
1. Introducción
Spanner es un servicio de base de datos distribuido de forma global, escalable horizontalmente y completamente administrado que es ideal para cargas de trabajo operativas relacionales y no relacionales.
Spanner tiene compatibilidad integrada con la búsqueda de vectores, lo que te permite realizar búsquedas semánticas o de similitud, y, además, implementar la generación aumentada por recuperación (RAG) en aplicaciones de IA generativa a gran escala, aprovechando las funciones de K-vecino más cercano exacto (KNN) o de vecino más cercano aproximado (ANN).
Las consultas de búsqueda de vectores de Spanner muestran datos actualizados en tiempo real en cuanto se confirman las transacciones, al igual que cualquier otra consulta sobre tus datos operativos.
En este lab, aprenderás a configurar las funciones básicas necesarias para aprovechar Spanner y realizar búsquedas de vectores, y acceder a modelos de LLM y de embeddings desde el jardín de modelos de Vertex AI con SQL.
La arquitectura se vería de la siguiente manera:
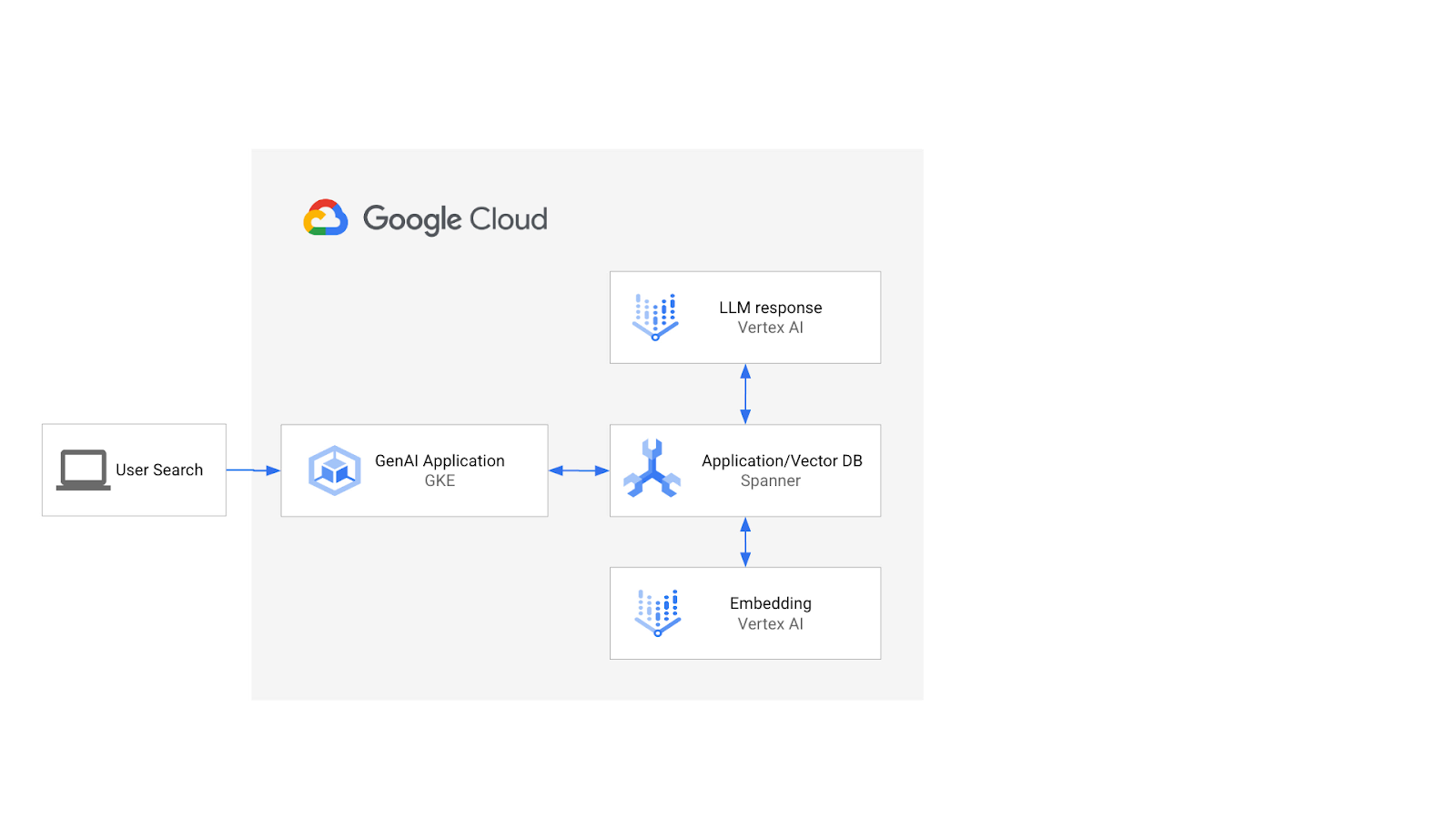
Con esa base, aprenderás a crear un índice de vectores respaldado por el algoritmo ScaNN y a usar las funciones de distancia APPROX cuando tus cargas de trabajo semánticas necesiten escalarse.
