
1. Pengantar
Spanner adalah layanan database terkelola sepenuhnya, skalabel secara horizontal, dan didistribusikan secara global yang sangat cocok untuk workload operasional relasional dan non-relasional.
Spanner memiliki dukungan penelusuran vektor bawaan, yang memungkinkan Anda melakukan penelusuran kesamaan atau semantik dan menerapkan retrieval augmented generation (RAG) dalam aplikasi GenAI dalam skala besar, dengan memanfaatkan fitur K-nearest neighbor yang tepat (KNN) atau perkiraan tetangga terdekat (ANN).
Kueri penelusuran vektor Spanner menampilkan data real-time baru segera setelah transaksi dilakukan, seperti kueri lainnya pada data operasional Anda.
Di lab ini, Anda akan mempelajari cara menyiapkan fitur dasar yang diperlukan untuk memanfaatkan Spanner dalam melakukan penelusuran vektor, serta mengakses model embedding dan LLM dari model garden Vertex AI menggunakan SQL.
Arsitekturnya akan terlihat seperti ini:
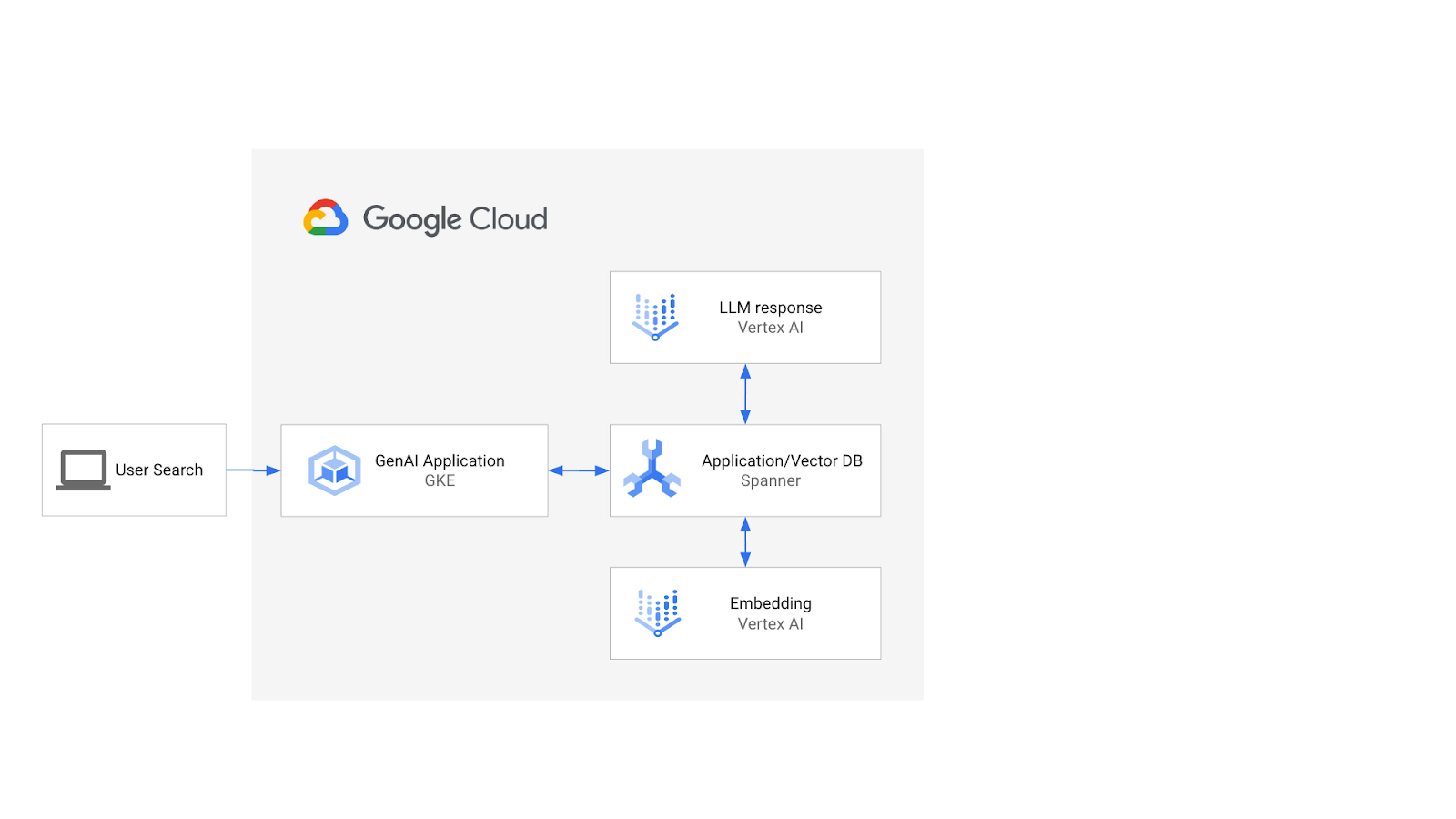
Dengan dasar tersebut, Anda akan mempelajari cara membuat indeks vektor yang didukung oleh algoritma ScaNN, dan menggunakan fungsi jarak APPROX saat beban kerja semantik Anda perlu diskalakan.
