
1. 소개
Spanner는 관계형 워크로드와 비관계형 워크로드 모두에 적합한 완전 관리형의 수평 확장 가능하고 전역으로 분산된 데이터베이스 서비스입니다.
Spanner의 Cassandra 인터페이스를 사용하면 익숙한 Cassandra 도구와 문법을 사용하여 Spanner의 확장 가능하고 가용성이 높은 완전 관리형 인프라를 활용할 수 있습니다.
학습할 내용
- Spanner 인스턴스와 데이터베이스를 설정하는 방법
- Cassandra 스키마 및 데이터 모델을 변환하는 방법
- Cassandra에서 Spanner로 이전 데이터를 일괄 내보내는 방법
- Cassandra 대신 Spanner를 가리키도록 애플리케이션을 구성하는 방법
필요한 항목
- 결제 계정에 연결된 Google Cloud 프로젝트
gcloudCLI가 설치되고 구성된 머신에 액세스하거나 Google Cloud Shell을 사용합니다.- 웹브라우저(예: Chrome, Firefox)
2. 설정 및 요건
GCP 프로젝트 만들기
Google Cloud 콘솔에 로그인하고 새 프로젝트를 만들거나 기존 프로젝트를 다시 사용합니다. 아직 Gmail이나 Google Workspace 계정이 없는 경우 계정을 만들어야 합니다.

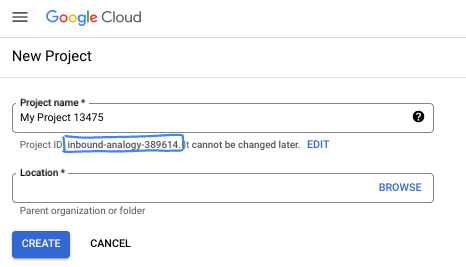
- 프로젝트 이름은 이 프로젝트 참가자의 표시 이름입니다. 이는 Google API에서 사용하지 않는 문자열이며 언제든지 업데이트할 수 있습니다.
- 프로젝트 ID는 모든 Google Cloud 프로젝트에서 고유하며, 변경할 수 없습니다(설정된 후에는 변경할 수 없음). Cloud 콘솔은 고유한 문자열을 자동으로 생성합니다. 일반적으로는 신경 쓰지 않아도 됩니다. 대부분의 Codelab에서는 프로젝트 ID (일반적으로
PROJECT_ID로 식별됨)를 참조해야 합니다. 생성된 ID가 마음에 들지 않으면 다른 임의 ID를 생성할 수 있습니다. 또는 직접 시도해 보고 사용 가능한지 확인할 수도 있습니다. 이 단계 이후에는 변경할 수 없으며 프로젝트 기간 동안 유지됩니다. - 참고로 세 번째 값은 일부 API에서 사용하는 프로젝트 번호입니다. 이 세 가지 값에 대한 자세한 내용은 문서를 참고하세요.
결제 설정
다음으로 결제 관리 사용자 가이드에 따라 Cloud 콘솔에서 결제를 사용 설정해야 합니다. Google Cloud 신규 사용자는 미화$300 상당의 무료 체험판 프로그램에 참여할 수 있습니다. 이 튜토리얼을 마친 후 비용이 결제되지 않도록 하려면 Codelab의 끝에 있는 '9단계 정리'에 따라 Spanner 인스턴스를 종료하세요.
Cloud Shell 시작
Google Cloud를 노트북에서 원격으로 실행할 수 있지만, 이 Codelab에서는 Cloud에서 실행되는 명령줄 환경인 Google Cloud Shell을 사용합니다.
Google Cloud 콘솔의 오른쪽 상단 툴바에 있는 Cloud Shell 아이콘을 클릭합니다.

환경을 프로비저닝하고 연결하는 데 몇 분 정도 소요됩니다. 완료되면 다음과 같이 표시됩니다.

가상 머신에는 필요한 개발 도구가 모두 들어있습니다. 영구적인 5GB 홈 디렉터리를 제공하고 Google Cloud에서 실행되므로 네트워크 성능과 인증이 크게 개선됩니다. 이 Codelab의 모든 작업은 브라우저 내에서 수행할 수 있습니다. 아무것도 설치할 필요가 없습니다.
