
1. Introduction
Les récentes avancées en matière de deep learning ont permis de représenter du texte et d'autres données de manière à capturer leur signification sémantique. Cela a conduit à une nouvelle approche de la recherche, appelée recherche vectorielle, qui utilise des représentations vectorielles de texte (appelées embeddings) pour trouver les documents les plus pertinents pour la requête d'un utilisateur. La recherche vectorielle est préférable à la recherche traditionnelle pour les applications telles que la recherche de vêtements, où les utilisateurs recherchent souvent des articles par leur description, leur style ou leur contexte plutôt que par le nom exact du produit ou de la marque. Nous pouvons intégrer la base de données Cloud Spanner à Vector Search pour effectuer une mise en correspondance de similarité vectorielle. En utilisant Spanner et Vector Search ensemble, les clients peuvent créer une intégration puissante qui combine la disponibilité, la fiabilité et l'évolutivité de Spanner, ainsi que les fonctionnalités avancées de recherche de similarité de Vertex AI Vector Search. Cette recherche est effectuée en comparant les embeddings des éléments dans l'index Vector Search et en renvoyant les correspondances les plus similaires.
Cas d'utilisation
Imaginez que vous êtes un data scientist chez un détaillant de mode et que vous essayez de suivre les tendances, les recherches de produits et les recommandations en constante évolution. Le problème est que vous disposez de ressources et de silos de données limités. Cet article de blog explique comment implémenter un cas d'utilisation de recommandation de vêtements à l'aide d'une approche de recherche de similarité sur les données de vêtements.Les étapes suivantes sont abordées :
- Données provenant de Spanner
- Vecteurs générés pour les données de vêtements à l'aide de ML.PREDICT et stockés dans Spanner
- Données vectorielles Spanner intégrées à Vector Search à l'aide de tâches Dataflow et Workflow
- Recherche vectorielle effectuée pour trouver une correspondance de similarité pour l'entrée saisie par l'utilisateur
Nous allons créer une application Web de démonstration pour effectuer une recherche de vêtements en fonction du texte saisi par l'utilisateur. L'application permet aux utilisateurs de rechercher des vêtements en saisissant une description textuelle.
Spanner vers l'index Vector Search :
Les données de recherche de vêtements sont stockées dans Spanner. Nous allons appeler l'API Vertex AI Embeddings dans la construction ML.PREDICT directement à partir des données Spanner. Nous allons ensuite exploiter les tâches Dataflow et Workflow qui importent ces données (inventaire et embeddings) dans Vertex AI Vector Search et actualisent l'index.
Exécution des requêtes utilisateur sur l'index :
Lorsqu'un utilisateur saisit une description de vêtements, l'application génère les embeddings en temps réel à l'aide de l'API Text Embeddings. Celles-ci sont ensuite envoyées en entrée à l'API Vector Search pour trouver 10 descriptions de produits pertinentes dans l'index et afficher l'image correspondante.
Présentation de l'architecture
L'architecture de l'application Spanner-Vector Search est illustrée dans le schéma en deux parties suivant :
Spanner vers l'index Vector Search : 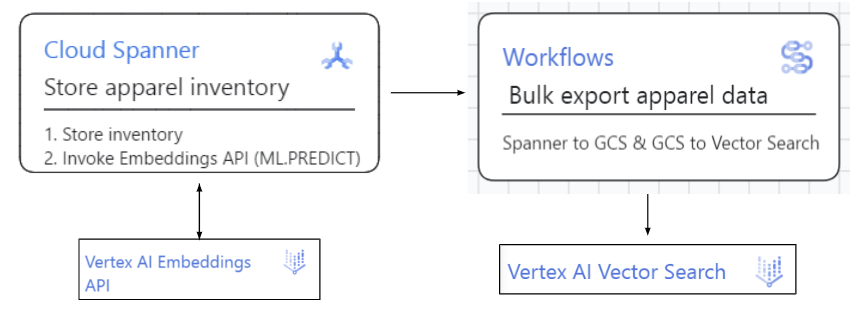
Application cliente pour exécuter les requêtes utilisateur sur l'index :
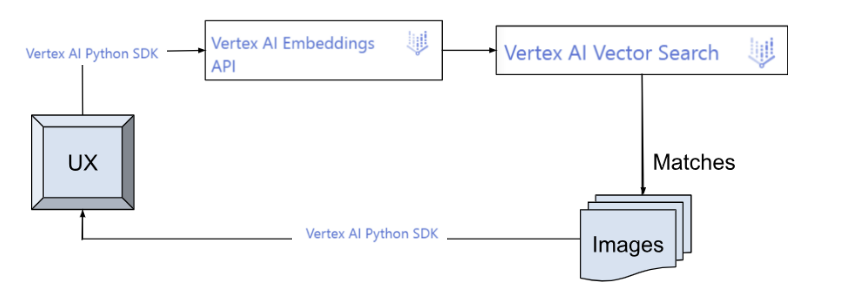 Ce que vous allez créer
Ce que vous allez créer
Spanner vers l'index vectoriel :
- Base de données Spanner pour stocker et gérer les données sources et les embeddings correspondants
- Tâche Workflow qui importe des données (ID et embeddings) dans la base de données Vertex AI Vector Search.
