
1. 简介
Spanner 是一种全代管式、可横向扩缩、全球分布的数据库服务,非常适合关系型和非关系型运营工作负载。
Spanner 具有内置的向量搜索支持,可让您执行相似度搜索或语义搜索,并在 GenAI 应用中大规模实现检索增强生成 (RAG),同时利用 精确的 K 最近邻 (KNN) 或 近似最近邻 (ANN) 功能。
与对运营数据执行的任何其他查询一样,Spanner 的向量搜索查询会在事务提交后立即返回最新的实时数据。
在本实验中,您将了解如何设置利用 Spanner 执行向量搜索所需的基本功能,并使用 SQL 访问 Vertex AI Model Garden 中的嵌入和 LLM 模型。
架构如下所示:
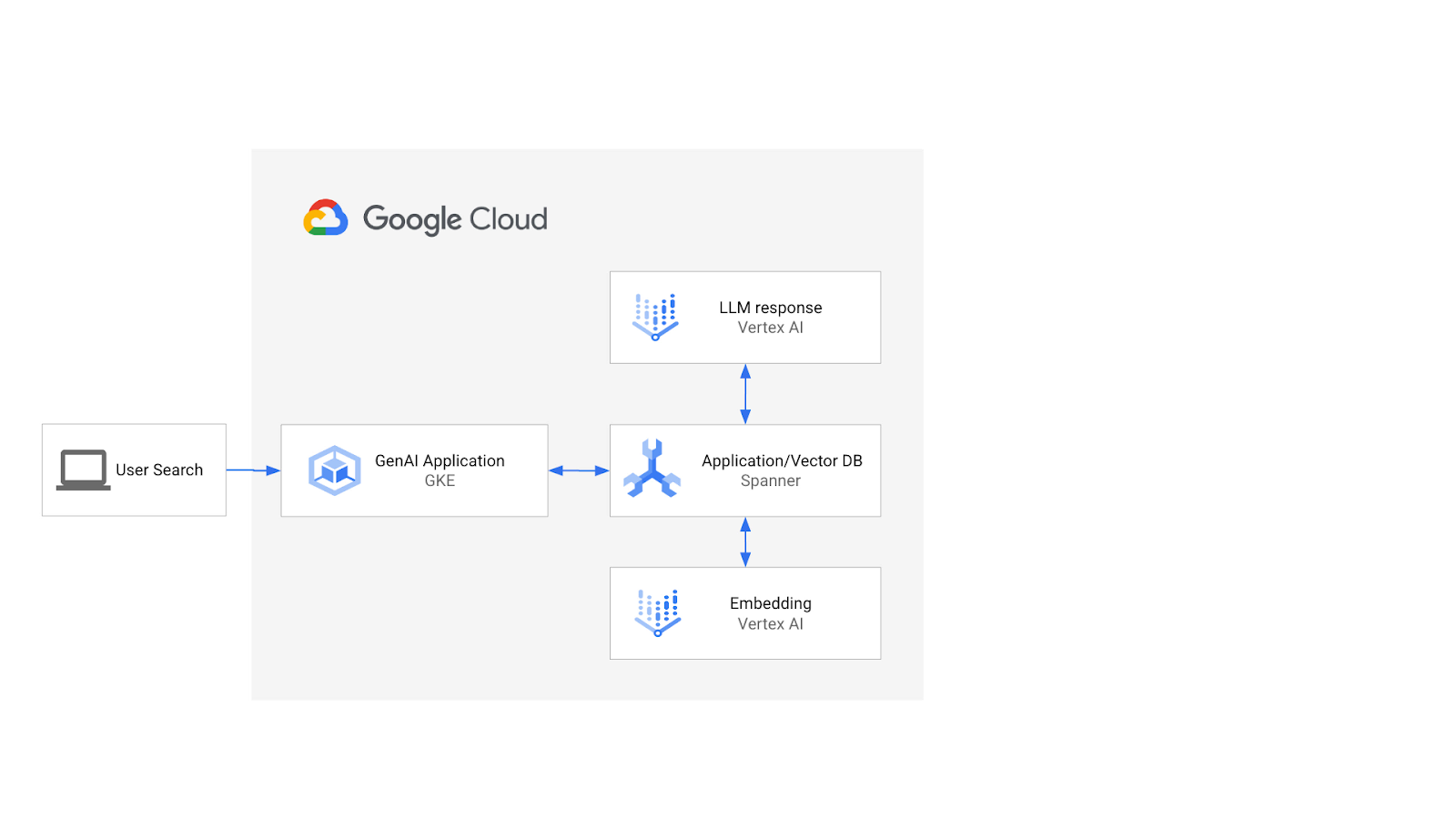
在此基础上,您将学习如何创建由 ScaNN 算法 支持的向量索引,以及在语义工作负载需要扩缩时如何使用 APPROX 距离函数。
构建内容
在本实验中,您将:
- 创建 Spanner 实例
- 设置 Spanner 的数据库架构,以与 Vertex AI 中的嵌入和 LLM 模型集成
- 加载零售数据集
- 针对数据集发出相似度搜索查询
- 向 LLM 模型提供上下文,以生成特定于产品的推荐。
- 修改架构并创建向量索引。
- 更改查询以利用新创建的向量索引。
学习内容
- 如何设置 Spanner 实例
- 如何与 Vertex AI 集成
- 如何使用 Spanner 执行向量搜索,以在零售数据集中查找类似商品
- 如何准备数据库以使用 ANN 搜索扩缩向量搜索工作负载。
所需条件
2. 设置和要求
创建项目
如果您还没有 Google 账号(Gmail 或 Google Apps),则必须 创建一个。登录 Google Cloud Platform Console ( console.cloud.google.com) 并创建一个新项目。
如果您已经有一个项目,请点击控制台左上方的项目选择下拉菜单:

然后在出现的对话框中点击“新建项目”按钮以创建一个新项目:
如果您还没有项目,则应该看到一个类似这样的对话框来创建您的第一个项目:
随后的项目创建对话框可让您输入新项目的详细信息:
请记住项目 ID,它在所有 Google Cloud 项目中都是唯一的名称(上述名称已被占用,您无法使用,抱歉!)。它稍后将在此 Codelab 中被称为 PROJECT_ID。
接下来,如果尚未执行此操作,则需要在 Developers Console 中 启用结算功能,以便使用 Google Cloud 资源并 启用 Spanner API。
在此 Codelab 中运行不会花费您超过几美元,但是如果您决定使用更多的资源或让它们运行(请参阅本文档末尾的“清理”部分),则可能会花费更多。如需了解 Google Cloud Spanner 价格,请参阅此处。
Google Cloud Platform 的新用户均有资格获享 $300 赠金,免费试用此 Codelab。
