
1. מבוא
Spanner הוא שירות מנוהל של מסד נתונים עם יכולת הרחבה אופקית, שמופץ באופן גלובלי ומתאים לעומסי עבודה רלציוניים ולא רלציוניים.
ממשק Cassandra של Spanner מאפשר לכם ליהנות מהתשתית המנוהלת, הניתנת להתאמה ובעלת הזמינות הגבוהה של Spanner, באמצעות כלים ותחביר מוכרים של Cassandra.
מה תלמדו
- איך מגדירים מסד נתונים ומופע Spanner.
- איך ממירים את הסכימה ואת מודל הנתונים של Cassandra.
- איך מייצאים נתונים היסטוריים מ-Cassandra ל-Spanner בכמות גדולה.
- איך מפנים את האפליקציה ל-Spanner במקום ל-Cassandra.
הדרישות
- פרויקט ב-Google Cloud שמקושר לחשבון לחיוב.
- גישה למכונה שמותקן בה
gcloudCLI ומגדירים אותה, או שימוש ב-Google Cloud Shell. - דפדפן אינטרנט, כמו Chrome או Firefox.
2. הגדרה ודרישות
יצירת פרויקט ב-GCP
נכנסים למסוף Google Cloud ויוצרים פרויקט חדש או משתמשים בפרויקט קיים. אם עדיין אין לכם חשבון Gmail או Google Workspace, אתם צריכים ליצור חשבון.

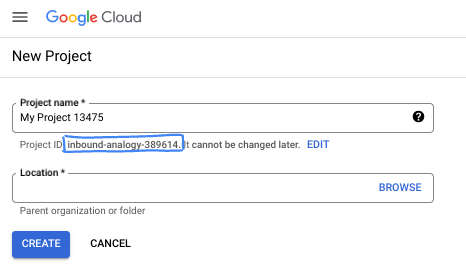
- שם הפרויקט הוא השם המוצג של הפרויקט הזה למשתתפים. זו מחרוזת תווים שלא נמצאת בשימוש ב-Google APIs. תמיד אפשר לעדכן את המיקום.
- מזהה הפרויקט הוא ייחודי לכל הפרויקטים ב-Google Cloud, והוא קבוע (אי אפשר לשנות אותו אחרי שהוא מוגדר). מסוף Cloud יוצר באופן אוטומטי מחרוזת ייחודית, ובדרך כלל לא צריך לדעת מה היא. ברוב ה-Codelabs, תצטרכו להפנות למזהה הפרויקט (בדרך כלל מסומן כ-
PROJECT_ID). אם אתם לא אוהבים את המזהה שנוצר, אתם יכולים ליצור מזהה אקראי אחר. אפשר גם לנסות כתובת משלכם ולבדוק אם היא זמינה. אי אפשר לשנות את הערך הזה אחרי השלב הזה, והוא יישאר כזה למשך הפרויקט. - לידיעתכם, יש ערך שלישי, מספר פרויקט, שחלק מממשקי ה-API משתמשים בו. מידע נוסף על שלושת הערכים האלה מופיע במאמרי העזרה.
הגדרת החיוב
לאחר מכן, תצטרכו לפעול לפי ההוראות במדריך למשתמש בנושא ניהול חיוב ולהפעיל את החיוב במסוף Cloud. משתמשים חדשים ב-Google Cloud זכאים לתוכנית תקופת ניסיון בחינם בשווי 300$. כדי להימנע מחיובים נוספים אחרי סיום המדריך הזה, אפשר להשבית את מופע Spanner בסוף ה-codelab לפי השלבים שבקטע 'שלב 9: ניקוי'.
הפעלת Cloud Shell
אפשר להפעיל את Google Cloud מרחוק מהמחשב הנייד, אבל ב-codelab הזה תשתמשו ב-Google Cloud Shell, סביבת שורת פקודה שפועלת בענן.
מתוך מסוף Google Cloud, לוחצים על סמל Cloud Shell בסרגל הכלים שבפינה הימנית העליונה:

יחלפו כמה רגעים עד שההקצאה והחיבור לסביבת העבודה יושלמו. בסיום התהליך, אמור להופיע משהו כזה:

המכונה הווירטואלית הזו כוללת את כל הכלים שדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות ברשת. אפשר לבצע את כל העבודה ב-codelab הזה בדפדפן. לא צריך להתקין שום דבר.
הבא בתור
בשלב הבא, תפרסו את אשכול Cassandra.
3. פריסת אשכול Cassandra (מקור)
ב-codelab הזה נגדיר אשכול Cassandra עם צומת יחיד ב-Compute Engine.
1. יצירת מכונה וירטואלית ב-GCE עבור Cassandra
כדי ליצור מכונה, משתמשים בפקודה gcloud compute instances create מ-Cloud Shell שהוקצה קודם.