Qué compilarás
Como parte de este lab, harás lo siguiente:
- Crear una instancia de Spanner
- Configurar el esquema de la base de datos de Spanner para que se integre con los modelos de LLM y de embeddings en Vertex AI
- Cargar un conjunto de datos de comercio minorista
- Emitir consultas de búsqueda de similitud en el conjunto de datos
- Proporcionar contexto al modelo de LLM para generar recomendaciones específicas del producto
- Modificar el esquema y crear un índice de vectores
- Cambiar las consultas para aprovechar el índice de vectores recién creado
Qué aprenderás
- Cómo configurar una instancia de Spanner
- Cómo realizar la integración con Vertex AI
- Cómo usar Spanner para realizar búsquedas de vectores y encontrar elementos similares en un conjunto de datos de comercio minorista
- Cómo preparar tu base de datos para escalar las cargas de trabajo de búsqueda de vectores con la búsqueda de ANN
Requisitos
2. Configuración y requisitos
Crea un proyecto
Si aún no tienes una Cuenta de Google (Gmail o Google Apps), debes crear una. Accede a Google Cloud Platform Console ( console.cloud.google.com) y crea un proyecto nuevo.
Si ya tienes un proyecto, haz clic en el menú desplegable de selección de proyectos en la parte superior izquierda de la Console:

y haz clic en el botón “PROYECTO NUEVO” en el diálogo resultante para crear un proyecto nuevo:
Si aún no tienes un proyecto, deberías ver un cuadro de diálogo como este para crear el primero:
El cuadro de diálogo de creación posterior del proyecto te permite ingresar los detalles de tu proyecto nuevo:
Recuerda el ID del proyecto, que es un nombre único en todos los proyectos de Google Cloud (el nombre anterior ya se encuentra en uso y no lo podrá usar). Se mencionará más adelante en este codelab como PROJECT_ID.
A continuación, si aún no lo has hecho, deberás habilitar la facturación en Developers Console para usar los recursos de Google Cloud y habilitar la API de Spanner.
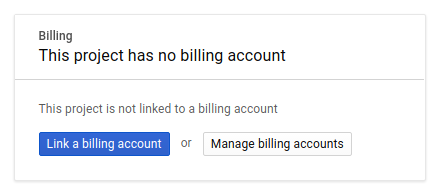
Ejecutar este codelab debería costar solo unos pocos dólares, pero su costo podría aumentar si decides usar más recursos o si los dejas en ejecución (consulta la sección “Limpiar” al final de este documento). Los precios de Google Cloud Spanner se documentan aquí.
Los usuarios nuevos de Google Cloud Platform están aptas para obtener una prueba gratuita de $300, por lo que este codelab es completamente gratuito.
Configuración de Google Cloud Shell
Si bien Google Cloud y Spanner se pueden operar de manera remota desde tu laptop, en este codelab usaremos Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
Esta máquina virtual basada en Debian está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Esto significa que todo lo que necesitarás para este Codelab es un navegador (sí, funciona en una Chromebook).
- Para activar Cloud Shell desde la consola de Cloud, solo haz clic en Activar Cloud Shell
 (el aprovisionamiento y la conexión al entorno debería llevar solo unos minutos).
(el aprovisionamiento y la conexión al entorno debería llevar solo unos minutos).
Una vez que estés conectado a Cloud Shell, deberías ver que ya te autenticaste y que el proyecto ya se configuró con tu PROJECT_ID.
gcloud auth list
Resultado del comando
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
Resultado del comando
[core]
project = <PROJECT_ID>
Si, por algún motivo, el proyecto no está configurado, solo emite el siguiente comando:
gcloud config set project <PROJECT_ID>
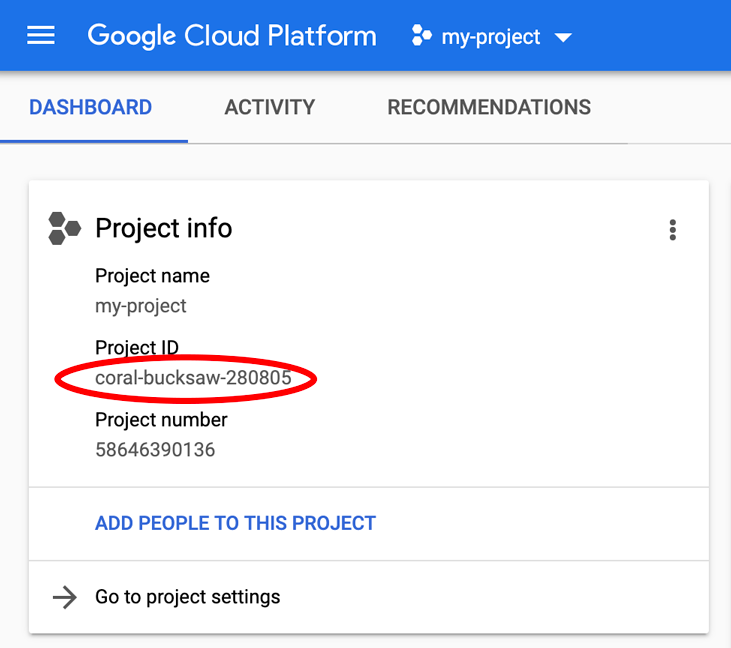
Si no conoce su PROJECT_ID, Observa el ID que usaste en los pasos de configuración o búscalo en el panel de la consola de Cloud:
Cloud Shell también configura algunas variables de entorno de forma predeterminada, lo que puede resultar útil cuando ejecutas comandos futuros.
