
1. Einführung
Spanner ist ein vollständig verwalteter, horizontal skalierbarer, global verteilter Datenbankdienst, der sich sowohl für relationale als auch für nicht relationale operative Arbeitslasten eignet.
Spanner bietet integrierte Unterstützung für die Vektorsuche. So können Sie Ähnlichkeits- oder semantische Suchen durchführen und RAG (Retrieval-Augmented Generation) in GenAI-Anwendungen im großen Maßstab implementieren. Dabei können Sie entweder Exact K-Nearest Neighbor (KNN) oder Approximate Nearest Neighbor (ANN) verwenden.
Die Vektorsuchanfragen von Cloud Spanner geben aktuelle Echtzeitdaten zurück, sobald Transaktionen übernommen werden – genau wie jede andere Abfrage Ihrer Betriebsdaten.
In diesem Lab erfahren Sie, wie Sie die grundlegenden Funktionen einrichten, die erforderlich sind, um mit Spanner eine Vektorsuche durchzuführen und mit SQL auf Einbettungs- und LLM-Modelle aus dem Model Garden von Vertex AI zuzugreifen.
Die Architektur würde so aussehen:
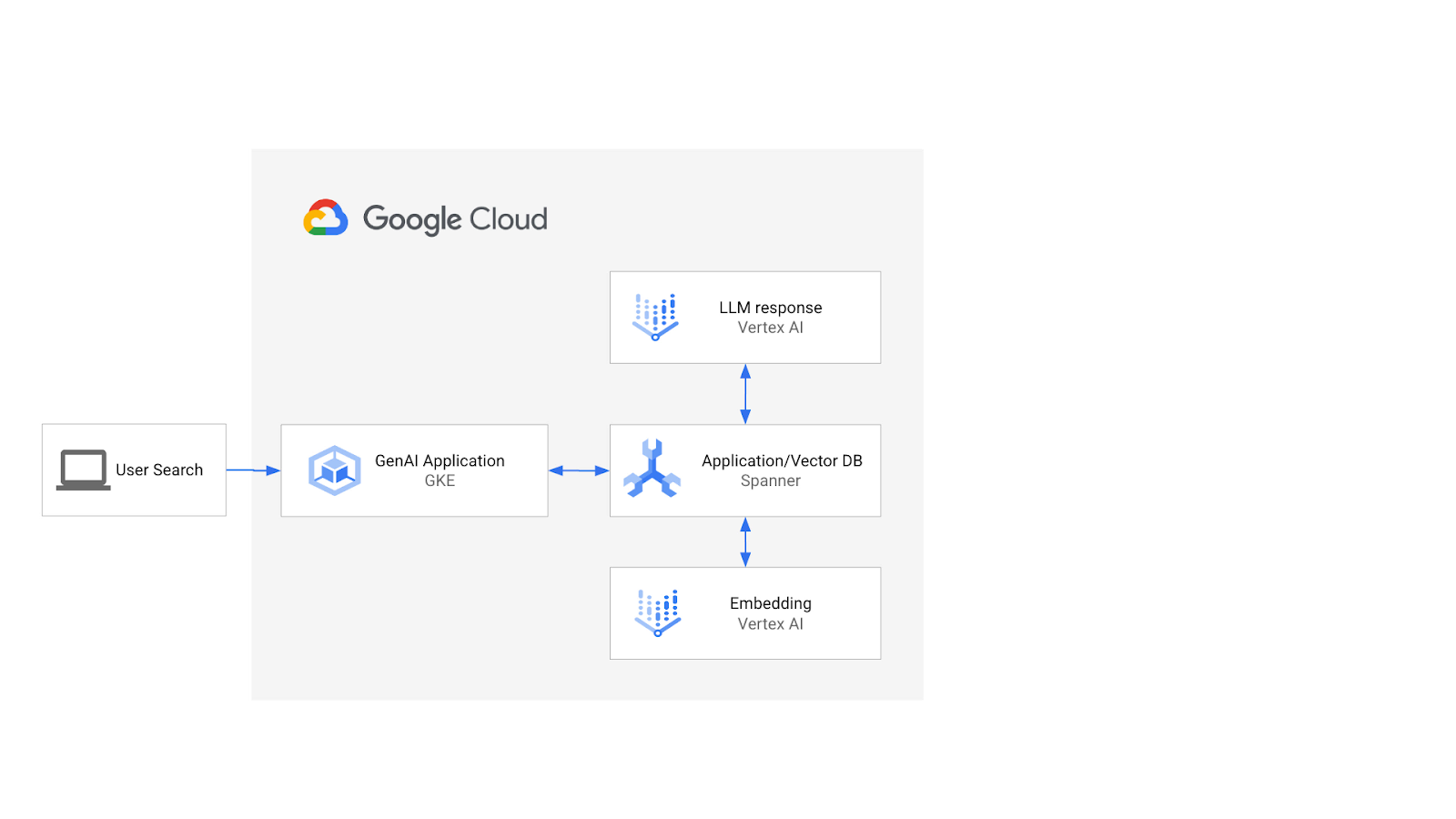
Auf dieser Grundlage erfahren Sie, wie Sie einen Vektorindex erstellen, der auf dem ScaNN-Algorithmus basiert, und die APPROX-Distanzfunktionen verwenden, wenn Ihre semantischen Arbeitslasten skaliert werden müssen.
Aufgaben
In diesem Lab haben Sie folgende Aufgaben:
- Spanner-Instanz erstellen
- Datenbankschema von Spanner für die Einbindung von Einbettungs- und LLM-Modellen in Vertex AI einrichten
- Einzelhandels-Dataset laden
- Ähnlichkeitssuchen für das Dataset ausführen
- Kontext für das LLM-Modell bereitstellen, um produktspezifische Empfehlungen zu generieren
- Ändern Sie das Schema und erstellen Sie einen Vektorindex.