gcloud compute instances create cassandra-origin \
--machine-type=e2-medium \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=cassandra-migration \
--boot-disk-size=20GB \
--zone=us-central1-a
2. התקנת Cassandra
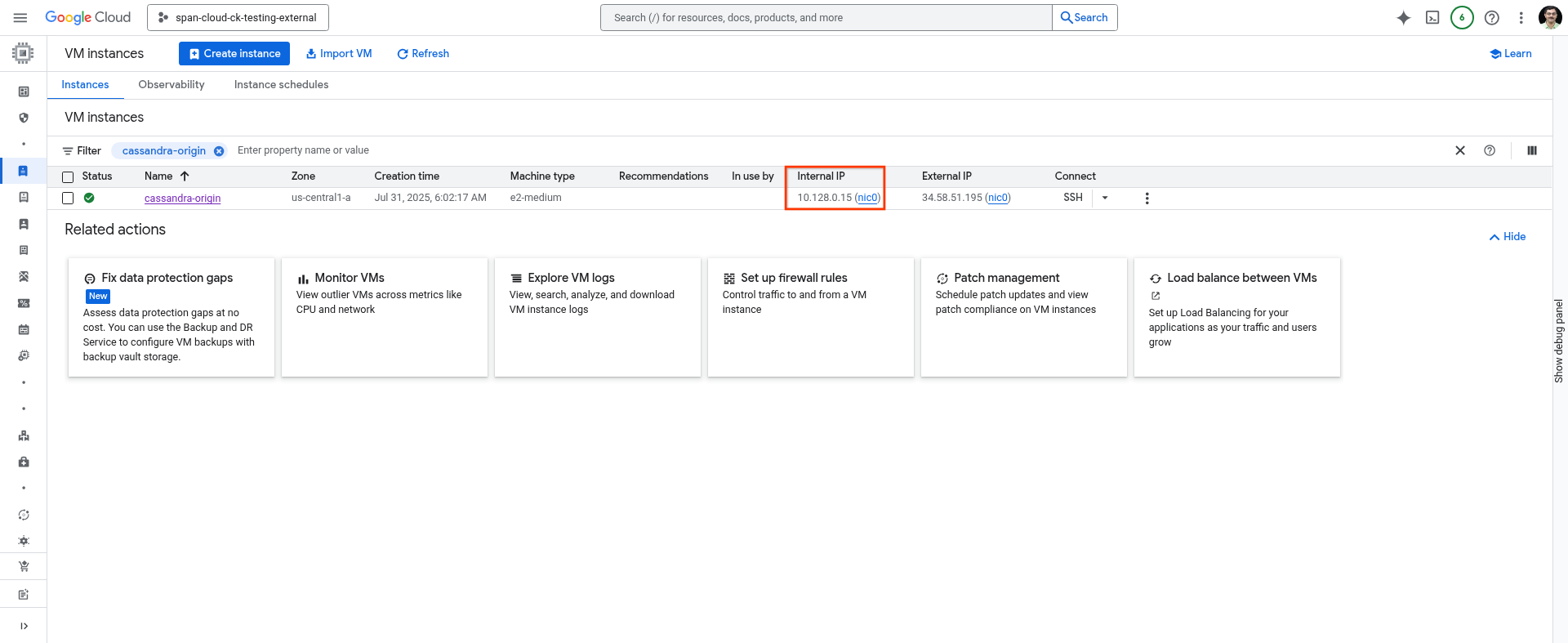
כדי להיכנס אל VM Instances מהדף Navigation menu, פועלים לפי ההוראות הבאות: 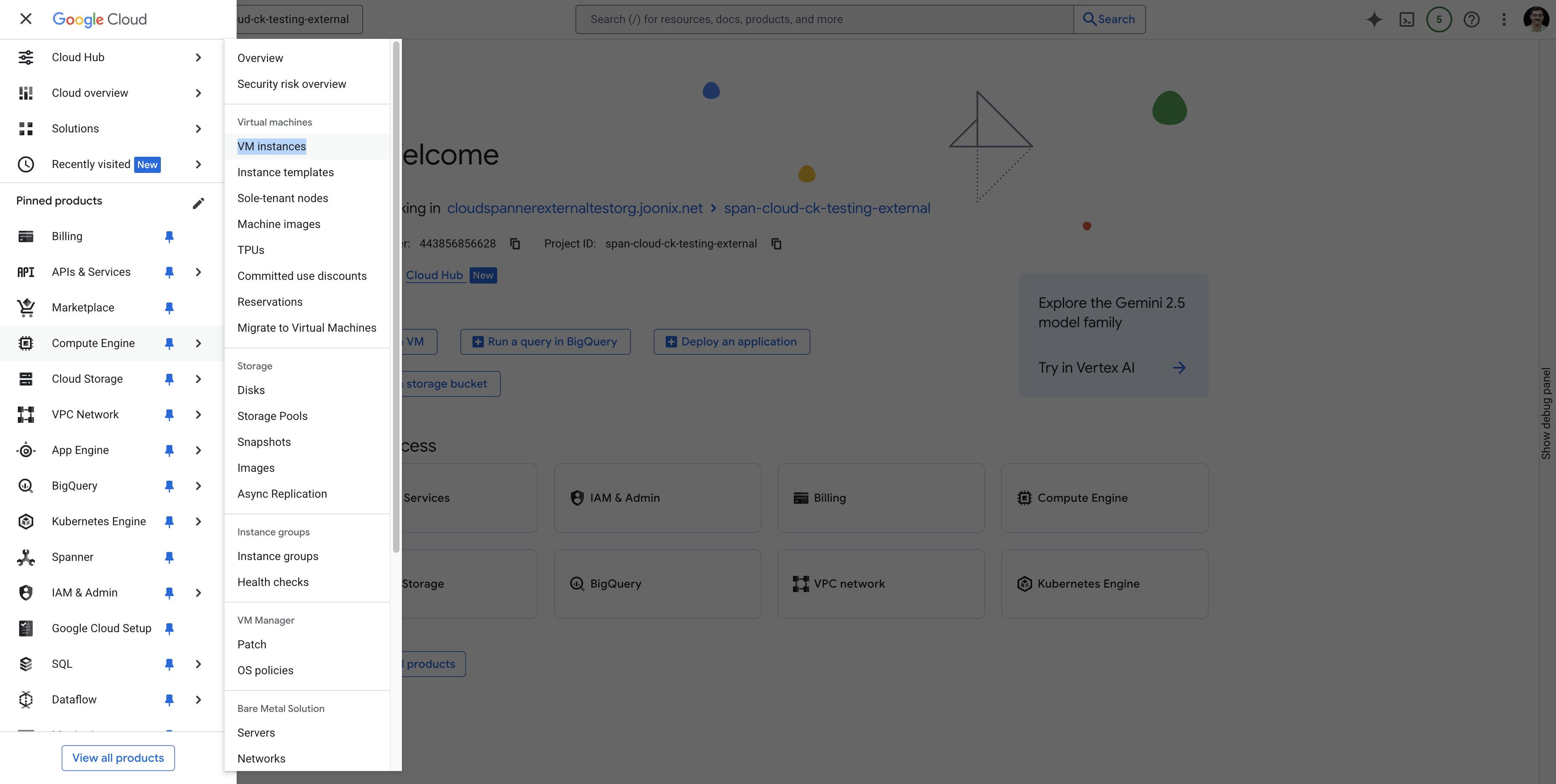 .
