
1. Einführung
Dank der jüngsten Fortschritte im Bereich des Deep Learnings können Text und andere Daten so dargestellt werden, dass die semantische Bedeutung erfasst wird. Dies hat zu einem neuen Suchansatz geführt, der als Vektorsuche bezeichnet wird. Dabei werden Vektordarstellungen von Text (Einbettungen) verwendet, um Dokumente zu finden, die für die Abfrage eines Nutzers am relevantesten sind. Die Vektorsuche wird gegenüber der herkömmlichen Suche für Anwendungen wie die Bekleidungssuche bevorzugt, bei der Nutzer häufig nach Artikeln anhand ihrer Beschreibung, ihres Stils oder ihres Kontexts suchen und nicht nach genauen Produkt- oder Markennamen. Wir können die Cloud Spanner-Datenbank in die Vektorsuche einbinden, um eine Vektorähnlichkeitsübereinstimmung durchzuführen. Durch die gemeinsame Verwendung von Spanner und der Vektorsuche können Kunden eine leistungsstarke Integration erstellen, die die Verfügbarkeit, Zuverlässigkeit und Skalierbarkeit von Spanner mit den erweiterten Funktionen der Ähnlichkeitssuche der Vektorsuche in Vertex AI kombiniert. Diese Suche wird durchgeführt, indem Einbettungen von Elementen im Vektorsuchindex verglichen und die ähnlichsten Übereinstimmungen zurückgegeben werden.
Anwendungsfall
Stellen Sie sich vor, Sie sind Data Scientist bei einem Modehändler und müssen mit den sich schnell ändernden Trends, Produktsuchen und Empfehlungen Schritt halten. Die Herausforderung besteht darin, dass Sie nur begrenzte Ressourcen und Datensilos haben. In diesem Blogpost wird gezeigt, wie Sie einen Anwendungsfall für Bekleidungsempfehlungen mithilfe der Ähnlichkeitssuche für Bekleidungsdaten implementieren.Die folgenden Schritte werden behandelt:
- Daten aus Spanner
- Vektoren, die für die Bekleidungsdaten mit ML.PREDICT generiert und in Spanner gespeichert wurden
- Spanner-Vektordaten, die mit Dataflow- und Workflow-Jobs in die Vektorsuche eingebunden wurden
- Vektorsuche, die durchgeführt wurde, um eine Ähnlichkeitsübereinstimmung für die vom Nutzer eingegebene Eingabe zu finden
Wir erstellen eine Demo-Webanwendung, um die Bekleidungssuche basierend auf vom Nutzer eingegebenem Text durchzuführen. Mit der Anwendung können Nutzer nach Bekleidung suchen, indem sie eine Textbeschreibung eingeben.
Spanner-zu-Vektorsuchindex:
Die Daten für die Bekleidungssuche werden in Spanner gespeichert. Wir rufen die Vertex AI Embeddings API im ML.PREDICT-Konstrukt direkt aus Spanner-Daten auf. Anschließend nutzen wir die Dataflow- und Workflow-Jobs, mit denen diese Daten (Inventar und Einbettungen) in die Vektorsuche von Vertex AI hochgeladen und der Index aktualisiert wird.
Nutzerabfragen für den Index ausführen:
Wenn ein Nutzer eine Bekleidungsbeschreibung eingibt, generiert die App die Einbettungen in Echtzeit mit der Text Embeddings API. Diese wird dann als Eingabe an die Vektorsuch-API gesendet, um 10 relevante Produktbeschreibungen aus dem Index zu finden und das entsprechende Bild anzuzeigen.
