
1. Introdução
O Spanner é um serviço de banco de dados totalmente gerenciado, escalonável horizontalmente e distribuído globalmente, ideal para cargas de trabalho operacionais relacionais e não relacionais.
O Spanner tem suporte integrado à pesquisa vetorial, permitindo que você realize pesquisas semânticas ou de similaridade e implemente a geração aumentada de recuperação (RAG, na sigla em inglês) em aplicativos de IA generativa em escala, aproveitando os recursos de vizinho k-mais próximo exato (KNN, na sigla em inglês) ou de vizinho mais próximo aproximado (ANN, na sigla em inglês).
As consultas de pesquisa vetorial do Spanner retornam dados atualizados em tempo real assim que as transações são confirmadas, assim como qualquer outra consulta nos dados operacionais.
Neste laboratório, você vai aprender a configurar os recursos básicos necessários para aproveitar o Spanner para realizar pesquisas vetoriais e acessar modelos de embedding e LLM do Model Garden da Vertex AI usando SQL.
A arquitetura seria assim:
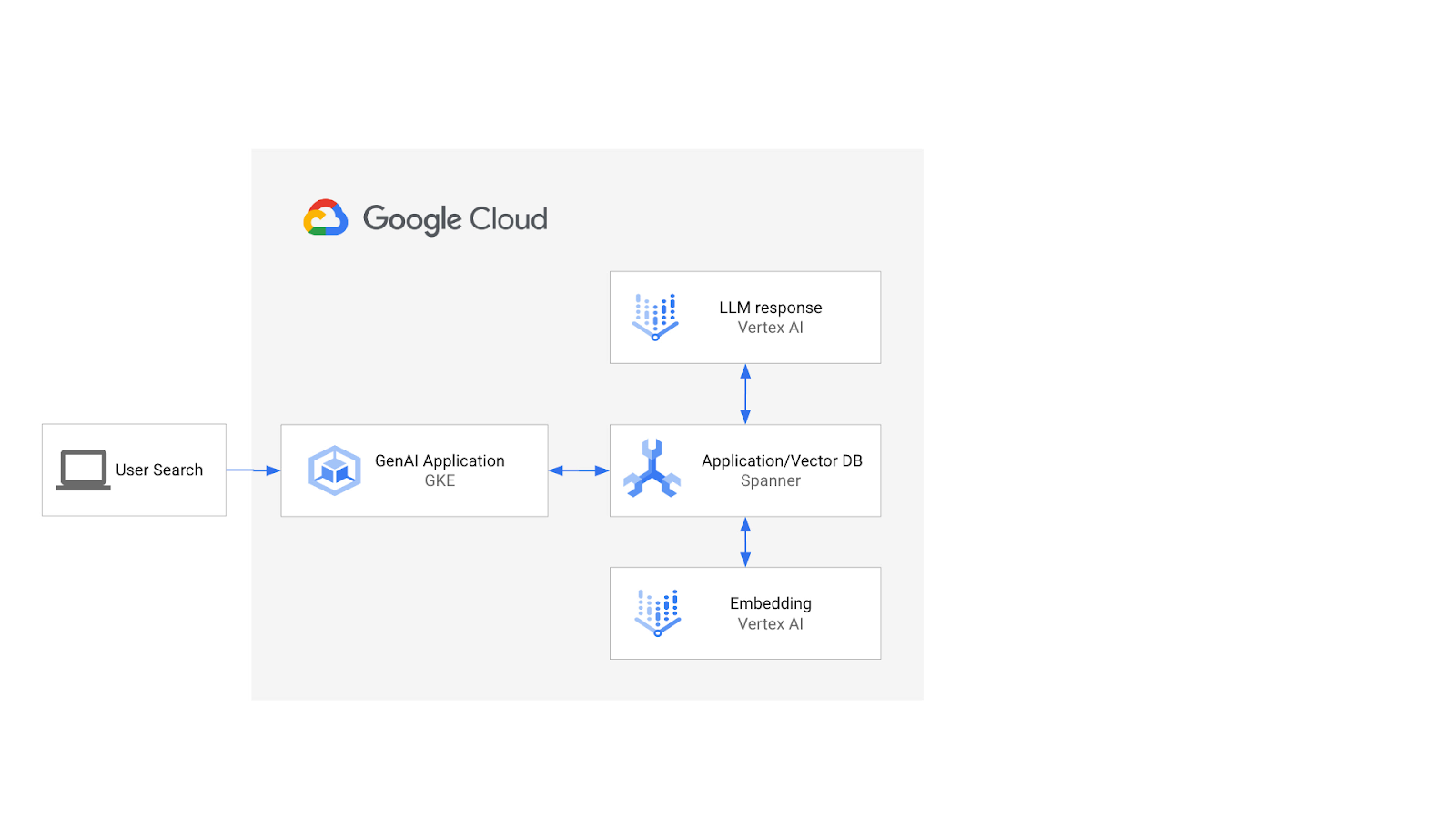
Com essa base, você vai aprender a criar um índice vetorial com o algoritmo ScaNN e usar as funções de distância APPROX quando as cargas de trabalho semânticas precisarem ser escalonadas.
