
1. Panoramica
Confidential Space offre un ambiente sicuro per la collaborazione tra più parti. Questo codelab mostra come utilizzare Confidential Space per proteggere la proprietà intellettuale sensibile, ad esempio i modelli di machine learning.
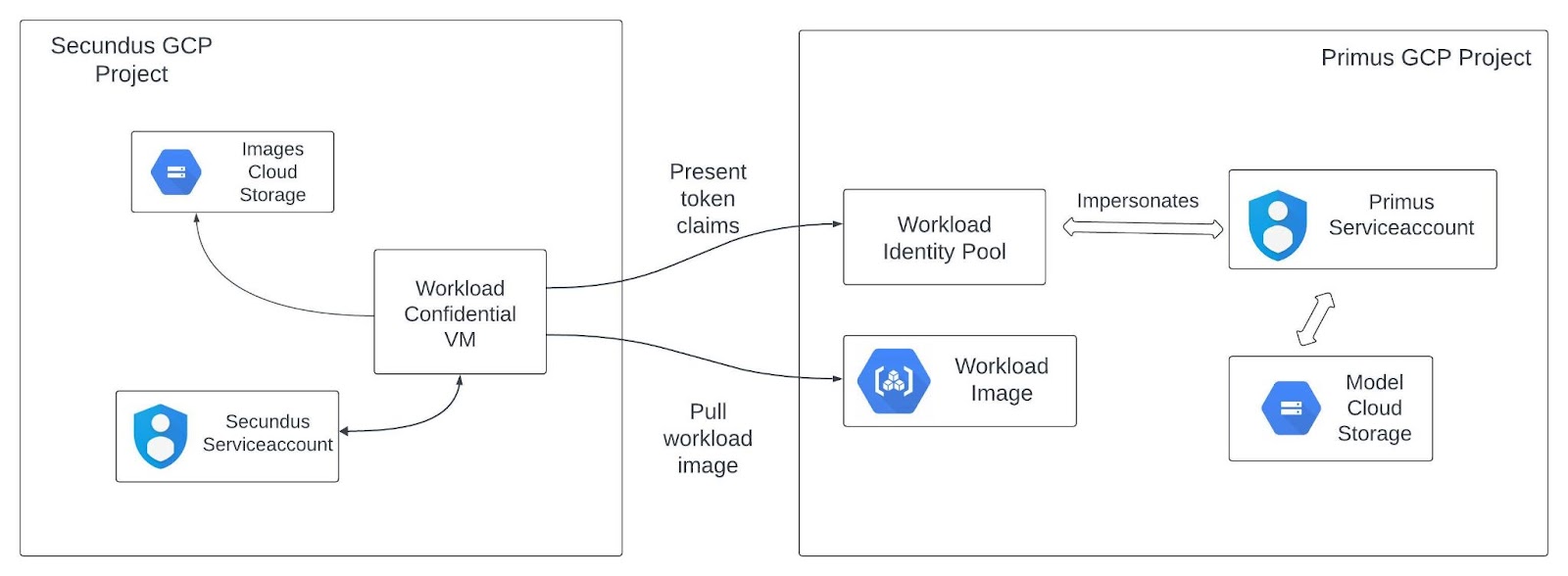
In questo codelab utilizzerai Confidential Space per consentire a un'azienda di condividere in modo sicuro il proprio modello di machine learning proprietario con un'altra azienda che vorrebbe utilizzarlo. In particolare, la società Primus dispone di un modello di machine learning che verrà rilasciato solo a un workload in esecuzione in Confidential Space, consentendo a Primus di mantenere il controllo completo della sua proprietà intellettuale. La società Secundus sarà l'operatore del workload ed eseguirà il workload di machine learning in un Confidential Space. Secundus caricherà questo modello ed eseguirà un'inferenza utilizzando dati di esempio di proprietà di Secundus.
In questo caso, Primus è l'autore del workload che scrive il codice del workload e un collaboratore che vuole proteggere la sua proprietà intellettuale dall'operatore del workload non attendibile, Secundus. Secundus è l'operatore del carico di lavoro di machine learning.