Google Cloud Shell 设置
虽然 Google Cloud 和 Spanner 可以从笔记本电脑远程操作,但在此 Codelab 中,我们将使用 Google Cloud Shell,这是一个在云端运行的命令行环境。
基于 Debian 的这个虚拟机已加载了您需要的所有开发工具。它提供了一个持久的 5GB 主目录,并且在 Google Cloud 中运行,大大增强了网络性能和身份验证。这意味着在本 Codelab 中,您只需要一个浏览器(没错,它适用于 Chromebook)。
- 如需从 Cloud Console 激活 Cloud Shell,只需点击激活 Cloud Shell
 (预配和连接到环境仅需花费一些时间)。
(预配和连接到环境仅需花费一些时间)。
在连接到 Cloud Shell 后,您应该会看到自己已通过身份验证,并且相关项目已设置为您的 PROJECT_ID。
gcloud auth list
命令输出
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
命令输出
[core]
project = <PROJECT_ID>
如果出于某种原因未设置项目,只需发出以下命令即可:
gcloud config set project <PROJECT_ID>
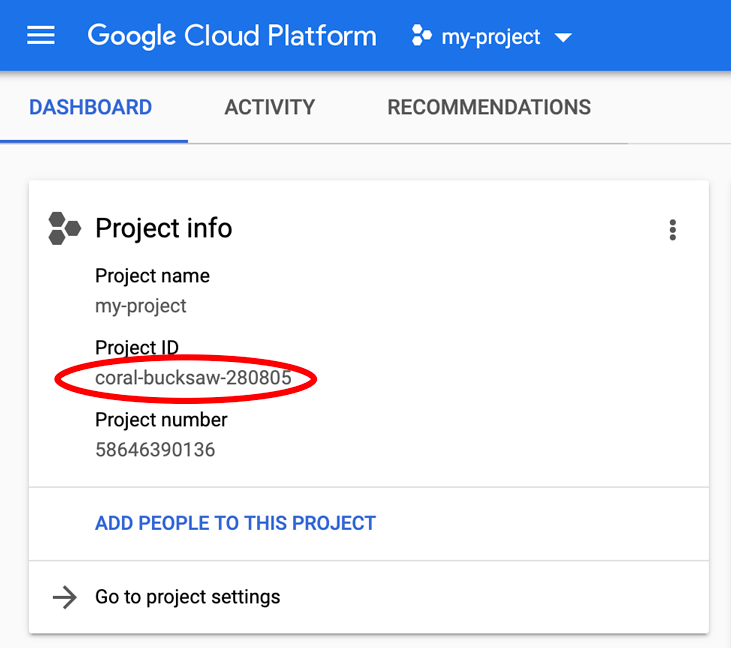
正在查找您的 PROJECT_ID?检查您在设置步骤中使用的 ID,或在 Cloud Console 信息中心查找该 ID:
默认情况下,Cloud Shell 还会设置一些环境变量,这对您日后运行命令可能会很有用。
echo $GOOGLE_CLOUD_PROJECT
命令输出
<PROJECT_ID>
启用 Spanner API
gcloud services enable spanner.googleapis.com
摘要
在此步骤中,如果您还没有项目,则已设置项目、激活 Cloud Shell 并启用了所需的 API。
后续步骤
接下来,您将设置 Spanner 实例和数据库。
3. 创建 Spanner 实例和数据库
创建 Spanner 实例
在此步骤中,我们会为此 Codelab 设置 Spanner 实例。 为此,请打开 Cloud Shell 并运行以下命令:
export SPANNER_INSTANCE_ID=retail-demo
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
--edition=ENTERPRISE
命令输出:
$ gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
--edition=ENTERPRISE
Creating instance...done.