다음 단계
다음으로 Cassandra 클러스터를 배포합니다.
3. Cassandra 클러스터 배포 (원본)
이 Codelab에서는 Compute Engine에 단일 노드 Cassandra 클러스터를 설정합니다.
1. Cassandra용 GCE VM 만들기
인스턴스를 만들려면 이전에 프로비저닝된 Cloud Shell에서 gcloud compute instances create 명령어를 사용합니다.
gcloud compute instances create cassandra-origin \
--machine-type=e2-medium \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=cassandra-migration \
--boot-disk-size=20GB \
--zone=us-central1-a
2. Cassandra 설치
아래 안내에 따라 Navigation menu 페이지에서 VM Instances로 이동합니다. 
cassandra-origin VM을 검색하고 SSH를 사용하여 VM에 연결합니다.
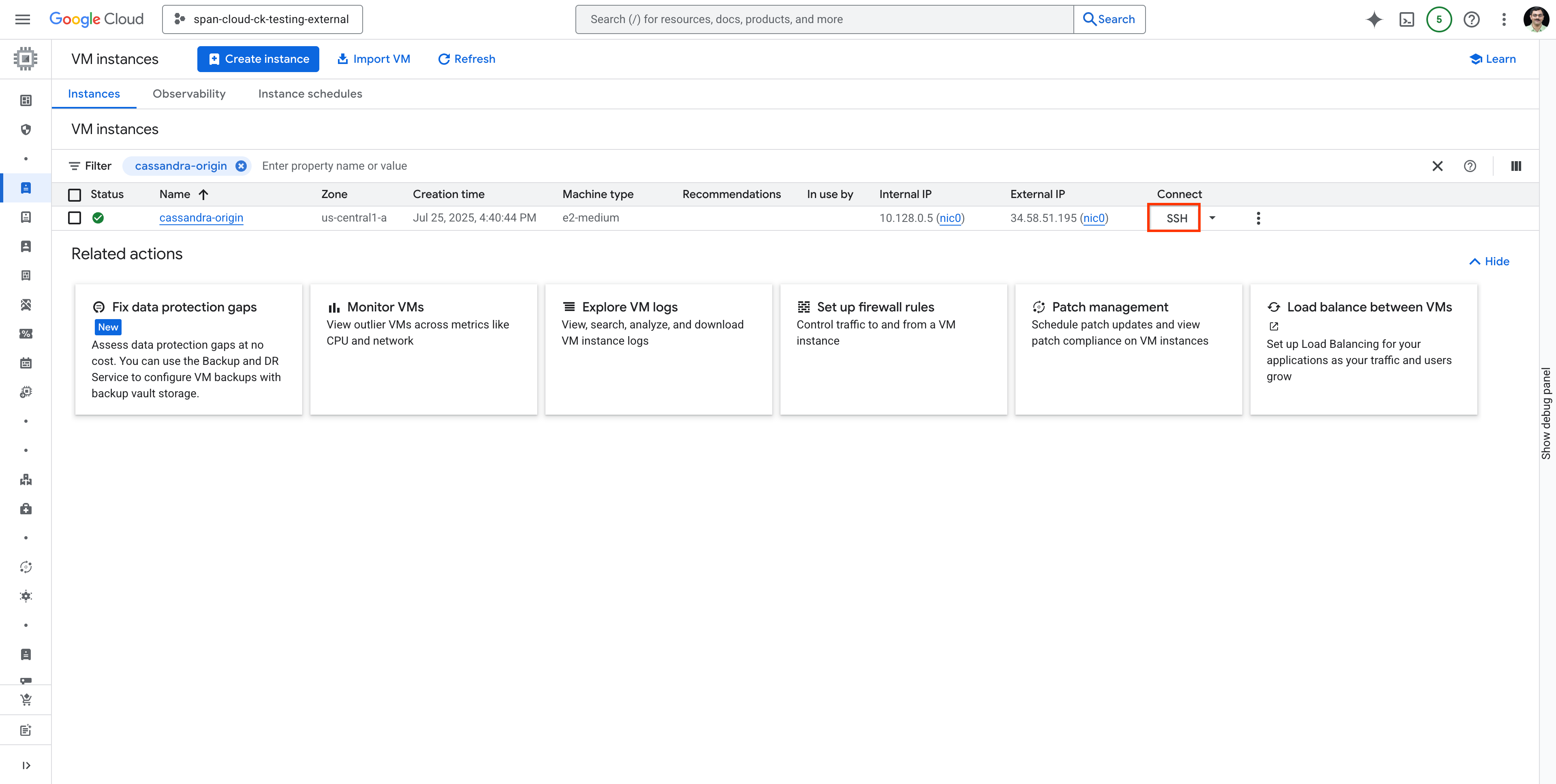 .