Yang akan Anda build
Sebagai bagian dari lab ini, Anda akan:
- Membuat instance Spanner
- Menyiapkan skema database Spanner untuk berintegrasi dengan model embedding dan LLM di Vertex AI
- Memuat set data retail
- Mengirimkan kueri penelusuran kemiripan terhadap set data
- Memberikan konteks ke model LLM untuk menghasilkan rekomendasi khusus produk.
- Ubah skema dan buat indeks vektor.
- Ubah kueri untuk memanfaatkan indeks vektor yang baru dibuat.
Yang akan Anda pelajari
- Cara menyiapkan instance Spanner
- Cara berintegrasi dengan VertexAI
- Cara menggunakan Spanner untuk melakukan penelusuran vektor guna menemukan item serupa dalam set data retail
- Cara menyiapkan database untuk menskalakan workload penelusuran vektor menggunakan penelusuran ANN.
Yang Anda butuhkan
2. Penyiapan dan persyaratan
Membuat project
Jika belum memiliki Akun Google (Gmail atau Google Apps), Anda harus membuatnya. Login ke Konsol Google Cloud Platform ( console.cloud.google.com) dan buat project baru.
Jika Anda sudah memiliki project, klik menu pull-down pilihan project di kiri atas konsol:

dan klik tombol 'PROJECT BARU' dalam dialog yang dihasilkan untuk membuat project baru:
Jika belum memiliki project, Anda akan melihat dialog seperti ini untuk membuat project pertama:
Dialog pembuatan project berikutnya memungkinkan Anda memasukkan detail project baru:
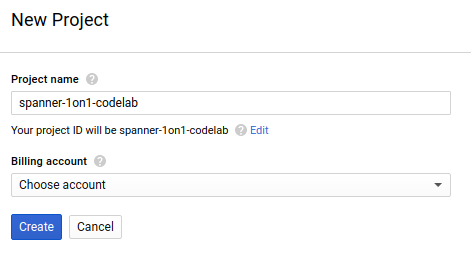
Ingat project ID yang merupakan nama unik di semua project Google Cloud (maaf, nama di atas telah digunakan dan tidak akan berfungsi untuk Anda!) Project ID tersebut selanjutnya akan dirujuk di codelab ini sebagai PROJECT_ID.
Selanjutnya, jika Anda belum melakukannya, Anda harus mengaktifkan penagihan di Developers Console untuk menggunakan resource Google Cloud dan mengaktifkan Spanner API.
Menjalankan melalui codelab ini tidak akan menghabiskan biaya lebih dari beberapa dolar, tetapi bisa lebih jika Anda memutuskan untuk menggunakan lebih banyak resource atau jika Anda membiarkannya berjalan (lihat bagian "pembersihan" di akhir dokumen ini). Harga Google Cloud Spanner didokumentasikan di sini.
Pengguna baru Google Cloud Platform memenuhi syarat untuk mendapatkan uji coba gratis senilai $300, yang menjadikan codelab ini sepenuhnya gratis.
Penyiapan Google Cloud Shell
Meskipun Google Cloud dan Spanner dapat dioperasikan dari jarak jauh menggunakan laptop Anda, dalam codelab ini, kita akan menggunakan Google Cloud Shell, lingkungan command line yang berjalan di Cloud.
Mesin virtual berbasis Debian ini memuat semua alat pengembangan yang akan Anda perlukan. Layanan ini menawarkan direktori beranda tetap sebesar 5 GB dan beroperasi di Google Cloud, sehingga sangat meningkatkan performa dan autentikasi jaringan. Ini berarti bahwa semua yang Anda perlukan untuk codelab ini adalah browser (ya, ini berfungsi di Chromebook).
- Untuk mengaktifkan Cloud Shell dari Cloud Console, cukup klik Aktifkan Cloud Shell
 (hanya perlu beberapa saat untuk melakukan penyediaan dan terhubung ke lingkungan).
(hanya perlu beberapa saat untuk melakukan penyediaan dan terhubung ke lingkungan).
Setelah terhubung ke Cloud Shell, Anda akan melihat bahwa Anda sudah diautentikasi dan project sudah ditetapkan ke PROJECT_ID Anda.
