
1. ภาพรวม
ในโลกของแอปสุขภาพและความแข็งแรงสมบูรณ์ สิ่งสำคัญคือการมอบประสบการณ์การใช้งานที่สมบูรณ์และดึงดูดให้ผู้ใช้มีส่วนร่วม สําหรับแอปโยคะ หมายความว่าต้องนำเสนอมากกว่าคำอธิบายท่าทางแบบข้อความธรรมดา รวมถึงให้ข้อมูลที่ครอบคลุม เนื้อหามัลติมีเดีย และความสามารถในการค้นหาอัจฉริยะ ในบล็อกนี้ เราจะอธิบายวิธีสร้างฐานข้อมูลท่าโยคะที่มีประสิทธิภาพโดยใช้ Firestore ของ Google Cloud, ใช้ประโยชน์จากส่วนขยายการค้นหาเวกเตอร์สำหรับการจับคู่ตามบริบท และผสานรวมความสามารถของ Gemini 2.0 Flash (เวอร์ชันทดลอง) เพื่อทำงานกับเนื้อหาแบบหลายมิติ
เหตุผลที่ควรใช้ Firestore
Firestore ซึ่งเป็นฐานข้อมูลเอกสาร NoSQL แบบ Serverless ของ Google Cloud เป็นตัวเลือกที่ยอดเยี่ยมในการสร้างแอปพลิเคชันที่ปรับขนาดได้และเป็นแบบไดนามิก เหตุผลที่ฟีเจอร์นี้เหมาะกับแอปโยคะของเรามีดังนี้
- ความสามารถในการปรับขนาดและประสิทธิภาพ: Firestore จะปรับขนาดโดยอัตโนมัติเพื่อรองรับผู้ใช้หลายล้านคนและชุดข้อมูลขนาดใหญ่ เพื่อให้แอปของคุณยังคงตอบสนองได้แม้จะมีจำนวนผู้ใช้เพิ่มขึ้น
- การอัปเดตแบบเรียลไทม์: การซิงค์แบบเรียลไทม์ในตัวช่วยให้ข้อมูลสอดคล้องกันในทุกไคลเอ็นต์ที่เชื่อมต่อ จึงเหมาะอย่างยิ่งสําหรับฟีเจอร์ต่างๆ เช่น คลาสสดหรือการฝึกแบบร่วมมือ
- รูปแบบข้อมูลที่ยืดหยุ่น: โครงสร้างแบบเอกสารของ Firestore ช่วยให้คุณจัดเก็บข้อมูลประเภทต่างๆ ได้ ซึ่งรวมถึงข้อความ รูปภาพ และแม้แต่การฝัง ทำให้เหมาะสําหรับแสดงข้อมูลท่าโยคะที่ซับซ้อน
- การค้นหาที่มีประสิทธิภาพ: Firestore รองรับการค้นหาที่ซับซ้อน ซึ่งรวมถึงความเท่าเทียมกัน ความไม่เท่าเทียมกัน และตอนนี้ยังมีการค้นหาความคล้ายคลึงของเวกเตอร์ด้วยส่วนขยายใหม่
- การรองรับการทำงานแบบออฟไลน์: Firestore จะแคชข้อมูลไว้ในเครื่อง ซึ่งช่วยให้แอปทำงานได้แม้ในขณะที่ผู้ใช้ออฟไลน์
การเพิ่มประสิทธิภาพการค้นหาด้วยส่วนขยายการค้นหาเวกเตอร์ของ Firestore
การค้นหาแบบดั้งเดิมที่อิงตามคีย์เวิร์ดอาจจํากัดเมื่อต้องจัดการกับแนวคิดที่ซับซ้อน เช่น ท่าโยคะ ผู้ใช้อาจค้นหาท่าที่ "เปิดสะโพก" หรือ "ปรับปรุงสมดุล" โดยที่ไม่รู้ชื่อท่าที่เฉพาะเจาะจง ด้วยเหตุนี้ การค้นหาด้วยเวกเตอร์จึงเข้ามามีบทบาท
การค้นหาเวกเตอร์ด้วย Firestore ช่วยให้คุณทําสิ่งต่อไปนี้ได้
- สร้างการฝัง: เปลี่ยนรูปแบบคําอธิบายข้อความ และในอนาคตอาจเปลี่ยนรูปแบบรูปภาพและเสียงเป็นการนําเสนอเวกเตอร์เชิงตัวเลข (การฝัง) ที่จับความหมายเชิงอรรถศาสตร์โดยใช้โมเดล เช่น โมเดลที่มีใน Vertex AI หรือโมเดลที่กําหนดเอง
- จัดเก็บการฝัง: จัดเก็บการฝังเหล่านี้ในเอกสาร Firestore โดยตรง
- ทำการค้นหาแบบคล้ายกัน: ค้นหาฐานข้อมูลเพื่อหาเอกสารที่คล้ายกันตามความหมายกับเวกเตอร์การค้นหาหนึ่งๆ ซึ่งจะเปิดใช้การจับคู่ตามบริบท
การผสานรวม Gemini 2.0 Flash (เวอร์ชันทดลอง)
Gemini 2.0 Flash เป็นโมเดล AI แบบหลายมิติข้อมูลล้ำสมัยของ Google แม้ว่าจะยังอยู่ระหว่างการทดสอบ แต่ฟีเจอร์นี้เปิดโอกาสที่น่าสนใจในการยกระดับแอปโยคะของเรา
- การสร้างข้อความ: ใช้ Gemini 2.0 Flash เพื่อสร้างคำอธิบายท่าโยคะอย่างละเอียด รวมถึงประโยชน์ การปรับท่า และข้อห้าม
- การสร้างรูปภาพ (เลียนแบบ): แม้ว่าการสร้างรูปภาพโดยตรงด้วย Gemini จะยังไม่พร้อมให้บริการแก่สาธารณะ แต่เราได้จำลองสิ่งนี้โดยใช้ Imagen ของ Google ซึ่งสร้างรูปภาพที่แสดงภาพท่าทาง
- การสร้างเสียง (เลียนแบบ): ในทำนองเดียวกัน เราสามารถใช้บริการการอ่านออกเสียงข้อความ (TTS) เพื่อสร้างคําแนะนําแบบเสียงสําหรับท่าแต่ละท่า ซึ่งจะแนะนําผู้ใช้ในการฝึก
เราอาจเสนอการผสานรวมเพื่อปรับปรุงแอปให้ใช้ฟีเจอร์ต่อไปนี้ของโมเดล