创建数据库
实例运行后,您可以创建数据库。Spanner 允许在单个实例上使用多个数据库。
您可以在数据库中定义架构。您还可以控制谁有权访问数据库、设置自定义加密、配置优化器以及设置保留期限。
如需创建数据库,请再次使用 gcloud 命令行工具:
export SPANNER_DATABASE=cymbal-bikes
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
命令输出:
$ gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Creating database...done.
摘要
在此步骤中,您已创建 Spanner 实例和数据库。
后续步骤
接下来,您将设置 Spanner 架构和数据。
4. 加载 Cymbal 架构和数据
创建 Cymbal 架构
如需设置架构,请前往 Spanner Studio:
架构包含两个部分。首先,您需要添加 products 表。将此语句复制并粘贴到空白标签页中。
对于架构,请将此 DDL 复制并粘贴到框中:
CREATE TABLE products (
categoryId INT64 NOT NULL,
productId INT64 NOT NULL,
productName STRING(MAX) NOT NULL,
productDescription STRING(MAX) NOT NULL,
productDescriptionEmbedding ARRAY<FLOAT32>,
createTime TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
inventoryCount INT64 NOT NULL,
priceInCents INT64,
) PRIMARY KEY(categoryId, productId);
然后,点击 run 按钮,等待几秒钟,架构就会创建完成。
接下来,您将创建两个模型,并将它们配置到 Vertex AI 模型端点。
第一个模型是用于从文本生成嵌入的嵌入模型,第二个模型是用于根据 Spanner 中的数据生成回答的 LLM 模型。
将以下架构粘贴到 Spanner Studio 的新标签页中:
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-004'
);
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-3.1-pro-preview',
default_batch_size = 1
);
然后,点击 run 按钮,等待几秒钟,模型就会创建完成。
在 Spanner Studio 的左侧窗格中,您应该会看到以下表格和模型:
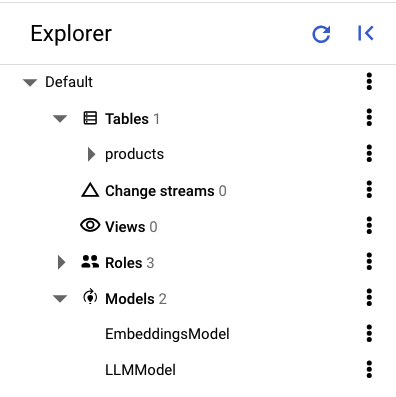
加载数据
现在,您需要将一些商品插入到数据库中。在 Spanner Studio 中打开一个新标签页,然后复制并粘贴以下 insert 语句:
INSERT INTO products (categoryId, productId, productName, productDescription, createTime, inventoryCount, priceInCents)
VALUES (1, 1, "Cymbal Helios Helmet", "Safety meets style with the Cymbal children's bike helmet. Its lightweight design, superior ventilation, and adjustable fit ensure comfort and protection on every ride. Stay bright and keep your child safe under the sun with Cymbal Helios!", PENDING_COMMIT_TIMESTAMP(), 100, 10999),
(1, 2, "Cymbal Sprout", "Let their cycling journey begin with the Cymbal Sprout, the ideal balance bike for beginning riders ages 2-4 years. Its lightweight frame, low seat height, and puncture-proof tires promote stability and confidence as little ones learn to balance and steer. Watch them sprout into cycling enthusiasts with Cymbal Sprout!", PENDING_COMMIT_TIMESTAMP(), 10, 13999),
(1, 3, "Cymbal Spark Jr.", "Light, vibrant, and ready for adventure, the Spark Jr. is the perfect first bike for young riders (ages 5-8). Its sturdy frame, easy-to-use brakes, and puncture-resistant tires inspire confidence and endless playtime. Let the spark of cycling ignite with Cymbal!", PENDING_COMMIT_TIMESTAMP(), 34, 13900),
(1, 4, "Cymbal Summit", "Conquering trails is a breeze with the Summit mountain bike. Its lightweight aluminum frame, responsive suspension, and powerful disc brakes provide exceptional control and comfort for experienced bikers navigating rocky climbs or shredding downhill. Reach new heights with Cymbal Summit!", PENDING_COMMIT_TIMESTAMP(), 0, 79999),
