
1. 소개
최근 딥러닝의 발전으로 시맨틱 의미를 포착하는 방식으로 텍스트 및 기타 데이터를 표현할 수 있게 되었습니다. 이로 인해 텍스트의 벡터 표현 (임베딩이라고 함)을 사용하여 사용자 쿼리와 가장 관련성이 높은 문서를 찾는 벡터 검색이라는 새로운 검색 접근 방식이 등장했습니다. 벡터 검색은 사용자가 정확한 제품 또는 브랜드 이름이 아닌 설명, 스타일 또는 컨텍스트로 항목을 검색하는 경우가 많은 의류 검색과 같은 애플리케이션에 기존 검색보다 선호됩니다. Cloud Spanner 데이터베이스를 벡터 검색과 통합하여 벡터 유사성 일치를 수행할 수 있습니다. 고객은 Spanner와 벡터 검색을 함께 사용하여 Spanner의 가용성, 안정성, 확장성과 Vertex AI 벡터 검색의 고급 유사성 검색 기능을 결합한 강력한 통합을 만들 수 있습니다. 이 검색은 벡터 검색 색인의 항목 임베딩을 비교하고 가장 유사한 일치 항목을 반환하여 수행됩니다.
사용 사례
급변하는 트렌드, 제품 검색, 추천을 따라가려는 패션 소매업체의 데이터 과학자라고 가정해 보겠습니다. 문제는 리소스와 데이터 사일로가 제한되어 있다는 것입니다. 이 블로그 게시물에서는 의류 데이터에 유사성 검색 접근 방식을 사용하여 의류 추천 사용 사례를 구현하는 방법을 보여줍니다. 다음 단계가 다루어집니다.
- Spanner에서 가져온 데이터
- ML.PREDICT를 사용하여 의류 데이터에 대해 생성되고 Spanner에 저장된 벡터
- Dataflow 및 워크플로 작업을 사용하여 벡터 검색과 통합된 Spanner 벡터 데이터
- 사용자가 입력한 입력의 유사성 일치를 찾기 위해 수행된 벡터 검색
사용자 입력 텍스트를 기반으로 의류 검색을 수행하는 데모 웹 애플리케이션을 빌드합니다. 이 애플리케이션을 사용하면 사용자가 텍스트 설명을 입력하여 의류를 검색할 수 있습니다.
Spanner to Vector Search Index:
의류 검색 데이터는 Spanner에 저장됩니다. Spanner 데이터에서 직접 ML.PREDICT 구성에서 Vertex AI Embeddings API를 호출합니다. 그런 다음 이 데이터 (인벤토리 및 임베딩)를 Vertex AI의 벡터 검색에 일괄 업로드하고 색인을 새로고침하는 Dataflow 및 워크플로 작업을 활용합니다.
색인에서 사용자 쿼리 실행:
사용자가 의류 설명을 입력하면 앱은 텍스트 임베딩 API를 사용하여 임베딩을 실시간으로 생성합니다. 그런 다음 색인에서 관련 제품 설명 10개를 찾고 해당 이미지를 표시하기 위해 벡터 검색 API에 입력으로 전송됩니다.
아키텍처 개요
Spanner-벡터 검색 애플리케이션의 아키텍처는 다음 두 부분으로 구성된 다이어그램에 나와 있습니다.