Cosa imparerai a fare
- Come configurare un ambiente in cui una parte può condividere il proprio modello ML proprietario con un'altra parte senza perdere il controllo della propria proprietà intellettuale.
Che cosa ti serve
- Un progetto Google Cloud
- Conoscenza di base di Google Compute Engine ( codelab), Confidential VM, container e repository remoti
- Conoscenza di base di service account, federazione delle identità per i workload e condizioni degli attributi.
Ruoli coinvolti nella configurazione di uno spazio confidenziale
In questo codelab, Company Primus sarà il proprietario della risorsa e l'autore del workload, responsabile di quanto segue:
- Configurazione delle risorse cloud richieste con un modello di machine learning
- Scrittura del codice del carico di lavoro
- Pubblicazione dell'immagine del workload
- Configurazione del criterio del pool di identità del workload per proteggere il modello ML da un operatore non attendibile
Secundus Company sarà l'operatore e responsabile di:
- Configurazione delle risorse cloud richieste per archiviare le immagini di esempio utilizzate dal carico di lavoro e i risultati
- Esecuzione del workload ML in Confidential Space utilizzando il modello fornito da Primus
Come funziona Confidential Space
Quando esegui il carico di lavoro in Confidential Space, viene eseguito il seguente processo utilizzando le risorse configurate:
- Il workload richiede un token di accesso Google generale per
$PRIMUS_SERVICEACCOUNTdal pool di identità del workload. Offre un token del servizio di verifica dell'attestazione con attestazioni di workload e ambiente. - Se le attestazioni di misurazione del carico di lavoro nel token del servizio di verifica dell'attestazione corrispondono alla condizione dell'attributo nel pool di identità per i carichi di lavoro, viene restituito il token di accesso per
$PRIMUS_SERVICEACCOUNT. - Il carico di lavoro utilizza il token di accesso al service account associato a
$PRIMUS_SERVICEACCOUNTper accedere al modello di machine learning archiviato nel bucket$PRIMUS_INPUT_STORAGE_BUCKET. - Il carico di lavoro esegue un'operazione sui dati di proprietà di Secundus e viene gestito ed eseguito da Secundus nel suo progetto.
- Il workload utilizza il service account
$WORKLOAD_SERVICEACCOUNTper scrivere i risultati dell'operazione nel bucket$SECUNDUS_RESULT_STORAGE_BUCKET.
2. Configura le risorse cloud
Prima di iniziare
- Clona questo repository utilizzando il comando riportato di seguito per ottenere gli script richiesti utilizzati in questo codelab.
git clone https://github.com/GoogleCloudPlatform/confidential-space.git
- Cambia la directory per questo codelab.
cd confidential-space/codelabs/ml_model_protection/scripts
- Assicurati di aver impostato le variabili di ambiente del progetto richieste come mostrato di seguito. Per ulteriori informazioni sulla configurazione di un progetto Google Cloud, consulta questo codelab. Puoi fare riferimento a questo articolo per scoprire come recuperare l'ID progetto e in che modo è diverso dal nome e dal numero del progetto.
export PRIMUS_PROJECT_ID=<GCP project id of Primus>
export SECUNDUS_PROJECT_ID=<GCP project id of Secundus>
- Abilita la fatturazione per i tuoi progetti.
- Abilita l'API Confidential Computing e le seguenti API per entrambi i progetti.
gcloud services enable \
cloudapis.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudshell.googleapis.com \
container.googleapis.com \
containerregistry.googleapis.com \
iam.googleapis.com \
confidentialcomputing.googleapis.com
- Assegna valori alle variabili per i nomi delle risorse specificati sopra utilizzando il seguente comando. Queste variabili ti consentono di personalizzare i nomi delle risorse in base alle esigenze e di utilizzare le risorse esistenti, se sono già state create. (ad es.