(1, 5, "Cymbal Breeze", "Cruise in style and embrace effortless pedaling with the Breeze electric bike. Its whisper-quiet motor and long-lasting battery let you conquer hills and distances with ease. Enjoy scenic rides, commutes, or errands with a boost of confidence from Cymbal Breeze!", PENDING_COMMIT_TIMESTAMP(), 72, 129999),
(1, 6, "Cymbal Trailblazer Backpack", "Carry all your essentials in style with the Trailblazer backpack. Its water-resistant material, multiple compartments, and comfortable straps keep your gear organized and accessible, allowing you to focus on the adventure. Blaze new trails with Cymbal Trailblazer!", PENDING_COMMIT_TIMESTAMP(), 24, 7999),
(1, 7, "Cymbal Phoenix Lights", "See and be seen with the Phoenix bike lights. Powerful LEDs and multiple light modes ensure superior visibility, enhancing your safety and enjoyment during day or night rides. Light up your journey with Cymbal Phoenix!", PENDING_COMMIT_TIMESTAMP(), 87, 3999),
(1, 8, "Cymbal Windstar Pump", "Flat tires are no match for the Windstar pump. Its compact design, lightweight construction, and high-pressure capacity make inflating tires quick and effortless. Get back on the road in no time with Cymbal Windstar!", PENDING_COMMIT_TIMESTAMP(), 36, 24999),
(1, 9,"Cymbal Odyssey Multi-Tool","Be prepared for anything with the Odyssey multi-tool. This handy gadget features essential tools like screwdrivers, hex wrenches, and tire levers, keeping you ready for minor repairs and adjustments on the go. Conquer your journey with Cymbal Odyssey!", PENDING_COMMIT_TIMESTAMP(), 52, 999),
(1, 10,"Cymbal Nomad Water Bottle","Stay hydrated on every ride with the Nomad water bottle. Its sleek design, BPA-free construction, and secure lock lid make it the perfect companion for staying refreshed and motivated throughout your adventures. Hydrate and explore with Cymbal Nomad!", PENDING_COMMIT_TIMESTAMP(), 42, 1299);
点击 run 按钮以插入数据。
摘要
在此步骤中,您创建了架构,并将一些基本数据加载到 cymbal-bikes 数据库中。
后续步骤
接下来,您将与嵌入模型集成,为商品说明生成嵌入,并将文本搜索请求转换为嵌入,以搜索相关商品。
5. 使用嵌入
为商品说明生成向量嵌入
如需对商品执行相似度搜索,您需要为商品说明生成嵌入。
借助在架构中创建的 EmbeddingsModel,这是一个简单的 UPDATE DML 语句。
UPDATE products p1
SET productDescriptionEmbedding =
(SELECT embeddings.values from ML.PREDICT(MODEL EmbeddingsModel,
(SELECT productDescription as content FROM products p2 where p2.productId=p1.productId)))
WHERE categoryId=1;
点击 run 按钮以更新商品说明。
使用向量搜索
在此示例中,您将通过 SQL 查询提供自然语言搜索请求。此查询会将搜索请求转换为嵌入,然后根据在上一步中生成的商品说明的存储嵌入搜索类似结果。
-- Use Spanner's vector search, and integration with embedding and LLM models to
-- return items that are semantically relevant and available in inventory based on
-- real-time data.