Spanner to Vector Search Index: 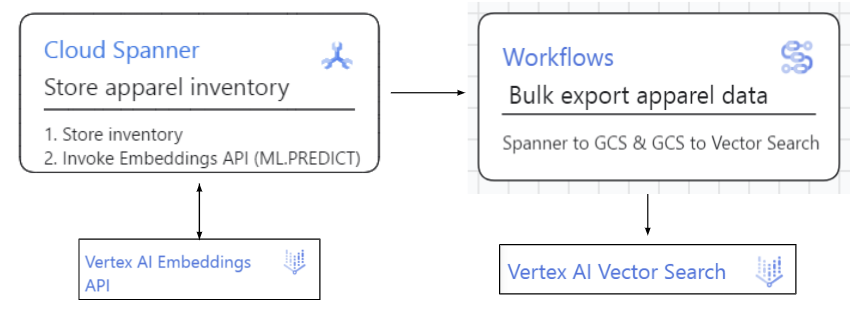
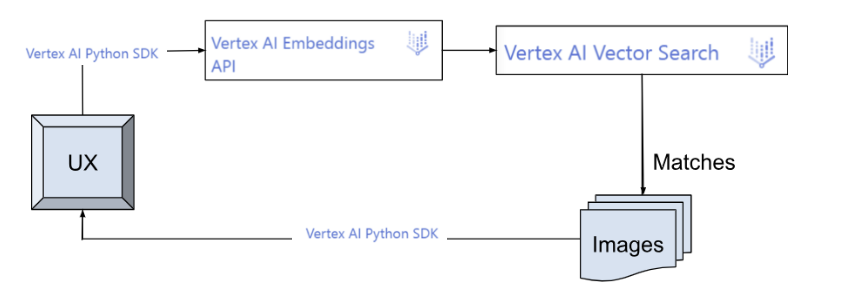
색인에서 사용자 쿼리를 실행하는 클라이언트 앱:
 빌드할 항목
빌드할 항목
Spanner to Vector Index:
- 소스 데이터 및 해당 임베딩을 저장하고 관리하는 Spanner 데이터베이스
- 데이터 (ID 및 임베딩)를 Vertex AI 벡터 검색 데이터베이스에 일괄 업로드하는 워크플로 작업
- 색인에서 관련 제품 설명을 찾는 데 사용되는 벡터 검색 API
색인에서 사용자 쿼리 실행:
- 사용자가 의류의 텍스트 설명을 입력하고 배포된 색인 엔드포인트를 사용하여 유사성 검색을 수행하며 입력에 가장 가까운 의류를 반환할 수 있는 웹 애플리케이션
작동 방식
사용자가 의류의 텍스트 설명을 입력하면 웹 애플리케이션이 설명을 벡터 검색 API로 보냅니다. 그런 다음 벡터 검색 API는 의류 설명의 임베딩을 사용하여 색인에서 가장 관련성이 높은 제품 설명을 찾습니다. 그런 다음 제품 설명과 해당 이미지가 사용자에게 표시됩니다. 일반적인 워크플로는 다음과 같습니다.
- Spanner에 저장된 데이터의 임베딩을 생성합니다.
- 임베딩을 내보내고 벡터 검색 색인에 업로드합니다.
- 최근접 이웃 검색을 수행하여 유사한 항목에 대해 벡터 검색 색인을 쿼리합니다.
2. 요구사항
시작하기 전에
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
- 필요한 모든 API (Cloud Spanner, Vertex AI, Google Cloud Storage)가 사용 설정되어 있는지 확인합니다.
- gcloud가 미리 로드되어 제공되는 Google Cloud에서 실행되는 명령줄 환경인 Cloud Shell을 사용합니다. gcloud 명령어 및 사용법은 문서를 참조하세요. 프로젝트가 설정되지 않은 경우 다음 명령어를 사용하여 설정합니다.
gcloud config set project <YOUR_PROJECT_ID>
- 활성 Google Cloud 프로젝트로 Cloud Spanner 페이지로 이동하여 시작합니다.
3. 백엔드: Spanner 데이터 소스 및 임베딩 만들기
이 사용 사례에서 Spanner 데이터베이스는 해당 이미지와 설명이 포함된 의류 인벤토리를 보관합니다. 텍스트 설명의 임베딩을 생성하고 Spanner 데이터베이스에 ARRAY<float64>로 저장해야 합니다.
- Spanner 데이터 만들기
인스턴스 이름은 'spanner-vertex', 데이터베이스 이름은 'spanner-vertex-embeddings'로 만듭니다. DDL을 사용하여 테이블을 만듭니다.
CREATE TABLE
apparels ( id NUMERIC,
category STRING(100),
sub_category STRING(50),
uri STRING(200),
content STRING(2000),
embedding ARRAY<FLOAT64>
)
PRIMARY KEY
(id);
- INSERT SQL을 사용하여 테이블에 데이터 삽입
샘플 데이터의 삽입 스크립트는 여기에서 확인할 수 있습니다.
