
1. Introdução
Os avanços recentes em aprendizado profundo possibilitaram representar textos e outros dados de uma forma que capture o significado semântico. Isso levou a uma nova abordagem de pesquisa, chamada pesquisa vetorial, que usa representações vetoriais de texto (conhecidas como embeddings) para encontrar documentos mais relevantes para a consulta de um usuário. A pesquisa vetorial é preferível à pesquisa tradicional para aplicativos como a pesquisa de roupas, em que os usuários geralmente pesquisam itens pela descrição, estilo ou contexto, em vez de nomes exatos de produtos ou marcas. Podemos integrar o banco de dados do Cloud Spanner com a pesquisa vetorial para realizar a correspondência de similaridade vetorial. Ao usar o Spanner e a pesquisa vetorial juntos, os clientes podem criar uma integração poderosa que combina a disponibilidade, a confiabilidade e a escalonabilidade do Spanner com os recursos avançados de pesquisa de similaridade da pesquisa vetorial da Vertex AI. Essa pesquisa é realizada comparando embeddings de itens no índice da Pesquisa vetorial e retornando as correspondências mais semelhantes.
Caso de uso
Imagine que você é um cientista de dados em uma loja de roupas tentando acompanhar as tendências, as pesquisas de produtos e as recomendações em rápida mudança. O desafio é que você tem recursos e silos de dados limitados. Esta postagem do blog demonstra como implementar um caso de uso de recomendação de roupas usando a abordagem de pesquisa de similaridade em dados de roupas.As etapas a seguir são abordadas:
- Dados originados do Spanner
- Vetores gerados para os dados de roupas usando ML.PREDICT e armazenados no Spanner
- Dados vetoriais do Spanner integrados à pesquisa vetorial usando jobs de fluxo de dados e fluxo de trabalho
- Pesquisa vetorial realizada para encontrar a correspondência de similaridade para a entrada do usuário
Vamos criar um aplicativo da Web de demonstração para realizar a pesquisa de roupas com base no texto de entrada do usuário. O aplicativo permite que os usuários busquem roupas inserindo uma descrição de texto.
Spanner para índice de pesquisa vetorial:
Os dados da pesquisa de roupas são armazenados no Spanner. Vamos invocar a API Embeddings da Vertex AI no constructo ML.PREDICT diretamente dos dados do Spanner. Em seguida, vamos aproveitar os jobs de fluxo de dados e fluxo de trabalho que fazem upload em massa desses dados (inventário e embeddings) para a pesquisa vetorial da Vertex AI e atualizam o índice.
Execução de consultas de usuário no índice:
Quando um usuário insere uma descrição de roupa, o app gera os embeddings em tempo real usando a API Text Embeddings. Isso é enviado como entrada para a API Vector Search para encontrar 10 descrições de produtos relevantes no índice e mostrar a imagem correspondente.
Visão geral da arquitetura
A arquitetura do app de pesquisa vetorial do Spanner é mostrada no diagrama de duas partes a seguir:
Spanner para índice de pesquisa vetorial: 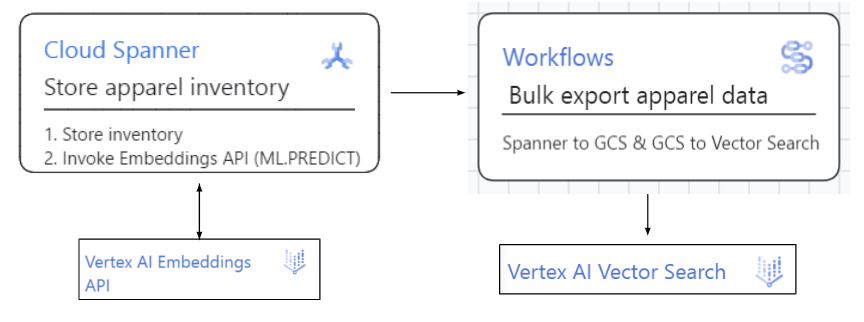
App cliente para executar consultas de usuário no índice:
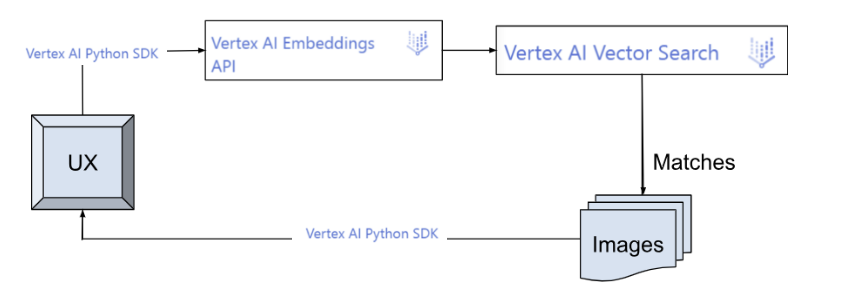 O que você vai criar
O que você vai criar
Spanner para índice vetorial:
- Banco de dados do Spanner para armazenar e gerenciar dados de origem e os embeddings correspondentes
- Um job de fluxo de trabalho que faz upload em massa de dados (ID e embeddings) para o banco de dados de pesquisa vetorial da Vertex AI.