- API Vector Search utilisée pour trouver des descriptions de produits pertinentes dans l'index.
Exécution des requêtes utilisateur sur l'index :
- Application Web qui permet aux utilisateurs de saisir des descriptions textuelles de vêtements, d'effectuer une recherche de similarité à l'aide du point de terminaison d'index déployé et de renvoyer les vêtements les plus proches de l'entrée.
Fonctionnement
Lorsqu'un utilisateur saisit une description textuelle de vêtements, l'application Web envoie la description à l'API Vector Search. L'API Vector Search utilise ensuite les embeddings des descriptions de vêtements pour trouver les descriptions de produits les plus pertinentes dans l'index. Les descriptions de produits et les images correspondantes sont ensuite affichées à l'utilisateur. Voici le workflow général :
- Générez des embeddings pour les données stockées dans Spanner.
- Exportez et importez les embeddings dans un index Vector Search.
- Interrogez l'index Vector Search pour trouver des éléments similaires en effectuant une recherche des voisins les plus proches.
2. Conditions requises
Avant de commencer
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée pour un projet.
- Assurez-vous que toutes les API nécessaires (Cloud Spanner, Vertex AI, Google Cloud Storage) sont activées
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud et fourni avec gcloud. Consultez la documentation pour connaître les commandes gcloud ainsi que leur utilisation. Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
gcloud config set project <YOUR_PROJECT_ID>
- Accédez à la page Cloud Spanner avec votre projet Google Cloud actif pour commencer.
3. Backend : créez votre source de données et vos embeddings Spanner
Dans ce cas d'utilisation, la base de données Spanner contient l'inventaire des vêtements avec les images et la description correspondantes. Assurez-vous de générer des embeddings pour la description textuelle et de les stocker dans votre base de données Spanner au format ARRAY<float64>.
- Créer les données Spanner
Créez une instance nommée "spanner-vertex" et une base de données nommée "spanner-vertex-embeddings". Créez une table à l'aide du LDD :
CREATE TABLE
apparels ( id NUMERIC,
category STRING(100),
sub_category STRING(50),
uri STRING(200),
content STRING(2000),
embedding ARRAY<FLOAT64>
)
PRIMARY KEY
(id);
- Insérez des données dans la table à l'aide de l'instruction SQL INSERT
Des scripts d'insertion pour des exemples de données sont disponibles ici.
- Créer un modèle d'embeddings textuels
Cela est nécessaire pour que nous puissions générer des embeddings pour le contenu de l'entrée. Voici le LDD correspondant :
CREATE MODEL text_embeddings INPUT(content STRING(MAX))
OUTPUT(
embeddings
STRUCT<
statistics STRUCT<truncated BOOL, token_count FLOAT64>,
values ARRAY<FLOAT64>>
)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/abis-345004/locations/us-central1/publishers/google/models/textembedding-gecko');
- Générer des embeddings textuels pour les données sources
Créez une table pour stocker les embeddings et insérez les embeddings générés. Dans une application de base de données réelle, le chargement des données dans Spanner jusqu'à l'étape 2 serait transactionnel. Afin de respecter les bonnes pratiques de conception, je préfère conserver les tables transactionnelles normalisées et créer une table distincte pour les embeddings.
CREATE TABLE apparels_embeddings (id string(100), embedding ARRAY<FLOAT64>)
PRIMARY KEY (id);
INSERT INTO apparels_embeddings(id, embeddings)
SELECT CAST(id as string), embeddings.values
FROM ML.PREDICT(
MODEL text_embeddings,
(SELECT id, content from apparels)
) ;
Maintenant que le contenu et les embeddings sont prêts, créons un index et un point de terminaison Vector Search pour stocker les embeddings qui nous aideront à effectuer la recherche vectorielle.
