
1. Introduction
Spanner est un service de base de données entièrement géré, évolutif horizontalement et distribué à l'échelle mondiale, idéal pour les charges de travail opérationnelles relationnelles et non relationnelles.
Spanner est compatible avec la recherche vectorielle intégrée, ce qui vous permet d'effectuer des recherches de similarités ou sémantiques, et d'implémenter la génération augmentée par récupération (RAG) dans les applications GenAI à grande échelle, en tirant parti des fonctionnalités exactes des k plus proches voisins (KNN) ou des plus proches voisins approximatifs (ANN).
Les requêtes de recherche vectorielle de Spanner renvoient des données en temps réel actualisées dès que les transactions sont validées, comme n'importe quelle autre requête sur vos données opérationnelles.
Dans cet atelier, vous allez découvrir comment configurer les fonctionnalités de base requises pour utiliser Spanner afin d'effectuer une recherche vectorielle, et accéder aux modèles d'embeddings et de LLM à partir du catalogue de modèles de Vertex AI à l'aide de SQL.
Voici à quoi ressemblera l'architecture :
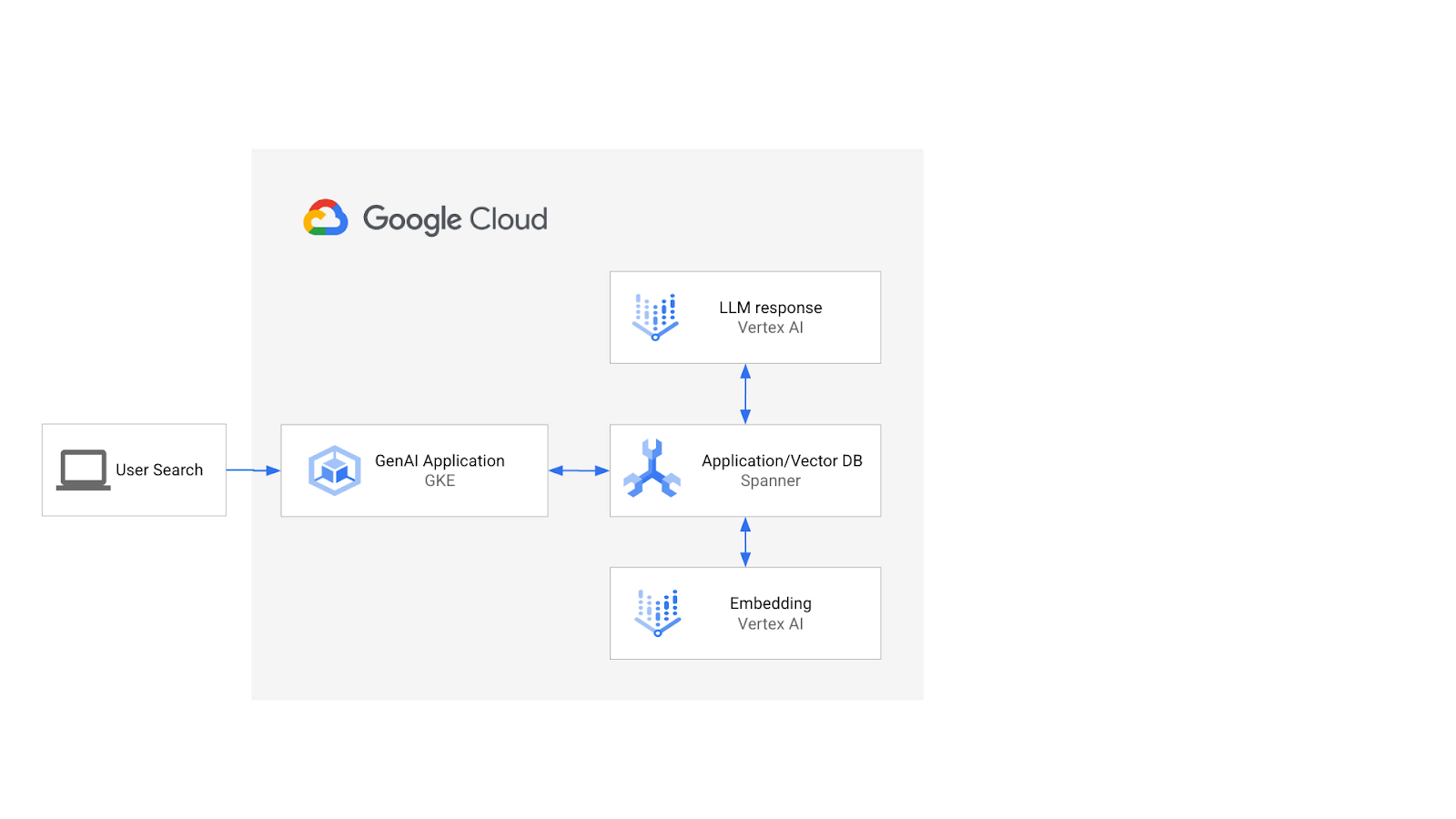
Vous apprendrez ensuite à créer un index vectoriel basé sur l'algorithme ScaNN et à utiliser les fonctions de distance APPROX lorsque vos charges de travail sémantiques doivent être mises à l'échelle.