SELECT productName, productDescription, inventoryCount, COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) as distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
点击 run 按钮以查找类似商品。结果应如下所示:
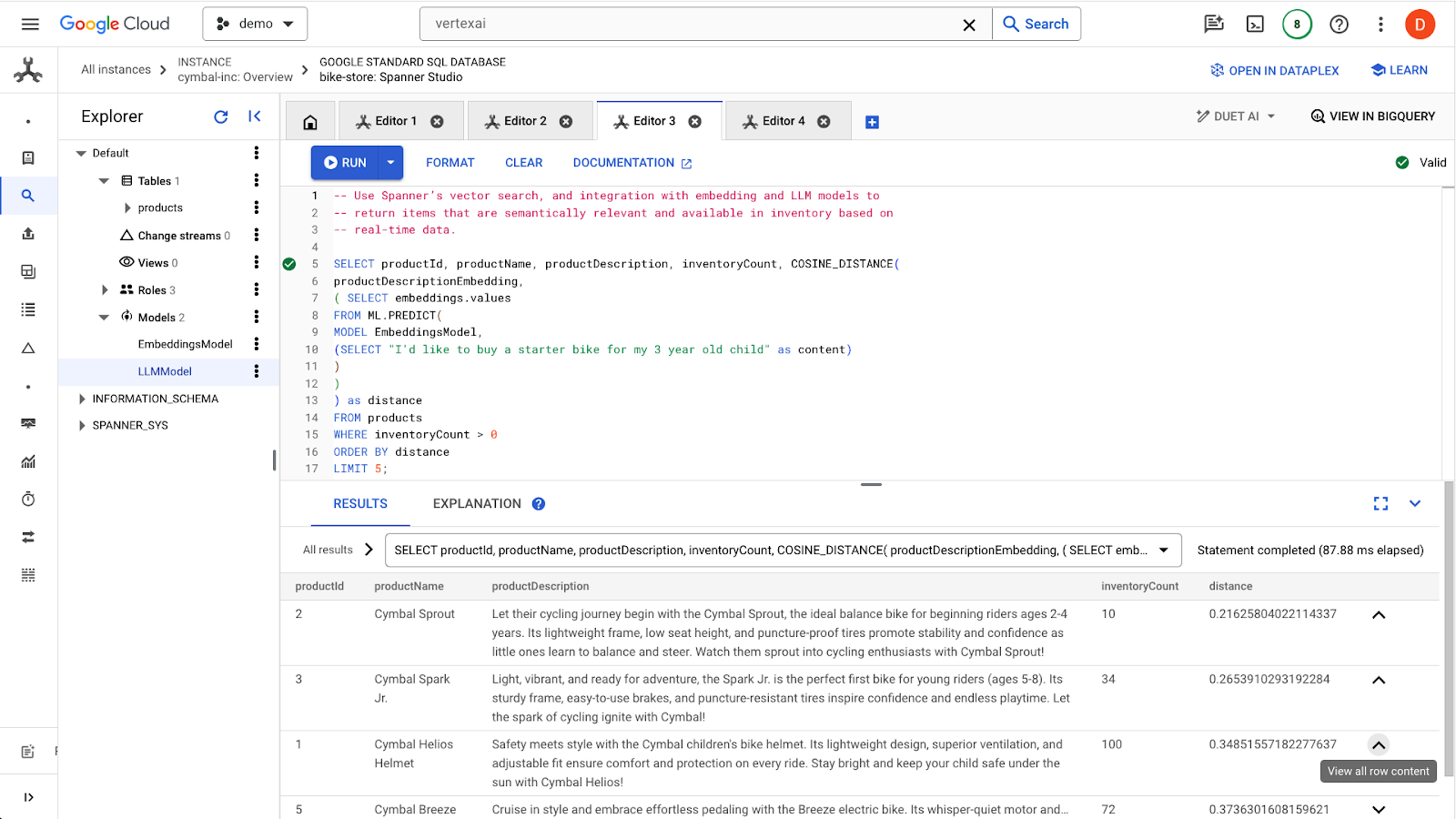
请注意,查询中使用了其他过滤条件,例如仅对有货的商品感兴趣 (inventoryCount > 0)。
摘要
在此步骤中,您使用 SQL 创建了商品说明嵌入和搜索请求嵌入,并利用了 Spanner 与 Vertex AI 中模型的集成。您还执行了向量搜索,以查找与搜索请求匹配的类似商品。
后续步骤
接下来,我们将使用搜索结果来馈送到 LLM,以便为每个商品生成自定义回答。
6. 使用 LLM
借助 Spanner,您可以轻松与 Vertex AI 提供的 LLM 模型集成。这样,开发者就可以使用 SQL 直接与 LLM 交互,而无需应用执行逻辑。
例如,我们从用户 "I'd like to buy a starter bike for my 3 year old child". 获得了上一个 SQL 查询的结果。
开发者希望使用以下提示为每个结果提供回答,说明该商品是否适合用户:
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me? I'd like to buy a starter bike for my 3 year old child"
以下是您可以使用的查询:
-- Use an LLM to analyze this list and provide a recommendation on whether each
-- product is a good fit for the user. We use the vector search and real time
-- inventory data to first filter the products to reduce the size of the prompt to
-- the LLM.
