
1. ภาพรวม
แล็บนี้จะอธิบายขั้นตอนโดยละเอียดเกี่ยวกับการติดตั้งใช้งานเซิร์ฟเวอร์แอปพลิเคชัน LIT ใน Google Cloud Platform (GCP) เพื่อโต้ตอบกับโมเดลพื้นฐาน Gemini ของ Vertex AI และโมเดลภาษาขนาดใหญ่ (LLM) ของบุคคลที่สามที่โฮสต์ด้วยตนเอง นอกจากนี้ ยังมีคำแนะนำเกี่ยวกับวิธีใช้ UI ของ LIT เพื่อแก้ไขข้อบกพร่องของพรอมต์และการตีความโมเดล
เมื่อทำตามแล็บนี้ ผู้ใช้จะได้เรียนรู้วิธีการต่อไปนี้
- กำหนดค่าเซิร์ฟเวอร์ LIT ใน GCP
- เชื่อมต่อเซิร์ฟเวอร์ LIT กับโมเดล Gemini ของ Vertex AI หรือ LLM อื่นๆ ที่โฮสต์ด้วยตนเอง
- ใช้ UI ของ LIT เพื่อวิเคราะห์ แก้จุดบกพร่อง และตีความพรอมต์เพื่อให้โมเดลมีประสิทธิภาพและข้อมูลเชิงลึกที่ดีขึ้น
LIT คืออะไร
LIT เป็นเครื่องมือแบบอินเทอร์แอกทีฟที่มองเห็นได้ซึ่งช่วยให้เข้าใจโมเดล โดยรองรับข้อความ รูปภาพ และข้อมูลแบบตาราง โดยสามารถเรียกใช้เป็นเซิร์ฟเวอร์แบบสแตนด์อโลนหรือภายในสภาพแวดล้อมของ Notebook เช่น Google Colab, Jupyter และ Google Cloud Vertex AI LIT พร้อมใช้งานจาก PyPI และ GitHub
การอัปเดตล่าสุดได้เพิ่มเครื่องมือสำหรับการแก้ไขข้อบกพร่องของพรอมต์ LLM ซึ่งช่วยให้คุณสำรวจได้ว่าเนื้อหาของผู้ใช้ โมเดล และระบบมีอิทธิพลต่อลักษณะการทำงานของการสร้างอย่างไร โดยเดิมทีเครื่องมือนี้สร้างขึ้นเพื่อทำความเข้าใจโมเดลการจัดประเภทและการถดถอย
Vertex AI และ Model Garden คืออะไร
Vertex AI เป็นแพลตฟอร์มแมชชีนเลิร์นนิง (ML) ที่ให้คุณฝึกและติดตั้งใช้งานโมเดล ML และแอปพลิเคชัน AI รวมถึงปรับแต่ง LLM เพื่อใช้ในแอปพลิเคชันที่ทำงานด้วยระบบ AI Vertex AI ผสานรวมเวิร์กโฟลว์วิศวกรรมข้อมูล วิทยาศาสตร์ข้อมูล และวิศวกรรม ML เพื่อให้ทีมของคุณทำงานร่วมกันได้โดยใช้ชุดเครื่องมือทั่วไป และปรับขนาดแอปพลิเคชันโดยใช้ประโยชน์จาก Google Cloud
Vertex Model Garden คือคลังโมเดล ML ที่ช่วยให้คุณค้นหา ทดสอบ ปรับแต่ง และติดตั้งใช้งานโมเดลและชิ้นงานที่เป็นกรรมสิทธิ์ของ Google รวมถึงโมเดลและชิ้นงานของบุคคลที่สามที่เลือก
สิ่งที่คุณต้องทำ
คุณจะใช้ Cloud Shell ของ Google และ Cloud Run เพื่อทำให้คอนเทนเนอร์ Docker ใช้งานได้จากอิมเมจที่สร้างไว้ล่วงหน้าของ LIT
Cloud Run เป็นแพลตฟอร์มการประมวลผลที่มีการจัดการซึ่งช่วยให้คุณเรียกใช้คอนเทนเนอร์โดยตรงบนโครงสร้างพื้นฐานที่ปรับขนาดได้ของ Google รวมถึงใน GPU
ชุดข้อมูล
โดยค่าเริ่มต้น เดโมจะใช้ชุดข้อมูลตัวอย่างการแก้ไขข้อบกพร่องของพรอมต์ LIT หรือคุณจะโหลดชุดข้อมูลของคุณเองผ่าน UI ก็ได้
ก่อนเริ่มต้น
คุณต้องมีโปรเจ็กต์ Google Cloud สำหรับคู่มืออ้างอิงนี้ คุณจะสร้างโปรเจ็กต์ใหม่หรือเลือกโปรเจ็กต์ที่สร้างไว้แล้วก็ได้
2. เปิด Google Cloud Console และ Cloud Shell
คุณจะเปิด Google Cloud Console และใช้ Google Cloud Shell ในขั้นตอนนี้
2-ก: เปิด Google Cloud Console
เปิดเบราว์เซอร์แล้วไปที่ Google Cloud Console
Google Cloud Console เป็นอินเทอร์เฟซผู้ดูแลระบบเว็บที่มีประสิทธิภาพและปลอดภัย ซึ่งช่วยให้คุณจัดการทรัพยากร Google Cloud ได้อย่างรวดเร็ว เป็นเครื่องมือ DevOps ที่พร้อมใช้งาน
2-b: เปิดใช้ Google Cloud Shell
Cloud Shell เป็นสภาพแวดล้อมการพัฒนาและการปฏิบัติการออนไลน์ที่เข้าถึงได้ทุกที่ด้วยเบราว์เซอร์ คุณจัดการทรัพยากรได้ด้วยเทอร์มินัลออนไลน์ที่โหลดไว้ล่วงหน้าพร้อมยูทิลิตีต่างๆ เช่น เครื่องมือบรรทัดคำสั่ง gcloud, kubectl และอื่นๆ นอกจากนี้ คุณยังพัฒนา สร้าง แก้จุดบกพร่อง และทำให้แอปที่ใช้ระบบคลาวด์ใช้งานได้โดยใช้โปรแกรมแก้ไข Cloud Shell ออนไลน์ Cloud Shell มีสภาพแวดล้อมออนไลน์ที่พร้อมสำหรับนักพัฒนาซอฟต์แวร์ โดยมาพร้อมชุดเครื่องมือโปรดที่ติดตั้งไว้ล่วงหน้าและพื้นที่เก็บข้อมูลถาวรขนาด 5 GB คุณจะต้องใช้ Command Prompt ในขั้นตอนถัดไป
เปิด Google Cloud Shell โดยใช้ไอคอนที่ด้านขวาบนของแถบเมนู ซึ่งวงกลมสีน้ำเงินในภาพหน้าจอต่อไปนี้