O que você vai criar
Como parte deste laboratório, você vai:
- Criar uma instância do Spanner
- Configurar o esquema de banco de dados do Spanner para integrar com modelos de embedding e LLM na Vertex AI
- Carregar um conjunto de dados de varejo
- Emitir consultas de pesquisa de similaridade no conjunto de dados
- Fornecer contexto ao modelo de LLM para gerar recomendações específicas do produto.
- Modificar o esquema e criar um índice vetorial.
- Alterar as consultas para aproveitar o índice vetorial recém-criado.
O que você vai aprender
- Como configurar uma instância do Spanner
- Como integrar com a Vertex AI
- Como usar o Spanner para realizar pesquisas vetoriais e encontrar itens semelhantes em um conjunto de dados de varejo
- Como preparar seu banco de dados para escalonar cargas de trabalho de pesquisa vetorial usando a pesquisa ANN.
O que é necessário
2. Configuração e requisitos
Criar um projeto
Se você ainda não tem uma Conta do Google (Gmail ou Google Apps), você deve criar uma. Faça login no Console do Google Cloud Platform ( console.cloud.google.com) e crie um novo projeto.
Se você já tiver um projeto, clique no menu suspenso de seleção de projeto no canto superior esquerdo do console:

e clique no botão "NEW PROJECT" na caixa de diálogo exibida para criar um novo projeto:
Se você ainda não tiver um projeto, uma caixa de diálogo como esta será exibida para criar seu primeiro:
A caixa de diálogo de criação de projeto subsequente permite que você insira os detalhes do novo projeto:
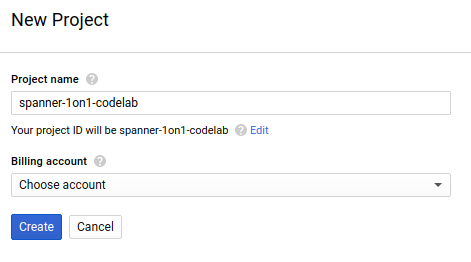
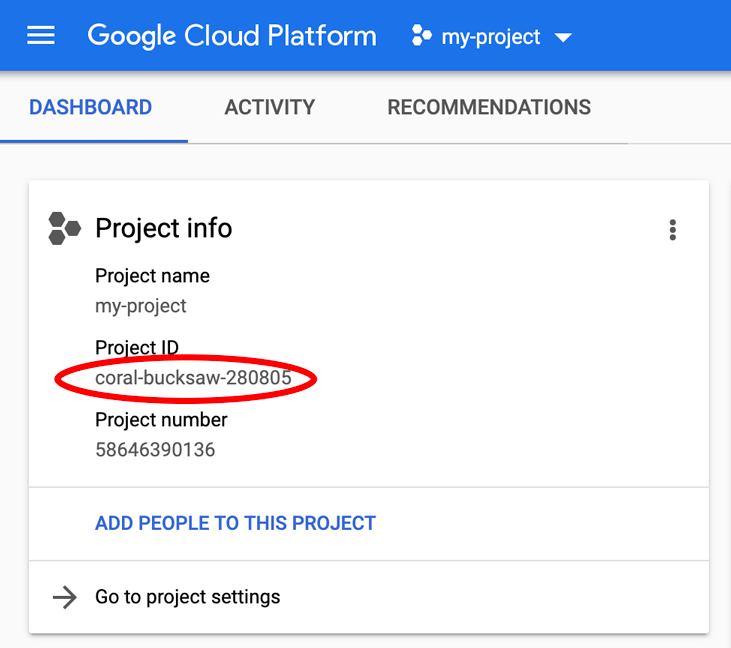
Lembre-se do ID do projeto, um nome exclusivo em todos os projetos do Google Cloud. O nome acima já foi escolhido e não servirá para você. Faremos referência a ele mais adiante neste codelab como PROJECT_ID.
Em seguida, será preciso ativar o faturamento no Developers Console para usar os recursos do Google Cloud e ativar a API Spanner, caso ainda não tenha feito isso.
A execução por meio deste codelab terá um custo baixo, mas poderá ser mais se você decidir usar mais recursos ou se deixá-los em execução. Consulte a seção "limpeza" no final deste documento. Os preços do Google Cloud Spanner estão documentados neste link.
Novos usuários do Google Cloud Platform estão qualificados para uma avaliação sem custo financeiro de US$300, o que torna este codelab totalmente sem custo financeiro.
Configuração do Google Cloud Shell
Embora o Google Cloud e o Spanner possam ser operados remotamente do seu laptop, neste codelab usaremos o Google Cloud Shell, um ambiente de linha de comando executado no Cloud.
O Cloud Shell é uma máquina virtual com base em Debian que contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Isso significa que tudo que você precisa para este codelab é um navegador (sim, funciona em um Chromebook).