.
מחפשים את ה-VM cassandra-origin ומתחברים ל-VM באמצעות SSH כמו שמוצג:
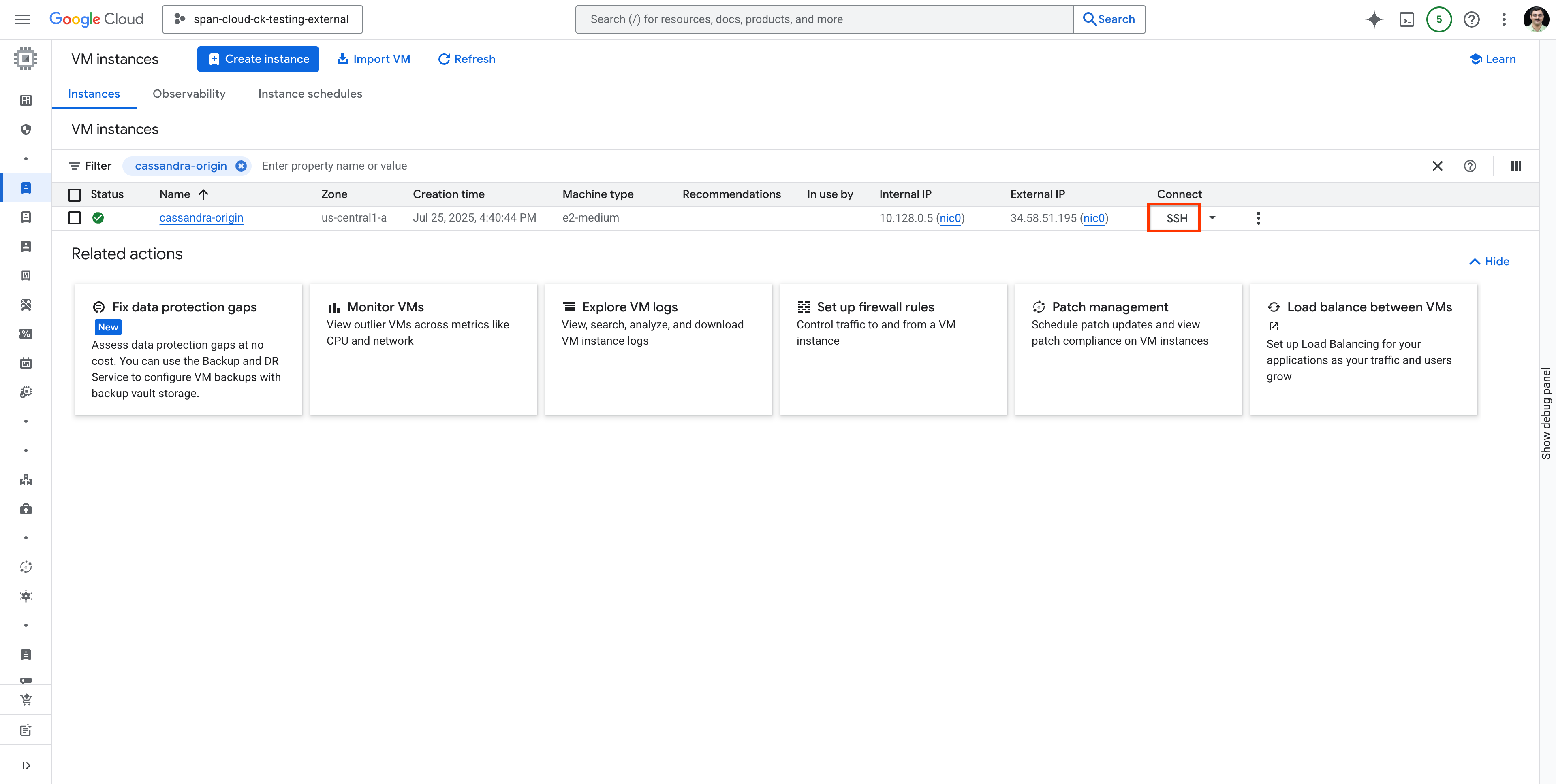 .
.
מריצים את הפקודות הבאות כדי להתקין את Cassandra במכונת ה-VM שיצרתם והתחברתם אליה באמצעות SSH.