คุณควรเห็นเทอร์มินัลที่มีเชลล์ Bash ที่ด้านล่างของหน้า

2-ค: ตั้งค่าโปรเจ็กต์ Google Cloud
คุณต้องตั้งค่ารหัสโปรเจ็กต์และภูมิภาคโปรเจ็กต์โดยใช้คำสั่ง gcloud
# Set your GCP Project ID.
gcloud config set project your-project-id
# Set your GCP Project Region.
gcloud config set run/region your-project-region
3. ติดตั้งใช้งานอิมเมจ Docker ของเซิร์ฟเวอร์แอป LIT ด้วย Cloud Run
3-ก: ทำให้แอป LIT ใช้งานได้กับ Cloud Run
ก่อนอื่นคุณต้องตั้งค่า LIT-App เวอร์ชันล่าสุดเป็นเวอร์ชันที่จะติดตั้งใช้งาน
# Set latest version as your LIT_SERVICE_TAG.
export LIT_SERVICE_TAG=latest
# List all the public LIT GCP App server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app
หลังจากตั้งค่าแท็กเวอร์ชันแล้ว คุณต้องตั้งชื่อบริการ
# Set your lit service name. While 'lit-app-service' is provided as a placeholder, you can customize the service name based on your preferences.
export LIT_SERVICE_NAME=lit-app-service
หลังจากนั้น คุณจะเรียกใช้คำสั่งต่อไปนี้เพื่อติดตั้งใช้งานคอนเทนเนอร์ใน Cloud Run ได้
# Use below cmd to deploy the LIT App to Cloud Run.
gcloud run deploy $LIT_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app:$LIT_SERVICE_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--no-allow-unauthenticated
นอกจากนี้ LIT ยังให้คุณเพิ่มชุดข้อมูลเมื่อเริ่มเซิร์ฟเวอร์ได้ด้วย โดยให้ตั้งค่าตัวแปร DATASETS ให้รวมข้อมูลที่ต้องการโหลดโดยใช้รูปแบบ name:path เช่น data_foo:/bar/data_2024.jsonl รูปแบบชุดข้อมูลควรเป็น .jsonl โดยแต่ละระเบียนจะมีฟิลด์ prompt และฟิลด์ target และ source (ไม่บังคับ) หากต้องการโหลดชุดข้อมูลหลายชุด ให้คั่นแต่ละชุดด้วยคอมมา หากไม่ได้ตั้งค่าไว้ ระบบจะโหลดชุดข้อมูลตัวอย่างการแก้ไขข้อบกพร่องของพรอมต์ LIT
# Set the dataset.
export DATASETS=[DATASETS]
การตั้งค่า MAX_EXAMPLES ช่วยให้คุณกำหนดจำนวนตัวอย่างสูงสุดที่จะโหลดจากชุดการประเมินแต่ละชุดได้
# Set the max examples.
export MAX_EXAMPLES=[MAX_EXAMPLES]
จากนั้นในคำสั่งการติดตั้งใช้งาน คุณจะเพิ่ม
--set-env-vars "DATASETS=$DATASETS" \
--set-env-vars "MAX_EXAMPLES=$MAX_EXAMPLES" \
3-ข: ดูบริการแอป LIT
หลังจากสร้างเซิร์ฟเวอร์แอป LIT แล้ว คุณจะเห็นบริการดังกล่าวในส่วน Cloud Run ของ Cloud Console
เลือกบริการแอป LIT ที่คุณเพิ่งสร้าง ตรวจสอบว่าชื่อบริการเหมือนกับ LIT_SERVICE_NAME

