
1. はじめに
Spanner は、リレーショナル ワークロードと非リレーショナル ワークロードの両方に適した、フルマネージドで水平スケーリング可能なグローバルに分散されたデータベース サービスです。
Spanner にはベクトル検索のサポートが組み込まれており、厳密な K 近傍法(KNN)または近似最近傍法(ANN)の機能を利用して、類似性検索やセマンティック検索を実行し、GenAI アプリケーションで検索拡張生成(RAG)を大規模に実装できます。
Spanner のベクトル検索クエリは、オペレーショナル データに対する一般的なクエリと同じように、トランザクションがコミットされると同時に、リアルタイムで最新のデータを返します。
このラボでは、Spanner を活用してベクトル検索を実行し、SQL を使用して Vertex AI の Model Garden からエンベディング モデルと LLM モデルにアクセスするために必要な基本機能を設定する手順を説明します。
アーキテクチャは次のようになります。
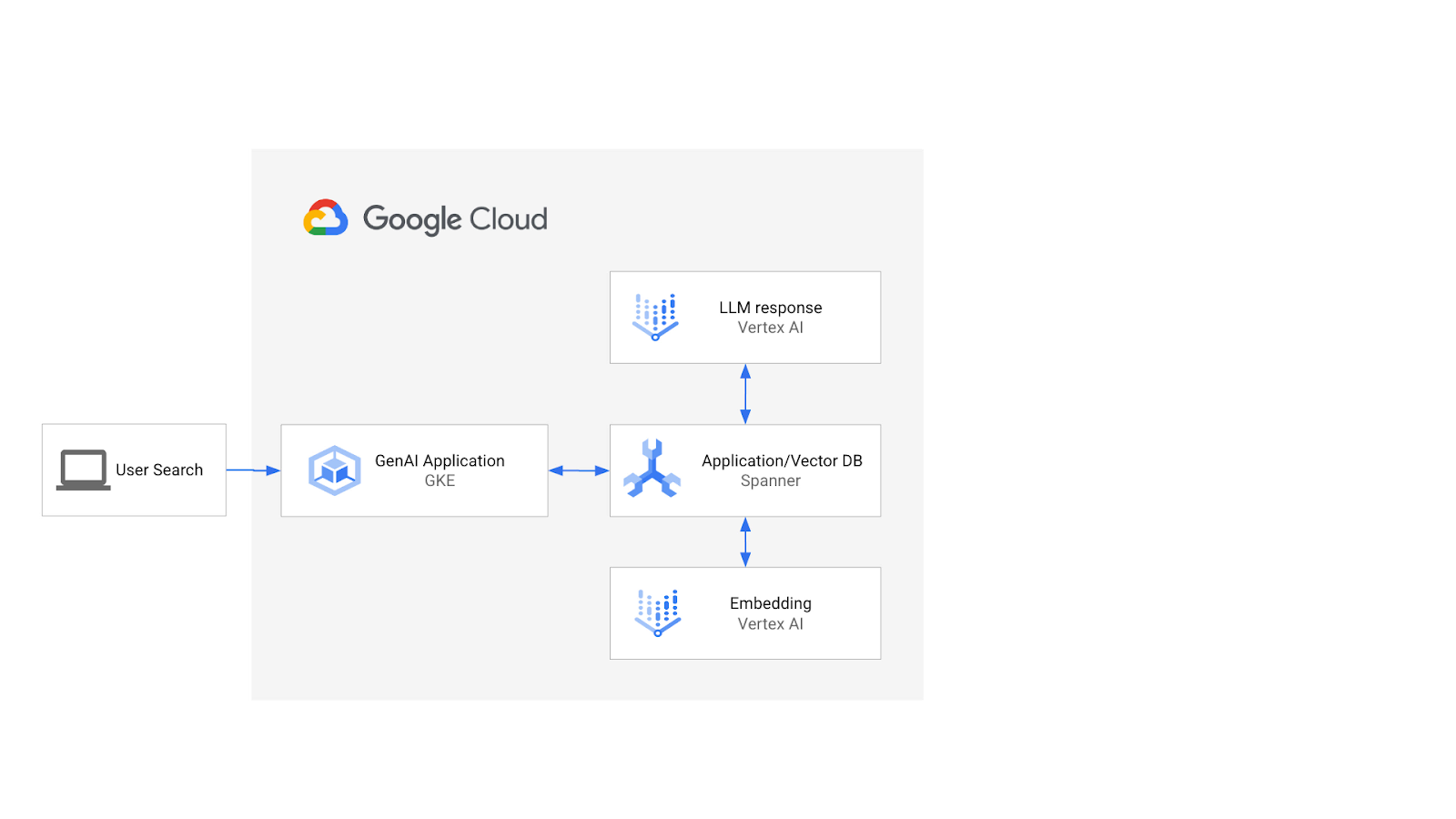
この基盤を基に、ScaNN アルゴリズムでサポートされるベクトル インデックスを作成する方法と、セマンティック ワークロードをスケーリングする必要がある場合に APPROX 距離関数を使用する方法について説明します。
作成するアプリの概要
このラボでは、次の作業を行います。
- Spanner インスタンスの作成
- VertexAI のエンベディング モデルと LLM モデルを統合するように Spanner のデータベース スキーマを設定する
- 小売データセットを読み込む
- データセットに対して類似性検索クエリを発行する
- LLM モデルにコンテキストを提供して、プロダクト固有のおすすめを生成します。
- スキーマを変更してベクトル インデックスを作成します。
- 新しく作成したベクトル インデックスを活用するようにクエリを変更します。
学習内容
- Spanner インスタンスの設定方法
- VertexAI と統合する方法
- Spanner を使用してベクトル検索を実行し、小売データセット内の類似アイテムを見つける方法
- ANN 検索を使用してベクトル検索ワークロードをスケーリングするようにデータベースを準備する方法。
必要なもの
2. 設定と要件
プロジェクトを作成する
Google アカウント(Gmail または Google Apps)をお持ちでない場合は、1 つ作成する必要があります。Google Cloud Platform のコンソール(console.cloud.google.com)にログインし、新しいプロジェクトを作成します。
すでにプロジェクトが存在する場合は、コンソールの左上にあるプロジェクト選択プルダウン メニューをクリックします。

表示されたダイアログで [NEW PROJECT] ボタンをクリックして、新しいプロジェクトを作成します。
まだプロジェクトが存在しない場合は、次のような最初のプロジェクトを作成するためのダイアログが表示されます。
続いて表示されるプロジェクト作成ダイアログでは、新しいプロジェクトの詳細を入力できます。
プロジェクト ID を忘れないようにしてください。プロジェクト ID は、すべての Google Cloud プロジェクトを通じて一意の名前にする必要があります(上記の名前はすでに使用されているため使用できません)。以降、この Codelab では PROJECT_ID と呼びます。
次に、Google Cloud リソースを使用し、Spanner API を有効にするために、Developers Console で課金を有効にする必要があります。
この Codelab の操作をすべて行っても、費用は数ドル程度です。ただし、その他のリソースを使いたい場合や、実行したままにしておきたいステップがある場合は、追加コストがかかる可能性があります(このドキュメントの最後にある「クリーンアップ」セクションを参照)。Google Cloud Spanner の料金については、こちらをご覧ください。
Google Cloud Platform の新規ユーザーの皆さんには、$300 の無料トライアルをご利用いただけます。その場合は、この Codelab を完全に無料でご利用いただけます。
Google Cloud Shell の設定
Google Cloud と Spanner はノートパソコンからリモートで操作でき、この Codelab では、Google Cloud Shell(Cloud 上で動作するコマンドライン環境)を使用します。
この Debian ベースの仮想マシンには、必要な開発ツールがすべて用意されています。仮想マシンは Google Cloud で稼働し、永続的なホーム ディレクトリが 5 GB 用意されているため、ネットワークのパフォーマンスと認証が大幅に向上しています。つまり、この Codelab に必要なのはブラウザだけです(Chromebook でも動作します)。
- Cloud Console から Cloud Shell を有効にするには、[Cloud Shell をアクティブにする]
 をクリックします(環境のプロビジョニングと接続に若干時間を要します)。