- Live API แบบหลายรูปแบบ: API ใหม่นี้ช่วยให้คุณสร้างแอปพลิเคชันสตรีมมิงภาพและเสียงแบบเรียลไทม์ด้วยการใช้เครื่องมือ
- ความเร็วและประสิทธิภาพ: Gemini 2.0 Flash ปรับปรุงเวลาในการรับโทเค็นแรก (TTFT) ได้อย่างมากเมื่อเทียบกับ Gemini 1.5 Flash
- ประสบการณ์การใช้งานที่ดีขึ้น: Gemini 2.0 มีการปรับปรุงความเข้าใจแบบมัลติโมเดล การเขียนโค้ด การทำตามคำสั่งที่ซับซ้อน และการเรียกใช้ฟังก์ชัน การปรับปรุงเหล่านี้ทำงานร่วมกันเพื่อรองรับประสบการณ์การใช้งานที่ดีขึ้น
ดูรายละเอียดเพิ่มเติมได้ที่หน้า%20over%20Gemini%201.5%20Flash) ของเอกสารประกอบนี้
การต่อสายกราวด์ด้วย Google Search
เราสามารถผสานรวม Google Search เพื่อตรวจสอบข้อมูลที่ได้จากแอปของเราเพื่อเพิ่มความน่าเชื่อถือและมอบแหล่งข้อมูลเพิ่มเติมได้ ซึ่งหมายความว่า
- การค้นหาตามบริบท: เมื่อผู้ใช้ที่ดูแลระบบป้อนรายละเอียดของท่าทาง เราสามารถใช้ชื่อท่าทางเพื่อทำการค้นหาใน Google
- การดึงข้อมูล URL: เราดึงข้อมูล URL ที่เกี่ยวข้อง เช่น บทความ วิดีโอ หรือเว็บไซต์โยคะที่มีชื่อเสียง ออกจากผลการค้นหาได้ และแสดงภายในแอป
สิ่งที่คุณจะสร้าง
คุณจะทําสิ่งต่อไปนี้ได้
- สร้างคอลเล็กชัน Firestore และโหลดเอกสาร Yoga
- ดูวิธีสร้างแอปพลิเคชัน CRUD ด้วย Firestore
- สร้างคำอธิบายท่าโยคะด้วย Gemini 2.0 Flash
- เปิดใช้ Firebase Vector Search ด้วยการผสานรวม Firestore
- สร้างการฝังจากคำอธิบายโยคะ
- ทำการค้นหาความคล้ายคลึงกันของข้อความค้นหาของผู้ใช้
ข้อกำหนด
2. ก่อนเริ่มต้น
สร้างโปรเจ็กต์
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud ในหน้าตัวเลือกโปรเจ็กต์
- ตรวจสอบว่าเปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ Cloud แล้ว ดูวิธีตรวจสอบว่าเปิดใช้การเรียกเก็บเงินในโปรเจ็กต์หรือไม่
- คุณจะใช้ Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud และโหลด bq ไว้ล่วงหน้า คลิก "เปิดใช้งาน Cloud Shell" ที่ด้านบนของคอนโซล Google Cloud

- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและโปรเจ็กต์ได้รับการตั้งค่าเป็นรหัสโปรเจ็กต์ของคุณโดยใช้คําสั่งต่อไปนี้
gcloud auth list
- เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อยืนยันว่าคำสั่ง gcloud รู้จักโปรเจ็กต์ของคุณ
gcloud config list project
- หากยังไม่ได้ตั้งค่าโปรเจ็กต์ ให้ใช้คําสั่งต่อไปนี้เพื่อตั้งค่า
gcloud config set project <YOUR_PROJECT_ID>
- เปิดใช้ API ที่จำเป็นโดยไปที่ลิงก์นี้จนกว่าคุณจะคลิกปุ่ม "เปิดใช้" ได้
หากมี API ใดขาดหายไป คุณสามารถเปิดใช้งานได้ทุกเมื่อในระหว่างการติดตั้งใช้งาน
โปรดดูคำสั่งและการใช้งาน gcloud ในเอกสารประกอบ
3. การตั้งค่าฐานข้อมูล
เอกสารประกอบมีขั้นตอนที่สมบูรณ์ยิ่งขึ้นเกี่ยวกับวิธีตั้งค่าอินสแตนซ์ Firestore ขั้นตอนคร่าวๆ ในการเริ่มต้นมีดังนี้
1 ไปที่ Firestore Viewer แล้วเลือก Firestore ในโหมดเนทีฟจากหน้าจอ "เลือกบริการฐานข้อมูล"
- เลือกตำแหน่งสำหรับ Firestore (ตรวจสอบว่าได้เลือก us-central1 แล้วและทำตามขั้นตอนนี้ทุกครั้งที่คุณเลือกภูมิภาค / ตำแหน่งในโค้ดแล็บนี้)
- คลิกสร้างฐานข้อมูล (หากเป็นการใช้งานครั้งแรก ให้ปล่อยเป็นฐานข้อมูล "(default)")
เมื่อสร้างโปรเจ็กต์ Firestore ระบบจะเปิดใช้ API ในเครื่องมือจัดการ Cloud API ด้วย
- สำคัญ: เลือกกฎความปลอดภัยเวอร์ชันทดสอบ (ไม่ใช่เวอร์ชันที่ใช้งานจริง) เพื่อให้เข้าถึงข้อมูลได้
- เมื่อตั้งค่าแล้ว คุณควรเห็นมุมมองฐานข้อมูล คอลเล็กชัน และเอกสาร Firestore ในโหมดเนทีฟดังที่แสดงในรูปภาพด้านล่าง
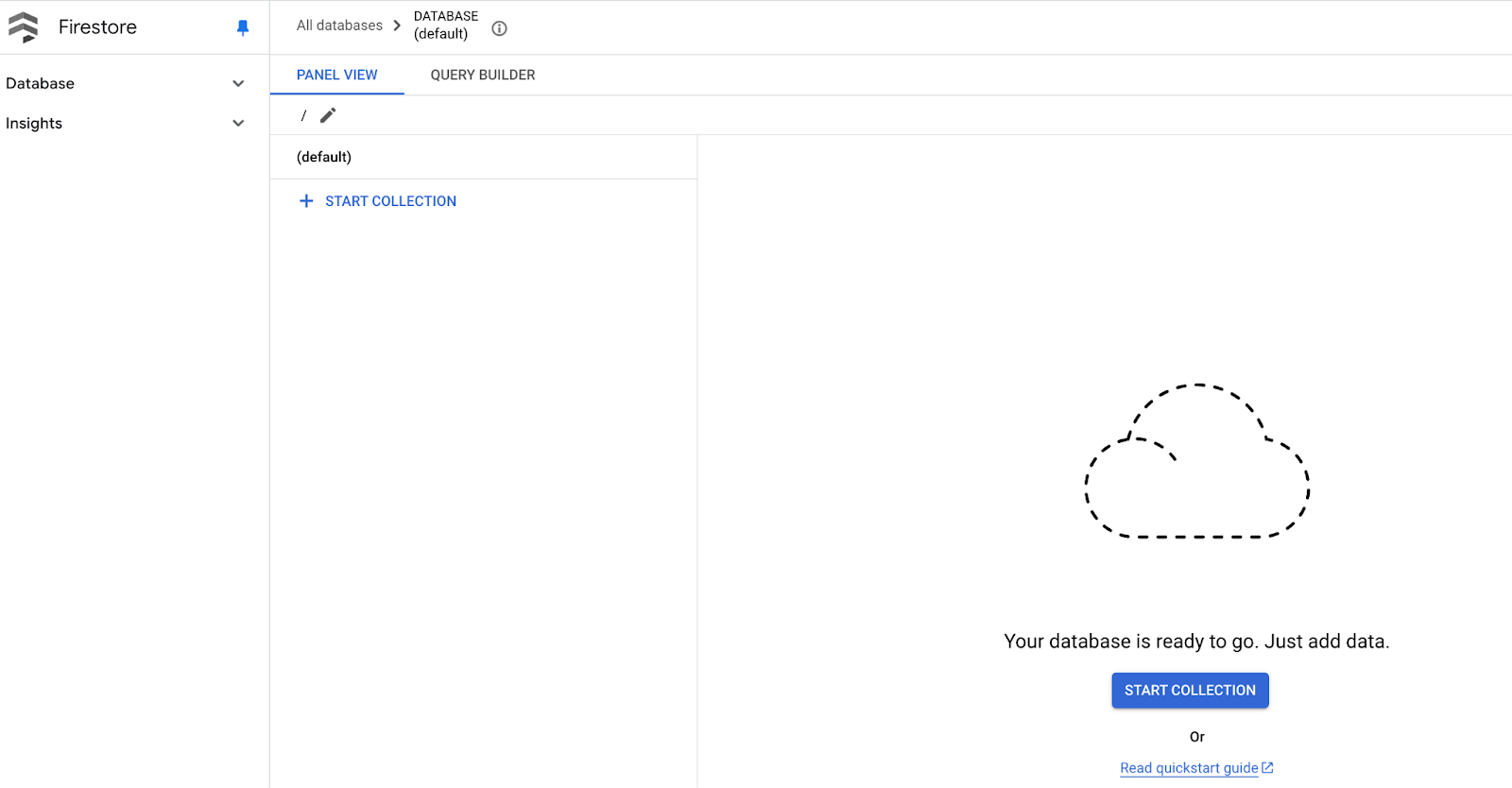