.
생성하고 SSH로 연결한 VM에 Cassandra를 설치하려면 다음 명령어를 실행하세요.
Java 설치 (Cassandra 종속 항목)
sudo apt-get update
sudo apt-get install -y openjdk-11-jre-headless
Cassandra 저장소 추가
echo "deb [signed-by=/etc/apt/keyrings/apache-cassandra.asc] https://debian.cassandra.apache.org 41x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
sudo curl -o /etc/apt/keyrings/apache-cassandra.asc https://downloads.apache.org/cassandra/KEYS
Cassandra 설치
sudo apt-get update
sudo apt-get install -y cassandra
Cassandra 서비스의 리슨 주소를 설정합니다.
여기에서는 보안 강화를 위해 Cassandra VM의 내부 IP 주소를 사용합니다.
호스트 머신의 IP 주소를 기록합니다.
Cloud Shell에서 다음 명령어를 사용하거나 Cloud 콘솔의 VM Instances 페이지에서 가져올 수 있습니다.
gcloud compute instances describe cassandra-origin --format="get(networkInterfaces[0].networkIP)" --zone=us-central1-a
또는
 .
.
구성 파일에서 주소 업데이트
원하는 편집기를 사용하여 Cassandra 구성 파일을 업데이트할 수 있습니다.
sudo vim /etc/cassandra/cassandra.yaml
rpc_address:를 VM의 IP 주소로 변경하고 파일을 저장한 후 닫습니다.
VM에서 Cassandra 서비스 사용 설정
sudo systemctl enable cassandra
sudo systemctl stop cassandra
sudo systemctl start cassandra
sudo systemctl status cassandra
3. 키스페이스 및 테이블 만들기 {create-keyspace-and-table}
'users' 테이블 예시를 사용하여 'analytics'라는 키스페이스를 만듭니다.
export CQLSH_HOST=<IP of the VM added as rpc_address>
/usr/bin/cqlsh
cqlsh 내부:
-- Create keyspace (adjust replication for production)
CREATE KEYSPACE analytics WITH replication = {'class':'SimpleStrategy', 'replication_factor':1};
-- Use the keyspace
USE analytics;
-- Create the users table
CREATE TABLE users (
id int PRIMARY KEY,
active boolean,
username text,
);
-- Insert 5 rows
INSERT INTO users (id, active, username) VALUES (1, true, 'd_knuth');
INSERT INTO users (id, active, username) VALUES (2, true, 'sanjay_ghemawat');
INSERT INTO users (id, active, username) VALUES (3, false, 'gracehopper');
INSERT INTO users (id, active, username) VALUES (4, true, 'brian_kernighan');
INSERT INTO users (id, active, username) VALUES (5, true, 'jeff_dean');
INSERT INTO users (id, active, username) VALUES (6, true, 'jaime_levy');
-- Select all users to verify the inserts.
SELECT * from users;
-- Exit cqlsh
EXIT;
SSH 세션을 열어 두거나 이 VM (hostname -I)의 IP 주소를 기록해 둡니다.
다음 단계
이제 Cloud Spanner 인스턴스와 데이터베이스를 설정합니다.
