
1. מבוא
Spanner הוא שירות מנוהל של מסד נתונים עם יכולת הרחבה אופקית, שמופץ באופן גלובלי ומתאים לעומסי עבודה תפעוליים רלציוניים ולא רלציוניים.
ל-Spanner יש תמיכה מובנית בחיפוש וקטורי, שמאפשרת לכם לבצע חיפוש סמנטי או חיפוש של דמיון ולהטמיע יצירה משופרת באמצעות אחזור (RAG) באפליקציות GenAI בהיקף נרחב, תוך שימוש בתכונות של שכנים מדויקים מסוג K-nearest neighbor (KNN) או שכנים משוערים מסוג K-nearest neighbor (ANN).
שאילתות של חיפוש וקטורי ב-Spanner מחזירות נתונים עדכניים בזמן אמת ברגע שהעסקאות מאושרות, בדיוק כמו כל שאילתה אחרת על הנתונים התפעוליים שלכם.
בשיעור ה-Lab הזה תלמדו איך להגדיר את התכונות הבסיסיות שנדרשות כדי להשתמש ב-Spanner לביצוע חיפוש וקטורי, ולגשת למודלים של הטמעה ו-LLM מ-Model Garden של Vertex AI באמצעות SQL.
הארכיטקטורה תיראה כך:
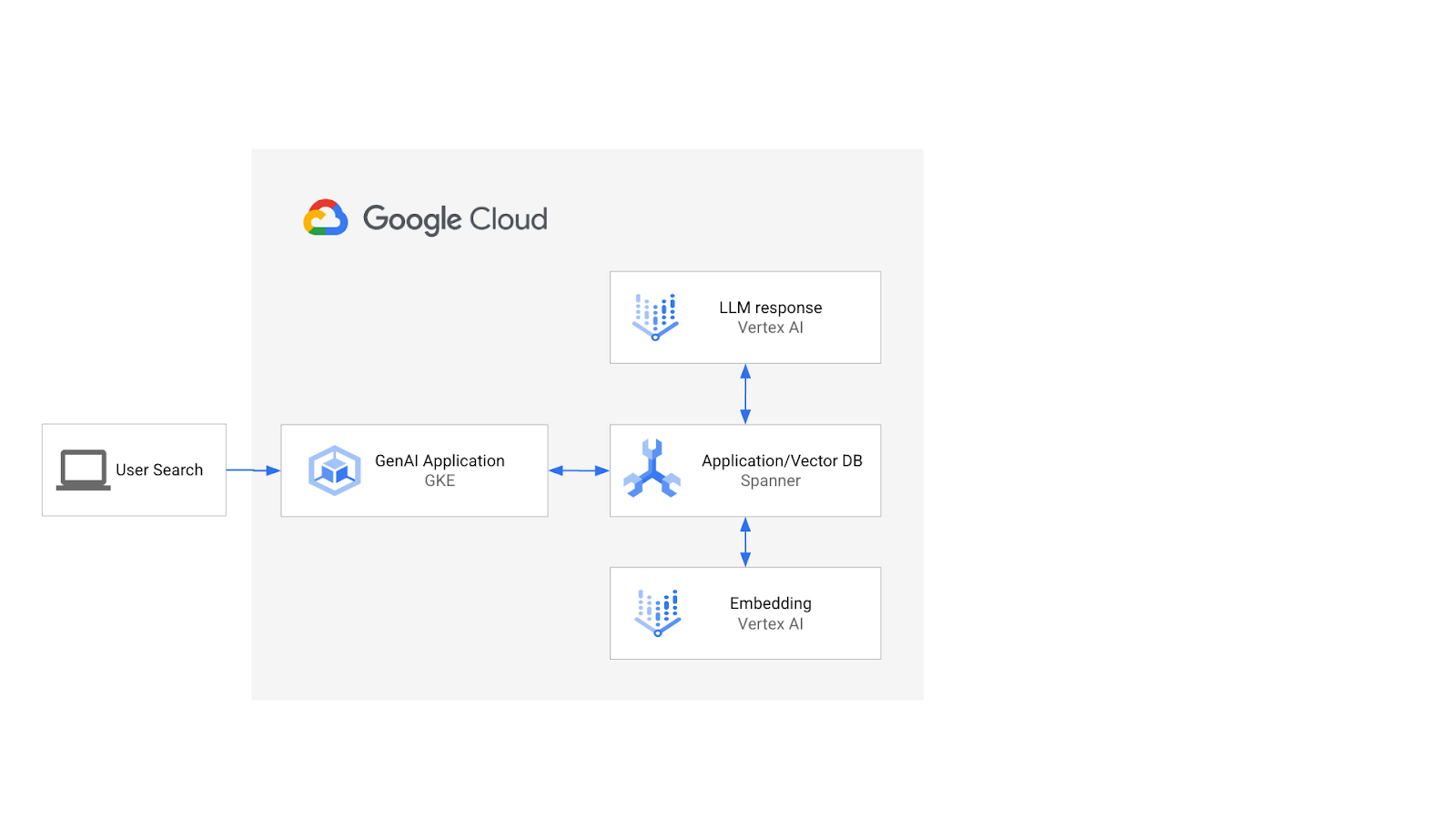
על בסיס זה, תלמדו איך ליצור אינדקס וקטורי שמגובה על ידי אלגוריתם ScaNN, ואיך להשתמש בפונקציות של מרחק משוער כשעומסי העבודה הסמנטיים שלכם צריכים להתרחב.
מה תפַתחו
במסגרת ה-Lab הזה:
- יצירת מופע Spanner
- הגדרת סכימת מסד הנתונים של Spanner לשילוב עם מודלים של הטמעה ו-LLM ב-Vertex AI
- טעינה של קבוצת נתונים קמעונאיים
- הנפקת שאילתות חיפוש של בעיות מול מערך הנתונים
- מספקים הקשר למודל ה-LLM כדי ליצור המלצות ספציפיות למוצרים.
- משנים את הסכימה ויוצרים אינדקס וקטורי.
- משנים את השאילתות כדי להשתמש באינדקס הווקטורי החדש שנוצר.