gcloud auth list
Output perintah
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
Output perintah
[core]
project = <PROJECT_ID>
Jika, untuk beberapa alasan, project belum disetel, cukup jalankan perintah berikut:
gcloud config set project <PROJECT_ID>
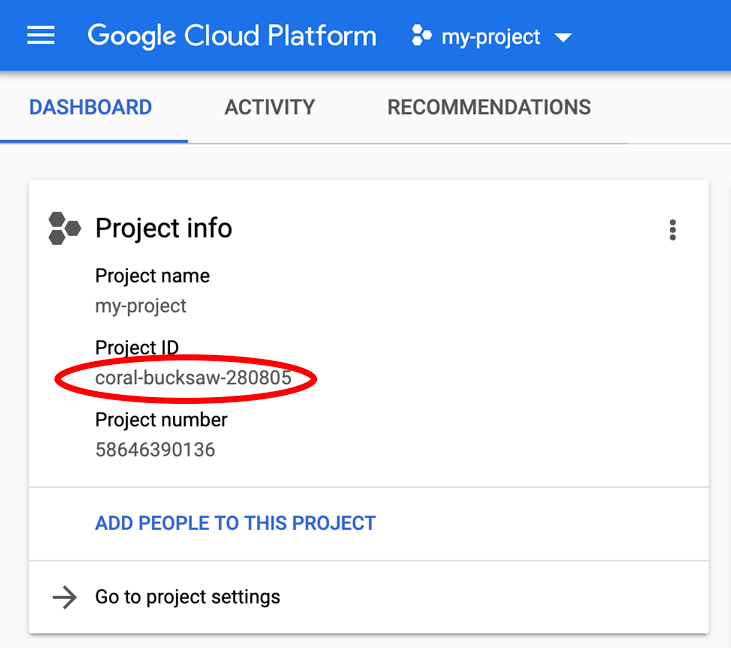
Mencari PROJECT_ID Anda? Periksa ID yang Anda gunakan di langkah-langkah penyiapan atau cari di dasbor Cloud Console:
Cloud Shell juga menetapkan beberapa variabel lingkungan secara default, yang mungkin berguna saat Anda menjalankan perintah di masa mendatang.
echo $GOOGLE_CLOUD_PROJECT
Output perintah
<PROJECT_ID>
Aktifkan Spanner API
gcloud services enable spanner.googleapis.com
Ringkasan
Pada langkah ini, Anda telah menyiapkan project jika belum memilikinya, mengaktifkan cloud shell, dan mengaktifkan API yang diperlukan.
Berikutnya
Selanjutnya, Anda akan menyiapkan instance dan database Spanner.
3. Membuat instance dan database Spanner
Buat instance Spanner
Pada langkah ini, kita menyiapkan Instance Spanner untuk codelab. Untuk melakukannya, buka Cloud Shell dan jalankan perintah ini:
export SPANNER_INSTANCE_ID=retail-demo
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
--edition=ENTERPRISE
Output perintah:
$ gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
--edition=ENTERPRISE
Creating instance...done.
Membuat database
Setelah instance Anda berjalan, Anda dapat membuat database. Spanner memungkinkan beberapa database dalam satu instance.
Database adalah tempat Anda menentukan skema. Anda juga dapat mengontrol siapa yang memiliki akses ke database, menyiapkan enkripsi kustom, mengonfigurasi pengoptimal, dan menetapkan periode retensi.
Untuk membuat database, gunakan lagi alat command line gcloud:
export SPANNER_DATABASE=cymbal-bikes
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Output perintah:
$ gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Creating database...done.
Ringkasan
Pada langkah ini, Anda telah membuat instance dan database Spanner.
Berikutnya
Selanjutnya, Anda akan menyiapkan skema dan data Spanner.
4. Memuat skema dan data Cymbal
Buat skema Cymbal
Untuk menyiapkan skema, buka Spanner Studio:
Ada dua bagian dalam skema. Pertama, Anda harus menambahkan tabel products. Salin dan tempel pernyataan ini di tab kosong.
Untuk skema, salin dan tempel DDL ini ke dalam kotak:
CREATE TABLE products (
categoryId INT64 NOT NULL,
productId INT64 NOT NULL,
productName STRING(MAX) NOT NULL,
productDescription STRING(MAX) NOT NULL,
productDescriptionEmbedding ARRAY<FLOAT32>,
createTime TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
inventoryCount INT64 NOT NULL,
priceInCents INT64,
) PRIMARY KEY(categoryId, productId);
Kemudian, klik tombol run dan tunggu beberapa detik hingga skema Anda dibuat.
Selanjutnya, Anda akan membuat dua model dan mengonfigurasinya ke endpoint model VertexAI.
Model pertama adalah model Embedding yang digunakan untuk membuat embedding dari teks, dan model kedua adalah model LLM yang digunakan untuk membuat respons berdasarkan data di Spanner.
Tempel skema berikut ke tab baru di Spanner Studio:
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-004'
);
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-pro',
default_batch_size = 1
);
Kemudian, klik tombol run dan tunggu beberapa detik hingga model Anda dibuat.