4. Spanner 인스턴스 만들기 (타겟)
Spanner에서 인스턴스는 하나 이상의 Spanner 데이터베이스를 호스팅하는 컴퓨팅 및 스토리지 리소스 클러스터입니다. 이 Codelab의 Spanner 데이터베이스를 호스팅하려면 인스턴스가 하나 이상 필요합니다.
gcloud SDK 버전 확인
인스턴스를 만들기 전에 Google Cloud Shell의 gcloud SDK가 필요한 버전(gcloud SDK 531.0.0보다 큰 버전)으로 업데이트되었는지 확인합니다. 아래 명령어를 따라 gcloud SDK 버전을 확인할 수 있습니다.
$ gcloud version | grep Google
다음은 출력 예시입니다.
Google Cloud SDK 489.0.0
사용 중인 버전이 필수 531.0.0 버전 (이전 예의 489.0.0)보다 이전인 경우 다음 명령어를 실행하여 Google Cloud SDK를 업그레이드해야 합니다.
sudo apt-get update \
&& sudo apt-get --only-upgrade install google-cloud-cli-anthoscli google-cloud-cli-cloud-run-proxy kubectl google-cloud-cli-skaffold google-cloud-cli-cbt google-cloud-cli-docker-credential-gcr google-cloud-cli-spanner-migration-tool google-cloud-cli-cloud-build-local google-cloud-cli-pubsub-emulator google-cloud-cli-app-engine-python google-cloud-cli-kpt google-cloud-cli-bigtable-emulator google-cloud-cli-datastore-emulator google-cloud-cli-spanner-emulator google-cloud-cli-app-engine-go google-cloud-cli-app-engine-python-extras google-cloud-cli-config-connector google-cloud-cli-package-go-module google-cloud-cli-istioctl google-cloud-cli-anthos-auth google-cloud-cli-gke-gcloud-auth-plugin google-cloud-cli-app-engine-grpc google-cloud-cli-kubectl-oidc google-cloud-cli-terraform-tools google-cloud-cli-nomos google-cloud-cli-local-extract google-cloud-cli-firestore-emulator google-cloud-cli-harbourbridge google-cloud-cli-log-streaming google-cloud-cli-minikube google-cloud-cli-app-engine-java google-cloud-cli-enterprise-certificate-proxy google-cloud-cli
Spanner API 사용 설정
Cloud Shell 내에 프로젝트 ID가 설정되어 있는지 확인합니다. 아래의 첫 번째 명령어를 사용하여 현재 구성된 프로젝트 ID를 찾습니다. 결과가 예상과 다른 경우 아래의 두 번째 명령어를 사용하여 올바른 결과를 설정합니다.
gcloud config get-value project
gcloud config set project [YOUR-DESIRED-PROJECT-ID]
기본 리전을 us-central1로 구성합니다. Spanner 리전 구성에서 지원하는 다른 리전으로 변경해도 됩니다.
gcloud config set compute/region us-central1
Spanner API를 사용 설정합니다.
gcloud services enable spanner.googleapis.com
Spanner 인스턴스 만들기
이 섹션에서는 무료 체험판 인스턴스 또는 프로비저닝된 인스턴스를 만듭니다. 이 Codelab 전반에서 사용되는 Spanner Cassandra 어댑터 인스턴스 ID는 cassandra-adapter-demo이며, export 명령줄을 사용하여 SPANNER_INSTANCE_ID 변수로 설정됩니다. 원하는 경우 인스턴스 ID 이름을 직접 선택할 수 있습니다.
무료 체험판 Spanner 인스턴스 만들기
프로젝트에 Cloud Billing이 사용 설정된 Google 계정이 있는 모든 사용자는 Spanner 90일 무료 체험판 인스턴스를 사용할 수 있습니다. 무료 체험판 인스턴스를 유료 인스턴스로 업그레이드하기로 선택하지 않으면 요금이 청구되지 않습니다. Spanner Cassandra 어댑터는 무료 체험판 인스턴스에서 지원됩니다. 자격 요건을 충족하는 경우 Cloud Shell을 열고 다음 명령어를 실행하여 무료 체험판 인스턴스를 만듭니다.
export SPANNER_INSTANCE_ID=cassandra-adapter-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
명령어 결과 출력:
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Creating instance...done.