4. Tâche Workflow : exporter des données Spanner vers Vector Search
- Créer un bucket Cloud Storage
Cela est nécessaire pour stocker les embeddings de Spanner dans un bucket GCS au format JSON attendu par Vector Search en entrée. Créez un bucket dans la même région que vos données dans Spanner. Créez un dossier si nécessaire, mais surtout créez-y un fichier vide nommé empty.json.
- Configurer Cloud Workflow
Pour configurer une exportation par lot de Spanner vers un index Vertex AI Vector Search :
Créer un index vide :
Assurez-vous que l'index Vector Search se trouve dans la même région que votre bucket Cloud Storage et les données. Suivez les 11 étapes d'instructions sous l'onglet "Console" de la section Créer un index pour la mise à jour par lot de la page "Gérer les index". Dans le dossier transmis à contentsDeltaUri, créez un fichier vide nommé empty.json, car vous ne pourrez pas créer d'index sans ce fichier. Cela crée un index vide.
Si vous disposez déjà d'un index, vous pouvez ignorer cette étape. Le workflow écrasera votre index.
Remarque : Vous ne pouvez pas déployer un index vide sur un point de terminaison. Nous reportons donc l'étape de déploiement sur un point de terminaison à une étape ultérieure, après avoir exporté les données vectorielles vers Cloud Storage.
Cloner ce dépôt Git : il existe plusieurs façons de cloner un dépôt Git. L'une d'elles consiste à exécuter la commande suivante à l'aide de l'interface de ligne de commande GitHub. Exécutez les deux commandes ci-dessous à partir du terminal Cloud Shell :
gh repo clone cloudspannerecosystem/spanner-ai
cd spanner-ai/vertex-vector-search/workflows
Ce dossier contient deux fichiers :
batch-export.yaml: il s'agit de la définition du workflow.sample-batch-input.json: il s'agit d'un exemple des paramètres d'entrée du workflow.
Configurer input.json à partir de l'exemple de fichier : commencez par copier l'exemple JSON.
cp sample-batch-input.json input.json
Modifiez ensuite input.json avec les détails de votre projet. Dans ce cas, votre fichier JSON doit se présenter comme suit :
{
"project_id": "<<YOUR_PROJECT>>",
"location": "<<us-central1>>",
"dataflow": {
"temp_location": "gs://<<YOUR_BUCKET>>/<<FOLDER_IF_ANY>>/workflow_temp"
},
"gcs": {
"output_folder": "gs://<<YOUR_BUCKET>>/<<FOLDER_IF_ANY>>/workflow_output"
},
"spanner": {
"instance_id": "spanner-vertex",
"database_id": "spanner-vertex-embeddings",
"table_name": "apparels_embeddings",
"columns_to_export": "embedding,id"
},
"vertex": {
"vector_search_index_id": "<<YOUR_INDEX_ID>>"
}
}
Configurer les autorisations
Pour les environnements de production, nous vous recommandons vivement de créer un compte de service et de lui attribuer un ou plusieurs rôles IAM contenant les autorisations minimales requises pour gérer le service. Les rôles suivants sont nécessaires pour configurer le workflow afin d'exporter des données (embeddings) de Spanner vers l'index Vector Search :
Compte de service Cloud Workflow :
Par défaut, il utilise le compte de service Compute Engine par défaut.
Si vous utilisez un compte de service configuré manuellement, vous devez inclure les rôles suivants :
Pour déclencher une tâche Dataflow : Administrateur Dataflow, Nœud de calcul Dataflow.
Pour emprunter l'identité d'un compte de service de nœud de calcul Dataflow : Utilisateur du compte de service.
Pour écrire des journaux : Rédacteur de journaux.
Pour déclencher la reconstruction de Vertex AI Vector Search : Utilisateur Vertex AI.
Compte de service de nœud de calcul Dataflow :
Si vous utilisez un compte de service configuré manuellement, vous devez inclure les rôles suivants :
Pour gérer Dataflow : Administrateur Dataflow, Nœud de calcul Dataflow. Pour lire des données à partir de Spanner : Lecteur de base de données Cloud Spanner Accès en écriture sur le registre de conteneurs GCS sélectionné : Propriétaire du bucket de stockage GCS.
