
1. परिचय
Spanner, पूरी तरह से मैनेज की जाने वाली, हॉरिज़ॉन्टली स्केल की जा सकने वाली, और दुनिया भर में उपलब्ध डेटाबेस सेवा है. यह रिलेशनल और नॉन-रिलेशनल, दोनों तरह के वर्कलोड के लिए बेहतरीन है.
Spanner के Cassandra इंटरफ़ेस की मदद से, Spanner के पूरी तरह से मैनेज किए गए, ज़रूरत के हिसाब से स्केल किए जा सकने वाले, और हमेशा उपलब्ध रहने वाले इन्फ़्रास्ट्रक्चर का फ़ायदा लिया जा सकता है. इसके लिए, Cassandra के जाने-पहचाने टूल और सिंटैक्स का इस्तेमाल किया जाता है.
आपको क्या सीखने को मिलेगा
- Spanner इंस्टेंस और डेटाबेस सेट अप करने का तरीका.
- Cassandra के स्कीमा और डेटा मॉडल को बदलने का तरीका.
- Cassandra से Spanner में, अपने पुराने डेटा को एक साथ एक्सपोर्ट करने का तरीका.
- अपने ऐप्लिकेशन को Cassandra के बजाय Spanner पर कैसे पॉइंट करें.
आपको किन चीज़ों की ज़रूरत होगी
- Google Cloud प्रोजेक्ट, किसी बिलिंग खाते से कनेक्ट होना चाहिए.
- आपके पास ऐसी मशीन का ऐक्सेस होना चाहिए जिस पर
gcloudसीएलआई इंस्टॉल और कॉन्फ़िगर किया गया हो. इसके अलावा, Google Cloud Shell का इस्तेमाल भी किया जा सकता है. - कोई वेब ब्राउज़र, जैसे कि Chrome या Firefox.
2. सेटअप और ज़रूरी शर्तें
GCP प्रोजेक्ट बनाना
Google Cloud Console में साइन इन करें और नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. अगर आपके पास पहले से कोई Gmail या Google Workspace खाता नहीं है, तो आपको एक खाता बनाना होगा.

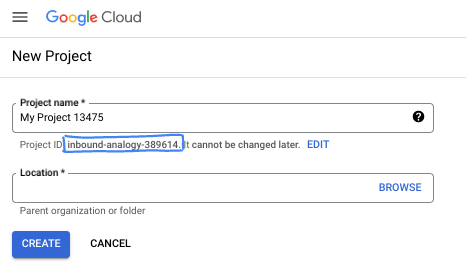
- प्रोजेक्ट का नाम, इस प्रोजेक्ट में हिस्सा लेने वाले लोगों के लिए डिसप्ले नेम होता है. यह एक वर्ण स्ट्रिंग है, जिसका इस्तेमाल Google API नहीं करते. इसे कभी भी अपडेट किया जा सकता है.
- प्रोजेक्ट आईडी, सभी Google Cloud प्रोजेक्ट के लिए यूनीक होता है. साथ ही, इसे बदला नहीं जा सकता. Cloud Console, यूनीक स्ट्रिंग को अपने-आप जनरेट करता है. आम तौर पर, आपको इससे कोई फ़र्क़ नहीं पड़ता कि यह क्या है. ज़्यादातर कोडलैब में, आपको अपने प्रोजेक्ट आईडी (आम तौर पर
PROJECT_IDके तौर पर पहचाना जाता है) का रेफ़रंस देना होगा. अगर आपको जनरेट किया गया आईडी पसंद नहीं है, तो कोई दूसरा रैंडम आईडी जनरेट किया जा सकता है. इसके अलावा, आपके पास अपना नाम आज़माने का विकल्प भी है. इससे आपको पता चलेगा कि वह नाम उपलब्ध है या नहीं. इस चरण के बाद, इसे बदला नहीं जा सकता. यह प्रोजेक्ट की अवधि तक बना रहता है. - आपकी जानकारी के लिए बता दें कि एक तीसरी वैल्यू भी होती है, जिसे प्रोजेक्ट नंबर कहते हैं. इसका इस्तेमाल कुछ एपीआई करते हैं. इन तीनों वैल्यू के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
बिलिंग सेट अप
इसके बाद, आपको बिलिंग मैनेज करने से जुड़ी उपयोगकर्ता गाइड को फ़ॉलो करना होगा. साथ ही, Cloud Console में बिलिंग चालू करनी होगी. Google Cloud के नए उपयोगकर्ताओं को, 300 डॉलर का क्रेडिट मिलता है. इसका इस्तेमाल वे मुफ़्त में आज़माने की अवधि के दौरान कर सकते हैं. अगर आपको इस ट्यूटोरियल के बाद बिलिंग से बचना है, तो कोडलैब के आखिर में "नौवां चरण: क्लीन अप करना" में दिए गए निर्देशों का पालन करके, Spanner इंस्टेंस को बंद करें.
Cloud Shell शुरू करना
Google Cloud को अपने लैपटॉप से रिमोटली ऐक्सेस किया जा सकता है. हालांकि, इस कोडलैब में Google Cloud Shell का इस्तेमाल किया जाएगा. यह क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है.
Google Cloud Console में, सबसे ऊपर दाएं कोने में मौजूद टूलबार पर, Cloud Shell आइकॉन पर क्लिक करें:

इसे चालू करने और एनवायरमेंट से कनेक्ट करने में सिर्फ़ कुछ सेकंड लगेंगे. यह प्रोसेस पूरी होने के बाद, आपको कुछ ऐसा दिखेगा:

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है. साथ ही, यह Google Cloud पर काम करता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस कोडलैब में मौजूद सभी टास्क, ब्राउज़र में किए जा सकते हैं. आपको कुछ भी इंस्टॉल करने की ज़रूरत नहीं है.