- Uma API Vector Search usada para encontrar descrições de produtos relevantes no índice.
Execução de consultas de usuário no índice:
- Um aplicativo da Web que permite aos usuários inserir descrições de texto de roupas, realizar pesquisas de similaridade usando o endpoint de índice implantado e retornar as roupas mais próximas da entrada.
Como funciona
Quando um usuário insere uma descrição de texto de roupa, o aplicativo da Web envia a descrição para a API Vector Search. A API Vector Search usa os embeddings das descrições de roupas para encontrar as descrições de produtos mais relevantes no índice. As descrições dos produtos e as imagens correspondentes são mostradas ao usuário. O fluxo de trabalho geral é o seguinte:
- Gerar embeddings para dados armazenados no Spanner.
- Exportar e fazer upload de embeddings para um índice da Pesquisa vetorial.
- Consulte o índice de pesquisa vetorial para itens semelhantes realizando uma pesquisa de vizinho mais próximo.
2. Requisitos
- Use um navegador, como o Chrome ou o Firefox.
- Tenha um projeto na nuvem do Google Cloud com o faturamento ativado.
Antes de começar
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto na nuvem. Aprenda a verificar se o faturamento está ativado em um projeto
- Verifique se todas as APIs necessárias (Cloud Spanner, Vertex AI, Google Cloud Storage) estão ativadas
- Você vai usar o Cloud Shell, um ambiente de linha de comando executado no Google Cloud que vem pré-carregado com gcloud. Consulte a documentação para ver o uso e os comandos gcloud. Se o projeto não estiver definido, use este comando:
gcloud config set project <YOUR_PROJECT_ID>
- Navegue até a página do Cloud Spanner com seu projeto ativo do Google Cloud para começar.
3. Back-end: criar a fonte de dados e os embeddings do Spanner
Nesse caso de uso, o banco de dados do Spanner abriga o inventário de roupas com as imagens e descrições correspondentes. Gere embeddings para a descrição do texto e armazene-os no banco de dados do Spanner como ARRAY<float64>.
- Criar os dados do Spanner
Crie uma instância chamada "spanner-vertex" e um banco de dados chamado "spanner-vertex-embeddings". Crie uma tabela usando o DDL:
CREATE TABLE
apparels ( id NUMERIC,
category STRING(100),
sub_category STRING(50),
uri STRING(200),
content STRING(2000),
embedding ARRAY<FLOAT64>
)
PRIMARY KEY
(id);
- Insira dados na tabela usando o SQL INSERT
Os scripts de inserção de dados de amostra estão disponíveis aqui.
- Criar o modelo de embeddings de texto
Isso é necessário para que possamos gerar embeddings para o conteúdo na entrada. Confira abaixo o DDL para o mesmo:
CREATE MODEL text_embeddings INPUT(content STRING(MAX))
OUTPUT(
embeddings
STRUCT<
statistics STRUCT<truncated BOOL, token_count FLOAT64>,
values ARRAY<FLOAT64>>
)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/abis-345004/locations/us-central1/publishers/google/models/textembedding-gecko');
- Gerar embeddings de texto para os dados de origem
Crie uma tabela para armazenar os embeddings e insira os embeddings gerados. Em um aplicativo de banco de dados real, o carregamento de dados no Spanner até a etapa 2 seria transacional. Para manter as práticas recomendadas de design intactas, prefiro manter as tabelas transacionais normalizadas, criando uma tabela separada para embeddings.
