
1. Introduzione
Spanner è un servizio di database completamente gestito, scalabile orizzontalmente e distribuito a livello globale, ideale per i carichi di lavoro operativi relazionali e non relazionali.
Spanner ha il supporto integrato per la ricerca vettoriale, che ti consente di eseguire ricerche di similarità o ricerca semantica e implementare la generazione aumentata dal recupero (RAG) nelle applicazioni AI generativa su larga scala, sfruttando le funzionalità di ricerca esatta del vicino più prossimo (KNN) o approssimativa del vicino più prossimo (ANN).
Le query di ricerca vettoriale di Spanner restituiscono dati aggiornati in tempo reale non appena le transazioni vengono eseguite, proprio come qualsiasi altra query sui dati operativi.
In questo lab, imparerai a configurare le funzionalità di base necessarie per utilizzare Spanner per eseguire la ricerca vettoriale e accedere ai modelli di embedding e LLM dal Model Garden di Vertex AI utilizzando SQL.
L'architettura ha questo aspetto:

Con questa base, imparerai a creare un indice vettoriale basato sull'algoritmo ScaNN e a utilizzare le funzioni di distanza APPROX quando i carichi di lavoro semantici devono essere scalati.
Cosa creerai
Nell'ambito di questo lab:
- Creerai un'istanza Spanner.
- Configurerai lo schema del database Spanner per l'integrazione con i modelli di embedding e LLM in Vertex AI.
- Caricherai un set di dati di vendita al dettaglio.
- Emetterai query di ricerca di similarità sul set di dati.
- Fornirai il contesto al modello LLM per generare consigli specifici per i prodotti.
- Modificherai lo schema e creerai un indice vettoriale.
- Modificherai le query per sfruttare l'indice vettoriale appena creato.
Obiettivi didattici
- Come configurare un'istanza Spanner
- Come eseguire l'integrazione con Vertex AI
- Come utilizzare Spanner per eseguire la ricerca vettoriale per trovare articoli simili in un set di dati di vendita al dettaglio
- Come preparare il database per scalare i carichi di lavoro di ricerca vettoriale utilizzando la ricerca ANN.
Che cosa ti serve
2. Configurazione e requisiti
Crea un progetto
Se non hai già un Account Google (Gmail o Google Workspace), devi crearne uno. Accedi alla console Google Cloud ( console.cloud.google.com) e crea un nuovo progetto.
Se hai già un progetto, fai clic sul menu a discesa di selezione del progetto in alto a sinistra nella console:

e fai clic sul pulsante "NUOVO PROGETTO" nella finestra di dialogo risultante per creare un nuovo progetto:
Se non hai ancora un progetto, dovresti visualizzare una finestra di dialogo simile a questa per crearne uno:
La finestra di dialogo successiva per la creazione del progetto ti consente di inserire i dettagli del nuovo progetto:
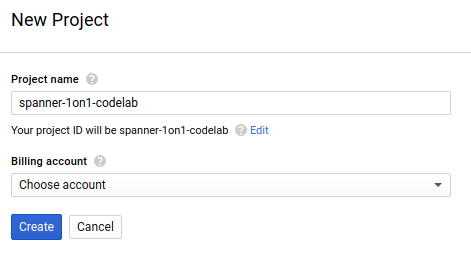
Ricorda l'ID progetto, che è un nome univoco tra tutti i progetti Google Cloud (il nome sopra è già stato utilizzato e non funzionerà per te, ci dispiace!). In questo codelab verrà indicato come PROJECT_ID.
Successivamente, se non l'hai già fatto, dovrai abilitare la fatturazione nella console per sviluppatori per utilizzare le risorse Google Cloud e abilitare l'API Spanner.
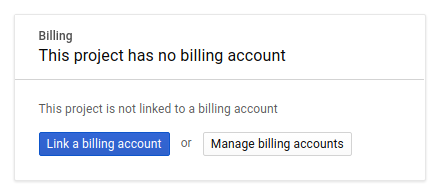
L'esecuzione di questo codelab non dovrebbe costarti più di qualche dollaro, ma potrebbe essere più cara se decidi di utilizzare più risorse o se le lasci in esecuzione (consulta la sezione "Pulizia" alla fine di questo documento). I prezzi di Google Cloud Spanner sono documentati qui.
I nuovi utenti di Google Cloud possono beneficiare di una prova senza costi di 300$, che dovrebbe rendere questo codelab completamente senza costi.
Configurazione di Google Cloud Shell
Sebbene Google Cloud e Spanner possano essere gestiti da remoto dal tuo laptop, in questo codelab utilizzeremo Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Questa macchina virtuale basata su Debian è dotata di tutti gli strumenti di sviluppo di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita in Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Ciò significa che per questo codelab ti servirà solo un browser (sì, funziona su un Chromebook).