をクリックします(環境のプロビジョニングと接続に若干時間を要します)。
Cloud Shell に接続すると、すでに認証は完了しており、プロジェクトに各自の PROJECT_ID が設定されています。
gcloud auth list
コマンド出力
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
コマンド出力
[core]
project = <PROJECT_ID>
なんらかの理由でプロジェクトが設定されていない場合は、次のコマンドを実行します。
gcloud config set project <PROJECT_ID>
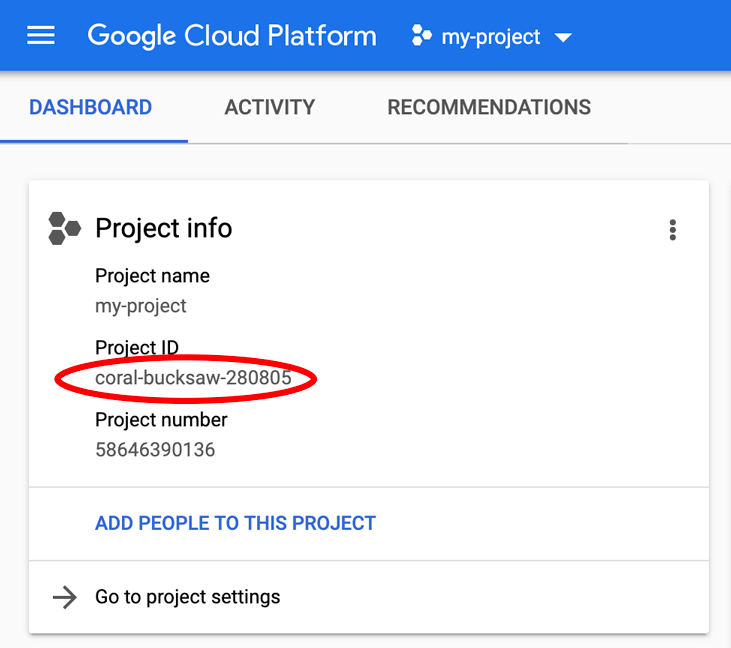
PROJECT_ID が見つからない場合は、設定手順で使用した ID を確認するか、Cloud Console ダッシュボードで検索します。
Cloud Shell では、デフォルトで環境変数もいくつか設定されます。これらの変数は、以降のコマンドを実行する際に有用なものです。
echo $GOOGLE_CLOUD_PROJECT
コマンド出力
<PROJECT_ID>
Spanner API を有効にする
gcloud services enable spanner.googleapis.com
概要
このステップでは、プロジェクトがまだない場合はプロジェクトを設定し、Cloud Shell を有効にして、必要な API を有効にしました。
次のセクション
次に、Spanner のインスタンスとデータベースを設定します。
3. Spanner のインスタンスとデータベースを作成する
Spanner インスタンスを作成する
この手順では、この Codelab 用に Spanner インスタンスを設定します。これを行うには、Cloud Shell を開いて次のコマンドを実行します。
export SPANNER_INSTANCE_ID=retail-demo
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
--edition=ENTERPRISE
コマンド出力:
$ gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
--edition=ENTERPRISE
Creating instance...done.
データベースを作成する
インスタンスが実行されたら、データベースを作成できます。Spanner では、1 つのインスタンスに複数のデータベースを作成できます。
データベースは、スキーマを定義する場所です。また、データベースにアクセスできるユーザーの制御、カスタム暗号化の設定、オプティマイザーの構成、保持期間の設定も可能です。
データベースを作成するには、もう一度 gcloud コマンドライン ツールを使用します。
export SPANNER_DATABASE=cymbal-bikes
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
コマンド出力:
$ gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Creating database...done.
概要
このステップでは、Spanner インスタンスとデータベースを作成しました。
次のセクション
次に、Spanner のスキーマとデータを設定します。
4. Cymbal のスキーマとデータを読み込む
Cymbal スキーマを作成する
スキーマを設定するには、Spanner Studio に移動します。
スキーマは 2 つの部分で構成されています。まず、products テーブルを追加します。このステートメントをコピーして、空のタブに貼り付けます。
[スキーマ] で、次の DDL をコピーしてボックスに貼り付けます。
CREATE TABLE products (
categoryId INT64 NOT NULL,
productId INT64 NOT NULL,
productName STRING(MAX) NOT NULL,
productDescription STRING(MAX) NOT NULL,
productDescriptionEmbedding ARRAY<FLOAT32>,
createTime TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
inventoryCount INT64 NOT NULL,
priceInCents INT64,
) PRIMARY KEY(categoryId, productId);
次に、run ボタンをクリックし、スキーマが作成されるまで数秒待ちます。
次に、2 つのモデルを作成し、Vertex AI モデルのエンドポイントに構成します。
最初のモデルはテキストからエンベディングを生成するために使用されるエンベディング モデルで、2 番目のモデルは Spanner のデータに基づいてレスポンスを生成するために使用される LLM モデルです。
次のスキーマを Spanner Studio の新しいタブに貼り付けます。
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-004'