Überblick über die Architektur
Die Architektur der Spanner-Vektorsuchanwendung ist im folgenden zweiteiligen Diagramm dargestellt:
Spanner-zu-Vektorsuchindex: 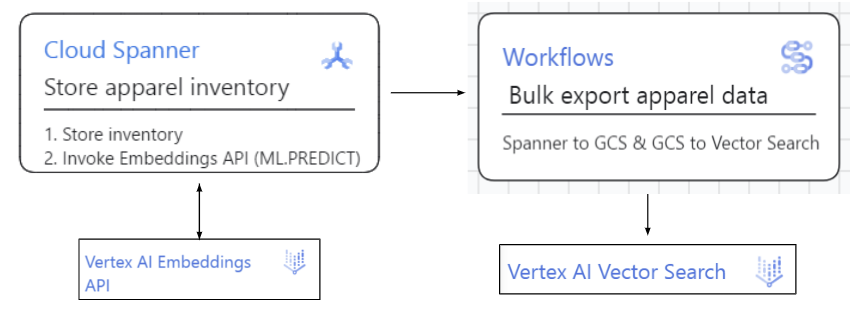
Client-App zum Ausführen von Nutzerabfragen für den Index:
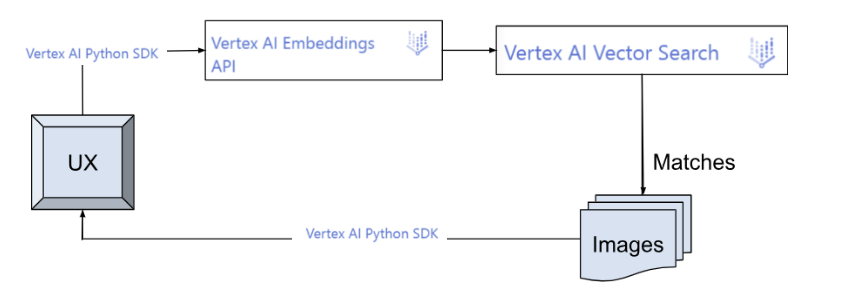 Aufgaben
Aufgaben
Spanner-zu-Vektorindex:
- Spanner-Datenbank zum Speichern und Verwalten von Quelldaten und den entsprechenden Einbettungen
- Ein Workflow-Job, mit dem Daten (ID und Einbettungen) in die Vektorsuchdatenbank von Vertex AI hochgeladen werden.
- Eine Vektorsuch-API, mit der relevante Produktbeschreibungen aus dem Index gefunden werden.
Nutzerabfragen für den Index ausführen:
- Eine Webanwendung, mit der Nutzer Textbeschreibungen von Bekleidung eingeben können. Sie führt eine Ähnlichkeitssuche mit dem bereitgestellten Indexendpunkt durch und gibt die ähnlichsten Kleidungsstücke zur Eingabe zurück.
So gehts
Wenn ein Nutzer eine Textbeschreibung von Bekleidung eingibt, sendet die Webanwendung die Beschreibung an die Vektorsuch-API. Die Vektorsuch-API verwendet dann die Einbettungen der Bekleidungsbeschreibungen, um die relevantesten Produktbeschreibungen aus dem Index zu finden. Die Produktbeschreibungen und die entsprechenden Bilder werden dann dem Nutzer angezeigt. Dies ist der allgemeine Workflow:
- Einbettungen generieren für in Spanner gespeicherte Daten.
- Einbettungen exportieren und in einen Vektorsuchindex hochladen.
- Den Vektorsuchindex nach ähnlichen Elementen abfragen, indem Sie eine Suche nach dem nächsten Nachbarn durchführen.
2. Voraussetzungen
Hinweis
- Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist
- Achten Sie darauf, dass alle erforderlichen APIs (Cloud Spanner, Vertex AI, Google Cloud Storage) aktiviert sind
- Sie verwenden die Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird und in der gcloud vorinstalliert ist. Weitere Informationen finden Sie in der Dokumentation zu gcloud-Befehlen und ihrer Verwendung. Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
gcloud config set project <YOUR_PROJECT_ID>
- Rufen Sie die Cloud Spanner-Seite mit Ihrem aktiven Google Cloud-Projekt auf, um zu beginnen.
3. Backend: Spanner-Datenquelle und Einbettungen erstellen
In diesem Anwendungsfall enthält die Spanner-Datenbank das Inventar an Bekleidung mit den entsprechenden Bildern und Beschreibungen. Achten Sie darauf, dass Sie Einbettungen für die Textbeschreibung generieren und sie in Ihrer Spanner-Datenbank als ARRAY<float64> speichern.
- Spanner-Daten erstellen
Erstellen Sie eine Instanz mit dem Namen „spanner-vertex“ und eine Datenbank mit dem Namen „spanner-vertex-embeddings“. Erstellen Sie eine Tabelle mit der DDL:
CREATE TABLE
apparels ( id NUMERIC,
category STRING(100),
sub_category STRING(50),
uri STRING(200),
content STRING(2000),
embedding ARRAY<FLOAT64>
)
PRIMARY KEY
(id);
- Daten mit dem INSERT-SQL in die Tabelle einfügen
Einfügeskripts für Beispieldaten sind hier verfügbar.