- 텍스트 임베딩 모델 만들기
입력의 콘텐츠에 대한 임베딩을 생성할 수 있도록 필요합니다. 아래는 동일한 DDL입니다.
CREATE MODEL text_embeddings INPUT(content STRING(MAX))
OUTPUT(
embeddings
STRUCT<
statistics STRUCT<truncated BOOL, token_count FLOAT64>,
values ARRAY<FLOAT64>>
)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/abis-345004/locations/us-central1/publishers/google/models/textembedding-gecko');
- 소스 데이터의 텍스트 임베딩 생성
임베딩을 저장할 테이블을 만들고 생성된 임베딩을 삽입합니다. 실제 데이터베이스 애플리케이션에서 Spanner에 대한 데이터 로드는 2단계까지 트랜잭션이 됩니다. 설계 권장사항을 그대로 유지하기 위해 트랜잭션 테이블을 정규화 하는 것이 좋으므로 임베딩을 위한 별도의 테이블을 만듭니다.
CREATE TABLE apparels_embeddings (id string(100), embedding ARRAY<FLOAT64>)
PRIMARY KEY (id);
INSERT INTO apparels_embeddings(id, embeddings)
SELECT CAST(id as string), embeddings.values
FROM ML.PREDICT(
MODEL text_embeddings,
(SELECT id, content from apparels)
) ;
이제 대량 콘텐츠와 임베딩이 준비되었으므로 벡터 검색을 수행하는 데 도움이 되는 임베딩을 저장할 벡터 검색 색인 및 엔드포인트를 만들어 보겠습니다.
4. 워크플로 작업: Spanner 데이터 내보내기에서 벡터 검색으로
- Cloud Storage 버킷 만들기
벡터 검색이 입력으로 예상하는 json 형식으로 Spanner의 임베딩을 GCS 버킷에 저장하는 데 필요합니다. Spanner의 데이터와 동일한 리전에 버킷을 만듭니다. 필요한 경우 내부에 폴더를 만들지만 주로 빈 파일 empty.json을 만듭니다.
- Cloud 워크플로 설정
Spanner에서 Vertex AI 벡터 검색 색인으로 일괄 내보내기를 설정하려면 다음 안내를 따르세요.
빈 색인 만들기:
벡터 검색 색인이 Cloud Storage 버킷 및 데이터와 동일한 리전에 있는지 확인합니다. 색인 관리 페이지의 일괄 업데이트를 위한 색인 만들기 섹션에 있는 콘솔 탭의 안내에 따라 11단계를 따릅니다. contentsDeltaUri에 전달되는 폴더에서 empty.json이라는 빈 파일을 만듭니다. 이 파일이 없으면 색인을 만들 수 없기 때문입니다. 이렇게 하면 빈 색인이 만들어집니다.
이미 색인이 있는 경우 이 단계를 건너뛸 수 있습니다. 워크플로가 색인을 덮어씁니다.
참고: 빈 색인을 엔드포인트에 배포할 수 없습니다. 따라서 벡터 데이터를 Cloud Storage로 내보낸 후 엔드포인트에 배포하는 단계를 나중 단계로 연기합니다.
이 Git 저장소 클론: Git 저장소를 클론하는 방법은 여러 가지가 있습니다. 한 가지 방법은 GitHub CLI를 사용하여 다음 명령어를 실행하는 것입니다. Cloud Shell 터미널에서 아래 2개의 명령어를 실행합니다.
gh repo clone cloudspannerecosystem/spanner-ai
cd spanner-ai/vertex-vector-search/workflows
이 폴더에는 두 개의 파일이 포함되어 있습니다.
batch-export.yaml: 워크플로 정의입니다.sample-batch-input.json: 워크플로 입력 매개변수의 샘플입니다.
샘플 파일에서 input.json 설정: 먼저 샘플 json을 복사합니다.
cp sample-batch-input.json input.json
그런 다음 프로젝트의 세부정보로 input.json을 수정합니다. 이 경우 json은 다음과 같아야 합니다.