Objectifs de l'atelier
Au cours de cet atelier, vous allez :
- créer une instance Spanner ;
- configurer le schéma de base de données de Spanner pour l'intégrer aux modèles d'embeddings et de LLM dans Vertex AI ;
- charger un ensemble de données de vente au détail ;
- envoyer des requêtes de recherche de similarités à l'ensemble de données ;
- fournir un contexte au modèle LLM pour générer des recommandations spécifiques aux produits ;
- modifier le schéma et créer un index vectoriel ;
- modifier les requêtes pour exploiter l'index vectoriel nouvellement créé.
Points abordés
- Comment configurer une instance Spanner
- Comment intégrer Vertex AI
- Comment utiliser Spanner pour effectuer une recherche vectorielle afin de trouver des articles similaires dans un ensemble de données de vente au détail
- Comment préparer votre base de données pour mettre à l'échelle les charges de travail de recherche vectorielle à l'aide de la recherche ANN
Ce dont vous avez besoin
2. Préparation
Créer un projet
Si vous ne possédez pas encore de compte Google (Gmail ou Google Apps), vous devez en créer un. Connectez-vous à la console Google Cloud Platform ( console.cloud.google.com) et créez un projet.
Si vous avez déjà un projet, cliquez sur le menu déroulant de sélection du projet dans l'angle supérieur gauche de la console :

Cliquez ensuite sur le bouton "NEW PROJECT" (NOUVEAU PROJET) dans la boîte de dialogue qui s'affiche pour créer un projet :
Si vous n'avez pas encore de projet, une boîte de dialogue semblable à celle-ci apparaîtra pour vous permettre d'en créer un :
La boîte de dialogue de création de projet suivante vous permet de saisir les détails de votre nouveau projet :
Notez l'ID du projet. Il s'agit d'un nom unique pour tous les projets Google Cloud, ce qui implique que le nom ci-dessus n'est plus disponible pour vous… Désolé ! Il sera désigné par le nom PROJECT_ID tout au long de cet atelier de programmation.
Ensuite, si ce n'est pas déjà fait, vous devez activer la facturation dans Developers Console afin de pouvoir utiliser les ressources Google Cloud puis activer l'API Spanner.
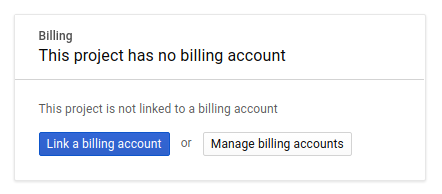
Suivre cet atelier de programmation ne devrait pas vous coûter plus d'un euro. Cependant, cela peut s'avérer plus coûteux si vous décidez d'utiliser davantage de ressources ou si vous n'interrompez pas les ressources (voir la section "Effectuer un nettoyage" à la fin du présent document). Les tarifs de Google Cloud Spanner sont décrits sur cette page.
Les nouveaux utilisateurs de Google Cloud Platform peuvent bénéficier d'un Essai sans frais avec 300 $ de crédits afin de suivre sans frais le présent atelier.
Configuration de Google Cloud Shell
Bien que Google Cloud et Spanner puissent être utilisés à distance depuis votre ordinateur portable, nous allons utiliser Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Cette machine virtuelle basée sur Debian contient tous les outils de développement dont vous aurez besoin. Elle intègre un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Cela signifie que tout ce dont vous avez besoin pour cet atelier de programmation est un navigateur (oui, tout fonctionne sur un Chromebook).
- Pour activer Cloud Shell à partir de Cloud Console, cliquez simplement sur Activer Cloud Shell
 (l'opération de provisionnement et la connexion à l'environnement ne devraient prendre que quelques minutes).
(l'opération de provisionnement et la connexion à l'environnement ne devraient prendre que quelques minutes).
Une fois connecté à Cloud Shell, vous êtes en principe authentifié, et le projet est déjà défini avec votre ID de projet.
gcloud auth list
Résultat de la commande
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
Résultat de la commande
[core]
project = <PROJECT_ID>
Si, pour une raison quelconque, le projet n'est pas défini, exécutez simplement la commande suivante :
gcloud config set project <PROJECT_ID>
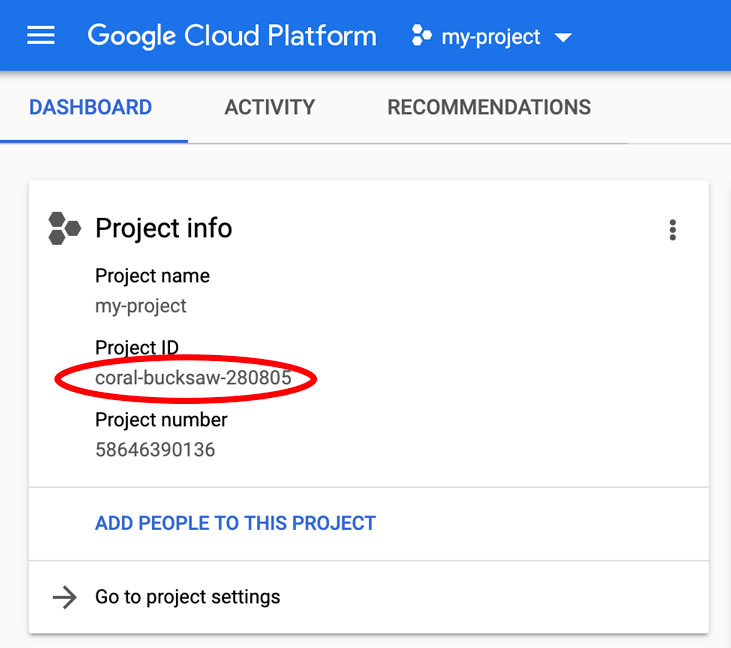
Vous recherchez votre PROJECT_ID ? Vérifiez l'ID que vous avez utilisé pendant les étapes de configuration ou recherchez-le dans le tableau de bord Cloud Console :
Par défaut, Cloud Shell définit certaines variables d'environnement qui pourront s'avérer utiles pour exécuter certaines commandes dans le futur.