- Texteinbettungsmodell erstellen
Dies ist erforderlich, damit wir Einbettungen für die Inhalte in der Eingabe generieren können. Unten sehen Sie die DDL dafür:
CREATE MODEL text_embeddings INPUT(content STRING(MAX))
OUTPUT(
embeddings
STRUCT<
statistics STRUCT<truncated BOOL, token_count FLOAT64>,
values ARRAY<FLOAT64>>
)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/abis-345004/locations/us-central1/publishers/google/models/textembedding-gecko');
- Texteinbettungen für die Quelldaten generieren
Erstellen Sie eine Tabelle zum Speichern der Einbettungen und fügen Sie die generierten Einbettungen ein. In einer realen Datenbankanwendung wäre der Datenlast in Spanner bis Schritt 2 transaktional. Um die Best Practices für das Design beizubehalten, bevorzuge ich es, die transaktionalen Tabellen zu normalisieren und daher eine separate Tabelle für Einbettungen zu erstellen.
CREATE TABLE apparels_embeddings (id string(100), embedding ARRAY<FLOAT64>)
PRIMARY KEY (id);
INSERT INTO apparels_embeddings(id, embeddings)
SELECT CAST(id as string), embeddings.values
FROM ML.PREDICT(
MODEL text_embeddings,
(SELECT id, content from apparels)
) ;
Nachdem die Bulk-Inhalte und Einbettungen fertig sind, erstellen wir einen Vektorsuchindex und einen Endpunkt, um die Einbettungen zu speichern, die für die Vektorsuche verwendet werden.
4. Workflow-Job: Spanner-Daten in die Vektorsuche exportieren
- Cloud Storage-Bucket erstellen
Dies ist erforderlich, um Einbettungen aus Spanner in einem GCS-Bucket im JSON-Format zu speichern, das von der Vektorsuche als Eingabe erwartet wird. Erstellen Sie einen Bucket in derselben Region wie Ihre Daten in Spanner. Erstellen Sie bei Bedarf einen Ordner und darin eine leere Datei mit dem Namen „empty.json“.
- Cloud Workflow einrichten
So richten Sie einen Batch-Export von Spanner in einen Vektorsuchindex von Vertex AI ein:
Leeren Index erstellen:
Achten Sie darauf, dass sich der Vektorsuchindex in derselben Region wie Ihr Cloud Storage-Bucket und die Daten befindet. Folgen Sie der 11-stufigen Anleitung auf dem Tab „Console“ im Abschnitt „Index für Batch-Update erstellen“ auf der Seite „Indexe verwalten“. Erstellen Sie in dem Ordner, der an „contentsDeltaUri“ übergeben wird, eine leere Datei mit dem Namen „empty.json“, da Sie ohne diese Datei keinen Index erstellen können. Dadurch wird ein leerer Index erstellt.
Wenn Sie bereits einen Index haben, können Sie diesen Schritt überspringen. Der Workflow überschreibt Ihren Index.
Hinweis: Sie können keinen leeren Index auf einem Endpunkt bereitstellen. Daher verschieben wir den Schritt der Bereitstellung auf einem Endpunkt auf einen späteren Zeitpunkt, nachdem die Vektordaten in Cloud Storage exportiert wurden.
Dieses Git-Repository klonen: Es gibt mehrere Möglichkeiten, ein Git-Repository zu klonen. Eine Möglichkeit besteht darin, den folgenden Befehl mit der GitHub CLI auszuführen. Führen Sie die folgenden beiden Befehle im Cloud Shell-Terminal aus:
gh repo clone cloudspannerecosystem/spanner-ai
cd spanner-ai/vertex-vector-search/workflows
Dieser Ordner enthält zwei Dateien:
batch-export.yaml: Dies ist die Workflow-Definition.sample-batch-input.json: Dies ist ein Beispiel für die Eingabeparameter des Workflows.
input.json aus der Beispieldatei einrichten:Kopieren Sie zuerst das Beispiel-JSON.