מה תלמדו
- איך מגדירים מופע Spanner
- איך משתלבים עם VertexAI
- איך משתמשים ב-Spanner כדי לבצע חיפוש וקטורי ולמצוא פריטים דומים במערך נתונים קמעונאי
- איך מכינים את מסד הנתונים להרחבת עומסי עבודה של חיפוש וקטורי באמצעות חיפוש ANN.
הדרישות
2. הגדרה ודרישות
יצירת פרויקט
אם עדיין אין לכם חשבון Google (Gmail או Google Apps), אתם צריכים ליצור חשבון. נכנסים אל Google Cloud Platform Console ( console.cloud.google.com) ויוצרים פרויקט חדש.
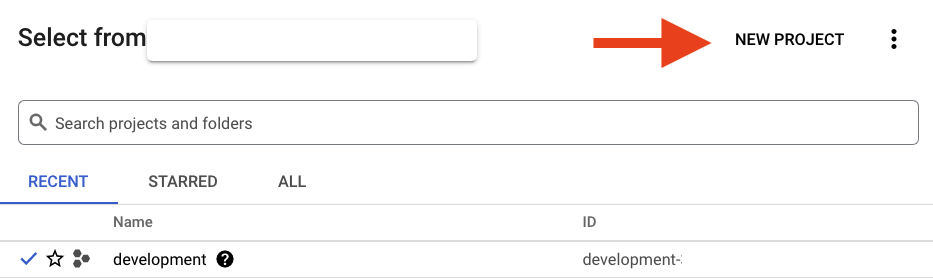
אם כבר יש לכם פרויקט, לוחצים על התפריט הנפתח לבחירת פרויקט בפינה הימנית העליונה של המסוף:

ולוחצים על הלחצן 'פרויקט חדש' בתיבת הדו-שיח שמופיעה כדי ליצור פרויקט חדש:
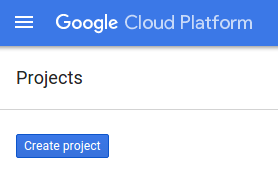
אם עדיין אין לכם פרויקט, תופיע תיבת דו-שיח כמו זו שמוצגת כאן, שבה תוכלו ליצור את הפרויקט הראשון:
בתיבת הדו-שיח הבאה ליצירת פרויקט, אפשר להזין את הפרטים של הפרויקט החדש:
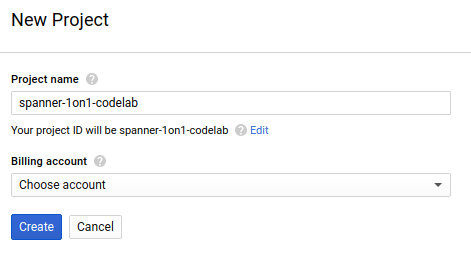
חשוב לזכור את מזהה הפרויקט, שהוא שם ייחודי בכל הפרויקטים ב-Google Cloud (השם שלמעלה כבר תפוס ולא יתאים לכם, מצטערים!). בהמשך ה-Codelab הזה, הוא יופיע בתור PROJECT_ID.
בשלב הבא, אם עדיין לא עשיתם זאת, תצטרכו להפעיל את החיוב במסוף למפתחים כדי להשתמש במשאבים של Google Cloud ולהפעיל את Spanner API.
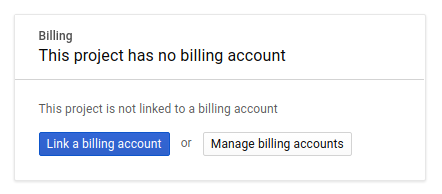
העלות של ה-Codelab הזה לא אמורה להיות גבוהה, אבל היא יכולה להיות גבוהה יותר אם תחליטו להשתמש ביותר משאבים או אם תשאירו אותם פועלים (ראו את הקטע 'ניקוי נתונים' בסוף המסמך הזה). מידע על התמחור של Google Cloud Spanner מופיע כאן.
משתמשים חדשים ב-Google Cloud Platform זכאים לתקופת ניסיון בחינם בשווי 300$, כך ששיעור ה-Codelab הזה יהיה בחינם לגמרי.
הגדרה של Google Cloud Shell
אפשר להפעיל את Google Cloud ואת Spanner מרחוק מהמחשב הנייד, אבל ב-Codelab הזה נשתמש ב-Google Cloud Shell, סביבת שורת פקודה שפועלת ב-Cloud.
המכונה הווירטואלית הזו מבוססת על Debian, וטעונים בה כל הכלים הדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות של הרשת. כלומר, כל מה שצריך כדי לבצע את ההדרכה הזו הוא דפדפן (כן, היא פועלת ב-Chromebook).
- כדי להפעיל את Cloud Shell ממסוף Cloud, פשוט לוחצים על 'הפעלת Cloud Shell'
 (הקצאת המשאבים והחיבור לסביבה אמורים להימשך רק כמה רגעים).
(הקצאת המשאבים והחיבור לסביבה אמורים להימשך רק כמה רגעים).
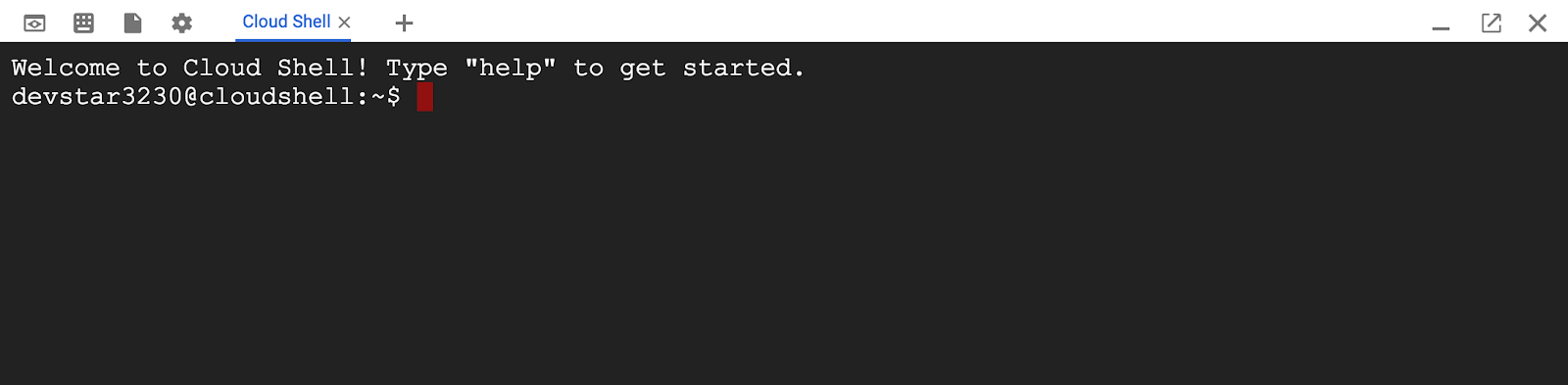
אחרי שמתחברים ל-Cloud Shell, אפשר לראות שהאימות כבר בוצע והפרויקט כבר הוגדר לפי PROJECT_ID.