- Ändern Sie die Abfragen, um den neu erstellten Vektorindex zu nutzen.
Lerninhalte
- Spanner-Instanz einrichten
- In Vertex AI einbinden
- Vektorsuche mit Spanner ausführen, um ähnliche Artikel in einem Einzelhandelsdatensatz zu finden
- So bereiten Sie Ihre Datenbank vor, um Vektorsuch-Arbeitslasten mit der ANN-Suche zu skalieren.
Voraussetzungen
2. Einrichtung und Anforderungen
Projekt erstellen
Wenn Sie noch kein Google-Konto (Gmail oder Google Apps) haben, müssen Sie eines erstellen. Melden Sie sich in der Google Cloud Platform Console ( console.cloud.google.com) an und erstellen Sie ein neues Projekt.
Wenn Sie bereits ein Projekt haben, klicken Sie oben links in der Console auf das Drop-down-Menü zur Projektauswahl:

Klicken Sie im angezeigten Dialogfeld auf die Schaltfläche „NEUES PROJEKT“, um ein neues Projekt zu erstellen:
Wenn Sie noch kein Projekt haben, wird ein Dialogfeld wie dieses angezeigt, in dem Sie Ihr erstes Projekt erstellen können:
Im nachfolgenden Dialogfeld zum Erstellen von Projekten können Sie die Details Ihres neuen Projekts eingeben:
Merken Sie sich die Projekt-ID. Sie ist für alle Google Cloud-Projekte ein eindeutiger Name. Der Name oben ist bereits vergeben und kann nicht verwendet werden. Sie wird später in diesem Codelab als PROJECT_ID bezeichnet.
Als Nächstes müssen Sie, falls noch nicht geschehen, die Abrechnung in der Entwicklerkonsole aktivieren, um Google Cloud-Ressourcen verwenden zu können, und die Spanner API aktivieren.
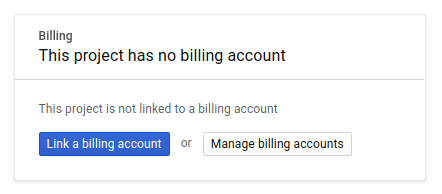
Die Durchführung dieses Codelabs sollte Sie nicht mehr als ein paar Dollar kosten, aber es könnte mehr sein, wenn Sie sich für mehr Ressourcen entscheiden oder wenn Sie sie laufen lassen (siehe Abschnitt „Bereinigen“ am Ende dieses Dokuments). Die Preise für Google Cloud Spanner sind hier dokumentiert.
Neuen Nutzern der Google Cloud Platform steht eine kostenlose Testversion mit einem Guthaben von 300 $ zur Verfügung. Dieses Codelab sollte damit vollständig kostenlos sein.
Google Cloud Shell-Einrichtung
Während Sie Google Cloud und Spanner von Ihrem Laptop aus per Fernzugriff nutzen können, wird in diesem Codelab Google Cloud Shell verwendet, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Diese Debian-basierte virtuelle Maschine verfügt über alle gängigen Entwicklungstools. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Für dieses Codelab benötigen Sie also nur einen Browser (es funktioniert auch auf einem Chromebook).
- Klicken Sie zum Aktivieren von Cloud Shell in der Cloud Console einfach auf „Cloud Shell aktivieren“
 . Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern.
. Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern.
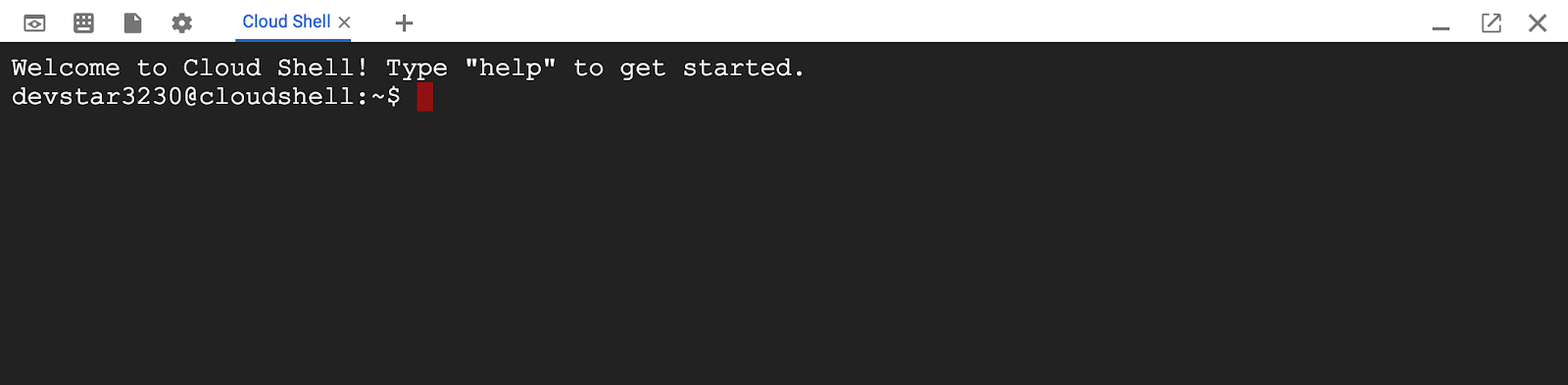
Sobald die Verbindung mit der Cloud Shell hergestellt ist, sehen Sie, dass Sie bereits authentifiziert sind und für das Projekt schon Ihre PROJECT_ID eingestellt ist.