- Per attivare Cloud Shell dalla console Google Cloud, fai clic su Attiva Cloud Shell
 (bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente).
(bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente).
Una volta eseguita la connessione a Cloud Shell, dovresti vedere che il tuo account è già autenticato e il progetto è già impostato sul tuo PROJECT_ID.
gcloud auth list
Output comando
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
Output comando
[core]
project = <PROJECT_ID>
Se, per qualche motivo, il progetto non è impostato, esegui il seguente comando:
gcloud config set project <PROJECT_ID>
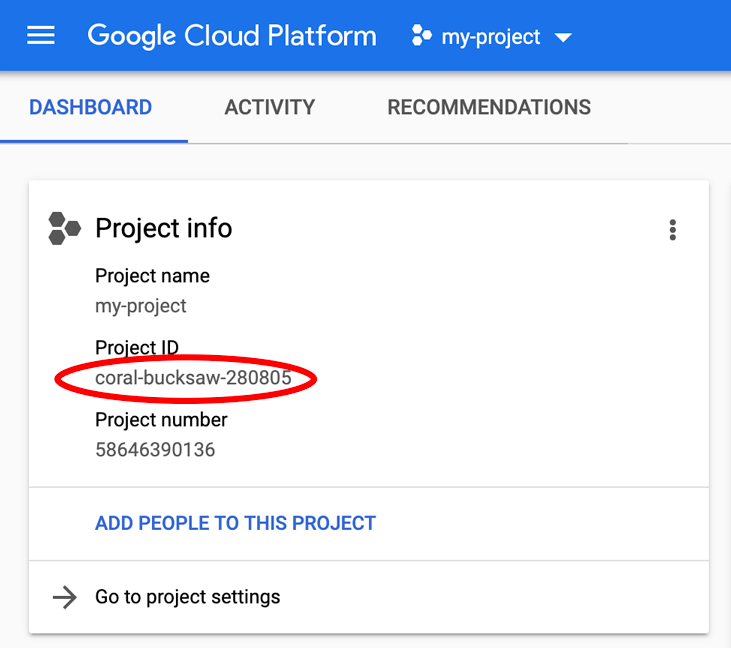
Cerchi il tuo PROJECT_ID? Controlla l'ID che hai utilizzato nei passaggi di configurazione o cercalo nella dashboard della console Google Cloud:
Cloud Shell imposta anche alcune variabili di ambiente per impostazione predefinita, che potrebbero essere utili quando esegui comandi futuri.
echo $GOOGLE_CLOUD_PROJECT
Output comando
<PROJECT_ID>
Abilita l'API Spanner
gcloud services enable spanner.googleapis.com
Riepilogo
In questo passaggio hai configurato il progetto, se non ne avevi già uno, hai attivato Cloud Shell e hai abilitato le API richieste.
In arrivo
Successivamente, configurerai l'istanza e il database Spanner.
3. Crea un'istanza e un database Spanner
Crea l'istanza Spanner
In questo passaggio configureremo l'istanza Spanner per il codelab. Per farlo, apri Cloud Shell ed esegui questo comando:
export SPANNER_INSTANCE_ID=retail-demo
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
--edition=ENTERPRISE
Output comando:
$ gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
--edition=ENTERPRISE
Creating instance...done.
Crea il database
Una volta che l'istanza è in esecuzione, puoi creare il database. Spanner consente di avere più database su una singola istanza.
Il database è il luogo in cui definisci lo schema. Puoi anche controllare chi ha accesso al database, configurare la crittografia personalizzata, configurare l'ottimizzatore e impostare il periodo di conservazione.
Per creare il database, utilizza di nuovo lo strumento a riga di comando gcloud:
export SPANNER_DATABASE=cymbal-bikes
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Output comando:
$ gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Creating database...done.
Riepilogo
In questo passaggio hai creato l'istanza e il database Spanner.
In arrivo
Successivamente, configurerai lo schema e i dati di Spanner.
4. Carica lo schema e i dati di Cymbal
Crea lo schema di Cymbal
Per configurare lo schema, vai a Spanner Studio:
Lo schema è composto da due parti. Innanzitutto, devi aggiungere la tabella products. Copia e incolla questa istruzione nella scheda vuota.