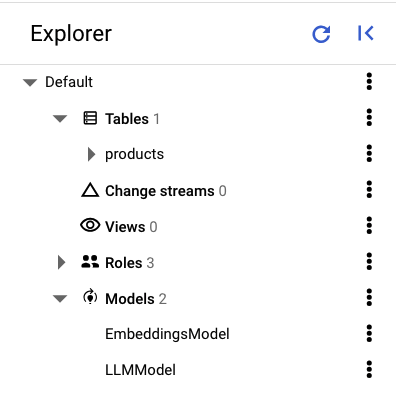
Di panel kiri Spanner Studio, Anda akan melihat tabel dan model berikut:
Memuat data
Sekarang, Anda akan ingin memasukkan beberapa produk ke dalam database. Buka tab baru di Spanner Studio, lalu salin dan tempel pernyataan penyisipan berikut:
INSERT INTO products (categoryId, productId, productName, productDescription, createTime, inventoryCount, priceInCents)
VALUES (1, 1, "Cymbal Helios Helmet", "Safety meets style with the Cymbal children's bike helmet. Its lightweight design, superior ventilation, and adjustable fit ensure comfort and protection on every ride. Stay bright and keep your child safe under the sun with Cymbal Helios!", PENDING_COMMIT_TIMESTAMP(), 100, 10999),
(1, 2, "Cymbal Sprout", "Let their cycling journey begin with the Cymbal Sprout, the ideal balance bike for beginning riders ages 2-4 years. Its lightweight frame, low seat height, and puncture-proof tires promote stability and confidence as little ones learn to balance and steer. Watch them sprout into cycling enthusiasts with Cymbal Sprout!", PENDING_COMMIT_TIMESTAMP(), 10, 13999),
(1, 3, "Cymbal Spark Jr.", "Light, vibrant, and ready for adventure, the Spark Jr. is the perfect first bike for young riders (ages 5-8). Its sturdy frame, easy-to-use brakes, and puncture-resistant tires inspire confidence and endless playtime. Let the spark of cycling ignite with Cymbal!", PENDING_COMMIT_TIMESTAMP(), 34, 13900),
(1, 4, "Cymbal Summit", "Conquering trails is a breeze with the Summit mountain bike. Its lightweight aluminum frame, responsive suspension, and powerful disc brakes provide exceptional control and comfort for experienced bikers navigating rocky climbs or shredding downhill. Reach new heights with Cymbal Summit!", PENDING_COMMIT_TIMESTAMP(), 0, 79999),
(1, 5, "Cymbal Breeze", "Cruise in style and embrace effortless pedaling with the Breeze electric bike. Its whisper-quiet motor and long-lasting battery let you conquer hills and distances with ease. Enjoy scenic rides, commutes, or errands with a boost of confidence from Cymbal Breeze!", PENDING_COMMIT_TIMESTAMP(), 72, 129999),
(1, 6, "Cymbal Trailblazer Backpack", "Carry all your essentials in style with the Trailblazer backpack. Its water-resistant material, multiple compartments, and comfortable straps keep your gear organized and accessible, allowing you to focus on the adventure. Blaze new trails with Cymbal Trailblazer!", PENDING_COMMIT_TIMESTAMP(), 24, 7999),
(1, 7, "Cymbal Phoenix Lights", "See and be seen with the Phoenix bike lights. Powerful LEDs and multiple light modes ensure superior visibility, enhancing your safety and enjoyment during day or night rides. Light up your journey with Cymbal Phoenix!", PENDING_COMMIT_TIMESTAMP(), 87, 3999),
(1, 8, "Cymbal Windstar Pump", "Flat tires are no match for the Windstar pump. Its compact design, lightweight construction, and high-pressure capacity make inflating tires quick and effortless. Get back on the road in no time with Cymbal Windstar!", PENDING_COMMIT_TIMESTAMP(), 36, 24999),
(1, 9,"Cymbal Odyssey Multi-Tool","Be prepared for anything with the Odyssey multi-tool. This handy gadget features essential tools like screwdrivers, hex wrenches, and tire levers, keeping you ready for minor repairs and adjustments on the go. Conquer your journey with Cymbal Odyssey!", PENDING_COMMIT_TIMESTAMP(), 52, 999),
(1, 10,"Cymbal Nomad Water Bottle","Stay hydrated on every ride with the Nomad water bottle. Its sleek design, BPA-free construction, and secure lock lid make it the perfect companion for staying refreshed and motivated throughout your adventures. Hydrate and explore with Cymbal Nomad!", PENDING_COMMIT_TIMESTAMP(), 42, 1299);
Klik tombol run untuk menyisipkan data.
Ringkasan
Pada langkah ini, Anda telah membuat skema dan memuat beberapa data dasar ke dalam database cymbal-bikes.
Berikutnya
Selanjutnya, Anda akan berintegrasi dengan model Embedding untuk membuat embedding bagi deskripsi produk, serta mengonversi permintaan penelusuran tekstual menjadi embedding untuk menelusuri produk yang relevan.
5. Menggunakan embedding
Membuat embedding vektor untuk deskripsi produk
Agar penelusuran kesamaan berfungsi pada produk, Anda perlu membuat embedding untuk deskripsi produk.
Dengan EmbeddingsModel yang dibuat dalam skema, ini adalah pernyataan DML UPDATE sederhana.
UPDATE products p1
SET productDescriptionEmbedding =
(SELECT embeddings.values from ML.PREDICT(MODEL EmbeddingsModel,
(SELECT productDescription as content FROM products p2 where p2.productId=p1.productId)))
WHERE categoryId=1;
Klik tombol run untuk memperbarui deskripsi produk.
Menggunakan penelusuran vektor
Dalam contoh ini, Anda akan memberikan permintaan penelusuran bahasa alami melalui kueri SQL. Kueri ini akan mengubah permintaan penelusuran menjadi embedding, lalu menelusuri hasil serupa berdasarkan embedding deskripsi produk tersimpan yang dibuat pada langkah sebelumnya.
-- Use Spanner's vector search, and integration with embedding and LLM models to
-- return items that are semantically relevant and available in inventory based on
-- real-time data.