cp sample-batch-input.json input.json
Bearbeiten Sie dann input.json mit Details für Ihr Projekt. In diesem Fall sollte Ihr JSON so aussehen:
{
"project_id": "<<YOUR_PROJECT>>",
"location": "<<us-central1>>",
"dataflow": {
"temp_location": "gs://<<YOUR_BUCKET>>/<<FOLDER_IF_ANY>>/workflow_temp"
},
"gcs": {
"output_folder": "gs://<<YOUR_BUCKET>>/<<FOLDER_IF_ANY>>/workflow_output"
},
"spanner": {
"instance_id": "spanner-vertex",
"database_id": "spanner-vertex-embeddings",
"table_name": "apparels_embeddings",
"columns_to_export": "embedding,id"
},
"vertex": {
"vector_search_index_id": "<<YOUR_INDEX_ID>>"
}
}
Berechtigungen einrichten
Für Produktionsumgebungen empfehlen wir dringend, ein neues Dienstkonto zu erstellen und ihm eine oder mehrere IAM-Rollen zuzuweisen, die die erforderlichen Mindestberechtigungen für die Verwaltung des Dienstes enthalten. Die folgenden Rollen sind erforderlich, um den Workflow für den Export von Daten (Einbettungen) aus Spanner in den Vektorsuchindex einzurichten:
Standardmäßig wird das Compute Engine-Standarddienstkonto verwendet.
Wenn Sie ein manuell konfiguriertes Dienstkonto verwenden, müssen Sie die folgenden Rollen einbeziehen:
So lösen Sie einen Dataflow-Job aus: Dataflow-Administrator, Dataflow-Worker.
So übernehmen Sie die Identität eines Dataflow-Worker-Dienstkontos: Dienstkontonutzer.
So schreiben Sie Logs: Logautor.
So lösen Sie den Wiederaufbau der Vektorsuche in Vertex AI aus: Vertex AI-Nutzer.
Wenn Sie ein manuell konfiguriertes Dienstkonto verwenden, müssen Sie die folgenden Rollen einbeziehen:
So verwalten Sie Dataflow: Dataflow-Administrator, Dataflow-Worker. So lesen Sie Daten aus Spanner: Cloud Spanner-Datenbankleser. Schreibzugriff auf ausgewählte GCS Container Registry: GCS Storage-Bucket-Inhaber.
- Cloud Workflow bereitstellen
Stellen Sie die Workflow-YAML-Datei in Ihrem Google Cloud-Projekt bereit. Sie können die Region oder den Standort konfigurieren, an dem der Workflow bei der Ausführung ausgeführt wird.
gcloud workflows deploy vector-export-workflow --source=batch-export.yaml --location="us-central1" [--service account=<service_account>]
or
gcloud workflows deploy vector-export-workflow --source=batch-export.yaml --location="us-central1"
Der Workflow sollte jetzt auf der Seite „Workflows“ in der Google Cloud Console sichtbar sein.
Hinweis: Sie können den Workflow auch in der Google Cloud Console erstellen und bereitstellen. Folgen Sie der Anleitung in der Cloud Console. Kopieren Sie für die Workflow-Definition den Inhalt von „batch-export.yaml“ und fügen Sie ihn ein.
Führen Sie den Workflow aus, damit der Datenexport beginnt.
- Cloud Workflow ausführen
Führen Sie den folgenden Befehl aus, um den Workflow auszuführen:
gcloud workflows execute vector-export-workflow --data="$(cat input.json)"
Die Ausführung sollte auf dem Tab „Ausführungen“ in „Workflows“ angezeigt werden. Dadurch werden Ihre Daten in die Vektorsuchdatenbank geladen und indexiert.
Hinweis: Sie können die Ausführung auch über die Console mit der Schaltfläche „Ausführen“ starten. Folgen Sie der Anleitung und kopieren Sie für die Eingabe den Inhalt Ihrer angepassten „input.json“ und fügen Sie ihn ein.
5. Vektorsuchindex bereitstellen
Index auf einem Endpunkt bereitstellen
Gehen Sie so vor, um den Index bereitzustellen:
- Auf der Seite „Vektorsuchindexe“ sollte neben dem Index, den Sie in Schritt 2 des vorherigen Abschnitts erstellt haben, die Schaltfläche „BEREITSTELLEN“ angezeigt werden. Alternativ können Sie die Seite mit den Indexinformationen aufrufen und auf die Schaltfläche „AUF ENDPUNKT BEREITSTELLEN“ klicken.