gcloud auth list
Befehlsausgabe
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
Befehlsausgabe
[core]
project = <PROJECT_ID>
Wenn das Projekt aus irgendeinem Grund nicht festgelegt ist, geben Sie einfach den folgenden Befehl ein:
gcloud config set project <PROJECT_ID>
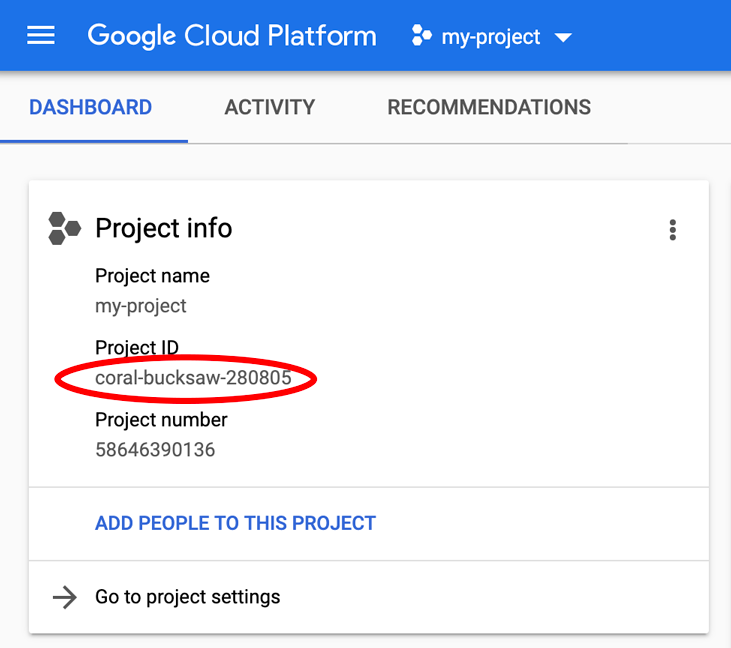
Suchst du nach deinem PROJECT_ID? Sehen Sie nach, welche ID Sie in den Einrichtungsschritten verwendet haben, oder suchen Sie sie im Cloud Console-Dashboard:
In Cloud Shell werden auch einige Umgebungsvariablen standardmäßig festgelegt, die beim Ausführen zukünftiger Befehle nützlich sein können.
echo $GOOGLE_CLOUD_PROJECT
Befehlsausgabe
<PROJECT_ID>
Spanner API aktivieren
gcloud services enable spanner.googleapis.com
Zusammenfassung
In diesem Schritt haben Sie Ihr Projekt eingerichtet, falls Sie noch keines hatten, Cloud Shell aktiviert und die erforderlichen APIs aktiviert.
Als Nächstes
Als Nächstes richten Sie die Spanner-Instanz und -Datenbank ein.
3. Spanner-Instanz und -Datenbank erstellen
Spanner-Instanz erstellen
In diesem Schritt richten wir unsere Cloud Spanner-Instanz für das Codelab ein. Öffnen Sie dazu Cloud Shell und führen Sie diesen Befehl aus:
export SPANNER_INSTANCE_ID=retail-demo
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
--edition=ENTERPRISE
Befehlsausgabe:
$ gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
--edition=ENTERPRISE
Creating instance...done.
Datenbank erstellen
Sobald Ihre Instanz ausgeführt wird, können Sie die Datenbank erstellen. Spanner ermöglicht mehrere Datenbanken in einer einzelnen Instanz.
In der Datenbank definieren Sie Ihr Schema. Sie können auch festlegen, wer Zugriff auf die Datenbank hat, eine benutzerdefinierte Verschlüsselung einrichten, den Optimierer konfigurieren und den Aufbewahrungszeitraum festlegen.
Verwenden Sie zum Erstellen der Datenbank noch einmal das gcloud-Befehlszeilentool:
export SPANNER_DATABASE=cymbal-bikes
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Befehlsausgabe:
$ gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Creating database...done.
Zusammenfassung
In diesem Schritt haben Sie die Spanner-Instanz und ‑Datenbank erstellt.
Als Nächstes
Als Nächstes richten Sie das Spanner-Schema und die Daten ein.
4. Cymbal-Schema und -Daten laden
Cymbal-Schema erstellen
So richten Sie das Schema ein:
Das Schema besteht aus zwei Teilen. Fügen Sie zuerst die Tabelle products hinzu. Kopieren Sie diese Anweisung und fügen Sie sie auf dem leeren Tab ein.
Kopieren Sie für das Schema diese DDL und fügen Sie sie in das Feld ein:
CREATE TABLE products (
categoryId INT64 NOT NULL,
productId INT64 NOT NULL,
productName STRING(MAX) NOT NULL,
productDescription STRING(MAX) NOT NULL,
productDescriptionEmbedding ARRAY<FLOAT32>,
createTime TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
inventoryCount INT64 NOT NULL,
priceInCents INT64,
) PRIMARY KEY(categoryId, productId);
Klicken Sie dann auf die Schaltfläche run und warten Sie einige Sekunden, bis das Schema erstellt wurde.
Als Nächstes erstellen Sie die beiden Modelle und konfigurieren sie für Vertex AI-Modellendpunkte.
Das erste Modell ist ein Einbettungsmodell, mit dem Einbettungen aus Text generiert werden. Das zweite ist ein LLM-Modell, mit dem Antworten auf Grundlage der Daten in Spanner generiert werden.
Fügen Sie das folgende Schema in einen neuen Tab in Spanner Studio ein:
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-004'
);
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-3.1-pro-preview',
default_batch_size = 1
);
Klicken Sie dann auf die Schaltfläche run und warten Sie einige Sekunden, bis Ihre Modelle erstellt wurden.