Per lo schema, copia e incolla questo DDL nella casella:
CREATE TABLE products (
categoryId INT64 NOT NULL,
productId INT64 NOT NULL,
productName STRING(MAX) NOT NULL,
productDescription STRING(MAX) NOT NULL,
productDescriptionEmbedding ARRAY<FLOAT32>,
createTime TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
inventoryCount INT64 NOT NULL,
priceInCents INT64,
) PRIMARY KEY(categoryId, productId);
Quindi, fai clic sul pulsante run e attendi alcuni secondi per la creazione dello schema.
Successivamente, creerai i due modelli e li configurerai per gli endpoint dei modelli Vertex AI.
Il primo modello è un modello di embedding utilizzato per generare embedding dal testo, mentre il secondo è un modello LLM utilizzato per generare risposte in base ai dati in Spanner.
Incolla lo schema seguente in una nuova scheda di Spanner Studio:
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-004'
);
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-3.1-pro-preview',
default_batch_size = 1
);
Quindi, fai clic sul pulsante run e attendi alcuni secondi per la creazione dei modelli.
Nel riquadro a sinistra di Spanner Studio dovresti visualizzare le seguenti tabelle e i seguenti modelli:
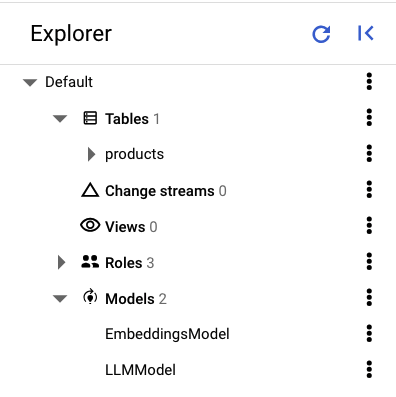
Carica i dati
Ora devi inserire alcuni prodotti nel database. Apri una nuova scheda in Spanner Studio, quindi copia e incolla le seguenti istruzioni di inserimento:
INSERT INTO products (categoryId, productId, productName, productDescription, createTime, inventoryCount, priceInCents)
VALUES (1, 1, "Cymbal Helios Helmet", "Safety meets style with the Cymbal children's bike helmet. Its lightweight design, superior ventilation, and adjustable fit ensure comfort and protection on every ride. Stay bright and keep your child safe under the sun with Cymbal Helios!", PENDING_COMMIT_TIMESTAMP(), 100, 10999),
(1, 2, "Cymbal Sprout", "Let their cycling journey begin with the Cymbal Sprout, the ideal balance bike for beginning riders ages 2-4 years. Its lightweight frame, low seat height, and puncture-proof tires promote stability and confidence as little ones learn to balance and steer. Watch them sprout into cycling enthusiasts with Cymbal Sprout!", PENDING_COMMIT_TIMESTAMP(), 10, 13999),
(1, 3, "Cymbal Spark Jr.", "Light, vibrant, and ready for adventure, the Spark Jr. is the perfect first bike for young riders (ages 5-8). Its sturdy frame, easy-to-use brakes, and puncture-resistant tires inspire confidence and endless playtime. Let the spark of cycling ignite with Cymbal!", PENDING_COMMIT_TIMESTAMP(), 34, 13900),
(1, 4, "Cymbal Summit", "Conquering trails is a breeze with the Summit mountain bike. Its lightweight aluminum frame, responsive suspension, and powerful disc brakes provide exceptional control and comfort for experienced bikers navigating rocky climbs or shredding downhill. Reach new heights with Cymbal Summit!", PENDING_COMMIT_TIMESTAMP(), 0, 79999),
(1, 5, "Cymbal Breeze", "Cruise in style and embrace effortless pedaling with the Breeze electric bike. Its whisper-quiet motor and long-lasting battery let you conquer hills and distances with ease. Enjoy scenic rides, commutes, or errands with a boost of confidence from Cymbal Breeze!", PENDING_COMMIT_TIMESTAMP(), 72, 129999),
(1, 6, "Cymbal Trailblazer Backpack", "Carry all your essentials in style with the Trailblazer backpack. Its water-resistant material, multiple compartments, and comfortable straps keep your gear organized and accessible, allowing you to focus on the adventure. Blaze new trails with Cymbal Trailblazer!", PENDING_COMMIT_TIMESTAMP(), 24, 7999),
(1, 7, "Cymbal Phoenix Lights", "See and be seen with the Phoenix bike lights. Powerful LEDs and multiple light modes ensure superior visibility, enhancing your safety and enjoyment during day or night rides. Light up your journey with Cymbal Phoenix!", PENDING_COMMIT_TIMESTAMP(), 87, 3999),
(1, 8, "Cymbal Windstar Pump", "Flat tires are no match for the Windstar pump. Its compact design, lightweight construction, and high-pressure capacity make inflating tires quick and effortless. Get back on the road in no time with Cymbal Windstar!", PENDING_COMMIT_TIMESTAMP(), 36, 24999),
(1, 9,"Cymbal Odyssey Multi-Tool","Be prepared for anything with the Odyssey multi-tool. This handy gadget features essential tools like screwdrivers, hex wrenches, and tire levers, keeping you ready for minor repairs and adjustments on the go. Conquer your journey with Cymbal Odyssey!", PENDING_COMMIT_TIMESTAMP(), 52, 999),
(1, 10,"Cymbal Nomad Water Bottle","Stay hydrated on every ride with the Nomad water bottle. Its sleek design, BPA-free construction, and secure lock lid make it the perfect companion for staying refreshed and motivated throughout your adventures. Hydrate and explore with Cymbal Nomad!", PENDING_COMMIT_TIMESTAMP(), 42, 1299);
Fai clic sul pulsante run per inserire i dati.