התקנת Java (תלות ב-Cassandra)
sudo apt-get update
sudo apt-get install -y openjdk-11-jre-headless
הוספת מאגר Cassandra
echo "deb [signed-by=/etc/apt/keyrings/apache-cassandra.asc] https://debian.cassandra.apache.org 41x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
sudo curl -o /etc/apt/keyrings/apache-cassandra.asc https://downloads.apache.org/cassandra/KEYS
התקנת Cassandra
sudo apt-get update
sudo apt-get install -y cassandra
מגדירים את כתובת ההאזנה לשירות Cassandra.
כאן אנחנו משתמשים בכתובת ה-IP הפנימית של מכונת Cassandra הווירטואלית כדי להוסיף אבטחה.
שימו לב לכתובת ה-IP של המחשב המארח
אפשר להשתמש בפקודה הבאה ב-Cloud Shell או להעתיק אותה מהדף VM Instances במסוף Cloud.
gcloud compute instances describe cassandra-origin --format="get(networkInterfaces[0].networkIP)" --zone=us-central1-a
או
 .
.
עדכון הכתובת בקובץ התצורה
אפשר להשתמש בעורך לבחירתכם כדי לעדכן את קובץ התצורה של Cassandra
sudo vim /etc/cassandra/cassandra.yaml
משנים את rpc_address: לכתובת ה-IP של המכונה הווירטואלית, שומרים את הקובץ וסוגרים אותו.
הפעלת שירות Cassandra במכונה הווירטואלית
sudo systemctl enable cassandra
sudo systemctl stop cassandra
sudo systemctl start cassandra
sudo systemctl status cassandra
3. יצירת מרחב מפתחות וטבלה {create-keyspace-and-table}
נשתמש בדוגמה של טבלת 'משתמשים' וניצור מרחב מפתחות בשם 'ניתוח נתונים'.
export CQLSH_HOST=<IP of the VM added as rpc_address>
/usr/bin/cqlsh
בתוך cqlsh:
-- Create keyspace (adjust replication for production)
CREATE KEYSPACE analytics WITH replication = {'class':'SimpleStrategy', 'replication_factor':1};
-- Use the keyspace
USE analytics;
-- Create the users table
CREATE TABLE users (
id int PRIMARY KEY,
active boolean,
username text,
);
-- Insert 5 rows
INSERT INTO users (id, active, username) VALUES (1, true, 'd_knuth');
INSERT INTO users (id, active, username) VALUES (2, true, 'sanjay_ghemawat');
INSERT INTO users (id, active, username) VALUES (3, false, 'gracehopper');
INSERT INTO users (id, active, username) VALUES (4, true, 'brian_kernighan');
INSERT INTO users (id, active, username) VALUES (5, true, 'jeff_dean');
INSERT INTO users (id, active, username) VALUES (6, true, 'jaime_levy');
-- Select all users to verify the inserts.
SELECT * from users;
-- Exit cqlsh
EXIT;
משאירים את סשן ה-SSH פתוח או רושמים את כתובת ה-IP של המכונה הווירטואלית הזו (hostname -I).
הבא בתור
לאחר מכן, תגדירו מכונה ומסד נתונים של Cloud Spanner.
4. יצירת מופע Spanner (יעד)
ב-Spanner, instance הוא אשכול של משאבי מחשוב ואחסון שמארח מסד נתונים אחד או יותר של Spanner. כדי להשתמש ב-codelab הזה, תצטרכו לפחות מופע אחד לאירוח מסד נתונים של Spanner.
בדיקת גרסת gcloud SDK
לפני שיוצרים מופע, מוודאים ש-gcloud SDK ב-Google Cloud Shell עודכן לגרסה הנדרשת – כל גרסה שגדולה מ-gcloud SDK 531.0.0. כדי למצוא את גרסת gcloud SDK, מריצים את הפקודה הבאה.
$ gcloud version | grep Google
פלט לדוגמה:
Google Cloud SDK 489.0.0
אם הגרסה שבה אתם משתמשים קודמת לגרסה הנדרשת 531.0.0 (489.0.0 בדוגמה הקודמת), אתם צריכים לשדרג את Google Cloud SDK על ידי הפעלת הפקודה הבאה:
sudo apt-get update \
&& sudo apt-get --only-upgrade install google-cloud-cli-anthoscli google-cloud-cli-cloud-run-proxy kubectl google-cloud-cli-skaffold google-cloud-cli-cbt google-cloud-cli-docker-credential-gcr google-cloud-cli-spanner-migration-tool google-cloud-cli-cloud-build-local google-cloud-cli-pubsub-emulator google-cloud-cli-app-engine-python google-cloud-cli-kpt google-cloud-cli-bigtable-emulator google-cloud-cli-datastore-emulator google-cloud-cli-spanner-emulator google-cloud-cli-app-engine-go google-cloud-cli-app-engine-python-extras google-cloud-cli-config-connector google-cloud-cli-package-go-module google-cloud-cli-istioctl google-cloud-cli-anthos-auth google-cloud-cli-gke-gcloud-auth-plugin google-cloud-cli-app-engine-grpc google-cloud-cli-kubectl-oidc google-cloud-cli-terraform-tools google-cloud-cli-nomos google-cloud-cli-local-extract google-cloud-cli-firestore-emulator google-cloud-cli-harbourbridge google-cloud-cli-log-streaming google-cloud-cli-minikube google-cloud-cli-app-engine-java google-cloud-cli-enterprise-certificate-proxy google-cloud-cli
הפעלת Spanner API
ב-Cloud Shell, מוודאים שמזהה הפרויקט מוגדר. כדי למצוא את מזהה הפרויקט שמוגדר כרגע, משתמשים בפקודה הראשונה שבהמשך. אם התוצאה לא צפויה, הפקודה השנייה שבהמשך מגדירה את התוצאה הנכונה.