अगला
इसके बाद, आपको Cassandra क्लस्टर डिप्लॉय करना होगा.
3. Cassandra क्लस्टर (ओरिजन) डिप्लॉय करना
इस कोडलैब के लिए, हम Compute Engine पर सिंगल-नोड Cassandra क्लस्टर सेट अप करेंगे.
1. Cassandra के लिए GCE वीएम बनाना
इंस्टेंस बनाने के लिए, पहले से उपलब्ध कराए गए Cloud Shell से gcloud compute instances create कमांड का इस्तेमाल करें.
gcloud compute instances create cassandra-origin \
--machine-type=e2-medium \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=cassandra-migration \
--boot-disk-size=20GB \
--zone=us-central1-a
2. Cassandra इंस्टॉल करना
नीचे दिए गए निर्देशों का पालन करके, Navigation menu पेज से VM Instances पर जाएं:  .
.
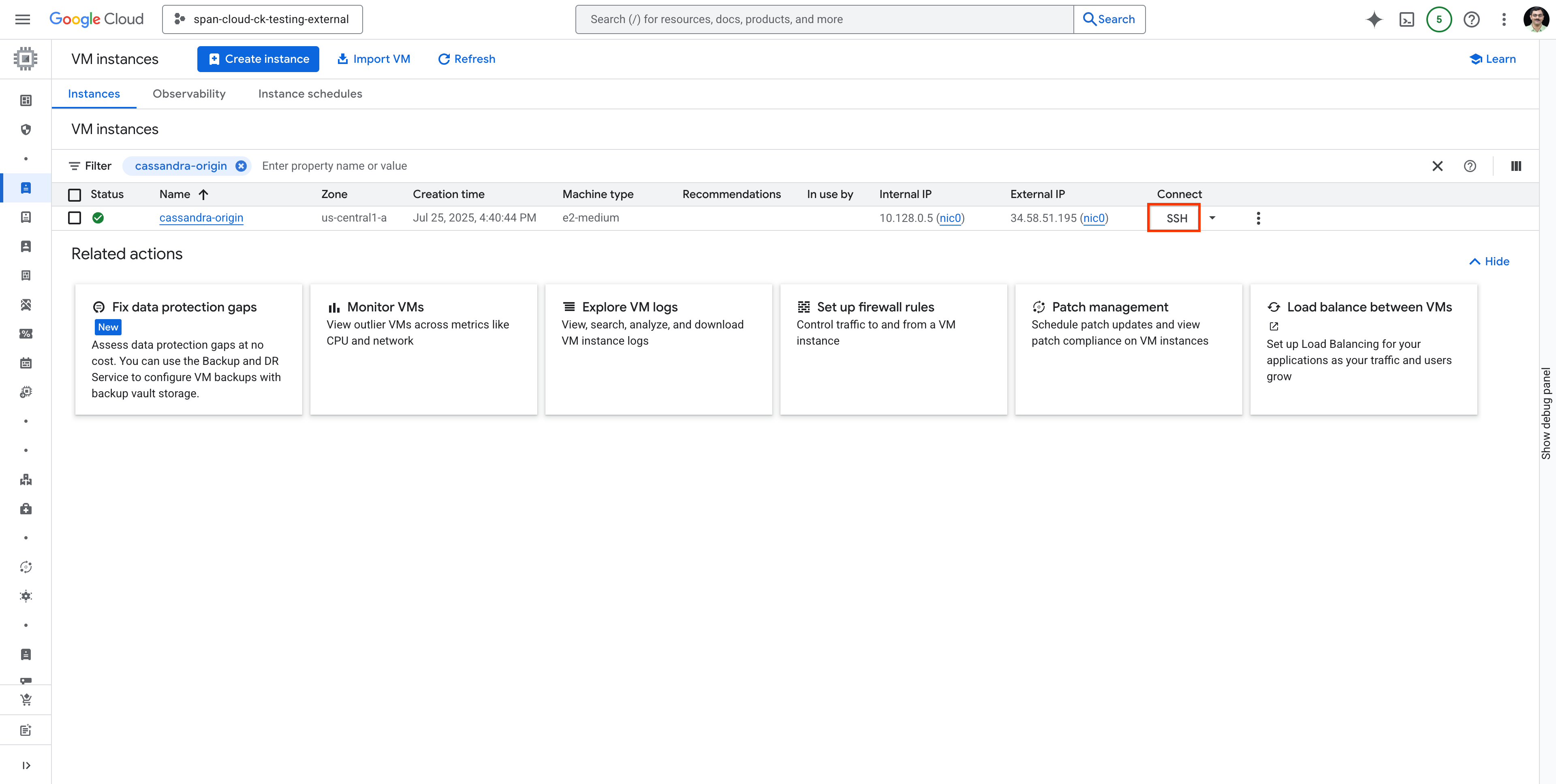
cassandra-origin वीएम खोजें और दिखाए गए तरीके से एसएसएच का इस्तेमाल करके वीएम से कनेक्ट करें:
 .
.
आपने जो वीएम बनाया है और जिसमें आपने एसएसएच किया है उस पर Cassandra को इंस्टॉल करने के लिए, यहां दी गई कमांड चलाएं.