Riepilogo
In questo passaggio hai creato lo schema e caricato alcuni dati di base nel database cymbal-bikes.
In arrivo
Successivamente, eseguirai l'integrazione con il modello di embedding per generare embedding per le descrizioni dei prodotti, nonché per convertire una richiesta di ricerca testuale in un embedding per cercare i prodotti pertinenti.
5. Utilizza gli embedding
Genera vector embedding per le descrizioni dei prodotti
Affinché la ricerca di similarità funzioni sui prodotti, devi generare embedding per le descrizioni dei prodotti.
Con il modello EmbeddingsModel creato nello schema, si tratta di una semplice istruzione DML UPDATE.
UPDATE products p1
SET productDescriptionEmbedding =
(SELECT embeddings.values from ML.PREDICT(MODEL EmbeddingsModel,
(SELECT productDescription as content FROM products p2 where p2.productId=p1.productId)))
WHERE categoryId=1;
Fai clic sul pulsante run per aggiornare le descrizioni dei prodotti.
Utilizza la ricerca vettoriale
In questo esempio, fornirai una richiesta di ricerca in linguaggio naturale tramite una query SQL. Questa query trasformerà la richiesta di ricerca in un embedding, quindi cercherà risultati simili in base agli embedding memorizzati delle descrizioni dei prodotti generati nel passaggio precedente.
-- Use Spanner's vector search, and integration with embedding and LLM models to
-- return items that are semantically relevant and available in inventory based on
-- real-time data.
SELECT productName, productDescription, inventoryCount, COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) as distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