);
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-3.1-pro-preview',
default_batch_size = 1
);
[run] ボタンをクリックし、モデルが作成されるまで数秒待ちます。
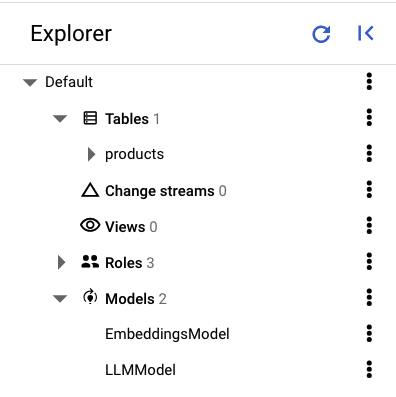
Spanner Studio の左側のペインに、次のテーブルとモデルが表示されます。
データを読み込む
次に、データベースに商品を挿入します。Spanner Studio で新しいタブを開き、次の挿入ステートメントをコピーして貼り付けます。
INSERT INTO products (categoryId, productId, productName, productDescription, createTime, inventoryCount, priceInCents)
VALUES (1, 1, "Cymbal Helios Helmet", "Safety meets style with the Cymbal children's bike helmet. Its lightweight design, superior ventilation, and adjustable fit ensure comfort and protection on every ride. Stay bright and keep your child safe under the sun with Cymbal Helios!", PENDING_COMMIT_TIMESTAMP(), 100, 10999),
(1, 2, "Cymbal Sprout", "Let their cycling journey begin with the Cymbal Sprout, the ideal balance bike for beginning riders ages 2-4 years. Its lightweight frame, low seat height, and puncture-proof tires promote stability and confidence as little ones learn to balance and steer. Watch them sprout into cycling enthusiasts with Cymbal Sprout!", PENDING_COMMIT_TIMESTAMP(), 10, 13999),
(1, 3, "Cymbal Spark Jr.", "Light, vibrant, and ready for adventure, the Spark Jr. is the perfect first bike for young riders (ages 5-8). Its sturdy frame, easy-to-use brakes, and puncture-resistant tires inspire confidence and endless playtime. Let the spark of cycling ignite with Cymbal!", PENDING_COMMIT_TIMESTAMP(), 34, 13900),
(1, 4, "Cymbal Summit", "Conquering trails is a breeze with the Summit mountain bike. Its lightweight aluminum frame, responsive suspension, and powerful disc brakes provide exceptional control and comfort for experienced bikers navigating rocky climbs or shredding downhill. Reach new heights with Cymbal Summit!", PENDING_COMMIT_TIMESTAMP(), 0, 79999),
(1, 5, "Cymbal Breeze", "Cruise in style and embrace effortless pedaling with the Breeze electric bike. Its whisper-quiet motor and long-lasting battery let you conquer hills and distances with ease. Enjoy scenic rides, commutes, or errands with a boost of confidence from Cymbal Breeze!", PENDING_COMMIT_TIMESTAMP(), 72, 129999),