gcloud auth list
פלט הפקודה
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
פלט הפקודה
[core]
project = <PROJECT_ID>
אם מסיבה כלשהי הפרויקט לא מוגדר, פשוט מריצים את הפקודה הבאה:
gcloud config set project <PROJECT_ID>
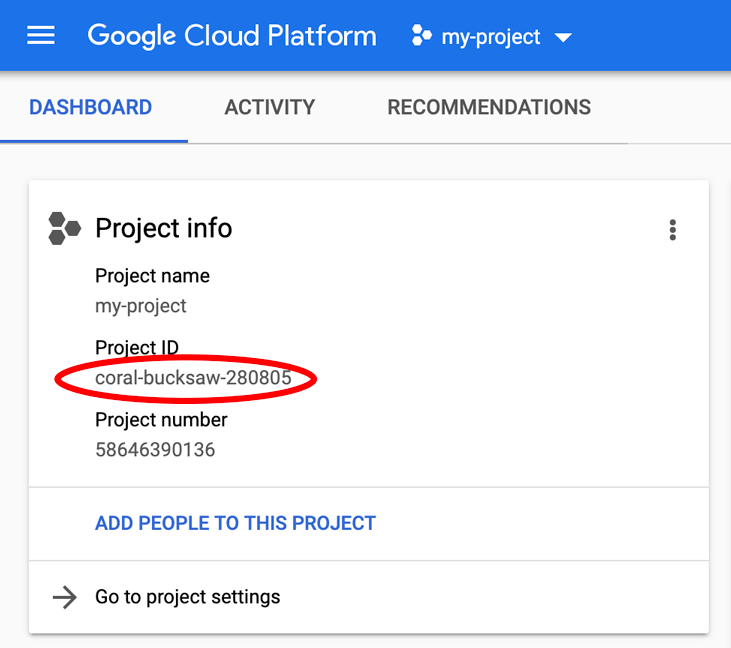
חיפשת את PROJECT_ID? בודקים באיזה מזהה השתמשתם בשלבי ההגדרה או מחפשים אותו בלוח הבקרה של Cloud Console:
ב-Cloud Shell מוגדרים גם כמה משתני סביבה כברירת מחדל, שיכולים להיות שימושיים כשמריצים פקודות בעתיד.
echo $GOOGLE_CLOUD_PROJECT
פלט הפקודה
<PROJECT_ID>
הפעלת Spanner API
gcloud services enable spanner.googleapis.com
סיכום
בשלב הזה הגדרתם את הפרויקט אם עדיין לא היה לכם פרויקט, הפעלתם את Cloud Shell והפעלתם את ממשקי ה-API הנדרשים.
הבאים בתור
בשלב הבא תגדירו את מכונת Spanner ואת מסד הנתונים.
3. יצירת מכונה ומסד נתונים ב-Spanner
יצירת מכונת Spanner
בשלב הזה מגדירים את מכונת Spanner לשיעור ה-Codelab. כדי לעשות זאת, פותחים את Cloud Shell ומריצים את הפקודה הבאה:
export SPANNER_INSTANCE_ID=retail-demo
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
--edition=ENTERPRISE
פלט הפקודה:
$ gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
--edition=ENTERPRISE
Creating instance...done.
יצירת מסד הנתונים
אחרי שהמופע פועל, אפשר ליצור את מסד הנתונים. ב-Spanner אפשר ליצור כמה מסדי נתונים במופע אחד.
במסד הנתונים מגדירים את הסכימה. אפשר גם לקבוע למי יש גישה למסד הנתונים, להגדיר הצפנה בהתאמה אישית, להגדיר את הכלי לאופטימיזציה ולקבוע את תקופת השמירה.
כדי ליצור את מסד הנתונים, משתמשים שוב בכלי שורת הפקודה gcloud:
export SPANNER_DATABASE=cymbal-bikes
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
פלט הפקודה:
$ gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Creating database...done.
סיכום
בשלב הזה יצרתם את המכונה ואת מסד הנתונים של Spanner.
הבאים בתור
בשלב הבא, מגדירים את הסכימה והנתונים של Spanner.
4. טעינת הסכימה והנתונים של Cymbal
יצירת סכימת Cymbal
כדי להגדיר את הסכימה, עוברים אל Spanner Studio:
הסכימה מורכבת משני חלקים. קודם כול, מוסיפים את הטבלה products. מעתיקים את ההצהרה הזו ומדביקים אותה בכרטיסייה הריקה.
מעתיקים ומדביקים את ה-DDL הבא בתיבה של הסכימה:
CREATE TABLE products (
categoryId INT64 NOT NULL,
productId INT64 NOT NULL,
productName STRING(MAX) NOT NULL,
productDescription STRING(MAX) NOT NULL,
productDescriptionEmbedding ARRAY<FLOAT32>,
createTime TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
inventoryCount INT64 NOT NULL,
priceInCents INT64,
) PRIMARY KEY(categoryId, productId);
אחר כך לוחצים על הלחצן run ומחכים כמה שניות עד ליצירת הסכימה.
בשלב הבא, תיצרו את שני המודלים ותגדירו אותם לנקודות קצה של מודלים ב-Vertex AI.
המודל הראשון הוא מודל הטמעה שמשמש ליצירת הטמעות מטקסט, והמודל השני הוא מודל LLM שמשמש ליצירת תשובות על סמך הנתונים ב-Spanner.