CREATE TABLE apparels_embeddings (id string(100), embedding ARRAY<FLOAT64>)
PRIMARY KEY (id);
INSERT INTO apparels_embeddings(id, embeddings)
SELECT CAST(id as string), embeddings.values
FROM ML.PREDICT(
MODEL text_embeddings,
(SELECT id, content from apparels)
) ;
Agora que o conteúdo e os embeddings em massa estão prontos, vamos criar um índice de pesquisa vetorial e um endpoint para armazenar os embeddings que vão ajudar a realizar a pesquisa vetorial.
4. Job de fluxo de trabalho: exportação de dados do Spanner para a pesquisa vetorial
- Criar um bucket do Cloud Storage
Isso é necessário para armazenar embeddings do Spanner em um bucket do GCS em um formato JSON que a Pesquisa Vetorial espera como entrada. Crie um bucket na mesma região dos dados no Spanner. Crie uma pasta dentro, se necessário, mas principalmente crie um arquivo vazio chamado empty.json.
- Configurar o fluxo de trabalho do Cloud
Para configurar uma exportação em lote do Spanner para um índice de pesquisa vetorial da Vertex AI:
Criar um índice vazio:
Verifique se o índice de pesquisa vetorial está na mesma região que o bucket do Cloud Storage e os dados. Siga as 11 etapas de instrução na guia "Console" na seção "Criar um índice para atualização em lote" na página "Gerenciar índices". Na pasta transmitida para contentsDeltaUri, crie um arquivo vazio chamado empty.json, porque não é possível criar um índice sem esse arquivo. Isso cria um índice vazio.
Se você já tiver um índice, pule esta etapa. O fluxo de trabalho vai substituir seu índice.
Observação: não é possível implantar um índice vazio em um endpoint. Portanto, vamos adiar a etapa de implantação em um endpoint para uma etapa posterior, depois de exportar os dados vetoriais para o Cloud Storage.
Clonar este repositório do Git: há várias maneiras de clonar um repositório do Git. Uma delas é executar o comando a seguir usando a CLI do GitHub. Execute os dois comandos abaixo no terminal do Cloud Shell:
gh repo clone cloudspannerecosystem/spanner-ai
cd spanner-ai/vertex-vector-search/workflows
Esta pasta contém dois arquivos
batch-export.yaml: esta é a definição do fluxo de trabalho.sample-batch-input.json: este é um exemplo dos parâmetros de entrada do fluxo de trabalho.
Configurar input.json do arquivo de amostra:primeiro, copie o JSON de amostra.
cp sample-batch-input.json input.json
Em seguida, edite input.json com detalhes do seu projeto. Nesse caso, seu JSON deve ser assim:
{
"project_id": "<<YOUR_PROJECT>>",
"location": "<<us-central1>>",
"dataflow": {
"temp_location": "gs://<<YOUR_BUCKET>>/<<FOLDER_IF_ANY>>/workflow_temp"
},
"gcs": {
"output_folder": "gs://<<YOUR_BUCKET>>/<<FOLDER_IF_ANY>>/workflow_output"
},
"spanner": {
"instance_id": "spanner-vertex",
"database_id": "spanner-vertex-embeddings",
"table_name": "apparels_embeddings",
"columns_to_export": "embedding,id"
},
"vertex": {
"vector_search_index_id": "<<YOUR_INDEX_ID>>"
}
}
Configurar permissões
Para ambientes de produção, é altamente recomendável criar uma nova conta de serviço e conceder a ela um ou mais papéis do IAM que contenham as permissões mínimas necessárias para gerenciar o serviço. Os papéis a seguir são necessários para configurar o fluxo de trabalho para exportar dados do Spanner (embeddings) para o índice da Pesquisa vetorial:
Conta de serviço do fluxo de trabalho do Cloud:
Por padrão, ele usa a conta de serviço padrão do Compute Engine.
Se você usar uma conta de serviço configurada manualmente, inclua os seguintes papéis:
Para acionar um job do Dataflow: administrador do Dataflow, worker do Dataflow.
Para representar uma conta de serviço do worker do Dataflow: Usuário da conta de serviço.
Para gravar registros: gravador de registros.
Para acionar a recriação da pesquisa vetorial da Vertex AI: usuário da Vertex AI.
Conta de serviço do worker do Dataflow:
Se você usar uma conta de serviço configurada manualmente, inclua os seguintes papéis:
Para gerenciar o Dataflow: administrador do Dataflow, worker do Dataflow. Para ler dados do Spanner: leitor de banco de dados do Cloud Spanner. Acesso de gravação no Container Registry do GCS selecionado: proprietário do bucket de armazenamento do GCS.