echo $GOOGLE_CLOUD_PROJECT
Resultado del comando
<PROJECT_ID>
Habilita la API de Spanner
gcloud services enable spanner.googleapis.com
Resumen
En este paso, configuraste tu proyecto si aún no tenías uno, activaste Cloud Shell y habilitaste las APIs necesarias.
Cuál es el próximo paso
A continuación, configurarás la instancia y la base de datos de Spanner.
3. Crea una instancia y una base de datos de Spanner
Crea la instancia de Spanner
En este paso, configuraremos nuestra instancia de Spanner para el codelab. Para ello, abre Cloud Shell y ejecuta este comando:
export SPANNER_INSTANCE_ID=retail-demo
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
--edition=ENTERPRISE
Resultado del comando:
$ gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
--edition=ENTERPRISE
Creating instance...done.
Crea la base de datos
Una vez que la instancia esté en ejecución, podrás crear la base de datos. Spanner permite varias bases de datos en una sola instancia.
La base de datos es donde defines tu esquema. También puedes controlar quién tiene acceso a la base de datos, configurar el encriptado personalizado, configurar el optimizador y establecer el período de retención.
Para crear la base de datos, vuelve a usar la herramienta de línea de comandos de gcloud:
export SPANNER_DATABASE=cymbal-bikes
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Resultado del comando:
$ gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Creating database...done.
Resumen
En este paso, creaste la instancia y la base de datos de Spanner.
Cuál es el próximo paso
A continuación, configurarás el esquema y los datos de Spanner.
4. Carga el esquema y los datos de Cymbal
Crea el esquema de Cymbal
Para configurar el esquema, navega a Spanner Studio:
El esquema tiene dos partes. Primero, debes agregar la tabla products. Copia y pega esta instrucción en la pestaña vacía.
Para el esquema, copia y pega este DDL en el cuadro:
CREATE TABLE products (
categoryId INT64 NOT NULL,
productId INT64 NOT NULL,
productName STRING(MAX) NOT NULL,
productDescription STRING(MAX) NOT NULL,
productDescriptionEmbedding ARRAY<FLOAT32>,
createTime TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
inventoryCount INT64 NOT NULL,
priceInCents INT64,
) PRIMARY KEY(categoryId, productId);
Luego, haz clic en el botón run y espera unos segundos para que se cree el esquema.
A continuación, crearás los dos modelos y los configurarás en los extremos de modelo de Vertex AI.
El primer modelo es un modelo de embeddings que se usa para generar embeddings a partir de texto, y el segundo es un modelo de LLM que se usa para generar respuestas basadas en los datos de Spanner.
Pega el siguiente esquema en una pestaña nueva de Spanner Studio:
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-004'
);
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-3.1-pro-preview',
default_batch_size = 1
);
Luego, haz clic en el botón run y espera unos segundos para que se creen los modelos.
