
1. 简介
Spanner 是一款全托管式、可横向扩缩、在全球范围分布的数据库服务,非常适合关系型和非关系型工作负载。
借助 Spanner 的 Cassandra 接口,您可以使用熟悉的 Cassandra 工具和语法来利用 Spanner 的全托管式、可扩缩且高可用的基础设施。
学习内容
- 如何设置 Spanner 实例和数据库。
- 如何转换 Cassandra 架构和数据模型。
- 如何将历史数据从 Cassandra 批量导出到 Spanner。
- 如何将应用指向 Spanner 而不是 Cassandra。
所需条件
- 与结算账号相关联的 Google Cloud 项目。
- 有权访问安装并配置了
gcloudCLI 的机器,或使用 Google Cloud Shell。 - 网络浏览器,例如 Chrome 或 Firefox。
2. 设置和要求
创建 GCP 项目
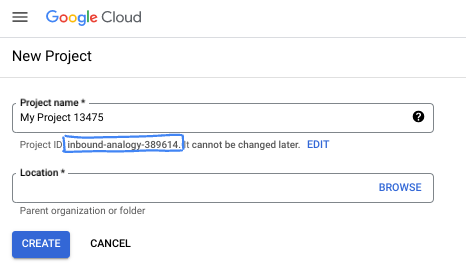
登录 Google Cloud 控制台,然后创建一个新项目或重复使用现有项目。如果您还没有 Gmail 或 Google Workspace 账号,则必须创建一个。

- 项目名称是此项目参与者的显示名称。它是 Google API 尚未使用的字符串。您可以随时对其进行更新。
- 项目 ID 在所有 Google Cloud 项目中是唯一的,并且是不可变的(一经设置便无法更改)。Cloud 控制台会自动生成一个唯一字符串;通常情况下,您无需关注该字符串。在大多数 Codelab 中,您都需要引用项目 ID(通常用
PROJECT_ID标识)。如果您不喜欢生成的 ID,可以再随机生成一个 ID。或者,您也可以尝试自己的项目 ID,看看是否可用。完成此步骤后便无法更改该 ID,并且此 ID 在项目期间会一直保留。 - 此外,还有第三个值,即部分 API 使用的项目编号,供您参考。如需详细了解所有这三个值,请参阅文档。
结算设置
接下来,您需要按照结算管理用户指南中的说明在 Cloud 控制台中启用结算功能。Google Cloud 新用户符合参与 300 美元免费试用计划的条件。为避免产生超出本教程范围的结算费用,您可以在本 Codelab 结束时按照“第 9 步:清理”中的说明关闭 Spanner 实例。