Fai clic sul pulsante run per trovare i prodotti simili. I risultati dovrebbero essere simili ai seguenti:
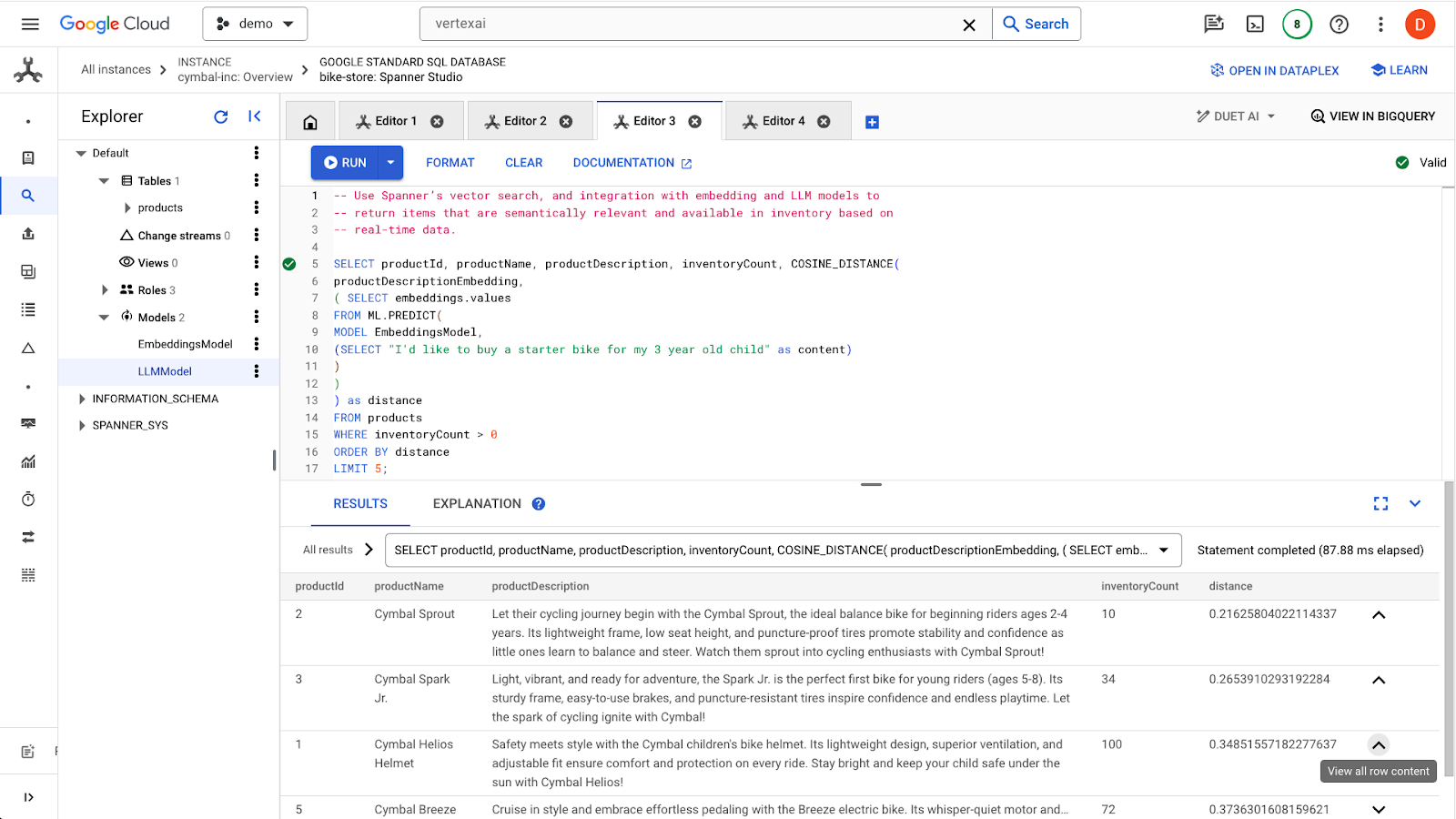
Tieni presente che nella query vengono utilizzati filtri aggiuntivi, ad esempio solo i prodotti disponibili (inventoryCount > 0).
Riepilogo
In questo passaggio hai creato embedding delle descrizioni dei prodotti e un embedding della richiesta di ricerca utilizzando SQL, sfruttando l'integrazione di Spanner con i modelli in Vertex AI. Hai anche eseguito una ricerca vettoriale per trovare prodotti simili che corrispondono alla richiesta di ricerca.
Passaggi successivi
Successivamente, utilizziamo i risultati della ricerca per alimentare un LLM per generare una risposta personalizzata per ogni prodotto.
6. Utilizza un LLM
Spanner semplifica l'integrazione con i modelli LLM forniti da Vertex AI. In questo modo, gli sviluppatori possono utilizzare SQL per interfacciarsi direttamente con gli LLM, anziché richiedere all'applicazione di eseguire la logica.
Ad esempio, abbiamo i risultati della query SQL precedente dell'utente "I'd like to buy a starter bike for my 3 year old child".
Lo sviluppatore vorrebbe fornire una risposta per ogni risultato per indicare se il prodotto è adatto all'utente, utilizzando il seguente prompt:
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me? I'd like to buy a starter bike for my 3 year old child"
Ecco la query che puoi utilizzare:
-- Use an LLM to analyze this list and provide a recommendation on whether each
-- product is a good fit for the user. We use the vector search and real time
-- inventory data to first filter the products to reduce the size of the prompt to
-- the LLM.
