף 7א למעלה.
8. מזל טוב
כל הכבוד על השלמת ה-Codelab! הגיע הזמן להירגע!
הסרת המשאבים
כדי לנקות את הסביבה של המעבדה, מוחקים את כל שירותי Google Cloud שנוצרו עבור המעבדה. מריצים את הפקודות הבאות באמצעות Google Cloud Shell.
אם החיבור ל-Google Cloud נותק בגלל חוסר פעילות, צריך לאפס את המשתנים לפי השלבים הקודמים.
# Delete the LIT App Service.
gcloud run services delete $LIT_SERVICE_NAME
אם הפעלתם שרת מודלים, אתם צריכים למחוק גם אותו.
# Delete the Model Service.
gcloud run services delete $MODEL_SERVICE_NAME
קריאה נוספת
כדי להמשיך ללמוד על התכונות של כלי ה-LIT, אפשר לעיין בחומרים הבאים:
- Gemma: קישור
- בסיס קוד פתוח של LIT: מאגר Git
- מאמר בנושא LIT: ArXiv
- מאמר בנושא ניפוי באגים בהנחיות של LIT: ArXiv
- סרטון הדגמה של התכונה LIT: YouTube
- הדגמה של ניפוי באגים בהנחיות ב-LIT: YouTube
- ערכת כלים לשימוש אחראי ב-AI גנרטיבי: קישור
יצירת קשר
אם יש לכם שאלות או בעיות לגבי ה-codelab הזה, אתם יכולים לפנות אלינו ב-GitHub.
רישיון
עבודה זו מורשית תחת רישיון Creative Commons שמותנה בייחוס 4.0 כללי.