echo $GOOGLE_CLOUD_PROJECT
Résultat de la commande
<PROJECT_ID>
Activer l'API Spanner
gcloud services enable spanner.googleapis.com
Résumé
Au cours de cette étape, vous avez configuré votre projet si vous n'en aviez pas déjà un, activé Cloud Shell et activé les API requises.
Étape suivante
Vous allez maintenant configurer l'instance et la base de données Spanner.
3. Créer une instance et une base de données Spanner
Créer l'instance Spanner
Au cours de cette étape, nous allons configurer notre instance Spanner pour l'atelier de programmation. Pour ce faire, ouvrez Cloud Shell et exécutez cette commande :
export SPANNER_INSTANCE_ID=retail-demo
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
--edition=ENTERPRISE
Résultat de la commande :
$ gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
--edition=ENTERPRISE
Creating instance...done.
Créer la base de données
Une fois l'instance en cours d'exécution, vous pouvez créer une base de données. Spanner autorise plusieurs bases de données sur une seule instance.
C'est dans la base de données que vous définissez votre schéma. Vous pouvez également contrôler qui a accès à la base de données, configurer un chiffrement personnalisé, configurer l'optimiseur et définir la période de conservation.
Pour créer la base de données, utilisez à nouveau l'outil de ligne de commande gcloud :
export SPANNER_DATABASE=cymbal-bikes
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Résultat de la commande :
$ gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Creating database...done.
Résumé
Au cours de cette étape, vous avez créé l'instance et la base de données Spanner.
Étape suivante
Vous allez maintenant configurer le schéma et les données Spanner.
4. Charger le schéma et les données Cymbal
Créer le schéma Cymbal
Pour configurer le schéma, accédez à Spanner Studio :
Le schéma comporte deux parties. Vous devez d'abord ajouter la table products. Copiez et collez cette instruction dans l'onglet vide.
Pour le schéma, copiez et collez cette instruction LDD dans la zone :
CREATE TABLE products (
categoryId INT64 NOT NULL,
productId INT64 NOT NULL,
productName STRING(MAX) NOT NULL,
productDescription STRING(MAX) NOT NULL,
productDescriptionEmbedding ARRAY<FLOAT32>,
createTime TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
inventoryCount INT64 NOT NULL,
priceInCents INT64,
) PRIMARY KEY(categoryId, productId);
Cliquez ensuite sur le bouton run et attendez quelques secondes que votre schéma soit créé.
Vous allez ensuite créer les deux modèles et les configurer sur les points de terminaison de modèle Vertex AI.
Le premier modèle est un modèle d'embeddings utilisé pour générer des embeddings à partir de texte, et le second est un modèle LLM utilisé pour générer des réponses en fonction des données de Spanner.
Collez le schéma suivant dans un nouvel onglet de Spanner Studio :
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-004'
);
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-3.1-pro-preview',
default_batch_size = 1
);
Cliquez ensuite sur le bouton run et attendez quelques secondes que vos modèles soient créés.