{
"project_id": "<<YOUR_PROJECT>>",
"location": "<<us-central1>>",
"dataflow": {
"temp_location": "gs://<<YOUR_BUCKET>>/<<FOLDER_IF_ANY>>/workflow_temp"
},
"gcs": {
"output_folder": "gs://<<YOUR_BUCKET>>/<<FOLDER_IF_ANY>>/workflow_output"
},
"spanner": {
"instance_id": "spanner-vertex",
"database_id": "spanner-vertex-embeddings",
"table_name": "apparels_embeddings",
"columns_to_export": "embedding,id"
},
"vertex": {
"vector_search_index_id": "<<YOUR_INDEX_ID>>"
}
}
권한 설정
프로덕션 환경의 경우 새 서비스 계정을 만들고 서비스 관리에 필요한 최소한의 권한을 포함하는 IAM 역할을 하나 이상 부여하는 것이 좋습니다. Spanner (임베딩)에서 벡터 검색 색인으로 데이터를 내보내는 워크플로를 설정하려면 다음 역할이 필요합니다.
기본적으로 Compute Engine 기본 서비스 계정 을 사용합니다.
수동으로 구성된 서비스 계정을 사용하는 경우 다음 역할을 포함해야 합니다.
Dataflow 작업을 트리거하려면 Dataflow 관리자, Dataflow 작업자 가 필요합니다.
Dataflow 작업자 서비스 계정을 가장하려면 서비스 계정 사용자 가 필요합니다.
로그를 작성하려면 로그 작성자 가 필요합니다.
Vertex AI 벡터 검색 재빌드를 트리거하려면 Vertex AI 사용자 가 필요합니다.
수동으로 구성된 서비스 계정을 사용하는 경우 다음 역할을 포함해야 합니다.
Dataflow를 관리하려면 Dataflow 관리자, Dataflow 작업자가 필요합니다. Spanner에서 데이터를 읽으려면 Cloud Spanner 데이터베이스 리더 가 필요합니다. 선택한 GCS Container Registry에 대한 쓰기 액세스 권한: GCS Storage 버킷 소유자
- Cloud 워크플로 배포
워크플로 yaml 파일을 Google Cloud 프로젝트에 배포합니다. 실행 시 워크플로가 실행될 리전 또는 위치를 구성할 수 있습니다.
gcloud workflows deploy vector-export-workflow --source=batch-export.yaml --location="us-central1" [--service account=<service_account>]
or
gcloud workflows deploy vector-export-workflow --source=batch-export.yaml --location="us-central1"
이제 Google Cloud 콘솔의 워크플로 페이지에 워크플로가 표시됩니다.
참고: Google Cloud 콘솔에서 워크플로를 만들고 배포할 수도 있습니다. Cloud 콘솔의 안내를 따르세요. 워크플로 정의의 경우 batch-export.yaml의 콘텐츠를 복사하여 붙여넣습니다.
완료되면 데이터 내보내기가 시작되도록 워크플로를 실행합니다.
- Cloud 워크플로 실행
다음 명령어를 실행하여 워크플로를 실행합니다.
gcloud workflows execute vector-export-workflow --data="$(cat input.json)"
실행은 워크플로의 실행 탭에 표시됩니다. 이렇게 하면 데이터가 벡터 검색 데이터베이스에 로드되고 색인이 생성됩니다.
참고: 실행 버튼을 사용하여 콘솔에서 실행할 수도 있습니다. 안내를 따르고 입력의 경우 맞춤설정된 input.json의 콘텐츠를 복사하여 붙여넣습니다.
5. 벡터 검색 색인 배포
엔드포인트에 색인 배포
다음 단계에 따라 색인을 배포할 수 있습니다.
- 벡터 검색 색인 페이지에서 이전 섹션의 2단계에서 만든 색인 옆에 배포 버튼이 표시됩니다. 또는 색인 정보 페이지로 이동하여 엔드포인트에 배포 버튼을 클릭할 수 있습니다.
- 필요한 정보를 제공하고 색인을 엔드포인트에 배포합니다.