export PRIMUS_INPUT_STORAGE_BUCKET='my-input-bucket')
- Puoi impostare le seguenti variabili con i nomi delle risorse cloud esistenti nel progetto Primus. Se la variabile è impostata, viene utilizzata la risorsa cloud esistente corrispondente del progetto Primus. Se la variabile non è impostata, il nome della risorsa cloud verrà generato dal nome del progetto e verrà creata una nuova risorsa cloud con quel nome. Di seguito sono riportate le variabili supportate per i nomi delle risorse:
| Il bucket che archivia il modello di machine learning di Primus. |
| Il pool di identità del workload (WIP) di Primus che convalida le rivendicazioni. |
| Il provider di pool di identità del workload di Primus che include la condizione di autorizzazione da utilizzare per i token firmati dal servizio di verifica dell'attestazione. |
| Service account Primus che |
| Il repository di artefatti in cui verrà eseguito il push dell'immagine Docker del carico di lavoro. |
- Puoi impostare le seguenti variabili con i nomi delle risorse cloud esistenti nel progetto Secundus. Se la variabile è impostata, viene utilizzata la risorsa cloud esistente corrispondente del progetto Secundus. Se la variabile non è impostata, il nome della risorsa cloud verrà generato dal nome del progetto e verrà creata una nuova risorsa cloud con quel nome. Di seguito sono riportate le variabili supportate per i nomi delle risorse:
| Il bucket che archivia le immagini di esempio che Secundus vuole classificare utilizzando il modello fornito da Primus. |
| Il bucket che archivia i risultati del workload. |
| Il nome dell'immagine container del workload. |
| Il tag dell'immagine container del workload. |
| Il service account con l'autorizzazione per accedere alla VM confidenziale che esegue il workload. |
- Avrai bisogno di determinate autorizzazioni per questi due progetti e puoi consultare questa guida su come concedere ruoli IAM utilizzando la console GCP:
- Per
$PRIMUS_PROJECT_ID, avrai bisogno di Amministratore storage, Amministratore Artifact Registry, Amministratore account di servizio e Amministratore pool di identità del workload IAM. - Per
$SECUNDUS_PROJECT_ID, avrai bisogno di Compute Admin, Storage Admin, Service Account Admin, IAM Workload Identity Pool Admin, Security Admin (facoltativo). - Esegui il seguente script per impostare i nomi delle variabili rimanenti su valori basati sull'ID progetto per i nomi delle risorse.
source config_env.sh
Configurare le risorse di Primus Company
Nell'ambito di questo passaggio, configurerai le risorse cloud richieste per Primus. Esegui il seguente script per configurare le risorse per Primus. Le seguenti risorse verranno create nell'ambito dell'esecuzione dello script:
- Bucket Cloud Storage (
$PRIMUS_INPUT_STORAGE_BUCKET) per archiviare il modello di machine learning di Primus. - Pool di identità del workload (
$PRIMUS_WORKLOAD_IDENTITY_POOL) per convalidare le rivendicazioni in base alle condizioni degli attributi configurate nel relativo fornitore. - Service account (
$PRIMUS_SERVICEACCOUNT) collegato al pool di identità del workload ($PRIMUS_WORKLOAD_IDENTITY_POOL) menzionato in precedenza con accesso IAM per leggere i dati dal bucket Cloud Storage (utilizzando il ruoloobjectViewer) e per collegare questo service account al pool di identità del workload (utilizzando il ruoloroles/iam.workloadIdentityUser).
Nell'ambito di questa configurazione delle risorse cloud, utilizzeremo un modello TensorFlow. Possiamo salvare l'intero modello, inclusi l'architettura, i pesi e la configurazione di addestramento, in un archivio ZIP. Ai fini di questo codelab, utilizzeremo il modello MobileNet V1 addestrato sul set di dati ImageNet disponibile qui.
./setup_primus_company_resources.sh
Lo script menzionato sopra configurerà la risorsa cloud. Ora scaricheremo e pubblicheremo il modello nel bucket Cloud Storage creato dallo script.
- Scarica il modello preaddestrato da qui.
- Una volta scaricato, rinomina il file tar scaricato in model.tar.gz.