启动 Cloud Shell
虽然可以通过笔记本电脑对 Google Cloud 进行远程操作,但在此 Codelab 中,您将使用 Google Cloud Shell,这是一个在云端运行的命令行环境。
在 Google Cloud 控制台中,点击右上角工具栏中的 Cloud Shell 图标:

预配和连接到环境应该只需要片刻时间。完成后,您应该会看到如下内容:

这个虚拟机已加载了您需要的所有开发工具。它提供了一个持久的 5 GB 主目录,并且在 Google Cloud 中运行,大大增强了网络性能和身份验证功能。您在此 Codelab 中的所有工作都可以在浏览器中完成。您无需安装任何程序。
后续步骤
接下来,您将部署 Cassandra 集群。
3. 部署 Cassandra 集群(原始)
在此 Codelab 中,我们将在 Compute Engine 上设置单节点 Cassandra 集群。
1. 为 Cassandra 创建 GCE 虚拟机
如需创建实例,请使用之前预配的 Cloud Shell 中的 gcloud compute instances create 命令。
gcloud compute instances create cassandra-origin \
--machine-type=e2-medium \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=cassandra-migration \
--boot-disk-size=20GB \
--zone=us-central1-a
2. 安装 Cassandra
按照以下说明从 Navigation menu 页面导航到 VM Instances: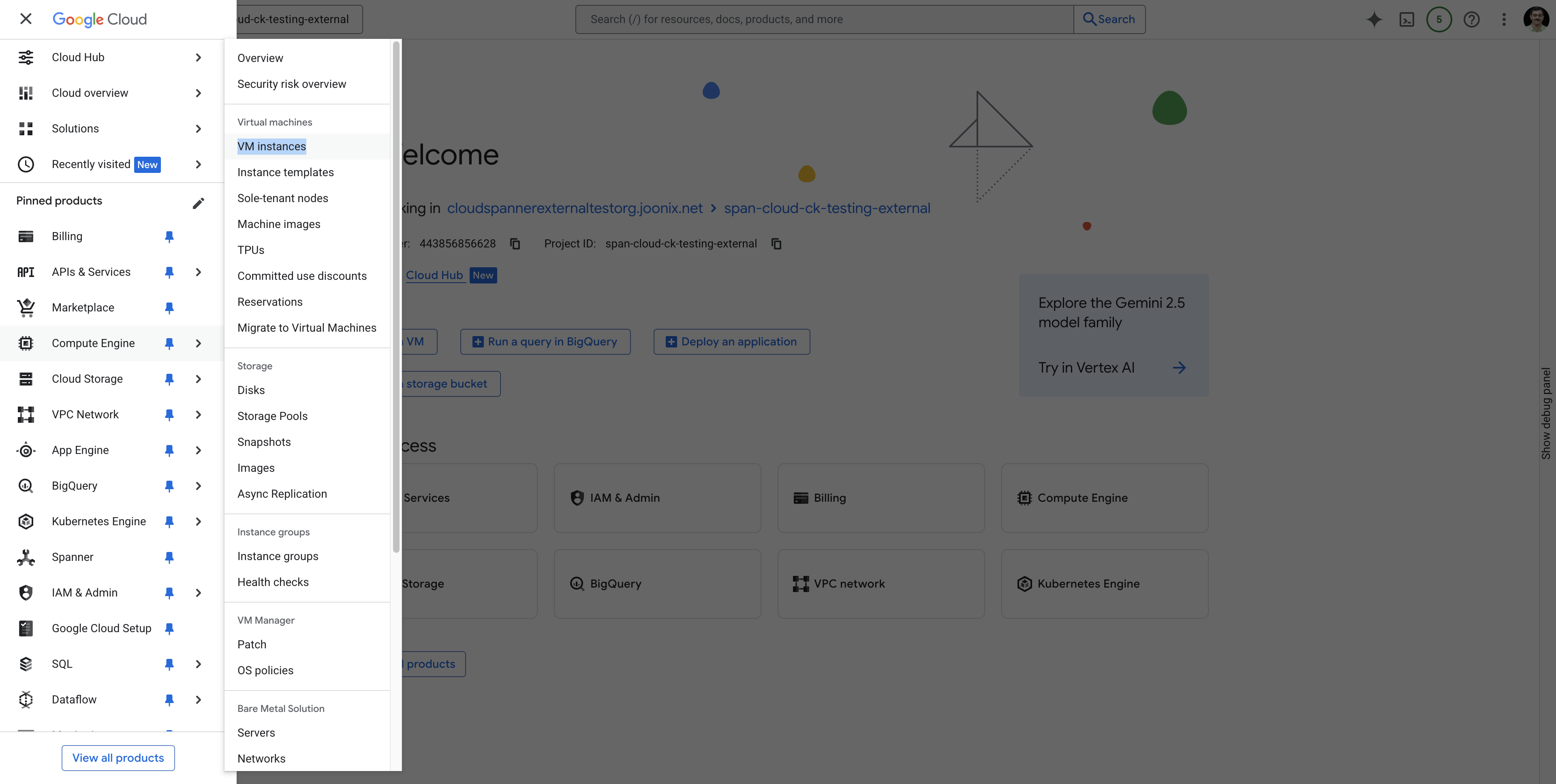 。
。
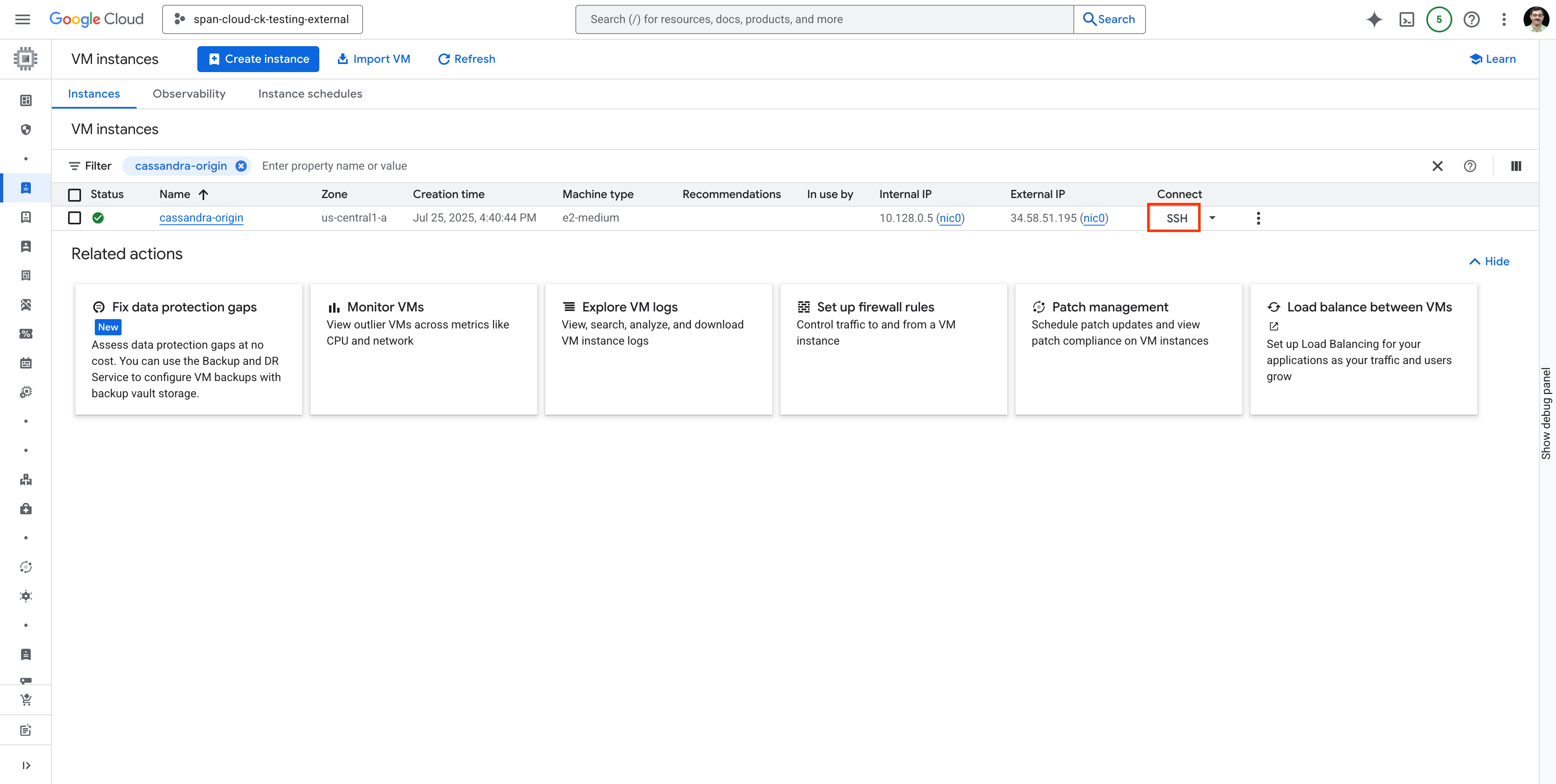
搜索 cassandra-origin 虚拟机,然后使用 SSH 连接到该虚拟机,如下所示:
 。
。
运行以下命令,在您创建并已通过 SSH 连接的虚拟机上安装 Cassandra。