En el panel izquierdo de Spanner Studio, deberías ver las siguientes tablas y modelos:
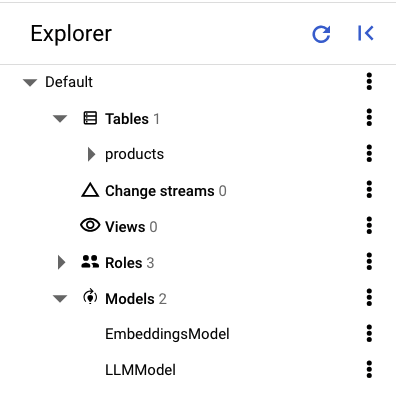
Carga los datos
Ahora, querrás insertar algunos productos en tu base de datos. Abre una pestaña nueva en Spanner Studio y, luego, copia y pega las siguientes instrucciones de inserción:
INSERT INTO products (categoryId, productId, productName, productDescription, createTime, inventoryCount, priceInCents)
VALUES (1, 1, "Cymbal Helios Helmet", "Safety meets style with the Cymbal children's bike helmet. Its lightweight design, superior ventilation, and adjustable fit ensure comfort and protection on every ride. Stay bright and keep your child safe under the sun with Cymbal Helios!", PENDING_COMMIT_TIMESTAMP(), 100, 10999),
(1, 2, "Cymbal Sprout", "Let their cycling journey begin with the Cymbal Sprout, the ideal balance bike for beginning riders ages 2-4 years. Its lightweight frame, low seat height, and puncture-proof tires promote stability and confidence as little ones learn to balance and steer. Watch them sprout into cycling enthusiasts with Cymbal Sprout!", PENDING_COMMIT_TIMESTAMP(), 10, 13999),
(1, 3, "Cymbal Spark Jr.", "Light, vibrant, and ready for adventure, the Spark Jr. is the perfect first bike for young riders (ages 5-8). Its sturdy frame, easy-to-use brakes, and puncture-resistant tires inspire confidence and endless playtime. Let the spark of cycling ignite with Cymbal!", PENDING_COMMIT_TIMESTAMP(), 34, 13900),
(1, 4, "Cymbal Summit", "Conquering trails is a breeze with the Summit mountain bike. Its lightweight aluminum frame, responsive suspension, and powerful disc brakes provide exceptional control and comfort for experienced bikers navigating rocky climbs or shredding downhill. Reach new heights with Cymbal Summit!", PENDING_COMMIT_TIMESTAMP(), 0, 79999),
(1, 5, "Cymbal Breeze", "Cruise in style and embrace effortless pedaling with the Breeze electric bike. Its whisper-quiet motor and long-lasting battery let you conquer hills and distances with ease. Enjoy scenic rides, commutes, or errands with a boost of confidence from Cymbal Breeze!", PENDING_COMMIT_TIMESTAMP(), 72, 129999),
(1, 6, "Cymbal Trailblazer Backpack", "Carry all your essentials in style with the Trailblazer backpack. Its water-resistant material, multiple compartments, and comfortable straps keep your gear organized and accessible, allowing you to focus on the adventure. Blaze new trails with Cymbal Trailblazer!", PENDING_COMMIT_TIMESTAMP(), 24, 7999),
(1, 7, "Cymbal Phoenix Lights", "See and be seen with the Phoenix bike lights. Powerful LEDs and multiple light modes ensure superior visibility, enhancing your safety and enjoyment during day or night rides. Light up your journey with Cymbal Phoenix!", PENDING_COMMIT_TIMESTAMP(), 87, 3999),
(1, 8, "Cymbal Windstar Pump", "Flat tires are no match for the Windstar pump. Its compact design, lightweight construction, and high-pressure capacity make inflating tires quick and effortless. Get back on the road in no time with Cymbal Windstar!", PENDING_COMMIT_TIMESTAMP(), 36, 24999),
(1, 9,"Cymbal Odyssey Multi-Tool","Be prepared for anything with the Odyssey multi-tool. This handy gadget features essential tools like screwdrivers, hex wrenches, and tire levers, keeping you ready for minor repairs and adjustments on the go. Conquer your journey with Cymbal Odyssey!", PENDING_COMMIT_TIMESTAMP(), 52, 999),
(1, 10,"Cymbal Nomad Water Bottle","Stay hydrated on every ride with the Nomad water bottle. Its sleek design, BPA-free construction, and secure lock lid make it the perfect companion for staying refreshed and motivated throughout your adventures. Hydrate and explore with Cymbal Nomad!", PENDING_COMMIT_TIMESTAMP(), 42, 1299);
Haz clic en el botón run para insertar los datos.
Resumen
En este paso, creaste el esquema y cargaste algunos datos básicos en la base de datos cymbal-bikes.
Cuál es el próximo paso
A continuación, realizarás la integración con el modelo de embeddings para generar embeddings para las descripciones de los productos, así como convertir una solicitud de búsqueda textual en un embedding para buscar productos relevantes.
5. Trabaja con embeddings
Genera embeddings de vectores para las descripciones de los productos
Para que la búsqueda de similitud funcione en los productos, debes generar embeddings para las descripciones de los productos.
Con el EmbeddingsModel creado en el esquema, esta es una sentencia DML UPDATE simple.
UPDATE products p1
SET productDescriptionEmbedding =
(SELECT embeddings.values from ML.PREDICT(MODEL EmbeddingsModel,
(SELECT productDescription as content FROM products p2 where p2.productId=p1.productId)))
WHERE categoryId=1;
Haz clic en el botón run para actualizar las descripciones de los productos.
Usa la búsqueda de vectores
En este ejemplo, proporcionarás una solicitud de búsqueda en lenguaje natural a través de una consulta en SQL. Esta consulta convertirá la solicitud de búsqueda en un embedding y, luego, buscará resultados similares en función de los embeddings almacenados de las descripciones de los productos que se generaron en el paso anterior.
-- Use Spanner's vector search, and integration with embedding and LLM models to
-- return items that are semantically relevant and available in inventory based on
-- real-time data.