또는 이 노트북을 보고 엔드포인트에 배포할 수 있습니다 (노트북의 배포 부분으로 건너뛰기). 배포되면 배포된 색인 ID와 엔드포인트 URL을 기록해 둡니다.
6. 프런트엔드: 사용자 데이터에서 벡터 검색으로
gradio 기반 UX를 사용하여 구현을 빠르게 테스트하는 간단한 Python 애플리케이션을 빌드해 보겠습니다. 여기에서 구현을 참조하여 자체 Colab 노트북에서 이 데모 앱을 구현할 수 있습니다.
- aiplatform Python SDK를 사용하여 Embeddings API를 호출하고 벡터 검색 색인 엔드포인트를 호출합니다.
# [START aiplatform_sdk_embedding]
!pip install google-cloud-aiplatform==1.35.0 --upgrade --quiet --user
import vertexai
vertexai.init(project=PROJECT_ID, location="us-central1")
from vertexai.language_models import TextEmbeddingModel
import sys
if "google.colab" in sys.modules:
# Define project information
PROJECT_ID = " " # Your project id
LOCATION = " " # Your location
# Authenticate user to Google Cloud
from google.colab import auth
auth.authenticate_user()
- gradio를 사용하여 사용자 인터페이스로 빠르고 쉽게 빌드하는 AI 애플리케이션을 데모합니다. 이 단계를 구현하기 전에 런타임을 다시 시작합니다.
!pip install gradio
import gradio as gr
- 사용자 입력 시 웹 앱에서 Embeddings API를 호출합니다. 텍스트 임베딩 모델인 textembedding-gecko@latest를 사용합니다.
아래 메서드는 텍스트 임베딩 모델을 호출하고 사용자가 입력한 텍스트의 벡터 임베딩을 반환합니다.
def text_embedding(content) -> list:
"""Text embedding with a Large Language Model."""
model = TextEmbeddingModel.from_pretrained("textembedding-gecko@latest")
embeddings = model.get_embeddings(content)
for embedding in embeddings:
vector = embedding.values
#print(f"Length of Embedding Vector: {len(vector)}")
return vector
테스트
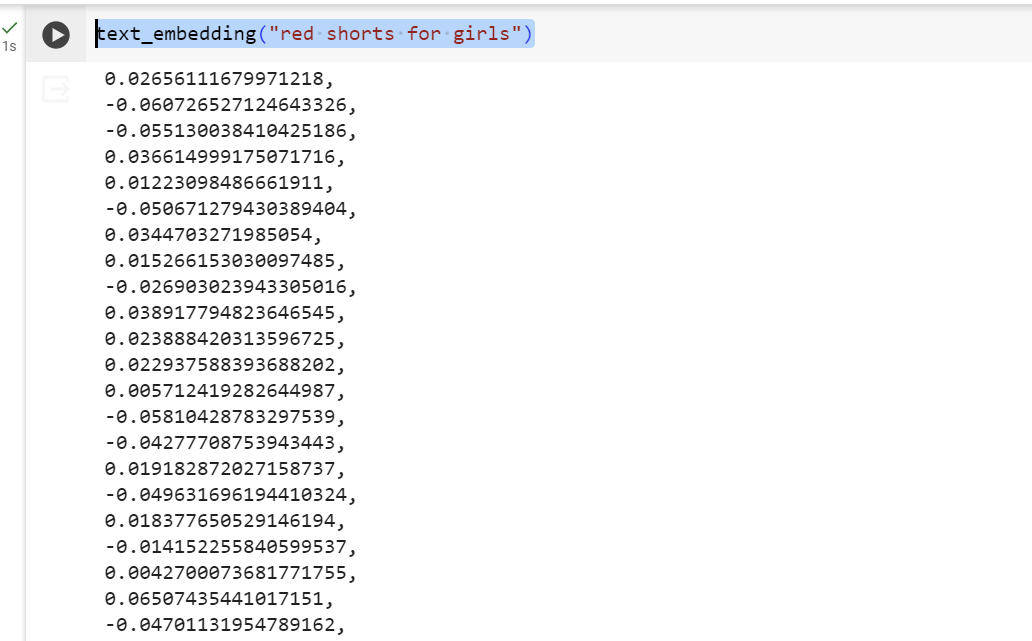
text_embedding("red shorts for girls")
아래와 비슷한 출력이 표시됩니다 (이미지는 높이가 잘려 벡터 응답 전체를 볼 수 없음).