- Para ativar o Cloud Shell no Console do Cloud, basta clicar em Ativar o Cloud Shell
 . Leva apenas alguns instantes para provisionar e se conectar ao ambiente.
. Leva apenas alguns instantes para provisionar e se conectar ao ambiente.
Após se conectar ao Cloud Shell, sua conta já está autenticada e o projeto está configurado com seu PROJECT_ID.
gcloud auth list
Resposta ao comando
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
Resposta ao comando
[core]
project = <PROJECT_ID>
Se, por algum motivo, o projeto não estiver definido, basta emitir o seguinte comando:
gcloud config set project <PROJECT_ID>
Quer encontrar seu PROJECT_ID? Veja qual ID você usou nas etapas de configuração ou procure-o no painel do Console do Cloud:
O Cloud Shell também define algumas variáveis de ambiente por padrão, o que pode ser útil ao executar comandos futuros.
echo $GOOGLE_CLOUD_PROJECT
Resposta ao comando
<PROJECT_ID>
Ativar a API Spanner
gcloud services enable spanner.googleapis.com
Resumo
Nesta etapa, você configurou seu projeto, caso ainda não tivesse um, ativou o Cloud Shell e ativou as APIs necessárias.
A seguir
Em seguida, você vai configurar a instância e o banco de dados do Spanner.
3. Criar uma instância e um banco de dados do Spanner
Criar a instância do Spanner
Nesta etapa, configuramos a instância do Spanner para o codelab. Para fazer isso, abra o Cloud Shell e execute este comando:
export SPANNER_INSTANCE_ID=retail-demo
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
--edition=ENTERPRISE
Resposta ao comando:
$ gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
--edition=ENTERPRISE
Creating instance...done.
Crie o banco de dados
Depois que a instância estiver em execução, você poderá criar o banco de dados. O Spanner permite vários bancos de dados em uma única instância.
O banco de dados é onde você define o esquema. Também é possível controlar quem tem acesso ao banco de dados, configurar a criptografia personalizada, configurar o otimizador e definir o período de armazenamento.
Para criar o banco de dados, use novamente a ferramenta de linha de comando gcloud:
export SPANNER_DATABASE=cymbal-bikes
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Resposta ao comando:
$ gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Creating database...done.
Resumo
Nesta etapa, você criou a instância e o banco de dados do Spanner.
A seguir
Em seguida, você vai configurar o esquema e os dados do Spanner.
4. Carregar o esquema e os dados do Cymbal
Criar o esquema do Cymbal
Para configurar o esquema, navegue até o Spanner Studio:
O esquema tem duas partes. Primeiro, adicione a tabela products. Copie e cole esta instrução na guia vazia.
Para o esquema, copie e cole este DDL na caixa:
CREATE TABLE products (
categoryId INT64 NOT NULL,
productId INT64 NOT NULL,
productName STRING(MAX) NOT NULL,
productDescription STRING(MAX) NOT NULL,
productDescriptionEmbedding ARRAY<FLOAT32>,
createTime TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
inventoryCount INT64 NOT NULL,
priceInCents INT64,
) PRIMARY KEY(categoryId, productId);
Em seguida, clique no botão run e aguarde alguns segundos para que o esquema seja criado.
Em seguida, você vai criar os dois modelos e configurá-los para endpoints de modelo da Vertex AI.
O primeiro modelo é um modelo de embedding usado para gerar embeddings de texto, e o segundo é um modelo de LLM usado para gerar respostas com base nos dados do Spanner.
Cole o esquema a seguir em uma nova guia no Spanner Studio:
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-004'
);
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-pro',
default_batch_size = 1
);
Em seguida, clique no botão run e aguarde alguns segundos para que os modelos sejam criados.