מדביקים את הסכימה הבאה בכרטיסייה חדשה ב-Spanner Studio:
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-004'
);
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-3.1-pro-preview',
default_batch_size = 1
);
לאחר מכן לוחצים על לחצן run וממתינים כמה שניות עד ליצירת המודלים.
בחלונית הימנית של Spanner Studio אמורות להופיע הטבלאות והמודלים הבאים:
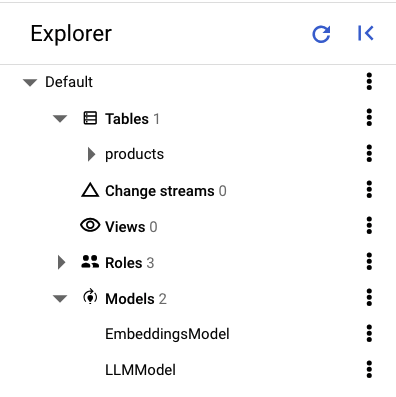
טעינת הנתונים
עכשיו כדאי להוסיף כמה מוצרים למסד הנתונים. פותחים כרטיסייה חדשה ב-Spanner Studio, ואז מעתיקים ומדביקים את הצהרות ההוספה הבאות:
INSERT INTO products (categoryId, productId, productName, productDescription, createTime, inventoryCount, priceInCents)
VALUES (1, 1, "Cymbal Helios Helmet", "Safety meets style with the Cymbal children's bike helmet. Its lightweight design, superior ventilation, and adjustable fit ensure comfort and protection on every ride. Stay bright and keep your child safe under the sun with Cymbal Helios!", PENDING_COMMIT_TIMESTAMP(), 100, 10999),
(1, 2, "Cymbal Sprout", "Let their cycling journey begin with the Cymbal Sprout, the ideal balance bike for beginning riders ages 2-4 years. Its lightweight frame, low seat height, and puncture-proof tires promote stability and confidence as little ones learn to balance and steer. Watch them sprout into cycling enthusiasts with Cymbal Sprout!", PENDING_COMMIT_TIMESTAMP(), 10, 13999),
(1, 3, "Cymbal Spark Jr.", "Light, vibrant, and ready for adventure, the Spark Jr. is the perfect first bike for young riders (ages 5-8). Its sturdy frame, easy-to-use brakes, and puncture-resistant tires inspire confidence and endless playtime. Let the spark of cycling ignite with Cymbal!", PENDING_COMMIT_TIMESTAMP(), 34, 13900),
(1, 4, "Cymbal Summit", "Conquering trails is a breeze with the Summit mountain bike. Its lightweight aluminum frame, responsive suspension, and powerful disc brakes provide exceptional control and comfort for experienced bikers navigating rocky climbs or shredding downhill. Reach new heights with Cymbal Summit!", PENDING_COMMIT_TIMESTAMP(), 0, 79999),
(1, 5, "Cymbal Breeze", "Cruise in style and embrace effortless pedaling with the Breeze electric bike. Its whisper-quiet motor and long-lasting battery let you conquer hills and distances with ease. Enjoy scenic rides, commutes, or errands with a boost of confidence from Cymbal Breeze!", PENDING_COMMIT_TIMESTAMP(), 72, 129999),
(1, 6, "Cymbal Trailblazer Backpack", "Carry all your essentials in style with the Trailblazer backpack. Its water-resistant material, multiple compartments, and comfortable straps keep your gear organized and accessible, allowing you to focus on the adventure. Blaze new trails with Cymbal Trailblazer!", PENDING_COMMIT_TIMESTAMP(), 24, 7999),
(1, 7, "Cymbal Phoenix Lights", "See and be seen with the Phoenix bike lights. Powerful LEDs and multiple light modes ensure superior visibility, enhancing your safety and enjoyment during day or night rides. Light up your journey with Cymbal Phoenix!", PENDING_COMMIT_TIMESTAMP(), 87, 3999),
(1, 8, "Cymbal Windstar Pump", "Flat tires are no match for the Windstar pump. Its compact design, lightweight construction, and high-pressure capacity make inflating tires quick and effortless. Get back on the road in no time with Cymbal Windstar!", PENDING_COMMIT_TIMESTAMP(), 36, 24999),
(1, 9,"Cymbal Odyssey Multi-Tool","Be prepared for anything with the Odyssey multi-tool. This handy gadget features essential tools like screwdrivers, hex wrenches, and tire levers, keeping you ready for minor repairs and adjustments on the go. Conquer your journey with Cymbal Odyssey!", PENDING_COMMIT_TIMESTAMP(), 52, 999),
(1, 10,"Cymbal Nomad Water Bottle","Stay hydrated on every ride with the Nomad water bottle. Its sleek design, BPA-free construction, and secure lock lid make it the perfect companion for staying refreshed and motivated throughout your adventures. Hydrate and explore with Cymbal Nomad!", PENDING_COMMIT_TIMESTAMP(), 42, 1299);
לוחצים על הלחצן run כדי להוסיף את הנתונים.
סיכום
בשלב הזה יצרתם את הסכמה וטענתם נתונים בסיסיים למסד הנתונים cymbal-bikes.
הבאים בתור
לאחר מכן, תבצעו שילוב עם מודל ההטמעה כדי ליצור הטמעות לתיאורי המוצרים, וגם כדי להמיר בקשת חיפוש טקסטואלית להטמעה כדי לחפש מוצרים רלוונטיים.
5. עבודה עם הטמעות
יצירת הטמעות וקטוריות לתיאורי מוצרים
כדי שהחיפוש לפי דמיון יפעל על המוצרים, צריך ליצור הטמעות לתיאורי המוצרים.
עם EmbeddingsModel שנוצר בסכימה, זוהי פקודת DML פשוטה של UPDATE.
UPDATE products p1
SET productDescriptionEmbedding =
(SELECT embeddings.values from ML.PREDICT(MODEL EmbeddingsModel,
(SELECT productDescription as content FROM products p2 where p2.productId=p1.productId)))
WHERE categoryId=1;
לוחצים על הלחצן run כדי לעדכן את תיאורי המוצרים.