- 배포된 색인 ID와 엔드포인트 ID를 선언합니다.
from google.cloud import aiplatform
DEPLOYED_INDEX_ID = "spanner_vector1_1702366982123"
#Vector Search Endpoint
index_endpoint = aiplatform.MatchingEngineIndexEndpoint('projects/273845608377/locations/us-central1/indexEndpoints/2021628049526620160')
- 색인 엔드포인트를 호출하고 사용자 입력 텍스트에 해당하는 임베딩 응답의 최근접 일치 항목 10개와 함께 결과를 표시하는 벡터 검색 메서드를 정의합니다.
벡터 검색의 아래 메서드 정의에서 find_neighbors 메서드가 호출되어 최근접 벡터 10개를 식별합니다.
def vector_search(content) -> list:
result = text_embedding(content)
#call_vector_search_api(content)
index_endpoint = aiplatform.MatchingEngineIndexEndpoint('projects/273845608377/locations/us-central1/indexEndpoints/2021628049526620160')
# run query
response = index_endpoint.find_neighbors(
deployed_index_id = DEPLOYED_INDEX_ID,
queries = [result],
num_neighbors = 10
)
out = []
# show the results
for idx, neighbor in enumerate(response[0]):
print(f"{neighbor.distance:.2f} {spanner_read_data(neighbor.id)}")
out.append(f"{spanner_read_data(neighbor.id)}")
return out
spanner_read_data 메서드에 대한 호출도 확인할 수 있습니다. 다음 단계에서 살펴보겠습니다.
- execute_sql 메서드를 호출하여 마지막 단계에서 반환된 최근접 이웃 벡터의 ID에 해당하는 이미지를 추출하는 Spanner 읽기 데이터 메서드 구현을 정의합니다.
!pip install google-cloud-spanner==3.36.0
from google.cloud import spanner
instance_id = "spanner-vertex"
database_id = "spanner-vertex-embeddings"
projectId = PROJECT_ID
client = spanner.Client()
client.project = projectId
instance = client.instance(instance_id)
database = instance.database(database_id)
def spanner_read_data(id):
query = "SELECT uri FROM apparels where id = " + id
outputs = []
with database.snapshot() as snapshot:
results = snapshot.execute_sql(query)
for row in results:
#print(row)
#output = "ID: {}, CONTENT: {}, URI: {}".format(*row)
output = "{}".format(*row)
outputs.append(output)
return "\n".join(outputs)
선택한 벡터에 해당하는 이미지의 URL을 반환해야 합니다.
- 마지막으로 사용자 인터페이스에서 조각을 결합하고 벡터 검색 프로세스를 트리거합니다.
from PIL import Image
def call_search(query):
response = vector_search(query)
return response
input_text = gr.Textbox(label="Enter your query. Examples: Girls Tops White Casual, Green t-shirt girls, jeans shorts, denim skirt etc.")
output_texts = [gr.Image(label="") for i in range(10)]
demo = gr.Interface(fn=call_search, inputs=input_text, outputs=output_texts, live=True)
resp = demo.launch(share = True)
아래와 같이 결과가 표시됩니다.