Dans le volet de gauche de Spanner Studio, vous devriez voir les tables et modèles suivants :
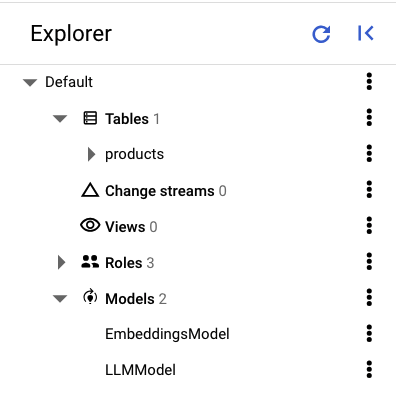
Charger les données
Vous allez maintenant insérer des produits dans votre base de données. Ouvrez un nouvel onglet dans Spanner Studio, puis copiez et collez les instructions d'insertion suivantes :
INSERT INTO products (categoryId, productId, productName, productDescription, createTime, inventoryCount, priceInCents)
VALUES (1, 1, "Cymbal Helios Helmet", "Safety meets style with the Cymbal children's bike helmet. Its lightweight design, superior ventilation, and adjustable fit ensure comfort and protection on every ride. Stay bright and keep your child safe under the sun with Cymbal Helios!", PENDING_COMMIT_TIMESTAMP(), 100, 10999),
(1, 2, "Cymbal Sprout", "Let their cycling journey begin with the Cymbal Sprout, the ideal balance bike for beginning riders ages 2-4 years. Its lightweight frame, low seat height, and puncture-proof tires promote stability and confidence as little ones learn to balance and steer. Watch them sprout into cycling enthusiasts with Cymbal Sprout!", PENDING_COMMIT_TIMESTAMP(), 10, 13999),
(1, 3, "Cymbal Spark Jr.", "Light, vibrant, and ready for adventure, the Spark Jr. is the perfect first bike for young riders (ages 5-8). Its sturdy frame, easy-to-use brakes, and puncture-resistant tires inspire confidence and endless playtime. Let the spark of cycling ignite with Cymbal!", PENDING_COMMIT_TIMESTAMP(), 34, 13900),
(1, 4, "Cymbal Summit", "Conquering trails is a breeze with the Summit mountain bike. Its lightweight aluminum frame, responsive suspension, and powerful disc brakes provide exceptional control and comfort for experienced bikers navigating rocky climbs or shredding downhill. Reach new heights with Cymbal Summit!", PENDING_COMMIT_TIMESTAMP(), 0, 79999),
(1, 5, "Cymbal Breeze", "Cruise in style and embrace effortless pedaling with the Breeze electric bike. Its whisper-quiet motor and long-lasting battery let you conquer hills and distances with ease. Enjoy scenic rides, commutes, or errands with a boost of confidence from Cymbal Breeze!", PENDING_COMMIT_TIMESTAMP(), 72, 129999),
(1, 6, "Cymbal Trailblazer Backpack", "Carry all your essentials in style with the Trailblazer backpack. Its water-resistant material, multiple compartments, and comfortable straps keep your gear organized and accessible, allowing you to focus on the adventure. Blaze new trails with Cymbal Trailblazer!", PENDING_COMMIT_TIMESTAMP(), 24, 7999),
(1, 7, "Cymbal Phoenix Lights", "See and be seen with the Phoenix bike lights. Powerful LEDs and multiple light modes ensure superior visibility, enhancing your safety and enjoyment during day or night rides. Light up your journey with Cymbal Phoenix!", PENDING_COMMIT_TIMESTAMP(), 87, 3999),
(1, 8, "Cymbal Windstar Pump", "Flat tires are no match for the Windstar pump. Its compact design, lightweight construction, and high-pressure capacity make inflating tires quick and effortless. Get back on the road in no time with Cymbal Windstar!", PENDING_COMMIT_TIMESTAMP(), 36, 24999),
(1, 9,"Cymbal Odyssey Multi-Tool","Be prepared for anything with the Odyssey multi-tool. This handy gadget features essential tools like screwdrivers, hex wrenches, and tire levers, keeping you ready for minor repairs and adjustments on the go. Conquer your journey with Cymbal Odyssey!", PENDING_COMMIT_TIMESTAMP(), 52, 999),
(1, 10,"Cymbal Nomad Water Bottle","Stay hydrated on every ride with the Nomad water bottle. Its sleek design, BPA-free construction, and secure lock lid make it the perfect companion for staying refreshed and motivated throughout your adventures. Hydrate and explore with Cymbal Nomad!", PENDING_COMMIT_TIMESTAMP(), 42, 1299);
Cliquez sur le bouton run pour insérer les données.
Résumé
Au cours de cette étape, vous avez créé le schéma et chargé des données de base dans la base de données cymbal-bikes.
Étape suivante
Vous allez ensuite intégrer le modèle d'embeddings pour générer des embeddings pour les descriptions de produits, ainsi que convertir une requête de recherche textuelle en embedding pour rechercher des produits pertinents.
5. Utiliser des embeddings
Générer des embeddings vectoriels pour les descriptions de produits
Pour que la recherche de similarités fonctionne sur les produits, vous devez générer des embeddings pour les descriptions de produits.
Avec le EmbeddingsModel créé dans le schéma, il s'agit d'une simple instruction LMD UPDATE.
UPDATE products p1
SET productDescriptionEmbedding =
(SELECT embeddings.values from ML.PREDICT(MODEL EmbeddingsModel,
(SELECT productDescription as content FROM products p2 where p2.productId=p1.productId)))
WHERE categoryId=1;
Cliquez sur le bouton run pour mettre à jour les descriptions de produits.
Utiliser la recherche vectorielle
Dans cet exemple, vous allez fournir une requête de recherche en langage naturel via une requête SQL. Cette requête transforme la requête de recherche en embedding, puis recherche des résultats similaires en fonction des embeddings stockés des descriptions de produits générés à l'étape précédente.
-- Use Spanner's vector search, and integration with embedding and LLM models to
-- return items that are semantically relevant and available in inventory based on
-- real-time data.