- Geben Sie die erforderlichen Informationen an und stellen Sie den Index auf einem Endpunkt bereit.
Alternativ können Sie sich dieses Notebook ansehen, um es auf einem Endpunkt bereitzustellen (springen Sie zum Bereitstellungsteil des Notebooks). Notieren Sie sich nach der Bereitstellung die ID des bereitgestellten Index und die Endpunkt-URL.
6. Frontend: Nutzerdaten für die Vektorsuche
Wir erstellen eine einfache Python-Anwendung mit einer Gradio-basierten Benutzeroberfläche, um unsere Implementierung schnell zu testen. Sie können sich hier auf die Implementierung hier beziehen, um diese Demo-App in Ihrem eigenen Colab-Notebook zu implementieren.
- Wir verwenden das aiplatform Python SDK, um die Embeddings API aufzurufen und den Endpunkt des Vektorsuchindex aufzurufen.
# [START aiplatform_sdk_embedding]
!pip install google-cloud-aiplatform==1.35.0 --upgrade --quiet --user
import vertexai
vertexai.init(project=PROJECT_ID, location="us-central1")
from vertexai.language_models import TextEmbeddingModel
import sys
if "google.colab" in sys.modules:
# Define project information
PROJECT_ID = " " # Your project id
LOCATION = " " # Your location
# Authenticate user to Google Cloud
from google.colab import auth
auth.authenticate_user()
- Wir verwenden Gradio, um die KI-Anwendung, die wir erstellen, schnell und einfach mit einer Benutzeroberfläche zu demonstrieren. Starten Sie die Laufzeit neu, bevor Sie diesen Schritt implementieren.
!pip install gradio
import gradio as gr
- Rufen Sie in der Webanwendung nach der Eingabe durch den Nutzer die Embeddings API auf. Wir verwenden das Texteinbettungsmodell: textembedding-gecko@latest
Die folgende Methode ruft das Texteinbettungsmodell auf und gibt die Vektoreinbettungen für den vom Nutzer eingegebenen Text zurück:
def text_embedding(content) -> list:
"""Text embedding with a Large Language Model."""
model = TextEmbeddingModel.from_pretrained("textembedding-gecko@latest")
embeddings = model.get_embeddings(content)
for embedding in embeddings:
vector = embedding.values
#print(f"Length of Embedding Vector: {len(vector)}")
return vector
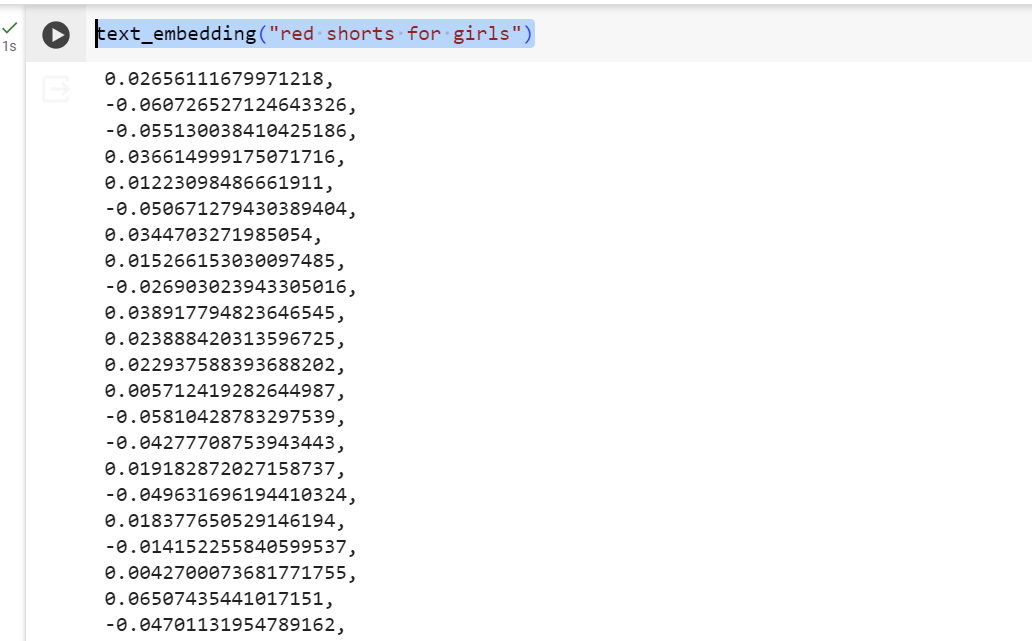
Testen
text_embedding("red shorts for girls")
Die Ausgabe sollte in etwa so aussehen (beachten Sie, dass das Bild in der Höhe zugeschnitten ist, sodass Sie nicht die gesamte Vektorantwort sehen können):
- Die ID des bereitgestellten Index und die Endpunkt-ID deklarieren
from google.cloud import aiplatform
DEPLOYED_INDEX_ID = "spanner_vector1_1702366982123"
#Vector Search Endpoint