Java इंस्टॉल करें (Cassandra की डिपेंडेंसी)
sudo apt-get update
sudo apt-get install -y openjdk-11-jre-headless
Cassandra रिपॉज़िटरी जोड़ना
echo "deb [signed-by=/etc/apt/keyrings/apache-cassandra.asc] https://debian.cassandra.apache.org 41x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
sudo curl -o /etc/apt/keyrings/apache-cassandra.asc https://downloads.apache.org/cassandra/KEYS
Cassandra इंस्टॉल करना
sudo apt-get update
sudo apt-get install -y cassandra
Cassandra सेवा के लिए, सुनने का पता सेट करें.
यहां हम ज़्यादा सुरक्षा के लिए, Cassandra वीएम के इंटरनल आईपी पते का इस्तेमाल करते हैं.
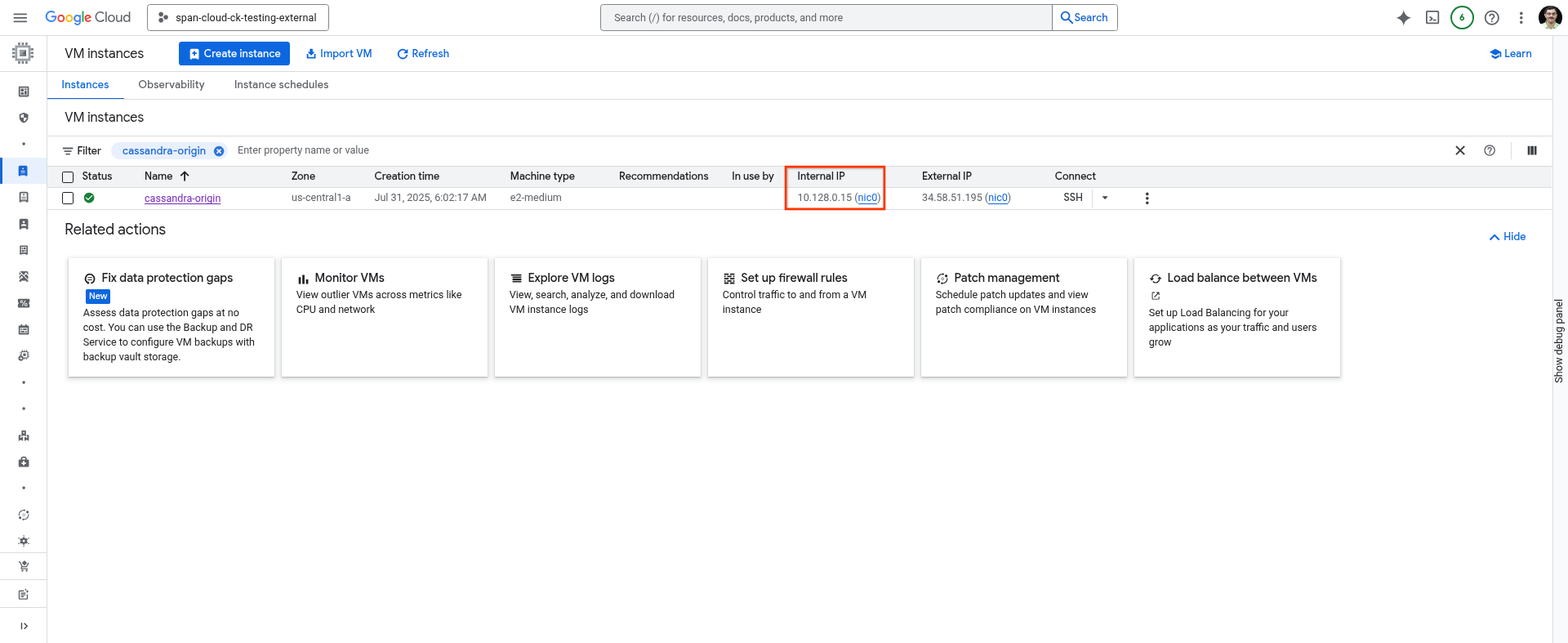
अपनी होस्ट मशीन का आईपी पता नोट करें
इसे पाने के लिए, Cloud Shell पर यहां दिया गया निर्देश इस्तेमाल करें या Cloud Console के VM Instances पेज पर जाएं.
gcloud compute instances describe cassandra-origin --format="get(networkInterfaces[0].networkIP)" --zone=us-central1-a
या
 .
.
कॉन्फ़िगरेशन फ़ाइल में पता अपडेट करें
Cassandra कॉन्फ़िगरेशन फ़ाइल को अपडेट करने के लिए, अपनी पसंद के एडिटर का इस्तेमाल किया जा सकता है
sudo vim /etc/cassandra/cassandra.yaml
rpc_address: को वीएम के आईपी पते से बदलें. इसके बाद, फ़ाइल को सेव करें और बंद करें.
वर्चुअल मशीन पर Cassandra सेवा चालू करना
sudo systemctl enable cassandra
sudo systemctl stop cassandra
sudo systemctl start cassandra
sudo systemctl status cassandra
3. कीस्पेस और टेबल बनाना {create-keyspace-and-table}
हम "users" टेबल का उदाहरण इस्तेमाल करेंगे और "analytics" नाम का कीस्पेस बनाएंगे.
export CQLSH_HOST=<IP of the VM added as rpc_address>
/usr/bin/cqlsh
cqlsh में:
-- Create keyspace (adjust replication for production)
CREATE KEYSPACE analytics WITH replication = {'class':'SimpleStrategy', 'replication_factor':1};
-- Use the keyspace
USE analytics;
-- Create the users table
CREATE TABLE users (
id int PRIMARY KEY,
active boolean,
username text,
);
-- Insert 5 rows
INSERT INTO users (id, active, username) VALUES (1, true, 'd_knuth');
INSERT INTO users (id, active, username) VALUES (2, true, 'sanjay_ghemawat');
INSERT INTO users (id, active, username) VALUES (3, false, 'gracehopper');
INSERT INTO users (id, active, username) VALUES (4, true, 'brian_kernighan');
INSERT INTO users (id, active, username) VALUES (5, true, 'jeff_dean');
INSERT INTO users (id, active, username) VALUES (6, true, 'jaime_levy');
-- Select all users to verify the inserts.