(1, 6, "Cymbal Trailblazer Backpack", "Carry all your essentials in style with the Trailblazer backpack. Its water-resistant material, multiple compartments, and comfortable straps keep your gear organized and accessible, allowing you to focus on the adventure. Blaze new trails with Cymbal Trailblazer!", PENDING_COMMIT_TIMESTAMP(), 24, 7999),
(1, 7, "Cymbal Phoenix Lights", "See and be seen with the Phoenix bike lights. Powerful LEDs and multiple light modes ensure superior visibility, enhancing your safety and enjoyment during day or night rides. Light up your journey with Cymbal Phoenix!", PENDING_COMMIT_TIMESTAMP(), 87, 3999),
(1, 8, "Cymbal Windstar Pump", "Flat tires are no match for the Windstar pump. Its compact design, lightweight construction, and high-pressure capacity make inflating tires quick and effortless. Get back on the road in no time with Cymbal Windstar!", PENDING_COMMIT_TIMESTAMP(), 36, 24999),
(1, 9,"Cymbal Odyssey Multi-Tool","Be prepared for anything with the Odyssey multi-tool. This handy gadget features essential tools like screwdrivers, hex wrenches, and tire levers, keeping you ready for minor repairs and adjustments on the go. Conquer your journey with Cymbal Odyssey!", PENDING_COMMIT_TIMESTAMP(), 52, 999),
(1, 10,"Cymbal Nomad Water Bottle","Stay hydrated on every ride with the Nomad water bottle. Its sleek design, BPA-free construction, and secure lock lid make it the perfect companion for staying refreshed and motivated throughout your adventures. Hydrate and explore with Cymbal Nomad!", PENDING_COMMIT_TIMESTAMP(), 42, 1299);
[run] ボタンをクリックしてデータを挿入します。
概要
このステップでは、スキーマを作成し、基本的なデータを cymbal-bikes データベースに読み込みました。
次のセクション
次に、エンベディング モデルと統合して、商品説明のエンベディングを生成し、テキスト検索リクエストをエンベディングに変換して関連商品を検索します。
5. エンベディングを操作する
商品説明のベクトル エンベディングを生成する
類似度検索を商品で機能させるには、商品説明のエンベディングを生成する必要があります。
スキーマに EmbeddingsModel が作成されているため、これは単純な UPDATE DML ステートメントです。
UPDATE products p1
SET productDescriptionEmbedding =
(SELECT embeddings.values from ML.PREDICT(MODEL EmbeddingsModel,
(SELECT productDescription as content FROM products p2 where p2.productId=p1.productId)))
WHERE categoryId=1;
run ボタンをクリックして、商品説明を更新します。
ベクトル検索の使用
この例では、SQL クエリを使用して自然言語検索リクエストを指定します。このクエリは、検索リクエストをエンベディングに変換し、前のステップで生成された商品説明の保存済みエンベディングに基づいて類似する結果を検索します。
-- Use Spanner's vector search, and integration with embedding and LLM models to
-- return items that are semantically relevant and available in inventory based on
-- real-time data.