No painel esquerdo do Spanner Studio, você verá as seguintes tabelas e modelos:
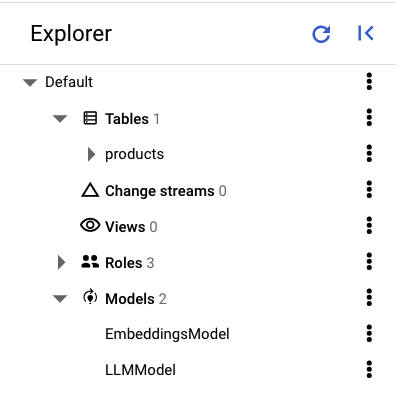
Carregue os dados
Agora, insira alguns produtos no banco de dados. Abra uma nova guia no Spanner Studio e copie e cole as seguintes instruções de inserção:
INSERT INTO products (categoryId, productId, productName, productDescription, createTime, inventoryCount, priceInCents)
VALUES (1, 1, "Cymbal Helios Helmet", "Safety meets style with the Cymbal children's bike helmet. Its lightweight design, superior ventilation, and adjustable fit ensure comfort and protection on every ride. Stay bright and keep your child safe under the sun with Cymbal Helios!", PENDING_COMMIT_TIMESTAMP(), 100, 10999),
(1, 2, "Cymbal Sprout", "Let their cycling journey begin with the Cymbal Sprout, the ideal balance bike for beginning riders ages 2-4 years. Its lightweight frame, low seat height, and puncture-proof tires promote stability and confidence as little ones learn to balance and steer. Watch them sprout into cycling enthusiasts with Cymbal Sprout!", PENDING_COMMIT_TIMESTAMP(), 10, 13999),
(1, 3, "Cymbal Spark Jr.", "Light, vibrant, and ready for adventure, the Spark Jr. is the perfect first bike for young riders (ages 5-8). Its sturdy frame, easy-to-use brakes, and puncture-resistant tires inspire confidence and endless playtime. Let the spark of cycling ignite with Cymbal!", PENDING_COMMIT_TIMESTAMP(), 34, 13900),
(1, 4, "Cymbal Summit", "Conquering trails is a breeze with the Summit mountain bike. Its lightweight aluminum frame, responsive suspension, and powerful disc brakes provide exceptional control and comfort for experienced bikers navigating rocky climbs or shredding downhill. Reach new heights with Cymbal Summit!", PENDING_COMMIT_TIMESTAMP(), 0, 79999),
(1, 5, "Cymbal Breeze", "Cruise in style and embrace effortless pedaling with the Breeze electric bike. Its whisper-quiet motor and long-lasting battery let you conquer hills and distances with ease. Enjoy scenic rides, commutes, or errands with a boost of confidence from Cymbal Breeze!", PENDING_COMMIT_TIMESTAMP(), 72, 129999),
(1, 6, "Cymbal Trailblazer Backpack", "Carry all your essentials in style with the Trailblazer backpack. Its water-resistant material, multiple compartments, and comfortable straps keep your gear organized and accessible, allowing you to focus on the adventure. Blaze new trails with Cymbal Trailblazer!", PENDING_COMMIT_TIMESTAMP(), 24, 7999),
(1, 7, "Cymbal Phoenix Lights", "See and be seen with the Phoenix bike lights. Powerful LEDs and multiple light modes ensure superior visibility, enhancing your safety and enjoyment during day or night rides. Light up your journey with Cymbal Phoenix!", PENDING_COMMIT_TIMESTAMP(), 87, 3999),
(1, 8, "Cymbal Windstar Pump", "Flat tires are no match for the Windstar pump. Its compact design, lightweight construction, and high-pressure capacity make inflating tires quick and effortless. Get back on the road in no time with Cymbal Windstar!", PENDING_COMMIT_TIMESTAMP(), 36, 24999),
(1, 9,"Cymbal Odyssey Multi-Tool","Be prepared for anything with the Odyssey multi-tool. This handy gadget features essential tools like screwdrivers, hex wrenches, and tire levers, keeping you ready for minor repairs and adjustments on the go. Conquer your journey with Cymbal Odyssey!", PENDING_COMMIT_TIMESTAMP(), 52, 999),
(1, 10,"Cymbal Nomad Water Bottle","Stay hydrated on every ride with the Nomad water bottle. Its sleek design, BPA-free construction, and secure lock lid make it the perfect companion for staying refreshed and motivated throughout your adventures. Hydrate and explore with Cymbal Nomad!", PENDING_COMMIT_TIMESTAMP(), 42, 1299);
Clique no botão run para inserir os dados.
Resumo
Nesta etapa, você criou o esquema e carregou alguns dados básicos no banco de dados cymbal-bikes.
A seguir
Em seguida, você vai integrar com o modelo de embedding para gerar embeddings para as descrições dos produtos, bem como converter uma solicitação de pesquisa textual em um embedding para pesquisar produtos relevantes.
5. Trabalhar com embeddings
Gerar embeddings de vetor para descrições de produtos
Para que a pesquisa de similaridade funcione nos produtos, é necessário gerar embeddings para as descrições dos produtos.
Com o EmbeddingsModel criado no esquema, essa é uma instrução DML UPDATE simples.
UPDATE products p1
SET productDescriptionEmbedding =
(SELECT embeddings.values from ML.PREDICT(MODEL EmbeddingsModel,
(SELECT productDescription as content FROM products p2 where p2.productId=p1.productId)))
WHERE categoryId=1;
Clique no botão run para atualizar as descrições dos produtos.
Usar a pesquisa vetorial
Neste exemplo, você vai fornecer uma solicitação de pesquisa em linguagem natural por meio de uma consulta SQL. Essa consulta vai transformar a solicitação de pesquisa em um embedding e, em seguida, pesquisar resultados semelhantes com base nos embeddings armazenados das descrições dos produtos que foram gerados na etapa anterior.
-- Use Spanner's vector search, and integration with embedding and LLM models to
-- return items that are semantically relevant and available in inventory based on
-- real-time data.