คุณดู URL ของบริการได้โดยคลิกบริการที่เพิ่งติดตั้งใช้งาน
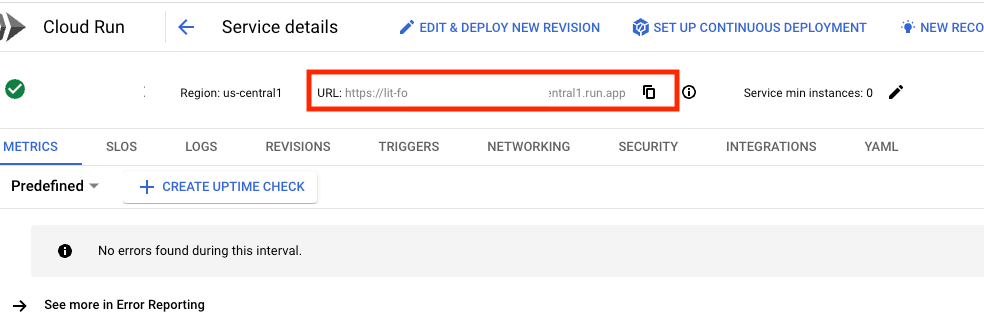
จากนั้นคุณจะดู UI ของ LIT ได้ หากพบข้อผิดพลาด โปรดดูส่วนการแก้ปัญหา

คุณสามารถตรวจสอบส่วนบันทึกเพื่อตรวจสอบกิจกรรม ดูข้อความแสดงข้อผิดพลาด และติดตามความคืบหน้าของการติดตั้งใช้งาน
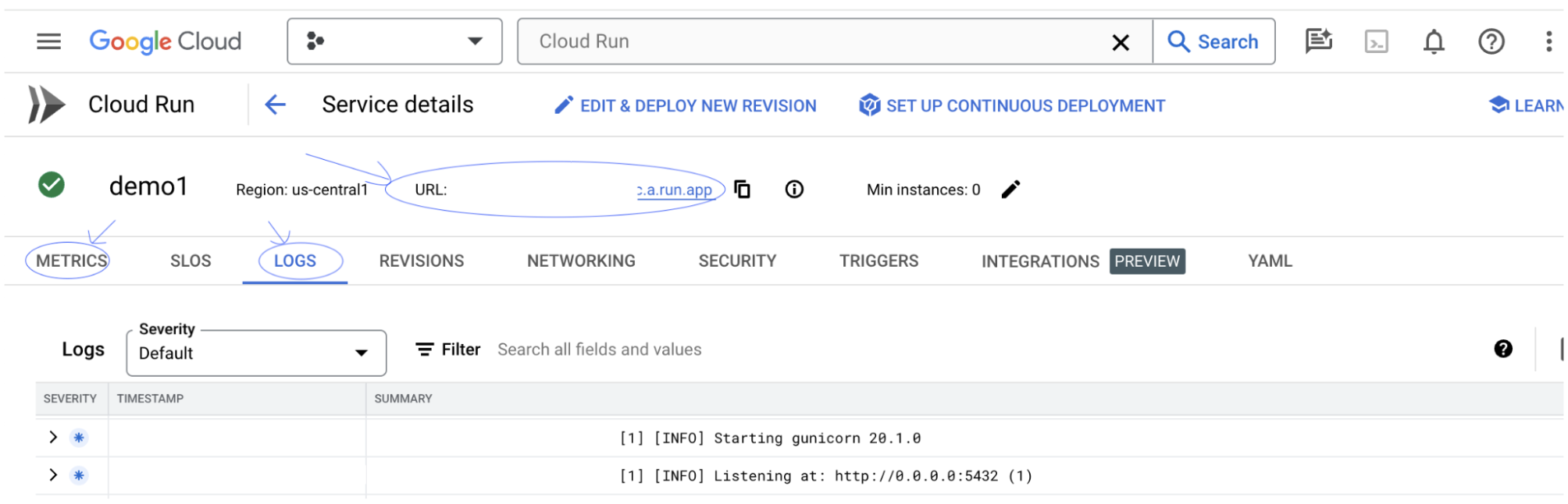
คุณสามารถตรวจสอบส่วนเมตริกเพื่อดูเมตริกของบริการได้