SELECT productName, productDescription, inventoryCount, COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) as distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
run ボタンをクリックして、類似の商品を見つけます。結果は次のようになります。
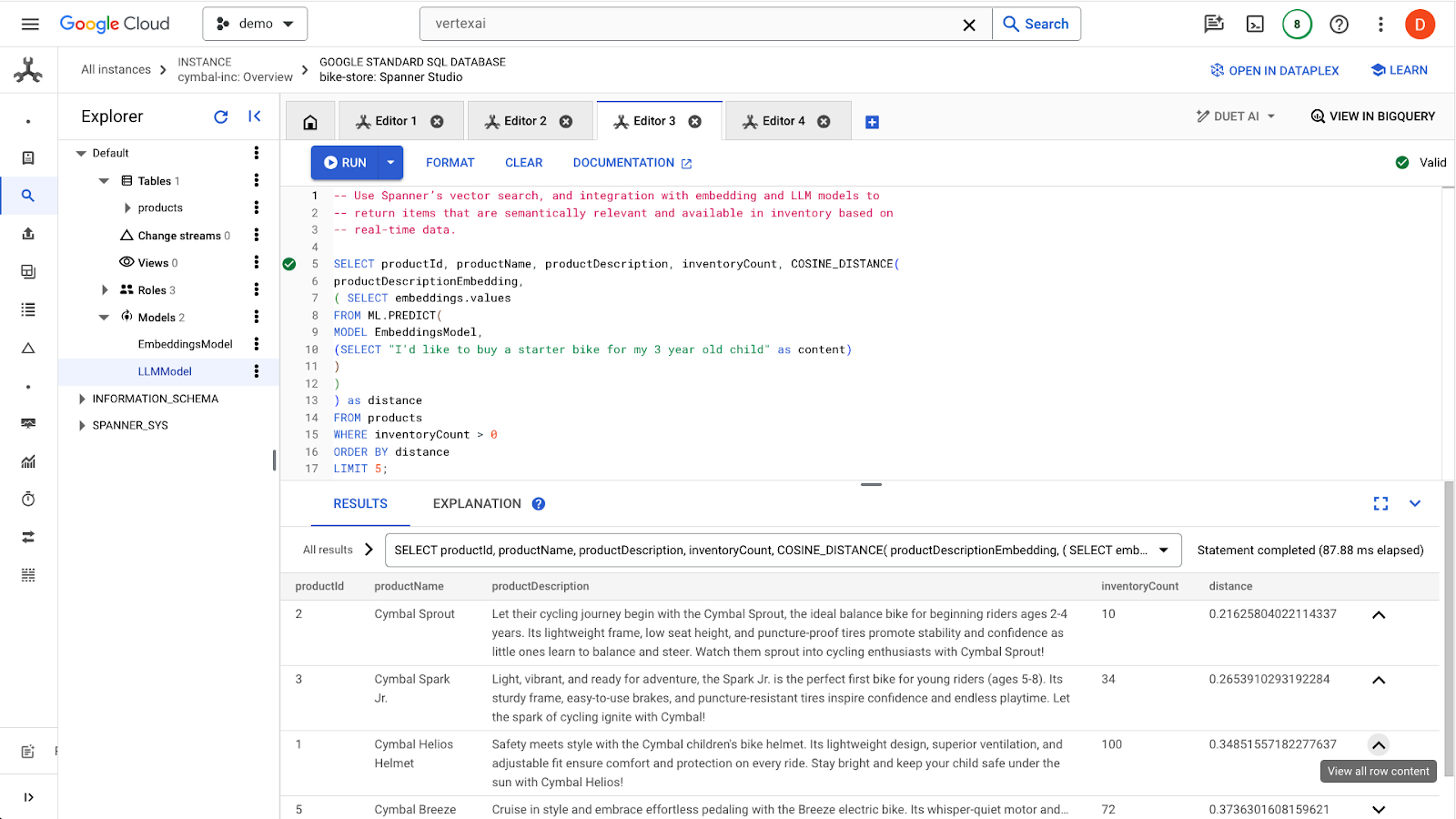
クエリでは、在庫ありの商品(inventoryCount > 0)のみに関心があるなど、追加のフィルタが使用されていることに注意してください。
概要
この手順では、Spanner と Vertex AI のモデルの統合を利用して、SQL を使用して商品説明のエンベディングと検索リクエストのエンベディングを作成しました。また、ベクトル検索を実行して、検索リクエストに一致する類似商品を見つけました。
次のステップ
次に、検索結果を LLM にフィードして、各プロダクトのカスタム レスポンスを生成します。
6. LLM を使用する
Spanner を使用すると、Vertex AI から提供される LLM モデルとの統合が簡単になります。これにより、デベロッパーは SQL を使用して LLM と直接やり取りできるようになり、アプリケーションでロジックを実行する必要がなくなります。
たとえば、ユーザー "I'd like to buy a starter bike for my 3 year old child". からの前の SQL クエリの結果があるとします。
デベロッパーは、次のプロンプトを使用して、各結果について、その商品がユーザーに適しているかどうかを回答したいと考えています。
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me? I'd like to buy a starter bike for my 3 year old child"
使用できるクエリは次のとおりです。
-- Use an LLM to analyze this list and provide a recommendation on whether each
-- product is a good fit for the user. We use the vector search and real time
-- inventory data to first filter the products to reduce the size of the prompt to
-- the LLM.