- คุณยังไม่ต้องทำขั้นตอนนี้ แต่โปรดทราบว่าคุณสามารถคลิก "เริ่มคอลเล็กชัน" และสร้างคอลเล็กชันใหม่ได้ ตั้งรหัสคอลเล็กชันเป็น "poses" คลิกปุ่มบันทึก
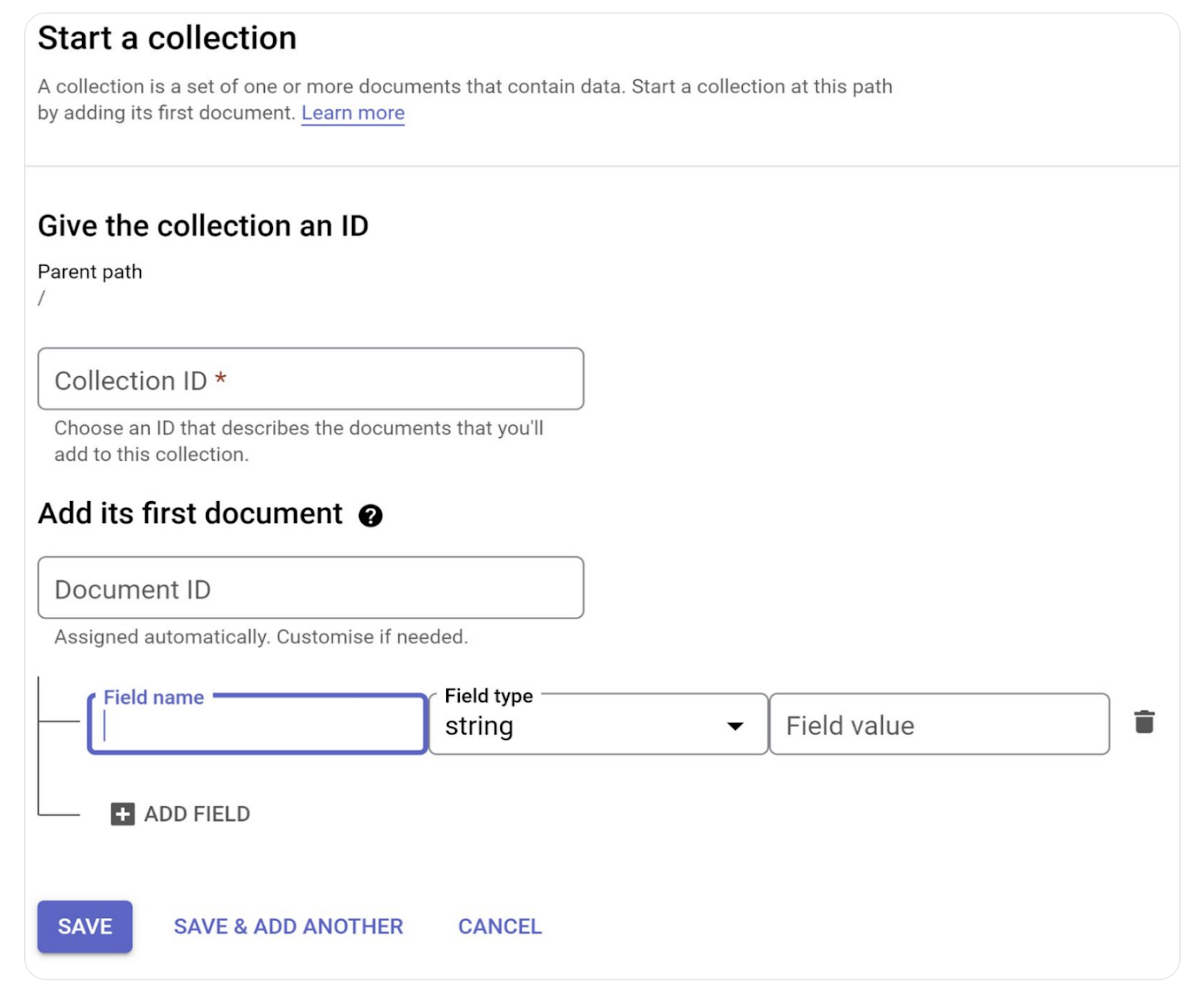
เคล็ดลับสำหรับมือโปรสำหรับการใช้งานเวอร์ชันที่ใช้งานจริง:
- เมื่อสร้างโมเดลข้อมูลและระบุผู้ที่ควรเข้าถึงเอกสารประเภทต่างๆ ได้แล้ว คุณสามารถสร้าง แก้ไข และตรวจสอบกฎความปลอดภัยจากอินเทอร์เฟซ Firebase คุณเข้าถึงกฎความปลอดภัยได้จากลิงก์นี้ https://console.firebase.google.com/u/0/project/<<your_project_id>>/firestore/rules
- อย่าลืมแก้ไข ตรวจสอบ และทดสอบกฎด้านความปลอดภัยก่อนทำให้โปรเจ็กต์ใช้งานได้จริงจากระยะการพัฒนา เนื่องจากกฎเหล่านี้มักเป็นสาเหตุที่ทำให้แอปทำงานต่างออกไปโดยที่คุณไม่รู้ตัว :)
ในการสาธิตนี้ เราจะใช้โหมดทดสอบ
4. Firestore REST API
- REST API มีประโยชน์สําหรับกรณีการใช้งานต่อไปนี้a. การเข้าถึง Firestore จากสภาพแวดล้อมที่มีทรัพยากรจํากัดซึ่งไม่สามารถเรียกใช้คลังไคลเอ็นต์ที่สมบูรณ์ได้ การดูแลระบบฐานข้อมูลอัตโนมัติหรือการดึงข้อมูลเมตาฐานข้อมูลที่ละเอียด
- วิธีที่ง่ายที่สุดในการใช้ Firestore คือการใช้ไลบรารีไคลเอ็นต์แบบเนทีฟอย่างใดอย่างหนึ่ง แต่ก็มีบางกรณีที่การเรียก REST API โดยตรงจะมีประโยชน์
- ในขอบเขตของบล็อกนี้ คุณจะเห็นการใช้งานและการสาธิต Firestore REST API ไม่ใช่ไลบรารีไคลเอ็นต์แบบเนทีฟ
- Firestore REST API ยอมรับโทเค็นรหัสการตรวจสอบสิทธิ์ Firebase หรือโทเค็น OAuth 2.0 ของข้อมูลประจำตัวของ Google สำหรับการตรวจสอบสิทธิ์ ดูข้อมูลเพิ่มเติมเกี่ยวกับหัวข้อการตรวจสอบสิทธิ์และการให้สิทธิ์ได้ที่เอกสารประกอบ
- ปลายทาง REST API ทั้งหมดอยู่ภายใต้ URL พื้นฐาน https://firestore.googleapis.com/v1/
Spring Boot และ Firestore API
โซลูชันนี้ในเฟรมเวิร์ก Spring Boot มีไว้เพื่อสาธิตแอปพลิเคชันไคลเอ็นต์ที่ใช้ Firestore API เพื่อรวบรวมและแก้ไขรายละเอียดท่าโยคะและการหายใจด้วยประสบการณ์การโต้ตอบของผู้ใช้
ดูคำอธิบายแบบทีละขั้นตอนโดยละเอียดเกี่ยวกับโซลูชัน CRUD ของ Firestore ในแอปท่าโยคะได้ที่ลิงก์บล็อก
หากต้องการมุ่งเน้นที่โซลูชันปัจจุบันและเรียนรู้ส่วน CRUD ในระหว่างเดินทาง ให้โคลนโซลูชันทั้งหมดที่มุ่งเน้นที่บล็อกนี้จากที่เก็บข้อมูลด้านล่างจากเทอร์มินัล Cloud Shell และรับสำเนาของโค้ดเบส
git clone https://github.com/AbiramiSukumaran/firestore-poserecommender
โปรดทราบว่า
- เมื่อโคลนที่เก็บข้อมูลนี้แล้ว คุณต้องทำการเปลี่ยนแปลงเพียงเล็กน้อยเกี่ยวกับรหัสโปรเจ็กต์, API ฯลฯ เท่านั้น ไม่จำเป็นต้องทำการเปลี่ยนแปลงอื่นๆ เพื่อทำให้แอปพลิเคชันใช้งานได้ องค์ประกอบแต่ละอย่างของแอปพลิเคชันจะอธิบายไว้ในส่วนถัดไป รายการการเปลี่ยนแปลงมีดังนี้
- ในไฟล์
src/main/java/com/example/demo/GenerateImageSample.javaให้แทนที่ "<<YOUR_PROJECT_ID>>" ด้วยรหัสโปรเจ็กต์ - ในไฟล์
src/main/java/com/example/demo/GenerateEmbeddings.javaให้แทนที่ "<<YOUR_PROJECT_ID>>" ด้วยรหัสโปรเจ็กต์ - ใน
src/main/java/com/example/demo/PoseController.javaให้แทนที่อินสแตนซ์ทั้งหมดของ "<<YOUR_PROJECT_ID>>"และชื่อฐานข้อมูล,ในกรณีนี้คือ"(default)",ด้วยค่าที่เหมาะสมจากการกําหนดค่า - ใน
src/main/java/com/example/demo/PoseController.javaให้แทนที่ "[YOUR_API_KEY]" ด้วยคีย์ API สำหรับ Gemini 2.0 Flash ซึ่งคุณรับได้จาก AI Studio - หากต้องการทดสอบในเครื่อง ให้เรียกใช้คําสั่งต่อไปนี้จากโฟลเดอร์โปรเจ็กต์ในเทอร์มินัล Cloud Shell
mvn package
mvn spring-boot:run
ขณะนี้คุณสามารถดูแอปพลิเคชันที่ทำงานอยู่ได้โดยคลิกตัวเลือก "ตัวอย่างเว็บ" จากเทอร์มินัล Cloud Shell เรายังไม่พร้อมทำการทดสอบและลองใช้แอปพลิเคชัน