3-ค: โหลดชุดข้อมูล
คลิกตัวเลือก Configure ใน UI ของ LIT แล้วเลือก Dataset โหลดชุดข้อมูลโดยระบุชื่อและ URL ของชุดข้อมูล รูปแบบชุดข้อมูลควรเป็น .jsonl โดยแต่ละระเบียนจะมีฟิลด์ prompt และฟิลด์ target และ source (ไม่บังคับ)

4. เตรียมโมเดล Gemini ใน Vertex AI Model Garden
โมเดลพื้นฐาน Gemini ของ Google พร้อมให้บริการจาก Vertex AI API LIT มีVertexAIModelGarden Model Wrapper เพื่อใช้โมเดลเหล่านี้ในการสร้าง เพียงระบุเวอร์ชันที่ต้องการ (เช่น "gemini-1.5-pro-001") ผ่านพารามิเตอร์ชื่อโมเดล ข้อได้เปรียบที่สำคัญของการใช้โมเดลเหล่านี้คือคุณไม่ต้องพยายามเพิ่มเติมในการติดตั้งใช้งาน โดยค่าเริ่มต้น คุณจะมีสิทธิ์เข้าถึงโมเดลต่างๆ เช่น Gemini 1.0 Pro และ Gemini 1.5 Pro ใน GCP ได้ทันที ซึ่งช่วยลดขั้นตอนการกำหนดค่าเพิ่มเติม
4-ก: ให้สิทธิ์ Vertex AI
หากต้องการค้นหา Gemini ใน GCP คุณต้องให้สิทธิ์ Vertex AI แก่บัญชีบริการ ตรวจสอบว่าชื่อบัญชีบริการคือ Default compute service account คัดลอกอีเมลบัญชีบริการของบัญชี
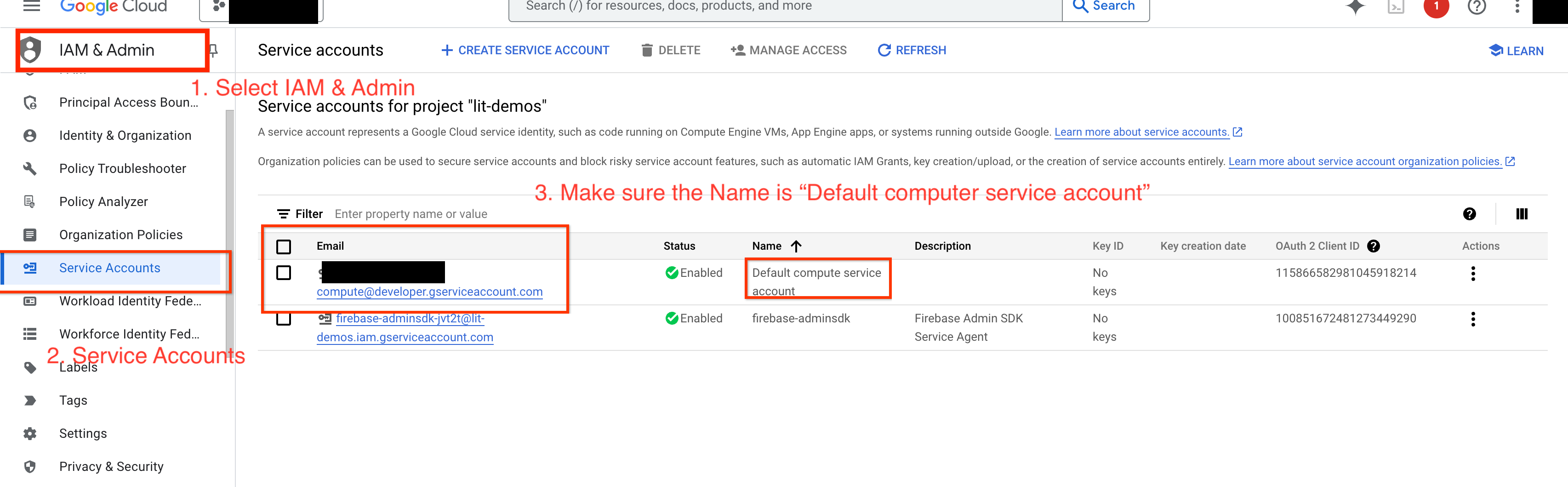
เพิ่มอีเมลบัญชีบริการเป็นหลักการที่มีบทบาท Vertex AI User ในรายการที่อนุญาตของ IAM

4-ข: โหลดโมเดล Gemini
คุณจะโหลดโมเดล Gemini และปรับพารามิเตอร์ตามขั้นตอนด้านล่าง
- คลิกตัวเลือก
Configureใน UI ของ LIT
- คลิกตัวเลือก
- เลือกตัวเลือก
geminiในส่วนตัวเลือกSelect a base model
- เลือกตัวเลือก
- คุณต้องตั้งชื่อโมเดลใน
new_name
- คุณต้องตั้งชื่อโมเดลใน
- ป้อนโมเดล Gemini ที่เลือกเป็น
model_name
- ป้อนโมเดล Gemini ที่เลือกเป็น
- คลิก
Load Model
- คลิก
- คลิก
Submit
- คลิก