Im linken Bereich von Spanner Studio sollten die folgenden Tabellen und Modelle angezeigt werden:
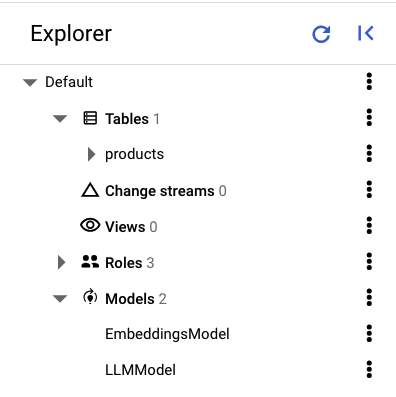
Daten laden
Als Nächstes fügen Sie einige Produkte in Ihre Datenbank ein. Öffnen Sie einen neuen Tab in Spanner Studio und kopieren Sie die folgenden INSERT-Anweisungen:
INSERT INTO products (categoryId, productId, productName, productDescription, createTime, inventoryCount, priceInCents)
VALUES (1, 1, "Cymbal Helios Helmet", "Safety meets style with the Cymbal children's bike helmet. Its lightweight design, superior ventilation, and adjustable fit ensure comfort and protection on every ride. Stay bright and keep your child safe under the sun with Cymbal Helios!", PENDING_COMMIT_TIMESTAMP(), 100, 10999),
(1, 2, "Cymbal Sprout", "Let their cycling journey begin with the Cymbal Sprout, the ideal balance bike for beginning riders ages 2-4 years. Its lightweight frame, low seat height, and puncture-proof tires promote stability and confidence as little ones learn to balance and steer. Watch them sprout into cycling enthusiasts with Cymbal Sprout!", PENDING_COMMIT_TIMESTAMP(), 10, 13999),
(1, 3, "Cymbal Spark Jr.", "Light, vibrant, and ready for adventure, the Spark Jr. is the perfect first bike for young riders (ages 5-8). Its sturdy frame, easy-to-use brakes, and puncture-resistant tires inspire confidence and endless playtime. Let the spark of cycling ignite with Cymbal!", PENDING_COMMIT_TIMESTAMP(), 34, 13900),
(1, 4, "Cymbal Summit", "Conquering trails is a breeze with the Summit mountain bike. Its lightweight aluminum frame, responsive suspension, and powerful disc brakes provide exceptional control and comfort for experienced bikers navigating rocky climbs or shredding downhill. Reach new heights with Cymbal Summit!", PENDING_COMMIT_TIMESTAMP(), 0, 79999),
(1, 5, "Cymbal Breeze", "Cruise in style and embrace effortless pedaling with the Breeze electric bike. Its whisper-quiet motor and long-lasting battery let you conquer hills and distances with ease. Enjoy scenic rides, commutes, or errands with a boost of confidence from Cymbal Breeze!", PENDING_COMMIT_TIMESTAMP(), 72, 129999),
(1, 6, "Cymbal Trailblazer Backpack", "Carry all your essentials in style with the Trailblazer backpack. Its water-resistant material, multiple compartments, and comfortable straps keep your gear organized and accessible, allowing you to focus on the adventure. Blaze new trails with Cymbal Trailblazer!", PENDING_COMMIT_TIMESTAMP(), 24, 7999),
(1, 7, "Cymbal Phoenix Lights", "See and be seen with the Phoenix bike lights. Powerful LEDs and multiple light modes ensure superior visibility, enhancing your safety and enjoyment during day or night rides. Light up your journey with Cymbal Phoenix!", PENDING_COMMIT_TIMESTAMP(), 87, 3999),
(1, 8, "Cymbal Windstar Pump", "Flat tires are no match for the Windstar pump. Its compact design, lightweight construction, and high-pressure capacity make inflating tires quick and effortless. Get back on the road in no time with Cymbal Windstar!", PENDING_COMMIT_TIMESTAMP(), 36, 24999),
(1, 9,"Cymbal Odyssey Multi-Tool","Be prepared for anything with the Odyssey multi-tool. This handy gadget features essential tools like screwdrivers, hex wrenches, and tire levers, keeping you ready for minor repairs and adjustments on the go. Conquer your journey with Cymbal Odyssey!", PENDING_COMMIT_TIMESTAMP(), 52, 999),
(1, 10,"Cymbal Nomad Water Bottle","Stay hydrated on every ride with the Nomad water bottle. Its sleek design, BPA-free construction, and secure lock lid make it the perfect companion for staying refreshed and motivated throughout your adventures. Hydrate and explore with Cymbal Nomad!", PENDING_COMMIT_TIMESTAMP(), 42, 1299);
Klicken Sie auf die Schaltfläche run, um die Daten einzufügen.
Zusammenfassung
In diesem Schritt haben Sie das Schema erstellt und einige grundlegende Daten in die cymbal-bikes-Datenbank geladen.
Als Nächstes
Als Nächstes integrieren Sie das Einbettungsmodell, um Einbettungen für die Produktbeschreibungen zu generieren und eine textbasierte Suchanfrage in eine Einbettung umzuwandeln, um nach relevanten Produkten zu suchen.
5. Mit Einbettungen arbeiten
Vektoreinbettungen für Produktbeschreibungen generieren
Damit die Ähnlichkeitssuche für die Produkte funktioniert, müssen Sie Einbettungen für die Produktbeschreibungen generieren.
Da die EmbeddingsModel im Schema erstellt wurde, ist dies eine einfache UPDATE-DML-Anweisung.