SELECT productName, productDescription, inventoryCount, COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) as distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
Cliquez sur le bouton run pour trouver les produits similaires. Voici le résultat attendu :
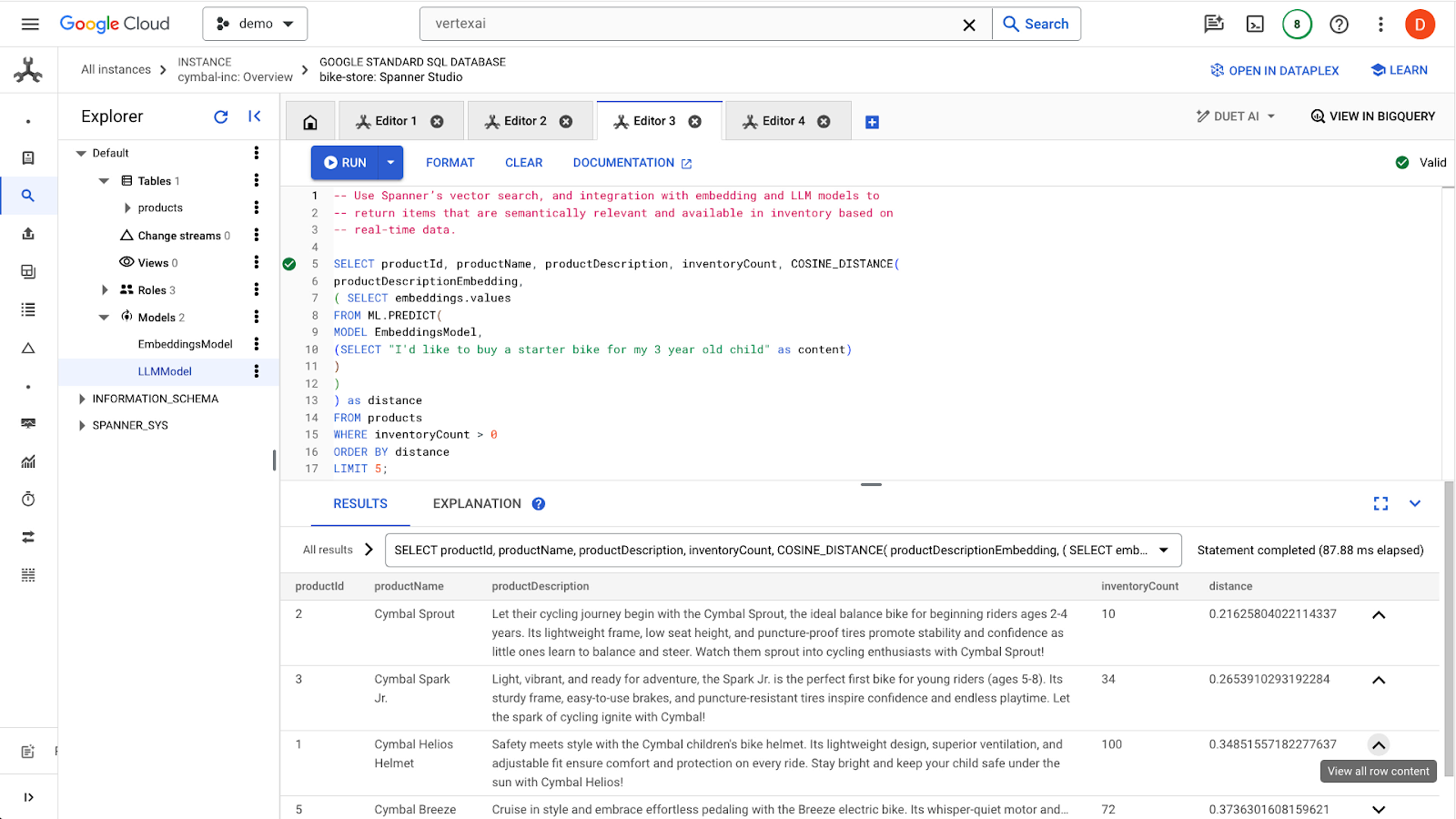
Notez que des filtres supplémentaires sont utilisés dans la requête, par exemple pour ne s'intéresser qu'aux produits en stock (inventoryCount > 0).
Résumé
Au cours de cette étape, vous avez créé des embeddings de description de produits et un embedding de requête de recherche à l'aide de SQL, en tirant parti de l'intégration de Spanner avec les modèles de Vertex AI. Vous avez également effectué une recherche vectorielle pour trouver des produits similaires correspondant à la requête de recherche.
Étapes suivantes
Utilisons maintenant les résultats de la recherche pour alimenter un LLM afin de générer une réponse personnalisée pour chaque produit.
6. Utiliser un LLM
Spanner facilite l'intégration aux modèles LLM diffusés à partir de Vertex AI. Les développeurs peuvent ainsi utiliser SQL pour interagir directement avec les LLM, sans que l'application n'ait à effectuer la logique.
Par exemple, nous avons les résultats de la requête SQL précédente de l'utilisateur "I'd like to buy a starter bike for my 3 year old child".
Le développeur souhaite fournir une réponse pour chaque résultat indiquant si le produit convient à l'utilisateur, à l'aide du prompt suivant :
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me? I'd like to buy a starter bike for my 3 year old child"
Voici la requête que vous pouvez utiliser :
-- Use an LLM to analyze this list and provide a recommendation on whether each
-- product is a good fit for the user. We use the vector search and real time
-- inventory data to first filter the products to reduce the size of the prompt to
-- the LLM.