- Pubblica il file model.tar.gz nel bucket Cloud Storage utilizzando il seguente comando dalla directory contenente il file model.tar.gz.
gsutil cp model.tar.gz gs://${PRIMUS_INPUT_STORAGE_BUCKET}/
Configurare le risorse di Secundus Company
Nell'ambito di questo passaggio, configurerai le risorse cloud richieste per Secundus. Esegui il seguente script per configurare le risorse per Secundus. Nell'ambito di questi passaggi verranno create le seguenti risorse:
- Bucket Cloud Storage (
$SECUNDUS_INPUT_STORAGE_BUCKET) per archiviare le immagini di esempio per l'esecuzione di inferenze da parte di Secundus. - Bucket Cloud Storage (
$SECUNDUS_RESULT_STORAGE_BUCKET) per archiviare il risultato dell'esecuzione del carico di lavoro ML da parte di Secundus.
Per questo codelab sono disponibili alcune immagini di esempio qui.
./setup_secundus_company_resources.sh
3. Crea workload
Crea un service account del workload
Ora creerai un service account per il workload con i ruoli e le autorizzazioni richiesti. Esegui il seguente script per creare un service account del workload nel progetto Secundus. Questo service account verrà utilizzato dalla VM che esegue il workload di ML.
Questo service account del workload ($WORKLOAD_SERVICEACCOUNT) avrà i seguenti ruoli:
confidentialcomputing.workloadUserper ottenere un token di attestazionelogging.logWriterper scrivere i log in Cloud Logging.objectViewerper leggere i dati dal bucket di archiviazione cloud$SECUNDUS_INPUT_STORAGE_BUCKET.objectUserper scrivere il risultato del workload nel bucket Cloud Storage$SECUNDUS_RESULT_STORAGE_BUCKET.
./create_workload_service_account.sh
Crea workload
Nell'ambito di questo passaggio, creerai un'immagine Docker del workload. Il workload verrà creato da Primus. Il carico di lavoro utilizzato in questo codelab è il codice Python di machine learning che accede al modello ML archiviato nel bucket di archiviazione di Primus ed esegue inferenze con le immagini di esempio archiviate in un bucket di archiviazione.
Il modello di machine learning archiviato nel bucket di archiviazione di Primus sarebbe accessibile solo ai carichi di lavoro che soddisfano le condizioni degli attributi richiesti. Queste condizioni degli attributi sono descritte in modo più dettagliato nella sezione successiva sull'autorizzazione del workload.
Ecco il metodo run_inference() del workload che verrà creato e utilizzato in questo codelab. Puoi trovare il codice completo del workload qui.
def run_inference(image_path, model):
try:
# Read and preprocess the image
image = tf.image.decode_image(tf.io.read_file(image_path), channels=3)
image = tf.image.resize(image, (128, 128))
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.expand_dims(image, axis=0)
# Get predictions from the model
predictions = model(image)
predicted_class = np.argmax(predictions)
top_k = 5
top_indices = np.argsort(predictions[0])[-top_k:][::-1]
# Convert top_indices to a TensorFlow tensor
top_indices_tensor = tf.convert_to_tensor(top_indices, dtype=tf.int32)
# Use TensorFlow tensor for indexing
top_scores = tf.gather(predictions[0], top_indices_tensor)
return {
"predicted_class": int(predicted_class),
"top_k_predictions": [
{"class_index": int(idx), "score": float(score)}
for idx, score in zip(top_indices, top_scores)
],
}
except Exception as e:
return {"error": str(e)}
Esegui il seguente script per creare un carico di lavoro in cui vengono eseguiti i seguenti passaggi:
- Crea Artifact Registry(
$PRIMUS_ARTIFACT_REGISTRY) di proprietà di Primus. - Aggiorna il codice del workload con i nomi delle risorse richieste.
- Crea il carico di lavoro ML e il Dockerfile per creare un'immagine Docker del codice del carico di lavoro. Qui trovi il Dockerfile utilizzato per questo codelab.