SELECT productName, productDescription, inventoryCount, content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
( SELECT
inventoryCount,
productName,
productDescription,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a starter bike for my 3 year old child \n",
"Product Name: ", productName, "\n",
"Product Description:", productDescription) AS prompt,
FROM products
WHERE inventoryCount > 0
ORDER by COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
( SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) LIMIT 5
),
STRUCT(256 AS maxOutputTokens)
);
Fai clic sul pulsante run per eseguire la query. I risultati dovrebbero essere simili ai seguenti:
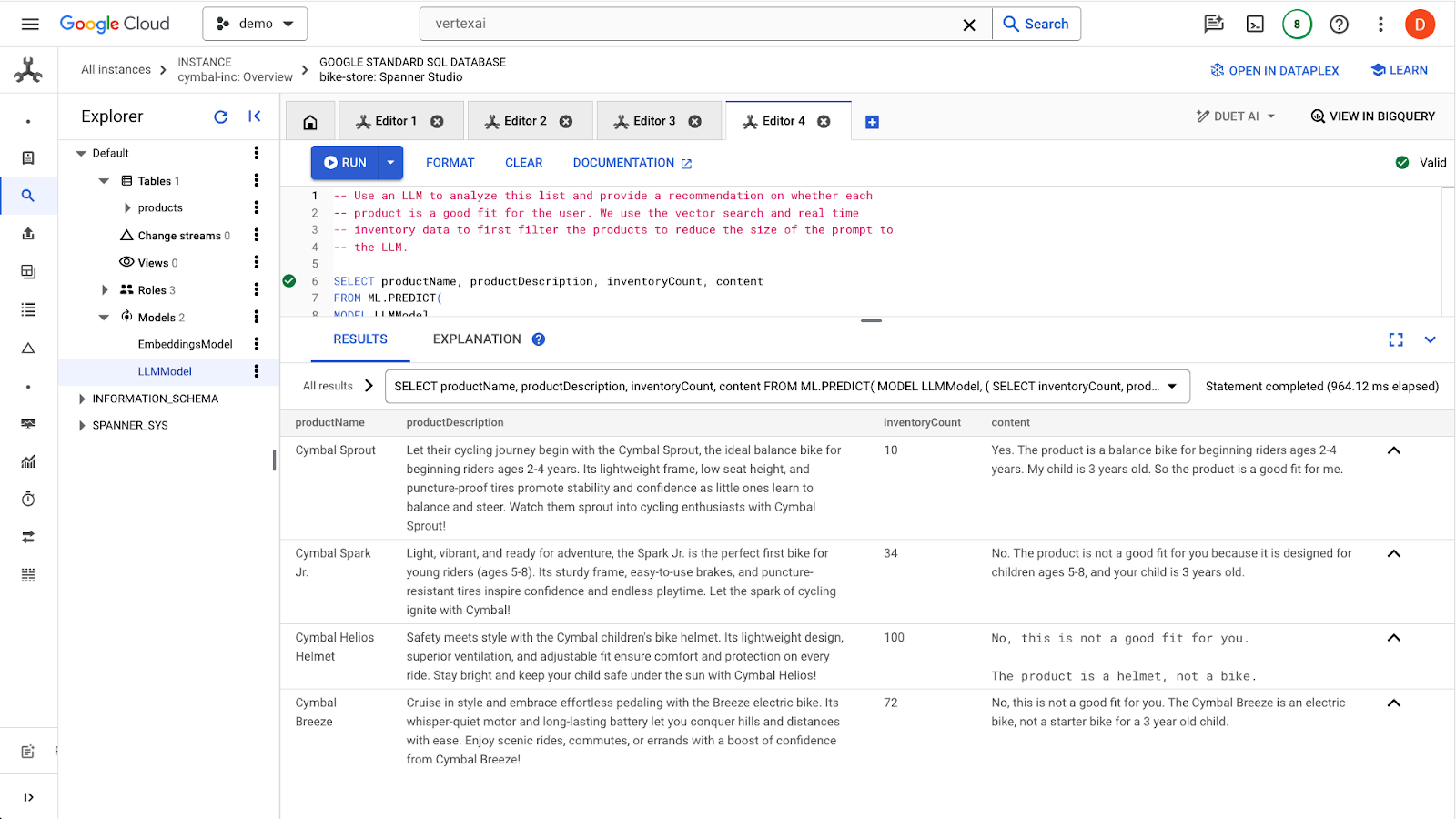
Il primo prodotto è adatto a un bambino di 3 anni a causa della fascia di età nella descrizione del prodotto (2-4 anni). Gli altri prodotti non sono adatti.
Riepilogo
In questo passaggio hai utilizzato un LLM per generare risposte di base ai prompt di un utente.
Passaggi successivi
Successivamente, scopriamo come utilizzare ANN per scalare la ricerca vettoriale.
7. Scala la ricerca vettoriale
Gli esempi di ricerca vettoriale precedenti hanno sfruttato la ricerca vettoriale KNN esatta. Questa funzionalità è ideale quando puoi eseguire query su sottoinsiemi molto specifici dei dati Spanner. Questi tipi di query sono detti altamente partizionabili.
Se non hai carichi di lavoro altamente partizionabili e hai una grande quantità di dati, ti consigliamo di utilizzare la ricerca vettoriale ANN sfruttando l'algoritmo ScaNN per aumentare le prestazioni di ricerca.
Per farlo in Spanner, devi fare due cose:
- Crea un indice vettoriale
- Modifica la query per utilizzare le funzioni di distanza APPROX.
Crea l'indice vettoriale
Per creare un indice vettoriale su questo set di dati, dobbiamo prima modificare la colonna productDescriptionEmbeddings per definire la lunghezza di ogni vettore. Per aggiungere la lunghezza del vettore a una colonna, devi eliminare la colonna originale e ricrearla.