- Implantar o fluxo de trabalho do Cloud
Implante o arquivo YAML do fluxo de trabalho no seu projeto na nuvem do Google. É possível configurar a região ou o local em que o fluxo de trabalho será executado.
gcloud workflows deploy vector-export-workflow --source=batch-export.yaml --location="us-central1" [--service account=<service_account>]
or
gcloud workflows deploy vector-export-workflow --source=batch-export.yaml --location="us-central1"
O fluxo de trabalho agora deve estar visível na página "Fluxos de trabalho" no console do Google Cloud.
Observação: também é possível criar e implantar o fluxo de trabalho no console do Google Cloud. Siga as instruções no console do Cloud. Para a definição do fluxo de trabalho, copie e cole o conteúdo de batch-export.yaml.
Quando isso for concluído, execute o fluxo de trabalho para que a exportação de dados comece.
- Executar o fluxo de trabalho do Cloud
Execute o comando a seguir para executar o fluxo de trabalho:
gcloud workflows execute vector-export-workflow --data="$(cat input.json)"
A execução vai aparecer na guia "Execuções" em "Fluxos de trabalho". Isso vai carregar seus dados no banco de dados de pesquisa vetorial e indexá-los.
Observação: também é possível executar no console usando o botão "Executar". Siga as instruções e, para a entrada, copie e cole o conteúdo do input.json personalizado.
5. Implantar o índice de pesquisa vetorial
Implantar o índice em um endpoint
Siga as etapas abaixo para implantar o índice:
- Na página "Índices de pesquisa vetorial", você verá um botão "IMPLANTAR" ao lado do índice que acabou de criar na etapa 2 da seção anterior. Como alternativa, navegue até a página de informações do índice e clique no botão "IMPLANTAR NO ENDPOINT".
- Forneça as informações necessárias e implante o índice em um endpoint.
Como alternativa, consulte este notebook para implantá-lo em um endpoint (pule para a parte de implantação do notebook). Depois de implantado, anote o ID do índice implantado e o URL do endpoint.
6. Front-end: dados do usuário para pesquisa vetorial
Vamos criar um aplicativo Python simples com uma UX com tecnologia Gradio para testar rapidamente nossa implementação. Consulte a implementação aqui para implementar esse app de demonstração no seu próprio notebook do Colab.
- Vamos usar o SDK Python da aiplatform para chamar a API Embeddings e também para invocar o endpoint do índice de pesquisa vetorial.
# [START aiplatform_sdk_embedding]
!pip install google-cloud-aiplatform==1.35.0 --upgrade --quiet --user
import vertexai
vertexai.init(project=PROJECT_ID, location="us-central1")
from vertexai.language_models import TextEmbeddingModel
import sys
if "google.colab" in sys.modules:
# Define project information
PROJECT_ID = " " # Your project id
LOCATION = " " # Your location
# Authenticate user to Google Cloud
from google.colab import auth
auth.authenticate_user()
- Vamos usar o Gradio para demonstrar o aplicativo de IA que estamos criando de forma rápida e fácil com uma interface do usuário. Reinicie o ambiente de execução antes de implementar esta etapa.
!pip install gradio
import gradio as gr
- No app da Web, após a entrada do usuário, invoque a API Embeddings. Vamos usar o modelo de embedding de texto: textembedding-gecko@latest
O método abaixo invoca o modelo de embedding de texto e retorna os embeddings vetoriais para o texto inserido pelo usuário:
def text_embedding(content) -> list:
"""Text embedding with a Large Language Model."""