5. ติดตั้งใช้งานเซิร์ฟเวอร์โมเดล LLM ที่โฮสต์ด้วยตนเองใน GCP
การโฮสต์ LLM ด้วยตนเองโดยใช้ Docker Image ของเซิร์ฟเวอร์โมเดลของ LIT ช่วยให้คุณใช้ฟังก์ชันความโดดเด่นและการสร้างโทเค็นของ LIT เพื่อรับข้อมูลเชิงลึกที่ละเอียดยิ่งขึ้นเกี่ยวกับลักษณะการทำงานของโมเดล อิมเมจเซิร์ฟเวอร์โมเดลใช้ได้กับโมเดล KerasNLP หรือ Hugging Face Transformers รวมถึงน้ำหนักที่จัดหาโดยไลบรารีและที่โฮสต์ด้วยตนเอง เช่น ใน Google Cloud Storage
5-ก: กำหนดค่าโมเดล
แต่ละคอนเทนเนอร์จะโหลดโมเดล 1 รายการ ซึ่งกำหนดค่าโดยใช้ตัวแปรสภาพแวดล้อม
คุณควรระบุโมเดลที่จะโหลดโดยการตั้งค่า MODEL_CONFIG รูปแบบควรเป็น name:path เช่น model_foo:model_foo_path เส้นทางอาจเป็น URL, เส้นทางไฟล์ในเครื่อง หรือชื่อของค่าที่กำหนดล่วงหน้าสำหรับเฟรมเวิร์กการเรียนรู้เชิงลึกที่กำหนดค่าไว้ (ดูข้อมูลเพิ่มเติมในตารางต่อไปนี้) เซิร์ฟเวอร์นี้ได้รับการทดสอบกับ Gemma, GPT2, Llama และ Mistral ในค่า DL_FRAMEWORK ที่รองรับทั้งหมด รุ่นอื่นๆ ควรใช้งานได้ แต่คุณอาจต้องปรับเปลี่ยน
# Set models you want to load. While 'gemma2b is given as a placeholder, you can load your preferred model by following the instructions above.
export MODEL_CONFIG=gemma2b:gemma_2b_en
นอกจากนี้ เซิร์ฟเวอร์โมเดล LIT ยังอนุญาตให้กำหนดค่าตัวแปรสภาพแวดล้อมต่างๆ ได้โดยใช้คำสั่งด้านล่าง โปรดดูรายละเอียดในตาราง โปรดทราบว่าต้องตั้งค่าตัวแปรแต่ละรายการแยกกัน
# Customize the variable value as needed.
export [VARIABLE]=[VALUE]
ตัวแปร | ค่า | คำอธิบาย |
DL_FRAMEWORK |
| ไลบรารีการประมาณที่ใช้ในการโหลดน้ำหนักของโมเดลไปยังรันไทม์ที่ระบุ ค่าเริ่มต้นคือ |
DL_RUNTIME |
| เฟรมเวิร์กแบ็กเอนด์ของการเรียนรู้เชิงลึกที่โมเดลทำงานอยู่ โมเดลทั้งหมดที่เซิร์ฟเวอร์นี้โหลดจะใช้แบ็กเอนด์เดียวกัน และความไม่เข้ากันจะส่งผลให้เกิดข้อผิดพลาด ค่าเริ่มต้นคือ |
PRECISION |
| ความแม่นยำของจุดลอยตัวสำหรับโมเดล LLM ค่าเริ่มต้นคือ |
BATCH_SIZE | จำนวนเต็มบวก | จำนวนตัวอย่างที่จะประมวลผลต่อกลุ่ม ค่าเริ่มต้นคือ |
SEQUENCE_LENGTH | จำนวนเต็มบวก | ความยาวลำดับสูงสุดของพรอมต์อินพุตบวกข้อความที่สร้างขึ้น ค่าเริ่มต้นคือ |
5-ข: ทำให้เซิร์ฟเวอร์โมเดลใช้งานได้กับ Cloud Run
ก่อนอื่นคุณต้องตั้งค่า Model Server เวอร์ชันล่าสุดเป็นเวอร์ชันที่จะทําให้ใช้งานได้
# Set latest as MODEL_VERSION_TAG.
export MODEL_VERSION_TAG=latest
# List all the public LIT GCP model server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server
หลังจากตั้งค่าแท็กเวอร์ชันแล้ว คุณต้องตั้งชื่อเซิร์ฟเวอร์โมเดล
# Set your Service name.
export MODEL_SERVICE_NAME='gemma2b-model-server'
หลังจากนั้น คุณจะเรียกใช้คำสั่งต่อไปนี้เพื่อติดตั้งใช้งานคอนเทนเนอร์ใน Cloud Run ได้ หากไม่ได้ตั้งค่าตัวแปรสภาพแวดล้อม ระบบจะใช้ค่าเริ่มต้น เนื่องจาก LLM ส่วนใหญ่ต้องใช้ทรัพยากรการประมวลผลที่มีราคาสูง เราจึงขอแนะนำให้ใช้ GPU หากต้องการเรียกใช้เฉพาะใน CPU (ซึ่งใช้ได้ดีกับโมเดลขนาดเล็ก เช่น GPT2) คุณสามารถนำอาร์กิวเมนต์ที่เกี่ยวข้องออกได้ --gpu 1 --gpu-type nvidia-l4 --max-instances 7
# Deploy the model service container.
gcloud beta run deploy $MODEL_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server:$MODEL_VERSION_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 7 \
--set-env-vars "MODEL_CONFIG=$MODEL_CONFIG" \
--no-allow-unauthenticated
นอกจากนี้ คุณยังปรับแต่งตัวแปรสภาพแวดล้อมได้โดยเพิ่มคำสั่งต่อไปนี้ รวมเฉพาะตัวแปรสภาพแวดล้อมที่จำเป็นสำหรับความต้องการเฉพาะของคุณ
--set-env-vars "DL_FRAMEWORK=$DL_FRAMEWORK" \
--set-env-vars "DL_RUNTIME=$DL_RUNTIME" \
--set-env-vars "PRECISION=$PRECISION" \
--set-env-vars "BATCH_SIZE=$BATCH_SIZE" \
--set-env-vars "SEQUENCE_LENGTH=$SEQUENCE_LENGTH" \
คุณอาจต้องใช้ตัวแปรสภาพแวดล้อมเพิ่มเติมเพื่อเข้าถึงโมเดลบางรายการ ดูวิธีการจาก Kaggle Hub (ใช้สำหรับโมเดล KerasNLP) และ Hugging Face Hub ตามความเหมาะสม
5-ค: เข้าถึงเซิร์ฟเวอร์โมเดล
หลังจากสร้างเซิร์ฟเวอร์โมเดลแล้ว คุณจะเห็นบริการที่เริ่มต้นในส่วน Cloud Run ของโปรเจ็กต์ GCP
เลือกเซิร์ฟเวอร์โมเดลที่คุณเพิ่งสร้าง ตรวจสอบว่าชื่อบริการเหมือนกับ MODEL_SERVICE_NAME
คุณดู URL ของบริการได้โดยคลิกบริการโมเดลที่คุณเพิ่งติดตั้งใช้งาน
คุณสามารถตรวจสอบส่วนบันทึกเพื่อตรวจสอบกิจกรรม ดูข้อความแสดงข้อผิดพลาด และติดตามความคืบหน้าของการติดตั้งใช้งาน
คุณสามารถตรวจสอบส่วนเมตริกเพื่อดูเมตริกของบริการได้
5-ง: โหลดโมเดลที่โฮสต์ด้วยตนเอง
หากคุณพร็อกซีเซิร์ฟเวอร์ LIT ในขั้นตอนที่ 3 (ดูส่วนการแก้ปัญหา) คุณจะต้องขอโทเค็นข้อมูลประจำตัว GCP โดยเรียกใช้คำสั่งต่อไปนี้
# Find your GCP identity token.
gcloud auth print-identity-token
คุณจะโหลดโมเดลที่โฮสต์ด้วยตนเองและปรับพารามิเตอร์ตามขั้นตอนด้านล่าง
- คลิกตัวเลือก
Configureใน UI ของ LIT - เลือกตัวเลือก
LLM (self hosted)ในส่วนตัวเลือกSelect a base model - คุณต้องตั้งชื่อโมเดลใน
new_name - ป้อน URL ของเซิร์ฟเวอร์โมเดลเป็น
base_url - ป้อนโทเค็นประจำตัวที่ได้รับใน
identity_tokenหากคุณพร็อกซีเซิร์ฟเวอร์แอป LIT (ดูขั้นตอนที่ 3 และขั้นตอนที่ 7) หรือเว้นว่างไว้ - คลิก
Load Model - คลิก
Submit