gcloud config get-value project
gcloud config set project [YOUR-DESIRED-PROJECT-ID]
מגדירים את אזור ברירת המחדל ל-us-central1. אתם יכולים לשנות את האזור הזה לאזור אחר שנתמך על ידי הגדרות אזוריות של Spanner.
gcloud config set compute/region us-central1
מפעילים את Spanner API:
gcloud services enable spanner.googleapis.com
יצירת מכונת Spanner
בקטע הזה, יוצרים מכונה וירטואלית לניסיון בחינם או מכונה וירטואלית שהוקצתה. במהלך ה-Codelab הזה, מזהה המופע של Spanner Cassandra Adapter שבו נעשה שימוש הוא cassandra-adapter-demo, שמוגדר כמשתנה SPANNER_INSTANCE_ID באמצעות שורת הפקודה export. אפשר גם לבחור שם משלכם למזהה המופע.
יצירת מכונה של Spanner לתקופת ניסיון בחינם
מכונה של Spanner לתקופת ניסיון בחינם של 90 יום זמינה לכל מי שיש לו חשבון Google והפעיל חיוב ב-Cloud בפרויקט שלו. לא נחייב אתכם, אלא אם תבחרו לשדרג את המופע של תקופת הניסיון בחינם למופע בתשלום. המתאם של Spanner Cassandra נתמך במכונה של תקופת הניסיון בחינם. אם אתם עומדים בדרישות, אתם יכולים ליצור מכונה במסגרת תקופת ניסיון בחינם. לשם כך, פותחים את Cloud Shell ומריצים את הפקודה הבאה:
export SPANNER_INSTANCE_ID=cassandra-adapter-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
פלט הפקודה:
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Creating instance...done.
5. העברת סכימה ומודל נתונים של Cassandra אל Spanner
השלב הראשוני והחשוב במעבר מנתונים ממסד נתונים של Cassandra ל-Spanner הוא שינוי הסכימה הקיימת של Cassandra כך שתתאים לדרישות המבניות ולדרישות של סוגי הנתונים ב-Spanner.
כדי לייעל את תהליך ההעברה המורכב הזה של הסכימה, אפשר להשתמש באחד משני הכלים החשובים של קוד פתוח ש-Spanner מספק:
- כלי ההעברה של Spanner: הכלי הזה עוזר להעביר סכימה על ידי התחברות למסד נתונים קיים של Cassandra והעברת הסכימה ל-Spanner. הכלי הזה זמין כחלק מ-
gcloud cli. - Spanner Cassandra Schema Tool: הכלי הזה עוזר להמיר DDL שיוצא מ-Cassandra ל-Spanner. אפשר להשתמש בכל אחד משני הכלים האלה ב-Codelab. ב-codelab הזה נשתמש בכלי להעברת נתונים ל-Spanner כדי להעביר את הסכימה.
כלי ההעברה של Spanner
Spanner Migration Tool עוזר להעביר סכימה ממקורות נתונים שונים כמו MySQL, Postgres, Cassandra וכו'.
בסדנת הקוד הזו נשתמש בממשק שורת הפקודה של הכלי הזה, אבל מומלץ מאוד לבדוק את הגרסה של הכלי שמבוססת על ממשק משתמש ולהשתמש בה. הגרסה הזו גם עוזרת לבצע שינויים בסכימת Spanner לפני שהיא מוחלת.
שימו לב: אם מריצים את spanner-migration-tool ב-Cloud Shell, יכול להיות שלא תהיה לו גישה לכתובת ה-IP הפנימית של מכונת Cassandra הווירטואלית. לכן, מומלץ להריץ את הפקודה הזו במכונת ה-VM שבה התקנתם את Cassandra.
מריצים את הפקודה הבאה ב-VM שבה התקנתם את Cassandra.
התקנת כלי ההעברה של Spanner
sudo apt-get update
sudo apt-get install --upgrade google-cloud-sdk-spanner-migration-tool
אם נתקלים בבעיות בהתקנה, אפשר לעיין installing-spanner-migration-tool לקבלת שלבים מפורטים.
רענון פרטי הכניסה ל-Gcloud
gcloud auth login
gcloud auth application-default login
העברת סכימה
export CASSANDRA_HOST=`<ip address of the VM used as rpc_address above>`
export PROJECT=`<PROJECT_ID>`
gcloud alpha spanner migrate schema \
--source=cassandra \
--source-profile="host=${CASSANDRA_HOST},user=cassandra,password=cassandra,port=9042,keyspace=analytics,datacenter=datacenter1" \
--target-profile="project=${PROJECT},instance=cassandra-adapter-demo,dbName=analytics" \
--project=${PROJECT}
אימות של Spanner DDL
gcloud spanner databases ddl describe analytics --instance=cassandra-adapter-demo
בסיום העברת הסכימה, הפלט של הפקודה הזו צריך להיות:
CREATE TABLE users (
active BOOL OPTIONS (
cassandra_type = 'boolean'
),
id INT64 NOT NULL OPTIONS (
cassandra_type = 'int'
),
username STRING(MAX) OPTIONS (
cassandra_type = 'text'
),
) PRIMARY KEY(id);
(אופציונלי) צפייה ב-DDL שהומר
אפשר לראות את ה-DDL שהומר ולהחיל אותו מחדש ב-Spanner (אם צריך לבצע שינויים נוספים)
cat `ls -t cassandra_*schema.ddl.txt | head -n 1`
הפלט של הפקודה הזו יהיה
CREATE TABLE `users` (
`active` BOOL OPTIONS (cassandra_type = 'boolean'),
`id` INT64 NOT NULL OPTIONS (cassandra_type = 'int'),
`username` STRING(MAX) OPTIONS (cassandra_type = 'text'),
) PRIMARY KEY (`id`)
(אופציונלי) צפייה בדוח ההמרות
cat `ls -t cassandra_*report.txt | head -n 1`
בדוח ההמרות מודגשות הבעיות שכדאי לזכור. לדוגמה, אם יש חוסר התאמה ברמת הדיוק המקסימלית של עמודה בין המקור לבין Spanner, היא תודגש כאן.