SELECT productName, productDescription, inventoryCount, content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
( SELECT
inventoryCount,
productName,
productDescription,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a starter bike for my 3 year old child \n",
"Product Name: ", productName, "\n",
"Product Description:", productDescription) AS prompt,
FROM products
WHERE inventoryCount > 0
ORDER by COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
( SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) LIMIT 5
),
STRUCT(256 AS maxOutputTokens)
);
点击 run 按钮以发出查询。结果应如下所示:
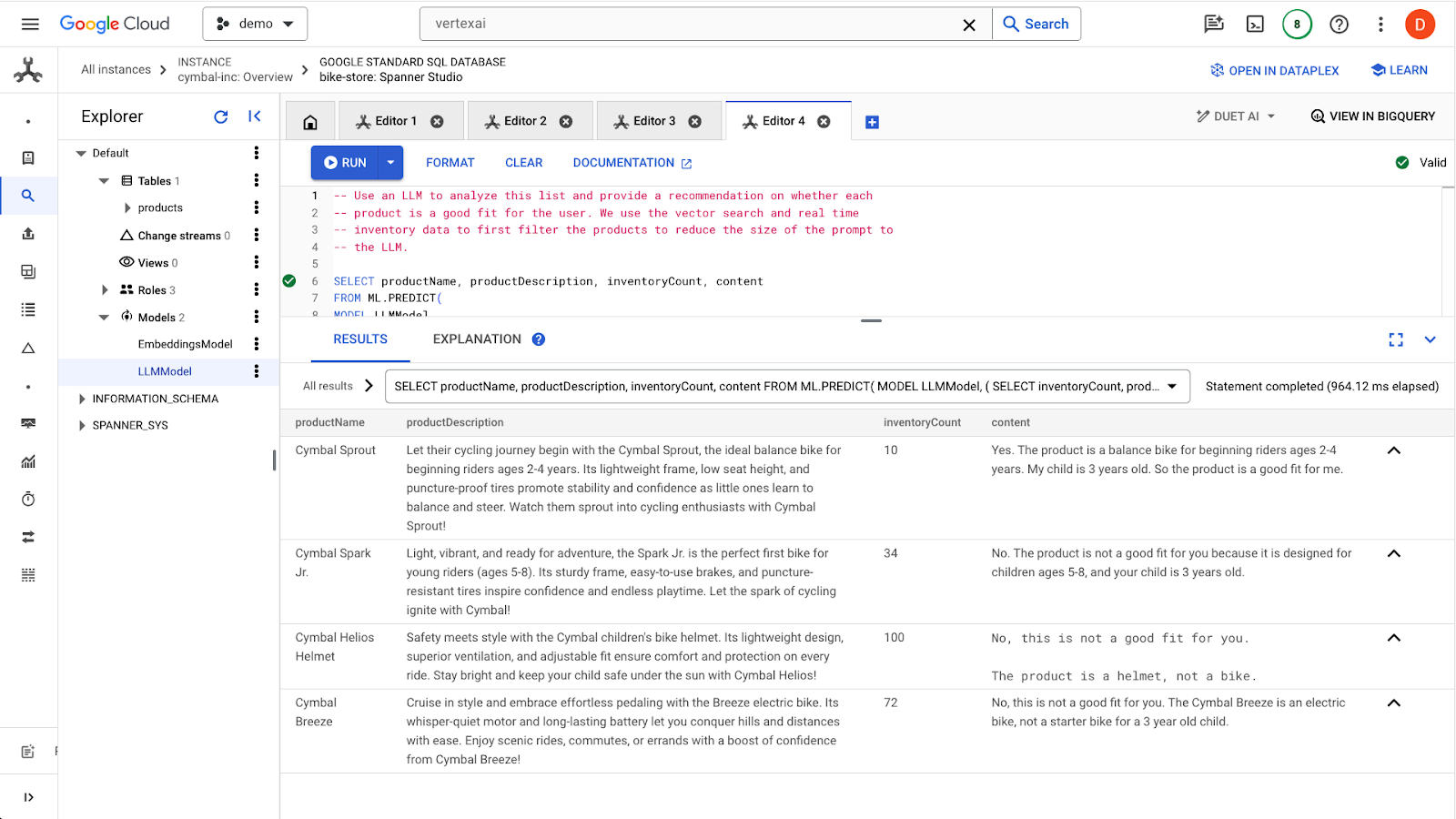
第一个商品适合 3 岁儿童,因为商品说明中的年龄段为 2-4 岁。其他商品不太适合。
摘要
在此步骤中,您使用了 LLM 来生成对用户提示的基本回答。
后续步骤
接下来,我们将学习如何使用 ANN 来扩缩向量搜索。
7. 扩缩向量搜索
之前的向量搜索示例利用了精确的 KNN 向量搜索。当您能够查询 Spanner 数据的非常具体的子集时,这非常有用。这些类型的查询被称为“高度可分区”。
如果您没有高度可分区的工作负载,并且有大量数据,则需要使用 ANN 向量搜索(利用 ScaNN 算法)来提高查找性能。
如需在 Spanner 中执行此操作,您需要执行以下两项操作:
- 创建向量索引
- 修改查询以使用 APPROX 距离函数。
创建向量索引
如需在此数据集上创建向量索引,我们首先需要修改 productDescriptionEmbeddings 列以定义每个向量的长度。如需向列添加向量长度,您必须删除原始列并重新创建它。
ALTER TABLE `products` DROP COLUMN `productDescriptionEmbedding`;