SELECT productName, productDescription, inventoryCount, content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
( SELECT
inventoryCount,
productName,
productDescription,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a starter bike for my 3 year old child \n",
"Product Name: ", productName, "\n",
"Product Description:", productDescription) AS prompt,
FROM products
WHERE inventoryCount > 0
ORDER by COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
( SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) LIMIT 5
),
STRUCT(256 AS maxOutputTokens)
);
Cliquez sur le bouton run pour envoyer la requête. Voici le résultat attendu :
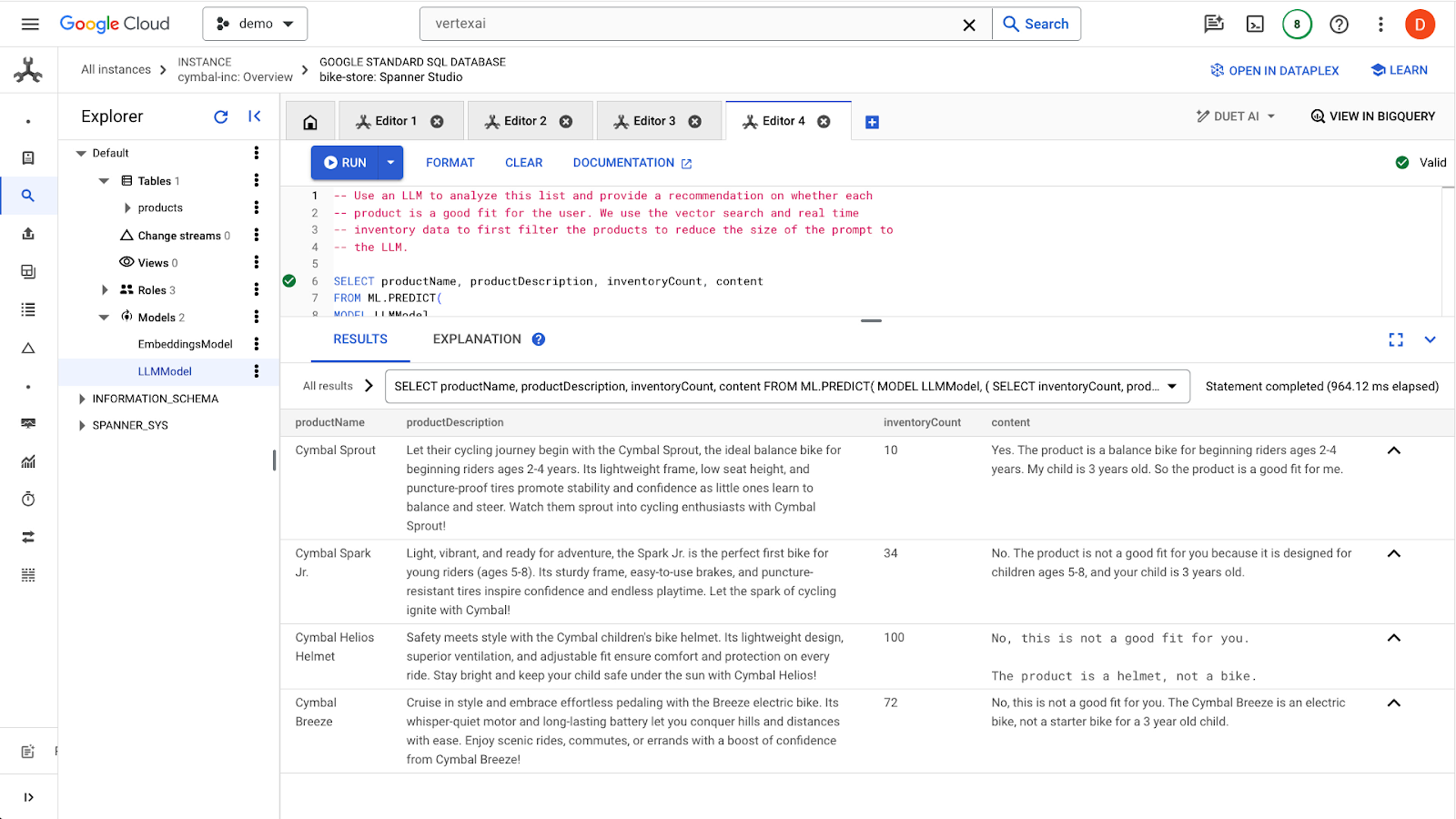
Le premier produit convient à un enfant de 3 ans en raison de la tranche d'âge indiquée dans la description du produit (2-4 ans). Les autres produits ne sont pas adaptés.
Résumé
Au cours de cette étape, vous avez utilisé un LLM pour générer des réponses de base aux prompts d'un utilisateur.
Étapes suivantes
Découvrez maintenant comment utiliser ANN pour mettre à l'échelle la recherche vectorielle.