- ไม่บังคับ: หากต้องการทำให้แอปใช้งานได้ใน Cloud Run คุณจะต้องเริ่มต้นแอปพลิเคชัน Java Cloud Run ใหม่ตั้งแต่ต้นจากเครื่องมือแก้ไข Cloud Shell และเพิ่มไฟล์ src และไฟล์เทมเพลตจาก repo ไปยังโปรเจ็กต์ใหม่ในโฟลเดอร์ที่เกี่ยวข้อง (เนื่องจากระบบไม่ได้ตั้งค่าโปรเจ็กต์ repo ของ GitHub ปัจจุบันไว้สำหรับการกำหนดค่าการทำให้ใช้งานได้ของ Cloud Run โดยค่าเริ่มต้น) ขั้นตอนที่ต้องทำในกรณีดังกล่าว (แทนการโคลนที่เก็บที่มีอยู่) มีดังนี้
- ไปที่เครื่องมือแก้ไข Cloud Shell (ตรวจสอบว่าเครื่องมือแก้ไขเปิดอยู่ ไม่ใช่เทอร์มินัล) คลิกไอคอนชื่อโปรเจ็กต์ Google Cloud ทางด้านซ้ายของแถบสถานะ (ส่วนที่บล็อกในภาพหน้าจอด้านล่าง)
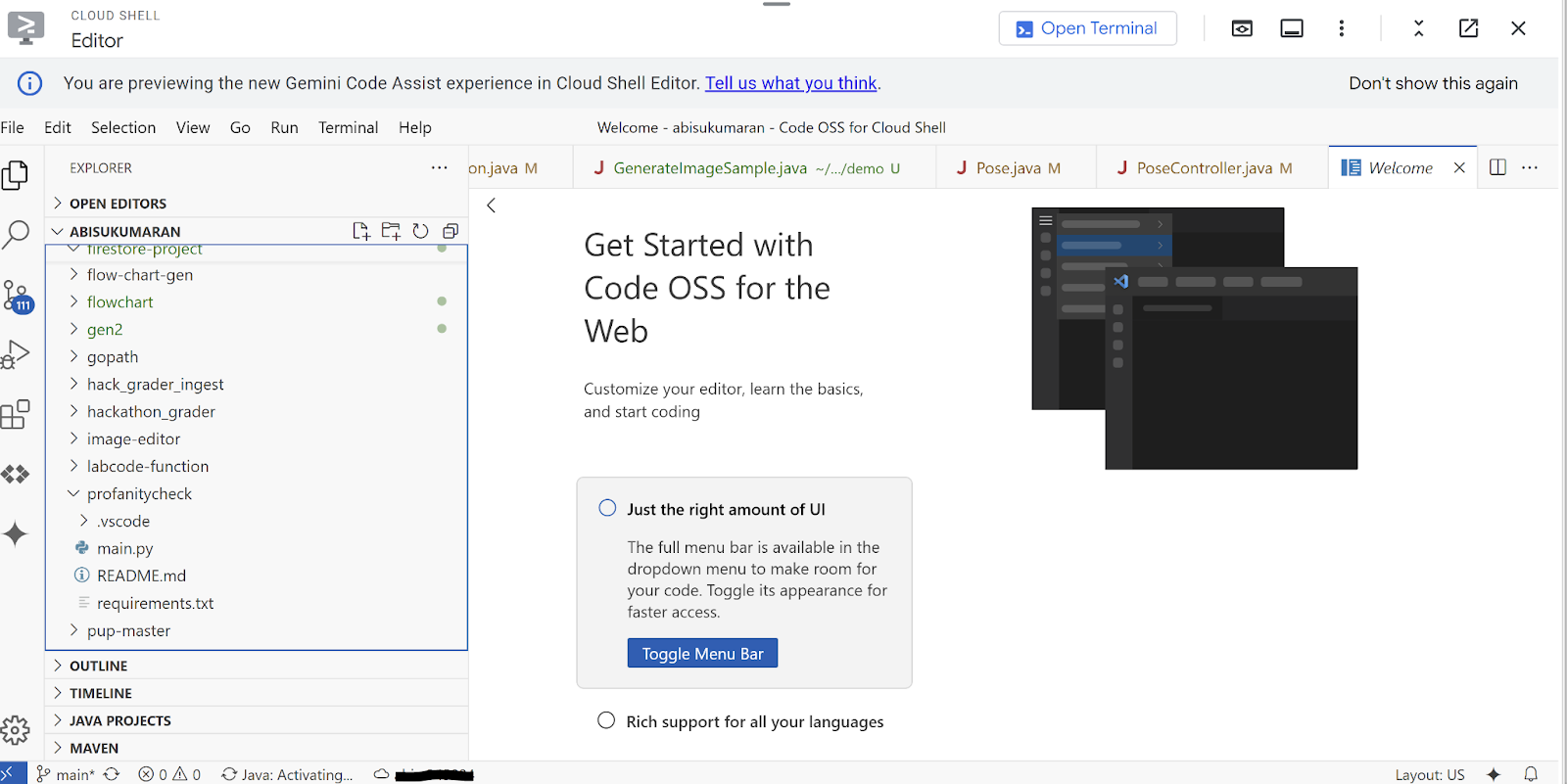
- เลือกแอปพลิเคชันใหม่ -> แอปพลิเคชัน Cloud Run -> Java: Cloud Run จากรายการตัวเลือก แล้วตั้งชื่อเป็น "firestore-poserecommender"
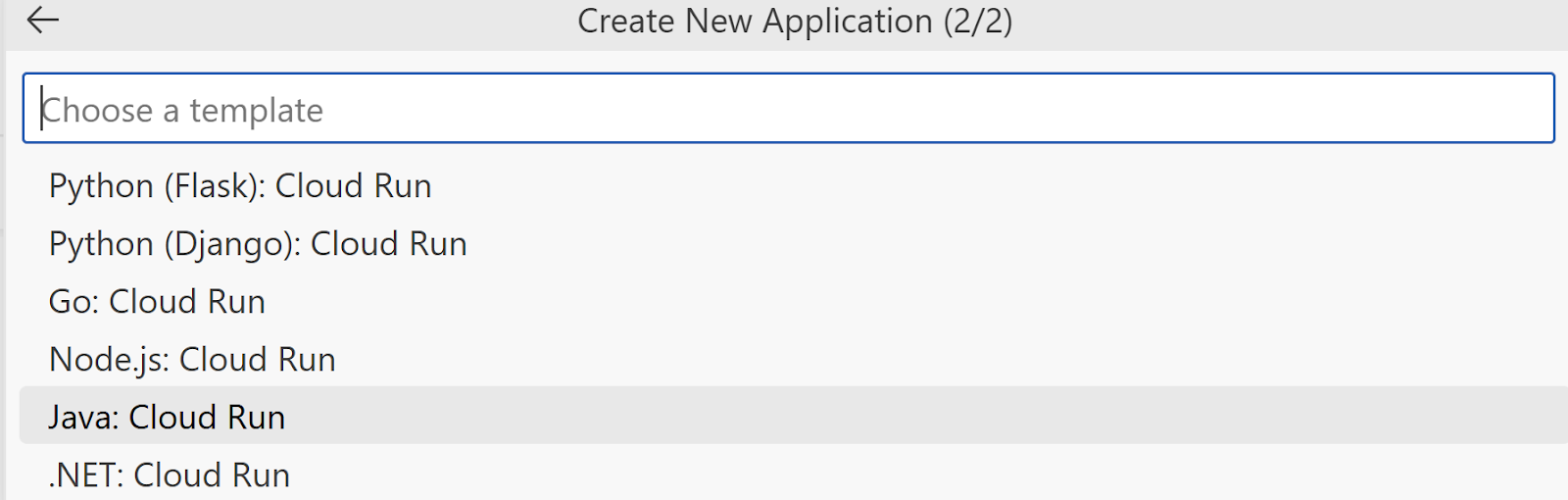
- ตอนนี้คุณควรเห็นเทมเพลตสแต็กแบบสมบูรณ์สําหรับแอปพลิเคชัน Java Cloud Run ที่กําหนดค่าไว้ล่วงหน้าและพร้อมใช้งาน
- นำคลาส Controller ที่มีอยู่ออก แล้วคัดลอกไฟล์ต่อไปนี้ไปยังโฟลเดอร์ที่เกี่ยวข้องในโครงสร้างโปรเจ็กต์
firestore-poserecommender/src/main/java/com/example/demo/
- FirestoreSampleApplication.java
- GenerateEmbeddings.java
- GenerateImageSample.java
- Pose.java
- PoseController.java
- ServletInitializer.java
firestore-poserecommender/src/main/resources/static/ - Index.html
firestore-poserecommender/src/main/resources/templates/
- contextsearch.html
- createpose.html
- errmessage.html
- pose.html
- ryoq.html
- searchpose.html
- showmessage.html
firestore-poserecommender/
- Dockerfile
- คุณต้องทําการเปลี่ยนแปลงในไฟล์ที่เกี่ยวข้องเพื่อแทนที่รหัสโปรเจ็กต์และคีย์ API ด้วยค่าที่เกี่ยวข้อง (ขั้นตอนที่ 1 ก ข ค และ ง ด้านบน)
5. การนำเข้าข้อมูล
ข้อมูลของแอปพลิเคชันอยู่ในไฟล์ data.json นี้ https://github.com/AbiramiSukumaran/firestore-poserecommender/blob/main/data.json
หากต้องการเริ่มต้นด้วยข้อมูลที่กําหนดไว้ล่วงหน้า ให้คัดลอก JSON มาแทนที่ "<<YOUR_PROJECT_ID>>" ทั้งหมดด้วยค่าของคุณ
- ไปที่ Firestore Studio
- ตรวจสอบว่าคุณได้สร้างคอลเล็กชันชื่อ "poses" แล้ว
- เพิ่มเอกสารจากไฟล์ repo ที่กล่าวถึงข้างต้นทีละรายการด้วยตนเอง
หรือจะนําเข้าข้อมูลในครั้งเดียวจากชุดที่กําหนดไว้ล่วงหน้าที่เราสร้างไว้ให้คุณก็ได้ โดยทําตามขั้นตอนต่อไปนี้
- ไปที่เทอร์มินัล Cloud Shell และตรวจสอบว่าได้ตั้งค่าโปรเจ็กต์ Google Cloud ที่ใช้งานอยู่และคุณได้รับสิทธิ์แล้ว สร้างที่เก็บข้อมูลในโปรเจ็กต์ด้วยคำสั่ง gsutil ที่ระบุไว้ด้านล่าง แทนที่ตัวแปร <PROJECT_ID> ในคําสั่งด้านล่างด้วยรหัสโปรเจ็กต์ Google Cloud ของคุณ
gsutil mb -l us gs://<PROJECT_ID>-yoga-poses-bucket
- เมื่อสร้างที่เก็บข้อมูลแล้ว เราจะต้องคัดลอกการส่งออกฐานข้อมูลที่เตรียมไว้ไปยังที่เก็บข้อมูลนี้ก่อนจึงจะนําเข้าไปยังฐานข้อมูล Firebase ได้ ใช้คำสั่งด้านล่างนี้
gsutil cp -r gs://demo-bq-gemini-public/yoga_poses gs://<PROJECT_ID>-yoga-poses-bucket
เมื่อเรามีข้อมูลที่จะนําเข้าแล้ว เราจึงไปยังขั้นตอนสุดท้ายของการนําเข้าข้อมูลไปยังฐานข้อมูล Firebase (ค่าเริ่มต้น) ที่เราสร้างขึ้นได้
- ไปที่คอนโซล Firestore แล้วคลิกนำเข้า/ส่งออกจากเมนูการนำทางด้านซ้าย
เลือก "นําเข้า" แล้วเลือกเส้นทาง Cloud Storage ที่คุณเพิ่งสร้าง จากนั้นไปยังส่วนต่างๆ จนกว่าคุณจะเลือกไฟล์ "yoga_poses.overall_export_metadata" ได้