SELECT productName, productDescription, inventoryCount, COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) as distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
Haz clic en el botón run para encontrar los productos similares. Los resultados deberían verse así:
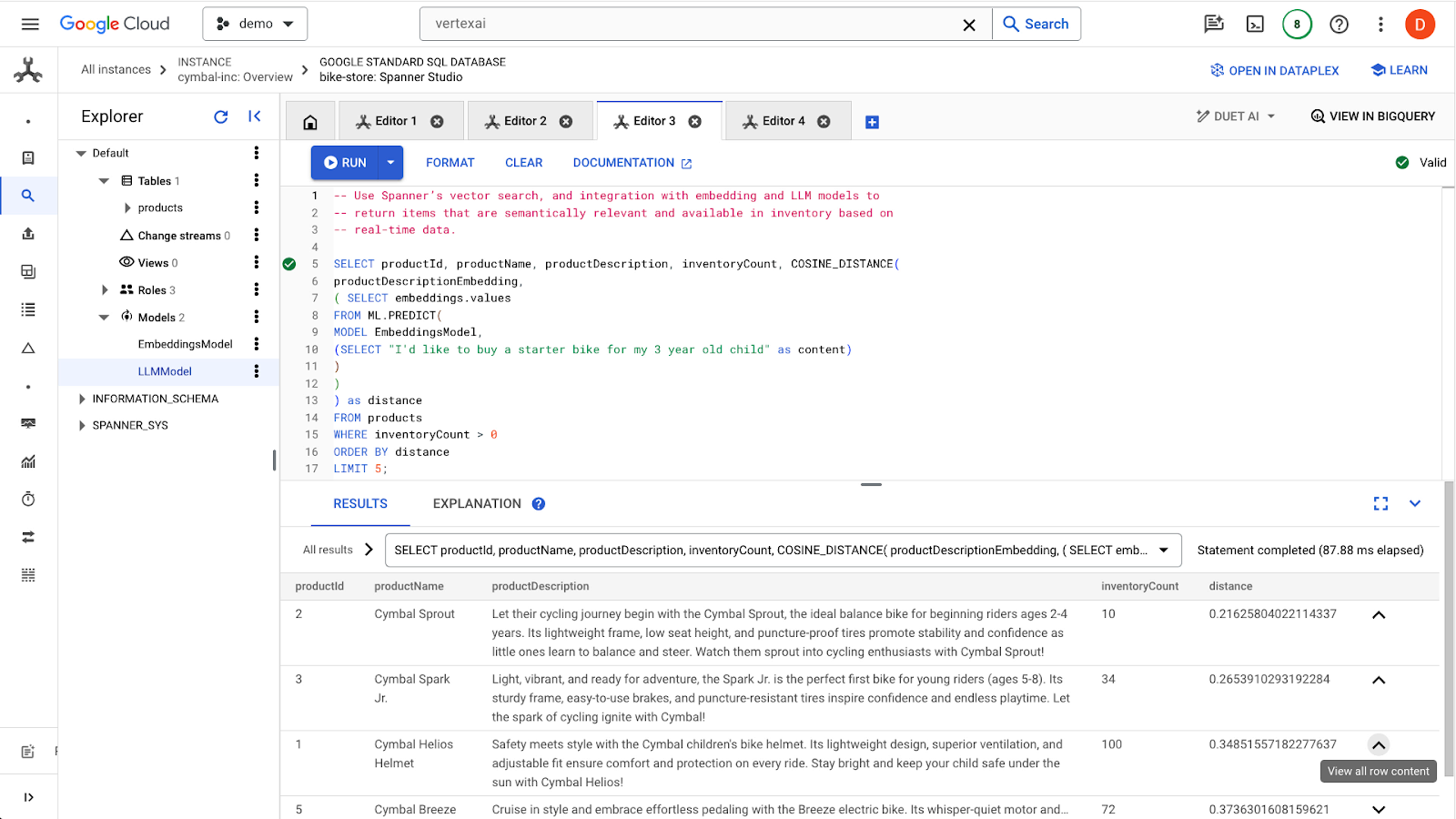
Observa que se usan filtros adicionales en la consulta, como solo interesarse en los productos que están en stock (inventoryCount > 0).
Resumen
En este paso, creaste embeddings de descripción de productos y un embedding de solicitud de búsqueda con SQL, aprovechando la integración de Spanner con los modelos en Vertex AI. También realizaste una búsqueda de vectores para encontrar productos similares que coincidan con la solicitud de búsqueda.
Próximos pasos
A continuación, usemos los resultados de la búsqueda para alimentar un LLM y generar una respuesta personalizada para cada producto.
6. Trabaja con un LLM
Spanner facilita la integración con los modelos de LLM que se entregan desde Vertex AI. Esto permite a los desarrolladores usar SQL para interactuar directamente con los LLMs, en lugar de requerir que la aplicación realice la lógica.
Por ejemplo, tenemos los resultados de la consulta de SQL anterior del usuario "I'd like to buy a starter bike for my 3 year old child".
El desarrollador desea proporcionar una respuesta para cada resultado sobre si el producto es adecuado para el usuario, con la siguiente instrucción:
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me? I'd like to buy a starter bike for my 3 year old child"
Esta es la consulta que puedes usar:
-- Use an LLM to analyze this list and provide a recommendation on whether each
-- product is a good fit for the user. We use the vector search and real time
-- inventory data to first filter the products to reduce the size of the prompt to
-- the LLM.