SELECT productName, productDescription, inventoryCount, COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) as distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
Klik tombol run untuk menemukan produk serupa. Hasilnya akan terlihat seperti ini:
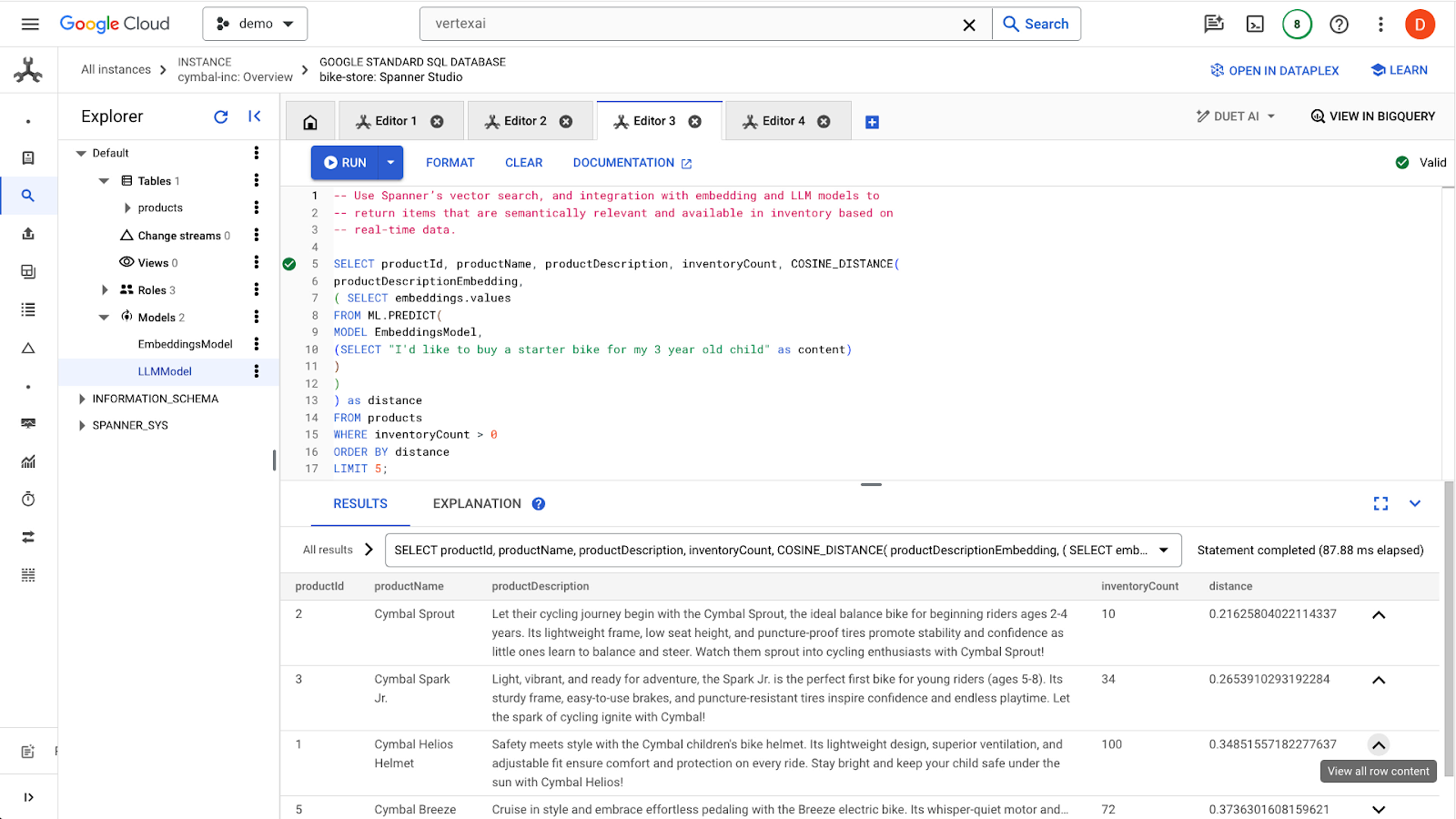
Perhatikan bahwa filter tambahan digunakan pada kueri, seperti hanya tertarik pada produk yang tersedia (inventoryCount > 0).
Ringkasan
Pada langkah ini, Anda membuat embedding deskripsi produk dan embedding permintaan penelusuran menggunakan SQL, dengan memanfaatkan integrasi Spanner dengan model di Vertex AI. Anda juga melakukan penelusuran vektor untuk menemukan produk serupa yang cocok dengan permintaan penelusuran.
Langkah Berikutnya
Selanjutnya, kita akan menggunakan hasil penelusuran untuk memasukkan data ke LLM guna menghasilkan respons khusus untuk setiap produk.
6. Bekerja dengan LLM
Spanner memudahkan integrasi dengan model LLM yang disajikan dari Vertex AI. Hal ini memungkinkan developer menggunakan SQL untuk berinteraksi langsung dengan LLM, bukan mengharuskan aplikasi melakukan logika.
Misalnya, kita memiliki hasil dari kueri SQL sebelumnya dari pengguna "I'd like to buy a starter bike for my 3 year old child".