- Déployer Cloud Workflow
Déployez le fichier YAML du workflow dans votre projet Google Cloud. Vous pouvez configurer la région ou l'emplacement où le workflow sera exécuté.
gcloud workflows deploy vector-export-workflow --source=batch-export.yaml --location="us-central1" [--service account=<service_account>]
or
gcloud workflows deploy vector-export-workflow --source=batch-export.yaml --location="us-central1"
Le workflow doit maintenant être visible sur la page "Workflows" de la console Google Cloud.
Remarque : Vous pouvez également créer et déployer le workflow à partir de la console Google Cloud. Suivez les instructions de la console Cloud. Pour la définition du workflow, copiez et collez le contenu de batch-export.yaml.
Une fois cette opération terminée, exécutez le workflow pour que l'exportation des données commence.
- Exécuter Cloud Workflow
Exécutez la commande suivante pour exécuter le workflow :
gcloud workflows execute vector-export-workflow --data="$(cat input.json)"
L'exécution doit s'afficher dans l'onglet "Exécutions" de Workflows. Vos données doivent être chargées dans la base de données Vector Search et indexées.
Remarque : Vous pouvez également exécuter à partir de la console à l'aide du bouton "Exécuter". Suivez les instructions et, pour l'entrée, copiez et collez le contenu de votre fichier input.json personnalisé.
5. Déployer l'index Vector Search
Déployer l'index sur un point de terminaison
Vous pouvez suivre les étapes ci-dessous pour déployer l'index :
- Sur la page des index Vector Search, vous devriez voir un bouton "DÉPLOYER" à côté de l'index que vous venez de créer à l'étape 2 de la section précédente. Vous pouvez également accéder à la page d'informations de l'index et cliquer sur le bouton "DÉPLOYER SUR LE POINT DE TERMINAISON".
- Fournissez les informations nécessaires et déployez l'index sur un point de terminaison.
Vous pouvez également consulter ce notebook pour le déployer sur un point de terminaison (passez à la partie "Déployer" du notebook). Une fois le déploiement effectué, notez l'ID de l'index déployé et l'URL du point de terminaison.
6. Frontend : données utilisateur vers Vector Search
Créons une application Python simple avec une UX basée sur Gradio pour tester rapidement notre implémentation. Vous pouvez vous reporter à l’implémentation ici pour implémenter cette application de démonstration dans votre propre notebook Colab.
- Nous allons utiliser le SDK Python aiplatform pour appeler l'API Embeddings et pour appeler le point de terminaison d'index Vector Search.
# [START aiplatform_sdk_embedding]
!pip install google-cloud-aiplatform==1.35.0 --upgrade --quiet --user
import vertexai
vertexai.init(project=PROJECT_ID, location="us-central1")
from vertexai.language_models import TextEmbeddingModel
import sys
if "google.colab" in sys.modules:
# Define project information
PROJECT_ID = " " # Your project id
LOCATION = " " # Your location
# Authenticate user to Google Cloud
from google.colab import auth
auth.authenticate_user()
- Nous allons utiliser Gradio pour présenter l'application d'IA que nous créons rapidement et facilement avec une interface utilisateur. Redémarrez l'environnement d'exécution avant d'implémenter cette étape.
!pip install gradio
import gradio as gr
- À partir de l'application Web, lors de la saisie de l'utilisateur, appelez l'API Embeddings. Nous allons utiliser le modèle d'embeddings textuels : textembedding-gecko@latest.
La méthode ci-dessous appelle le modèle d'embeddings textuels et renvoie les embeddings vectoriels pour le texte saisi par l'utilisateur :
def text_embedding(content) -> list:
"""Text embedding with a Large Language Model."""