index_endpoint = aiplatform.MatchingEngineIndexEndpoint('projects/273845608377/locations/us-central1/indexEndpoints/2021628049526620160')
- Definieren Sie die Vektorsuchmethode, um den Indexendpunkt aufzurufen und das Ergebnis mit den 10 ähnlichsten Übereinstimmungen für die Einbettungsantwort entsprechend dem vom Nutzer eingegebenen Text anzuzeigen.
Beachten Sie in der folgenden Methodendefinition für die Vektorsuche, dass die Methode „find_neighbors“ aufgerufen wird, um die 10 ähnlichsten Vektoren zu ermitteln.
def vector_search(content) -> list:
result = text_embedding(content)
#call_vector_search_api(content)
index_endpoint = aiplatform.MatchingEngineIndexEndpoint('projects/273845608377/locations/us-central1/indexEndpoints/2021628049526620160')
# run query
response = index_endpoint.find_neighbors(
deployed_index_id = DEPLOYED_INDEX_ID,
queries = [result],
num_neighbors = 10
)
out = []
# show the results
for idx, neighbor in enumerate(response[0]):
print(f"{neighbor.distance:.2f} {spanner_read_data(neighbor.id)}")
out.append(f"{spanner_read_data(neighbor.id)}")
return out
Außerdem sehen Sie den Aufruf der Methode „spanner_read_data“. Sehen wir uns das im nächsten Schritt an.
- Definieren Sie die Implementierung der Methode „Spanner-Daten lesen“, die die Methode „execute_sql“ aufruft, um die Bilder zu extrahieren, die den IDs der Vektoren des nächsten Nachbarn entsprechen, die im letzten Schritt zurückgegeben wurden.
!pip install google-cloud-spanner==3.36.0
from google.cloud import spanner
instance_id = "spanner-vertex"
database_id = "spanner-vertex-embeddings"
projectId = PROJECT_ID
client = spanner.Client()
client.project = projectId
instance = client.instance(instance_id)
database = instance.database(database_id)
def spanner_read_data(id):
query = "SELECT uri FROM apparels where id = " + id
outputs = []
with database.snapshot() as snapshot:
results = snapshot.execute_sql(query)
for row in results:
#print(row)
#output = "ID: {}, CONTENT: {}, URI: {}".format(*row)
output = "{}".format(*row)
outputs.append(output)
return "\n".join(outputs)
Es sollten die URLs der Bilder zurückgegeben werden, die den ausgewählten Vektoren entsprechen.
- Fügen wir die Teile schließlich in einer Benutzeroberfläche zusammen und lösen wir den Vektorsuchprozess aus.
from PIL import Image
def call_search(query):
response = vector_search(query)
return response
input_text = gr.Textbox(label="Enter your query. Examples: Girls Tops White Casual, Green t-shirt girls, jeans shorts, denim skirt etc.")