SELECT productName, productDescription, inventoryCount, content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
( SELECT
inventoryCount,
productName,
productDescription,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a starter bike for my 3 year old child \n",
"Product Name: ", productName, "\n",
"Product Description:", productDescription) AS prompt,
FROM products
WHERE inventoryCount > 0
ORDER by COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
( SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) LIMIT 5
),
STRUCT(256 AS maxOutputTokens)
);
Haz clic en el botón run para emitir la consulta. Los resultados deberían verse así:
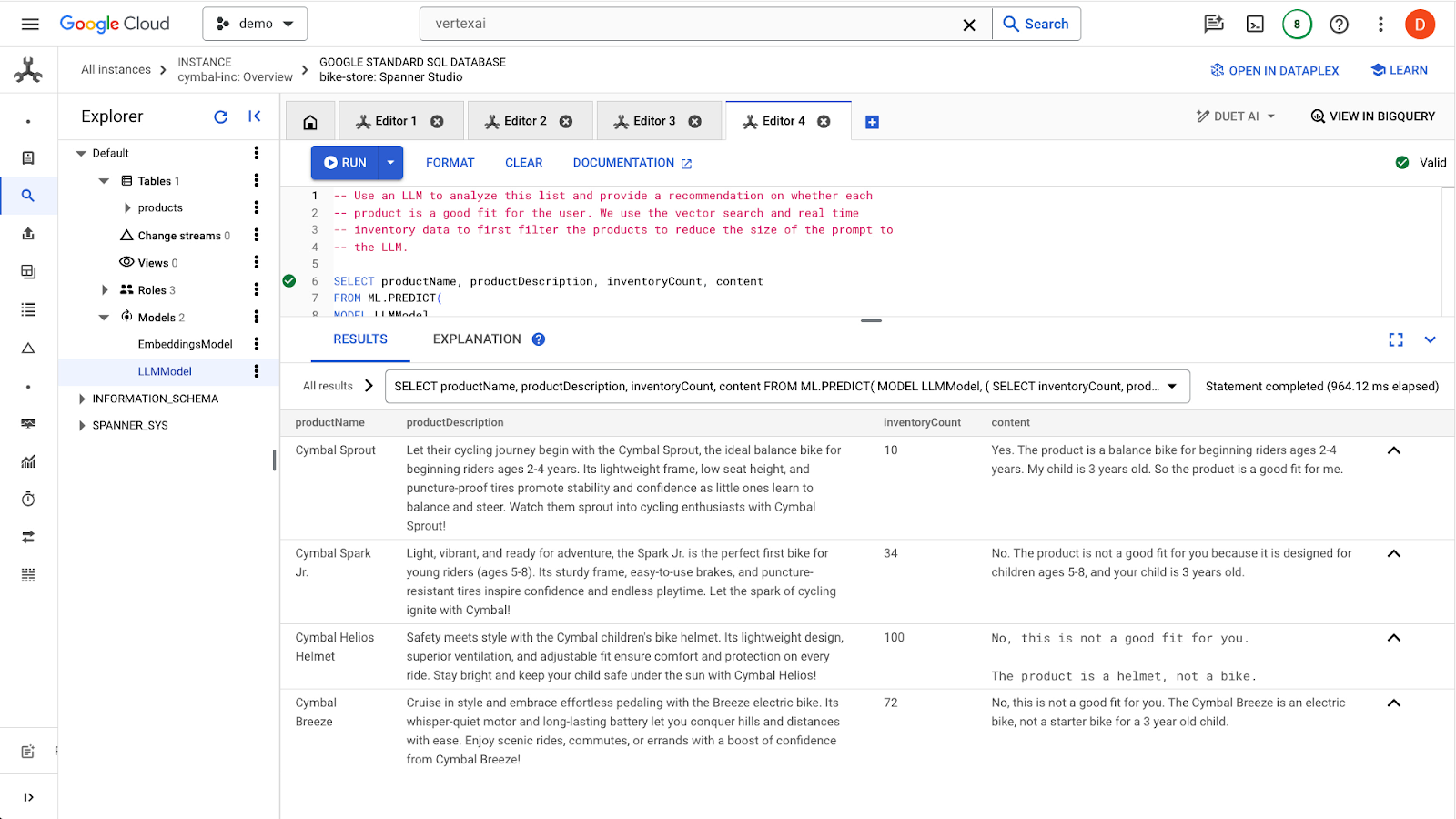
El primer producto es adecuado para un niño de 3 años debido al rango de edad en la descripción del producto (niños de 2 a 4 años). Los demás productos no son muy adecuados.
Resumen
En este paso, trabajaste con un LLM para generar respuestas básicas a las instrucciones de un usuario.
Próximos pasos
A continuación, veamos cómo usar ANN para escalar la búsqueda de vectores.