model = TextEmbeddingModel.from_pretrained("textembedding-gecko@latest")
embeddings = model.get_embeddings(content)
for embedding in embeddings:
vector = embedding.values
#print(f"Length of Embedding Vector: {len(vector)}")
return vector
Tester
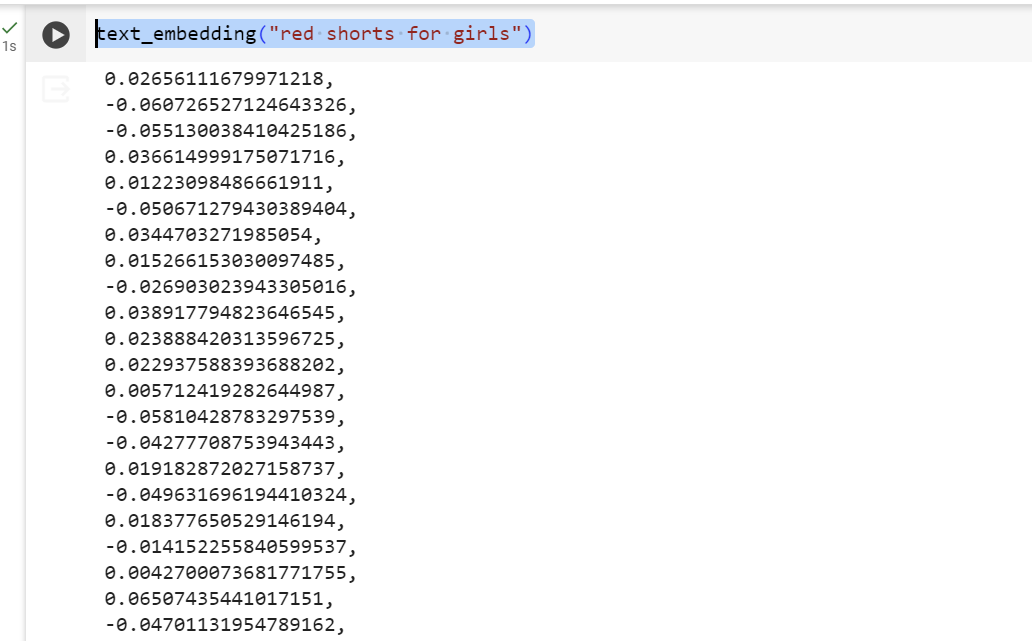
text_embedding("red shorts for girls")
Vous devriez obtenir un résultat semblable à celui ci-dessous (veuillez noter que l'image est rognée en hauteur, vous ne pouvez donc pas voir l'intégralité de la réponse vectorielle) :
- Déclarez l'ID de l'index déployé et l'ID du point de terminaison.
from google.cloud import aiplatform
DEPLOYED_INDEX_ID = "spanner_vector1_1702366982123"
#Vector Search Endpoint
index_endpoint = aiplatform.MatchingEngineIndexEndpoint('projects/273845608377/locations/us-central1/indexEndpoints/2021628049526620160')
- Définissez la méthode Vector Search pour appeler le point de terminaison d'index et afficher le résultat avec les 10 correspondances les plus proches pour la réponse d'embedding correspondant au texte saisi par l'utilisateur.
Dans la définition de méthode ci-dessous pour Vector Search, notez que la méthode find_neighbors est appelée pour identifier les 10 vecteurs les plus proches.
def vector_search(content) -> list:
result = text_embedding(content)
#call_vector_search_api(content)
index_endpoint = aiplatform.MatchingEngineIndexEndpoint('projects/273845608377/locations/us-central1/indexEndpoints/2021628049526620160')
# run query
response = index_endpoint.find_neighbors(
deployed_index_id = DEPLOYED_INDEX_ID,
queries = [result],
num_neighbors = 10
)
out = []
# show the results
for idx, neighbor in enumerate(response[0]):
print(f"{neighbor.distance:.2f} {spanner_read_data(neighbor.id)}")
out.append(f"{spanner_read_data(neighbor.id)}")
return out
Vous remarquerez également l'appel à la méthode spanner_read_data. Examinons-la à l'étape suivante.
- Définissez l'implémentation de la méthode de lecture des données Spanner qui appelle la méthode execute_sql pour extraire les images correspondant aux ID des vecteurs voisins les plus proches renvoyés à l'étape précédente.
!pip install google-cloud-spanner==3.36.0
from google.cloud import spanner
instance_id = "spanner-vertex"
database_id = "spanner-vertex-embeddings"
projectId = PROJECT_ID
client = spanner.Client()
client.project = projectId
instance = client.instance(instance_id)
database = instance.database(database_id)
def spanner_read_data(id):
query = "SELECT uri FROM apparels where id = " + id
outputs = []
with database.snapshot() as snapshot:
results = snapshot.execute_sql(query)
for row in results:
#print(row)
#output = "ID: {}, CONTENT: {}, URI: {}".format(*row)
output = "{}".format(*row)
outputs.append(output)
return "\n".join(outputs)
Elle doit renvoyer les URL des images correspondant aux vecteurs choisis.