- Crea e pubblica l'immagine Docker in Artifact Registry (
$PRIMUS_ARTIFACT_REGISTRY) di proprietà di Primus. - Concedi l'autorizzazione di lettura
$WORKLOAD_SERVICEACCOUNTper$PRIMUS_ARTIFACT_REGISTRY. È necessario che il container del workload esegua il pull dell'immagine Docker del workload da Artifact Registry.
./create_workload.sh
Inoltre, i carichi di lavoro possono essere codificati per garantire il caricamento della versione prevista del modello di machine learning controllando l'hash o la firma del modello prima di utilizzarlo. Il vantaggio di questi controlli aggiuntivi è che garantiscono l'integrità del modello di machine learning. In questo modo, l'operatore del workload dovrà anche aggiornare l'immagine del workload o i relativi parametri quando è previsto che il workload utilizzi versioni diverse del modello di ML.
4. Autorizza ed esegui il workload
Autorizza workload
Primus vuole autorizzare i carichi di lavoro ad accedere al proprio modello di machine learning in base agli attributi delle seguenti risorse:
- Cosa: codice verificato
- Dove: un ambiente sicuro
- Chi: un operatore considerato attendibile
Primus utilizza la federazione delle identità per i workload per applicare un criterio di accesso basato su questi requisiti. La federazione delle identità per i workload consente di specificare condizioni degli attributi. Queste condizioni limitano le identità che possono autenticarsi con il pool di identità del workload (WIP). Puoi aggiungere il servizio di verifica dell'attestazione al pool di identità del workload come provider del pool di identità del workload per presentare le misurazioni e applicare il criterio.
Il pool di identità del workload è già stato creato in precedenza nell'ambito del passaggio di configurazione delle risorse cloud. Ora Primus creerà un nuovo provider di pool di identità del workload OIDC. Il --attribute-condition specificato autorizza l'accesso al container del carico di lavoro. Richiede:
- Cosa: l'ultima versione di
$WORKLOAD_IMAGE_NAMEcaricata nel repository$PRIMUS_ARTIFACT_REPOSITORY. - Dove: il Trusted Execution Environment di Confidential Space viene eseguito sull'immagine VM di Confidential Space completamente supportata.
- Chi: service account Secundus
$WORKLOAD_SERVICE_ACCOUNT.
export WORKLOAD_IMAGE_DIGEST=$(gcloud artifacts docker images describe ${PRIMUS_PROJECT_REPOSITORY_REGION}-docker.pkg.dev/$PRIMUS_PROJECT_ID/$PRIMUS_ARTIFACT_REPOSITORY/$WORKLOAD_IMAGE_NAME:$WORKLOAD_IMAGE_TAG --format="value(image_summary.digest)" --project ${PRIMUS_PROJECT_ID})
gcloud config set project $PRIMUS_PROJECT_ID
gcloud iam workload-identity-pools providers create-oidc $PRIMUS_WIP_PROVIDER \
--location="global" \
--workload-identity-pool="$PRIMUS_WORKLOAD_IDENTITY_POOL" \
--issuer-uri="https://confidentialcomputing.googleapis.com/" \
--allowed-audiences="https://sts.googleapis.com" \
--attribute-mapping="google.subject='assertion.sub'" \
--attribute-condition="assertion.swname == 'CONFIDENTIAL_SPACE' &&
'STABLE' in assertion.submods.confidential_space.support_attributes &&
assertion.submods.container.image_digest == '${WORKLOAD_IMAGE_DIGEST}' &&
assertion.submods.container.image_reference == '${PRIMUS_PROJECT_REPOSITORY_REGION}-docker.pkg.dev/$PRIMUS_PROJECT_ID/$PRIMUS_ARTIFACT_REPOSITORY/$WORKLOAD_IMAGE_NAME:$WORKLOAD_IMAGE_TAG' &&
'$WORKLOAD_SERVICEACCOUNT@$SECUNDUS_PROJECT_ID.iam.gserviceaccount.com' in assertion.google_service_accounts"
Esegui workload
Nell'ambito di questo passaggio, eseguiremo il workload nella VM Confidential Space. Gli argomenti TEE obbligatori vengono passati utilizzando il flag dei metadati. Gli argomenti per il container del workload vengono passati utilizzando la parte "tee-cmd" del flag. Il risultato dell'esecuzione del workload verrà pubblicato in $SECUNDUS_RESULT_STORAGE_BUCKET.