6. ייצוא נתונים היסטוריים בכמות גדולה
כדי לבצע את ההעברה בכמות גדולה, תצטרכו:
- הקצאת משאבים או שימוש חוזר בקטגוריה קיימת ב-GCS.
- העלאת קובץ התצורה של Cassandra Driver לקטגוריית האחסון
- מפעילים העברה בכמות גדולה.
אפשר להפעיל את ההעברה בכמות גדולה מ-Cloud Shell או מהמכונה הווירטואלית החדשה שהוקצתה, אבל מומלץ להשתמש במכונה הווירטואלית לצורך ה-Codelab הזה, כי חלק מהשלבים, כמו יצירת קובץ תצורה, ישמרו קבצים באחסון המקומי.
הקצאת מאגר GCS.
בסוף השלב הזה, אמור להיות לכם מאגר GCS שהוקצה לו נפח אחסון, והנתיב שלו מיוצא במשתנה בשם CASSANDRA_BUCKET_NAME. אם רוצים לעשות שימוש חוזר בקטגוריה קיימת, אפשר פשוט לייצא את הנתיב.
if [ -z ${CASSANDRA_BUCKET_NAME} ]; then
export CASSANDRA_BUCKET_NAME="gs://cassandra-demo-$(date +%Y-%m-%d-%H-%M-%S)-$(head /dev/urandom | tr -dc a-z | head -c 20)"
gcloud storage buckets create "${CASSANDRA_BUCKET_NAME}"
else
echo "using existing bucket ${CASSANDRA_BUCKET_NAME}"
fi
יצירה והעלאה של קובץ תצורה של מנהל התקן
כאן אנחנו מעלים קובץ תצורה בסיסי מאוד של מנהל התקן של Cassandra. פרטים נוספים על פורמט הקובץ זמינים כאן.
# Configuration for the Cassandra instance and GCS bucket
INSTANCE_NAME="cassandra-origin"
ZONE="us-central1-a"
CASSANDRA_PORT="9042"
# Retrieve the internal IP address of the Cassandra instance
CASSANDRA_IP=$(gcloud compute instances describe "${INSTANCE_NAME}" \
--format="get(networkInterfaces[0].networkIP)" \
--zone="${ZONE}")
# Check if the IP was successfully retrieved
if [[ -z "${CASSANDRA_IP}" ]]; then
echo "Error: Could not retrieve Cassandra instance IP."
exit 1
fi
# Define the full contact point
CONTACT_POINT="${CASSANDRA_IP}:${CASSANDRA_PORT}"
# Create a temporary file with the specified content
TMP_FILE=$(mktemp)
cat <<EOF > "${TMP_FILE}"
# Reference configuration for the DataStax Java driver for Apache Cassandra®.
# This file is in HOCON format, see https://github.com/typesafehub/config/blob/master/HOCON.md.
datastax-java-driver {
basic.contact-points = ["${CONTACT_POINT}"]
basic.session-keyspace = analytics
basic.load-balancing-policy.local-datacenter = datacenter1
advanced.auth-provider {
class = PlainTextAuthProvider
username = cassandra
password = cassandra
}
}
EOF
# Upload the temporary file to the specified GCS bucket
if gsutil cp "${TMP_FILE}" "${CASSANDRA_BUCKET_NAME}/cassandra.conf"; then
echo "Successfully uploaded ${TMP_FILE} to ${CASSANDRA_BUCKET_NAME}/cassandra.conf"
# Concatenate (cat) the uploaded file from GCS
echo "Displaying the content of the uploaded file:"
gsutil cat "${CASSANDRA_BUCKET_NAME}/cassandra.conf"
else
echo "Error: Failed to upload file to GCS."
fi
# Clean up the temporary file
rm "${TMP_FILE}"
הפעלת העברה בכמות גדולה
זוהי פקודה לדוגמה להפעלת העברה בכמות גדולה של הנתונים ל-Spanner. במקרי שימוש בפועל בסביבת ייצור, תצטרכו לשנות את סוג המכונה ואת מספר המכונות בהתאם לקנה המידה ולתפוקה הרצויים. רשימה מלאה של האפשרויות זמינה בכתובת README_Sourcedb_to_Spanner.md#cassandra-to-spanner-bulk-migration.
gcloud dataflow flex-template run "sourcedb-to-spanner-flex-job" \
--project "`gcloud config get-value project`" \
--region "us-central1" \
--max-workers "2" \
--num-workers "1" \
--worker-machine-type "e2-standard-8" \
--template-file-gcs-location "gs://dataflow-templates-us-central1/latest/flex/Sourcedb_to_Spanner_Flex" \
--additional-experiments="[\"disable_runner_v2\"]" \
--parameters "sourceDbDialect=CASSANDRA" \
--parameters "insertOnlyModeForSpannerMutations=true" \
--parameters "sourceConfigURL=$CASSANDRA_BUCKET_NAME/cassandra.conf" \
--parameters "instanceId=cassandra-adapter-demo" \
--parameters "databaseId=analytics" \
--parameters "projectId=`gcloud config get-value project`" \
--parameters "outputDirectory=$CASSANDRA_BUCKET_NAME/output" \
--parameters "batchSizeForSpannerMutations=1"
יוצג פלט כמו בדוגמה הבאה. שימו לב ל-id שנוצר והשתמשו בו כדי לשלוח שאילתה על הסטטוס של עבודת Dataflow.