- Enfin, assemblons les éléments dans une interface utilisateur et déclenchons le processus Vector Search.
from PIL import Image
def call_search(query):
response = vector_search(query)
return response
input_text = gr.Textbox(label="Enter your query. Examples: Girls Tops White Casual, Green t-shirt girls, jeans shorts, denim skirt etc.")
output_texts = [gr.Image(label="") for i in range(10)]
demo = gr.Interface(fn=call_search, inputs=input_text, outputs=output_texts, live=True)
resp = demo.launch(share = True)
Le résultat doit s'afficher comme suit :
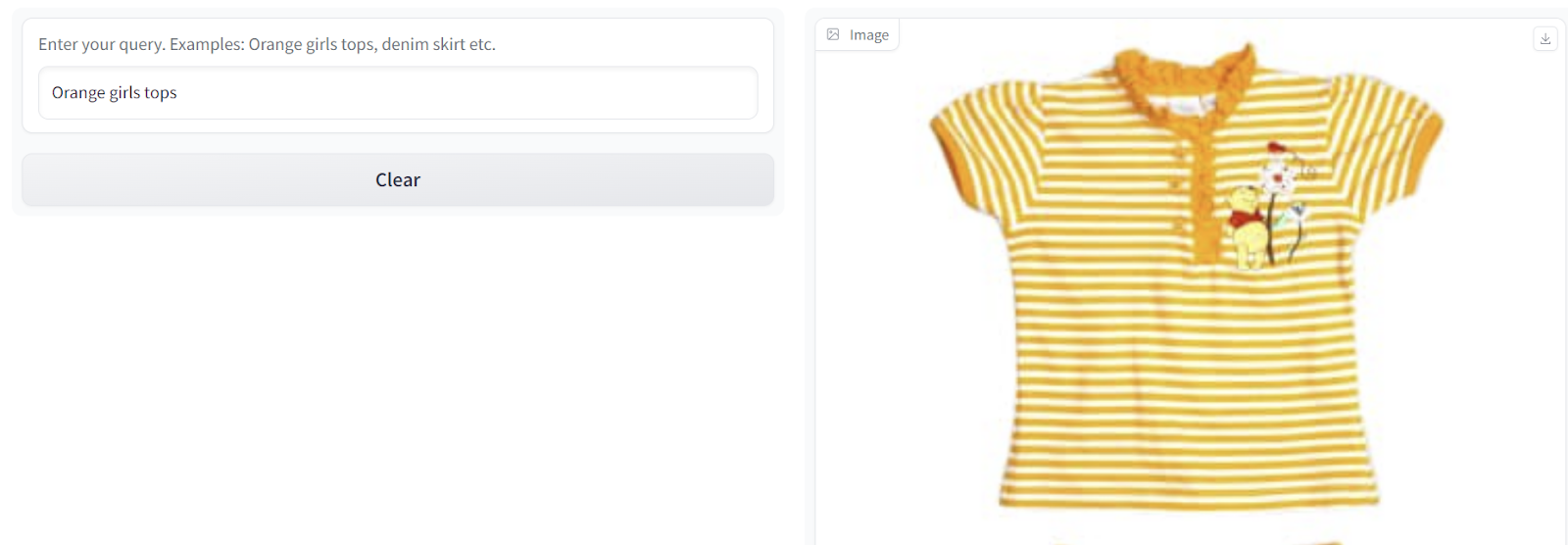
Image : lien
Regardez la vidéo du résultat : ici.
7. Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cet atelier soient facturées sur votre compte Google Cloud, procédez comme suit :
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur "Supprimer".
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur "Arrêter" pour supprimer le projet.
- Si vous ne souhaitez pas supprimer le projet, supprimez l'instance Spanner en accédant à l'instance que vous venez de créer pour ce projet, puis cliquez sur le bouton "SUPPRIMER L'INSTANCE" en haut à droite de la page de présentation de l'instance.
- Vous pouvez également accéder à l'index Vector Search, annuler le déploiement du point de terminaison et de l'index, puis supprimer l'index.
8. Conclusion
Félicitations ! Vous avez implémenté avec succès la recherche vectorielle Spanner-Vertex en :
- créant une source de données et des embeddings Spanner pour les applications provenant de la base de données Spanner ;
- créant un index de base de données Vector Search ;
- intégrant des données vectorielles de Spanner à Vector Search à l'aide de tâches Dataflow et Workflow ;
- déployant l'index sur un point de terminaison ;
- appelant enfin Vector Search sur l'entrée utilisateur dans une implémentation du SDK Vertex AI basée sur Python.
N'hésitez pas à étendre l'implémentation à votre propre cas d'utilisation ou à improviser le cas d'utilisation actuel avec de nouvelles fonctionnalités. Pour en savoir plus sur les fonctionnalités de machine learning de Spanner, cliquez ici.