SELECT * from users;
-- Exit cqlsh
EXIT;
एसएसएच सेशन को खुला रखें या इस वीएम (hostname -I) का आईपी पता नोट करें.
अगला
इसके बाद, आपको Cloud Spanner इंस्टेंस और डेटाबेस सेट अप करना होगा.
4. Spanner इंस्टेंस (टारगेट) बनाना
Spanner में, इंस्टेंस, कंप्यूटिंग और स्टोरेज संसाधनों का एक ऐसा क्लस्टर होता है जो एक या उससे ज़्यादा Spanner डेटाबेस को होस्ट करता है. इस कोडलैब के लिए, Spanner डेटाबेस को होस्ट करने के लिए कम से कम एक इंस्टेंस की ज़रूरत होगी.
gcloud SDK टूल का वर्शन देखना
कोई इंस्टेंस बनाने से पहले, पक्का करें कि Google Cloud Shell में gcloud SDK को ज़रूरी वर्शन पर अपडेट कर दिया गया हो. यह gcloud SDK 531.0.0 से ज़्यादा होना चाहिए. नीचे दिए गए निर्देश का पालन करके, gcloud SDK का वर्शन देखा जा सकता है.
$ gcloud version | grep Google
यहां आउटपुट का एक उदाहरण दिया गया है:
Google Cloud SDK 489.0.0
अगर आपके पास 531.0.0 वर्शन (पिछले उदाहरण में 489.0.0) से पहले का वर्शन है, तो आपको Google Cloud SDK को अपग्रेड करना होगा. इसके लिए, यह कमांड चलाएं:
sudo apt-get update \
&& sudo apt-get --only-upgrade install google-cloud-cli-anthoscli google-cloud-cli-cloud-run-proxy kubectl google-cloud-cli-skaffold google-cloud-cli-cbt google-cloud-cli-docker-credential-gcr google-cloud-cli-spanner-migration-tool google-cloud-cli-cloud-build-local google-cloud-cli-pubsub-emulator google-cloud-cli-app-engine-python google-cloud-cli-kpt google-cloud-cli-bigtable-emulator google-cloud-cli-datastore-emulator google-cloud-cli-spanner-emulator google-cloud-cli-app-engine-go google-cloud-cli-app-engine-python-extras google-cloud-cli-config-connector google-cloud-cli-package-go-module google-cloud-cli-istioctl google-cloud-cli-anthos-auth google-cloud-cli-gke-gcloud-auth-plugin google-cloud-cli-app-engine-grpc google-cloud-cli-kubectl-oidc google-cloud-cli-terraform-tools google-cloud-cli-nomos google-cloud-cli-local-extract google-cloud-cli-firestore-emulator google-cloud-cli-harbourbridge google-cloud-cli-log-streaming google-cloud-cli-minikube google-cloud-cli-app-engine-java google-cloud-cli-enterprise-certificate-proxy google-cloud-cli
Spanner API को चालू करना
Cloud Shell में, पक्का करें कि आपका प्रोजेक्ट आईडी सेट अप हो. फ़िलहाल कॉन्फ़िगर किए गए प्रोजेक्ट आईडी को ढूंढने के लिए, यहां दिए गए पहले निर्देश का इस्तेमाल करें. अगर नतीजा उम्मीद के मुताबिक नहीं है, तो यहां दिया गया दूसरा निर्देश सही नतीजा सेट करता है.
gcloud config get-value project
gcloud config set project [YOUR-DESIRED-PROJECT-ID]
अपनी डिफ़ॉल्ट जगह को us-central1 पर सेट करें. इसे Spanner के क्षेत्रीय कॉन्फ़िगरेशन के साथ काम करने वाले किसी दूसरे क्षेत्र में बदला जा सकता है.
gcloud config set compute/region us-central1
Spanner API चालू करें:
gcloud services enable spanner.googleapis.com
Spanner इंस्टेंस बनाना
इस सेक्शन में, आपको मुफ़्त में आज़माने के लिए इंस्टेंस या प्रोविज़न किया गया इंस्टेंस बनाना होगा. इस कोडलैब में, Spanner Cassandra Adapter के जिस इंस्टेंस आईडी का इस्तेमाल किया गया है वह cassandra-adapter-demo है. इसे export कमांड लाइन का इस्तेमाल करके, SPANNER_INSTANCE_ID वैरिएबल के तौर पर सेट किया गया है. आपके पास इंस्टेंस आईडी का नाम चुनने का विकल्प होता है.