model = TextEmbeddingModel.from_pretrained("textembedding-gecko@latest")
embeddings = model.get_embeddings(content)
for embedding in embeddings:
vector = embedding.values
#print(f"Length of Embedding Vector: {len(vector)}")
return vector
Realizar o teste
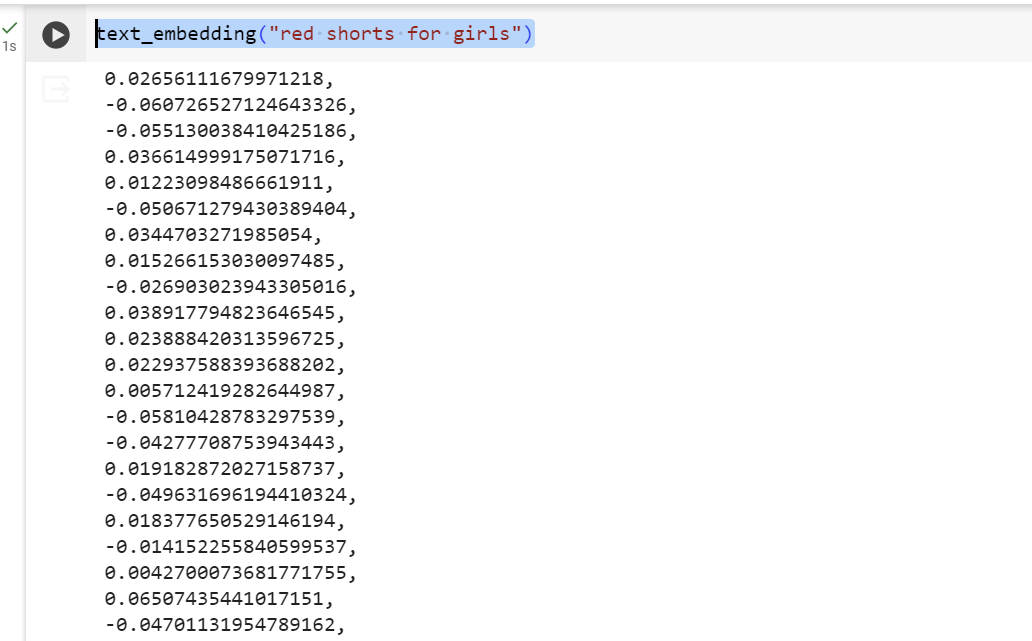
text_embedding("red shorts for girls")
Você verá uma saída semelhante à abaixo (observe que a imagem é cortada em altura para que você não consiga ver a resposta vetorial inteira):
- Declare o ID do índice implantado e o ID do endpoint.
from google.cloud import aiplatform
DEPLOYED_INDEX_ID = "spanner_vector1_1702366982123"
#Vector Search Endpoint
index_endpoint = aiplatform.MatchingEngineIndexEndpoint('projects/273845608377/locations/us-central1/indexEndpoints/2021628049526620160')
- Defina o método de pesquisa vetorial para chamar o endpoint do índice e mostrar o resultado com as 10 correspondências mais próximas para a resposta de embedding correspondente ao texto de entrada do usuário.
Na definição do método abaixo para pesquisa vetorial, observe que o método find_neighbors é invocado para identificar os 10 vetores mais próximos.
def vector_search(content) -> list:
result = text_embedding(content)
#call_vector_search_api(content)
index_endpoint = aiplatform.MatchingEngineIndexEndpoint('projects/273845608377/locations/us-central1/indexEndpoints/2021628049526620160')
# run query
response = index_endpoint.find_neighbors(
deployed_index_id = DEPLOYED_INDEX_ID,
queries = [result],
num_neighbors = 10
)
out = []
# show the results
for idx, neighbor in enumerate(response[0]):
print(f"{neighbor.distance:.2f} {spanner_read_data(neighbor.id)}")
out.append(f"{spanner_read_data(neighbor.id)}")
return out
Você também vai notar a chamada para o método spanner_read_data. Vamos analisar isso na próxima etapa.
- Defina a implementação do método de leitura de dados do Spanner que invoca o método execute_sql para extrair as imagens correspondentes aos IDs dos vetores de vizinhos mais próximos retornados da última etapa.
!pip install google-cloud-spanner==3.36.0
from google.cloud import spanner
instance_id = "spanner-vertex"
database_id = "spanner-vertex-embeddings"
projectId = PROJECT_ID
client = spanner.Client()
client.project = projectId
instance = client.instance(instance_id)
database = instance.database(database_id)
def spanner_read_data(id):
query = "SELECT uri FROM apparels where id = " + id
outputs = []
with database.snapshot() as snapshot:
results = snapshot.execute_sql(query)
for row in results:
#print(row)
#output = "ID: {}, CONTENT: {}, URI: {}".format(*row)
output = "{}".format(*row)
outputs.append(output)
return "\n".join(outputs)
Ele deve retornar os URLs das imagens correspondentes aos vetores escolhidos.