7. Escala la búsqueda de vectores
En los ejemplos anteriores de búsqueda de vectores, se aprovechó la búsqueda de vectores de KNN exacto. Esto es excelente cuando puedes consultar subconjuntos muy específicos de tus datos de Spanner. Se dice que esos tipos de consultas son altamente particionables.
Si no tienes cargas de trabajo altamente particionables y tienes una gran cantidad de datos, te recomendamos que uses la búsqueda de vectores de ANN aprovechando el algoritmo ScaNN para aumentar el rendimiento de la búsqueda.
Para ello en Spanner, deberás hacer lo siguiente:
- Crear un índice de vectores
- Modificar tu consulta para usar las funciones de distancia APPROX
Crea el índice de vectores
Para crear un índice de vectores en este conjunto de datos, primero debemos modificar la columna productDescriptionEmbeddings para definir la longitud de cada vector. Para agregar la longitud del vector a una columna, debes quitar la columna original y volver a crearla.
ALTER TABLE `products` DROP COLUMN `productDescriptionEmbedding`;
ALTER TABLE
`products` ADD COLUMN `productDescriptionEmbedding` ARRAY<FLOAT32>(vector_length=>768);
A continuación, vuelve a crear los embeddings desde el paso Generate Vector embedding que ejecutaste antes.
UPDATE products p1
SET productDescriptionEmbedding =
(SELECT embeddings.values from ML.PREDICT(MODEL EmbeddingsModel,
(SELECT productDescription as content FROM products p2 where p2.productId=p1.productId)))
WHERE categoryId=1;
Después de crear la columna, crea el índice:
CREATE VECTOR INDEX ProductDescriptionEmbeddingIndex
ON products(productDescriptionEmbedding)
WHERE productDescriptionEmbedding IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
Usa el índice nuevo
Para usar el nuevo índice de vectores, deberás modificar ligeramente la consulta de embeddings anterior.
Esta es la consulta original:
SELECT productName, productDescription, inventoryCount, COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) as distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
Deberás realizar los siguientes cambios:
- Usa una sugerencia de índice para el nuevo índice de vectores:
@{force_index=ProductDescriptionEmbeddingIndex}. - Cambia la llamada a la función
COSINE_DISTANCEporAPPROX_COSINE_DISTANCE. Ten en cuenta que las opciones de JSON en la consulta final que se muestra a continuación también son obligatorias. - Genera los embeddings de la función ML.PREDICT por separado.
- Copia los resultados de los embeddings en la consulta final.
Genera los embeddings
-- Generate the prompt embeddings
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
Destaca los resultados de la consulta y cópialos.
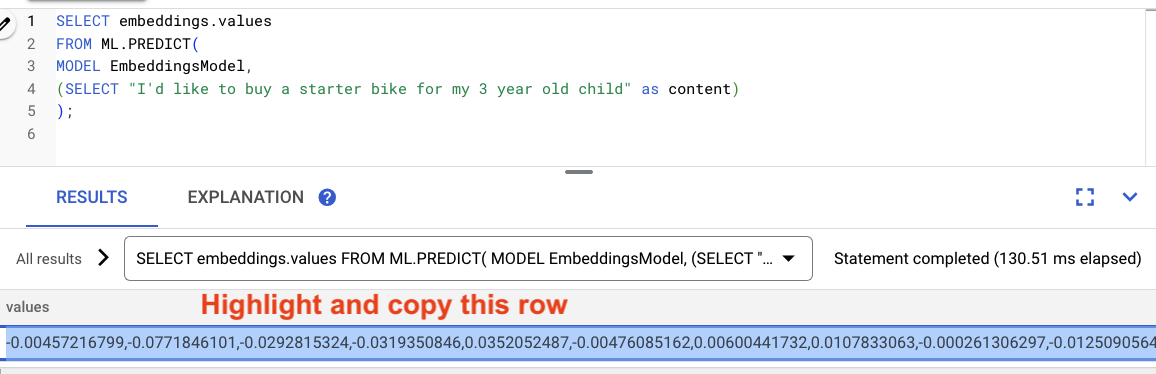
Luego, reemplaza <VECTOR> en la siguiente consulta pegando los embeddings que copiaste.