SELECT productName, productDescription, inventoryCount, COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) as distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
Clique no botão run para encontrar os produtos semelhantes. Os resultados serão assim:
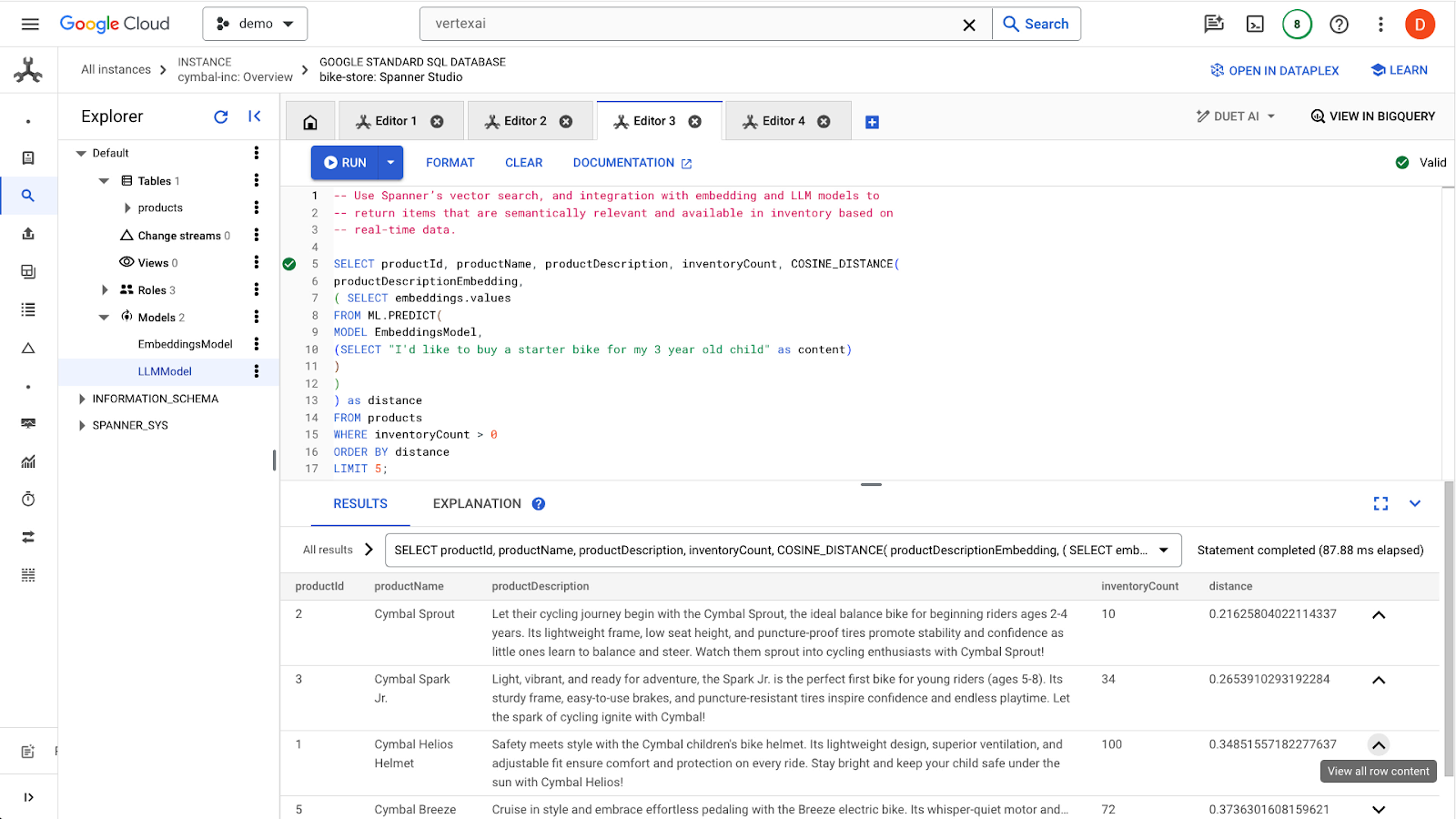
Observe que outros filtros são usados na consulta, como apenas produtos em estoque (inventoryCount > 0).
Resumo
Nesta etapa, você criou embeddings de descrição de produtos e um embedding de solicitação de pesquisa usando SQL, aproveitando a integração do Spanner com modelos na Vertex AI. Você também realizou uma pesquisa vetorial para encontrar produtos semelhantes que correspondam à solicitação de pesquisa.
Próximas etapas
Em seguida, vamos usar os resultados da pesquisa para alimentar um LLM e gerar uma resposta personalizada para cada produto.
6. Trabalhar com um LLM
O Spanner facilita a integração com modelos de LLM veiculados na Vertex AI. Isso permite que os desenvolvedores usem SQL para interagir diretamente com LLMs, em vez de exigir que o aplicativo execute a lógica.
Por exemplo, temos os resultados da consulta SQL anterior do usuário "I'd like to buy a starter bike for my 3 year old child".
O desenvolvedor gostaria de fornecer uma resposta para cada resultado sobre se o produto é adequado para o usuário, usando o seguinte comando:
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me? I'd like to buy a starter bike for my 3 year old child"
Esta é a consulta que você pode usar:
-- Use an LLM to analyze this list and provide a recommendation on whether each
-- product is a good fit for the user. We use the vector search and real time
-- inventory data to first filter the products to reduce the size of the prompt to
-- the LLM.