SELECT productName, productDescription, inventoryCount, content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
( SELECT
inventoryCount,
productName,
productDescription,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a starter bike for my 3 year old child \n",
"Product Name: ", productName, "\n",
"Product Description:", productDescription) AS prompt,
FROM products
WHERE inventoryCount > 0
ORDER by COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
( SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) LIMIT 5
),
STRUCT(256 AS maxOutputTokens)
);
run ボタンをクリックしてクエリを発行します。結果は次のようになります。
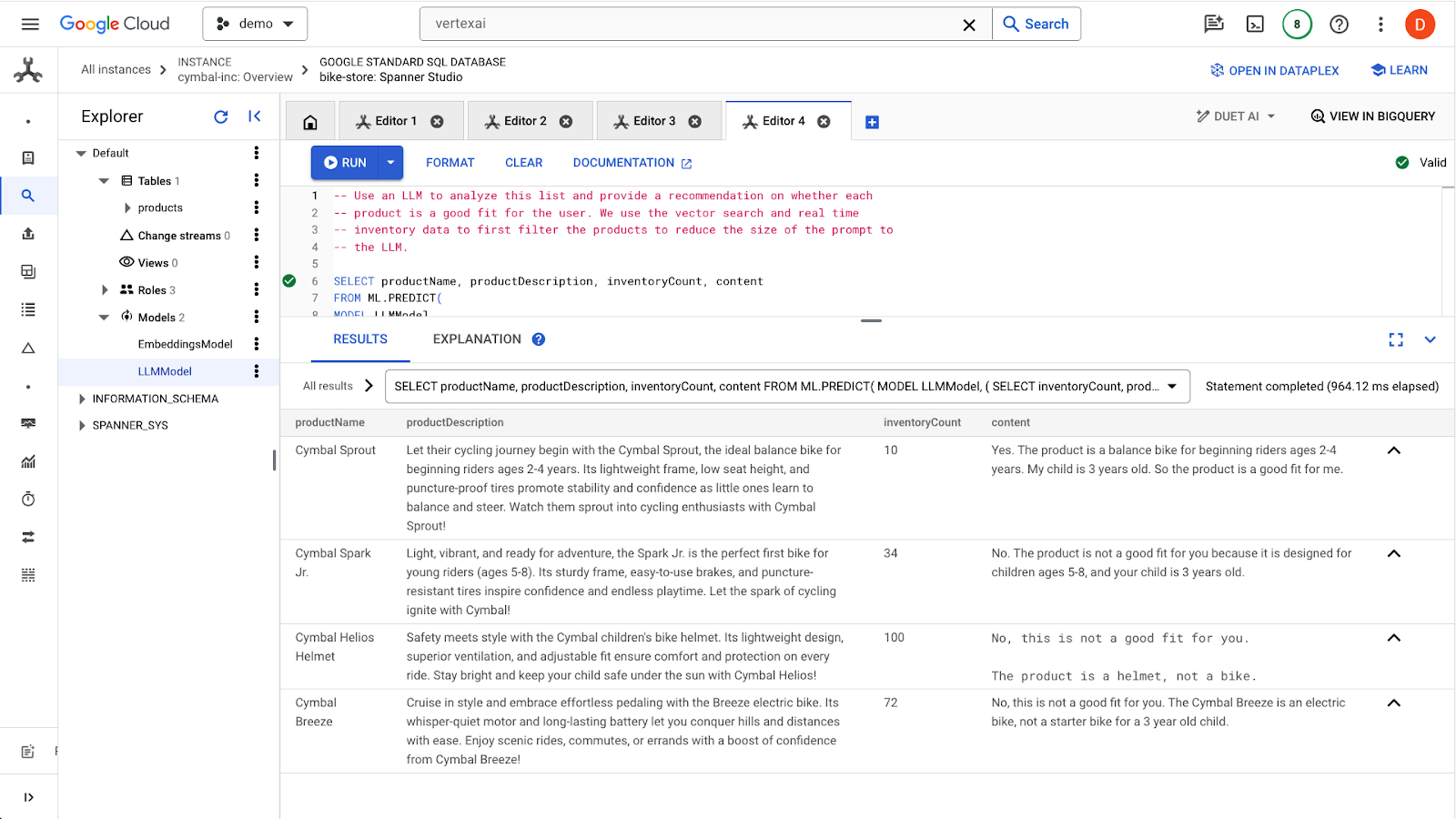
1 つ目の商品は、商品説明の年齢層(2 ~ 4 歳)から 3 歳児に適しています。他の製品はあまり適していません。
概要
このステップでは、LLM を使用してユーザーからのプロンプトに対する基本的な回答を生成しました。
次のステップ
次に、ベクトル検索のスケーリングに ANN を使用する方法について説明します。
7. ベクトル検索のスケーリング
前のベクトル検索の例では、正確な KNN ベクトル検索を活用していました。これは、Spanner データの非常に具体的なサブセットをクエリできる場合に最適です。このようなタイプのクエリは、パーティション分割性が高いと言われます。
パーティション化可能なワークロードがなく、大量のデータがある場合は、ScaNN アルゴリズムを活用した ANN ベクトル検索を使用して、ルックアップ パフォーマンスを向上させる必要があります。
Spanner でこれを行うには、次の 2 つの操作を行う必要があります。
- ベクトル インデックスを作成する
- APPROX 距離関数を使用するようにクエリを変更します。
ベクトル インデックスを作成する
このデータセットにベクトル インデックスを作成するには、まず productDescriptionEmbeddings 列を変更して各ベクトルの長さを定義する必要があります。ベクトル長を列に追加するには、元の列を削除して再作成する必要があります。