job: createTime: '2025-08-08T09:41:09.820267Z' currentStateTime: '1970-01-01T00:00:00Z' id: 2025-08-08_02_41_09-17637291823018196600 location: us-central1 name: sourcedb-to-spanner-flex-job projectId: span-cloud-ck-testing-external startTime: '2025-08-08T09:41:09.820267Z'
מריצים את הפקודה שלמטה כדי לבדוק את סטטוס העבודה ומחכים עד שהסטטוס ישתנה ל-JOB_STATE_DONE.
gcloud dataflow jobs describe --region=us-central1 <dataflow job id> | grep "currentState:"
בהתחלה, העבודה תהיה במצב של המתנה בתור, כמו
currentState: JOB_STATE_QUEUED
בזמן שהעבודה נמצאת בתור או פועלת, מומלץ מאוד לעיין בדף Dataflow/Jobs בממשק המשתמש של מסוף Cloud כדי לעקוב אחרי העבודה.
אחרי שהפעולה תסתיים, סטטוס העבודה ישתנה ל:
currentState: JOB_STATE_DONE
7. הפניית האפליקציה אל Spanner (מעבר)
אחרי שמאמתים בקפידה את הדיוק והתקינות של הנתונים אחרי שלב המיגרציה, השלב החשוב הוא להעביר את המיקוד התפעולי של האפליקציה ממערכת Cassandra מדור קודם למסד הנתונים החדש של Spanner שאוכלס בנתונים. תקופת המעבר הקריטית הזו נקראת בדרך כלל מעבר חד למערכת אחרת (cutover).
שלב המעבר החד למערכת אחרת (cutover) מסמן את הרגע שבו תעבורת הנתונים של האפליקציה בזמן אמת מנותבת מחדש מאשכול Cassandra המקורי ומחוברת ישירות לתשתית Spanner החזקה והניתנת להרחבה. המעבר הזה מדגים כמה קל לאפליקציות להשתמש ביכולות של Spanner, במיוחד כשמשתמשים בממשק Spanner Cassandra.
בעזרת ממשק Spanner Cassandra, תהליך המעבר פשוט יותר. התהליך כולל בעיקר הגדרה של אפליקציות הלקוח כך שישתמשו בלקוח המקורי של Spanner Cassandra לכל האינטראקציות עם הנתונים. במקום לתקשר עם מסד הנתונים של Cassandra (המקור), האפליקציות יתחילו לקרוא ולכתוב נתונים ישירות ב-Spanner (היעד). השינוי המהותי הזה בקישוריות מושג בדרך כלל באמצעות SpannerCqlSessionBuilder, רכיב מרכזי בספריית הלקוח של Spanner Cassandra, שמסייע ליצור חיבורים למופע Spanner. הפעולה הזו למעשה מעבירה את כל תעבורת הנתונים של האפליקציה ל-Spanner.
באפליקציות Java שכבר נעשה בהן שימוש בספרייה cassandra-java-driver, שילוב של Spanner Cassandra Java Client דורש רק שינויים קלים בהגדרה הראשונית של CqlSession.
קבלת התלות google-cloud-spanner-cassandra
כדי להתחיל להשתמש ב-Spanner Cassandra Client, קודם צריך לשלב את התלות שלו בפרויקט. הארטיפקטים google-cloud-spanner-cassandra מתפרסמים ב-Maven Central, תחת מזהה הקבוצה com.google.cloud. מוסיפים את התלות החדשה הבאה בקטע <dependencies> הקיים בפרויקט Java. הנה דוגמה פשוטה לאופן שבו אפשר לכלול את התלות google-cloud-spanner-cassandra:
<!-- native Spanner Cassandra Client -->
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner-cassandra</artifactId>
<version>0.2.0</version>
</dependency>
</dependencies>
שינוי הגדרות החיבור כדי להתחבר ל-Spanner
אחרי שמוסיפים את התלות הנדרשת, השלב הבא הוא לשנות את הגדרות החיבור כדי להתחבר למסד נתונים של Spanner.
אפליקציה טיפוסית שמתקשרת עם אשכול Cassandra משתמשת לעיתים קרובות בקוד שדומה לקוד הבא כדי ליצור חיבור:
CqlSession session = CqlSession.builder()
.addContactPoint(new InetSocketAddress("127.0.0.1", 9042))
.withLocalDatacenter("datacenter1")
.withAuthCredentials("username", "password")
.build();
כדי להפנות את החיבור הזה ל-Spanner, צריך לשנות את CqlSession לוגיקת היצירה. במקום להשתמש ישירות בפונקציה CqlSessionBuilder הרגילה מ-cassandra-java-driver, תשתמשו בפונקציה SpannerCqlSession.builder() שסופקה על ידי Spanner Cassandra Client. הנה דוגמה להמחשה של שינוי קוד החיבור:
String databaseUri = "projects/<your-gcp-project>/instances/<your-spanner-instance>/databases/<your-spanner-database>";
CqlSession session = SpannerCqlSession.builder()
.setDatabaseUri(databaseUri)
.addContactPoint(new InetSocketAddress("localhost", 9042))
.withLocalDatacenter("datacenter1")
.build();
אם תיצרו מופע של CqlSession באמצעות SpannerCqlSession.builder() ותספקו את databaseUri הנכון, האפליקציה שלכם תיצור עכשיו חיבור למסד הנתונים של Spanner שמוגדר כיעד דרך Spanner Cassandra Client. השינוי המהותי הזה מבטיח שכל פעולות הקריאה והכתיבה הבאות שהאפליקציה מבצעת יופנו אל Spanner ויטופלו על ידו, וכך יושלם המעבר החד למערכת אחרת (cutover) הראשוני. בשלב הזה, האפליקציה אמורה להמשיך לפעול כצפוי, ועכשיו היא מבוססת על יכולת ההתאמה והאמינות של Spanner.