gcloud compute instances create ${WORKLOAD_VM} \
--confidential-compute-type=SEV \
--shielded-secure-boot \
--project=${SECUNDUS_PROJECT_ID} \
--maintenance-policy=MIGRATE \
--scopes=cloud-platform --zone=${SECUNDUS_PROJECT_ZONE} \
--image-project=confidential-space-images \
--image-family=confidential-space \
--service-account=${WORKLOAD_SERVICEACCOUNT}@${SECUNDUS_PROJECT_ID}.iam.gserviceaccount.com \
--metadata ^~^tee-image-reference=${PRIMUS_PROJECT_REPOSITORY_REGION}-docker.pkg.dev/${PRIMUS_PROJECT_ID}/${PRIMUS_ARTIFACT_REPOSITORY}/${WORKLOAD_IMAGE_NAME}:${WORKLOAD_IMAGE_TAG}
Visualizza risultati
Una volta completato correttamente il carico di lavoro, il risultato del carico di lavoro di ML verrà pubblicato in $SECUNDUS_RESULT_STORAGE_BUCKET.
gsutil cat gs://$SECUNDUS_RESULT_STORAGE_BUCKET/result
Ecco alcuni esempi di come potrebbero apparire i risultati dell'inferenza sulle immagini di esempio:
Image: sample_image_1.jpeg, Response: {'predicted_class': 531, 'top_k_predictions': [{'class_index': 531, 'score': 12.08437442779541}, {'class_index': 812, 'score': 10.269512176513672}, {'class_index': 557, 'score': 9.202644348144531}, {'class_index': 782, 'score': 9.08737564086914}, {'class_index': 828, 'score': 8.912498474121094}]}
Image: sample_image_2.jpeg, Response: {'predicted_class': 905, 'top_k_predictions': [{'class_index': 905, 'score': 9.53619384765625}, {'class_index': 557, 'score': 7.928380966186523}, {'class_index': 783, 'score': 7.70129919052124}, {'class_index': 531, 'score': 7.611623287200928}, {'class_index': 906, 'score': 7.021416187286377}]}
Image: sample_image_3.jpeg, Response: {'predicted_class': 905, 'top_k_predictions': [{'class_index': 905, 'score': 6.09878396987915}, {'class_index': 447, 'score': 5.992854118347168}, {'class_index': 444, 'score': 5.9582319259643555}, {'class_index': 816, 'score': 5.502010345458984}, {'class_index': 796, 'score': 5.450454235076904}]}
Per ogni immagine di esempio in un bucket di archiviazione Secundus, vedrai una voce nei risultati. Questa voce includerà due informazioni chiave:
- Indice di predicted_class: si tratta di un indice numerico che rappresenta la classe a cui il modello prevede che appartenga l'immagine.
- Top_k_predictions::fornisce fino a k previsioni per l'immagine, classificate dalla più probabile alla meno probabile. Il valore di k è impostato su 5 in questo codelab, ma puoi modificarlo nel codice del carico di lavoro per ottenere più o meno previsioni.
Per tradurre l'indice della classe in un nome leggibile, consulta l'elenco delle etichette disponibili qui. Ad esempio, se vedi un indice di classe pari a 2, questo corrisponde all'etichetta di classe "tinca" nell'elenco delle etichette.
In questo codelab abbiamo dimostrato che un modello di proprietà di Primus viene rilasciato solo al carico di lavoro in esecuzione in un TEE. Secundus esegue il carico di lavoro ML in un TEE e questo carico di lavoro è in grado di utilizzare il modello di proprietà di Primus, mentre Primus mantiene il controllo completo sul modello.