שימוש בחיפוש וקטורי
בדוגמה הזו, תספקו בקשת חיפוש בשפה טבעית באמצעות שאילתת SQL. השאילתה הזו תמיר את בקשת החיפוש להטמעה, ואז תחפש תוצאות דומות על סמך ההטמעות המאוחסנות של תיאורי המוצרים שנוצרו בשלב הקודם.
-- Use Spanner's vector search, and integration with embedding and LLM models to
-- return items that are semantically relevant and available in inventory based on
-- real-time data.
SELECT productName, productDescription, inventoryCount, COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) as distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
לוחצים על הלחצן run כדי למצוא את המוצרים הדומים. התוצאות אמורות להיראות כך:
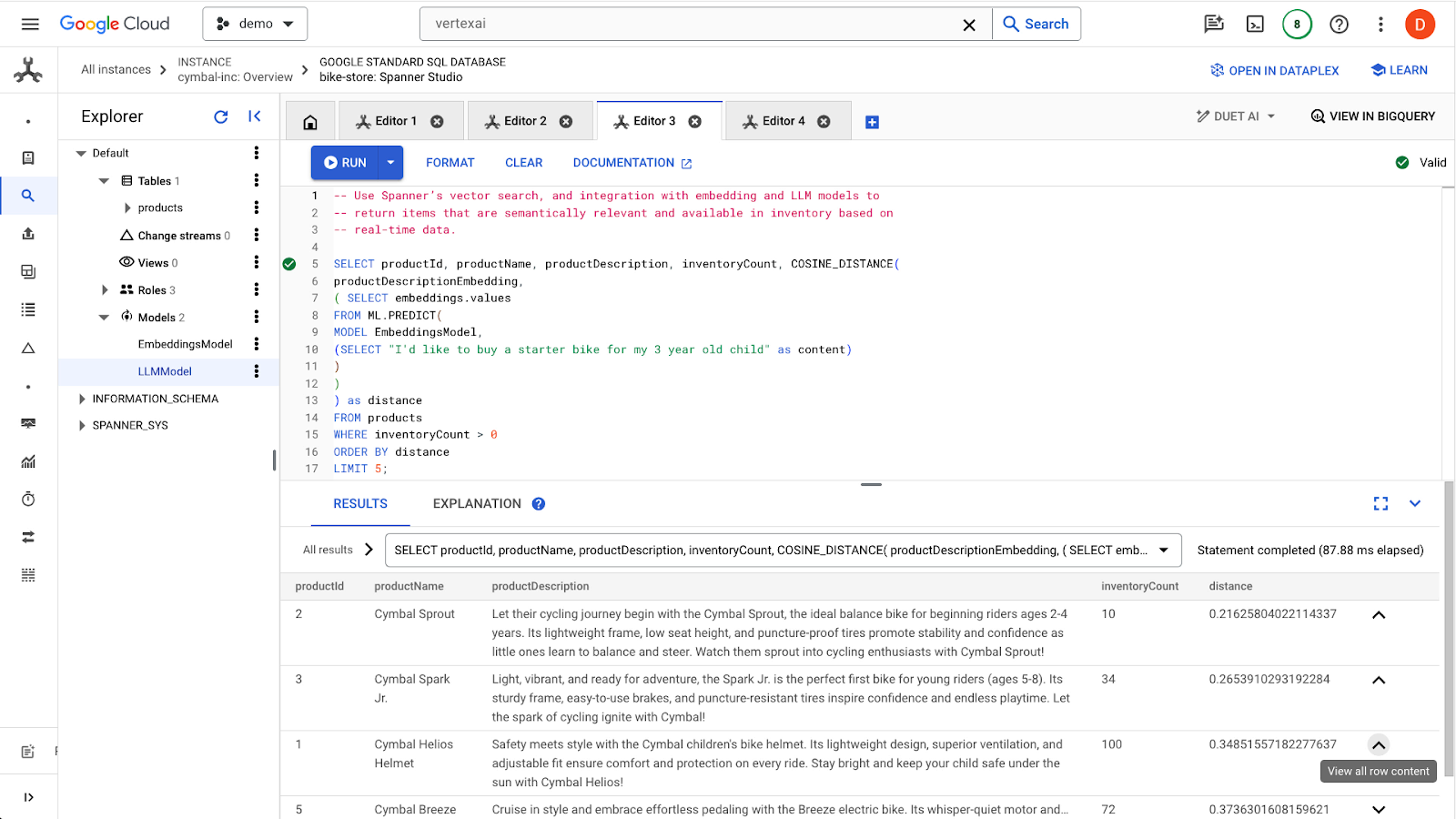
שימו לב שנעשה שימוש במסננים נוספים בשאילתה, למשל רק מוצרים שנמצאים במלאי (inventoryCount > 0).
סיכום
בשלב הזה, יצרתם הטמעות של תיאורי מוצרים והטמעה של בקשת חיפוש באמצעות SQL, תוך שימוש בשילוב של Spanner עם מודלים ב-Vertex AI. בנוסף, מתבצע חיפוש וקטורי כדי למצוא מוצרים דומים שתואמים לבקשת החיפוש.
השלבים הבאים
עכשיו נשתמש בתוצאות החיפוש כדי להזין אותן ל-LLM וליצור תשובה מותאמת אישית לכל מוצר.
6. עבודה עם LLM
קל לשלב את Spanner עם מודלים של LLM שמופעלים מ-VertexAI. כך המפתחים יכולים להשתמש ב-SQL כדי ליצור ממשק ישירות עם מודלים של שפה גדולה (LLM), במקום לדרוש מהאפליקציה לבצע את הלוגיקה.
לדוגמה, יש לנו את התוצאות משאילתת ה-SQL הקודמת מהמשתמש "I'd like to buy a starter bike for my 3 year old child".
המפתח רוצה לספק תשובה לכל תוצאה לגבי מידת ההתאמה של המוצר למשתמש, באמצעות ההנחיה הבאה:
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me? I'd like to buy a starter bike for my 3 year old child"
זו השאילתה שבה אפשר להשתמש:
-- Use an LLM to analyze this list and provide a recommendation on whether each
-- product is a good fit for the user. We use the vector search and real time
-- inventory data to first filter the products to reduce the size of the prompt to
-- the LLM.