SELECT productName, productDescription, inventoryCount, content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
( SELECT
inventoryCount,
productName,
productDescription,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a starter bike for my 3 year old child \n",
"Product Name: ", productName, "\n",
"Product Description:", productDescription) AS prompt,
FROM products
WHERE inventoryCount > 0
ORDER by COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
( SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) LIMIT 5
),
STRUCT(256 AS maxOutputTokens)
);
Clique no botão run para emitir a consulta. Os resultados serão assim:
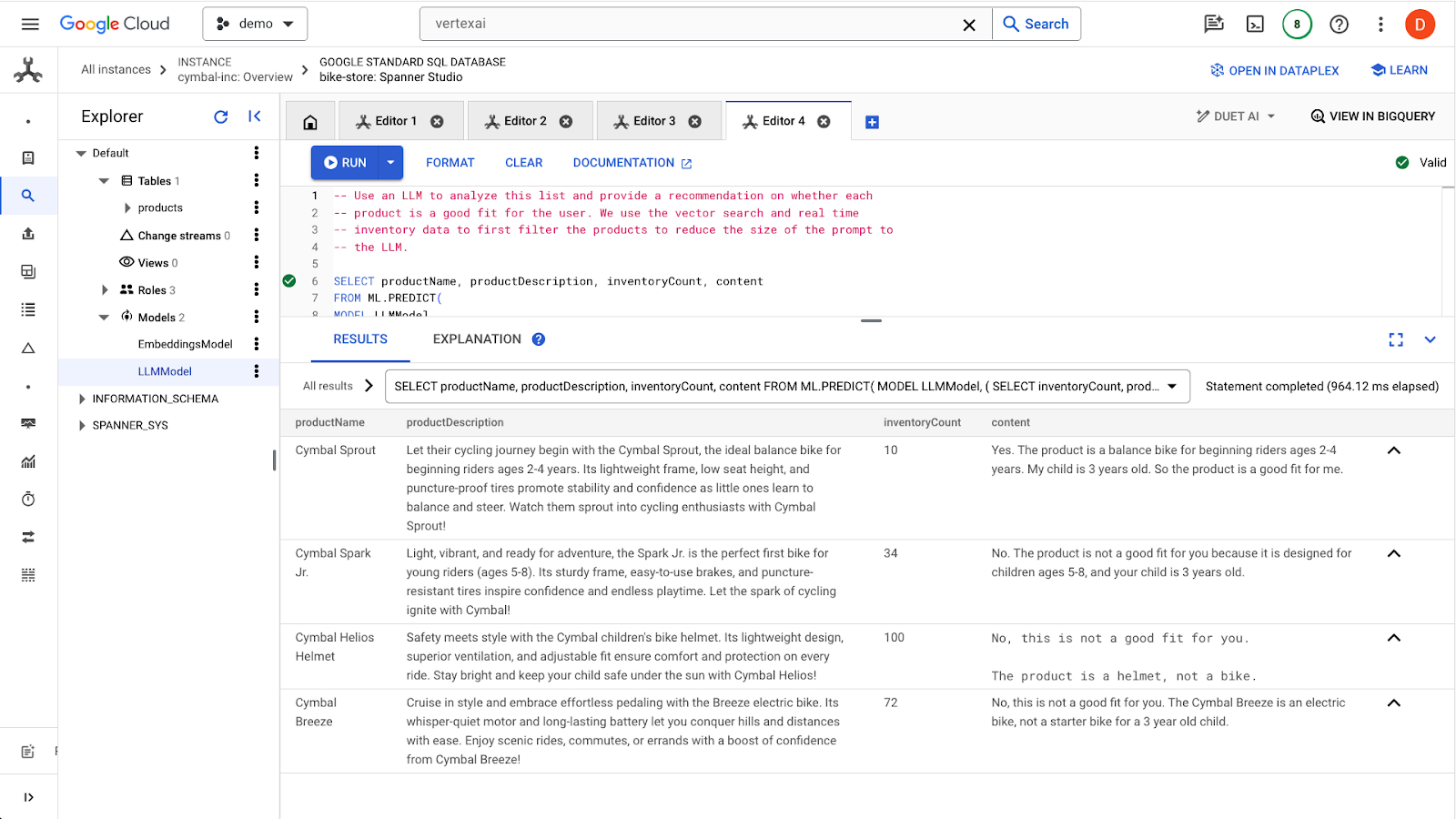
O primeiro produto é adequado para uma criança de 3 anos devido à faixa etária na descrição do produto (2 a 4 anos). Os outros produtos não são adequados.
Resumo
Nesta etapa, você trabalhou com um LLM para gerar respostas básicas a comandos de um usuário.
Próximas etapas
Em seguida, vamos aprender a usar a ANN para escalonar a pesquisa vetorial.