安装 Java(Cassandra 依赖项)
sudo apt-get update
sudo apt-get install -y openjdk-11-jre-headless
添加 Cassandra 代码库
echo "deb [signed-by=/etc/apt/keyrings/apache-cassandra.asc] https://debian.cassandra.apache.org 41x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
sudo curl -o /etc/apt/keyrings/apache-cassandra.asc https://downloads.apache.org/cassandra/KEYS
安装 Cassandra
sudo apt-get update
sudo apt-get install -y cassandra
为 Cassandra 服务设置监听地址。
为提高安全性,我们在此处使用了 Cassandra 虚拟机的内部 IP 地址。
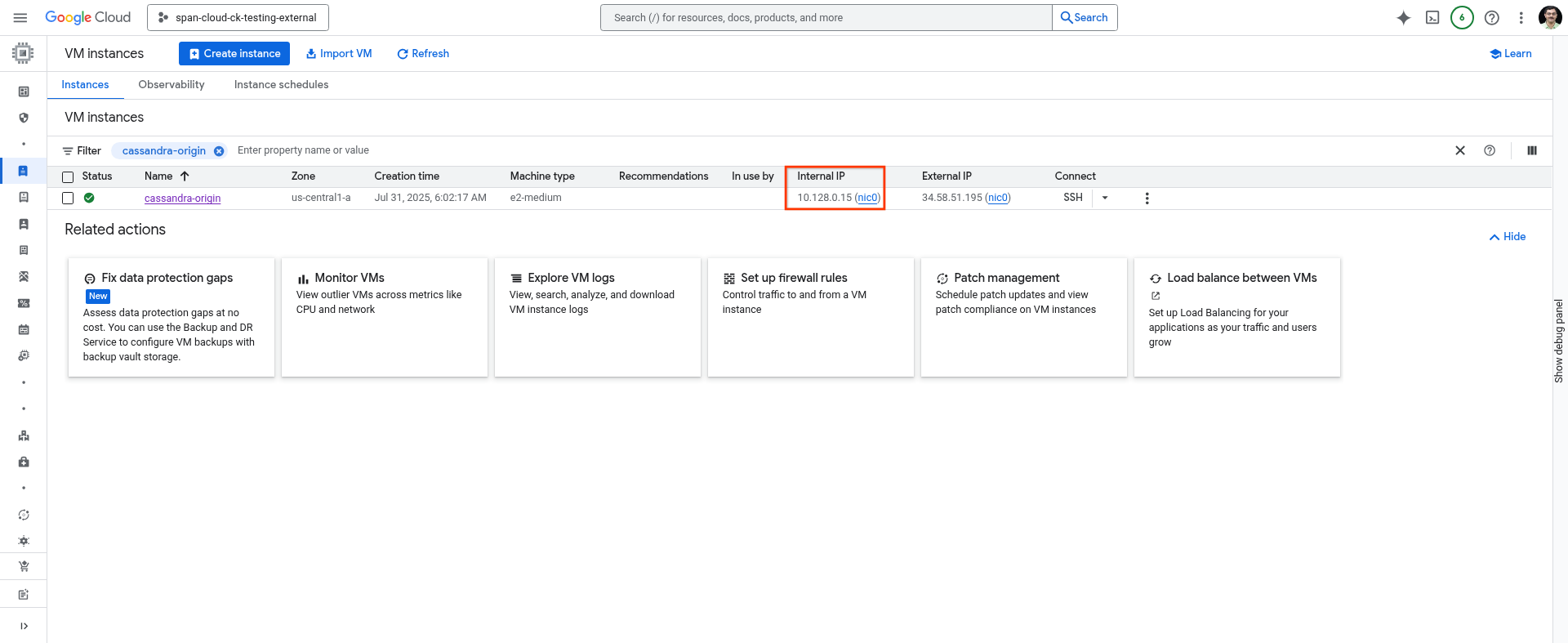
记下宿主机的 IP 地址
您可以在 Cloud Shell 中使用以下命令,也可以从 Cloud 控制台的 VM Instances 页面获取该值。
gcloud compute instances describe cassandra-origin --format="get(networkInterfaces[0].networkIP)" --zone=us-central1-a
或
 。
。
更新配置文件中的地址
您可以使用所选的编辑器更新 Cassandra 配置文件
sudo vim /etc/cassandra/cassandra.yaml
将 rpc_address: 更改为虚拟机的 IP 地址,然后保存并关闭该文件。
在虚拟机上启用 Cassandra 服务
sudo systemctl enable cassandra
sudo systemctl stop cassandra
sudo systemctl start cassandra
sudo systemctl status cassandra
3. 创建键空间和表 {create-keyspace-and-table}
我们将使用“users”表示例,并创建一个名为“analytics”的键空间。
export CQLSH_HOST=<IP of the VM added as rpc_address>
/usr/bin/cqlsh
在 cqlsh 中:
-- Create keyspace (adjust replication for production)
CREATE KEYSPACE analytics WITH replication = {'class':'SimpleStrategy', 'replication_factor':1};
-- Use the keyspace
USE analytics;
-- Create the users table
CREATE TABLE users (
id int PRIMARY KEY,
active boolean,
username text,
);
-- Insert 5 rows
INSERT INTO users (id, active, username) VALUES (1, true, 'd_knuth');
INSERT INTO users (id, active, username) VALUES (2, true, 'sanjay_ghemawat');
INSERT INTO users (id, active, username) VALUES (3, false, 'gracehopper');
INSERT INTO users (id, active, username) VALUES (4, true, 'brian_kernighan');
INSERT INTO users (id, active, username) VALUES (5, true, 'jeff_dean');
INSERT INTO users (id, active, username) VALUES (6, true, 'jaime_levy');
-- Select all users to verify the inserts.