ALTER TABLE `products` DROP COLUMN `productDescriptionEmbedding`;
ALTER TABLE
`products` ADD COLUMN `productDescriptionEmbedding` ARRAY<FLOAT32>(vector_length=>768);
次に、以前に実行した Generate Vector embedding ステップからエンベディングを再度作成します。
UPDATE products p1
SET productDescriptionEmbedding =
(SELECT embeddings.values from ML.PREDICT(MODEL EmbeddingsModel,
(SELECT productDescription as content FROM products p2 where p2.productId=p1.productId)))
WHERE categoryId=1;
列を作成したら、インデックスを作成します。
CREATE VECTOR INDEX ProductDescriptionEmbeddingIndex
ON products(productDescriptionEmbedding)
WHERE productDescriptionEmbedding IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
新しいインデックスを使用する
新しいベクトル インデックスを使用するには、以前のエンベディング クエリを少し変更する必要があります。
元のクエリは次のとおりです。
SELECT productName, productDescription, inventoryCount, COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) as distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
次の変更を行う必要があります。
- 新しいベクトル インデックスのインデックス ヒントを使用します。
@{force_index=ProductDescriptionEmbeddingIndex} COSINE_DISTANCE関数の呼び出しをAPPROX_COSINE_DISTANCEに変更します。次の最終的なクエリの JSON オプションも必須です。- ML.PREDICT 関数からエンベディングを個別に生成します。
- エンベディングの結果を最終的なクエリにコピーします。
エンベディングを生成する
-- Generate the prompt embeddings
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
クエリの結果をハイライト表示してコピーします。
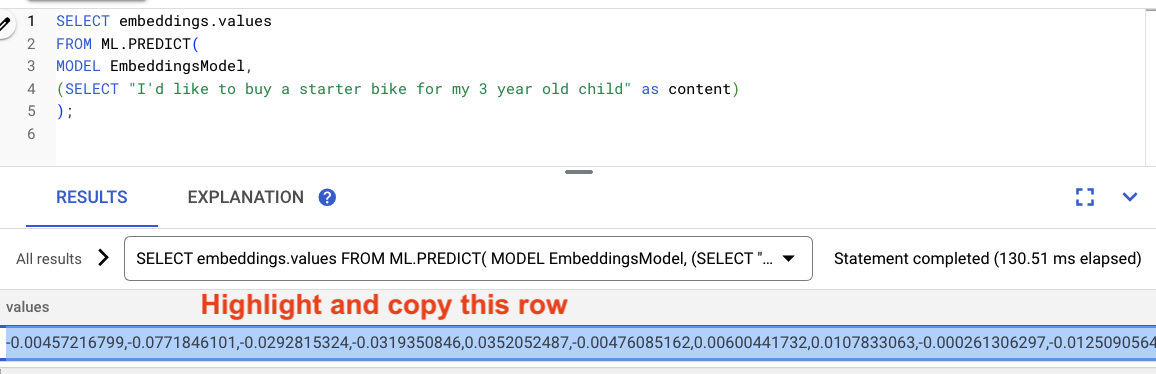