SELECT productName, productDescription, inventoryCount, content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
( SELECT
inventoryCount,
productName,
productDescription,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a starter bike for my 3 year old child \n",
"Product Name: ", productName, "\n",
"Product Description:", productDescription) AS prompt,
FROM products
WHERE inventoryCount > 0
ORDER by COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
( SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) LIMIT 5
),
STRUCT(256 AS maxOutputTokens)
);
לוחצים על הלחצן run כדי להריץ את השאילתה. התוצאות אמורות להיראות כך:
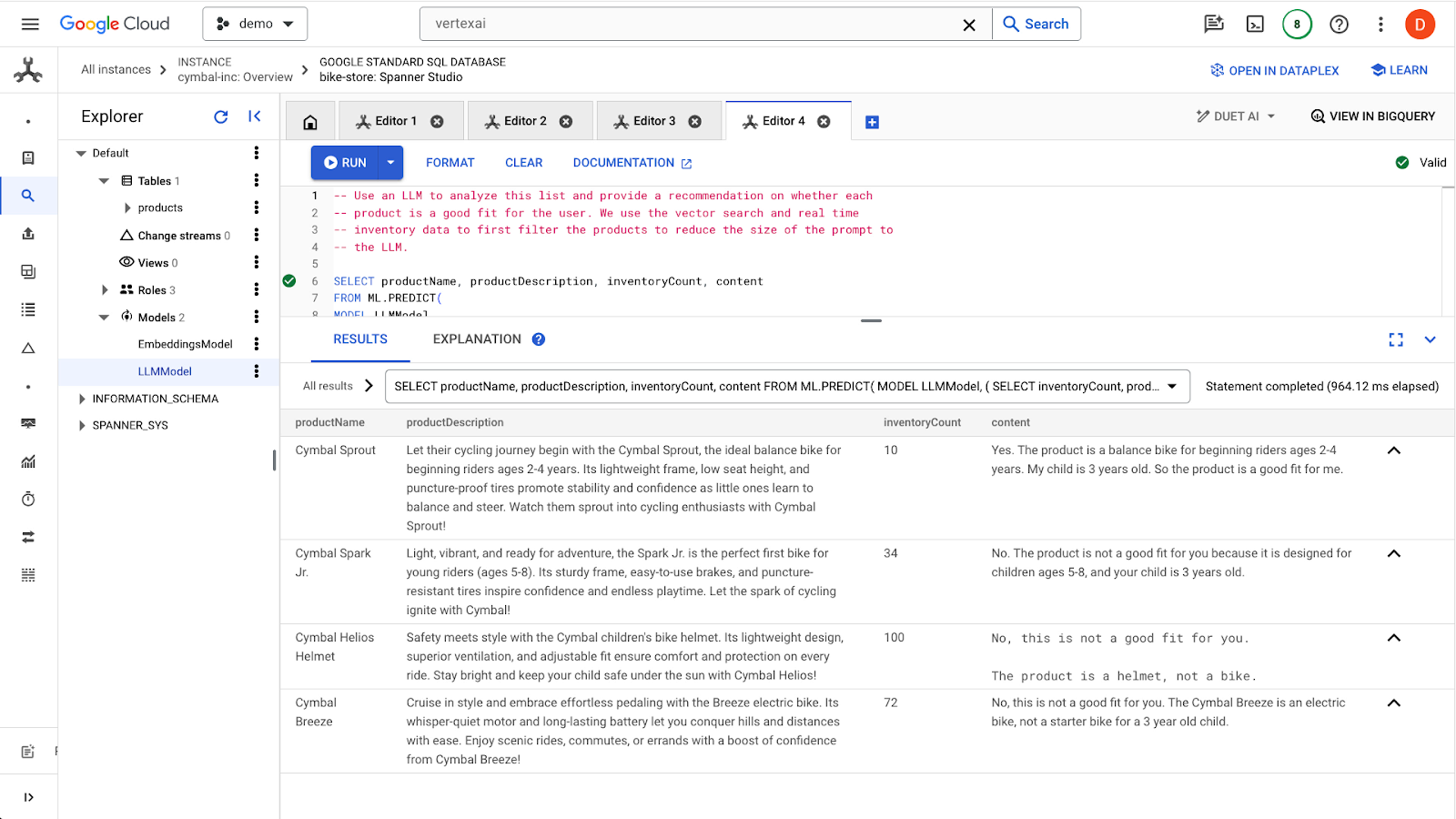
המוצר הראשון מתאים לילדים בני 3 בגלל טווח הגילאים שמופיע בתיאור המוצר (ילדים בני שנתיים עד 4). המוצרים האחרים לא מתאימים במיוחד.
סיכום
בשלב הזה, עבדתם עם LLM כדי ליצור תשובות בסיסיות להנחיות ממשתמש.
השלבים הבאים
בשלב הבא נלמד איך להשתמש ב-ANN כדי להרחיב את החיפוש הווקטורי.
7. התאמה להיקף של חיפוש וקטורי
בדוגמאות הקודמות לחיפוש וקטורי נעשה שימוש בחיפוש וקטורי מדויק של KNN. האפשרות הזו מצוינת כשאתם יכולים להריץ שאילתות על קבוצות משנה ספציפיות מאוד של נתוני Spanner. סוגי השאילתות האלה מוגדרים כניתנות לחלוקה גבוהה.
אם אין לכם עומסי עבודה שניתנים לחלוקה למחיצות, ויש לכם כמות גדולה של נתונים, כדאי להשתמש בחיפוש וקטורי של ANN באמצעות אלגוריתם ScaNN כדי לשפר את ביצועי החיפוש.
כדי לעשות את זה ב-Spanner, צריך לבצע שני דברים:
- יצירת אינדקס וקטורי
- משנים את השאילתה כך שתשתמש בפונקציות המרחק APPROX.
יצירת אינדקס וקטורי
כדי ליצור אינדקס וקטורי בקבוצת הנתונים הזו, קודם נצטרך לשנות את העמודה productDescriptionEmbeddings כדי להגדיר את האורך של כל וקטור. כדי להוסיף את אורך הווקטור לעמודה, צריך להסיר את העמודה המקורית וליצור אותה מחדש.