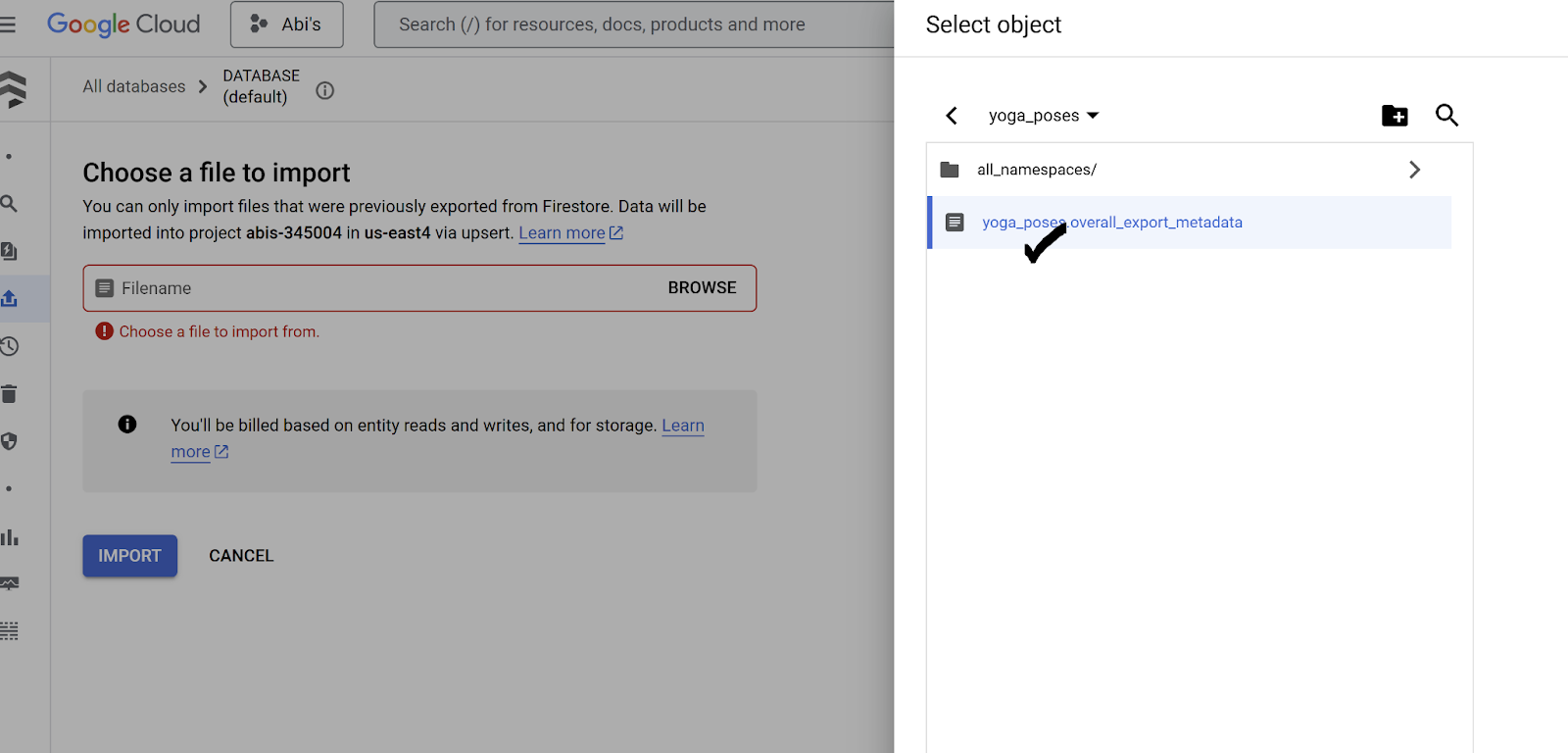
- คลิก "นำเข้า"
การนําเข้าจะใช้เวลา 2-3 วินาที เมื่อพร้อมแล้ว คุณสามารถตรวจสอบฐานข้อมูล Firestore และคอลเล็กชันได้โดยไปที่ https://console.cloud.google.com/firestore/databases เลือกฐานข้อมูลเริ่มต้นและคอลเล็กชันท่าดังที่แสดงด้านล่าง
- อีกวิธีหนึ่งคือคุณสร้างระเบียนด้วยตนเองผ่านแอปพลิเคชันได้ด้วยเมื่อติดตั้งใช้งานโดยใช้การดำเนินการ "สร้างท่าทางใหม่"
6. การค้นหาเวกเตอร์
เปิดใช้ส่วนขยายการค้นหาเวกเตอร์ของ Firestore
ใช้ส่วนขยายนี้เพื่อฝังและค้นหาเอกสาร Firestore โดยอัตโนมัติด้วยฟีเจอร์การค้นหาเวกเตอร์ใหม่ ซึ่งจะนำคุณไปยังฮับส่วนขยาย Firebase
เมื่อติดตั้งส่วนขยายการค้นหาเวกเตอร์ คุณต้องระบุคอลเล็กชันและชื่อช่องเอกสาร การเพิ่มหรืออัปเดตเอกสารที่มีฟิลด์นี้จะทริกเกอร์ส่วนขยายนี้ให้คํานวณการฝังเวกเตอร์สําหรับเอกสาร ระบบจะเขียนการฝังเวกเตอร์นี้กลับไปยังเอกสารเดิม และจัดทำดัชนีเอกสารในสตอเรจเวกเตอร์ให้พร้อมสำหรับการค้นหา
มาดูขั้นตอนต่างๆ กัน
ติดตั้งส่วนขยาย:
ติดตั้งส่วนขยาย "การค้นหาเวกเตอร์ด้วย Firestore" จาก Firebase Extensions Marketplace โดยคลิก "ติดตั้งในคอนโซล Firebase"
สำคัญ:
เมื่อไปที่หน้าส่วนขยายนี้เป็นครั้งแรก คุณจะต้องเลือกโปรเจ็กต์เดียวกับที่คุณกําลังทํางานในคอนโซล Google Cloud ที่แสดงในคอนโซล Firebase
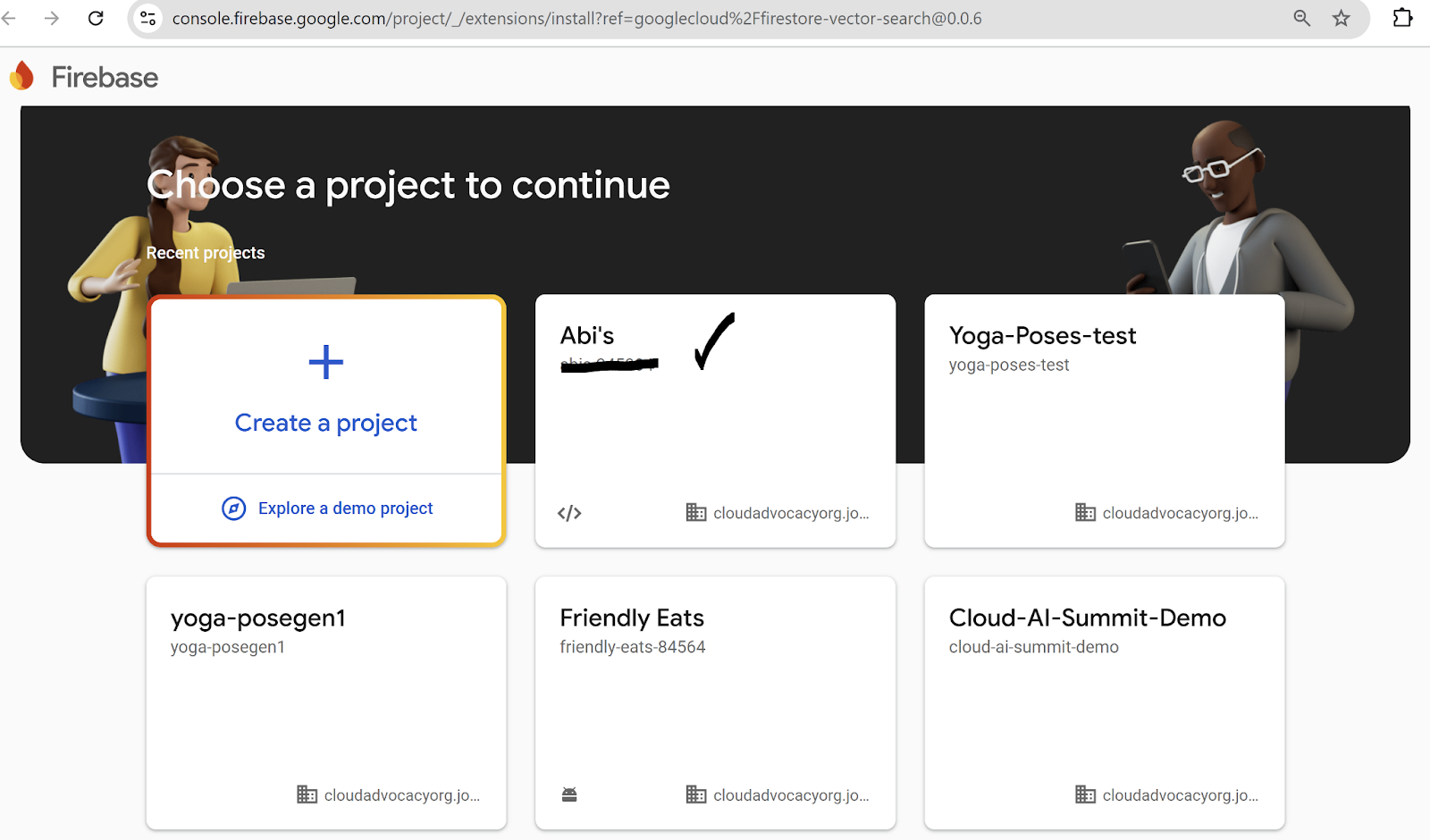
หากโปรเจ็กต์ไม่แสดงในรายการ ให้เพิ่มโปรเจ็กต์ใน Firebase (เลือกโปรเจ็กต์ Google Cloud ที่มีอยู่จากรายการ)
กําหนดค่าส่วนขยาย
ระบุคอลเล็กชัน ("poses") ฟิลด์ที่มีข้อความที่จะฝัง ("posture") และพารามิเตอร์อื่นๆ เช่น มิติข้อมูลการฝัง
หากมี API ที่ต้องเปิดใช้ในขั้นตอนนี้ หน้าการกําหนดค่าจะอนุญาตให้คุณดำเนินการดังกล่าว โดยให้ทําตามขั้นตอนตามลําดับ
หากหน้าเว็บไม่ตอบสนองหลังจากเปิดใช้ API ไปสักพัก ให้รีเฟรชหน้าเว็บแล้วคุณควรจะเห็น API ที่เปิดใช้
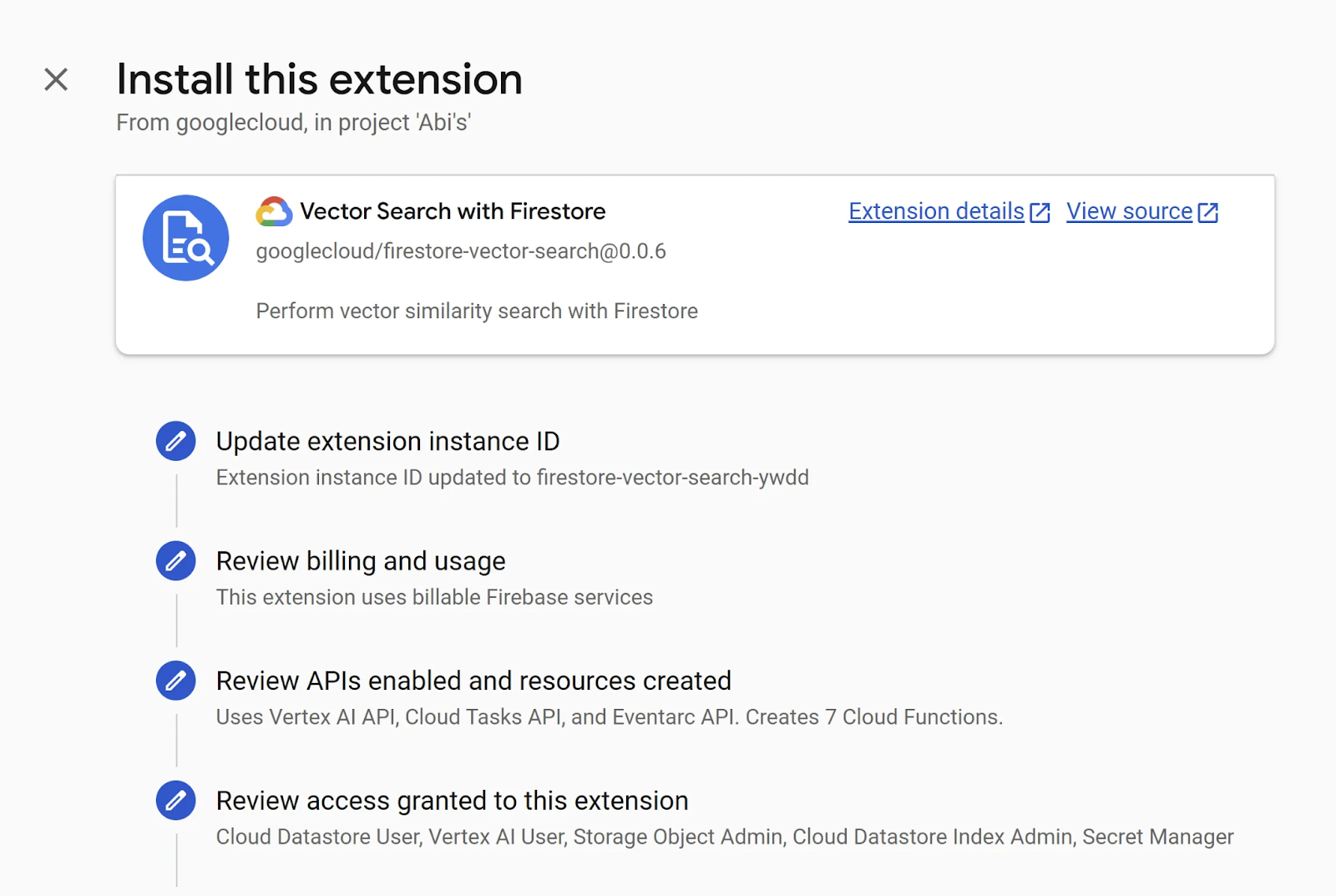
ในขั้นตอนใดขั้นตอนหนึ่งต่อไปนี้ คุณจะสามารถใช้ LLM ที่ต้องการเพื่อสร้างการฝังได้ เลือก "Vertex AI"
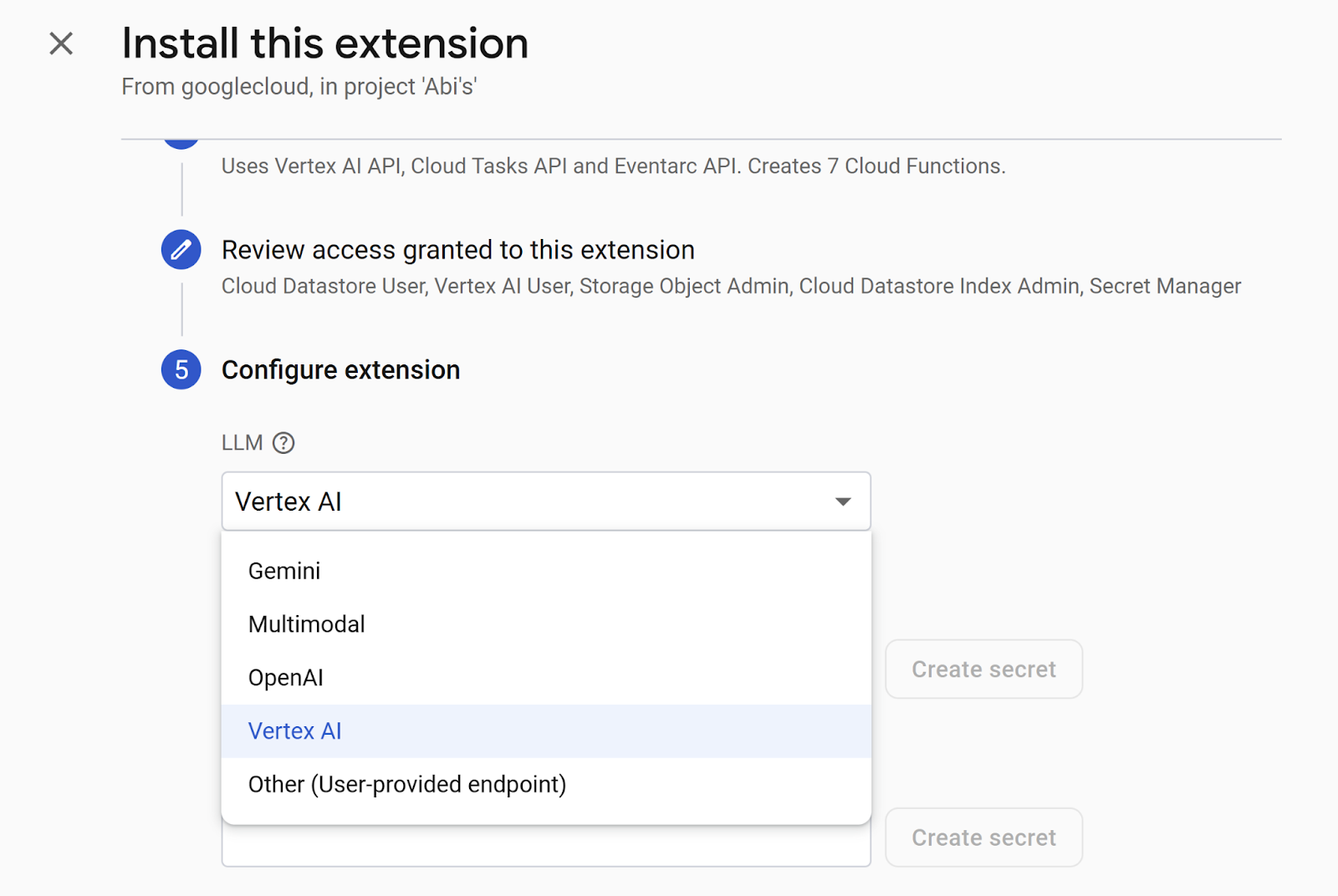
การตั้งค่า 2-3 รายการถัดไปเกี่ยวข้องกับคอลเล็กชันและช่องที่คุณต้องการฝัง
LLM: Vertex AI
เส้นทางของคอลเล็กชัน: poses
ขีดจํากัดการค้นหาเริ่มต้น: 3
การวัดระยะทาง: โคไซน์
ชื่อช่องป้อน: posture
ชื่อช่องเอาต์พุต: ฝัง
ชื่อฟิลด์สถานะ: status
ฝังเอกสารที่มีอยู่: ใช่
อัปเดตการฝังที่มีอยู่: ใช่
ตำแหน่ง Cloud Functions: us-central1
เปิดใช้เหตุการณ์: ไม่ได้เลือก
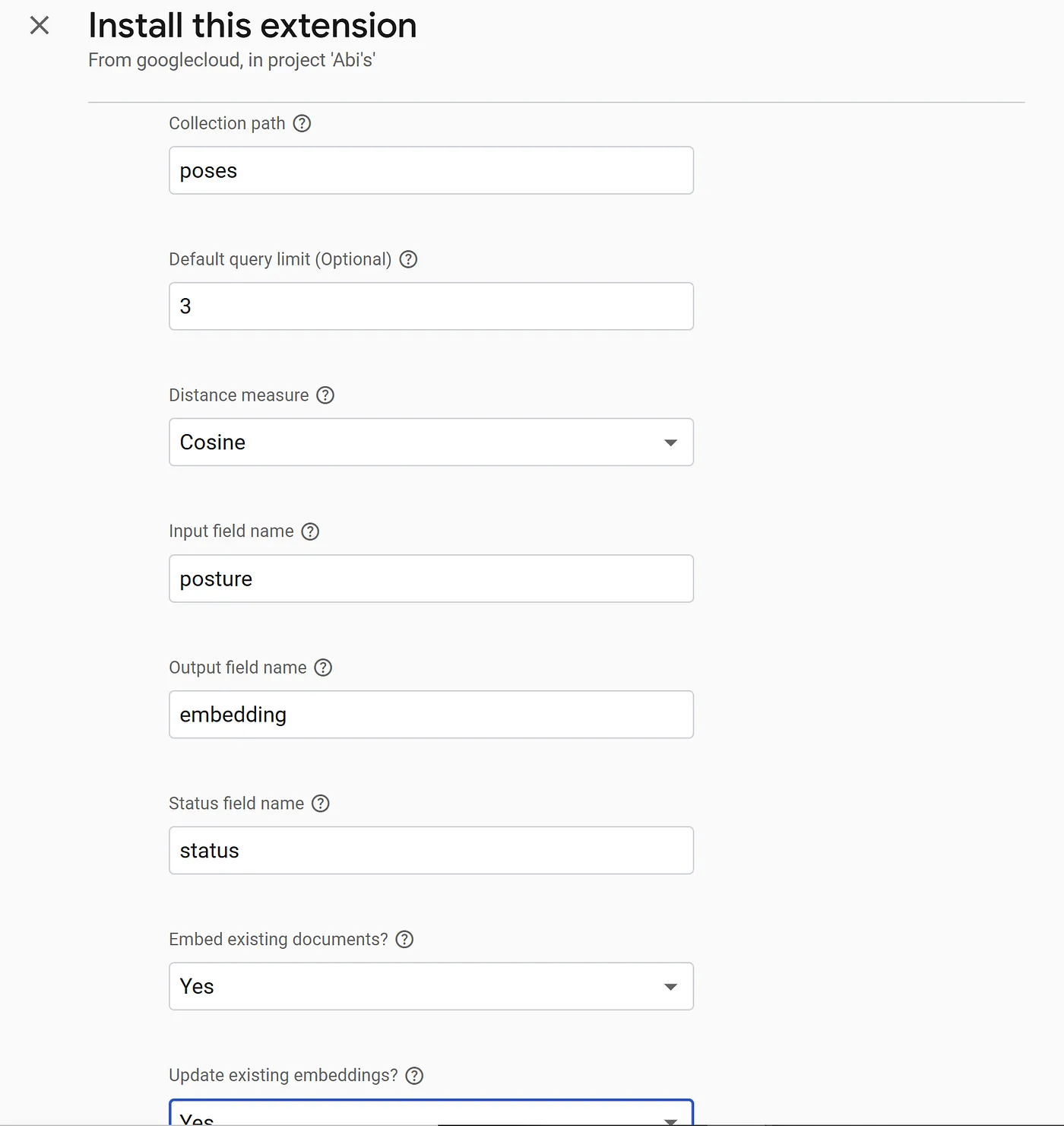
เมื่อตั้งค่าทั้งหมดแล้ว ให้คลิกปุ่ม "ติดตั้งส่วนขยาย" ซึ่งจะใช้เวลา 3-5 นาที
สร้างการฝัง:
เมื่อคุณเพิ่มหรืออัปเดตเอกสารในคอลเล็กชัน "ท่าทาง" ส่วนขยายจะสร้างการฝังโดยอัตโนมัติโดยใช้โมเดลที่ผ่านการฝึกอบรมไว้ล่วงหน้าหรือโมเดลที่คุณเลือกผ่านปลายทาง API ในกรณีนี้ เราเลือก Vertex AI ในการกําหนดค่าส่วนขยาย
การสร้างดัชนี
ซึ่งจะกำหนดให้สร้างดัชนีในช่องการฝัง ณ เวลาที่ใช้งานการฝังในแอปพลิเคชัน
Firestore จะสร้างดัชนีสําหรับการค้นหาพื้นฐานโดยอัตโนมัติ แต่คุณสามารถอนุญาตให้ Firestore สร้างไวยากรณ์ดัชนีได้โดยเรียกใช้การค้นหาที่ไม่มีดัชนี และระบบจะแสดงลิงก์ไปยังดัชนีที่สร้างขึ้นให้คุณในข้อความแสดงข้อผิดพลาดที่ฝั่งแอปพลิเคชัน ขั้นตอนในการสร้างดัชนีเวกเตอร์มีดังนี้
- ไปที่เทอร์มินัล Cloud Shell
- เรียกใช้คําสั่งต่อไปนี้
gcloud firestore indexes composite create --collection-group="poses" --query-scope=COLLECTION --database="(default)" --field-config vector-config='{"dimension":"768", "flat": "{}"}',field-path="embedding"