次のクエリで、コピーしたエンベディングを貼り付けて <VECTOR> を置き換えます。
-- Embedding query now using the vector index
SELECT productName, productDescription, inventoryCount,
APPROX_COSINE_DISTANCE(productDescriptionEmbedding, array<float32>[@VECTOR], options => JSON '{\"num_leaves_to_search\": 10}')
FROM products @{force_index=ProductDescriptionEmbeddingIndex}
WHERE productDescriptionEmbedding IS NOT NULL AND inventoryCount > 0
ORDER BY distance
LIMIT 5;
次のようになります。
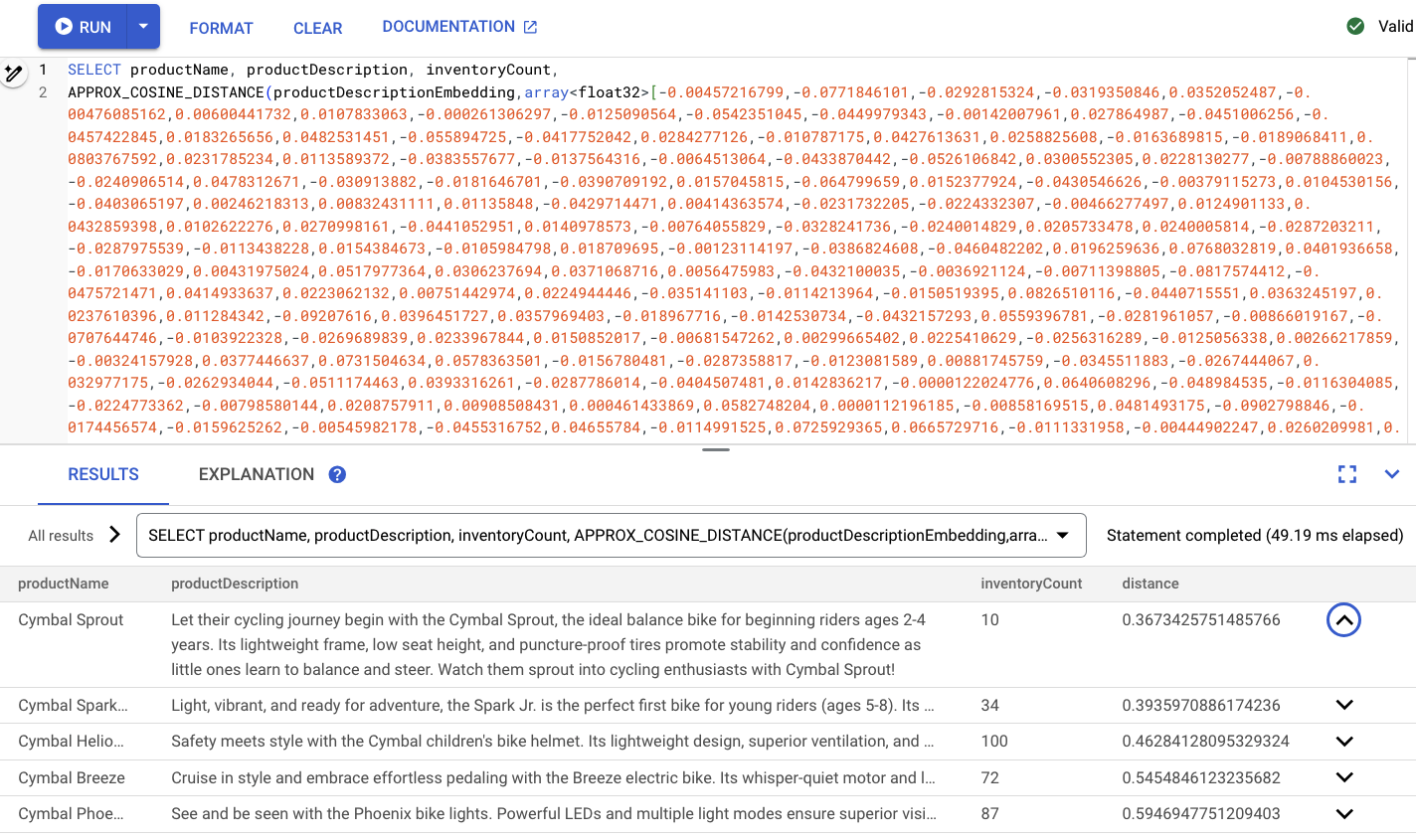
概要
このステップでは、スキーマを変換してベクトル インデックスを作成しました。次に、ベクトル インデックスを使用して ANN 検索を実行するようにエンベディング クエリを書き換えました。これは、データが増加してベクトル検索ワークロードをスケーリングする際に重要なステップです。
次のステップ
次に、クリーンアップを行います。
8. クリーンアップ(省略可)
クリーンアップするには、Cloud Console の Cloud Spanner セクションに移動して、Codelab で作成した 'retail-demo' インスタンスを削除します。
9. 完了
おめでとうございます。Spanner の組み込みベクトル検索を使用して類似性検索を正常に実行しました。また、エンベディング モデルと LLM モデルを簡単に操作して、SQL を使用して生成 AI 機能を直接提供する方法も学びました。
最後に、ベクトル検索ワークロードをスケーリングするために ScaNN アルゴリズムを基盤とする ANN 検索を実行するプロセスについて学習しました。
次のステップ
Spanner の厳密最近傍(KNN ベクトル検索)機能の詳細については、https://cloud.google.com/spanner/docs/find-k-nearest-neighbors をご覧ください。
Spanner の近似最近傍(ANN ベクトル検索)機能の詳細については、https://cloud.google.com/spanner/docs/find-approximate-nearest-neighbors をご覧ください。
Spanner の Vertex AI 統合を使用して SQL でオンライン予測を実行する方法については、https://cloud.google.com/spanner/docs/ml をご覧ください。