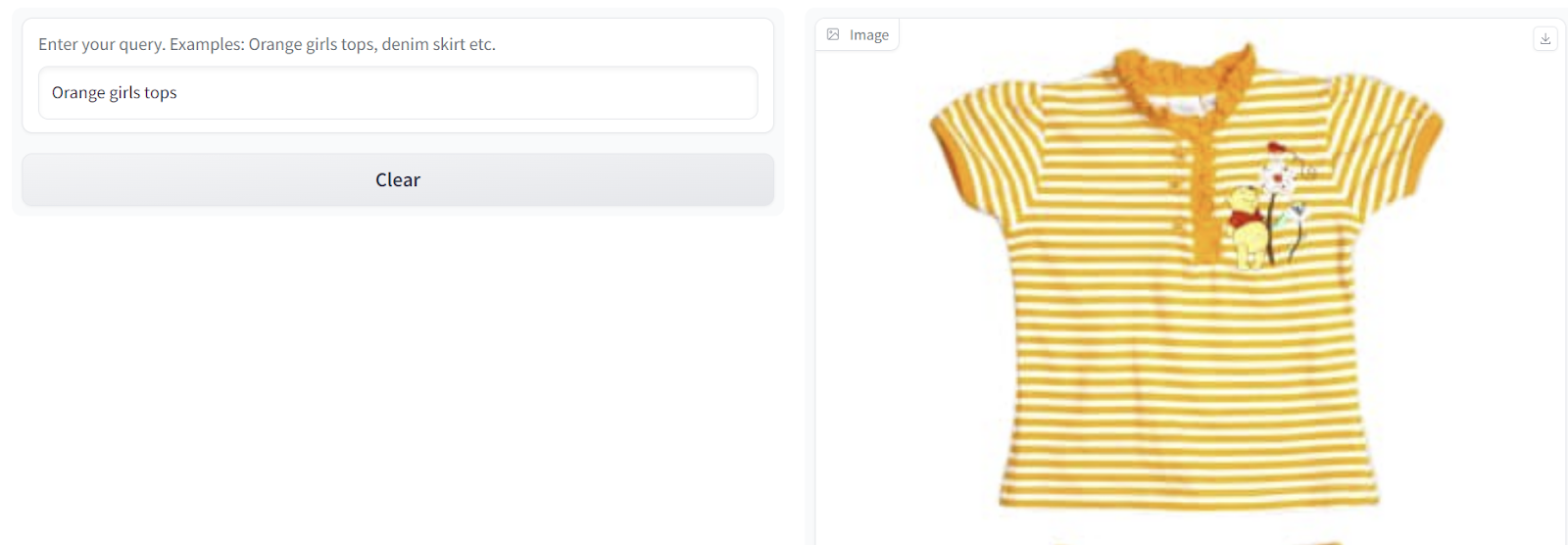
이미지: 링크
결과 동영상 보기: 여기.
7. 삭제
이 게시물에서 사용한 리소스의 비용이 Google Cloud 계정에 청구되지 않도록 하려면 다음 단계를 수행하세요.
- Google Cloud 콘솔에서 리소스 관리 페이지로 이동합니다.
- 프로젝트 목록에서 삭제하려는 프로젝트를 선택한 후 '삭제'를 클릭합니다.
- 대화상자에서 프로젝트 ID를 입력한 후 종료를 클릭하여 프로젝트를 삭제합니다.
- 프로젝트를 삭제하지 않으려면 이 프로젝트를 위해 만든 인스턴스로 이동하여 인스턴스 개요 페이지의 오른쪽 상단에 있는 인스턴스 삭제 버튼을 클릭하여 Spanner 인스턴스를 삭제합니다.
- 벡터 검색 색인으로 이동하여 엔드포인트와 색인의 배포를 취소하고 색인을 삭제할 수도 있습니다.
8. 결론
축하합니다. 다음 단계를 통해 Spanner - Vertex 벡터 검색 구현을 완료했습니다.
- Spanner 데이터베이스에서 가져온 애플리케이션의 Spanner 데이터 소스 및 임베딩 만들기
- 벡터 검색 데이터베이스 색인 만들기
- Dataflow 및 워크플로 작업을 사용하여 Spanner에서 벡터 검색으로 벡터 데이터 통합
- 엔드포인트에 색인 배포
- 마지막으로 Vertex AI SDK의 Python 기반 구현에서 사용자 입력에 대한 벡터 검색 호출
구현을 자체 사용 사례로 확장하거나 현재 사용 사례를 새로운 기능으로 즉흥적으로 개선해 보세요. 여기에서 Spanner의 머신러닝 기능에 대해 자세히 알아보세요. here.