6. โต้ตอบกับ LIT บน GCP
LIT มีชุดฟีเจอร์มากมายที่จะช่วยคุณแก้ไขข้อบกพร่องและทําความเข้าใจลักษณะการทํางานของโมเดล คุณสามารถทำสิ่งต่างๆ ได้ง่ายๆ เช่น การค้นหาโมเดลโดยการพิมพ์ข้อความในช่องและดูการคาดการณ์ของโมเดล หรือตรวจสอบโมเดลอย่างละเอียดด้วยชุดฟีเจอร์ที่มีประสิทธิภาพของ LIT ซึ่งรวมถึง
6-ก: ค้นหาโมเดลผ่าน LIT
LIT จะค้นหาชุดข้อมูลโดยอัตโนมัติหลังจากโหลดโมเดลและชุดข้อมูล คุณดูคำตอบของแต่ละโมเดลได้โดยเลือกคำตอบในคอลัมน์
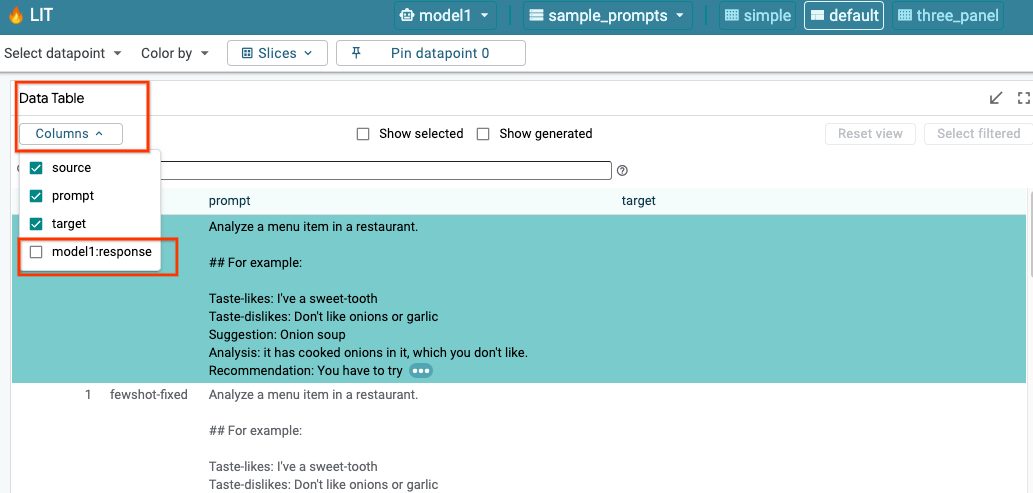