อ่านข้อมูลเพิ่มเติมได้ที่นี่
เมื่อสร้างดัชนีเวกเตอร์แล้ว คุณจะทำการค้นหาเพื่อนบ้านที่ใกล้ที่สุดด้วยเวกเตอร์เชิงลึกได้
หมายเหตุสำคัญ:
จากจุดนี้เป็นต้นไป คุณไม่จําเป็นต้องทําการเปลี่ยนแปลงใดๆ ในแหล่งที่มา เพียงทำตามขั้นตอนเพื่อทําความเข้าใจสิ่งที่แอปพลิเคชันกำลังทํา
ทำการค้นหาเวกเตอร์
มาดูว่าแอปพลิเคชันที่สร้างขึ้นใหม่ของคุณเข้าใกล้การค้นหาด้วยเวกเตอร์อย่างไร เมื่อจัดเก็บการฝังแล้ว คุณสามารถใช้คลาส VectorQuery ของ Firestore Java SDK เพื่อทำการค้นหาด้วยเวกเตอร์และรับผลลัพธ์ใกล้เคียงที่สุดได้ ดังนี้
CollectionReference coll = firestore.collection("poses");
VectorQuery vectorQuery = coll.findNearest(
"embedding",
userSearchTextEmbedding,
/* limit */ 3,
VectorQuery.DistanceMeasure.EUCLIDEAN,
VectorQueryOptions.newBuilder().setDistanceResultField("vector_distance")
.setDistanceThreshold(2.0)
.build());
ApiFuture<VectorQuerySnapshot> future = vectorQuery.get();
VectorQuerySnapshot vectorQuerySnapshot = future.get();
List<Pose> posesList = new ArrayList<Pose>();
// Get the ID of the closest document (assuming results are sorted by distance)
String closestDocumentId = vectorQuerySnapshot.getDocuments().get(0).getId();
ข้อมูลโค้ดนี้เปรียบเทียบการฝังข้อความค้นหาของผู้ใช้กับการฝังเอกสารใน Firestore และดึงข้อมูลโค้ดที่ใกล้เคียงที่สุดตามบริบท
7. Gemini 2.0 Flash
การผสานรวม Gemini 2.0 Flash (สําหรับการสร้างคําอธิบาย)
มาดูกันว่าแอปพลิเคชันที่สร้างขึ้นใหม่จัดการการผสานรวม Gemini 2.0 Flash เพื่อสร้างคำอธิบายอย่างไร
สมมติว่าผู้ใช้ที่ดูแลระบบ / ผู้สอนโยคะต้องการป้อนรายละเอียดของท่าด้วยความช่วยเหลือของ Gemini 2.0 Flash แล้วทำการค้นหาเพื่อดูรายการที่ตรงกันมากที่สุด การดำเนินการนี้ส่งผลให้มีการดึงรายละเอียดของท่าทางที่ตรงกันพร้อมกับออบเจ็กต์หลายรูปแบบที่รองรับผลลัพธ์
String apiUrl = "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.0-flash-exp:generateContent?key=[YOUR_API_KEY]";
Map<String, Object> requestBody = new HashMap<>();
List<Map<String, Object>> contents = new ArrayList<>();
List<Map<String, Object>> tools = new ArrayList<>();
Map<String, Object> content = new HashMap<>();
List<Map<String, Object>> parts = new ArrayList<>();
Map<String, Object> part = new HashMap<>();
part.put("text", prompt);
parts.add(part);
content.put("parts", parts);
contents.add(content);
requestBody.put("contents", contents);
/**Setting up Grounding*/
Map<String, Object> googleSearchTool = new HashMap<>();
googleSearchTool.put("googleSearch", new HashMap<>());
tools.add(googleSearchTool);
requestBody.put("tools", tools);
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
HttpEntity<Map<String, Object>> requestEntity = new HttpEntity<>(requestBody, headers);
ResponseEntity<String> response = restTemplate.exchange(apiUrl, HttpMethod.POST, requestEntity, String.class);
System.out.println("Generated response: " + response);
String responseBody = response.getBody();
JSONObject jsonObject = new JSONObject(responseBody);
JSONArray candidates = jsonObject.getJSONArray("candidates");
JSONObject candidate = candidates.getJSONObject(0);
JSONObject contentResponse = candidate.getJSONObject("content");
JSONArray partsResponse = contentResponse.getJSONArray("parts");