SELECT * from users;
-- Exit cqlsh
EXIT;
保持 SSH 会话处于打开状态,或记下此虚拟机的 IP 地址 (hostname -I)。
后续步骤
接下来,您将设置 Cloud Spanner 实例和数据库。
4. 创建 Spanner 实例(目标)
在 Spanner 中,实例是计算和存储资源的集群,用于托管一个或多个 Spanner 数据库。您至少需要 1 个实例来托管此 Codelab 的 Spanner 数据库。
查看 gcloud SDK 版本
在创建实例之前,请确保 Google Cloud Shell 中的 gcloud SDK 已更新为所需版本(高于 gcloud SDK 531.0.0 的任何版本)。您可以通过运行以下命令找到 gcloud SDK 版本。
$ gcloud version | grep Google
以下是输出示例:
Google Cloud SDK 489.0.0
如果您使用的版本低于所需的 531.0.0 版本(上例中的 489.0.0),则需要运行以下命令来升级 Google Cloud SDK:
sudo apt-get update \
&& sudo apt-get --only-upgrade install google-cloud-cli-anthoscli google-cloud-cli-cloud-run-proxy kubectl google-cloud-cli-skaffold google-cloud-cli-cbt google-cloud-cli-docker-credential-gcr google-cloud-cli-spanner-migration-tool google-cloud-cli-cloud-build-local google-cloud-cli-pubsub-emulator google-cloud-cli-app-engine-python google-cloud-cli-kpt google-cloud-cli-bigtable-emulator google-cloud-cli-datastore-emulator google-cloud-cli-spanner-emulator google-cloud-cli-app-engine-go google-cloud-cli-app-engine-python-extras google-cloud-cli-config-connector google-cloud-cli-package-go-module google-cloud-cli-istioctl google-cloud-cli-anthos-auth google-cloud-cli-gke-gcloud-auth-plugin google-cloud-cli-app-engine-grpc google-cloud-cli-kubectl-oidc google-cloud-cli-terraform-tools google-cloud-cli-nomos google-cloud-cli-local-extract google-cloud-cli-firestore-emulator google-cloud-cli-harbourbridge google-cloud-cli-log-streaming google-cloud-cli-minikube google-cloud-cli-app-engine-java google-cloud-cli-enterprise-certificate-proxy google-cloud-cli
启用 Spanner API
在 Cloud Shell 中,确保项目 ID 已设置。使用以下第一条命令查找当前配置的项目 ID。如果结果与预期不符,请运行下面的第二个命令来设置正确的结果。
gcloud config get-value project
gcloud config set project [YOUR-DESIRED-PROJECT-ID]
将默认区域配置为 us-central1。您可以随意将此区域更改为 Spanner 区域配置支持的其他区域。
gcloud config set compute/region us-central1
启用 Spanner API:
gcloud services enable spanner.googleapis.com
创建 Spanner 实例
在本部分中,您将创建免费试用实例或预配实例。在本 Codelab 中,使用的 Spanner Cassandra 适配器实例 ID 为 cassandra-adapter-demo,通过 export 命令行将其设置为 SPANNER_INSTANCE_ID 变量。您可以选择自己的实例 ID 名称。
创建免费试用 Spanner 实例
任何拥有 Google 账号并在项目中启用了 Cloud Billing 的用户都可以使用 Spanner 90 天免费试用实例。除非您选择将免费试用实例升级为付费实例,否则无需支付费用。免费试用实例支持 Spanner Cassandra 适配器。如果符合条件,请打开 Cloud Shell 并运行以下命令,以创建免费试用实例:
export SPANNER_INSTANCE_ID=cassandra-adapter-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
命令输出:
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Creating instance...done.
5. 将 Cassandra 架构和数据模型迁移到 Spanner
将数据从 Cassandra 数据库迁移到 Spanner 的初始阶段也是关键阶段,需要转换现有的 Cassandra 架构,使其符合 Spanner 的结构和数据类型要求。
为了简化这一复杂的架构迁移流程,您可以使用 Spanner 提供的两款实用开源工具中的任意一款:
- Spanner 迁移工具:此工具可帮助您迁移架构,只需连接到现有的 Cassandra 数据库,然后将架构迁移到 Spanner 即可。此工具可作为
gcloud cli的一部分提供。 - Spanner Cassandra 架构工具:此工具可帮助您将从 Cassandra 导出的 DDL 转换为 Spanner。您可以使用这两种工具中的任一种来完成本 Codelab。在此 Codelab 中,我们将使用 Spanner 迁移工具迁移架构。
Spanner 迁移工具
Spanner 迁移工具可帮助您从各种数据源(例如 MySQL、Postgres、Cassandra 等)迁移架构。
虽然出于本 Codelab 的目的,我们将使用此工具的 CLI,但我们强烈建议您探索并使用此工具的基于界面的版本,该版本还可以帮助您在应用 Spanner 架构之前对其进行修改。
请注意,如果在 Cloud Shell 上运行 spanner-migration-tool,则可能无法访问 Cassandra 虚拟机的内部 IP 地址。因此,我们建议在安装了 Cassandra 的虚拟机上运行相同的命令。
在安装了 Cassandra 的虚拟机上执行以下命令。
安装 Spanner 迁移工具
sudo apt-get update
sudo apt-get install --upgrade google-cloud-sdk-spanner-migration-tool
如果您在安装过程中遇到任何问题,请参阅 installing-spanner-migration-tool,了解详细步骤。
刷新 Gcloud 凭据
gcloud auth login