Developer ingin memberikan respons untuk setiap hasil tentang apakah produk cocok untuk pengguna, menggunakan perintah berikut:
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me? I'd like to buy a starter bike for my 3 year old child"
Berikut kueri yang dapat Anda gunakan:
-- Use an LLM to analyze this list and provide a recommendation on whether each
-- product is a good fit for the user. We use the vector search and real time
-- inventory data to first filter the products to reduce the size of the prompt to
-- the LLM.
SELECT productName, productDescription, inventoryCount, content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
( SELECT
inventoryCount,
productName,
productDescription,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a starter bike for my 3 year old child \n",
"Product Name: ", productName, "\n",
"Product Description:", productDescription) AS prompt,
FROM products
WHERE inventoryCount > 0
ORDER by COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
( SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) LIMIT 5
),
STRUCT(256 AS maxOutputTokens)
);
Klik tombol run untuk mengeluarkan kueri. Hasilnya akan terlihat seperti ini:
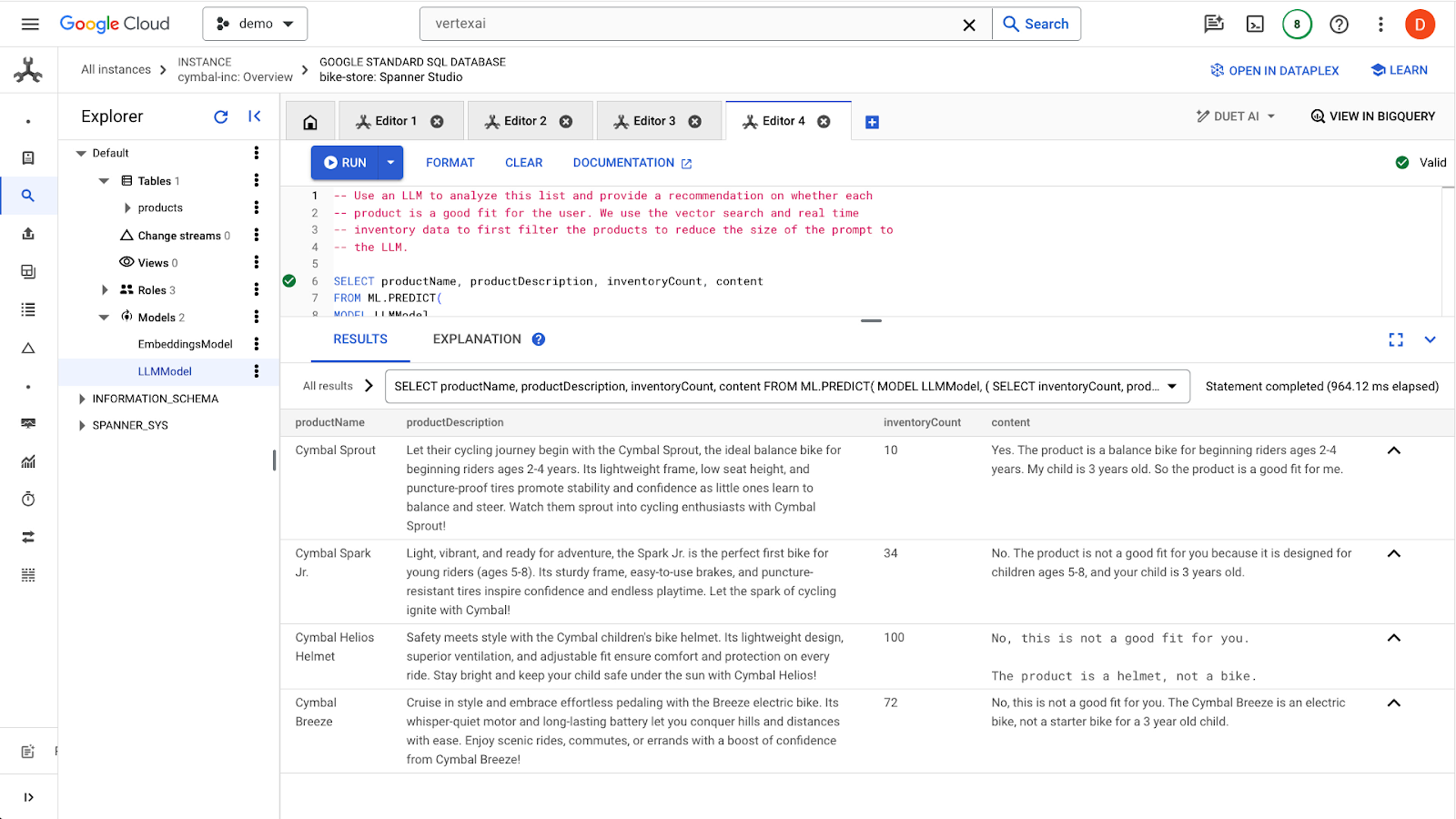
Produk pertama cocok untuk anak berusia 3 tahun karena rentang usia dalam deskripsi produk (anak berusia 2-4 tahun). Produk lainnya tidak cocok.
Ringkasan
Pada langkah ini, Anda telah bekerja dengan LLM untuk menghasilkan respons dasar terhadap perintah dari pengguna.
Langkah Berikutnya
Selanjutnya, mari pelajari cara menggunakan ANN untuk menskalakan penelusuran vektor.