7. Mettre à l'échelle la recherche vectorielle
Les exemples de recherche vectorielle précédents ont exploité la recherche vectorielle KNN exacte. C'est idéal lorsque vous pouvez interroger des sous-ensembles très spécifiques de vos données Spanner. Ces types de requêtes sont dits hautement partitionnables.
Si vous n'avez pas de charges de travail hautement partitionnables et que vous disposez d'une grande quantité de données, vous devez utiliser la recherche vectorielle ANN en tirant parti de l' algorithme ScaNN pour améliorer les performances de recherche.
Pour ce faire dans Spanner, vous devez effectuer deux opérations :
- Créer un index vectoriel
- Modifier votre requête pour utiliser les fonctions de distance APPROX.
Créer l'index vectoriel
Pour créer un index vectoriel sur cet ensemble de données, nous devons d'abord modifier la colonne productDescriptionEmbeddings afin de définir la longueur de chaque vecteur. Pour ajouter la longueur du vecteur à une colonne, vous devez supprimer la colonne d'origine et la recréer.
ALTER TABLE `products` DROP COLUMN `productDescriptionEmbedding`;
ALTER TABLE
`products` ADD COLUMN `productDescriptionEmbedding` ARRAY<FLOAT32>(vector_length=>768);
Ensuite, recréez les embeddings à partir de l'étape Generate Vector embedding que vous avez exécutée précédemment.
UPDATE products p1
SET productDescriptionEmbedding =
(SELECT embeddings.values from ML.PREDICT(MODEL EmbeddingsModel,
(SELECT productDescription as content FROM products p2 where p2.productId=p1.productId)))
WHERE categoryId=1;
Une fois la colonne créée, créez l'index :
CREATE VECTOR INDEX ProductDescriptionEmbeddingIndex
ON products(productDescriptionEmbedding)
WHERE productDescriptionEmbedding IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
Utiliser le nouvel index
Pour utiliser le nouvel index vectoriel, vous devez modifier légèrement la requête d'embedding précédente.
Voici la requête d'origine :
SELECT productName, productDescription, inventoryCount, COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) as distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
Vous devez apporter les modifications suivantes :
- Utiliser une indication d'index pour le nouvel index vectoriel :
@{force_index=ProductDescriptionEmbeddingIndex} - Modifier l'appel de fonction
COSINE_DISTANCEenAPPROX_COSINE_DISTANCE. Notez que les options JSON de la requête finale ci-dessous sont également requises. - Générer les embeddings à partir de la fonction ML.PREDICT séparément.
- Copier les résultats des embeddings dans la requête finale.
Générer les embeddings
-- Generate the prompt embeddings
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
Mettez en surbrillance les résultats de la requête et copiez-les.
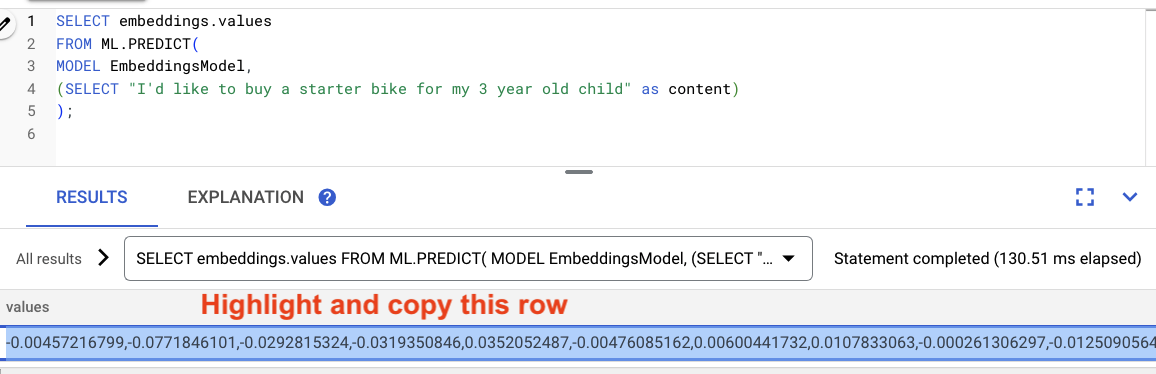
Remplacez ensuite <VECTOR> dans la requête suivante en collant les embeddings que vous avez copiés.