Spanner का मुफ़्त में आज़माए जाने वाला इंस्टेंस बनाना
Spanner को 90 दिनों तक मुफ़्त में आज़माने की सुविधा उन सभी लोगों के लिए उपलब्ध है जिनके पास Google खाता है और जिनके प्रोजेक्ट में Cloud Billing की सुविधा चालू है. जब तक मुफ़्त में आज़माने की सुविधा वाले इंस्टेंस को पैसे चुकाकर इस्तेमाल किए जाने वाले इंस्टेंस में अपग्रेड नहीं किया जाता, तब तक आपसे कोई शुल्क नहीं लिया जाता. Spanner Cassandra Adapter, मुफ़्त में आज़माने के लिए उपलब्ध इंस्टेंस में काम करता है. ज़रूरी शर्तें पूरी करने पर, Cloud Shell खोलकर और यह निर्देश चलाकर, बिना किसी शुल्क के आज़माने की सुविधा वाला इंस्टेंस बनाएं:
export SPANNER_INSTANCE_ID=cassandra-adapter-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
कमांड का आउटपुट:
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Creating instance...done.
5. Cassandra के स्कीमा और डेटा मॉडल को Spanner में माइग्रेट करना
Cassandra डेटाबेस से Spanner में डेटा ट्रांसफ़र करने के शुरुआती और अहम चरण में, मौजूदा Cassandra स्कीमा को Spanner की स्ट्रक्चरल और डेटा टाइप की ज़रूरी शर्तों के मुताबिक बदलना होता है.
स्कीमा माइग्रेशन की इस मुश्किल प्रोसेस को आसान बनाने के लिए, Spanner की ओर से उपलब्ध कराए गए दो ओपन सोर्स टूल में से किसी एक का इस्तेमाल करें:
- Spanner Migration Tool: यह टूल, मौजूदा Cassandra डेटाबेस से कनेक्ट करके स्कीमा को Spanner में माइग्रेट करने में मदद करता है. यह टूल,
gcloud cliके साथ उपलब्ध है. - Spanner Cassandra Schema Tool: यह टूल, Cassandra से एक्सपोर्ट किए गए DDL को Spanner में बदलने में आपकी मदद करता है. कोडलैब के लिए, इनमें से किसी भी टूल का इस्तेमाल किया जा सकता है. इस कोडलैब में, हम स्कीमा को माइग्रेट करने के लिए Spanner Migration Tool का इस्तेमाल करेंगे.
Spanner माइग्रेशन टूल
Spanner Migration Tool की मदद से, MySQL, Postgres, Cassandra वगैरह जैसे अलग-अलग डेटा सोर्स से स्कीमा माइग्रेट किया जा सकता है.
इस कोडलैब के लिए, हम इस टूल के सीएलआई का इस्तेमाल करेंगे. हालांकि, हमारा सुझाव है कि आप इस टूल के यूज़र इंटरफ़ेस (यूआई) वाले वर्शन को एक्सप्लोर करें और उसका इस्तेमाल करें. इससे आपको Spanner स्कीमा में बदलाव करने में भी मदद मिलती है.
ध्यान दें कि अगर spanner-migration-tool को Cloud Shell पर चलाया जाता है, तो हो सकता है कि इसके पास आपकी Cassandra VM के इंटरनल आईपी पते का ऐक्सेस न हो. इसलिए, हमारा सुझाव है कि आप इसे उसी वीएम पर चलाएं जहां आपने Cassandra इंस्टॉल किया है.
Cassandra को जिस वर्चुअल मशीन (वीएम) पर इंस्टॉल किया गया है उस पर यह कमांड चलाएं.
Spanner Migration Tool इंस्टॉल करना
sudo apt-get update
sudo apt-get install --upgrade google-cloud-sdk-spanner-migration-tool
अगर आपको इंस्टॉल करने में कोई समस्या आ रही है, तो सिलसिलेवार निर्देशों के लिए installing-spanner-migration-tool पर जाएं.
Gcloud क्रेडेंशियल रीफ़्रेश करें
gcloud auth login
gcloud auth application-default login
स्कीमा माइग्रेट करना
export CASSANDRA_HOST=`<ip address of the VM used as rpc_address above>`
export PROJECT=`<PROJECT_ID>`
gcloud alpha spanner migrate schema \
--source=cassandra \
--source-profile="host=${CASSANDRA_HOST},user=cassandra,password=cassandra,port=9042,keyspace=analytics,datacenter=datacenter1" \
--target-profile="project=${PROJECT},instance=cassandra-adapter-demo,dbName=analytics" \
--project=${PROJECT}
Spanner DDL की पुष्टि करना
gcloud spanner databases ddl describe analytics --instance=cassandra-adapter-demo
स्कीमा माइग्रेशन के आखिर में, इस कमांड का आउटपुट यह होना चाहिए:
CREATE TABLE users (
active BOOL OPTIONS (
cassandra_type = 'boolean'
),
id INT64 NOT NULL OPTIONS (
cassandra_type = 'int'
),
username STRING(MAX) OPTIONS (
cassandra_type = 'text'
),
) PRIMARY KEY(id);
(ज़रूरी नहीं) बदले गए DDL को देखें
बदले गए DDL को देखा जा सकता है. साथ ही, अगर आपको कुछ और बदलाव करने हैं, तो इसे Spanner पर फिर से लागू किया जा सकता है
cat `ls -t cassandra_*schema.ddl.txt | head -n 1`
इस कमांड का आउटपुट यह होगा
CREATE TABLE `users` (
`active` BOOL OPTIONS (cassandra_type = 'boolean'),
`id` INT64 NOT NULL OPTIONS (cassandra_type = 'int'),
`username` STRING(MAX) OPTIONS (cassandra_type = 'text'),
) PRIMARY KEY (`id`)
(ज़रूरी नहीं) कन्वर्ज़न रिपोर्ट देखना
cat `ls -t cassandra_*report.txt | head -n 1`
कन्वर्ज़न रिपोर्ट में उन समस्याओं के बारे में बताया जाता है जिन पर आपको ध्यान देना चाहिए. उदाहरण के लिए, अगर सोर्स और Spanner के बीच किसी कॉलम की ज़्यादा से ज़्यादा सटीक वैल्यू में अंतर है, तो उसे यहां हाइलाइट किया जाएगा.