ALTER TABLE `products` DROP COLUMN `productDescriptionEmbedding`;
ALTER TABLE
`products` ADD COLUMN `productDescriptionEmbedding` ARRAY<FLOAT32>(vector_length=>768);
Successivamente, crea di nuovo gli embedding dal passaggio Generate Vector embedding che hai eseguito in precedenza.
UPDATE products p1
SET productDescriptionEmbedding =
(SELECT embeddings.values from ML.PREDICT(MODEL EmbeddingsModel,
(SELECT productDescription as content FROM products p2 where p2.productId=p1.productId)))
WHERE categoryId=1;
Dopo aver creato la colonna, crea l'indice:
CREATE VECTOR INDEX ProductDescriptionEmbeddingIndex
ON products(productDescriptionEmbedding)
WHERE productDescriptionEmbedding IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
Utilizza il nuovo indice
Per utilizzare il nuovo indice vettoriale, dovrai modificare leggermente la query di embedding precedente.
Ecco la query originale:
SELECT productName, productDescription, inventoryCount, COSINE_DISTANCE(
productDescriptionEmbedding,
( SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
) as distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
Dovrai apportare le seguenti modifiche:
- Utilizza un suggerimento di indice per il nuovo indice vettoriale:
@{force_index=ProductDescriptionEmbeddingIndex} - Modifica la chiamata alla funzione
COSINE_DISTANCEinAPPROX_COSINE_DISTANCE. Tieni presente che anche le opzioni JSON nella query finale riportata di seguito sono obbligatorie. - Genera gli embedding separatamente dalla funzione ML.PREDICT.
- Copia i risultati degli embedding nella query finale.
Genera gli embedding
-- Generate the prompt embeddings
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
)
)
Evidenzia i risultati della query e copiali.
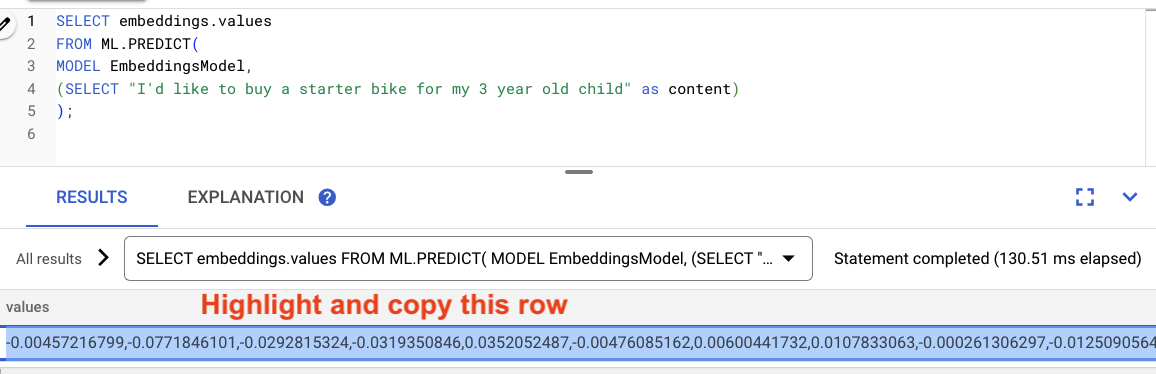
Quindi sostituisci <VECTOR> nella query seguente incollando gli embedding che hai copiato.
-- Embedding query now using the vector index