-- Embedding query now using the vector index
SELECT productName, productDescription, inventoryCount,
APPROX_COSINE_DISTANCE(productDescriptionEmbedding, array<float32>[@VECTOR], options => JSON '{\"num_leaves_to_search\": 10}')
FROM products @{force_index=ProductDescriptionEmbeddingIndex}
WHERE productDescriptionEmbedding IS NOT NULL AND inventoryCount > 0
ORDER BY distance
LIMIT 5;
Voici un exemple :
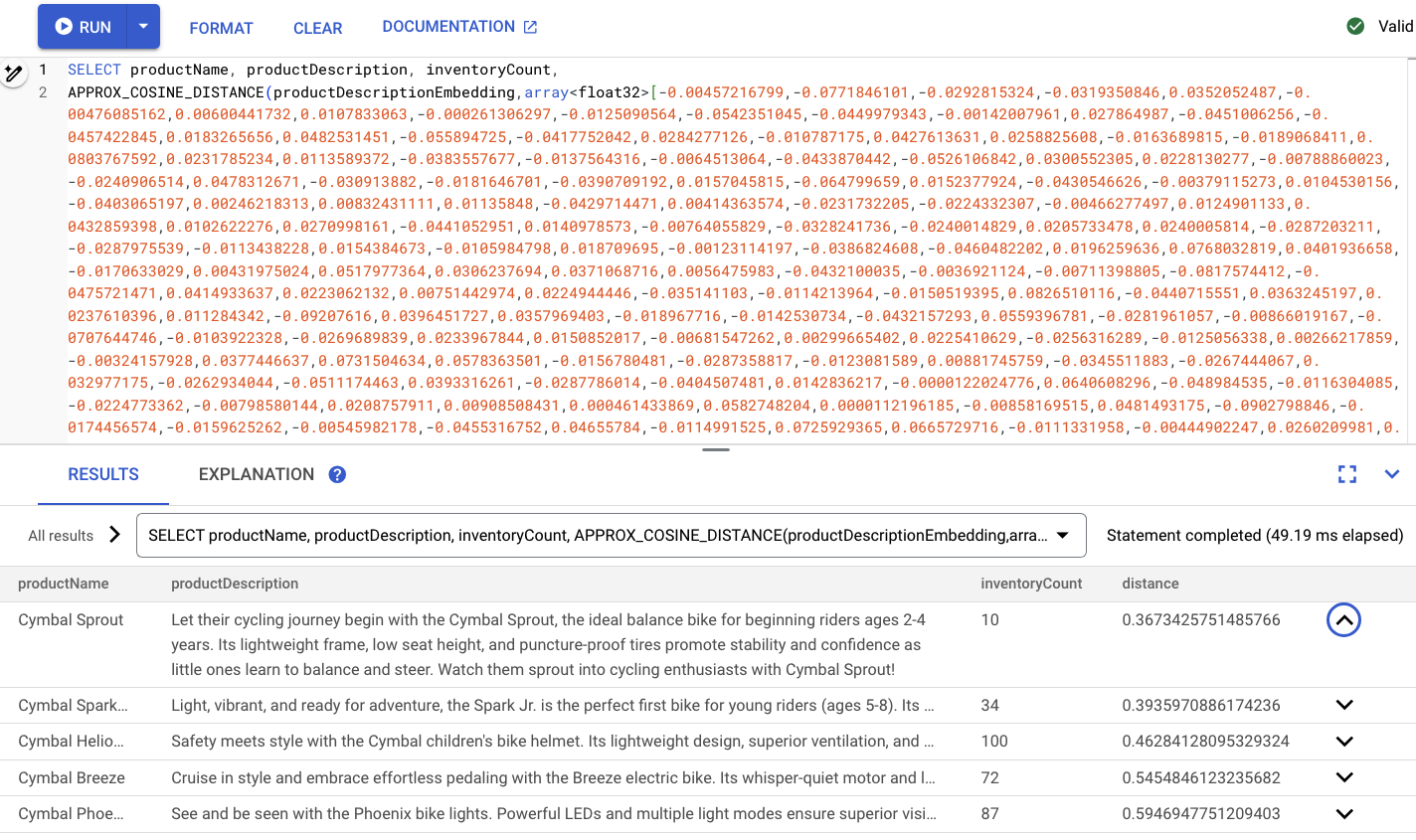
Résumé
Au cours de cette étape, vous avez converti votre schéma pour créer un index vectoriel. Vous avez ensuite réécrit la requête d'embedding pour effectuer une recherche ANN à l'aide de l'index vectoriel. Il s'agit d'une étape importante à mesure que vos données se développent pour mettre à l'échelle les charges de travail de recherche vectorielle.
Étapes suivantes
Il est maintenant temps d'effectuer un nettoyage.
8. Effectuer un nettoyage (facultatif)
Pour libérer de l'espace, accédez simplement à la section Cloud Spanner de la console Cloud et supprimez l'instance 'retail-demo' que nous avons créée dans l'atelier de programmation.
9. Félicitations !
Félicitations ! Vous avez effectué une recherche de similarités à l'aide de la recherche vectorielle intégrée de Spanner. Vous avez également vu à quel point il est facile d'utiliser des modèles d'embeddings et de LLM pour fournir des fonctionnalités d'IA générative directement à l'aide de SQL.
Enfin, vous avez découvert le processus permettant d'effectuer une recherche ANN basée sur l'algorithme ScaNN pour mettre à l'échelle les charges de travail de recherche vectorielle.
Étape suivante
Pour en savoir plus sur la fonctionnalité de recherche des k plus proches voisins (KNN) de Spanner, consultez la page https://cloud.google.com/spanner/docs/find-k-nearest-neighbors.
Pour en savoir plus sur la fonctionnalité de recherche des plus proches voisins approximatifs (ANN) de Spanner, consultez la page https://cloud.google.com/spanner/docs/find-approximate-nearest-neighbors.
Pour en savoir plus sur l'exécution de prédictions en ligne avec SQL à l'aide de l'intégration Vertex AI de Spanner, consultez la page https://cloud.google.com/spanner/docs/ml.