7. Menskalakan penelusuran vektor
Contoh penelusuran vektor sebelumnya memanfaatkan penelusuran vektor KNN yang tepat. Hal ini sangat berguna jika Anda dapat membuat kueri {i>subset<i} data Spanner yang sangat spesifik. Jenis kueri tersebut dikatakan dapat dipartisi secara tinggi.
Jika tidak memiliki workload yang sangat dapat dipartisi, dan memiliki data dalam jumlah besar, Anda dapat menggunakan penelusuran vektor ANN yang memanfaatkan algoritma ScaNN untuk meningkatkan performa penelusuran.
Untuk melakukannya di Spanner, Anda harus melakukan dua hal:
- Membuat Indeks Vektor
- Ubah kueri Anda untuk menggunakan fungsi jarak APPROX.
Membuat Indeks Vektor
Untuk membuat indeks vektor pada set data ini, kita harus mengubah kolom productDescriptionEmbeddings terlebih dahulu untuk menentukan panjang setiap vektor. Untuk menambahkan panjang vektor ke kolom, Anda harus melepaskan kolom asli dan membuatnya kembali.
ALTER TABLE `products` DROP COLUMN `productDescriptionEmbedding`;
ALTER TABLE
`products` ADD COLUMN `productDescriptionEmbedding` ARRAY<FLOAT32>(vector_length=>768);
Selanjutnya, buat ulang sematan dari langkah Generate Vector embedding yang sebelumnya Anda jalankan.
UPDATE products p1
SET productDescriptionEmbedding =
(SELECT embeddings.values from ML.PREDICT(MODEL EmbeddingsModel,
(SELECT productDescription as content FROM products p2 where p2.productId=p1.productId)))
WHERE categoryId=1;
Setelah kolom dibuat, buat indeks:
CREATE VECTOR INDEX ProductDescriptionEmbeddingIndex
ON products(productDescriptionEmbedding)
WHERE productDescriptionEmbedding IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
Menggunakan indeks baru
Untuk menggunakan indeks vektor baru, Anda harus sedikit mengubah kueri embedding sebelumnya.
Berikut kueri aslinya:
SELECT productName, productDescription, inventoryCount, COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) as distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
Anda harus melakukan perubahan berikut:
- Gunakan petunjuk indeks untuk indeks vektor baru:
@{force_index=ProductDescriptionEmbeddingIndex} - Ubah panggilan fungsi
COSINE_DISTANCEmenjadiAPPROX_COSINE_DISTANCE. Perhatikan bahwa opsi JSON dalam kueri akhir di bawah juga diperlukan. - Buat embedding dari fungsi ML.PREDICT secara terpisah.
- Salin hasil penyematan ke dalam kueri akhir.
Buat embedding
-- Generate the prompt embeddings
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
Tandai hasil dari kueri, lalu salin.
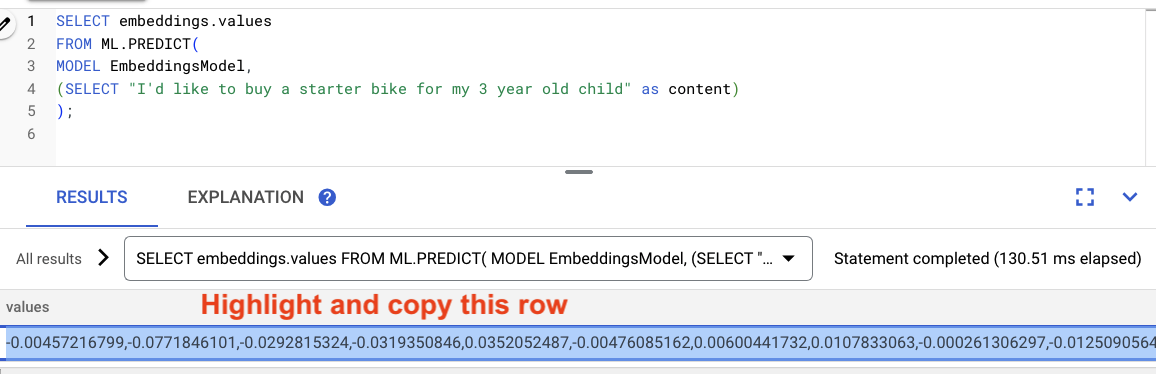
Kemudian, ganti <VECTOR> di kueri berikut dengan menempelkan embedding yang Anda salin.