SELECT productName, productDescription, inventoryCount,
APPROX_COSINE_DISTANCE(productDescriptionEmbedding, array<float32>[@VECTOR], options => JSON '{\"num_leaves_to_search\": 10}')
FROM products @{force_index=ProductDescriptionEmbeddingIndex}
WHERE productDescriptionEmbedding IS NOT NULL AND inventoryCount > 0
ORDER BY distance
LIMIT 5;
Il sito dovrebbe avere il seguente aspetto:
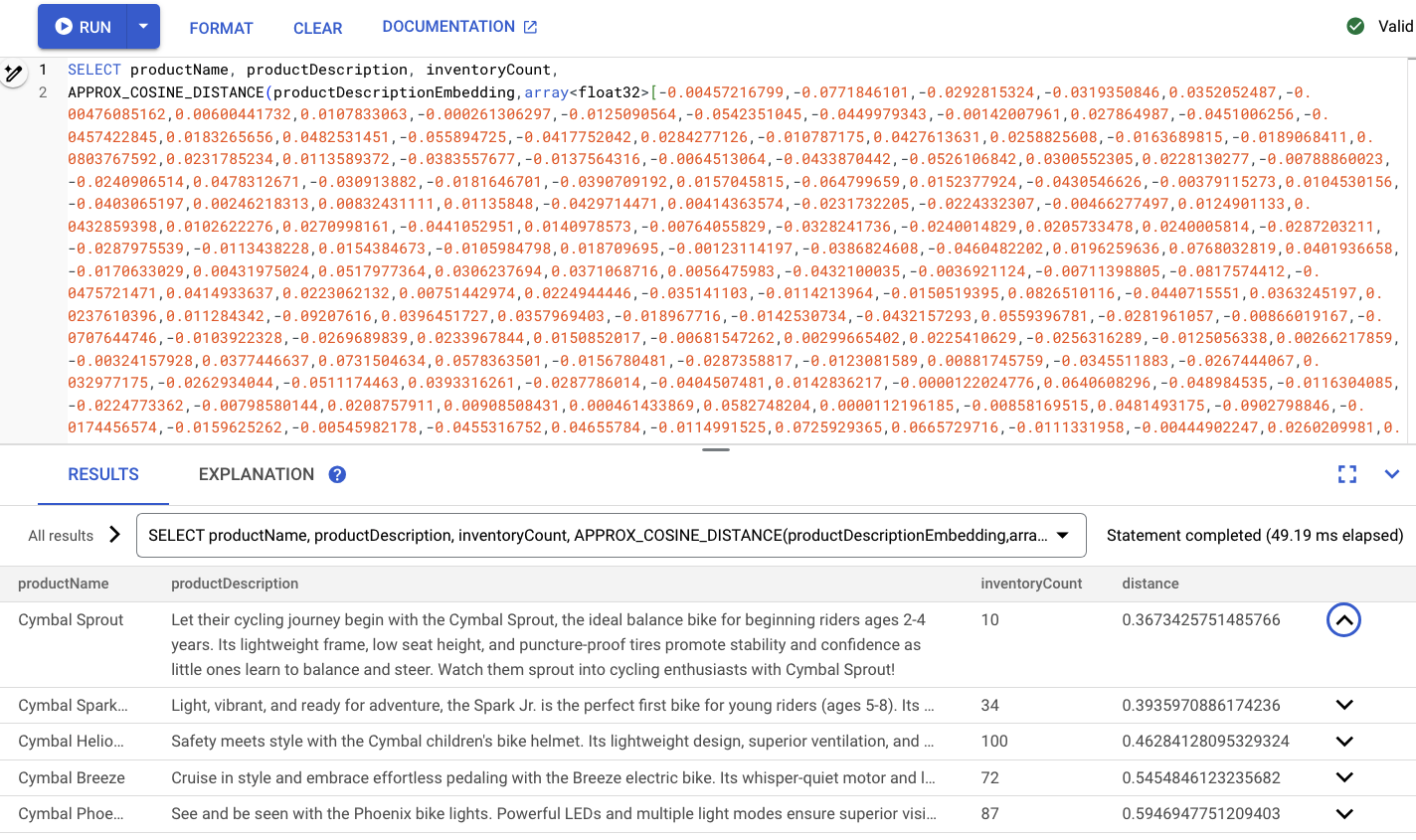
Riepilogo
In questo passaggio hai convertito lo schema per creare un indice vettoriale. Poi hai riscritto la query di embedding per eseguire la ricerca ANN utilizzando l'indice vettoriale. Questo è un passaggio importante man mano che i dati aumentano per scalare i carichi di lavoro di ricerca vettoriale.
Passaggi successivi
Ora è il momento di liberare spazio.
8. Pulizia (facoltativo)
Per liberare spazio, vai alla sezione Cloud Spanner della console Cloud ed elimina l'istanza 'retail-demo' che abbiamo creato nel codelab.
9. Complimenti!
Complimenti, hai eseguito correttamente una ricerca di similarità utilizzando la ricerca vettoriale integrata di Spanner. Inoltre, hai visto quanto è facile utilizzare i modelli di embedding e LLM per fornire funzionalità di AI generativa direttamente utilizzando SQL.
Infine, hai imparato la procedura per eseguire la ricerca ANN basata sull'algoritmo ScaNN per scalare i carichi di lavoro di ricerca vettoriale.
Passaggi successivi
Scopri di più sulla funzionalità di ricerca vettoriale del vicino più prossimo (KNN) esatto di Spanner qui: https://cloud.google.com/spanner/docs/find-k-nearest-neighbors
Scopri di più sulla funzionalità di ricerca vettoriale del vicino più prossimo (ANN) approssimativa di Spanner qui: https://cloud.google.com/spanner/docs/find-approximate-nearest-neighbors
Puoi anche leggere ulteriori informazioni su come eseguire previsioni online con SQL utilizzando l'integrazione di Spanner con Vertex AI qui: https://cloud.google.com/spanner/docs/ml