6. अपना पुराना डेटा बल्क में एक्सपोर्ट करना
एक साथ कई फ़ाइलें माइग्रेट करने के लिए, आपको यह करना होगा:
- कोई नया GCS बकेट बनाएं या किसी मौजूदा GCS बकेट का फिर से इस्तेमाल करें.
- Cassandra Driver की कॉन्फ़िगरेशन फ़ाइल को बकेट में अपलोड करें
- एक साथ कई खातों को माइग्रेट करने की सुविधा लॉन्च की गई.
एक साथ कई वर्चुअल मशीनें माइग्रेट करने की प्रोसेस को Cloud Shell या नई वर्चुअल मशीन से लॉन्च किया जा सकता है. हालांकि, हम इस कोडलैब के लिए वर्चुअल मशीन का इस्तेमाल करने का सुझाव देते हैं. ऐसा इसलिए, क्योंकि कॉन्फ़िगरेशन फ़ाइल बनाने जैसे कुछ चरणों में, फ़ाइलें लोकल स्टोरेज में सेव होती हैं.
GCS बकेट उपलब्ध कराएं.
इस चरण के आखिर में, आपको एक GCS बकेट उपलब्ध करानी होगी. साथ ही, उसके पाथ को CASSANDRA_BUCKET_NAME नाम के वैरिएबल में एक्सपोर्ट करना होगा. अगर आपको किसी मौजूदा बकेट का फिर से इस्तेमाल करना है, तो पाथ एक्सपोर्ट करके आगे बढ़ें.
if [ -z ${CASSANDRA_BUCKET_NAME} ]; then
export CASSANDRA_BUCKET_NAME="gs://cassandra-demo-$(date +%Y-%m-%d-%H-%M-%S)-$(head /dev/urandom | tr -dc a-z | head -c 20)"
gcloud storage buckets create "${CASSANDRA_BUCKET_NAME}"
else
echo "using existing bucket ${CASSANDRA_BUCKET_NAME}"
fi
ड्राइवर कॉन्फ़िगरेशन फ़ाइल बनाना और अपलोड करना
यहां हम Cassandra ड्राइवर की एक सामान्य कॉन्फ़िगरेशन फ़ाइल अपलोड करते हैं. फ़ाइल के पूरे फ़ॉर्मैट के लिए, कृपया यह देखें.
# Configuration for the Cassandra instance and GCS bucket
INSTANCE_NAME="cassandra-origin"
ZONE="us-central1-a"
CASSANDRA_PORT="9042"
# Retrieve the internal IP address of the Cassandra instance
CASSANDRA_IP=$(gcloud compute instances describe "${INSTANCE_NAME}" \
--format="get(networkInterfaces[0].networkIP)" \
--zone="${ZONE}")
# Check if the IP was successfully retrieved
if [[ -z "${CASSANDRA_IP}" ]]; then
echo "Error: Could not retrieve Cassandra instance IP."
exit 1
fi
# Define the full contact point
CONTACT_POINT="${CASSANDRA_IP}:${CASSANDRA_PORT}"
# Create a temporary file with the specified content
TMP_FILE=$(mktemp)
cat <<EOF > "${TMP_FILE}"
# Reference configuration for the DataStax Java driver for Apache Cassandra®.
# This file is in HOCON format, see https://github.com/typesafehub/config/blob/master/HOCON.md.
datastax-java-driver {
basic.contact-points = ["${CONTACT_POINT}"]
basic.session-keyspace = analytics
basic.load-balancing-policy.local-datacenter = datacenter1
advanced.auth-provider {
class = PlainTextAuthProvider
username = cassandra
password = cassandra
}
}
EOF
# Upload the temporary file to the specified GCS bucket
if gsutil cp "${TMP_FILE}" "${CASSANDRA_BUCKET_NAME}/cassandra.conf"; then
echo "Successfully uploaded ${TMP_FILE} to ${CASSANDRA_BUCKET_NAME}/cassandra.conf"
# Concatenate (cat) the uploaded file from GCS
echo "Displaying the content of the uploaded file:"
gsutil cat "${CASSANDRA_BUCKET_NAME}/cassandra.conf"
else
echo "Error: Failed to upload file to GCS."
fi
# Clean up the temporary file
rm "${TMP_FILE}"
एक साथ कई माइग्रेशन करना
यह आपके डेटा को Spanner में बल्क माइग्रेट करने के लिए, एक सैंपल कमांड है. असल प्रोडक्शन के इस्तेमाल के उदाहरणों के लिए, आपको अपनी ज़रूरत के हिसाब से मशीन टाइप और संख्या में बदलाव करना होगा. विकल्पों की पूरी सूची देखने के लिए, कृपया README_Sourcedb_to_Spanner.md#cassandra-to-spanner-bulk-migration पर जाएं.