gcloud auth application-default login
迁移架构
export CASSANDRA_HOST=`<ip address of the VM used as rpc_address above>`
export PROJECT=`<PROJECT_ID>`
gcloud alpha spanner migrate schema \
--source=cassandra \
--source-profile="host=${CASSANDRA_HOST},user=cassandra,password=cassandra,port=9042,keyspace=analytics,datacenter=datacenter1" \
--target-profile="project=${PROJECT},instance=cassandra-adapter-demo,dbName=analytics" \
--project=${PROJECT}
验证 Spanner DDL
gcloud spanner databases ddl describe analytics --instance=cassandra-adapter-demo
在架构迁移结束时,此命令的输出应为:
CREATE TABLE users (
active BOOL OPTIONS (
cassandra_type = 'boolean'
),
id INT64 NOT NULL OPTIONS (
cassandra_type = 'int'
),
username STRING(MAX) OPTIONS (
cassandra_type = 'text'
),
) PRIMARY KEY(id);
(可选)查看转换后的 DDL
您可以查看转换后的 DDL,并在 Spanner 上重新应用它(如果需要进行其他更改)
cat `ls -t cassandra_*schema.ddl.txt | head -n 1`
此命令的输出将为
CREATE TABLE `users` (
`active` BOOL OPTIONS (cassandra_type = 'boolean'),
`id` INT64 NOT NULL OPTIONS (cassandra_type = 'int'),
`username` STRING(MAX) OPTIONS (cassandra_type = 'text'),
) PRIMARY KEY (`id`)
(可选)查看转化报告
cat `ls -t cassandra_*report.txt | head -n 1`
转化报告会突出显示您应注意的问题。例如,如果源与 Spanner 之间存在列的最大精度不匹配的情况,系统会在此处突出显示。
6. 批量导出历史数据
如需执行批量迁移,您必须:
- 预配或重复使用现有的 GCS 存储分区。
- 将 Cassandra 驱动程序配置文件上传到存储分区
- 启动批量迁移。
虽然您可以从 Cloud Shell 或新配置的虚拟机启动批量迁移,但我们建议您在此 Codelab 中使用虚拟机,因为创建配置文件等一些步骤会将文件保留在本地存储空间中。
预配 GCS 存储分区。
完成此步骤后,您应该已预配一个 GCS 存储分区,并已将该存储分区的路径导出到名为 CASSANDRA_BUCKET_NAME 的变量中。如果您想重复使用现有存储分区,只需导出路径即可继续操作。
if [ -z ${CASSANDRA_BUCKET_NAME} ]; then
export CASSANDRA_BUCKET_NAME="gs://cassandra-demo-$(date +%Y-%m-%d-%H-%M-%S)-$(head /dev/urandom | tr -dc a-z | head -c 20)"
gcloud storage buckets create "${CASSANDRA_BUCKET_NAME}"
else
echo "using existing bucket ${CASSANDRA_BUCKET_NAME}"
fi
创建并上传驱动程序配置文件
在此处,我们上传一个非常基本的 Cassandra 驱动程序配置文件。如需了解文件的完整格式,请参阅此处。
# Configuration for the Cassandra instance and GCS bucket
INSTANCE_NAME="cassandra-origin"
ZONE="us-central1-a"
CASSANDRA_PORT="9042"
# Retrieve the internal IP address of the Cassandra instance
CASSANDRA_IP=$(gcloud compute instances describe "${INSTANCE_NAME}" \
--format="get(networkInterfaces[0].networkIP)" \
--zone="${ZONE}")
# Check if the IP was successfully retrieved
if [[ -z "${CASSANDRA_IP}" ]]; then
echo "Error: Could not retrieve Cassandra instance IP."
exit 1
fi
# Define the full contact point
CONTACT_POINT="${CASSANDRA_IP}:${CASSANDRA_PORT}"
# Create a temporary file with the specified content
TMP_FILE=$(mktemp)
cat <<EOF > "${TMP_FILE}"
# Reference configuration for the DataStax Java driver for Apache Cassandra®.
# This file is in HOCON format, see https://github.com/typesafehub/config/blob/master/HOCON.md.
datastax-java-driver {
basic.contact-points = ["${CONTACT_POINT}"]
basic.session-keyspace = analytics
basic.load-balancing-policy.local-datacenter = datacenter1
advanced.auth-provider {
class = PlainTextAuthProvider
username = cassandra
password = cassandra
}
}
EOF
# Upload the temporary file to the specified GCS bucket
if gsutil cp "${TMP_FILE}" "${CASSANDRA_BUCKET_NAME}/cassandra.conf"; then
echo "Successfully uploaded ${TMP_FILE} to ${CASSANDRA_BUCKET_NAME}/cassandra.conf"
# Concatenate (cat) the uploaded file from GCS
echo "Displaying the content of the uploaded file:"
gsutil cat "${CASSANDRA_BUCKET_NAME}/cassandra.conf"
else
echo "Error: Failed to upload file to GCS."