JSONObject partResponse = partsResponse.getJSONObject(0);
String generatedText = partResponse.getString("text");
System.out.println("Generated Text: " + generatedText);
ก. การเลียนแบบการสร้างรูปภาพและเสียง
Gemini 2.0 Flash Experimental สามารถสร้างผลลัพธ์แบบหลายรูปแบบได้ แต่เรายังไม่ได้ลงชื่อสมัครใช้การทดลองใช้ก่อนเปิดตัว จึงจำลองเอาต์พุตรูปภาพและเสียงด้วย Imagen และ TTS API ตามลำดับ ลองนึกภาพว่าการสร้างทั้งหมดนี้ด้วยการเรียกใช้ API 1 ครั้งไปยัง Gemini 2.0 Flash นั้นยอดเยี่ยมเพียงใด
try (PredictionServiceClient predictionServiceClient =
PredictionServiceClient.create(predictionServiceSettings)) {
final EndpointName endpointName =
EndpointName.ofProjectLocationPublisherModelName(
projectId, location, "google", "imagen-3.0-generate-001");
Map<String, Object> instancesMap = new HashMap<>();
instancesMap.put("prompt", prompt);
Value instances = mapToValue(instancesMap);
Map<String, Object> paramsMap = new HashMap<>();
paramsMap.put("sampleCount", 1);
paramsMap.put("aspectRatio", "1:1");
paramsMap.put("safetyFilterLevel", "block_few");
paramsMap.put("personGeneration", "allow_adult");
Value parameters = mapToValue(paramsMap);
PredictResponse predictResponse =
predictionServiceClient.predict(
endpointName, Collections.singletonList(instances), parameters);
for (Value prediction : predictResponse.getPredictionsList()) {
Map<String, Value> fieldsMap = prediction.getStructValue().getFieldsMap();
if (fieldsMap.containsKey("bytesBase64Encoded")) {
bytesBase64Encoded = fieldsMap.get("bytesBase64Encoded").getStringValue();
}
}
return bytesBase64Encoded;
}
try {
// Create a Text-to-Speech client
try (TextToSpeechClient textToSpeechClient = TextToSpeechClient.create()) {
// Set the text input to be synthesized
SynthesisInput input = SynthesisInput.newBuilder().setText(postureString).build();
// Build the voice request, select the language code ("en-US") and the ssml
// voice gender
// ("neutral")
VoiceSelectionParams voice =
VoiceSelectionParams.newBuilder()
.setLanguageCode("en-US")
.setSsmlGender(SsmlVoiceGender.NEUTRAL)
.build();
// Select the type of audio file you want returned
AudioConfig audioConfig =
AudioConfig.newBuilder().setAudioEncoding(AudioEncoding.MP3).build();
// Perform the text-to-speech request on the text input with the selected voice
// parameters and audio file type
SynthesizeSpeechResponse response =
textToSpeechClient.synthesizeSpeech(input, voice, audioConfig);
// Get the audio contents from the response
ByteString audioContents = response.getAudioContent();
// Convert to Base64 string
String base64Audio = Base64.getEncoder().encodeToString(audioContents.toByteArray());
// Add the Base64 encoded audio to the Pose object
return base64Audio;
}
} catch (Exception e) {
e.printStackTrace(); // Handle exceptions appropriately. For a real app, log and provide user feedback.
return "Error in Audio Generation";
}
}
ข. การกําหนดค่าพื้นฐานด้วย Google Search:
หากตรวจสอบโค้ดการเรียกใช้ Gemini ในขั้นตอนที่ 6 คุณจะเห็นข้อมูลโค้ดต่อไปนี้เพื่อเปิดใช้การอ้างอิงข้อมูลของ Google Search สําหรับคําตอบ LLM