gcloud dataflow flex-template run "sourcedb-to-spanner-flex-job" \
--project "`gcloud config get-value project`" \
--region "us-central1" \
--max-workers "2" \
--num-workers "1" \
--worker-machine-type "e2-standard-8" \
--template-file-gcs-location "gs://dataflow-templates-us-central1/latest/flex/Sourcedb_to_Spanner_Flex" \
--additional-experiments="[\"disable_runner_v2\"]" \
--parameters "sourceDbDialect=CASSANDRA" \
--parameters "insertOnlyModeForSpannerMutations=true" \
--parameters "sourceConfigURL=$CASSANDRA_BUCKET_NAME/cassandra.conf" \
--parameters "instanceId=cassandra-adapter-demo" \
--parameters "databaseId=analytics" \
--parameters "projectId=`gcloud config get-value project`" \
--parameters "outputDirectory=$CASSANDRA_BUCKET_NAME/output" \
--parameters "batchSizeForSpannerMutations=1"
इससे इस तरह का आउटपुट जनरेट होगा. जनरेट किए गए id को नोट करें और डेटाफ़्लो जॉब की स्थिति के बारे में क्वेरी करने के लिए इसका इस्तेमाल करें.
job: createTime: '2025-08-08T09:41:09.820267Z' currentStateTime: '1970-01-01T00:00:00Z' id: 2025-08-08_02_41_09-17637291823018196600 location: us-central1 name: sourcedb-to-spanner-flex-job projectId: span-cloud-ck-testing-external startTime: '2025-08-08T09:41:09.820267Z'
जॉब की स्थिति देखने के लिए, यहां दिया गया निर्देश चलाएं. इसके बाद, स्थिति के JOB_STATE_DONE में बदलने तक इंतज़ार करें.
gcloud dataflow jobs describe --region=us-central1 <dataflow job id> | grep "currentState:"
शुरुआत में, नौकरी को इस तरह की कतार में रखा जाएगा
currentState: JOB_STATE_QUEUED
जब तक यह काम पूरा नहीं हो जाता, तब तक हमारा सुझाव है कि आप Cloud Console के यूज़र इंटरफ़ेस (यूआई) में Dataflow/Jobs पेज पर जाकर, इस काम की स्थिति पर नज़र रखें.
ऐसा करने के बाद, काम की स्थिति बदलकर यह हो जाएगी:
currentState: JOB_STATE_DONE
7. अपने ऐप्लिकेशन को Spanner पर पॉइंट करना (कटओवर)
माइग्रेशन के बाद, आपके डेटा की सटीकता और इंटिग्रिटी की पुष्टि करने के बाद, सबसे अहम चरण यह है कि आपके ऐप्लिकेशन के ऑपरेशनल फ़ोकस को लेगसी Cassandra सिस्टम से नए Spanner डेटाबेस पर ट्रांसफ़र किया जाए. इस अहम ट्रांज़िशन पीरियड को आम तौर पर, "कटओवर" कहा जाता है.
कटओवर फ़ेज़ में, लाइव ऐप्लिकेशन ट्रैफ़िक को ओरिजनल Cassandra क्लस्टर से हटाकर, मज़बूत और बड़े पैमाने पर इस्तेमाल किए जा सकने वाले Spanner इन्फ़्रास्ट्रक्चर पर रीडायरेक्ट किया जाता है. इस ट्रांज़िशन से पता चलता है कि ऐप्लिकेशन, Spanner का इस्तेमाल कितनी आसानी से कर सकते हैं. खास तौर पर, Spanner Cassandra इंटरफ़ेस का इस्तेमाल करते समय.
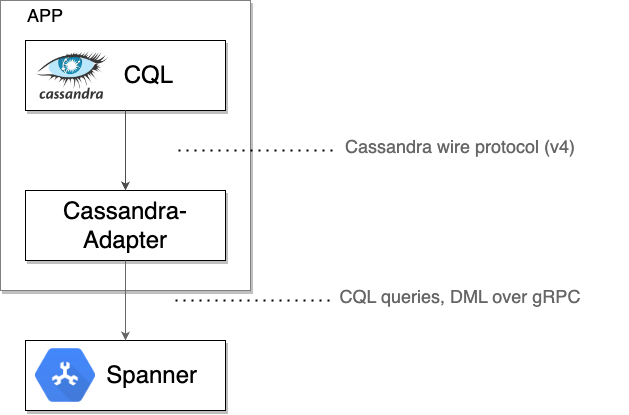
Spanner Cassandra इंटरफ़ेस की मदद से, कटओवर की प्रोसेस को आसानी से पूरा किया जा सकता है. इसमें मुख्य रूप से, अपने क्लाइंट ऐप्लिकेशन को कॉन्फ़िगर करना शामिल है, ताकि सभी डेटा इंटरैक्शन के लिए नेटिव Spanner Cassandra Client का इस्तेमाल किया जा सके. आपके ऐप्लिकेशन, Cassandra (ओरिजन) डेटाबेस से कम्यूनिकेट करने के बजाय, सीधे तौर पर Spanner (टारगेट) में डेटा को पढ़ने और लिखने लगेंगे. कनेक्टिविटी में यह बुनियादी बदलाव, आम तौर पर SpannerCqlSessionBuilder का इस्तेमाल करके किया जाता है. यह Spanner Cassandra Client लाइब्रेरी का एक मुख्य कॉम्पोनेंट है. इससे आपके Spanner इंस्टेंस से कनेक्शन बनाने में मदद मिलती है. इससे आपके ऐप्लिकेशन का पूरा डेटा ट्रैफ़िक, Spanner पर रीडायरेक्ट हो जाता है.