5. Cassandra 스키마 및 데이터 모델을 Spanner로 마이그레이션
Cassandra 데이터베이스에서 Spanner로 데이터를 전환하는 초기 단계이자 중요한 단계는 기존 Cassandra 스키마를 변환하여 Spanner의 구조 및 데이터 유형 요구사항에 맞추는 것입니다.
이 복잡한 스키마 마이그레이션 프로세스를 간소화하려면 Spanner에서 제공하는 두 가지 유용한 오픈소스 도구 중 하나를 사용하세요.
- Spanner 마이그레이션 도구: 이 도구를 사용하면 기존 Cassandra 데이터베이스에 연결하고 스키마를 Spanner로 마이그레이션하여 스키마를 마이그레이션할 수 있습니다. 이 도구는
gcloud cli의 일부로 제공됩니다. - Spanner Cassandra 스키마 도구: 이 도구를 사용하면 Cassandra에서 내보낸 DDL을 Spanner로 변환할 수 있습니다. Codelab에서는 이 두 도구 중 하나를 사용할 수 있습니다. 이 Codelab에서는 Spanner 마이그레이션 도구를 사용하여 스키마를 마이그레이션합니다.
Spanner 마이그레이션 도구
Spanner 마이그레이션 도구는 MySQL, Postgres, Cassandra 등 다양한 데이터 소스에서 스키마를 마이그레이션하는 데 도움이 됩니다.
이 Codelab에서는 이 도구의 CLI를 사용하지만, 적용하기 전에 Spanner 스키마를 수정하는 데도 도움이 되는 UI 기반 버전의 도구를 살펴보고 사용하는 것이 좋습니다.
Cloud Shell에서 spanner-migration-tool을 실행하면 Cassandra VM의 내부 IP 주소에 액세스하지 못할 수 있습니다. 따라서 Cassandra를 설치한 VM에서 동일한 명령어를 실행하는 것이 좋습니다.
Cassandra를 설치한 VM에서 다음을 실행합니다.
Spanner 마이그레이션 도구 설치
sudo apt-get update
sudo apt-get install --upgrade google-cloud-sdk-spanner-migration-tool
설치에 문제가 있는 경우 installing-spanner-migration-tool에서 자세한 단계를 참고하세요.
Gcloud 사용자 인증 정보 새로고침
gcloud auth login
gcloud auth application-default login
스키마 마이그레이션
export CASSANDRA_HOST=`<ip address of the VM used as rpc_address above>`
export PROJECT=`<PROJECT_ID>`
gcloud alpha spanner migrate schema \
--source=cassandra \
--source-profile="host=${CASSANDRA_HOST},user=cassandra,password=cassandra,port=9042,keyspace=analytics,datacenter=datacenter1" \
--target-profile="project=${PROJECT},instance=cassandra-adapter-demo,dbName=analytics" \
--project=${PROJECT}
Spanner DDL 확인
gcloud spanner databases ddl describe analytics --instance=cassandra-adapter-demo
스키마 이전이 완료되면 이 명령어의 출력은 다음과 같아야 합니다.
CREATE TABLE users (
active BOOL OPTIONS (
cassandra_type = 'boolean'
),
id INT64 NOT NULL OPTIONS (
cassandra_type = 'int'
),
username STRING(MAX) OPTIONS (
cassandra_type = 'text'
),
) PRIMARY KEY(id);
(선택사항) 변환된 DDL 보기
변환된 DDL을 확인하고 Spanner에 다시 적용할 수 있습니다 (추가 변경이 필요한 경우).
cat `ls -t cassandra_*schema.ddl.txt | head -n 1`
이 명령어의 출력은 다음과 같습니다.
CREATE TABLE `users` (
`active` BOOL OPTIONS (cassandra_type = 'boolean'),
`id` INT64 NOT NULL OPTIONS (cassandra_type = 'int'),
`username` STRING(MAX) OPTIONS (cassandra_type = 'text'),
) PRIMARY KEY (`id`)
(선택사항) 전환 보고서 보기
cat `ls -t cassandra_*report.txt | head -n 1`
전환 보고서에는 유의해야 할 문제가 강조 표시됩니다. 예를 들어 소스와 Spanner 간에 열의 최대 정밀도가 일치하지 않으면 여기에 강조 표시됩니다.