UPDATE products p1
SET productDescriptionEmbedding =
(SELECT embeddings.values from ML.PREDICT(MODEL EmbeddingsModel,
(SELECT productDescription as content FROM products p2 where p2.productId=p1.productId)))
WHERE categoryId=1;
Klicken Sie auf die Schaltfläche run, um die Produktbeschreibungen zu aktualisieren.
Vektorsuche verwenden
In diesem Beispiel stellen Sie eine Suchanfrage in natürlicher Sprache über eine SQL-Abfrage. Bei dieser Anfrage wird die Suchanfrage in eine Einbettung umgewandelt und dann nach ähnlichen Ergebnissen gesucht, die auf den gespeicherten Einbettungen der Produktbeschreibungen basieren, die im vorherigen Schritt generiert wurden.
-- Use Spanner's vector search, and integration with embedding and LLM models to
-- return items that are semantically relevant and available in inventory based on
-- real-time data.
SELECT productName, productDescription, inventoryCount, COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) as distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
Klicken Sie auf die Schaltfläche run, um ähnliche Produkte zu finden. Die Ergebnisse sollten so aussehen:
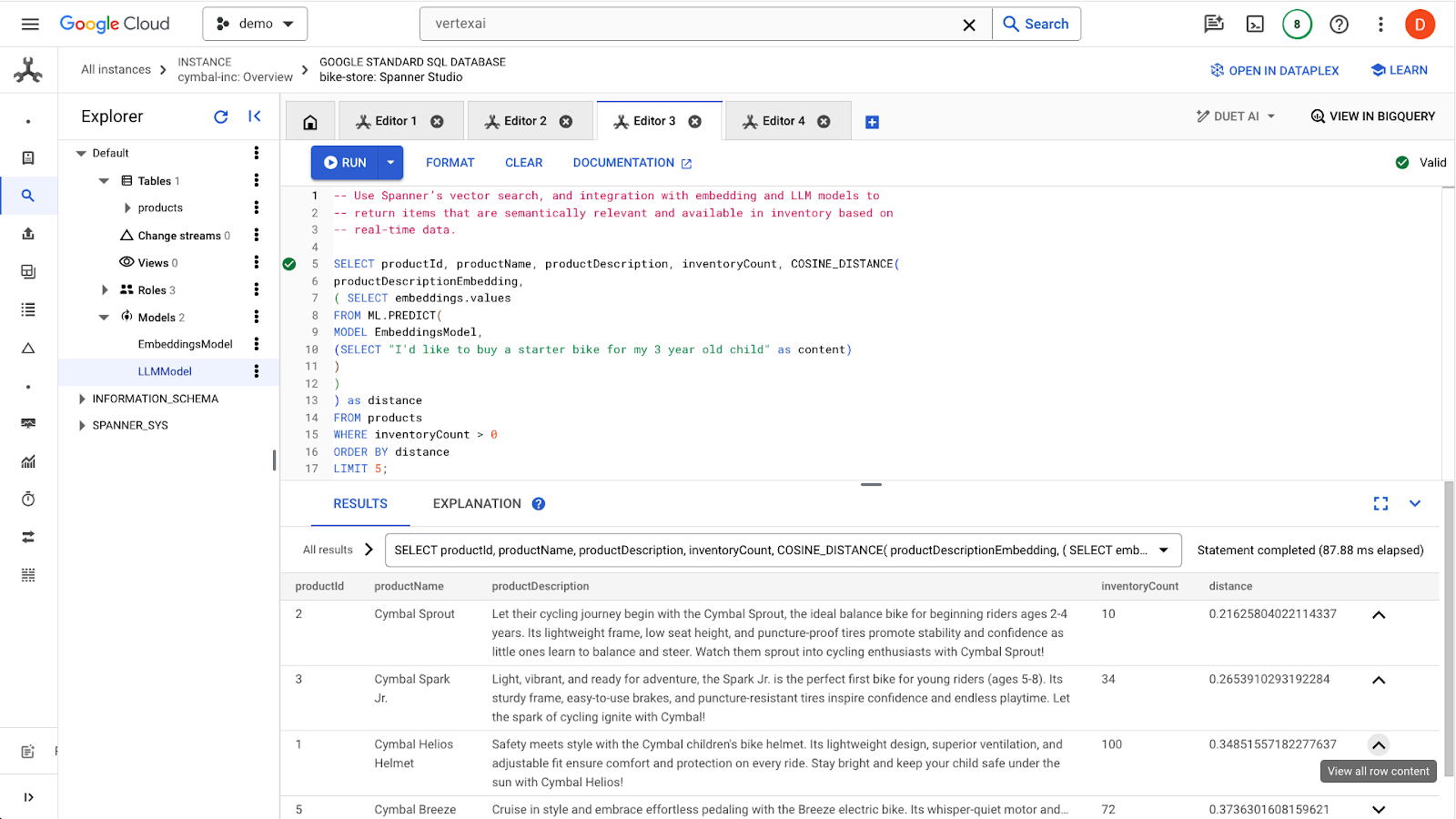
Beachten Sie, dass in der Abfrage zusätzliche Filter verwendet werden, z. B. nur Produkte, die auf Lager sind (inventoryCount > 0).
Zusammenfassung
In diesem Schritt haben Sie mithilfe von SQL und der Spanner-Integration mit Modellen in Vertex AI Einbettungen für Produktbeschreibungen und eine Einbettung für Suchanfragen erstellt. Sie haben auch eine Vektorsuche durchgeführt, um ähnliche Produkte zu finden, die der Suchanfrage entsprechen.
Nächste Schritte
Als Nächstes verwenden wir die Suchergebnisse, um ein LLM zu trainieren und eine benutzerdefinierte Antwort für jedes Produkt zu generieren.