7. Escalonamento da pesquisa vetorial
Os exemplos de pesquisa vetorial anteriores aproveitaram a pesquisa vetorial KNN exata. Isso é ótimo quando você pode consultar subconjuntos muito específicos dos dados do Spanner. Esses tipos de consultas são considerados altamente particionáveis.
Se você não tiver cargas de trabalho altamente particionáveis e tiver uma grande quantidade de dados, use a pesquisa vetorial ANN aproveitando o algoritmo ScaNN para aumentar o desempenho de pesquisa.
Para fazer isso no Spanner, você precisa fazer duas coisas:
- Criar um índice vetorial
- Modificar a consulta para usar as funções de distância APPROX.
Criar o índice vetorial
Para criar um índice vetorial nesse conjunto de dados, primeiro precisamos modificar a coluna productDescriptionEmbeddings para definir o comprimento de cada vetor. Para adicionar o comprimento do vetor a uma coluna, é necessário remover a coluna original e recriá-la.
ALTER TABLE `products` DROP COLUMN `productDescriptionEmbedding`;
ALTER TABLE
`products` ADD COLUMN `productDescriptionEmbedding` ARRAY<FLOAT32>(vector_length=>768);
Em seguida, crie os embeddings novamente na etapa Generate Vector embedding que você executou anteriormente.
UPDATE products p1
SET productDescriptionEmbedding =
(SELECT embeddings.values from ML.PREDICT(MODEL EmbeddingsModel,
(SELECT productDescription as content FROM products p2 where p2.productId=p1.productId)))
WHERE categoryId=1;
Depois que a coluna for criada, crie o índice:
CREATE VECTOR INDEX ProductDescriptionEmbeddingIndex
ON products(productDescriptionEmbedding)
WHERE productDescriptionEmbedding IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
Usar o novo índice
Para usar o novo índice vetorial, é necessário modificar ligeiramente a consulta de embedding anterior.
Esta é a consulta original:
SELECT productName, productDescription, inventoryCount, COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) as distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
Você precisa fazer as seguintes mudanças:
- Use uma dica de índice para o novo índice vetorial:
@{force_index=ProductDescriptionEmbeddingIndex} - Mude a chamada de função
COSINE_DISTANCEparaAPPROX_COSINE_DISTANCE. Observe que as opções JSON na consulta final abaixo também são necessárias. - Gere os embeddings da função ML.PREDICT separadamente.
- Copie os resultados dos embeddings para a consulta final.
Gerar os embeddings
-- Generate the prompt embeddings
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
Destaque os resultados da consulta e copie-os.
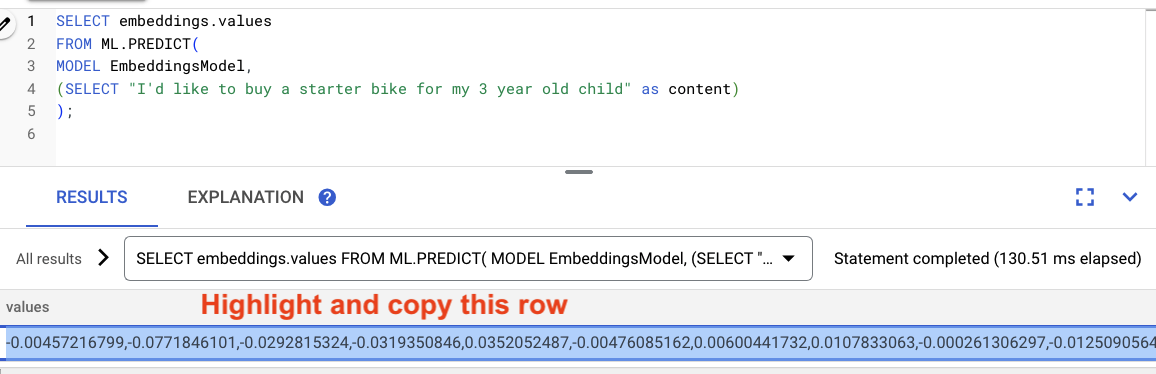
Em seguida, substitua <VECTOR> na consulta a seguir colando os embeddings que você copiou.