output_texts = [gr.Image(label="") for i in range(10)]
demo = gr.Interface(fn=call_search, inputs=input_text, outputs=output_texts, live=True)
resp = demo.launch(share = True)
Das Ergebnis sollte so aussehen:
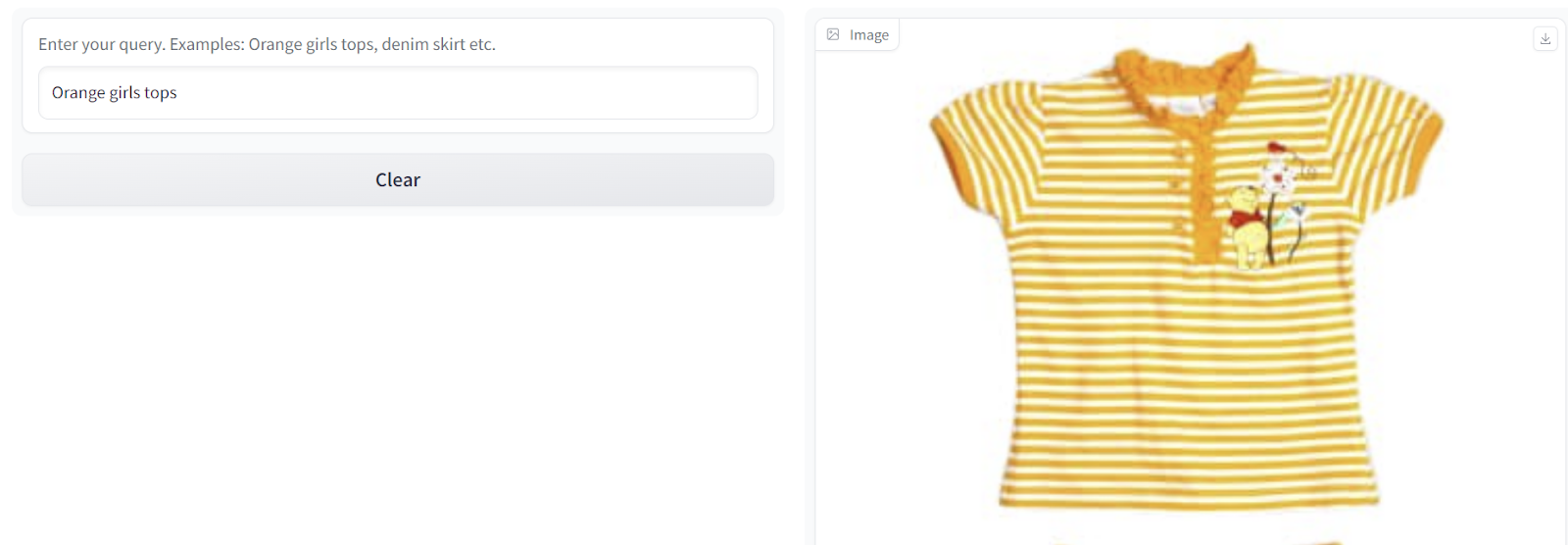
Bild: Link
Video mit dem Ergebnis ansehen: hier.
7. Bereinigen
Mit den folgenden Schritten vermeiden Sie, dass Ihrem Google Cloud-Konto die in diesem Beitrag verwendeten Ressourcen in Rechnung gestellt werden:
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
- Wenn Sie das Projekt nicht löschen möchten, löschen Sie die Spanner-Instanz. Rufen Sie dazu die Instanz auf, die Sie gerade für dieses Projekt erstellt haben, und klicken Sie in der oberen rechten Ecke der Seite „Instanzübersicht“ auf die Schaltfläche „INSTANZ LÖSCHEN“.
- Sie können auch zum Vektorsuchindex navigieren, die Bereitstellung des Endpunkts und des Index aufheben und den Index löschen.
8. Fazit
Glückwunsch! Sie haben die Implementierung der Spanner-Vektorsuche in Vertex AI abgeschlossen, indem Sie
- eine Spanner-Datenquelle und Einbettungen für Anwendungen erstellt haben, die aus der Spanner-Datenbank stammen.
- einen Vektorsuchdatenbankindex erstellt haben.
- Vektordaten aus Spanner mit Dataflow- und Workflow-Jobs in die Vektorsuche eingebunden haben.
- den Index auf einem Endpunkt bereitgestellt haben.
- schließlich die Vektorsuche für die Nutzereingabe in einer Python-basierten Implementierung des Vertex AI SDK aufgerufen haben.
Sie können die Implementierung für Ihren eigenen Anwendungsfall erweitern oder den aktuellen Anwendungsfall mit neuen Funktionen verbessern. Weitere Informationen zu den Machine-Learning-Funktionen von Spanner hier.