ALTER TABLE
`products` ADD COLUMN `productDescriptionEmbedding` ARRAY<FLOAT32>(vector_length=>768);
接下来,从您之前运行的 Generate Vector embedding 步骤中再次创建嵌入。
UPDATE products p1
SET productDescriptionEmbedding =
(SELECT embeddings.values from ML.PREDICT(MODEL EmbeddingsModel,
(SELECT productDescription as content FROM products p2 where p2.productId=p1.productId)))
WHERE categoryId=1;
创建列后,创建索引:
CREATE VECTOR INDEX ProductDescriptionEmbeddingIndex
ON products(productDescriptionEmbedding)
WHERE productDescriptionEmbedding IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
使用新索引
如需使用新的向量索引,您必须对之前的嵌入查询进行一些修改。
以下是原始查询:
SELECT productName, productDescription, inventoryCount, COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) as distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
您必须进行以下更改:
- 为新的向量索引使用索引提示:
@{force_index=ProductDescriptionEmbeddingIndex} - 将
COSINE_DISTANCE函数调用更改为APPROX_COSINE_DISTANCE。请注意,以下最终查询中的 JSON 选项也是必需的。 - 从 ML.PREDICT 函数中单独生成嵌入。
- 将嵌入的结果复制到最终查询中。
生成嵌入
-- Generate the prompt embeddings
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
突出显示查询结果,然后复制它们。
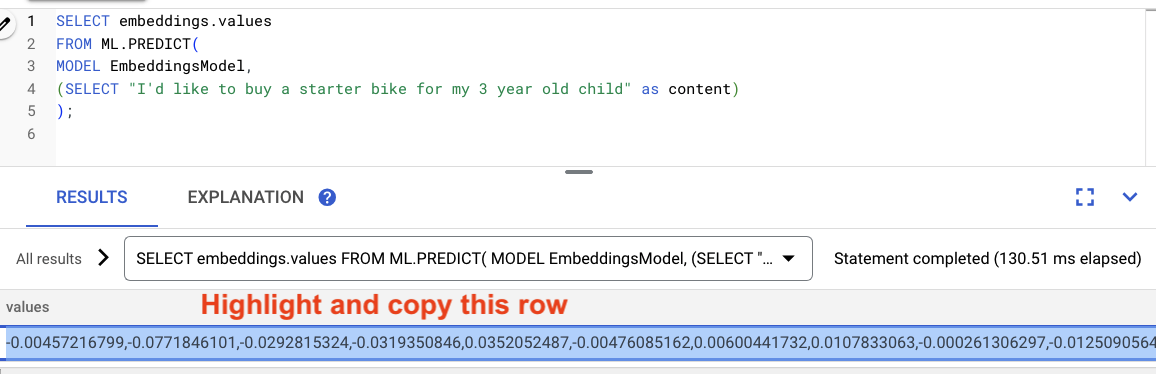