ALTER TABLE `products` DROP COLUMN `productDescriptionEmbedding`;
ALTER TABLE
`products` ADD COLUMN `productDescriptionEmbedding` ARRAY<FLOAT32>(vector_length=>768);
לאחר מכן, יוצרים שוב את ההטמעות מהשלב Generate Vector embedding שהפעלתם קודם.
UPDATE products p1
SET productDescriptionEmbedding =
(SELECT embeddings.values from ML.PREDICT(MODEL EmbeddingsModel,
(SELECT productDescription as content FROM products p2 where p2.productId=p1.productId)))
WHERE categoryId=1;
אחרי שיוצרים את העמודה, יוצרים את האינדקס:
CREATE VECTOR INDEX ProductDescriptionEmbeddingIndex
ON products(productDescriptionEmbedding)
WHERE productDescriptionEmbedding IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
שימוש באינדקס החדש
כדי להשתמש באינדקס הווקטורי החדש, תצטרכו לשנות מעט את שאילתת ההטמעה הקודמת.
זו השאילתה המקורית:
SELECT productName, productDescription, inventoryCount, COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) as distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
תצטרכו לבצע את השינויים הבאים:
- משתמשים ברמז לאינדקס עבור אינדקס הווקטורים החדש:
@{force_index=ProductDescriptionEmbeddingIndex} - משנים את הקריאה לפונקציה
COSINE_DISTANCEל-APPROX_COSINE_DISTANCE. שימו לב: גם האפשרויות בפורמט JSON שמופיעות בשאילתה הסופית למטה הן חובה. - צריך ליצור את ההטמעות בנפרד באמצעות הפונקציה ML.PREDICT.
- מעתיקים את תוצאות ההטמעות לשאילתה הסופית.
יצירת ההטמעות
-- Generate the prompt embeddings
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
מסמנים את התוצאות מהשאילתה ומעתיקים אותן.
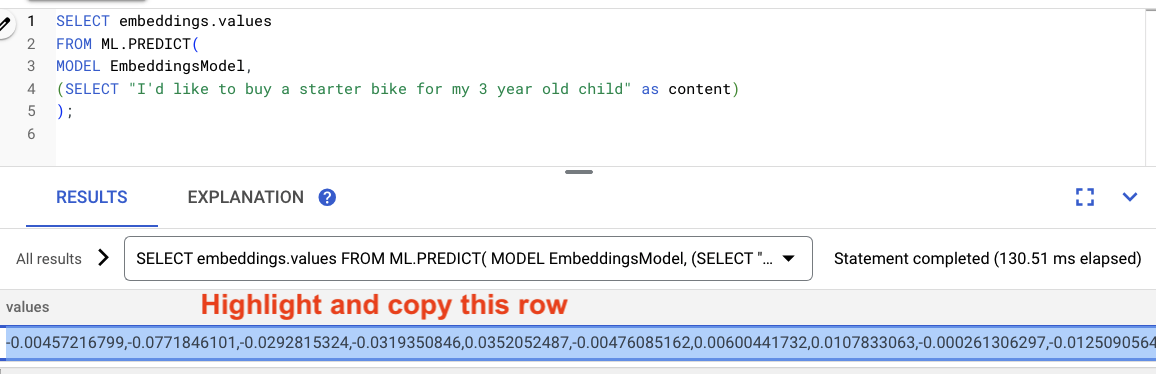
אחר כך, מחליפים את <VECTOR> בשאילתה הבאה על ידי הדבקת הווקטורים שהעתקתם.