6. 이전 데이터 일괄 내보내기
일괄 마이그레이션을 수행하려면 다음 단계를 따라야 합니다.
- 기존 GCS 버킷을 프로비저닝하거나 재사용합니다.
- Cassandra 드라이버 구성 파일을 버킷에 업로드
- 일괄 마이그레이션을 실행합니다.
Cloud Shell 또는 새로 프로비저닝된 VM에서 일괄 이전을 시작할 수 있지만, 구성 파일 생성과 같은 일부 단계에서는 로컬 저장소에 파일이 유지되므로 이 Codelab에서는 VM을 사용하는 것이 좋습니다.
GCS 버킷을 프로비저닝합니다.
이 단계를 마치면 GCS 버킷을 프로비저닝하고 CASSANDRA_BUCKET_NAME이라는 변수에 경로를 내보내야 합니다. 기존 버킷을 재사용하려면 경로를 내보내면 됩니다.
if [ -z ${CASSANDRA_BUCKET_NAME} ]; then
export CASSANDRA_BUCKET_NAME="gs://cassandra-demo-$(date +%Y-%m-%d-%H-%M-%S)-$(head /dev/urandom | tr -dc a-z | head -c 20)"
gcloud storage buckets create "${CASSANDRA_BUCKET_NAME}"
else
echo "using existing bucket ${CASSANDRA_BUCKET_NAME}"
fi
드라이버 구성 파일 만들기 및 업로드
여기서는 매우 기본적인 Cassandra 드라이버 구성 파일을 업로드합니다. 파일의 전체 형식은 여기를 참고하세요.
# Configuration for the Cassandra instance and GCS bucket
INSTANCE_NAME="cassandra-origin"
ZONE="us-central1-a"
CASSANDRA_PORT="9042"
# Retrieve the internal IP address of the Cassandra instance
CASSANDRA_IP=$(gcloud compute instances describe "${INSTANCE_NAME}" \
--format="get(networkInterfaces[0].networkIP)" \
--zone="${ZONE}")
# Check if the IP was successfully retrieved
if [[ -z "${CASSANDRA_IP}" ]]; then
echo "Error: Could not retrieve Cassandra instance IP."
exit 1
fi
# Define the full contact point
CONTACT_POINT="${CASSANDRA_IP}:${CASSANDRA_PORT}"
# Create a temporary file with the specified content
TMP_FILE=$(mktemp)
cat <<EOF > "${TMP_FILE}"
# Reference configuration for the DataStax Java driver for Apache Cassandra®.
# This file is in HOCON format, see https://github.com/typesafehub/config/blob/master/HOCON.md.
datastax-java-driver {
basic.contact-points = ["${CONTACT_POINT}"]
basic.session-keyspace = analytics
basic.load-balancing-policy.local-datacenter = datacenter1
advanced.auth-provider {
class = PlainTextAuthProvider
username = cassandra
password = cassandra
}
}
EOF
# Upload the temporary file to the specified GCS bucket
if gsutil cp "${TMP_FILE}" "${CASSANDRA_BUCKET_NAME}/cassandra.conf"; then
echo "Successfully uploaded ${TMP_FILE} to ${CASSANDRA_BUCKET_NAME}/cassandra.conf"
# Concatenate (cat) the uploaded file from GCS
echo "Displaying the content of the uploaded file:"
gsutil cat "${CASSANDRA_BUCKET_NAME}/cassandra.conf"
else
echo "Error: Failed to upload file to GCS."
fi
# Clean up the temporary file
rm "${TMP_FILE}"
일괄 마이그레이션 실행
Spanner로 데이터를 일괄 마이그레이션하는 샘플 명령어입니다. 실제 프로덕션 사용 사례의 경우 원하는 규모와 처리량에 따라 머신 유형과 개수를 조정해야 합니다. 옵션의 전체 목록은 README_Sourcedb_to_Spanner.md#cassandra-to-spanner-bulk-migration을 참고하세요.