הפרטים הטכניים: איך פועל לקוח Spanner Cassandra
לקוח Spanner Cassandra פועל כ-TCP proxy מקומי, ומיירט את הבייטים של פרוטוקול Cassandra הגולמי שנשלחים על ידי מנהל התקן או כלי לקוח. לאחר מכן, הוא עוטף את הבייטים האלה יחד עם המטא-נתונים הדרושים בהודעות gRPC לצורך תקשורת עם Spanner. התשובות מ-Spanner מתורגמות בחזרה לפורמט של Cassandra ונשלחות בחזרה לדרייבר או לכלי המקוריים.
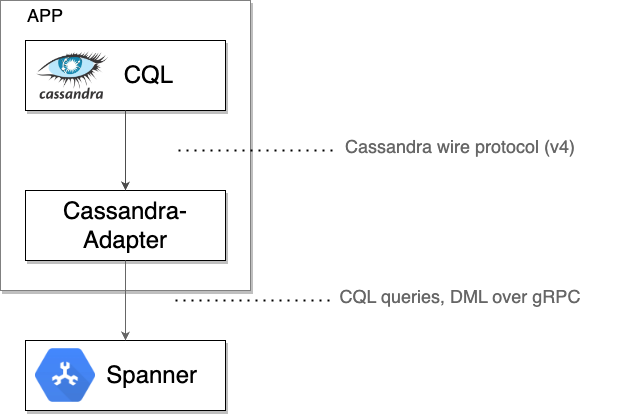
אחרי שמוודאים ש-Spanner משרת את כל התנועה בצורה תקינה, אפשר בסופו של דבר:
- להוציא משימוש את אשכול Cassandra המקורי.
8. ניקוי (אופציונלי)
כדי לנקות, פשוט נכנסים אל הקטע Spanner במסוף Cloud ומוחקים את מופע cassandra-adapter-demo שיצרנו ב-codelab.
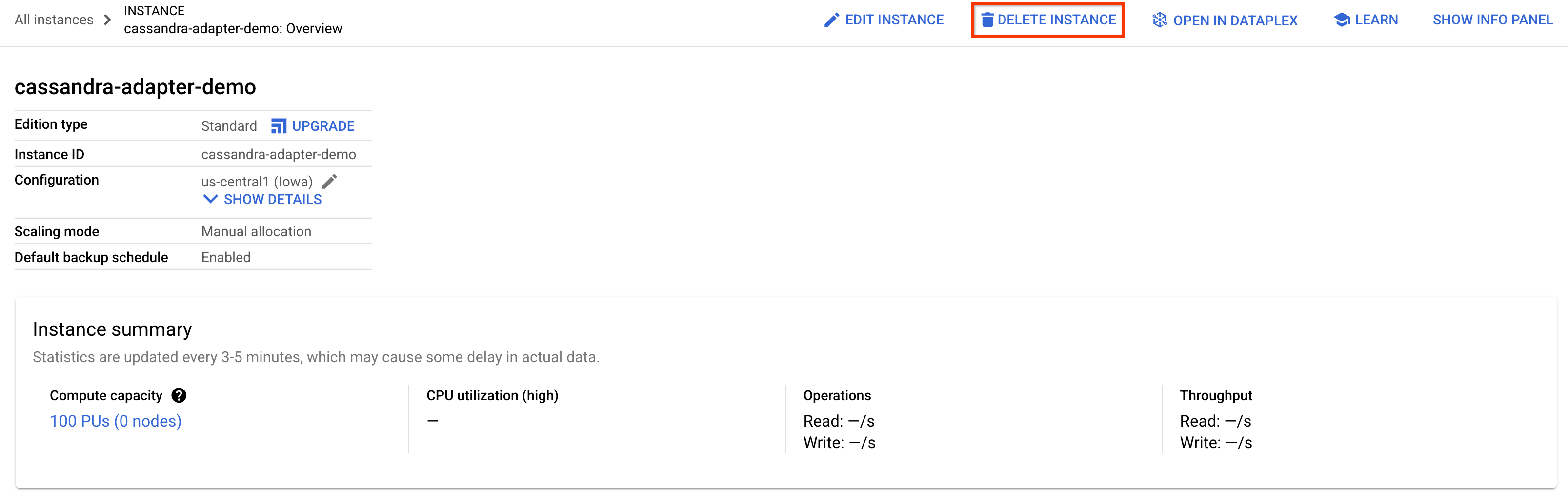
מחיקת מסד נתונים של Cassandra (אם הוא מותקן באופן מקומי או נשמר)
אם התקנתם את Cassandra מחוץ למכונה וירטואלית ב-Compute Engine שנוצרה כאן, צריך לפעול לפי השלבים המתאימים כדי להסיר את הנתונים או להסיר את ההתקנה של Cassandra.