6. Mit einem LLM arbeiten
Spanner erleichtert die Integration mit LLM-Modellen, die über Vertex AI bereitgestellt werden. So können Entwickler SQL verwenden, um direkt mit LLMs zu interagieren, anstatt die Logik in der Anwendung auszuführen.
Wir haben beispielsweise die Ergebnisse der vorherigen SQL-Abfrage vom Nutzer "I'd like to buy a starter bike for my 3 year old child"..
Der Entwickler möchte für jedes Ergebnis eine Antwort darauf geben, ob das Produkt für den Nutzer geeignet ist. Dazu verwendet er den folgenden Prompt:
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me? I'd like to buy a starter bike for my 3 year old child"
Hier ist die Abfrage, die Sie verwenden können:
-- Use an LLM to analyze this list and provide a recommendation on whether each
-- product is a good fit for the user. We use the vector search and real time
-- inventory data to first filter the products to reduce the size of the prompt to
-- the LLM.
SELECT productName, productDescription, inventoryCount, content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
( SELECT
inventoryCount,
productName,
productDescription,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a starter bike for my 3 year old child \n",
"Product Name: ", productName, "\n",
"Product Description:", productDescription) AS prompt,
FROM products
WHERE inventoryCount > 0
ORDER by COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
( SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) LIMIT 5
),
STRUCT(256 AS maxOutputTokens)
);
Klicken Sie auf die Schaltfläche run, um die Anfrage zu senden. Die Ergebnisse sollten so aussehen:
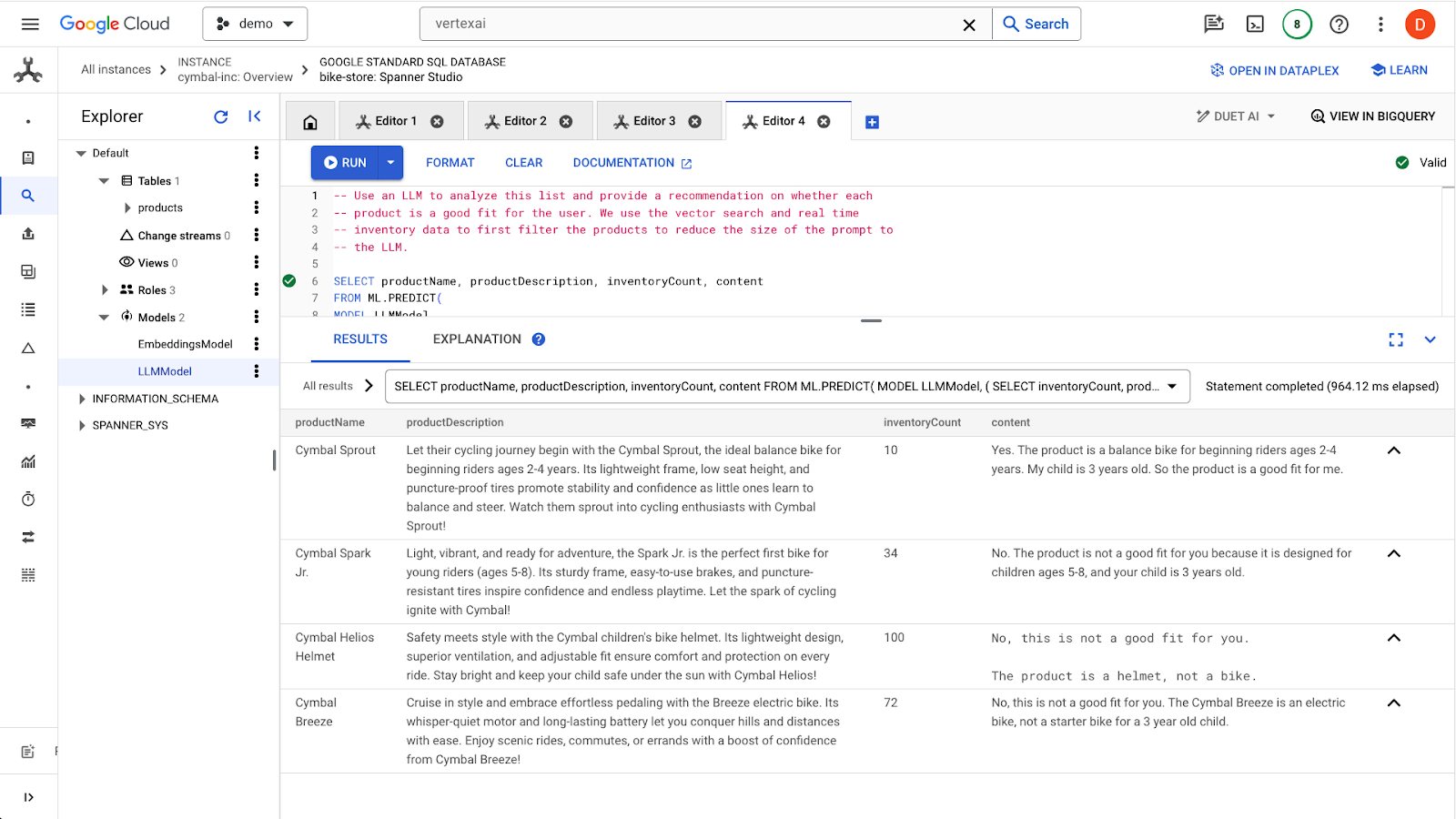
Das erste Produkt ist für ein 3-jähriges Kind geeignet, da in der Produktbeschreibung die Altersgruppe „2–4 Jahre“ angegeben ist. Die anderen Produkte passen nicht so gut.