/**Setting up Grounding*/
Map<String, Object> googleSearchTool = new HashMap<>();
googleSearchTool.put("googleSearch", new HashMap<>());
tools.add(googleSearchTool);
requestBody.put("tools", tools);
การดำเนินการนี้ช่วยให้เราดำเนินการต่อไปนี้ได้
- ปรับโมเดลให้สอดคล้องกับผลการค้นหาจริง
- ดึง URL ที่เกี่ยวข้องซึ่งอ้างอิงในผลการค้นหา
8. เรียกใช้แอปพลิเคชัน
มาดูความสามารถทั้งหมดของแอปพลิเคชัน Java Spring Boot ที่สร้างขึ้นใหม่ด้วยอินเทอร์เฟซเว็บ Thymeleaf ที่เรียบง่ายกัน
- การดำเนินการ CRUD ของ Firestore (สร้าง อ่าน อัปเดต ลบ)
- การค้นหาคีย์เวิร์ด
- การสร้างบริบทตาม Generative AI
- การค้นหาตามบริบท (การค้นหาเวกเตอร์)
- เอาต์พุตหลายโมดัลที่เกี่ยวข้องกับการค้นหา
- เรียกใช้คําค้นหาของคุณเอง (คําค้นหาในรูปแบบ StructuredQuery)
ตัวอย่าง: {"structuredQuery":{"select":{"fields":[{"fieldPath":"name"}]},"from":[{"collectionId":"fitness_poses"}]}}
ฟีเจอร์ทั้งหมดที่พูดถึงจนถึงตอนนี้เป็นส่วนหนึ่งของแอปพลิเคชันที่คุณเพิ่งสร้างจากรีโป https://github.com/AbiramiSukumaran/firestore-poserecommender
หากต้องการสร้าง เรียกใช้ และทำให้ใช้งานได้ ให้เรียกใช้คำสั่งต่อไปนี้จากเทอร์มินัล Cloud Shell
mvn package
mvn spring-boot:run
คุณควรเห็นผลลัพธ์และสามารถทดลองใช้ฟีเจอร์ของแอปพลิเคชันได้ ดูวิดีโอด้านล่างเพื่อดูการสาธิตเอาต์พุต
เครื่องมือแนะนำท่าทางด้วย Firestore, การค้นหาเวกเตอร์ และ Gemini 2.0 Flash
ขั้นตอนที่ไม่บังคับ:
หากต้องการทำให้ใช้งานได้ใน Cloud Run (สมมติว่าคุณได้เริ่มต้นแอปพลิเคชันใหม่ด้วย Dockerfile และคัดลอกไฟล์ตามที่จำเป็นแล้ว) ให้เรียกใช้คำสั่งต่อไปนี้จาก Cloud Shell Terminal ภายในไดเรกทอรีโปรเจ็กต์
gcloud run deploy --source .
ระบุชื่อแอปพลิเคชัน รหัสภูมิภาค (เลือกรหัสสำหรับ us-central1) แล้วเลือกการเรียกใช้ที่ไม่ผ่านการตรวจสอบสิทธิ์ "Y" ตามข้อความแจ้ง คุณควรได้รับปลายทางแอปพลิเคชันในเทอร์มินัลเมื่อการทําให้ใช้งานได้สําเร็จ
9. ล้างข้อมูล
โปรดทำตามขั้นตอนต่อไปนี้เพื่อเลี่ยงไม่ให้เกิดการเรียกเก็บเงินกับบัญชี Google Cloud สำหรับทรัพยากรที่ใช้ในโพสต์นี้
- ในคอนโซล Google Cloud ให้ไปที่หน้าจัดการทรัพยากร
- ในรายการโปรเจ็กต์ ให้เลือกโปรเจ็กต์ที่ต้องการลบ แล้วคลิกลบ
- ในกล่องโต้ตอบ ให้พิมพ์รหัสโปรเจ็กต์ แล้วคลิกปิดเพื่อลบโปรเจ็กต์
10. ขอแสดงความยินดี
ยินดีด้วย คุณใช้ Firestore เพื่อสร้างแอปพลิเคชันการจัดการท่าโยคะที่มีประสิทธิภาพและชาญฉลาดเรียบร้อยแล้ว การรวมความสามารถของ Firestore, ส่วนขยายการค้นหาเวกเตอร์ และความสามารถของ Gemini 2.0 Flash (ที่มีการสร้างภาพและเสียงจำลอง) ทำให้เราสร้างแอปโยคะที่มีส่วนร่วมและให้ข้อมูลอย่างแท้จริงเพื่อใช้การดำเนินการ CRUD, ทำการค้นหาตามคีย์เวิร์ด, การค้นหาเวกเตอร์ตามบริบท และสร้างเนื้อหามัลติมีเดีย
แนวทางนี้ไม่ได้จำกัดไว้เพียงแอปโยคะ เมื่อโมเดล AI เช่น Gemini พัฒนาอย่างต่อเนื่อง โอกาสในการสร้างประสบการณ์ของผู้ใช้ที่สมจริงและเหมาะกับผู้ใช้แต่ละคนมากขึ้นก็จะยิ่งเพิ่มขึ้น อย่าลืมติดตามข่าวสารเกี่ยวกับการพัฒนาและเอกสารประกอบล่าสุดจาก Google Cloud และ Firebase เพื่อใช้ประโยชน์จากเทคโนโลยีเหล่านี้อย่างเต็มศักยภาพ
หากต้องการขยายการให้บริการแอปนี้ ฉันจะพยายามทำ 2 อย่างกับ Gemini 2.0 Flash
- ใช้ Multimodal Live API เพื่อสร้างการสตรีมภาพและเสียงแบบเรียลไทม์สำหรับกรณีการใช้งาน
- ใช้โหมดการคิดเพื่อสร้างความคิดที่อยู่เบื้องหลังคำตอบสำหรับการโต้ตอบกับข้อมูลแบบเรียลไทม์เพื่อให้ประสบการณ์การใช้งานสมจริงยิ่งขึ้น
โปรดลองใช้และส่งคำขอดึงข้อมูลมา :>D!!!