Java ऐप्लिकेशन में पहले से ही cassandra-java-driver लाइब्रेरी का इस्तेमाल किया जा रहा है. ऐसे में, Spanner Cassandra Java Client को इंटिग्रेट करने के लिए, CqlSession को शुरू करने के तरीके में सिर्फ़ मामूली बदलाव करने होते हैं.
google-cloud-spanner-cassandra डिपेंडेंसी पाना
Spanner Cassandra Client का इस्तेमाल शुरू करने के लिए, आपको सबसे पहले अपने प्रोजेक्ट में इसकी डिपेंडेंसी शामिल करनी होगी. google-cloud-spanner-cassandra आर्टफ़ैक्ट, Maven Central में पब्लिश किए जाते हैं. इन्हें ग्रुप आईडी com.google.cloud के तहत पब्लिश किया जाता है. अपने Java प्रोजेक्ट में, मौजूदा <dependencies> सेक्शन में यह नई डिपेंडेंसी जोड़ें. google-cloud-spanner-cassandra डिपेंडेंसी को शामिल करने का एक आसान उदाहरण यहां दिया गया है:
<!-- native Spanner Cassandra Client -->
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner-cassandra</artifactId>
<version>0.2.0</version>
</dependency>
</dependencies>
Spanner से कनेक्ट करने के लिए, कनेक्शन के कॉन्फ़िगरेशन में बदलाव करना
ज़रूरी डिपेंडेंसी जोड़ने के बाद, अगला चरण Spanner डेटाबेस से कनेक्ट करने के लिए, कनेक्शन कॉन्फ़िगरेशन में बदलाव करना है.
Cassandra क्लस्टर के साथ इंटरैक्ट करने वाला कोई सामान्य ऐप्लिकेशन, कनेक्शन बनाने के लिए अक्सर इस तरह के कोड का इस्तेमाल करता है:
CqlSession session = CqlSession.builder()
.addContactPoint(new InetSocketAddress("127.0.0.1", 9042))
.withLocalDatacenter("datacenter1")
.withAuthCredentials("username", "password")
.build();
इस कनेक्शन को Spanner पर रीडायरेक्ट करने के लिए, आपको CqlSession बनाने के लॉजिक में बदलाव करना होगा. cassandra-java-driver से सीधे तौर पर स्टैंडर्ड CqlSessionBuilder का इस्तेमाल करने के बजाय, Spanner Cassandra Client की ओर से उपलब्ध कराए गए SpannerCqlSession.builder() का इस्तेमाल करें. यहां उदाहरण देकर बताया गया है कि कनेक्शन कोड में बदलाव कैसे किया जा सकता है:
String databaseUri = "projects/<your-gcp-project>/instances/<your-spanner-instance>/databases/<your-spanner-database>";
CqlSession session = SpannerCqlSession.builder()
.setDatabaseUri(databaseUri)
.addContactPoint(new InetSocketAddress("localhost", 9042))
.withLocalDatacenter("datacenter1")
.build();
SpannerCqlSession.builder() का इस्तेमाल करके CqlSession को इंस्टैंशिएट करने और सही databaseUri देने पर, आपका ऐप्लिकेशन अब Spanner Cassandra Client के ज़रिए, आपके टारगेट Spanner डेटाबेस से कनेक्ट हो जाएगा. इस अहम बदलाव से यह पक्का होता है कि आपके ऐप्लिकेशन की ओर से की जाने वाली सभी रीड और राइट कार्रवाइयां, Spanner पर रीडायरेक्ट की जाएंगी और Spanner से ही पूरी की जाएंगी. इससे, शुरुआती कटओवर की प्रोसेस पूरी हो जाएगी. इस समय, आपका ऐप्लिकेशन उम्मीद के मुताबिक काम करता रहेगा. अब यह Spanner की स्केलेबिलिटी और भरोसेमंद होने की सुविधा के साथ काम करेगा.
बारीकियों के बारे में जानें: Spanner Cassandra Client कैसे काम करता है
Spanner Cassandra क्लाइंट, लोकल टीसीपी प्रॉक्सी के तौर पर काम करता है. यह ड्राइवर या क्लाइंट टूल से भेजे गए, Cassandra प्रोटोकॉल के रॉ बाइट को इंटरसेप्ट करता है. इसके बाद, यह इन बाइट को ज़रूरी मेटाडेटा के साथ gRPC मैसेज में रैप करता है, ताकि Spanner के साथ कम्यूनिकेट किया जा सके. Spanner से मिले जवाबों को वापस Cassandra वायर फ़ॉर्मैट में बदला जाता है. इसके बाद, इन्हें ओरिजनल ड्राइवर या टूल को वापस भेज दिया जाता है.
जब आपको लगे कि Spanner सभी ट्रैफ़िक को सही तरीके से मैनेज कर रहा है, तब ये काम किए जा सकते हैं:
- ओरिजनल Cassandra क्लस्टर को बंद करें.
8. डेटा को व्यवस्थित करना (ज़रूरी नहीं)
सफाई करने के लिए, Cloud Console के Spanner सेक्शन में जाएं. इसके बाद, कोडलैब में बनाया गया cassandra-adapter-demo इंस्टेंस मिटाएं.
Cassandra डेटाबेस मिटाएं. ऐसा तब करें, जब इसे स्थानीय तौर पर इंस्टॉल किया गया हो या यह बना रहे
अगर आपने Cassandra को यहां बनाए गए Compute Engine VM के बाहर इंस्टॉल किया है, तो डेटा हटाने या Cassandra को अनइंस्टॉल करने के लिए, सही तरीका अपनाएं.
9. बधाई हो!
आगे क्या करना है?
- Spanner के बारे में ज़्यादा जानें.
- Cassandra इंटरफ़ेस के बारे में ज़्यादा जानें.