Zusammenfassung
In diesem Schritt haben Sie mit einem LLM gearbeitet, um grundlegende Antworten auf Prompts eines Nutzers zu generieren.
Nächste Schritte
Als Nächstes sehen wir uns an, wie Sie ANN zum Skalieren der Vektorsuche verwenden können.
7. Vektorsuche skalieren
In den vorherigen Beispielen für die Vektorsuche wurde die exakte KNN-Vektorsuche verwendet. Das ist besonders nützlich, wenn Sie sehr spezifische Teilmengen Ihrer Spanner-Daten abfragen können. Diese Arten von Anfragen gelten als stark partitionierbar.
Wenn Sie keine Arbeitslasten haben, die sich gut partitionieren lassen, und Sie eine große Datenmenge haben, sollten Sie die ANN-Vektorsuche mit dem ScaNN-Algorithmus verwenden, um die Suchleistung zu steigern.
Dazu sind in Spanner zwei Schritte erforderlich:
- Vektorindex erstellen
- Ändern Sie Ihre Abfrage so, dass die APPROX-Distanzfunktionen verwendet werden.
Vektorindex erstellen
Um einen Vektorindex für dieses Dataset zu erstellen, müssen wir zuerst die Spalte productDescriptionEmbeddings ändern, um die Länge der einzelnen Vektoren zu definieren. Wenn Sie die Vektorlänge einer Spalte hinzufügen möchten, müssen Sie die ursprüngliche Spalte löschen und neu erstellen.
ALTER TABLE `products` DROP COLUMN `productDescriptionEmbedding`;
ALTER TABLE
`products` ADD COLUMN `productDescriptionEmbedding` ARRAY<FLOAT32>(vector_length=>768);
Erstellen Sie als Nächstes die Einbettungen noch einmal aus dem Generate Vector embedding-Schritt, den Sie zuvor ausgeführt haben.
UPDATE products p1
SET productDescriptionEmbedding =
(SELECT embeddings.values from ML.PREDICT(MODEL EmbeddingsModel,
(SELECT productDescription as content FROM products p2 where p2.productId=p1.productId)))
WHERE categoryId=1;
Nachdem die Spalte erstellt wurde, erstellen Sie den Index:
CREATE VECTOR INDEX ProductDescriptionEmbeddingIndex
ON products(productDescriptionEmbedding)
WHERE productDescriptionEmbedding IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
Neuen Index verwenden
Wenn Sie den neuen Vektorindex verwenden möchten, müssen Sie die vorherige Einbettungsabfrage leicht ändern.
Dies ist die ursprüngliche Abfrage:
SELECT productName, productDescription, inventoryCount, COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) as distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
Sie müssen die folgenden Änderungen vornehmen:
- Verwenden Sie einen Indexhinweis für den neuen Vektorindex:
@{force_index=ProductDescriptionEmbeddingIndex} - Ändern Sie den
COSINE_DISTANCE-Funktionsaufruf inAPPROX_COSINE_DISTANCE. Die JSON-Optionen in der endgültigen Abfrage unten sind ebenfalls erforderlich. - Generieren Sie die Embeddings separat mit der Funktion ML.PREDICT.
- Kopieren Sie die Ergebnisse der Einbettungen in die endgültige Abfrage.
Einbettungen generieren
-- Generate the prompt embeddings
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
Markieren Sie die Ergebnisse der Abfrage und kopieren Sie sie.
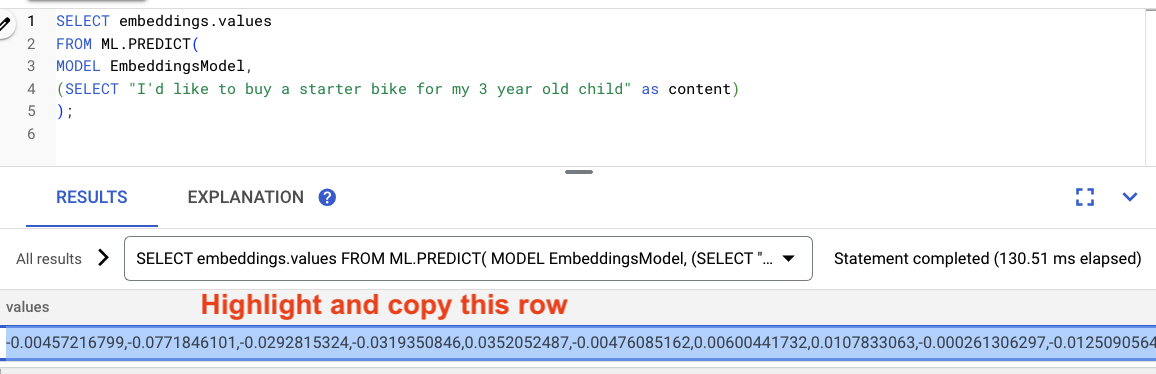
Ersetzen Sie dann <VECTOR> in der folgenden Abfrage, indem Sie die kopierten Einbettungen einfügen.