然后,将以下查询中的 <VECTOR> 替换为您复制的嵌入。
-- Embedding query now using the vector index
SELECT productName, productDescription, inventoryCount,
APPROX_COSINE_DISTANCE(productDescriptionEmbedding, array<float32>[@VECTOR], options => JSON '{\"num_leaves_to_search\": 10}')
FROM products @{force_index=ProductDescriptionEmbeddingIndex}
WHERE productDescriptionEmbedding IS NOT NULL AND inventoryCount > 0
ORDER BY distance
LIMIT 5;
输出应如下所示:
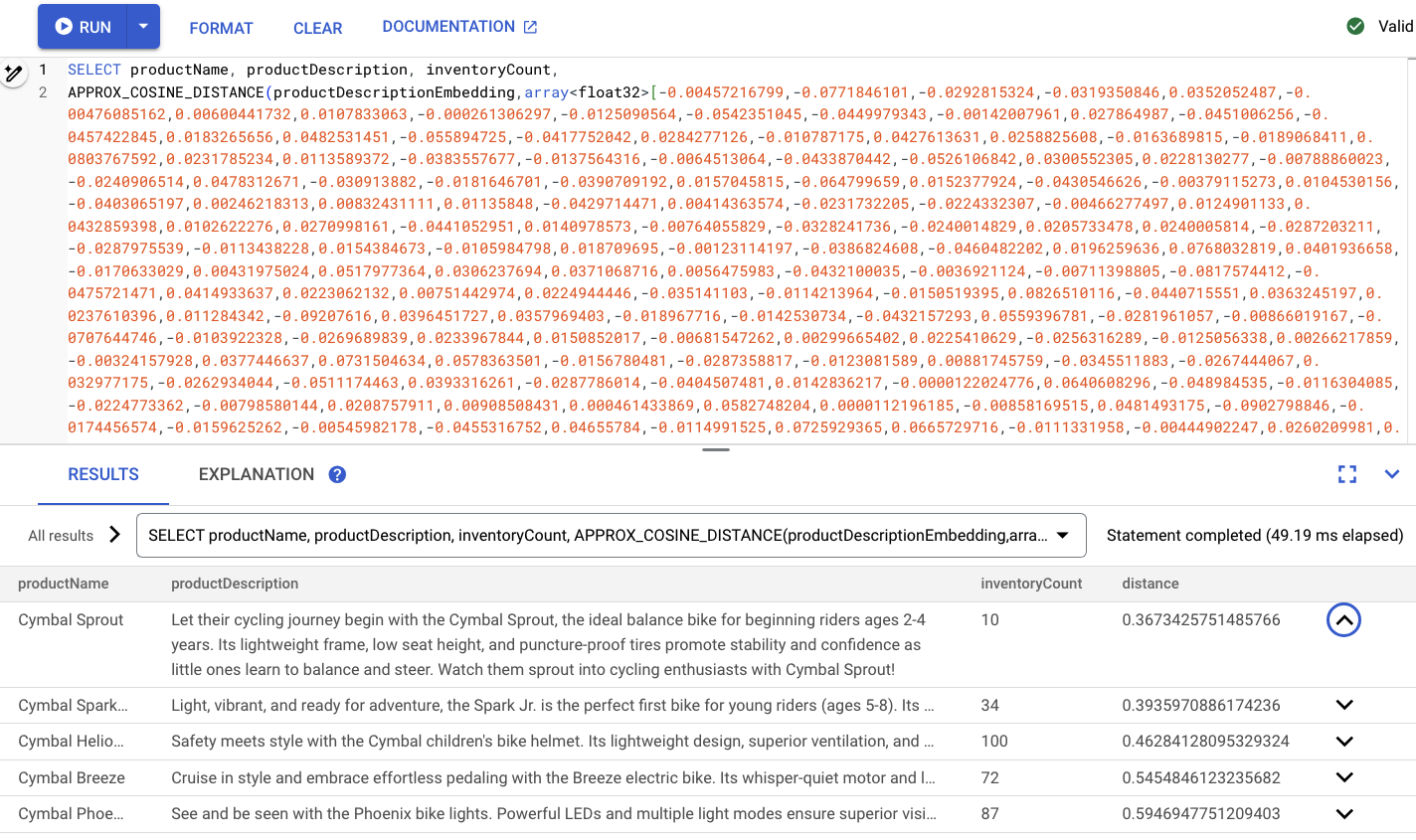
摘要
在此步骤中,您转换了架构以创建向量索引。然后,您重写了嵌入查询以使用向量索引执行 ANN 搜索。随着数据的增长,这是扩缩向量搜索工作负载的重要一步。
后续步骤
接下来,该清理了!
8. 清理(可选)
如需清理,只需进入 Cloud Spanner 部分的 Cloud Console,然后删除我们在 Codelab 中创建的 'retail-demo'实例即可。
9. 恭喜!
恭喜,您已使用 Spanner 的内置向量搜索成功执行相似度搜索。此外,您还了解了使用嵌入和 LLM 模型直接使用 SQL 提供生成式 AI 功能是多么容易。
最后,您学习了执行由 ScaNN 算法 支持的 ANN 搜索以扩缩向量搜索工作负载的过程。
接下来怎么做?
如需详细了解 Spanner 的精确最近邻 (KNN 向量搜索) 功能,请访问: https://cloud.google.com/spanner/docs/find-k-nearest-neighbors
如需详细了解 Spanner 的近似最近邻 (ANN 向量搜索) 功能,请访问: https://cloud.google.com/spanner/docs/find-approximate-nearest-neighbors
您还可以详细了解如何使用 Spanner 的 Vertex AI 集成通过 SQL 执行在线预测: https://cloud.google.com/spanner/docs/ml