-- Embedding query now using the vector index
SELECT productName, productDescription, inventoryCount,
APPROX_COSINE_DISTANCE(productDescriptionEmbedding, array<float32>[@VECTOR], options => JSON '{\"num_leaves_to_search\": 10}')
FROM products @{force_index=ProductDescriptionEmbeddingIndex}
WHERE productDescriptionEmbedding IS NOT NULL AND inventoryCount > 0
ORDER BY distance
LIMIT 5;
Ini akan terlihat seperti berikut:
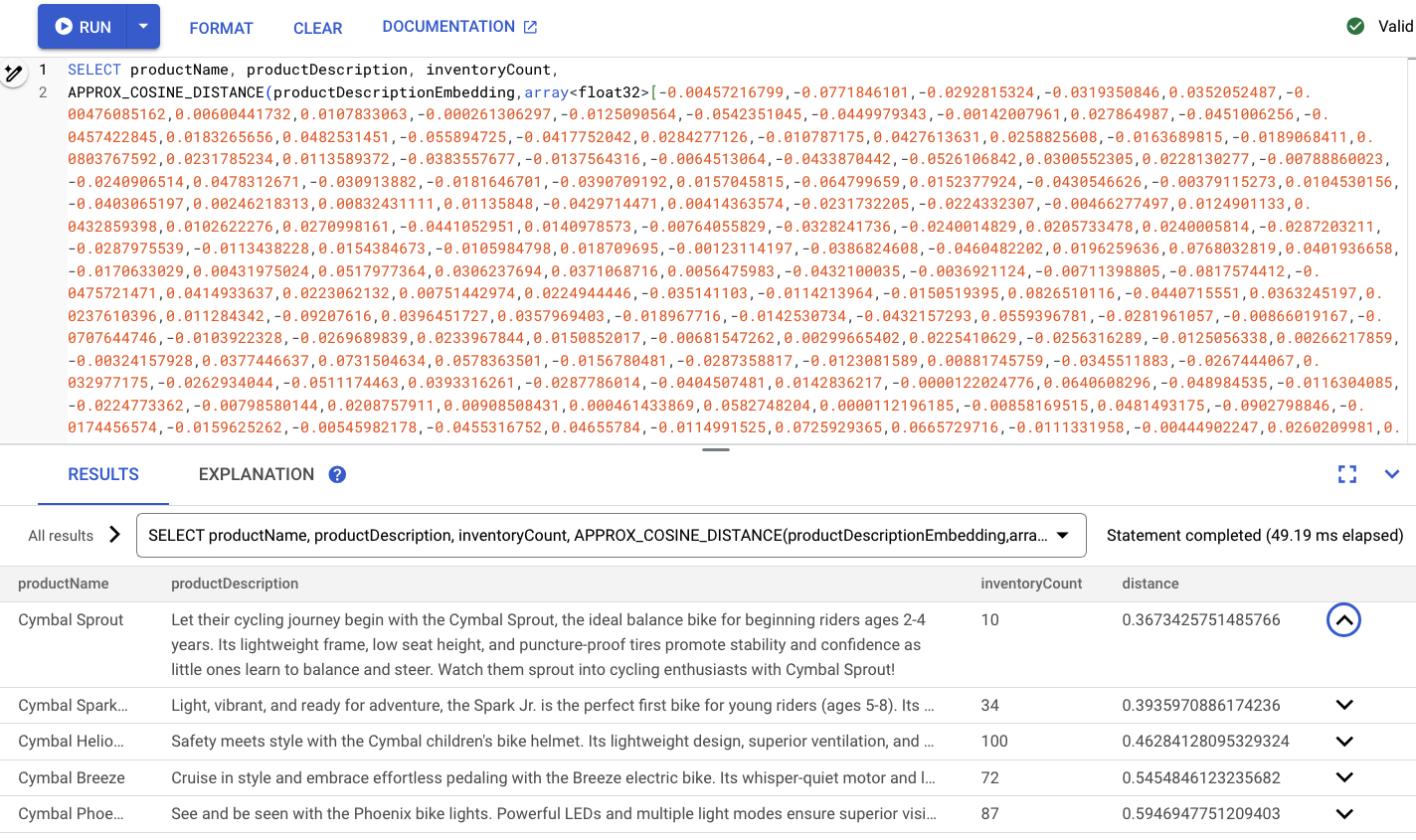
Ringkasan
Pada langkah ini, Anda mengonversi skema untuk membuat indeks vektor. Kemudian, Anda menulis ulang kueri embedding untuk melakukan penelusuran ANN menggunakan indeks vektor. Langkah ini penting seiring pertumbuhan data Anda untuk menskalakan workload penelusuran vektor.
Langkah Berikutnya
Selanjutnya, saatnya membersihkan!
8. Membersihkan (opsional)
Untuk membersihkan, cukup buka bagian Cloud Spanner di Cloud Console dan hapus instance 'retail-demo' yang kita buat di codelab.
9. Selamat!
Selamat, Anda telah berhasil melakukan penelusuran kemiripan menggunakan penelusuran vektor bawaan Spanner. Selain itu, Anda telah melihat betapa mudahnya bekerja dengan model embedding dan LLM untuk menyediakan fungsi AI generatif secara langsung menggunakan SQL.
Terakhir, Anda mempelajari proses untuk melakukan penelusuran ANN yang didukung oleh algoritma ScaNN untuk menskalakan workload penelusuran vektor.
Apa langkah selanjutnya?
Pelajari lebih lanjut fitur tetangga terdekat yang tepat (penelusuran vektor KNN) Spanner di sini: https://cloud.google.com/spanner/docs/find-k-nearest-neighbors
Pelajari lebih lanjut fitur perkiraan tetangga terdekat (penelusuran vektor ANN) Spanner di sini: https://cloud.google.com/spanner/docs/find-approximate-nearest-neighbors
Anda juga dapat membaca lebih lanjut cara melakukan prediksi online dengan SQL menggunakan integrasi VertexAI Spanner di sini: https://cloud.google.com/spanner/docs/ml