-- Embedding query now using the vector index
SELECT productName, productDescription, inventoryCount,
APPROX_COSINE_DISTANCE(productDescriptionEmbedding, array<float32>[@VECTOR], options => JSON '{\"num_leaves_to_search\": 10}')
FROM products @{force_index=ProductDescriptionEmbeddingIndex}
WHERE productDescriptionEmbedding IS NOT NULL AND inventoryCount > 0
ORDER BY distance
LIMIT 5;
Die Ausgabe sollte ungefähr so aussehen:
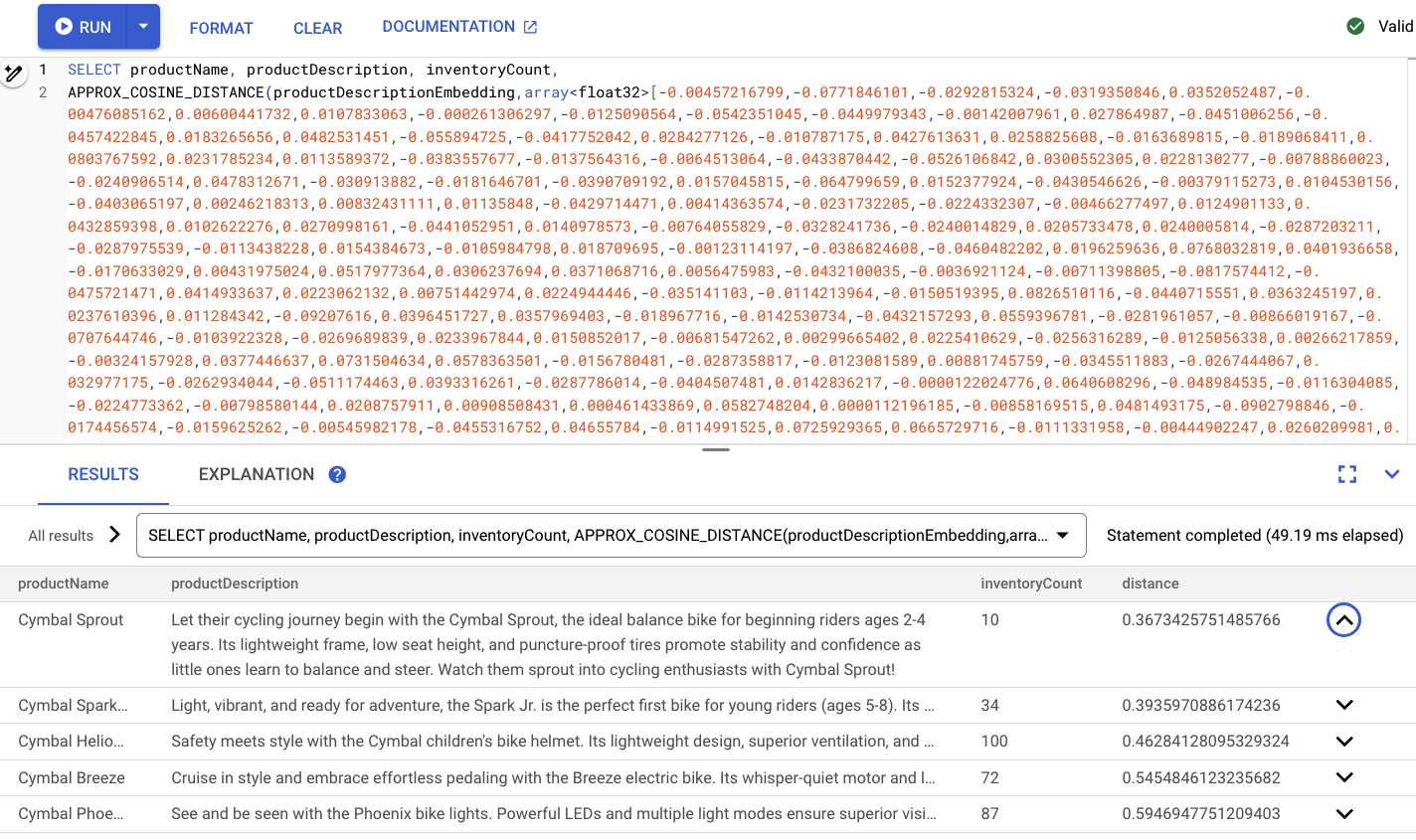
Zusammenfassung
In diesem Schritt haben Sie Ihr Schema konvertiert, um einen Vektorindex zu erstellen. Anschließend haben Sie die Einbettungsanfrage neu geschrieben, um die ANN-Suche mit dem Vektorindex durchzuführen. Dies ist ein wichtiger Schritt, wenn Ihre Daten wachsen und Sie Vektorsucharbeitslasten skalieren möchten.
Nächste Schritte
Als Nächstes ist es Zeit, aufzuräumen.
8. Bereinigen (optional)
Rufen Sie zum Bereinigen einfach den Cloud Spanner-Bereich der Cloud Console auf und löschen Sie die Instanz 'retail-demo', die wir im Codelab erstellt haben.
9. Glückwunsch!
Sie haben erfolgreich eine Suche nach Ähnlichkeiten mit der integrierten Vektorsuche von Spanner durchgeführt. Außerdem haben Sie gesehen, wie einfach es ist, mit Embedding- und LLM-Modellen zu arbeiten, um generative KI-Funktionen direkt mit SQL bereitzustellen.
Schließlich haben Sie gelernt, wie Sie die ANN-Suche mit dem ScaNN-Algorithmus durchführen, um Vektorsucharbeitslasten zu skalieren.
Nächste Schritte
Weitere Informationen zur Funktion „Exakte Suche nach den nächsten Nachbarn (KNN-Vektorsuche)“ von Spanner finden Sie unter https://cloud.google.com/spanner/docs/find-k-nearest-neighbors.
Weitere Informationen zur Funktion „Approximate Nearest Neighbor“ (ANN-Vektorsuche) von Spanner finden Sie unter https://cloud.google.com/spanner/docs/find-approximate-nearest-neighbors.
Weitere Informationen zum Ausführen von Onlinevorhersagen mit SQL mithilfe der Vertex AI-Integration von Spanner finden Sie unter https://cloud.google.com/spanner/docs/ml.