-- Embedding query now using the vector index
SELECT productName, productDescription, inventoryCount,
APPROX_COSINE_DISTANCE(productDescriptionEmbedding, array<float32>[@VECTOR], options => JSON '{\"num_leaves_to_search\": 10}')
FROM products @{force_index=ProductDescriptionEmbeddingIndex}
WHERE productDescriptionEmbedding IS NOT NULL AND inventoryCount > 0
ORDER BY distance
LIMIT 5;
O código será semelhante a este:
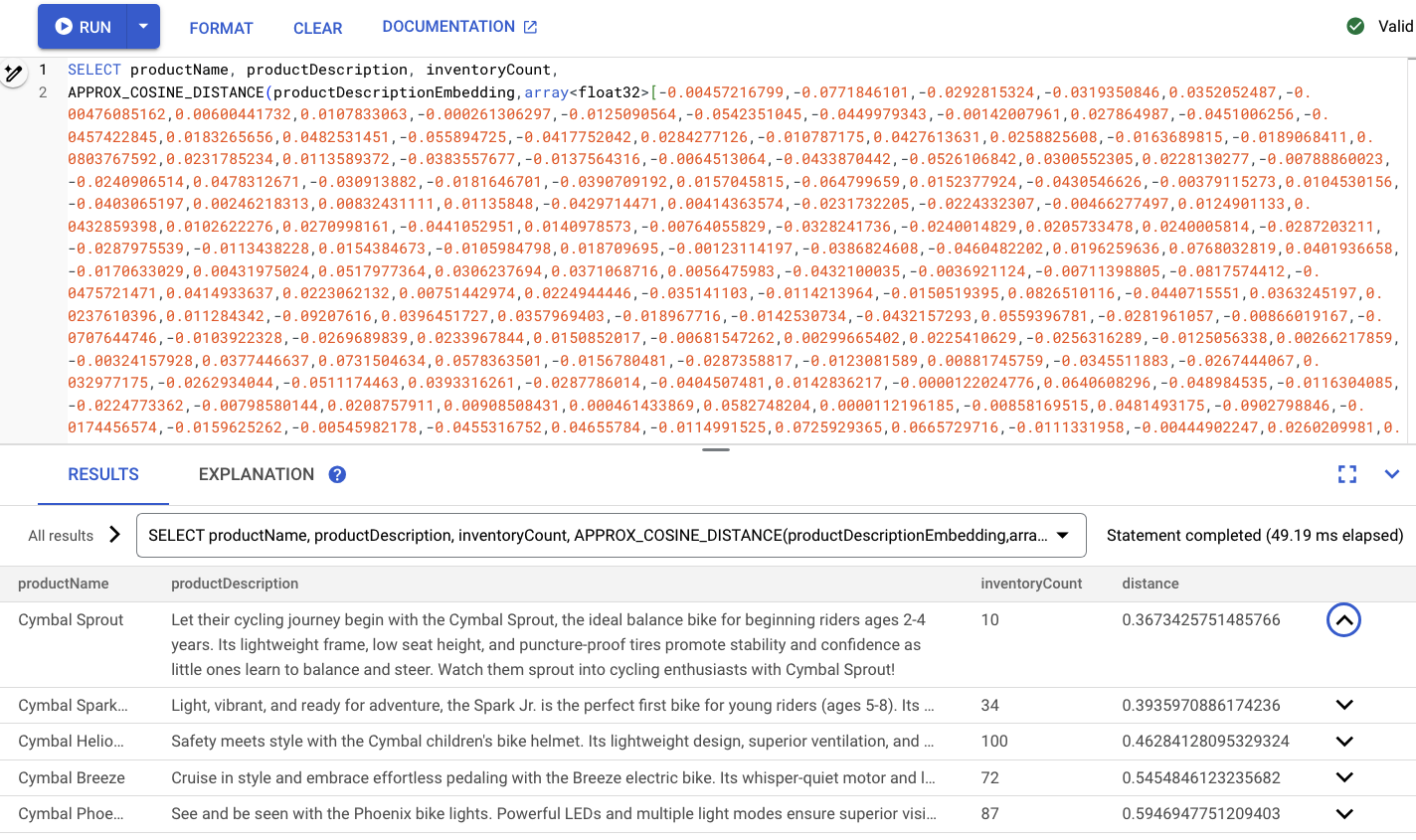
Resumo
Nesta etapa, você converteu o esquema para criar um índice vetorial. Em seguida, você reescreveu a consulta de embedding para realizar a pesquisa ANN usando o índice vetorial. Essa é uma etapa importante à medida que seus dados crescem para escalonar cargas de trabalho de pesquisa vetorial.
Próximas etapas
Em seguida, é hora de liberar espaço!
8. Limpeza (opcional)
Para liberar espaço, acesse a seção Cloud Spanner do Console do Cloud e exclua a instância 'retail-demo' que criamos no codelab.
9. Parabéns!
Parabéns, você realizou uma pesquisa de similaridade usando a pesquisa vetorial integrada do Spanner. Além disso, você viu como é fácil trabalhar com modelos de embedding e LLM para fornecer funcionalidades de IA generativa diretamente usando SQL.
Por fim, você aprendeu o processo para realizar a pesquisa ANN com o algoritmo ScaNN para escalonar cargas de trabalho de pesquisa vetorial.
A seguir
Saiba mais sobre o recurso de pesquisa vetorial de vizinho mais próximo exato (KNN, na sigla em inglês) do Spanner neste link: https://cloud.google.com/spanner/docs/find-k-nearest-neighbors
Saiba mais sobre o recurso de pesquisa vetorial de vizinho mais próximo aproximado (ANN, na sigla em inglês) do Spanner neste link: https://cloud.google.com/spanner/docs/find-approximate-nearest-neighbors
Você também pode ler mais sobre como realizar previsões on-line com SQL usando a integração da Vertex AI do Spanner neste link: https://cloud.google.com/spanner/docs/ml