6-b: ใช้เทคนิคความโดดเด่นของลำดับ
ปัจจุบันเทคนิคความโดดเด่นของลำดับใน LIT รองรับเฉพาะโมเดลที่โฮสต์ด้วยตนเอง
Sequence Salience เป็นเครื่องมือภาพที่ช่วยแก้ไขข้อบกพร่องของพรอมต์ LLM โดยไฮไลต์ส่วนของพรอมต์ที่มีความสำคัญมากที่สุดสำหรับเอาต์พุตที่กำหนด ดูข้อมูลเพิ่มเติมเกี่ยวกับความโดดเด่นของลำดับได้ในบทแนะนำฉบับเต็มเพื่อดูข้อมูลเพิ่มเติมเกี่ยวกับวิธีใช้ฟีเจอร์นี้
หากต้องการเข้าถึงผลลัพธ์ความโดดเด่น ให้คลิกอินพุตหรือเอาต์พุตใดก็ได้ในพรอมต์หรือคำตอบ แล้วผลลัพธ์ความโดดเด่นจะปรากฏขึ้น

6-ค: พรอมต์และเป้าหมายการแก้ไขด้วยตนเอง
LIT ช่วยให้คุณแก้ไขpromptและtargetสำหรับจุดข้อมูลที่มีอยู่ได้ด้วยตนเอง เมื่อคลิก Add ระบบจะเพิ่มข้อมูลใหม่ลงในชุดข้อมูล

6-ง: เปรียบเทียบพรอมต์แบบเทียบเคียง
LIT ช่วยให้คุณเปรียบเทียบพรอมต์แบบคู่ขนานในตัวอย่างต้นฉบับและตัวอย่างที่แก้ไขแล้วได้ คุณสามารถแก้ไขตัวอย่างด้วยตนเอง และดูผลการคาดการณ์และการวิเคราะห์ความโดดเด่นของลำดับสำหรับทั้งเวอร์ชันต้นฉบับและเวอร์ชันที่แก้ไขพร้อมกันได้ คุณสามารถแก้ไขพรอมต์สำหรับแต่ละจุดข้อมูล และ LIT จะสร้างคำตอบที่สอดคล้องกันโดยการค้นหาโมเดล

6-จ: เปรียบเทียบโมเดลหลายรายการควบคู่กัน
LIT ช่วยให้เปรียบเทียบโมเดลแบบเคียงข้างกันได้ในตัวอย่างการสร้างข้อความและการให้คะแนนแต่ละรายการ รวมถึงในตัวอย่างที่รวบรวมไว้สำหรับเมตริกที่เฉพาะเจาะจง การค้นหาโมเดลที่โหลดไว้ต่างๆ จะช่วยให้คุณเปรียบเทียบความแตกต่างในคำตอบได้อย่างง่ายดาย

6-f: Automatic Counterfactual Generators
คุณสามารถใช้เครื่องมือสร้างข้อเท็จจริงสมมติอัตโนมัติเพื่อสร้างอินพุตทางเลือก และดูว่าโมเดลทำงานอย่างไรกับอินพุตเหล่านั้นได้ทันที