-- Embedding query now using the vector index
SELECT productName, productDescription, inventoryCount,
APPROX_COSINE_DISTANCE(productDescriptionEmbedding, array<float32>[@VECTOR], options => JSON '{\"num_leaves_to_search\": 10}')
FROM products @{force_index=ProductDescriptionEmbeddingIndex}
WHERE productDescriptionEmbedding IS NOT NULL AND inventoryCount > 0
ORDER BY distance
LIMIT 5;
הוא אמור להיראות כך:
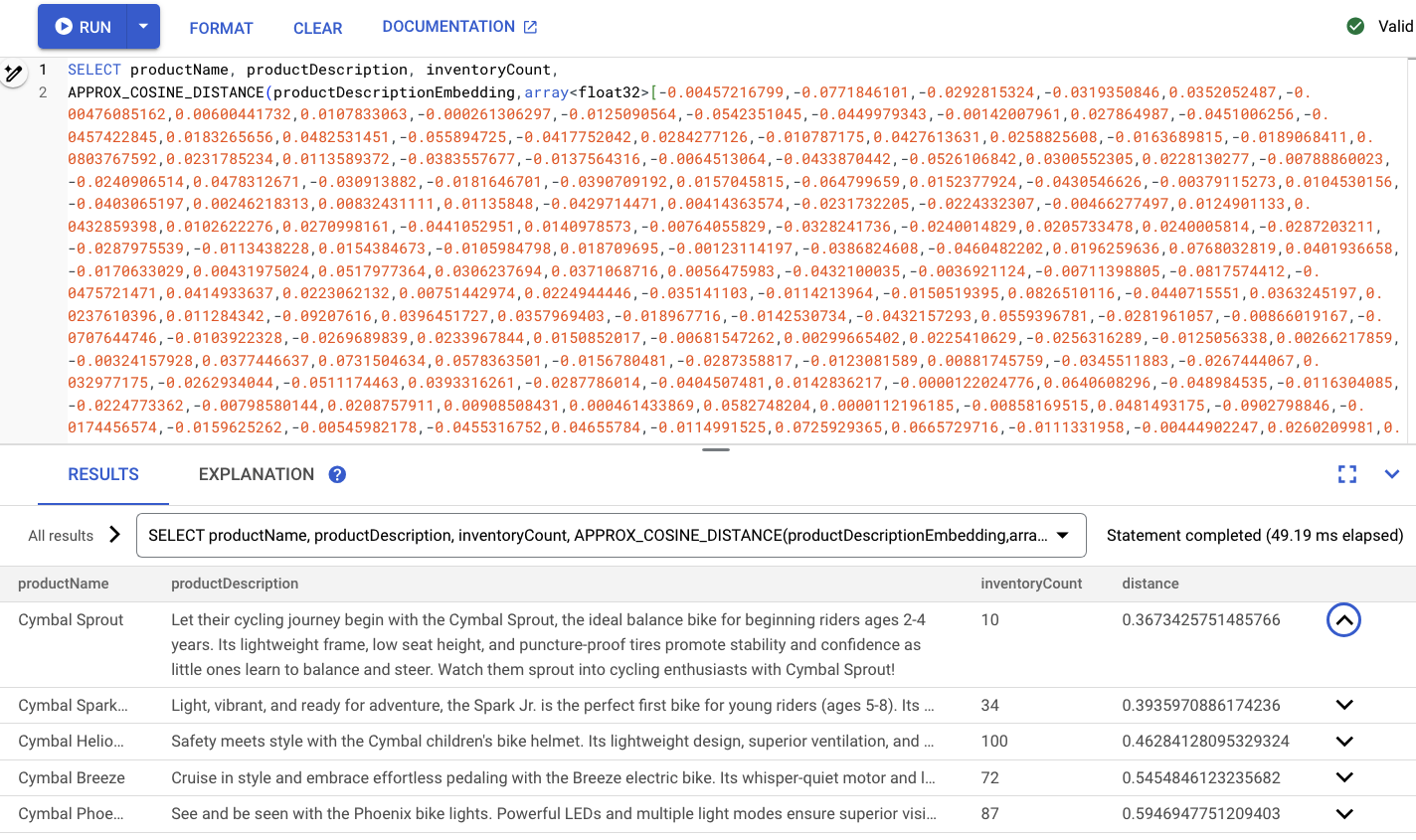
סיכום
בשלב הזה המרתם את הסכימה כדי ליצור אינדקס וקטורי. ואז כתבת מחדש את שאילתת ההטמעה כדי לבצע חיפוש ANN באמצעות אינדקס הווקטורים. זהו שלב חשוב, כי ככל שהנתונים גדלים, עומסי העבודה של חיפוש וקטורי גדלים בהתאם.
השלבים הבאים
עכשיו הגיע הזמן לנקות!
8. ניקוי (אופציונלי)
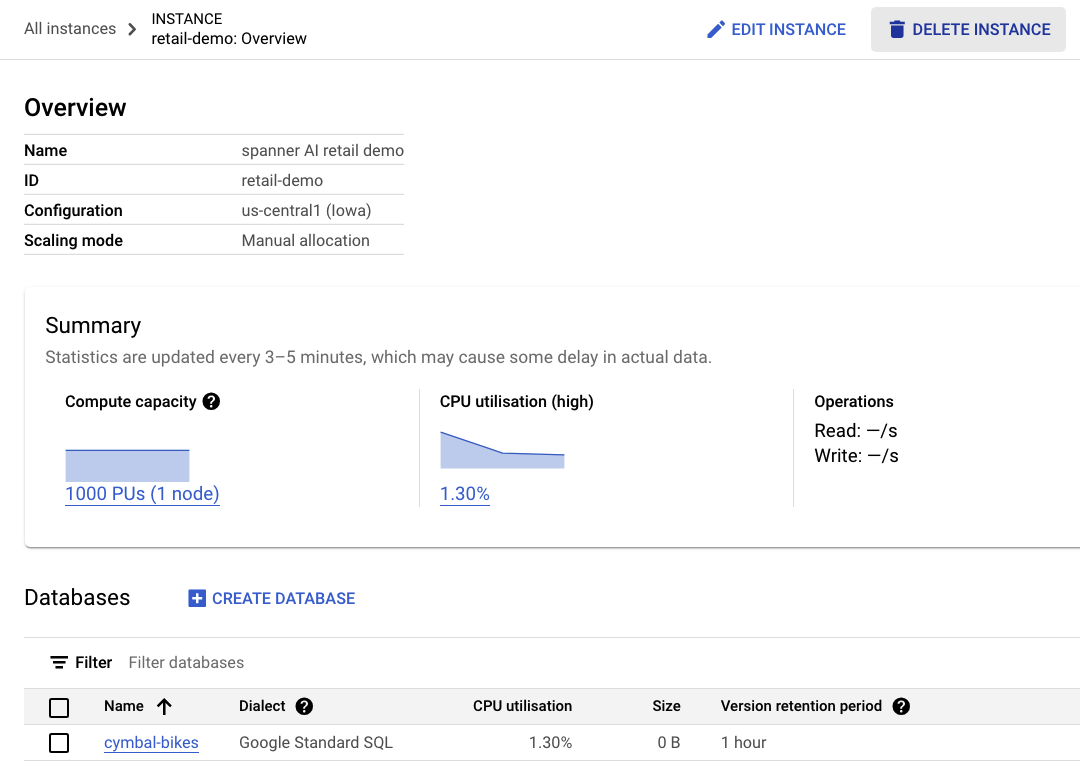
כדי לנקות, פשוט נכנסים אל הקטע Cloud Spanner ב-Cloud Console ומוחקים את מופע 'retail-demo' שיצרנו ב-codelab.
9. מעולה!
הצלחת לבצע חיפוש דמיון באמצעות חיפוש וקטורי מובנה ב-Spanner. בנוסף, ראיתם כמה קל לעבוד עם הטמעה ומודלים של LLM כדי לספק פונקציונליות של AI גנרטיבי ישירות באמצעות SQL.
לבסוף, למדתם את התהליך לביצוע חיפוש ANN שמבוסס על האלגוריתם ScaNN לצורך הרחבת עומסי עבודה של חיפוש וקטורים.
מה השלב הבא?
מידע נוסף על התכונה 'חיפוש וקטורים של k השכנים הקרובים ביותר (KNN)' ב-Spanner זמין כאן: https://cloud.google.com/spanner/docs/find-k-nearest-neighbors
מידע נוסף על התכונה של Spanner לחיפוש וקטורים של שכנים קרובים משוערים (ANN) זמין כאן: https://cloud.google.com/spanner/docs/find-approximate-nearest-neighbors
בקישור הבא אפשר לקרוא מידע נוסף על ביצוע תחזיות אונליין באמצעות SQL באמצעות השילוב של Spanner עם VertexAI: https://cloud.google.com/spanner/docs/ml