gcloud dataflow flex-template run "sourcedb-to-spanner-flex-job" \
--project "`gcloud config get-value project`" \
--region "us-central1" \
--max-workers "2" \
--num-workers "1" \
--worker-machine-type "e2-standard-8" \
--template-file-gcs-location "gs://dataflow-templates-us-central1/latest/flex/Sourcedb_to_Spanner_Flex" \
--additional-experiments="[\"disable_runner_v2\"]" \
--parameters "sourceDbDialect=CASSANDRA" \
--parameters "insertOnlyModeForSpannerMutations=true" \
--parameters "sourceConfigURL=$CASSANDRA_BUCKET_NAME/cassandra.conf" \
--parameters "instanceId=cassandra-adapter-demo" \
--parameters "databaseId=analytics" \
--parameters "projectId=`gcloud config get-value project`" \
--parameters "outputDirectory=$CASSANDRA_BUCKET_NAME/output" \
--parameters "batchSizeForSpannerMutations=1"
그러면 다음과 같은 출력이 생성됩니다. 생성된 id를 기록해 두고 이를 사용하여 Dataflow 작업의 상태를 쿼리합니다.
job: createTime: '2025-08-08T09:41:09.820267Z' currentStateTime: '1970-01-01T00:00:00Z' id: 2025-08-08_02_41_09-17637291823018196600 location: us-central1 name: sourcedb-to-spanner-flex-job projectId: span-cloud-ck-testing-external startTime: '2025-08-08T09:41:09.820267Z'
아래 명령어를 실행하여 작업 상태를 확인하고 상태가 JOB_STATE_DONE로 변경될 때까지 기다립니다.
gcloud dataflow jobs describe --region=us-central1 <dataflow job id> | grep "currentState:"
처음에는 작업이 다음과 같이 대기열에 추가된 상태가 됩니다.
currentState: JOB_STATE_QUEUED
작업이 대기열에 추가되거나 실행되는 동안 Cloud Console UI에서 Dataflow/Jobs 페이지를 탐색하여 작업을 모니터링하는 것이 좋습니다.
작업이 완료되면 작업 상태가 다음과 같이 변경됩니다.
currentState: JOB_STATE_DONE
7. Spanner를 가리키도록 애플리케이션 구성 (전환)
마이그레이션 단계 후 데이터의 정확성과 무결성을 꼼꼼하게 검증한 후에는 애플리케이션의 운영 초점을 기존 Cassandra 시스템에서 새로 채워진 Spanner 데이터베이스로 전환하는 것이 중요합니다. 이 중요한 전환 기간을 일반적으로 '컷오버'라고 합니다.
전환 단계는 라이브 애플리케이션 트래픽이 원래 Cassandra 클러스터에서 리디렉션되어 강력하고 확장 가능한 Spanner 인프라에 직접 연결되는 시점을 나타냅니다. 이 전환은 애플리케이션이 Spanner의 기능을 얼마나 쉽게 활용할 수 있는지를 보여줍니다. 특히 Spanner Cassandra 인터페이스를 사용하는 경우에 그렇습니다.
Spanner Cassandra 인터페이스를 사용하면 전환 프로세스가 간소화됩니다. 주로 모든 데이터 상호작용에 네이티브 Spanner Cassandra 클라이언트를 사용하도록 클라이언트 애플리케이션을 구성하는 작업이 포함됩니다. 애플리케이션이 Cassandra (원본) 데이터베이스와 통신하는 대신 Spanner (타겟)에 직접 데이터를 읽고 쓰는 작업을 원활하게 시작합니다. 이러한 연결의 근본적인 변화는 일반적으로 Spanner 인스턴스에 대한 연결 설정을 용이하게 하는 Spanner Cassandra 클라이언트 라이브러리의 핵심 구성요소인 SpannerCqlSessionBuilder를 사용하여 이루어집니다. 이렇게 하면 애플리케이션의 전체 데이터 트래픽 흐름이 Spanner로 효과적으로 리라우팅됩니다.