- Por fim, vamos juntar as partes em uma interface do usuário e acionar o processo de pesquisa vetorial.
from PIL import Image
def call_search(query):
response = vector_search(query)
return response
input_text = gr.Textbox(label="Enter your query. Examples: Girls Tops White Casual, Green t-shirt girls, jeans shorts, denim skirt etc.")
output_texts = [gr.Image(label="") for i in range(10)]
demo = gr.Interface(fn=call_search, inputs=input_text, outputs=output_texts, live=True)
resp = demo.launch(share = True)
Você verá o resultado mostrado abaixo:
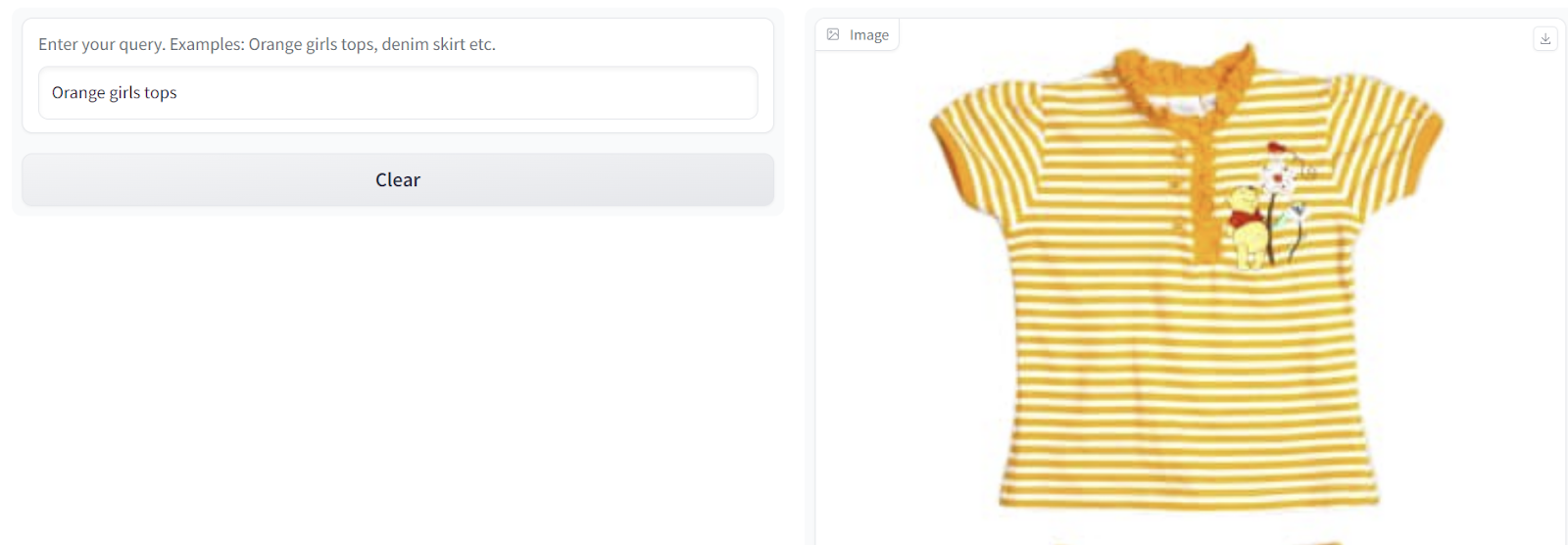
Imagem: link
Confira o vídeo de resultado: aqui.
7. Liberar espaço
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados nesta postagem, siga estas etapas:
- No console do Google Cloud, acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir.
- Na caixa de diálogo, digite o ID do projeto e clique em Desligar para excluí-lo.
- Se você não quiser excluir o projeto, exclua a instância do Spanner navegando até a instância que acabou de criar para esse projeto e clique no botão "EXCLUIR INSTÂNCIA" no canto superior direito da página de visão geral da instância.
- Você também pode navegar até o índice de pesquisa vetorial, cancelar a implantação do endpoint e do índice e excluir o índice.
8. Conclusão
Parabéns! Você concluiu a implementação da pesquisa vetorial do Spanner - Vertex
- Criando a fonte de dados e os embeddings do Spanner para aplicativos originados do banco de dados do Spanner.
- Criando o índice do banco de dados de pesquisa vetorial.
- Integrando dados vetoriais do Spanner à pesquisa vetorial usando jobs de fluxo de dados e fluxo de trabalho.
- Implantando o índice em um endpoint.
- Por fim, invocando a pesquisa vetorial na entrada do usuário em uma implementação com tecnologia Python do SDK da Vertex AI.
Fique à vontade para estender a implementação ao seu caso de uso ou improvisar o caso de uso atual com novos recursos. Saiba mais sobre os recursos de aprendizado de máquina do Spanner aqui.