6-g: ประเมินประสิทธิภาพของโมเดล
คุณสามารถประเมินประสิทธิภาพของโมเดลโดยใช้เมตริก (ปัจจุบันรองรับคะแนน BLEU และ ROUGE สำหรับการสร้างข้อความ) ในชุดข้อมูลทั้งหมด หรือชุดข้อมูลย่อยของตัวอย่างที่กรองหรือเลือก

7. การแก้ปัญหา
7-ก: ปัญหาเกี่ยวกับสิทธิ์เข้าถึงที่อาจเกิดขึ้นและวิธีแก้ไข
เนื่องจากมีการใช้ --no-allow-unauthenticated เมื่อทำให้ใช้งานได้กับ Cloud Run คุณจึงอาจพบข้อผิดพลาดที่ถูกปฏิเสธดังที่แสดงด้านล่าง

คุณเข้าถึงบริการแอป LIT ได้ 2 วิธี
1. พร็อกซีไปยังบริการในพื้นที่
คุณสามารถพร็อกซีบริการไปยังโฮสต์ในเครื่องได้โดยใช้คำสั่งด้านล่าง
# Proxy the service to local host.
gcloud run services proxy $LIT_SERVICE_NAME
จากนั้นคุณควรจะเข้าถึงเซิร์ฟเวอร์ LIT ได้โดยคลิกลิงก์บริการที่พร็อกซี
2. ตรวจสอบสิทธิ์ผู้ใช้โดยตรง
คุณสามารถทำตามลิงก์นี้เพื่อตรวจสอบสิทธิ์ผู้ใช้ ซึ่งจะช่วยให้เข้าถึงบริการแอป LIT ได้โดยตรง นอกจากนี้ วิธีนี้ยังช่วยให้กลุ่มผู้ใช้เข้าถึงบริการได้ด้วย สำหรับงานพัฒนาที่ต้องทำงานร่วมกับหลายคน ตัวเลือกนี้จะมีประสิทธิภาพมากกว่า
7-b: การตรวจสอบเพื่อให้แน่ใจว่าเซิร์ฟเวอร์โมเดลเปิดตัวเรียบร้อยแล้ว
หากต้องการให้แน่ใจว่าเซิร์ฟเวอร์โมเดลเปิดตัวเรียบร้อยแล้ว คุณสามารถค้นหาเซิร์ฟเวอร์โมเดลได้โดยตรงด้วยการส่งคำขอ เซิร์ฟเวอร์โมเดลมีปลายทาง 3 รายการ ได้แก่ predict, tokenize และ salience โปรดระบุทั้งฟิลด์ prompt และฟิลด์ target ในคำขอ
# Query the model server predict endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/predict -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server tokenize endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/tokenize -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server salience endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/salience -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
หากพบปัญหาในการเข้าถึง โปรดดูส่วน 7-ก ด้านบน
8. ขอแสดงความยินดี
เก่งมากที่ทำ Codelab เสร็จสมบูรณ์ ได้เวลาพักผ่อนแล้ว
ล้างข้อมูล
หากต้องการล้างข้อมูลใน Lab ให้ลบบริการ Google Cloud ทั้งหมดที่สร้างขึ้นสำหรับ Lab ใช้ Google Cloud Shell เพื่อเรียกใช้คำสั่งต่อไปนี้
หากการเชื่อมต่อ Google Cloud ขาดหายไปเนื่องจากไม่มีการใช้งาน ให้รีเซ็ตตัวแปรโดยทำตามขั้นตอนก่อนหน้า
# Delete the LIT App Service.
gcloud run services delete $LIT_SERVICE_NAME
หากคุณเริ่มเซิร์ฟเวอร์โมเดล คุณก็ต้องลบเซิร์ฟเวอร์โมเดลด้วย
# Delete the Model Service.
gcloud run services delete $MODEL_SERVICE_NAME
อ่านเพิ่มเติม
ดูข้อมูลเพิ่มเติมเกี่ยวกับฟีเจอร์ของเครื่องมือ LIT ได้จากสื่อการเรียนรู้ด้านล่าง
- Gemma: ลิงก์
- ฐานโค้ดโอเพนซอร์สของ LIT: ที่เก็บ Git
- เอกสาร LIT: ArXiv
- เอกสารการแก้ไขข้อบกพร่องของพรอมต์ LIT: ArXiv
- วิดีโอสาธิตฟีเจอร์ LIT: Youtube
- การสาธิตการแก้ไขข้อบกพร่องของพรอมต์ LIT: Youtube
- ชุดเครื่องมือ GenAI ที่มีความรับผิดชอบ: ลิงก์
การติดต่อ
หากมีคำถามหรือปัญหาเกี่ยวกับ Codelab นี้ โปรดติดต่อเราที่ GitHub
ใบอนุญาต
ผลงานนี้ได้รับอนุญาตภายใต้สัญญาอนุญาตครีเอทีฟคอมมอนส์แบบระบุแหล่งที่มา 4.0 ทั่วไป