이미 cassandra-java-driver 라이브러리를 사용하는 Java 애플리케이션의 경우 Spanner Cassandra Java 클라이언트를 통합하려면 CqlSession 초기화만 약간 변경하면 됩니다.
google-cloud-spanner-cassandra 종속 항목 가져오기
Spanner Cassandra 클라이언트를 사용하려면 먼저 종속 항목을 프로젝트에 통합해야 합니다. google-cloud-spanner-cassandra 아티팩트는 그룹 ID com.google.cloud 아래의 Maven Central에 게시됩니다. Java 프로젝트의 기존 <dependencies> 섹션에 다음 새 종속 항목을 추가합니다. 다음은 google-cloud-spanner-cassandra 종속 항목을 포함하는 방법을 보여주는 간단한 예입니다.
<!-- native Spanner Cassandra Client -->
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner-cassandra</artifactId>
<version>0.2.0</version>
</dependency>
</dependencies>
Spanner에 연결하도록 연결 구성 변경
필요한 종속 항목을 추가한 후 다음 단계는 Spanner 데이터베이스에 연결하도록 연결 구성을 변경하는 것입니다.
Cassandra 클러스터와 상호작용하는 일반적인 애플리케이션은 다음 코드와 유사한 코드를 사용하여 연결을 설정합니다.
CqlSession session = CqlSession.builder()
.addContactPoint(new InetSocketAddress("127.0.0.1", 9042))
.withLocalDatacenter("datacenter1")
.withAuthCredentials("username", "password")
.build();
이 연결을 Spanner로 리디렉션하려면 CqlSession 생성 로직을 수정해야 합니다. cassandra-java-driver에서 표준 CqlSessionBuilder를 직접 사용하는 대신 Spanner Cassandra 클라이언트에서 제공하는 SpannerCqlSession.builder()를 사용합니다. 다음은 연결 코드를 수정하는 방법을 보여주는 예입니다.
String databaseUri = "projects/<your-gcp-project>/instances/<your-spanner-instance>/databases/<your-spanner-database>";
CqlSession session = SpannerCqlSession.builder()
.setDatabaseUri(databaseUri)
.addContactPoint(new InetSocketAddress("localhost", 9042))
.withLocalDatacenter("datacenter1")
.build();
SpannerCqlSession.builder()을 사용하여 CqlSession를 인스턴스화하고 올바른 databaseUri를 제공하면 애플리케이션이 이제 Spanner Cassandra 클라이언트를 통해 대상 Spanner 데이터베이스에 연결됩니다. 이 중요한 변경사항을 통해 애플리케이션에서 실행하는 모든 후속 읽기 및 쓰기 작업이 Spanner로 전달되고 Spanner에서 처리되므로 초기 전환이 효과적으로 완료됩니다. 이제 애플리케이션이 Spanner의 확장성과 안정성을 기반으로 예상대로 계속 작동합니다.
내부 구조: Spanner Cassandra 클라이언트 작동 방식
Spanner Cassandra 클라이언트는 드라이버 또는 클라이언트 도구에서 전송된 원시 Cassandra 프로토콜 바이트를 가로채는 로컬 TCP 프록시 역할을 합니다. 그런 다음 필요한 메타데이터와 함께 이러한 바이트를 Spanner와의 통신을 위해 gRPC 메시지로 래핑합니다. Spanner의 응답은 Cassandra 와이어 형식으로 다시 변환되어 원래 드라이버 또는 도구로 다시 전송됩니다.

Spanner가 모든 트래픽을 올바르게 처리한다고 확신하면 다음 작업을 할 수 있습니다.
- 원래 Cassandra 클러스터를 사용 중단합니다.
8. 정리 (선택사항)
정리하려면 Cloud Console의 Spanner 섹션으로 이동하여 Codelab에서 만든 cassandra-adapter-demo 인스턴스를 삭제하면 됩니다.
Cassandra 데이터베이스 삭제 (로컬에 설치되었거나 지속된 경우)
여기에서 만든 Compute Engine VM 외부에서 Cassandra를 설치한 경우 적절한 단계에 따라 데이터를 삭제하거나 Cassandra를 제거합니다.
9. 축하합니다.
다음 단계
- Spanner에 대해 자세히 알아보세요.
- Cassandra 인터페이스에 대해 자세히 알아보세요.