Esegui carico di lavoro non autorizzato
Secundus modifica l'immagine del workload estraendo un'immagine del workload diversa dal proprio repository di artefatti, che non è autorizzato da Primus. Il pool di identità del workload di Primus ha autorizzato solo l'immagine del workload ${PRIMUS_PROJECT_REPOSITORY_REGION}-docker.pkg.dev/$PRIMUS_PROJECT_ID/$PRIMUS_ARTIFACT_REPOSITORY/$WORKLOAD_IMAGE_NAME:$WORKLOAD_IMAGE_TAG.
Esegui nuovamente il workload
Quando Secundus tenta di eseguire il workload originale con questa nuova immagine del workload, l'operazione non va a buon fine. Per visualizzare l'errore, elimina il file dei risultati originale e l'istanza VM, quindi prova a eseguire di nuovo il workload.
Assicurati che sia stata pubblicata una nuova immagine Docker in Artifact Registry di Secundus (come us-docker.pkg.dev/${SECUNDUS_PROJECT_ID}/custom-image/${WORKLOAD_IMAGE_NAME}:${WORKLOAD_IMAGE_TAG}) e che al service account del workload ($WORKLOAD_SERVICEACCOUNT) sia stata concessa l'autorizzazione di lettura di Artifact Registry per leggere questa nuova immagine del workload. Questo per garantire che il workload non venga chiuso prima che il criterio WIP di Primus rifiuti il token presentato dal workload.
Elimina il file dei risultati e l'istanza VM esistenti
- Imposta il progetto sul progetto
$SECUNDUS_PROJECT_ID.
gcloud config set project $SECUNDUS_PROJECT_ID
- Elimina il file dei risultati.
gsutil rm gs://$SECUNDUS_RESULT_STORAGE_BUCKET/result
- Elimina l'istanza Confidential VM.
gcloud compute instances delete ${WORKLOAD_VM} --zone=${SECUNDUS_PROJECT_ZONE}
Esegui il carico di lavoro non autorizzato:
gcloud compute instances create ${WORKLOAD_VM} \
--confidential-compute-type=SEV \
--shielded-secure-boot \
--maintenance-policy=MIGRATE \
--scopes=cloud-platform --zone=${SECUNDUS_PROJECT_ZONE} \
--image-project=confidential-space-images \
--image-family=confidential-space \
--service-account=${WORKLOAD_SERVICEACCOUNT}@${SECUNDUS_PROJECT_ID}.iam.gserviceaccount.com \
--metadata ^~^tee-image-reference=us-docker.pkg.dev/${SECUNDUS_PROJECT_ID}/custom-image/${WORKLOAD_IMAGE_NAME}:${WORKLOAD_IMAGE_TAG}
Visualizza errore
Al posto dei risultati del workload, viene visualizzato un errore (The given credential is rejected by the attribute condition).
gsutil cat gs://$SECUNDUS_RESULT_STORAGE_BUCKET/result
5. Elimina
Qui trovi lo script che può essere utilizzato per liberare spazio dalle risorse che abbiamo creato nell'ambito di questo codelab. Nell'ambito di questa pulizia, verranno eliminate le seguenti risorse:
- Bucket di archiviazione di input di Primus (
$PRIMUS_INPUT_STORAGE_BUCKET). - Account di servizio Primus (
$PRIMUS_SERVICEACCOUNT). - Repository di artefatti di Primus (
$PRIMUS_ARTIFACT_REPOSITORY). - Pool di identità del workload Primus (
$PRIMUS_WORKLOAD_IDENTITY_POOL). - Service account del workload di Secundus (
$WORKLOAD_SERVICEACCOUNT). - Bucket di archiviazione di input di Secundus (
$SECUNDUS_INPUT_STORAGE_BUCKET). - Istanze di calcolo del workload.
- Bucket di archiviazione dei risultati di Secundus (
$SECUNDUS_RESULT_STORAGE_BUCKET).
$ ./cleanup.sh
Se hai terminato l'esplorazione, valuta la possibilità di eliminare il progetto.
- Vai alla console di Cloud Platform.
- Seleziona il progetto che vuoi chiudere, quindi fai clic su "Elimina" in alto: il progetto verrà pianificato per l'eliminazione.
Passaggi successivi
Dai un'occhiata ad alcuni di questi codelab simili…