fi
# Clean up the temporary file
rm "${TMP_FILE}"
运行批量迁移
以下是将数据批量迁移到 Spanner 的示例命令。对于实际生产用例,您需要根据所需的规模和吞吐量调整机器类型和数量。如需查看完整的选项列表,请访问 README_Sourcedb_to_Spanner.md#cassandra-to-spanner-bulk-migration。
gcloud dataflow flex-template run "sourcedb-to-spanner-flex-job" \
--project "`gcloud config get-value project`" \
--region "us-central1" \
--max-workers "2" \
--num-workers "1" \
--worker-machine-type "e2-standard-8" \
--template-file-gcs-location "gs://dataflow-templates-us-central1/latest/flex/Sourcedb_to_Spanner_Flex" \
--additional-experiments="[\"disable_runner_v2\"]" \
--parameters "sourceDbDialect=CASSANDRA" \
--parameters "insertOnlyModeForSpannerMutations=true" \
--parameters "sourceConfigURL=$CASSANDRA_BUCKET_NAME/cassandra.conf" \
--parameters "instanceId=cassandra-adapter-demo" \
--parameters "databaseId=analytics" \
--parameters "projectId=`gcloud config get-value project`" \
--parameters "outputDirectory=$CASSANDRA_BUCKET_NAME/output" \
--parameters "batchSizeForSpannerMutations=1"
这将生成如下所示的输出。记下生成的 id,并使用该 ID 查询 Dataflow 作业的状态。
job: createTime: '2025-08-08T09:41:09.820267Z' currentStateTime: '1970-01-01T00:00:00Z' id: 2025-08-08_02_41_09-17637291823018196600 location: us-central1 name: sourcedb-to-spanner-flex-job projectId: span-cloud-ck-testing-external startTime: '2025-08-08T09:41:09.820267Z'
运行以下命令检查作业的状态,并等待状态变为 JOB_STATE_DONE。
gcloud dataflow jobs describe --region=us-central1 <dataflow job id> | grep "currentState:"
最初,作业将处于排队状态,例如
currentState: JOB_STATE_QUEUED
在作业排队/运行期间,我们强烈建议您在 Cloud 控制台界面中探索 Dataflow/Jobs 页面,以监控作业。
完成后,作业的状态将更改为:
currentState: JOB_STATE_DONE
7. 将应用指向 Spanner(割接)
在迁移阶段结束后,请仔细验证数据的准确性和完整性,然后将应用的运营重心从旧版 Cassandra 系统转移到新填充的 Spanner 数据库。这一关键过渡期通常称为“割接”。
割接阶段标志着实时应用流量从原始 Cassandra 集群重定向到强大且可扩容的 Spanner 基础架构的时刻。此过渡演示了应用可以轻松利用 Spanner 的强大功能,尤其是在使用 Spanner Cassandra 接口时。
借助 Spanner Cassandra 接口,切换过程得以简化。主要涉及配置客户端应用,以利用原生 Spanner Cassandra 客户端进行所有数据交互。您的应用将不再与 Cassandra(源)数据库通信,而是会无缝开始直接从 Spanner(目标)读取和写入数据。这种连接方式的根本转变通常是通过使用 SpannerCqlSessionBuilder 实现的,它是 Spanner Cassandra 客户端库的关键组件,可帮助您建立与 Spanner 实例的连接。这会有效地将应用的整个数据流量重新路由到 Spanner。