-- Embedding query now using the vector index
SELECT productName, productDescription, inventoryCount,
APPROX_COSINE_DISTANCE(productDescriptionEmbedding, array<float32>[@VECTOR], options => JSON '{\"num_leaves_to_search\": 10}')
FROM products @{force_index=ProductDescriptionEmbeddingIndex}
WHERE productDescriptionEmbedding IS NOT NULL AND inventoryCount > 0
ORDER BY distance
LIMIT 5;
Debería verse algo similar a esto:
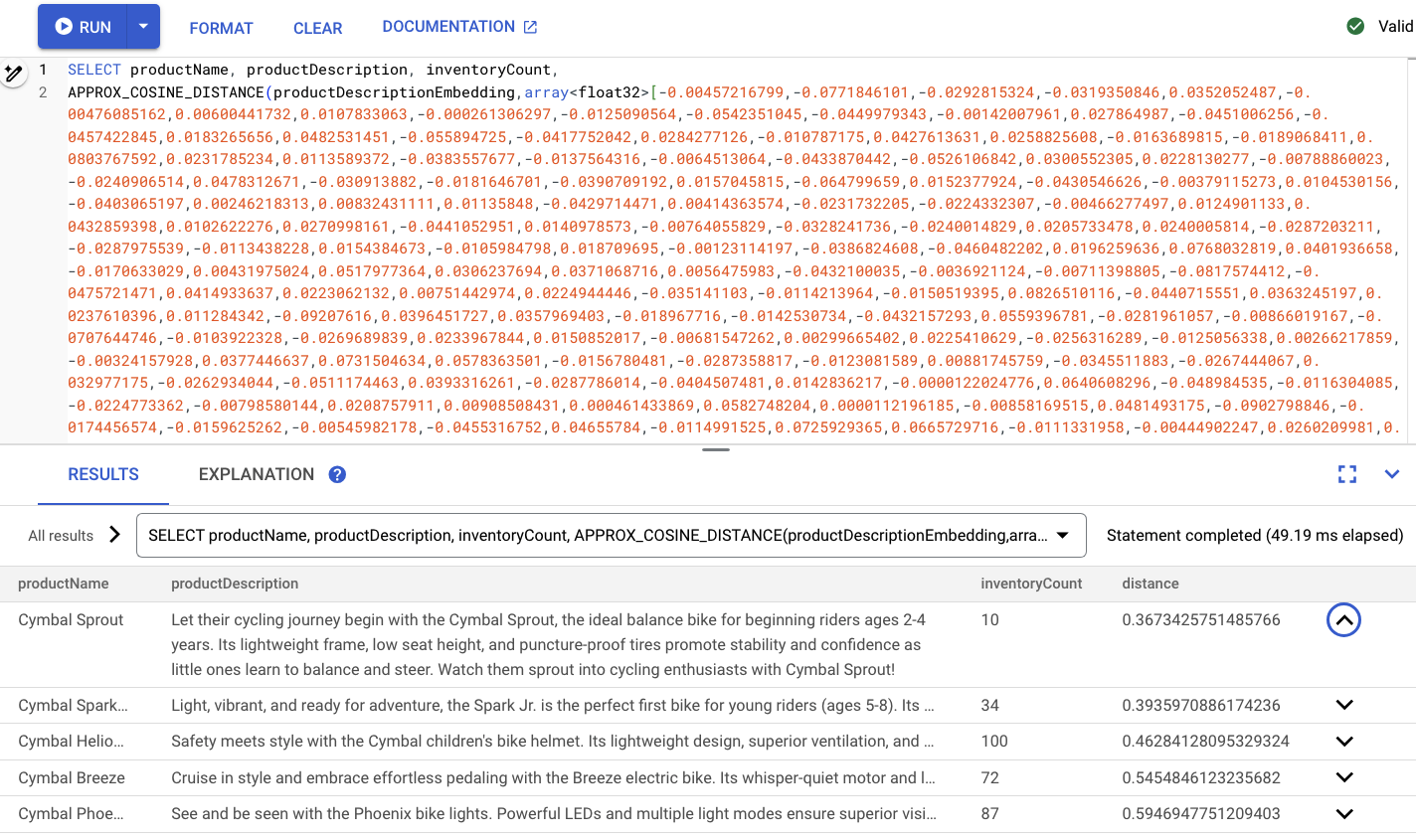
Resumen
En este paso, convertiste tu esquema para crear un índice de vectores. Luego, volviste a escribir la consulta de embeddings para realizar la búsqueda de ANN con el índice de vectores. Este es un paso importante a medida que tus datos crecen para escalar las cargas de trabajo de búsqueda de vectores.
Próximos pasos
A continuación, es hora de limpiar.
8. Limpieza (opcional)
Para limpiar, ve a la sección de Cloud Spanner de la consola de Cloud y borra la instancia 'retail-demo' que creamos en el codelab.
9. ¡Felicitaciones!
Felicitaciones, realizaste correctamente una búsqueda de similitud con la búsqueda de vectores integrada de Spanner. Además, viste lo fácil que es trabajar con modelos de LLM y de embeddings para proporcionar funcionalidad de IA generativa directamente con SQL.
Por último, aprendiste el proceso para realizar la búsqueda de ANN respaldada por el algoritmo ScaNN para escalar las cargas de trabajo de búsqueda de vectores.
Próximos pasos
Obtén más información sobre la función de K-vecino más cercano exacto (búsqueda de vectores de KNN) de Spanner aquí: https://cloud.google.com/spanner/docs/find-k-nearest-neighbors
Obtén más información sobre la función de vecino más cercano aproximado (búsqueda de vectores de ANN) de Spanner aquí: https://cloud.google.com/spanner/docs/find-approximate-nearest-neighbors
También puedes obtener más información para realizar predicciones en línea con SQL usando la integración de Vertex AI de Spanner aquí: https://cloud.google.com/spanner/docs/ml