对于已使用 cassandra-java-driver 库的 Java 应用,集成 Spanner Cassandra Java 客户端只需对 CqlSession 初始化进行少量更改。
获取 google-cloud-spanner-cassandra 依赖项
如需开始使用 Spanner Cassandra 客户端,您首先需要将它的依赖项纳入您的项目。google-cloud-spanner-cassandra 工件已发布到 Maven Central,位于组 ID com.google.cloud 下。在 Java 项目中现有 <dependencies> 部分下添加以下新依赖项。以下是一个简化示例,展示了如何添加 google-cloud-spanner-cassandra 依赖项:
<!-- native Spanner Cassandra Client -->
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner-cassandra</artifactId>
<version>0.2.0</version>
</dependency>
</dependencies>
更改连接配置以连接到 Spanner
添加必要的依赖项后,下一步是更改连接配置以连接到 Spanner 数据库。
与 Cassandra 集群交互的典型应用通常会使用类似以下代码来建立连接:
CqlSession session = CqlSession.builder()
.addContactPoint(new InetSocketAddress("127.0.0.1", 9042))
.withLocalDatacenter("datacenter1")
.withAuthCredentials("username", "password")
.build();
如需将此连接重定向到 Spanner,您需要修改 CqlSession 创建逻辑。您将使用 Spanner Cassandra 客户端提供的 SpannerCqlSession.builder(),而不是直接使用 cassandra-java-driver 中的标准 CqlSessionBuilder。以下示例说明了如何修改连接代码:
String databaseUri = "projects/<your-gcp-project>/instances/<your-spanner-instance>/databases/<your-spanner-database>";
CqlSession session = SpannerCqlSession.builder()
.setDatabaseUri(databaseUri)
.addContactPoint(new InetSocketAddress("localhost", 9042))
.withLocalDatacenter("datacenter1")
.build();
通过使用 SpannerCqlSession.builder() 实例化 CqlSession 并提供正确的 databaseUri,您的应用现在将通过 Spanner Cassandra 客户端与目标 Spanner 数据库建立连接。这项关键变更可确保您的应用执行的所有后续读写操作都将定向到 Spanner 并由 Spanner 提供服务,从而有效完成初始割接。此时,您的应用应继续按预期运行,现在由 Spanner 的可伸缩性和可靠性提供支持。
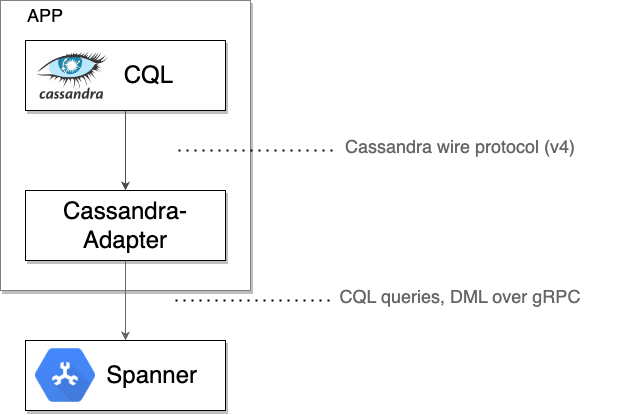
幕后花絮:Spanner Cassandra 客户端的运作方式
Spanner Cassandra 客户端充当本地 TCP 代理,拦截驱动程序或客户端工具发送的原始 Cassandra 协议字节。然后,它将这些字节与必要的元数据一起封装到 gRPC 消息中,以便与 Spanner 进行通信。来自 Spanner 的响应会转换回 Cassandra 线格式,并发送回原始驱动程序或工具。
确信 Spanner 能够正确处理所有流量后,您最终可以:
- 停用原始 Cassandra 集群。
8. 清理(可选)
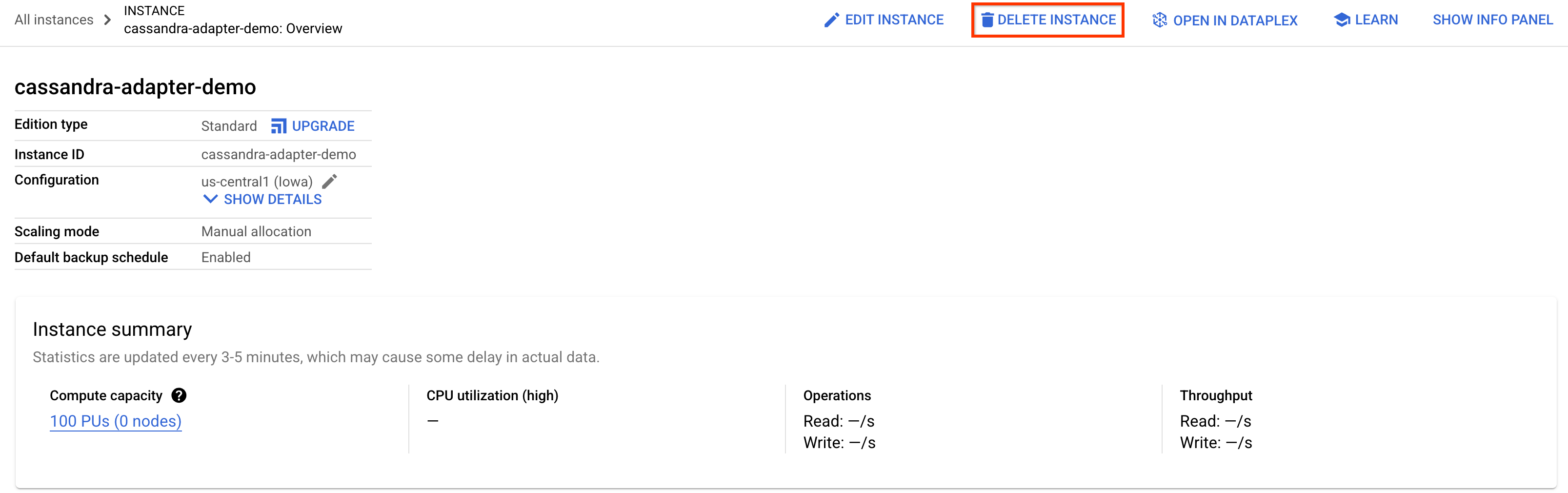
如需清理,只需前往 Cloud 控制台的 Spanner 部分,然后删除我们在 Codelab 中创建的 cassandra-adapter-demo 实例即可。
删除 Cassandra 数据库(如果已在本地安装或持久存在)
如果您在通过此处创建的 Compute Engine 虚拟机之外安装了 Cassandra,请按照相应步骤移除数据或卸载 Cassandra。
9. 恭喜!
接下来怎么做?
- 详细了解 Spanner。
- 详细了解 Cassandra 接口。